interagir • Processo manual para definição de secrets • 3 a 5 interações dependendo do aplicativo ◦ Git, pipelines, Jira • Alguns repos/pipelines necessitavam de aprovação • Tempos para rollout com a plataforma escalada • Tempo de resposta durante o scaling em momentos de pico ◦ Tempo de inicialização da app ▪ Principalmente o tempo da AWS ◦ Regras de scaling agressivas para tentar contornar o tempo de inicialização ▪ 30% de uso de CPU ▪ $$$ • Não é rápido o suficiente Principais dificuldades:
Um namespace por aplicação • Escolha da família de ec2 para nodes (m5.xlarge) • Limite do número de nodes por cluster (100) • Aplicações stateful não seriam migradas • Utilização de backends de disco diferentes do EBS não suportadas Premissas e definições:
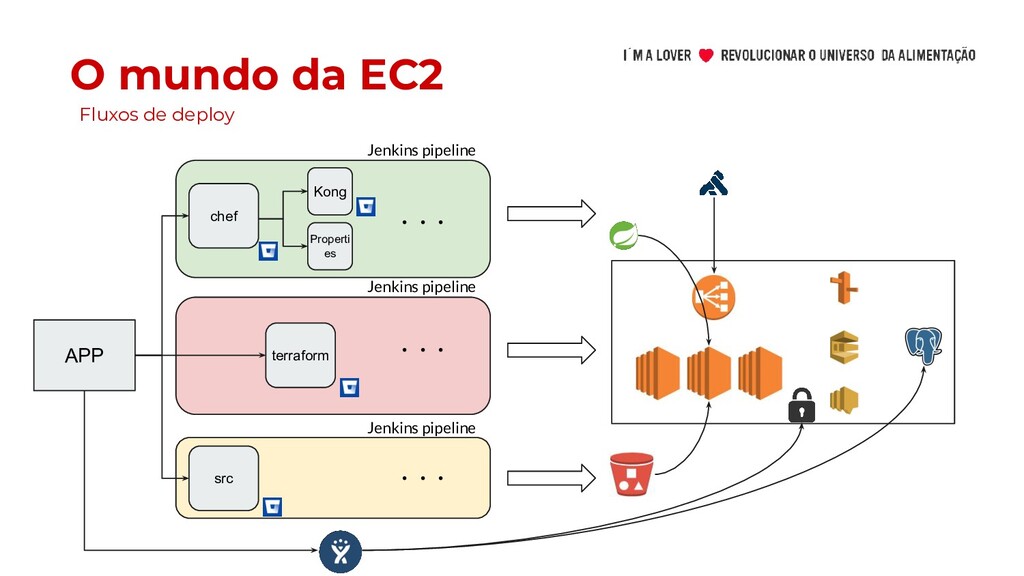
cluster • Foco em (no mínimo) igualar as funcionalidades de EC2 ◦ Logs ◦ Scaling ◦ Monitoria ◦ Secrets ◦ Estratégias de Deployment ◦ Interação pela Kubernetes Dashboards e kubectl • Declarado freeze da antiga stack A primeira fase:
• Imutabilidade das aplicações • Health checks e Liveness Probes • Monitoria individual de métricas por app Ferramentas e abstrações para migração: • Pipelines • Aplicação de manifestos K8S • Acessos a app por LoadBalancer • Grafana Dashboards para métricas e indicadores Igual mas diferente:
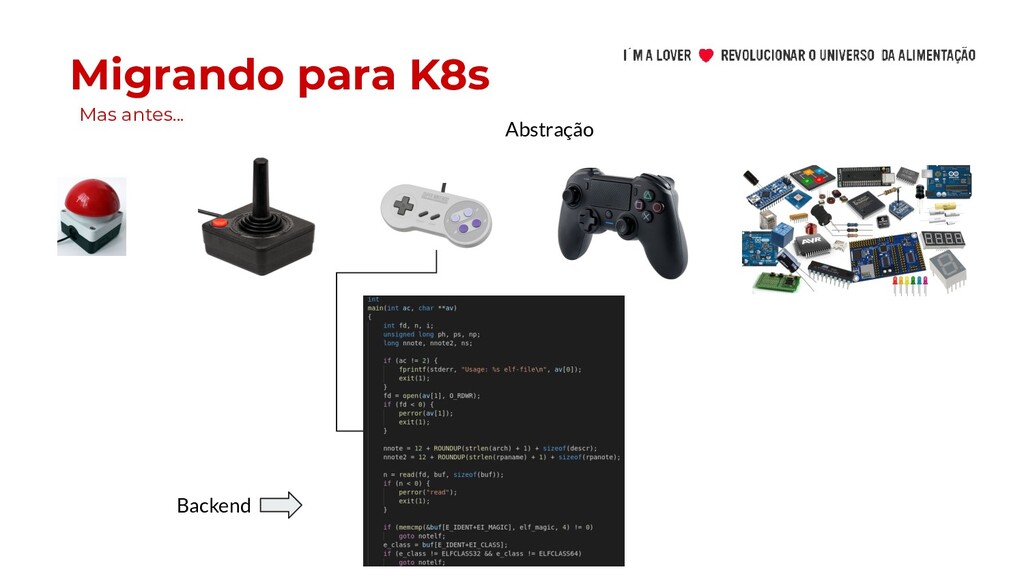
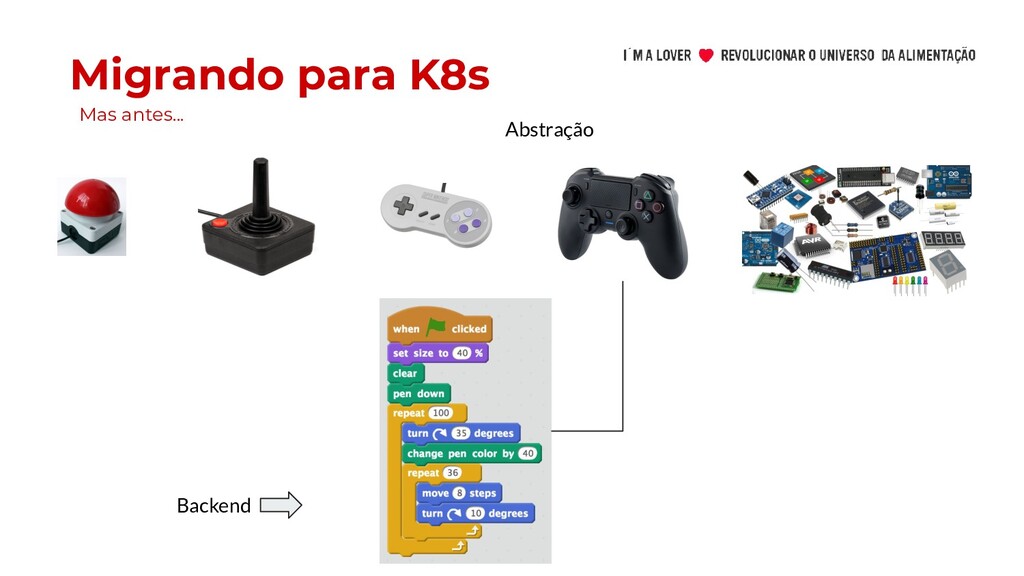
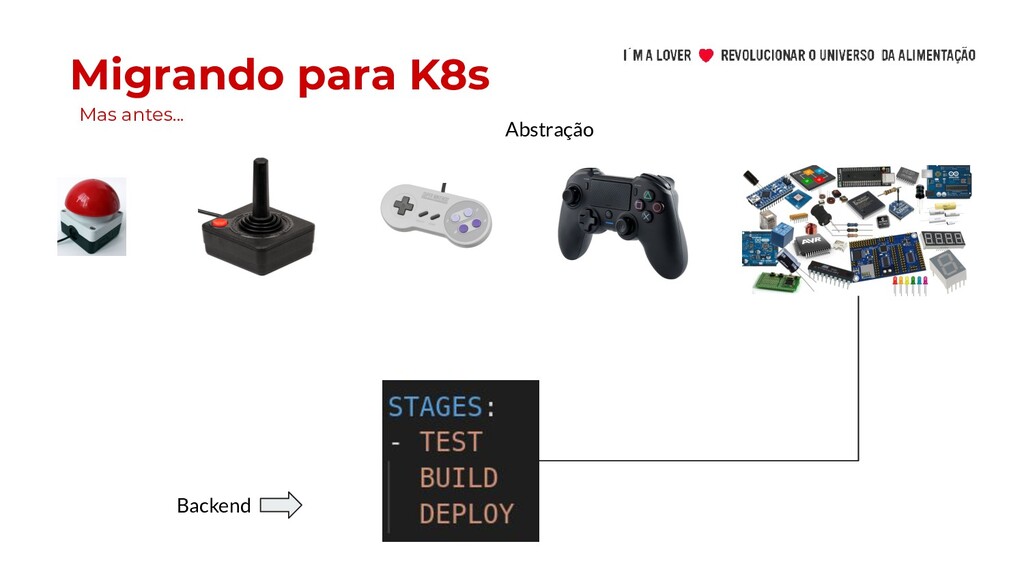
metrô) • Pouco conhecimento de Docker • Imagens docker gigantes • Dimensionamento de recursos • Métricas e Escalabilidade Horizontal • Liveness Probe e Readiness Probe • Tempo de subida das aplicações • Escalabilidade de Banco de dados • ConfigMaps vs arquivo de propriedades • Muitos “Lift and Shift” • Falsa ideia que K8S implementa 12 factors por você. Os benefícios chamaram a atenção de muitos, mas…
conhecimento de Docker • Imagens docker gigantes • Dimensionamento de recursos • Métricas e Escalabilidade Horizontal • Liveness Probe e Readiness Probe • Tempo de subida das aplicações • Escalabilidade de Banco de dados • ConfigMaps vs arquivo de propriedades • Muitos “Lift and Shift” • Falsa ideia que K8S implementa 12 factors por você. Os benefícios chamaram a atenção de muitos, mas… Migrando para K8s
• Falta de padronização • Explosão de Load Balancers • Falta de rotinas para warmup • Gerenciamento de Secrets muito ruim • Quedas do sistema de monitoria • Sistemas requerendo hardware diferenciado • Muitas interações necessárias com o time de SRE Problemas começaram a surgir:
Abstração e transparências ◦ Simplificação ◦ Padronização ◦ Rotinas agendadas de warmup ◦ Geração de releases ◦ Lifecycle da Chart • um exemplo… .1.16 A segunda fase:
métricas ◦ Canary, AB e outras transformações de camada 7 • Vault ◦ Autonomia para Devs ◦ Versionamento de Secrets ◦ Ingestão automática nos PODs ◦ Integração com Services Accounts ◦ Granularidade de acessos A segunda fase:
Infra ▪ Maior estabilidade dos componentes de infra ▪ Flexibilidade de updates ◦ High Demand ▪ Perfis de aplicação CPU,Memory ou Network bound • Sharding de Prometheus ◦ Maior disponibilidade de métricas e alarmes essenciais • External DNS ◦ Menos interação com Terraform A segunda fase:
aplicações são inevitáveis • Implemente padrões o quanto antes • Ache o equilíbrio entre abstração e flexibilidade (perfil do time) • Estude sistemas distribuídos • Decida quais tipos de apps vão ou não para o K8S • Crie versões e lifecycle para toda nova fase ou tecnologia implantada Resumo Lições aprendidas:
auth e separação de namespaces • Observabilidade ◦ Service Mesh (Istio) • Resiliência do sistema de métricas e monitoria ◦ Cortex • Camada de validações de governança e segurança ◦ OPA Novos desafios e necessidades:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}