soTware project grows as the square of the number of engineers and Leveson [17] cites evidence that most failures in complex systems result from unexpected inter-‐component interac@on rather than intra-‐component bugs, we conclude that less machinery is (quadra@cally) beYer.” hYp://lab.mscs.mu.edu/Dist2012/lectures/HarvestYield.pdf
hYp://zookeeper.apache.org/ hYp://[email protected]/ hYp://www.acunu.com/acunu-‐[email protected] hYps://github.com/bitly/nsq hYps://github.com/davegardnerisme/cruTflake hYps://github.com/davegardnerisme/nsqphp Plus a load of other things I’ve not men@oned.
Systems hYps://github.com/Neslix/Hystrix Timelike: a network simulator hYp://aphyr.com/posts/277-‐@melike-‐a-‐network-‐simulator Notes on distributed systems for young bloods hYp://www.somethingsimilar.com/2013/01/14/notes-‐on-‐distributed-‐ systems-‐for-‐young-‐bloods/ Stream de-‐duplica@on (relevant to NSQ) hYp://www.davegardner.me.uk/blog/2012/11/06/stream-‐de-‐ duplica@on/ ID genera@on in distributed systems hYp://www.slideshare.net/davegardnerisme/unique-‐id-‐genera@on-‐in-‐ distributed-‐systems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
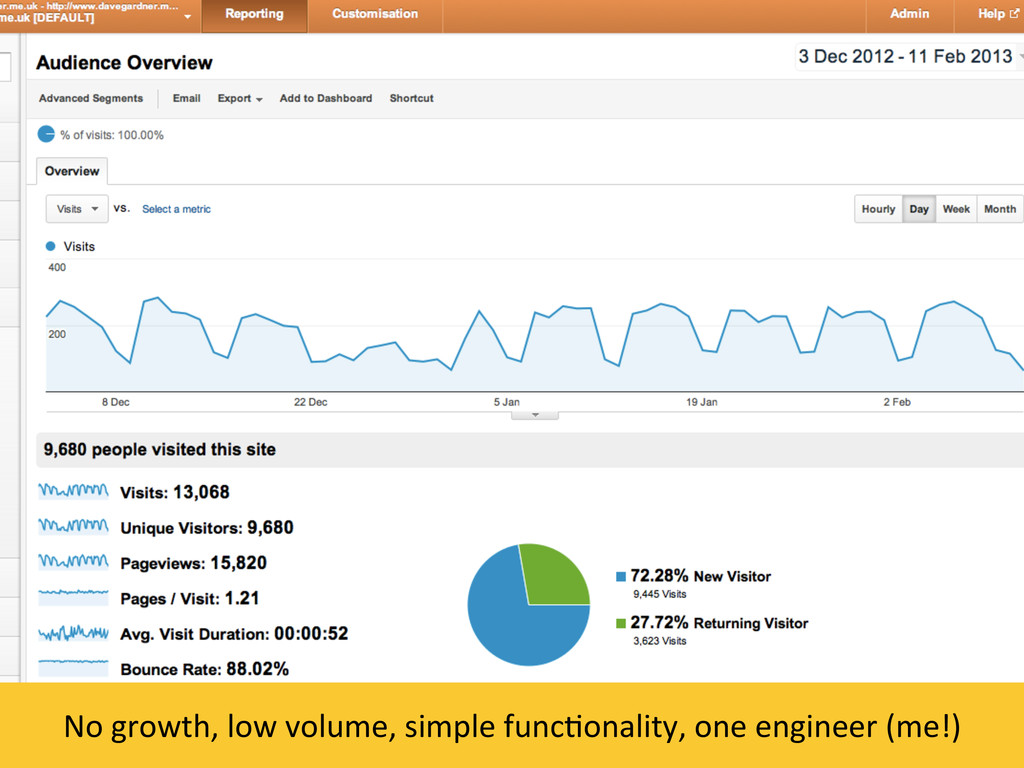{kind=link}
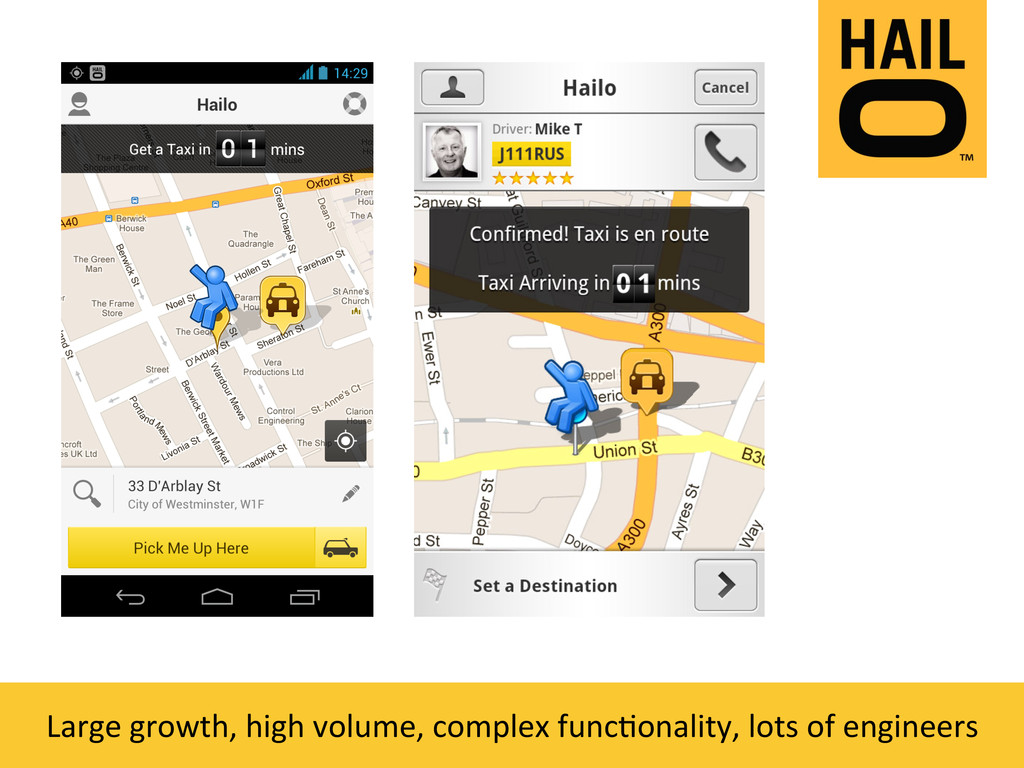{kind=link}
{kind=link}
![“.. Brooks [1] reveals that the complexity of a](https://files.speakerdeck.com/presentations/0e605c10600701305d5622000a9f016b/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
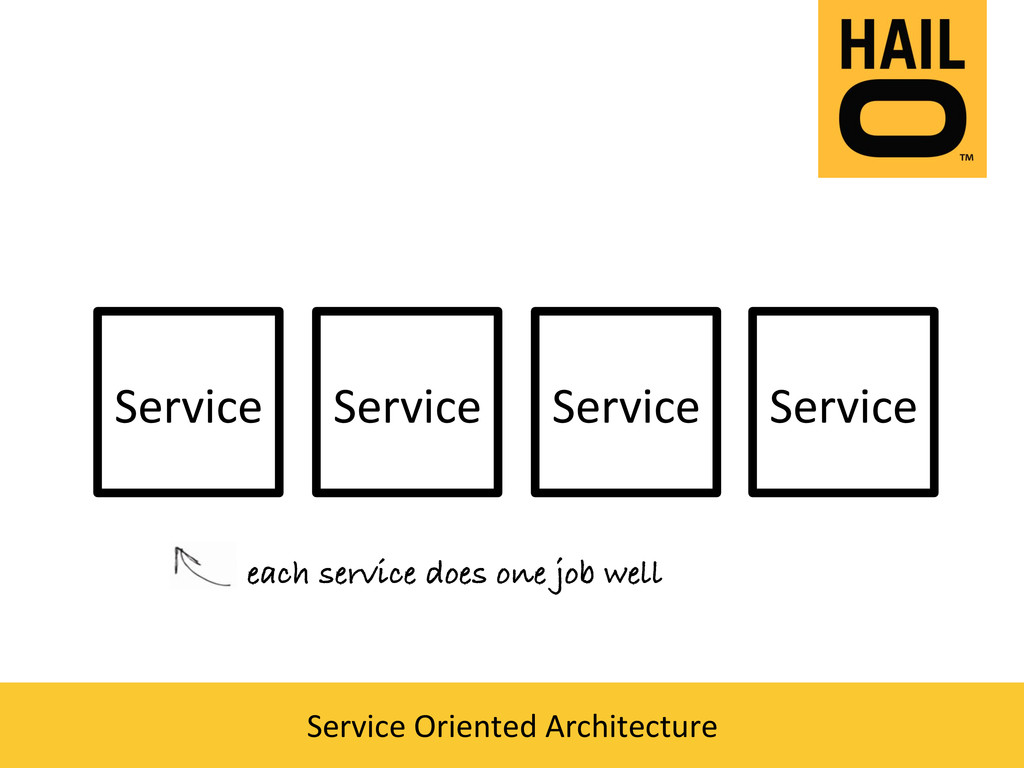{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}