NLP, Computer Vision, Predictive Modeling & ML in general • Interested in Cloud Tech and Scaling Stuff • Starting my own ML consulting business: http://ogrisel.com jeudi 7 mars 13
tokens to integer feature indices • A Big Python dict: slow to (un)pickle • Large Corpus: ~10^6 tokens • Vocabulary == Statefulness == Sync barrier • No easy way to run in parallel jeudi 7 mars 13
hash function: • Does not need any memory storage • Hashing is stateless: can run in parallel! >>> from sklearn.utils.murmurhash import * >>> murmurhash3_bytes_u32('cat', 0) % 10 9L >>> murmurhash3_bytes_u32('sat', 0) % 10 0L jeudi 7 mars 13
22.055MB (training set) 7532 documents - 13.801MB (testing set) Extracting features from the training dataset using a sparse vectorizer done in 12.881007s at 1.712MB/s n_samples: 11314, n_features: 129792 Extracting features from the test dataset using the same vectorizer done in 4.043470s at 3.413MB/s n_samples: 7532, n_features: 129792 TfidfVectorizer jeudi 7 mars 13
22.055MB (training set) 7532 documents - 13.801MB (testing set) Extracting features from the training dataset using a sparse vectorizer done in 5.281561s at 4.176MB/s n_samples: 11314, n_features: 65536 Extracting features from the test dataset using the same vectorizer done in 3.413027s at 4.044MB/s n_samples: 7532, n_features: 65536 HashingVectorizer jeudi 7 mars 13
140MB raw text / 174,180 reviews: 53s • Books reviews: 1.3GB XML file 900MB raw text / 975,194 reviews: ~6min • https://gist.github.com/ogrisel/4313514 jeudi 7 mars 13
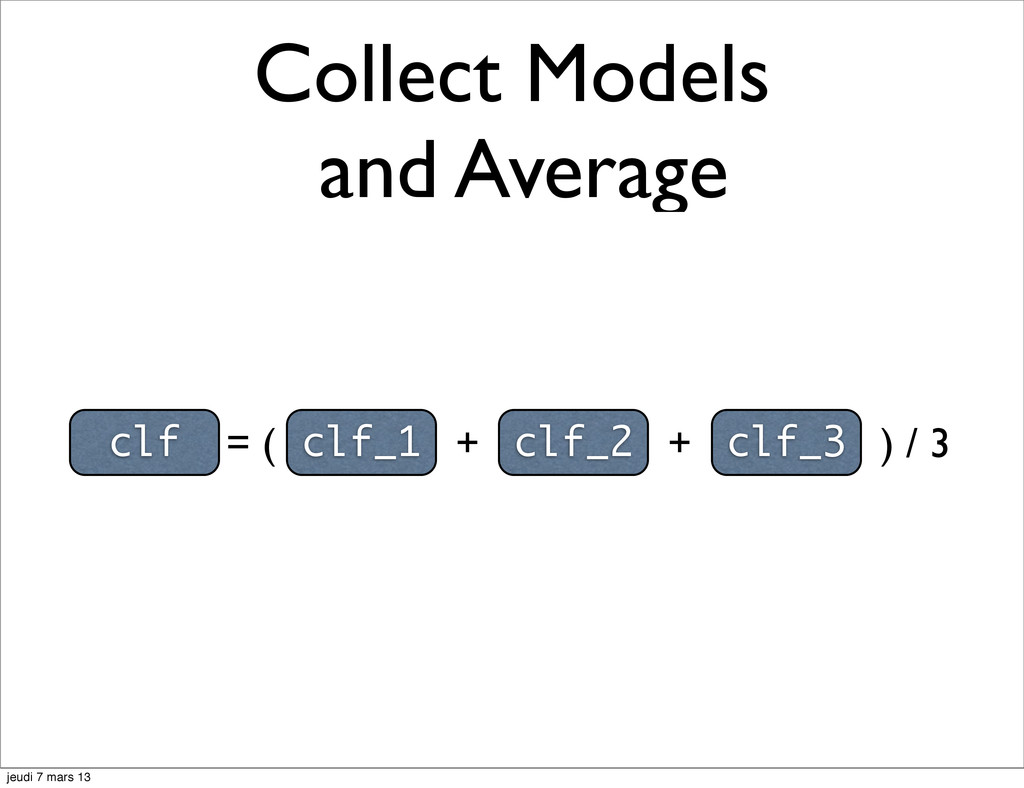
Labels 2 Text Data 2 Labels 3 Text Data 3 vec vec vec Labels 1 Vec Data 1 Labels 2 Vec Data 2 Labels 3 Text Data 3 clf_1 clf_2 clf_2 clf_3 jeudi 7 mars 13
exactly equivalent of models trained on the unpartitioned dataset • If very much data: does not matter much in practice: Gilles Louppe & Pierre Geurts http://www.cs.bris.ac.uk/~flach/ jeudi 7 mars 13
without exec under Unix • Break some optimized runtimes: • OpenBlas • Grand Central Dispatch under OSX • Will be fixed in Python 3 at some point... jeudi 7 mars 13
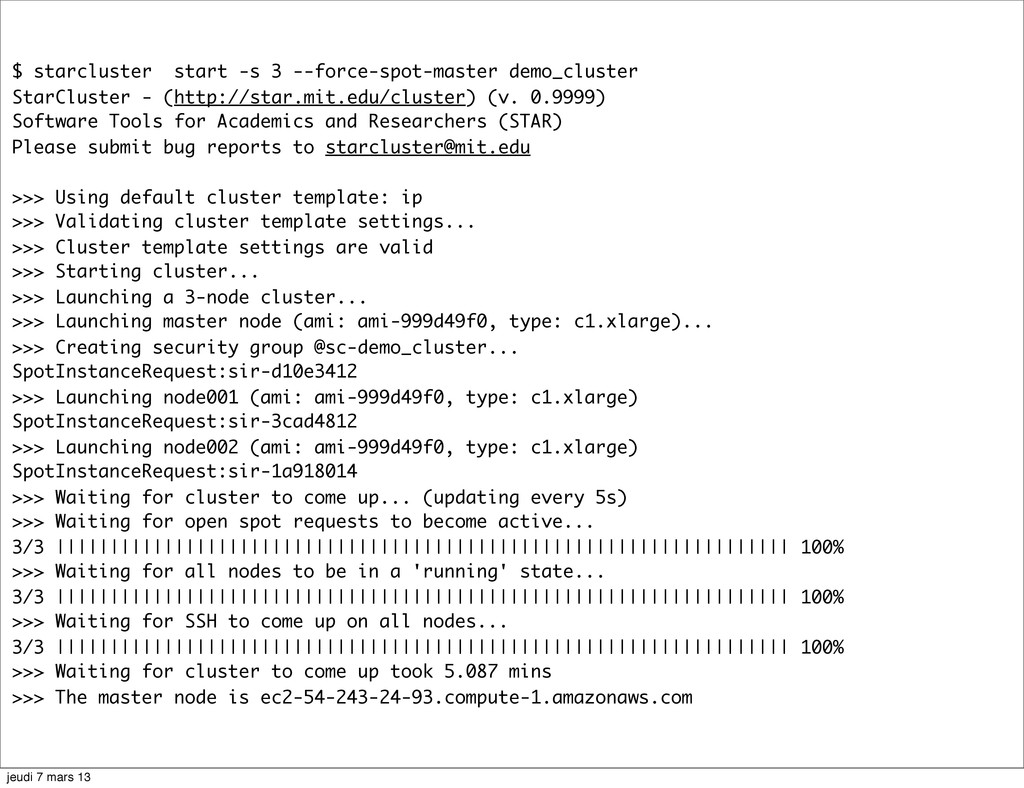
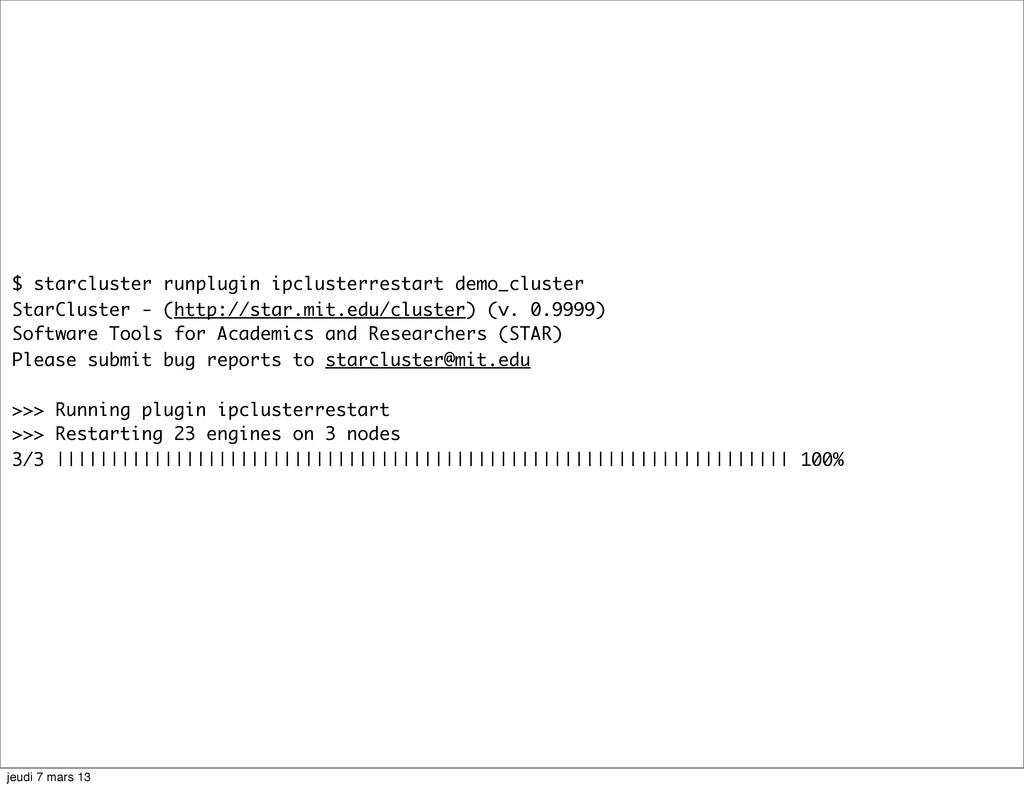
(v. 0.9999) Software Tools for Academics and Researchers (STAR) Please submit bug reports to [email protected] >>> Using default cluster template: ip >>> Validating cluster template settings... >>> Cluster template settings are valid >>> Starting cluster... >>> Launching a 3-node cluster... >>> Launching master node (ami: ami-999d49f0, type: c1.xlarge)... >>> Creating security group @sc-demo_cluster... SpotInstanceRequest:sir-d10e3412 >>> Launching node001 (ami: ami-999d49f0, type: c1.xlarge) SpotInstanceRequest:sir-3cad4812 >>> Launching node002 (ami: ami-999d49f0, type: c1.xlarge) SpotInstanceRequest:sir-1a918014 >>> Waiting for cluster to come up... (updating every 5s) >>> Waiting for open spot requests to become active... 3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100% >>> Waiting for all nodes to be in a 'running' state... 3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100% >>> Waiting for SSH to come up on all nodes... 3/3 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100% >>> Waiting for cluster to come up took 5.087 mins >>> The master node is ec2-54-243-24-93.compute-1.amazonaws.com jeudi 7 mars 13
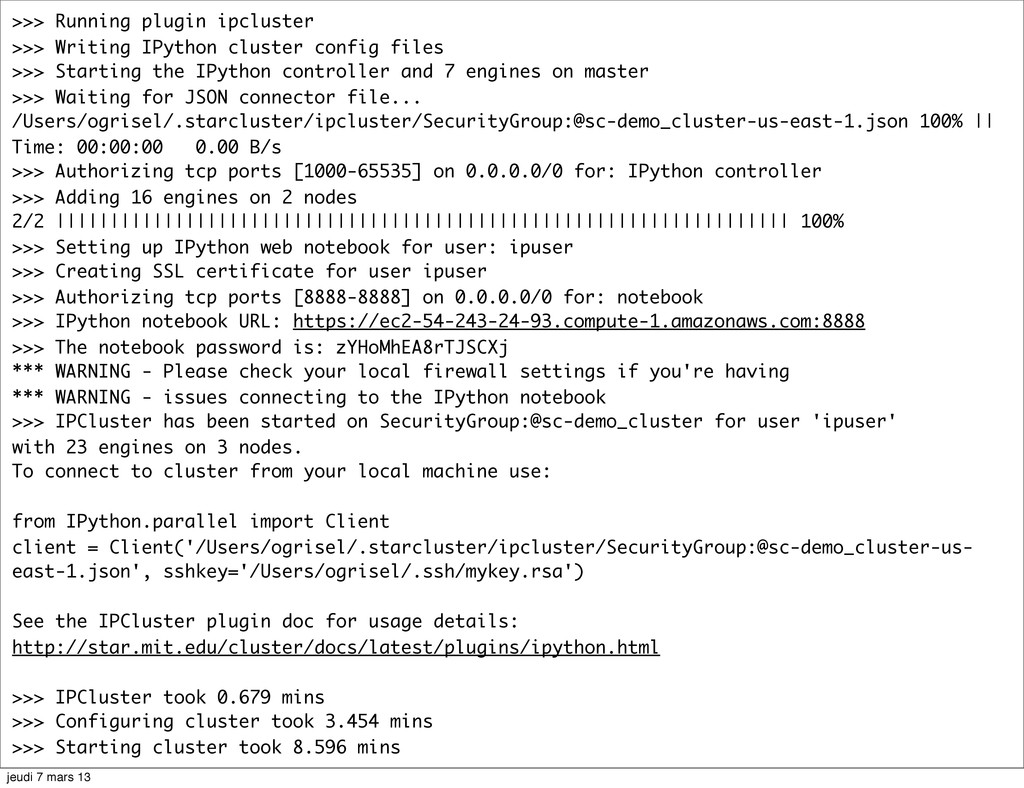
>>> Starting the IPython controller and 7 engines on master >>> Waiting for JSON connector file... /Users/ogrisel/.starcluster/ipcluster/SecurityGroup:@sc-demo_cluster-us-east-1.json 100% || Time: 00:00:00 0.00 B/s >>> Authorizing tcp ports [1000-65535] on 0.0.0.0/0 for: IPython controller >>> Adding 16 engines on 2 nodes 2/2 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 100% >>> Setting up IPython web notebook for user: ipuser >>> Creating SSL certificate for user ipuser >>> Authorizing tcp ports [8888-8888] on 0.0.0.0/0 for: notebook >>> IPython notebook URL: https://ec2-54-243-24-93.compute-1.amazonaws.com:8888 >>> The notebook password is: zYHoMhEA8rTJSCXj *** WARNING - Please check your local firewall settings if you're having *** WARNING - issues connecting to the IPython notebook >>> IPCluster has been started on SecurityGroup:@sc-demo_cluster for user 'ipuser' with 23 engines on 3 nodes. To connect to cluster from your local machine use: from IPython.parallel import Client client = Client('/Users/ogrisel/.starcluster/ipcluster/SecurityGroup:@sc-demo_cluster-us- east-1.json', sshkey='/Users/ogrisel/.ssh/mykey.rsa') See the IPCluster plugin doc for usage details: http://star.mit.edu/cluster/docs/latest/plugins/ipython.html >>> IPCluster took 0.679 mins >>> Configuring cluster took 3.454 mins >>> Starting cluster took 8.596 mins jeudi 7 mars 13
stuff to disk for failover Inefficient for small to medium problems [(k, v)] mapper [(k, v)] reducer [(k, v)] Data and model params as (k, v) pairs? Complex to leverage for Iterative Algorithms jeudi 7 mars 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
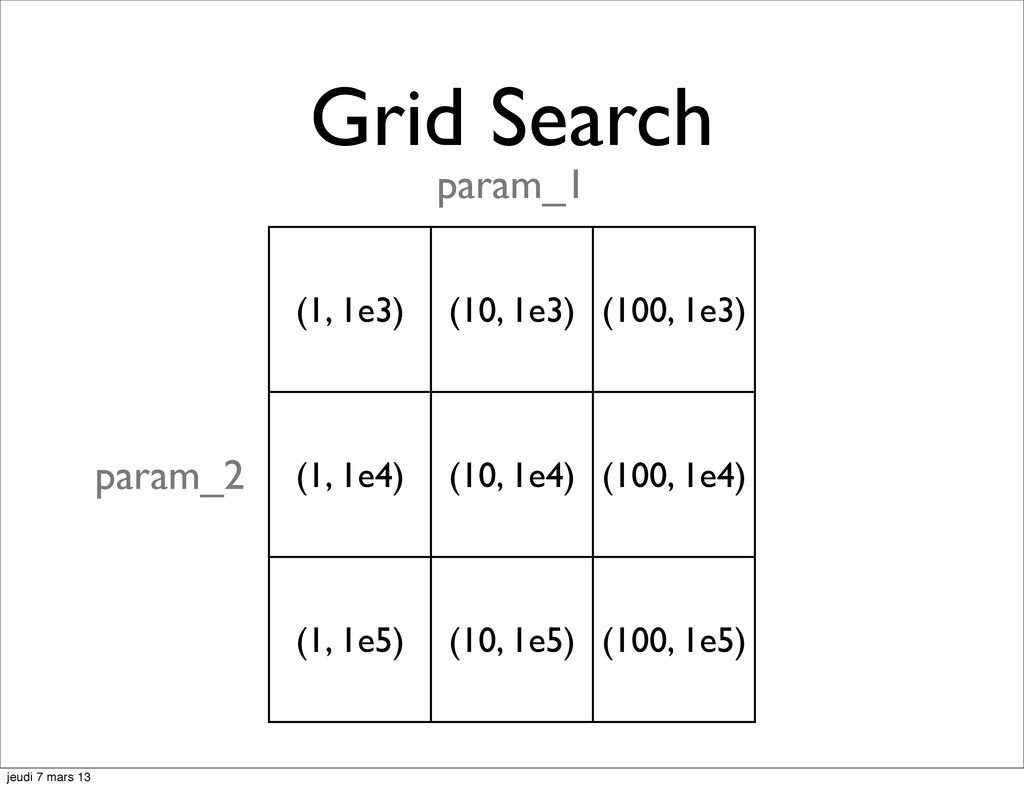
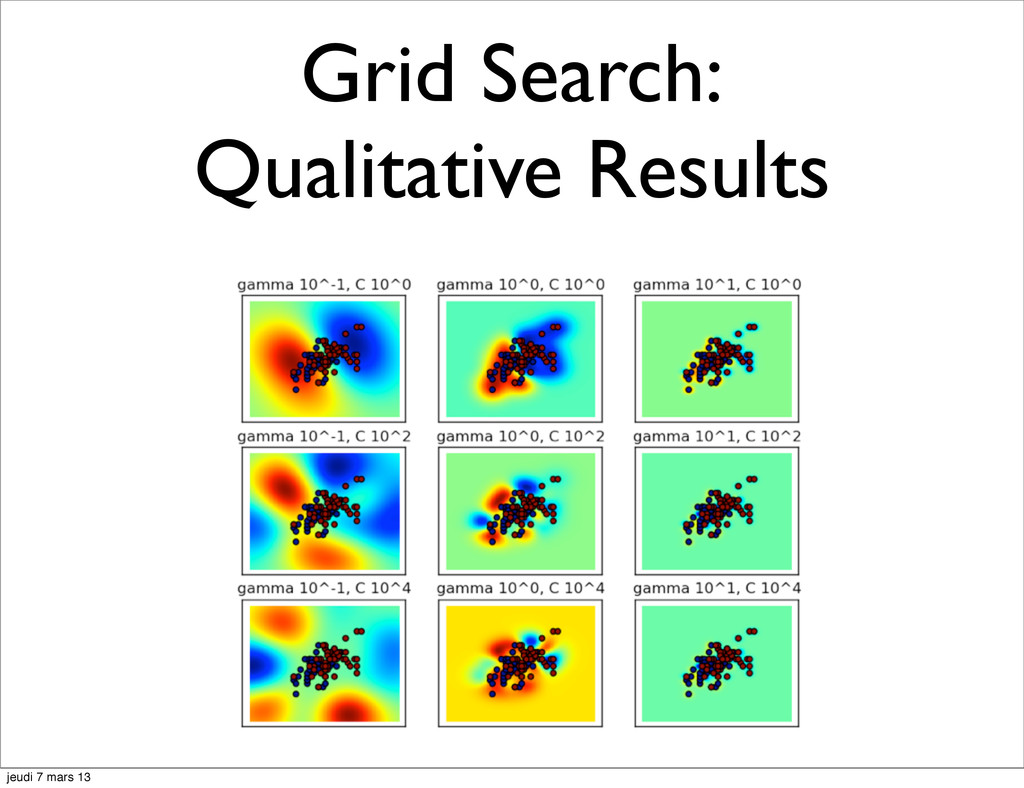
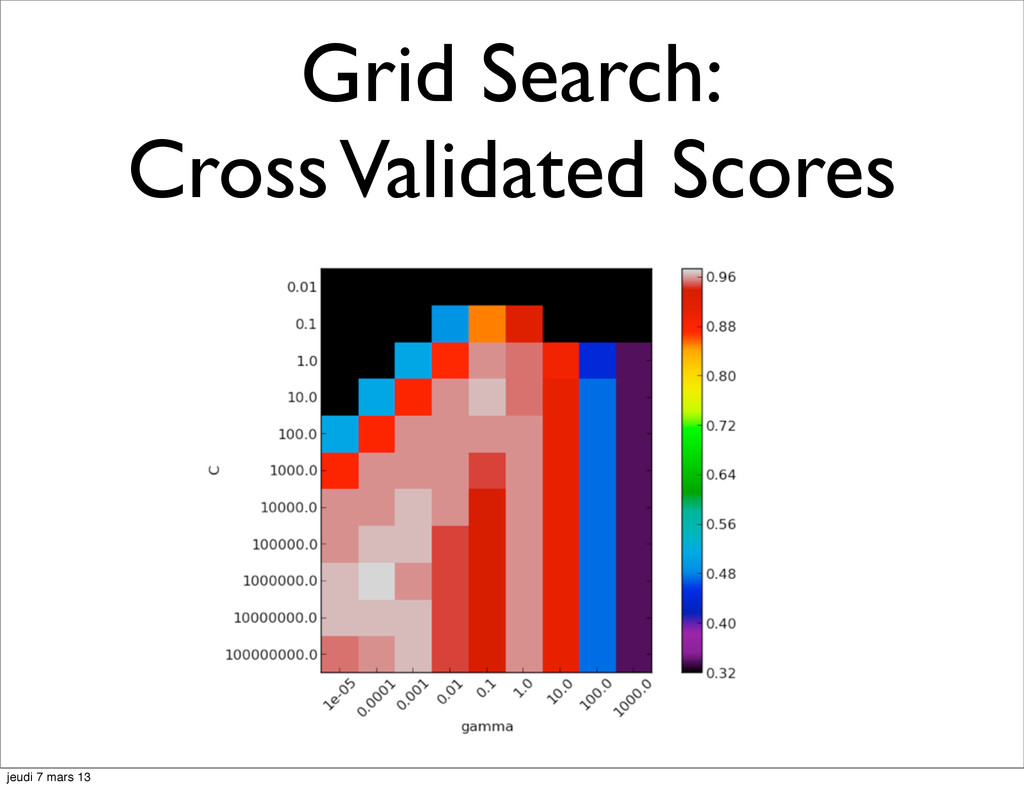
![Model Selection the Hyperparameters hell param_1 in [1, 10, 100]](https://files.speakerdeck.com/presentations/9c8f07b06ade0130866412313d1860bb/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[global] DEFAULT_TEMPLATE=ip [key mykey] KEY_LOCATION=~/.ssh/mykey.rsa [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/9c8f07b06ade0130866412313d1860bb/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
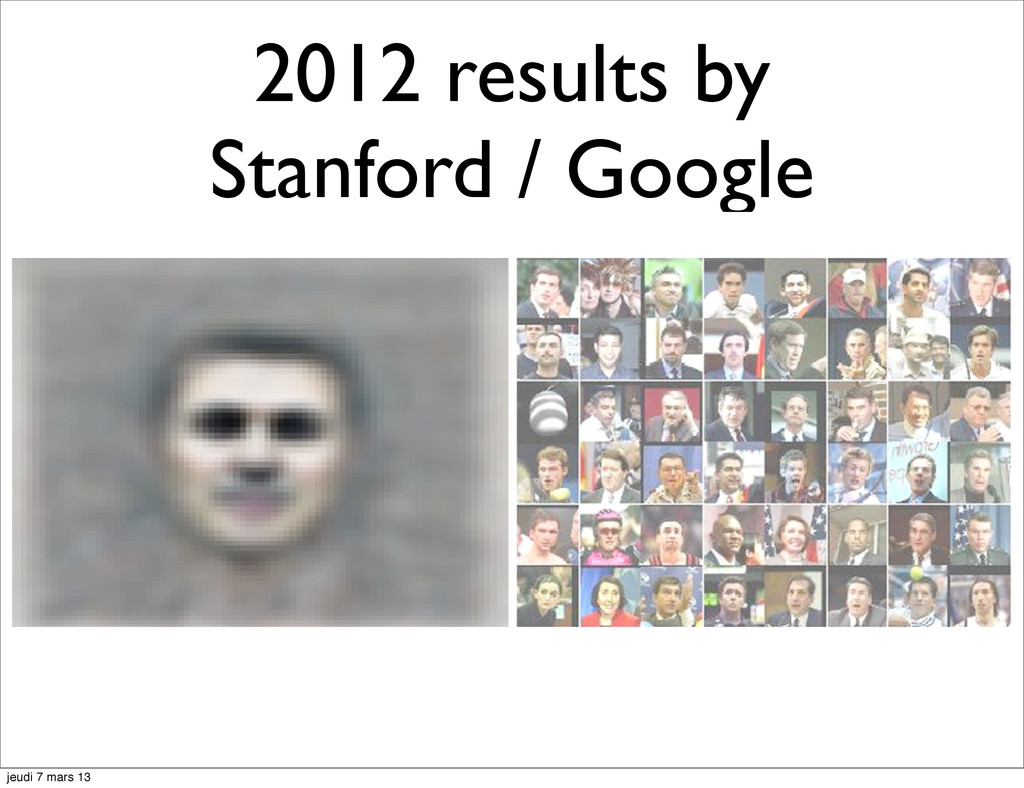{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce? [ (k1, v1), (k2, v2), ... ] mapper mapper](https://files.speakerdeck.com/presentations/9c8f07b06ade0130866412313d1860bb/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
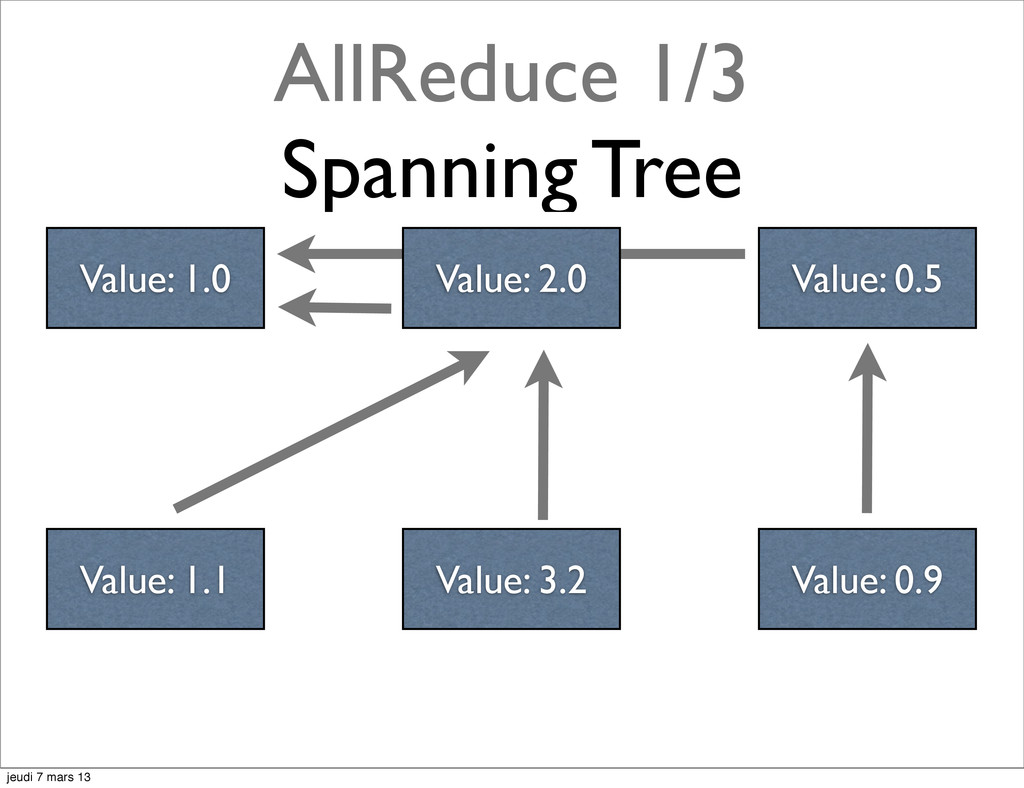{kind=link}
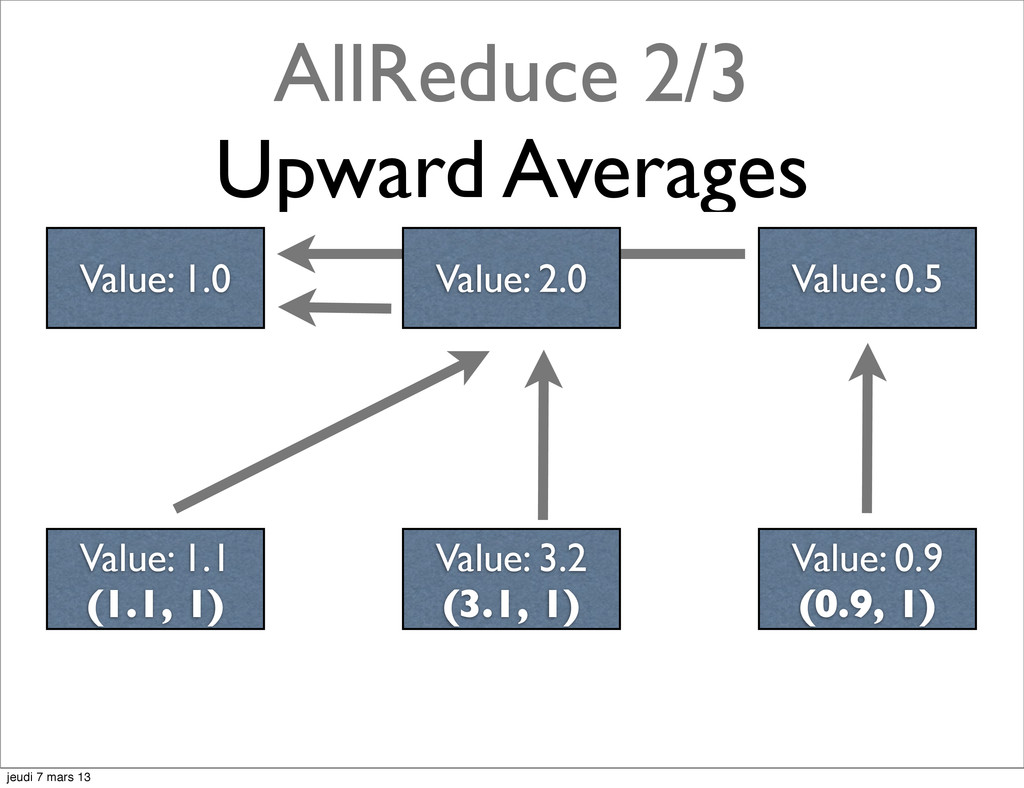{kind=link}
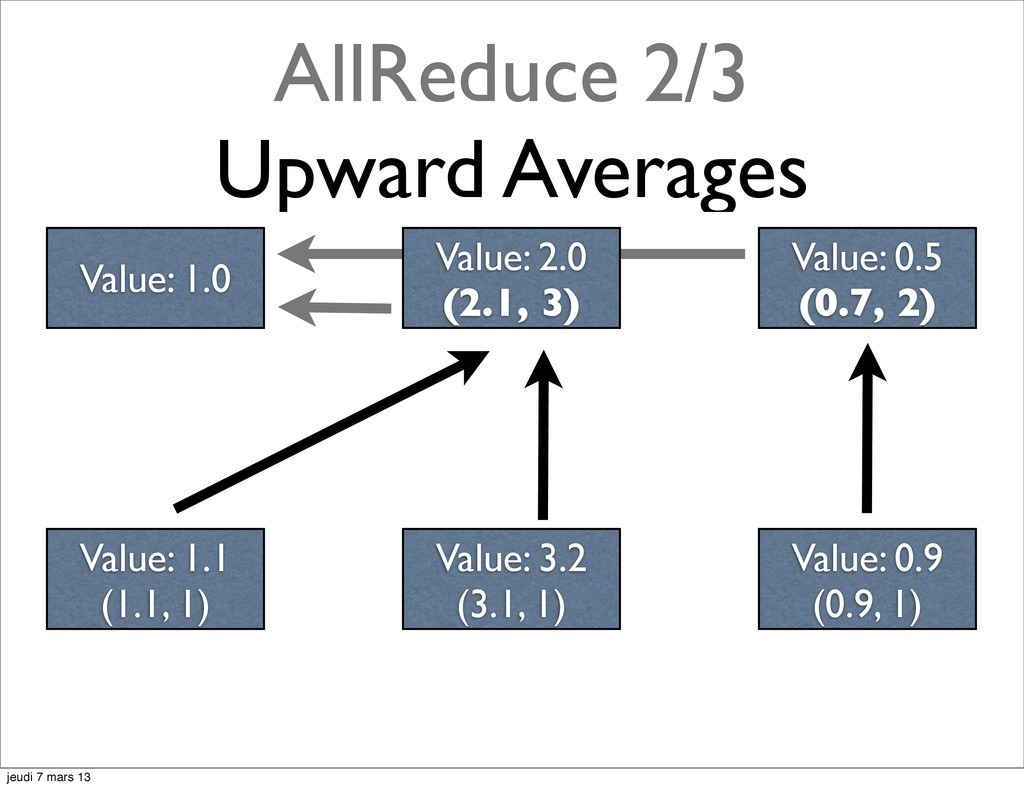{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Killall IPython engines on StarCluster [plugin ipcluster] SETUP_CLASS = starcluster.plugins.ipcluster.IPCluster](https://files.speakerdeck.com/presentations/9c8f07b06ade0130866412313d1860bb/slide_86.jpg){kind=link}
{kind=link}