Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amebaブログにおける 記事カテゴリ付与プロジェクト
Search
CyberAgent
PRO
October 06, 2023
Technology
0
360
Amebaブログにおける 記事カテゴリ付与プロジェクト
CyberAgent
PRO
October 06, 2023
Tweet
Share
More Decks by CyberAgent
See All by CyberAgent
マッチングアプリにおけるユーザー構成の変化は、事業KPIにどう影響しているのか
cyberagentdevelopers
PRO
1
27
Geo-Experiments : ABEMAはなぜ新しい宣伝の効果検証にチャレンジするのか
cyberagentdevelopers
PRO
1
27
ABEMA NEWSにおける PoCをAIプロダクト化する ビジネスリードエンジニアリング
cyberagentdevelopers
PRO
0
280
チーム開発の基礎_研究を事業につなげるために
cyberagentdevelopers
PRO
8
4.8k
生成AIの研究活用_AILab2025研修
cyberagentdevelopers
PRO
12
7k
生成AIを活用したデータ分析でいまできること
cyberagentdevelopers
PRO
2
430
IBC 2025 動画技術関連レポート / IBC 2025 Report
cyberagentdevelopers
PRO
2
480
2025年度 生成AI 実践編
cyberagentdevelopers
PRO
8
1k
LLMを用いたメタデータベースレコメンド検証
cyberagentdevelopers
PRO
6
2.2k
Other Decks in Technology
See All in Technology
「お金で解決」が全てではない!大規模WebアプリのCI高速化 #phperkaigi
stefafafan
4
2.1k
スピンアウト講座03_CLAUDE-MDとSKILL-MD
overflowinc
0
700
「通るまでRe-run」から卒業!落ちないテストを書く勘所
asumikam
2
450
スピンアウト講座04_ルーティン処理
overflowinc
0
660
【社内勉強会】新年度からコーディングエージェントを使いこなす - 構造と制約で引き出すClaude Codeの実践知
nwiizo
10
6k
Phase08_クイックウィン実装
overflowinc
0
980
ABEMAのバグバウンティの取り組み
kurochan
1
360
20260321_エンベディングってなに?RAGってなに?エンベディングの説明とGemini Embedding 2 の紹介
tsho
0
140
LINEヤフーにおけるAIOpsの現在地
lycorptech_jp
PRO
5
2k
開発チームとQAエンジニアの新しい協業モデル -年末調整開発チームで実践する【QAリード施策】-
kaomi_wombat
0
200
Astro Islandsの 内部実装を 「日本で一番わかりやすく」 ざっくり解説!
knj
0
170
イベントで大活躍する電子ペーパー名札を作る(その2) 〜 M5PaperとM5PaperS3 〜 / IoTLT @ JLCPCB オープンハードカンファレンス
you
PRO
0
180
Featured
See All Featured
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
360
Information Architects: The Missing Link in Design Systems
soysaucechin
0
840
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Color Theory Basics | Prateek | Gurzu
gurzu
0
260
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
100
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Art, The Web, and Tiny UX
lynnandtonic
304
21k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
75
Rails Girls Zürich Keynote
gr2m
96
14k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.9k
Context Engineering - Making Every Token Count
addyosmani
9
770
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
250
Transcript
Amebaブログにおける 記事カテゴリ付与プロジェクト メディア事業部 Data Science Center Wakamatsu Kohei
Wakamatsu Kohei CA2020年度新卒 → ABEMA → Ameba広告 → WinTicket 機械学習,
MLOps, DataOps, etc 2 Profile
今日お話しすること/しないこと 前提 • Amebaブログの記事カテゴリを推論するシステムを作成した 話すこと • システムが使われ続けるためのMLエンジニア視点からの取り組み • (最後に)事業貢献のための専門性の使い所 話さないこと
• 機械学習手法の詳細 • 記事カテゴリプロジェクトの詳細
前提
「Amebaブログ」は2004年に開始し、現在では7,500万人の月間利用者数(延べ)を誇る 日本最大級のブログサービスです。25億以上のブログ記事があり、 一部のブログが国立図書館にウェブアーカイブされ、エンタメが資産化しつつあります。 そんなAmebaを中心とし、 • 芸能人・有名人を活用したビジネスモデルの開発 • ブログ公式アフィリエイトの運用 • AmebaNewsのオリジナルコンテンツの生成
様々なビジネス展開を現在行っています。 5 Amebaについて
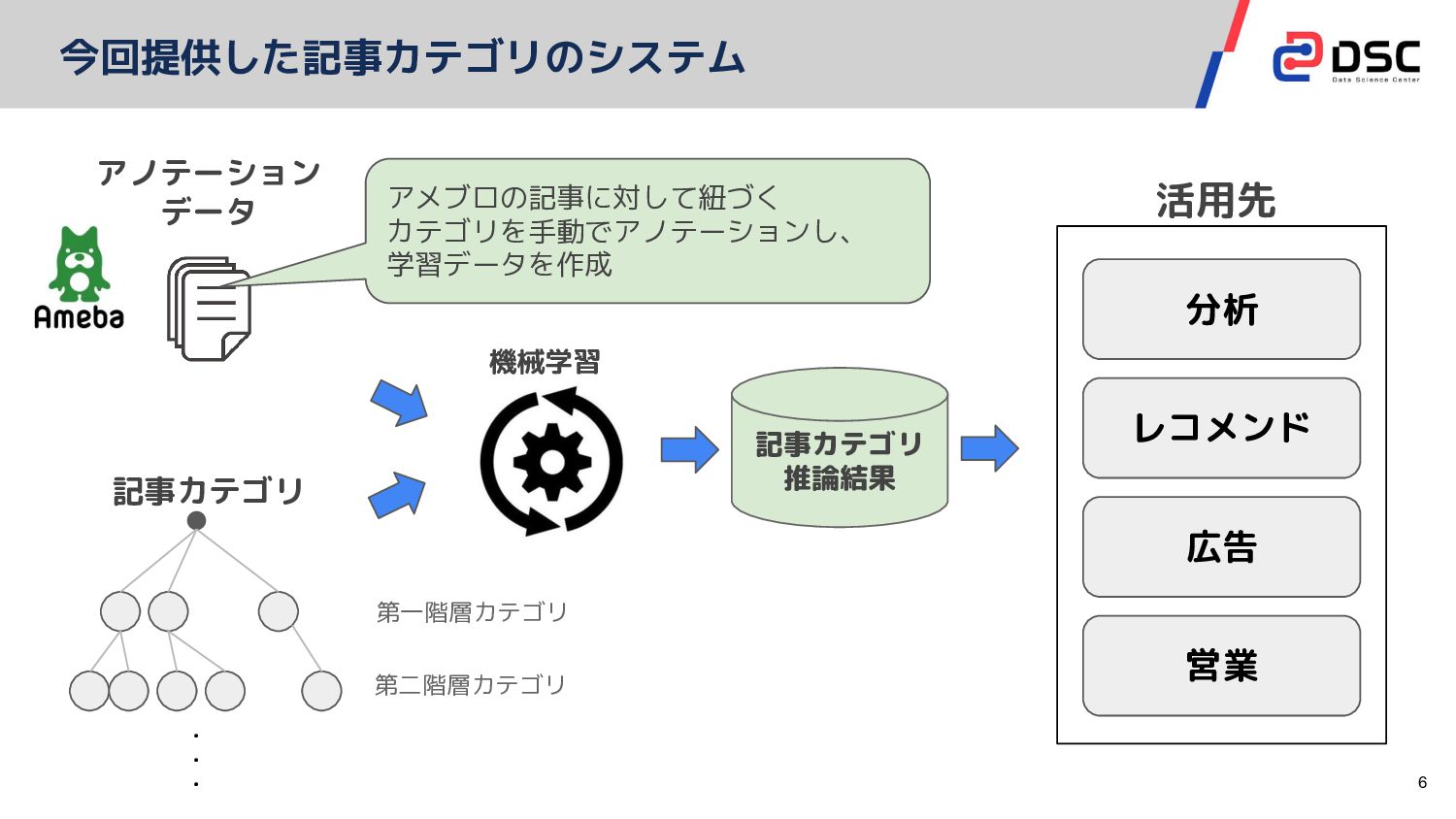
6 今回提供した記事カテゴリのシステム アノテーション データ 記事カテゴリ 分析 レコメンド 記事カテゴリ 推論結果 広告
営業 活用先 第一階層カテゴリ 第二階層カテゴリ ・ ・ ・ 機械学習 アメブロの記事に対して紐づく カテゴリを手動でアノテーションし、 学習データを作成
記事カテゴリの代替手段について 7 ブロガージャンル • ブロガーに対し付与されているジャンル • 記事には付与されていないので 例えば「アイドルブロガーが野球を見に 行った記事」には「野球」ジャンルから 辿り着けない
ハッシュタグ • 記事に対しブロガーが付与したタグ • ブロガー独自の定義のため カバレッジが低く種類が多い • 正しさはまちまち
記事カテゴリの代替手段について 課題 • 取り扱いは難しいが 情報としてはとても大事で 分析や施策/戦略立案に 利用されている • カバレッジと精度が不安 •
回遊/検索などにそのまま 利用するのは難しい 8 ブロガージャンル • ブロガーに対し付与されているジャンル • 記事には付与されていないので 例えば「アイドルブロガーが野球を見に 行った記事」には「野球」ジャンルから 辿り着けない ハッシュタグ • 記事に対しブロガーが付与したタグ • ブロガー独自の定義のため カバレッジが低く種類が多い • 正しさはまちまち
9 今回提供した記事カテゴリのシステムの目的 アノテーション データ 記事カテゴリ 分析 レコメンド 記事カテゴリ 推論結果 広告
営業 活用先 第一階層カテゴリ 第二階層カテゴリ ・ ・ ・ 機械学習 アメブロの記事に対して紐づく カテゴリを手動でアノテーションし、 学習データを作成 • 全ての記事に • ブロガーの情報とは独立して • 内容に沿ったカテゴリを付与する
10 今回提供したカテゴリについて • 記事に対し複数のカテゴリが紐づく • それぞれのカテゴリに対し 当てはまりの良さを表すスコアがついている • カテゴリは階層構造 •
現在、数百カテゴリに対するスコアが 全記事に対して付与 { “美容/美容ケア”: 0.96, “美容/美容ケア/ヘアケア”: 0.94, “ファッション/レディース”: 0.89, “ファッション/レディース/アイテム紹介”: 0.89, … } 具体例
取り組み
12 カテゴリの導入によって期待されること 短期的に - 分析用途でのさらなる広範な利用 - 検索/回遊/特集などによってユーザへの展開 - 代替手段を置き換えて意思決定に使われる状態へ -
何らかの分析や施策で試用できていること - 既存の推薦等のシステムで利用できていること - 上記で課題が見つかっていれば それに対するアプローチを決定できていること 長期的に
短期的に価値発揮しつつ、長期的な価値創出を目指す 13 価値発揮のサイクル 投資し続けることは難しい 短期的に利用されないと 一度作って終わり、になる 長期的な活用を見据えないと
短期的に価値発揮しつつ、長期的な価値創出を目指す 14 価値発揮のサイクル システム実装 価値発揮 新規ニーズ創出
15 価値発揮のサイクル: 実現のために 認識の共有 • 提供する機能の利用方法がわかること • 提供する機能がどんな状態なのかわかること 短期的な 価値発揮
• 新しいニーズに応えるための手順が 仕組み化されていること 長期的な 価値創出 • 新たな要望に応えやすい状態になっていること • データが資産になっていくこと
16 価値発揮のサイクル: 実現のために 認識の共有 • 提供する機能の利用方法がわかること • 提供する機能がどんな状態なのかわかること 短期的な 価値発揮
• 新しいニーズに応えるための手順が 仕組み化されていること 長期的な 価値創出 • 新たな要望に応えやすい状態になっていること • データが資産になっていくこと
認識の共有の難しさ 17 • 機械学習による推論結果の解釈は利用者にとっては困難 ◦ マルチラベル分類における推論値 → カテゴリごとに意味合いが異なる • どのくらい信用していいかわからない
{ “美容/美容ケア”: 0.96, “美容/美容ケア/ヘアケア”: 0.94, … } • 値が大きければ良さそう? • この結果ってどのくらい 正しいんだろうか…?
認識の共有: 提供するデータをわかりやすく 18 利用者(サービスのエンジニア/分析者)に使っていただく形式として、 以下の要望(条件)を満たすスコアを提供した • 複数のカテゴリ間で相対的に比較できる • 任意のカテゴリに対するスコアが閾値以上であれば、 そのカテゴリが当てはまっていると解釈できる
全てのカテゴリでGaussian Mixture Modelを用いた スコア最適化により統一的な空間で表現する • True, Falseが属するクラスタの 正規分布の平均を0, 1に固定し分散を最適化 • ある閾値以上のスコアをPositiveと仮定した場合に 各カテゴリにおけるmicro-f1 scoreが最大化されるよう分散を更新
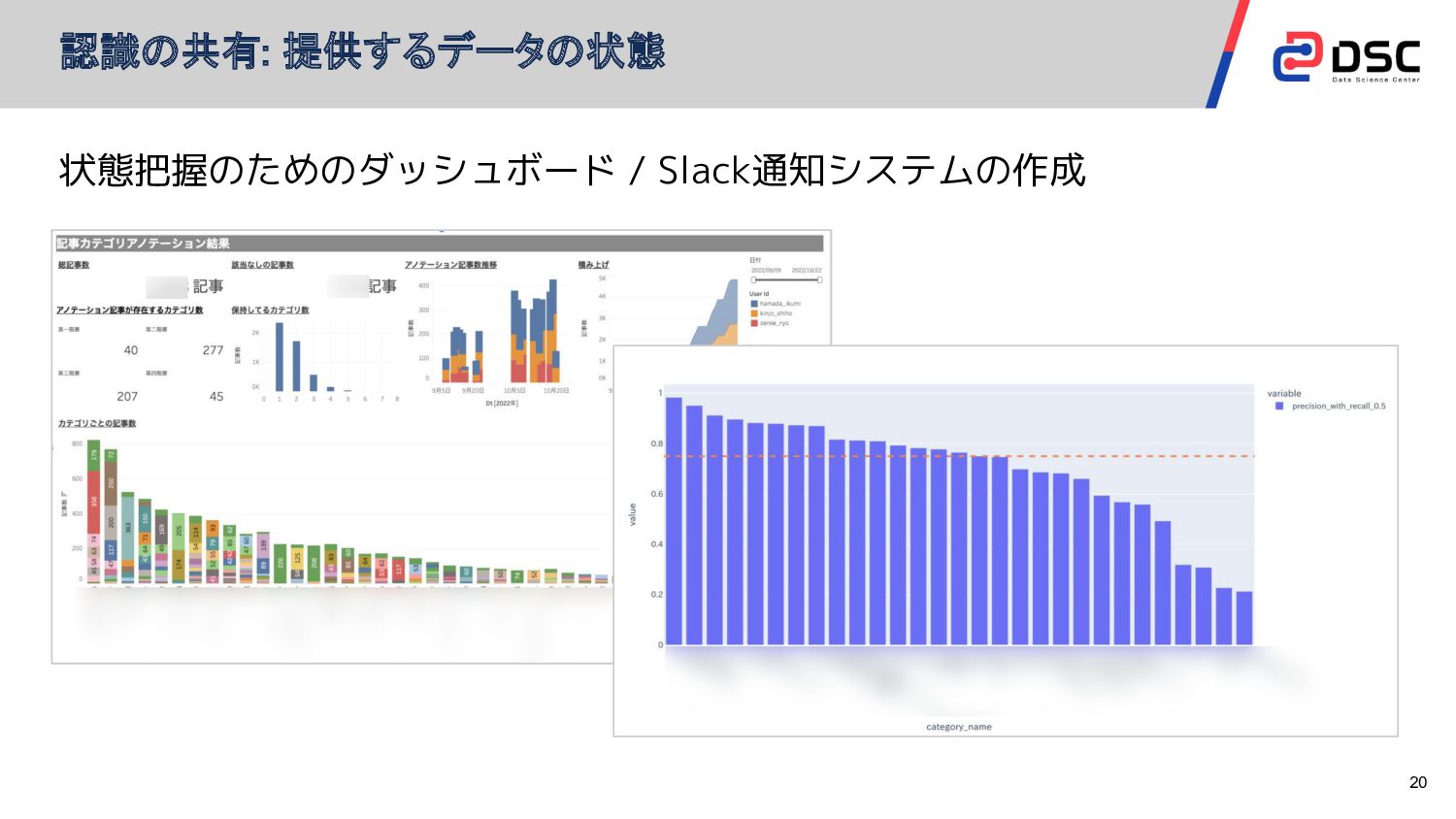
認識の共有: 提供するデータはどの程度信頼して良い? 19 提供する機械学習モデルの状態はどのように伝えたら良い? → macro-f1, micro-f1, etc…? 運用に関わるビジネスの方と連携し、チームとして目指す指標を次のように策定 全てのカテゴリはこの指標を満たすよう改善を行う
「Recall r%の時にPrecision p%以上」=「r%拾えてp%当てられる」 この指標を目指して改善していくぞ この指標を目指して改善していきましょう
認識の共有: 提供するデータの状態 20 状態把握のためのダッシュボード / Slack通知システムの作成
認識の共有: まとめ 21 以下を共通の言葉や図で表現した • システムが提供するもの ◦ 解釈のために深堀り (GMM) •
システムの現状 ◦ 解釈のために指標の分解 → チーム全体としてどういう状態を目指すべきか? 「一つのある指標」という共通の指針が得られた
22 価値発揮のサイクル: 実現のために 認識の共有 • 提供する機能の利用方法がわかること • 提供する機能がどんな状態なのかわかること 短期的な 価値発揮
• 新しいニーズに応えるための手順が 仕組み化されていること 長期的な 価値創出 • 新たな要望に応えやすい状態になっていること • データが資産になっていくこと
運用の中で新たなニーズが生まれてくる 「あるカテゴリの精度をもっと上げたい」 「新しいカテゴリに対する出力結果が欲しい」 「既存のカテゴリの構造を変更したい」 実際にあった要望: 「あるカテゴリのついた記事を施策に利用したいので精度を上げたい」 短期的な価値発揮 23
具体例: 任意のカテゴリの精度を上げるには 24 任意のカテゴリの精度を上げるためにアノテーションデータを確保する →アノテーション対象の選択方法を工夫 手順 ①アノテーション対象の候補を選択(文字数、PV実績などで決定) ②対象カテゴリに対するスコアが一定以上のものからランダムサンプリング ※一定以上のものを選択することによって多様性の低下を防ぐ
具体例: 任意のカテゴリの精度を上げるには 25 任意のカテゴリの精度を上げるためにアノテーションデータを確保する →アノテーション対象の選択方法を工夫 手順 ①アノテーション対象の候補を選択(文字数、PV実績などで決定) ②対象カテゴリに対するスコアが一定以上のものからランダムサンプリング ※一定以上のものを選択することによって多様性の低下を防ぐ 利用者が満たしたいアノテーション数と精度を設定として記述
条件が満たされるまで優先的に選ばれやすい状態が維持され、 課題解決に向かう
短期的な価値発揮: 仕組みづくり 26 ビジネスの方と開発者/運用者/利用者向けに改善手段を大別 それぞれに手順書と取り込むための仕組みが用意され、システムに反映される システム実装 価値発揮 新規ニーズ創出
27 価値発揮のサイクル: 実現のために 認識の共有 • 提供する機能の利用方法がわかること • 提供する機能がどんな状態なのかわかること 短期的な 価値発揮
• 新しいニーズに応えるための手順が 仕組み化されていること 長期的な 価値創出 • 新たな要望に応えやすい状態になっていること • データが資産になっていくこと
長期的な価値創出 28 アノテーションデータは資産になる • モデルの長期的な改善のため • 分岐等の別の目的での利用される可能性 機械学習エンジニアの観点から以下に取り組んだ • 品質の高い状態を保つ
(今日話すこと) • 長く活用される状態を保つ
以下が担保されている状態を目指す • 網羅性: 数百あるカテゴリ全てである程度サンプル数が確保されている • 正確性: 学習のノイズになり得るデータが極力少ない → データの蓄積のために
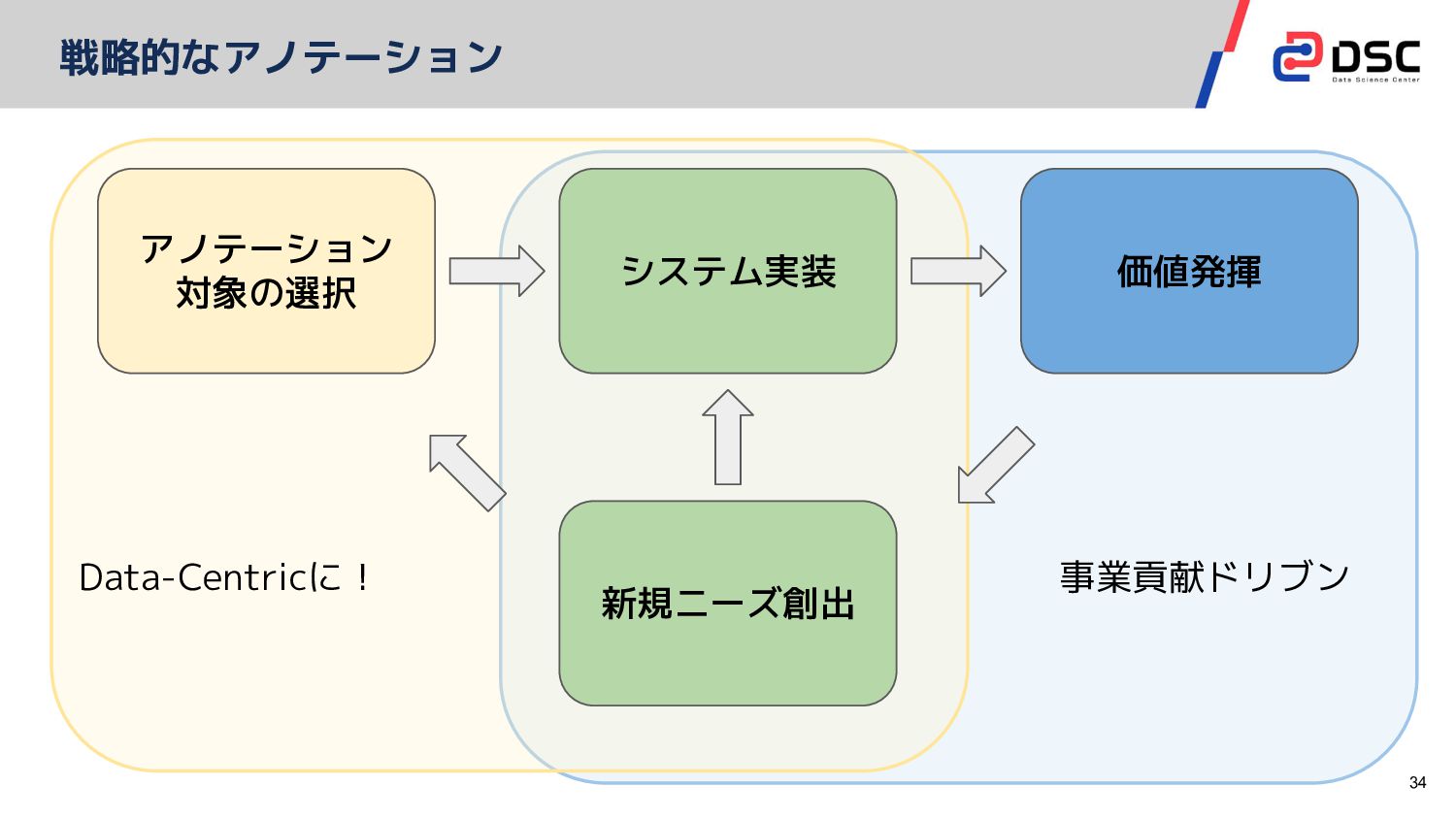
戦略的にアノテーションデータを選択する機能を実現 長期的な価値創出: 戦略的なアノテーション 29
戦略的にアノテーションデータを選択する機能の実現 状態の把握 • サンプル数や指標についてチェック 長期的な価値創出: 戦略的なアノテーション 30
戦略的にアノテーションデータを選択する機能の実現 条件 / 優先度 1. 特定のカテゴリに設定したサンプル数に満たない 2. 特定のカテゴリに設定した指標に満たない 3. カテゴリ全体に設定したサンプル数に満たない
4. カテゴリ全体に設定した指標に満たない 5. ランダムサンプリング 長期的な価値創出: 戦略的なアノテーション 31 • 指標を正しく解釈するためにまずサンプル数を確保 ◦ 指標がデータ数が少ないことが起因か、質が低いことが起因かを区別したい
戦略的にアノテーションデータを選択する機能の実現 条件 / 優先度 1. 特定のカテゴリに設定したサンプル数に満たない 2. 特定のカテゴリに設定した指標に満たない 3. カテゴリ全体に設定したサンプル数に満たない
4. カテゴリ全体に設定した指標に満たない 5. ランダムサンプリング 長期的な価値創出: 戦略的なアノテーション 32 • ある程度サンプル数が集まれば指標は”サチる”可能性がある ◦ すでにある学習データがノイズになっている場合を考慮
長期的な価値創出: 戦略的なアノテーション 戦略的にアノテーションデータを選択する機能の実現 対象 • 未学習データ: サンプル数の増加 ◦ あるカテゴリについて一定以上のスコアが付与された 記事からランダムサンプリング
▪ スコアの降順に選択すると学習データの多様性を変化させづらい 懸念があるため • 学習データ: 既存ラベルからのノイズの排除 ◦ 再アノテーションになる ◦ あるカテゴリについて、False Positive Predictionの中から スコアが最大であるものを選択(Least Confidence; Active Learning) 33
34 戦略的なアノテーション システム実装 価値発揮 新規ニーズ創出 アノテーション 対象の選択 事業貢献ドリブン Data-Centricに!
まとめ
36 振り返り 短期的に - 分析用途でのさらなる広範な利用 ✅ - 検索/回遊/特集などによってユーザへの展開 (まだ) -
代替手段を置き換えて意思決定に使われる状態へ (まだ) - 何らかの分析や施策で試用できていること ✅ - 既存の推薦等のシステムで利用できていること ✅ - 上記で課題が見つかっていれば それに対するアプローチを決定できていること ✅ 長期的に
37 - まだまだ始まったばかり、これからいろんな問題が出てくる - 全てのプロジェクト、ステークホルダーに対しできることではない - まず対等に話せるような状態にするところから 始まるケースも多分にある - 「仕組み」や「フロー」がプロジェクトやサービスの貢献に
役立ったことを評価するのはとても難しい 振り返り 課題
まとめ 3 MLエンジニアとしての取り組み • ビジネスの方と共通の言葉でコミュニケーションができる状態作り • 改善したい指標を明確にし責務を分けて貢献できる仕組み作り • 事業貢献と並行して資産になるようなデータ蓄積の試み
まとめ 3 個人的に • 使われるって難しい、使われるための取り組みも重要 • ロジックを解くだけにデータ活用の技術が、 システムを提供するためだけにエンジニアリングがあるわけではない • こういった課題に取り組んでくださる方を募集しています
サイバーエージェントでは 一緒に挑戦する仲間を募集中です! ✔オンラインでカジュアル面談実施中 ✔今すぐ転職を考えていなくてもOK! 詳しくはコチラから👉
41 評価について 弊社エンジニアの資料をご覧ください https://speakerdeck.com/cyberagentdevelopers/detahuo-yong-gashi-ye-gong-xian-siteirukotowoshi-sutamenoqu-rizu-mi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}