These slides outline (at a high level) the research we've accomplished at Agile Medicine to determine a best case minimum viable solution for quick and easy genomic data management.
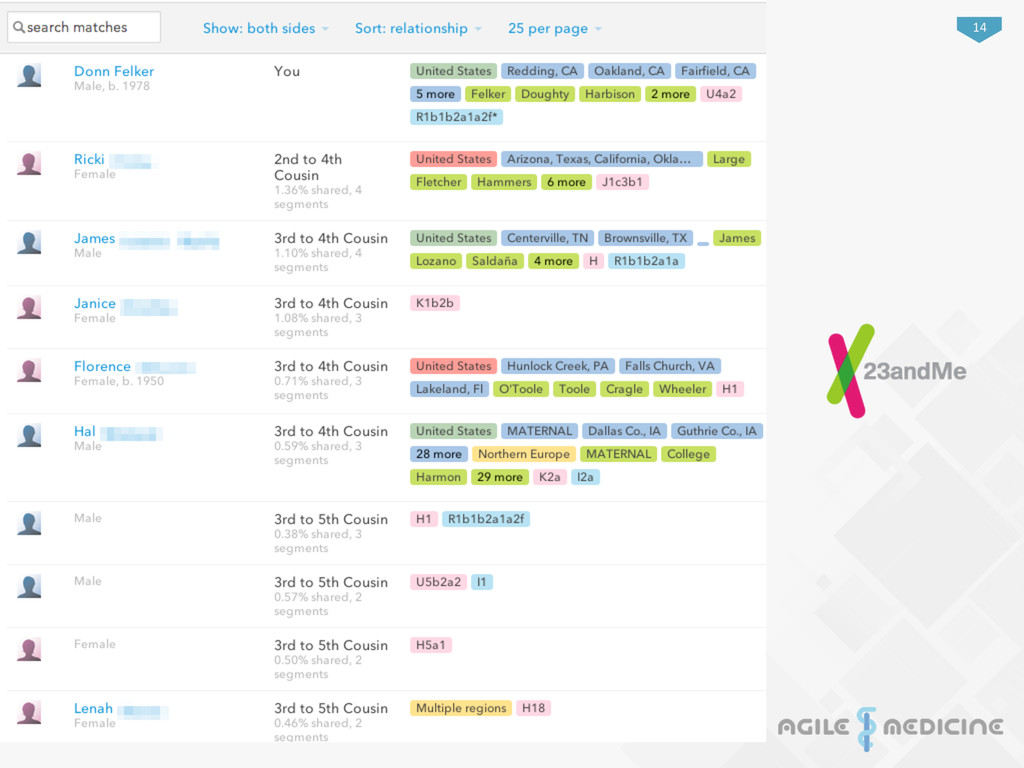
make new cells, exis:ng cells divide in two. Before dividing the DNA of a cell is copied. During that copying process some:mes mistakes are made -‐ kind of like typos. These mistakes lead to varia:ons in the DNA sequence at par:cular loca:ons called Single Nucleo:de Polymorphisms or SNPs (pronounced “snips”). SNPs are Copying Errors SNPs can generate biological varia:on between people by causing differences in the recipes for proteins that are wriTen in genes. Those differences can in turn influence a variety of traits such as appearance, disease suscep:bility or response to drugs. While some SNPs lead to differences in health or physical appearance, most SNPs seem to lead to no observable differences between people at all. Consequence of SNPs DNA is passed from parent to child, so you inherit your SNPs versions from your parents. You will be a match with your siblings, grandparents, aunts, uncles, and cousins at many of these SNPs. But you will have far fewer matches with people to whom you are only distantly related. The number of SNPs where you match another person can therefore be used to tell how closely related you are. SNPs as a Measure of Genetic Similarity
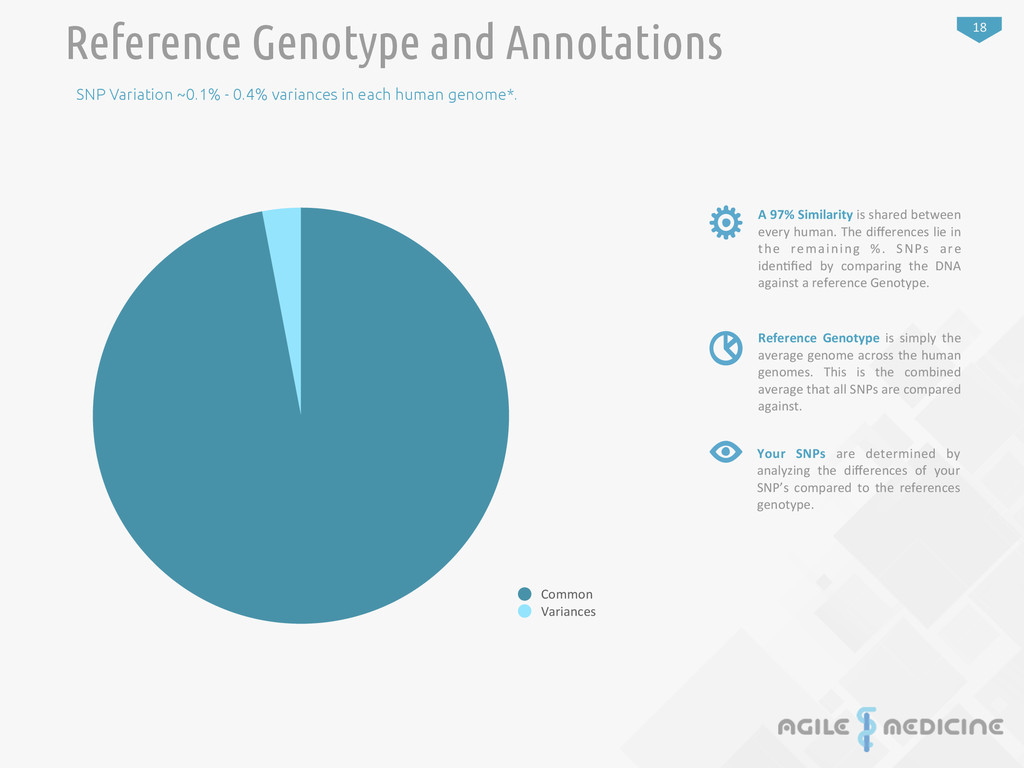
variances in each human genome*. Common Variances A 97% Similarity is shared between every human. The differences lie in the remaining %. SNPs are iden:fied by comparing the DNA against a reference Genotype. Reference Genotype is simply the average genome across the human genomes. This is the combined average that all SNPs are compared against. Your SNPs are determined by analyzing the differences of your SNP’s compared to the references genotype.
individual datasets MySQL Rela1onal Database 23479827349857920347502345 2342769782309809-‐84507860983456 45249580980984958609830945 987879423589087782789298498924 D N A ... HUGE DATASETS Person A
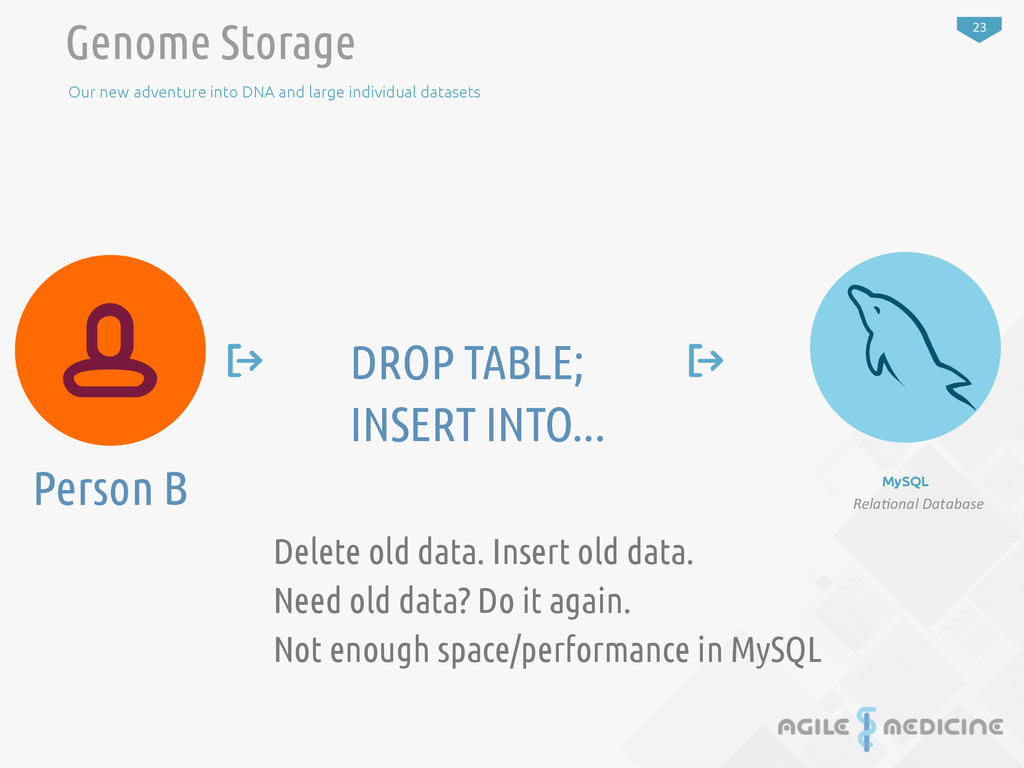
individual datasets MySQL Rela1onal Database DROP TABLE; INSERT INTO... Person B Delete old data. Insert old data. Need old data? Do it again. Not enough space/performance in MySQL
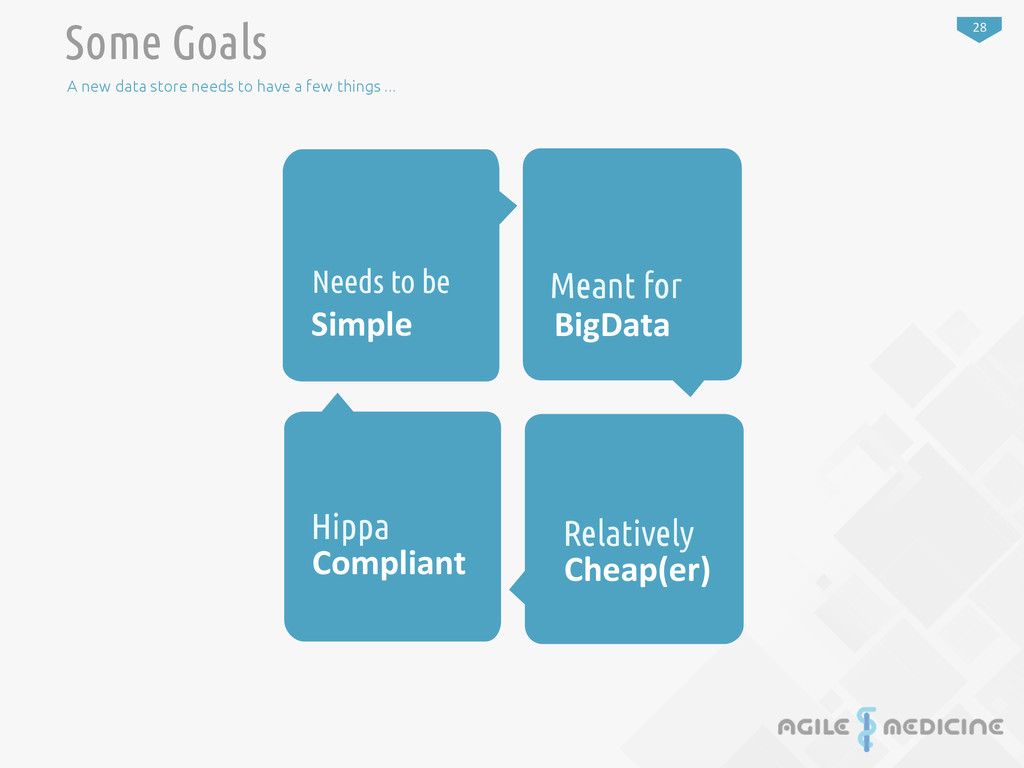
Goals: Speed Cost. Flexibility. Tooling. Genome data has a tendency to change schema quite o_en due to new discoveries. Changes should be easy to implement and should not require a rebuild of the en:re datastore. Adapts to Change Inser:ng data should be fast. VERY FAST. Genotype data is quite large for each person and inser:ng data and querying for data should be quick. Query/Indexing The primary use case of this is for research and academia. Time is valuable and is normally spent focused on researching the medical issue at hand and not implemen:ng technical solu:ons around the datastore. The datastore is a TOOL, not the solu:on and it should help facilitate solving the issue, not become the issue. A Tool for Research Tradi:onally this type of research was done on university super computers with massive processing power. Unfortunately these machines require advanced reserva:ons and cost a lot to maintain. Future research should not be held up by wai:ng for the university super computer and should be cheap to operate. Cheaper to Operate
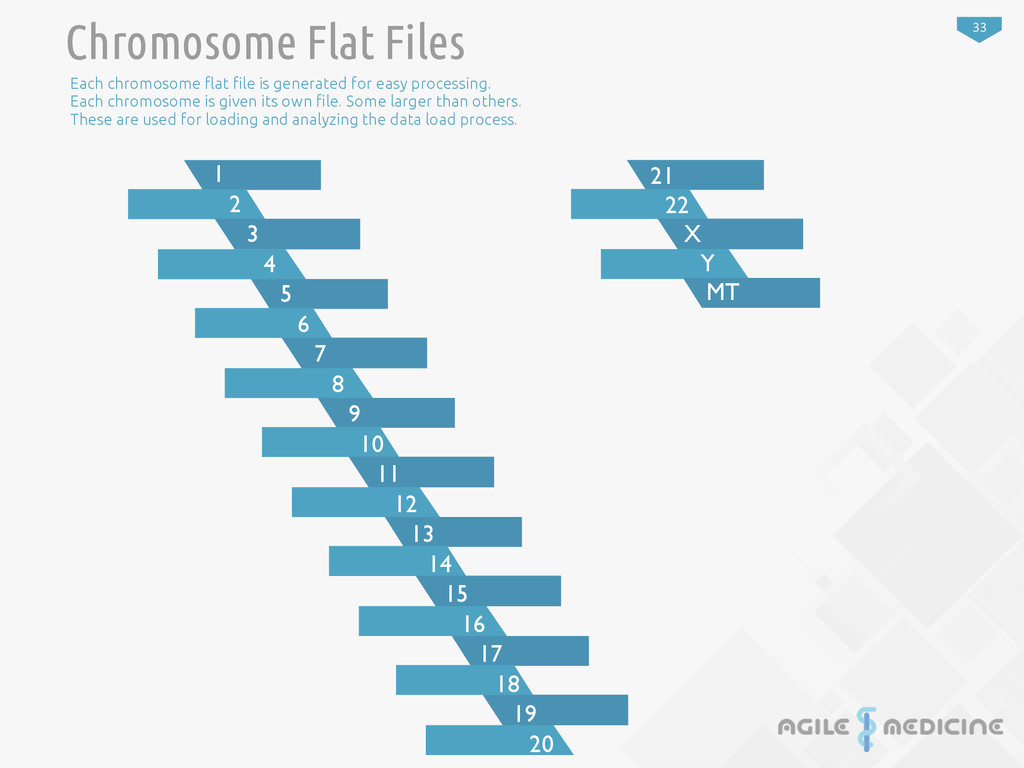
10 11 12 13 14 15 16 17 18 19 20 21 22 X Y MT Chromosome Flat Files Each chromosome !at "le is generated for easy processing. Each chromosome is given its own "le. Some larger than others. These are used for loading and analyzing the data load process.
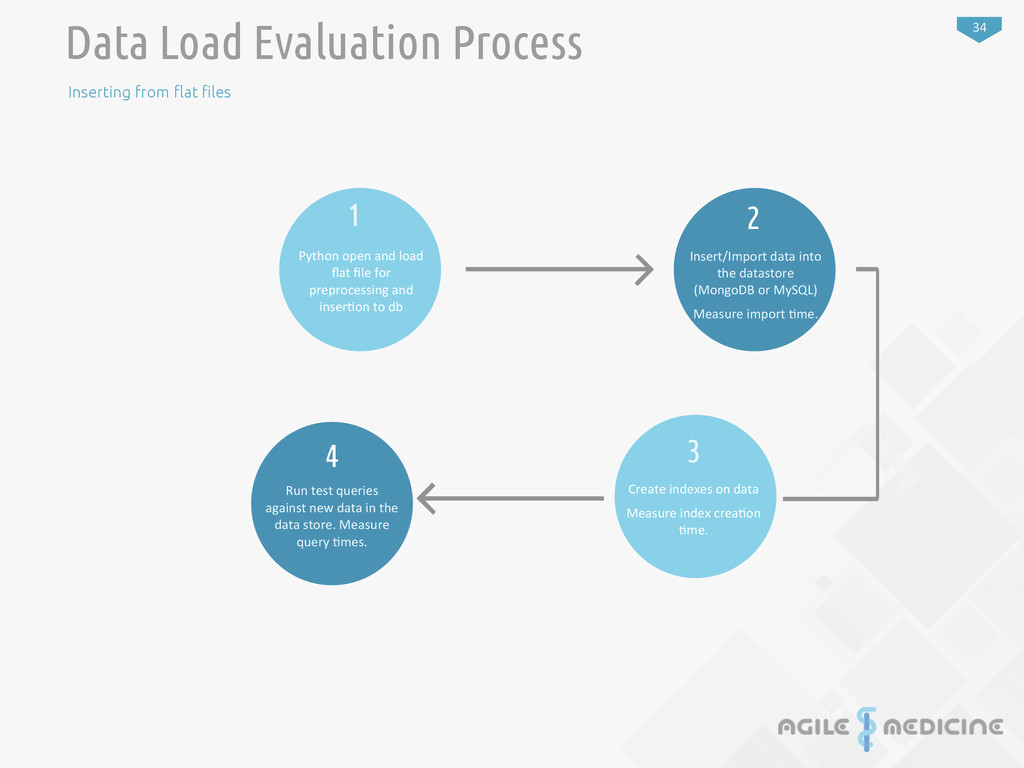
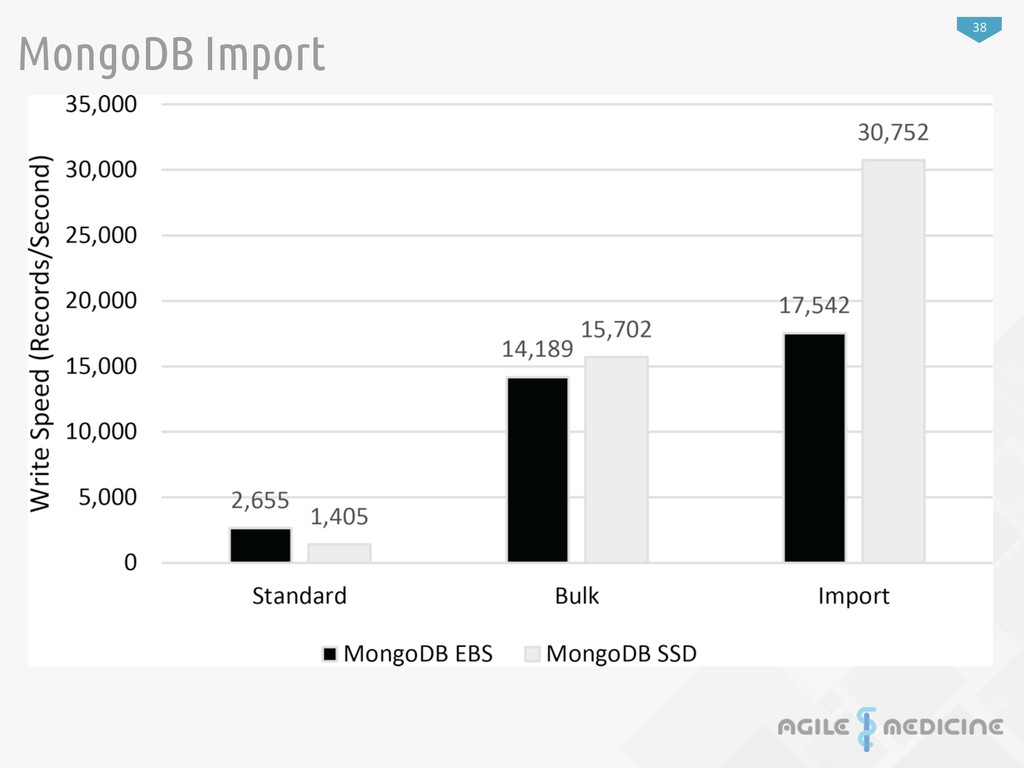
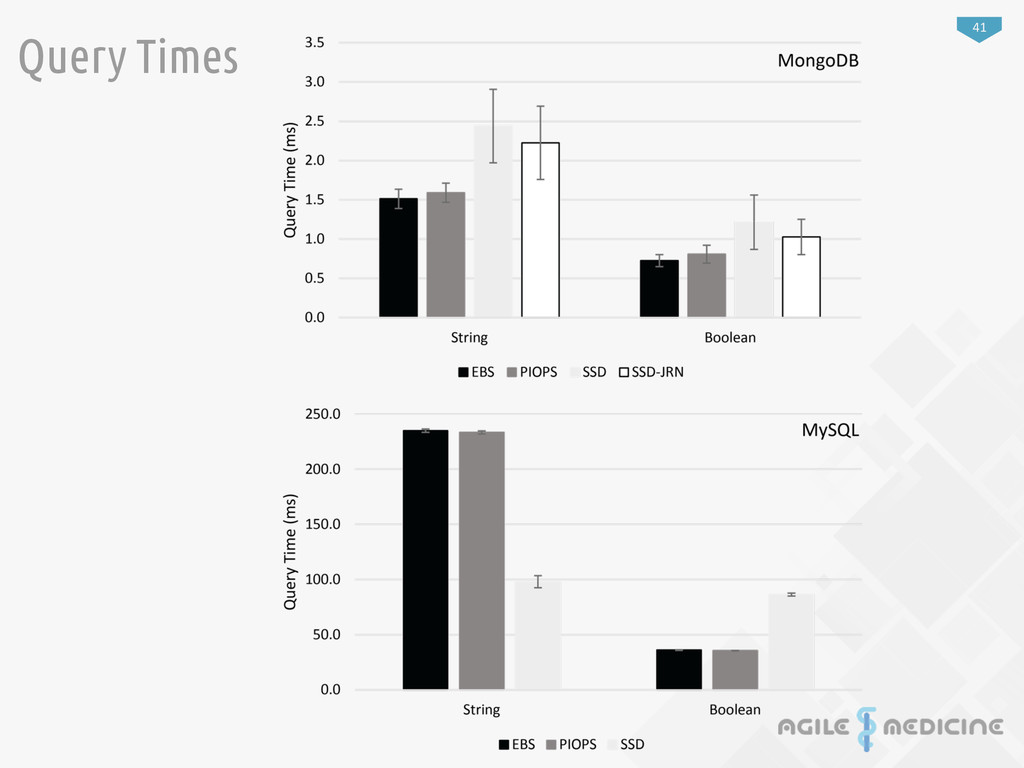
preprocessing and inser:on to db 2 Insert/Import data into the datastore (MongoDB or MySQL) Measure import :me. 4 Run test queries against new data in the data store. Measure query :mes. 3 Create indexes on data Measure index crea:on :me. Data Load Evaluation Process Inserting from !at "les
source (!at "les/etc) and FK relationships would have to be created and run in order to properly. Other ways? Yes... but ... Outside of mysqlimport and disabling fk checks we were limited to importing the "rst "le and then keeping the keys in memory and then inserting the second table/etc. Complex data in !at "les = complex problems importing into Relational stores.
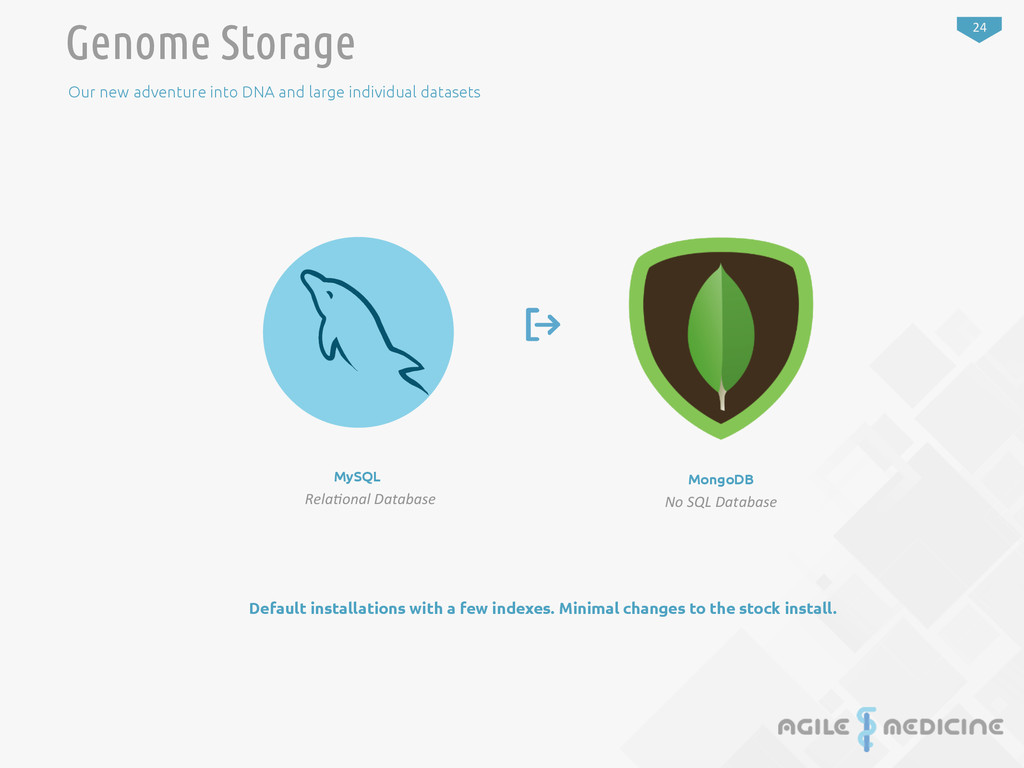
set of data but no where near the size of data that Mongo is meant to hold out of the box. Being able to keep the addi:onal data easily available makes research and re-‐analysis of genome data easier. Genome schema changes are frequent and require tooling that can adapt to change. A schema-‐less system is a perfect fit for genomic data. Adding and removing documents is built into the system. This is much more difficult with tradi:onal rela:onal stores. MongoDB is built to be controlled with JavaScript. Many high performance applica:ons are being built with JavaScript. Younger researchers are much more likely to be familiar with the language. Scale & Growth Adapts to Change Research Programming
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![45 Thank You @donnfelker donnfelker.com [email protected]](https://files.speakerdeck.com/presentations/179d32009c9e0131cbab526b40603ada/slide_44.jpg){kind=link}