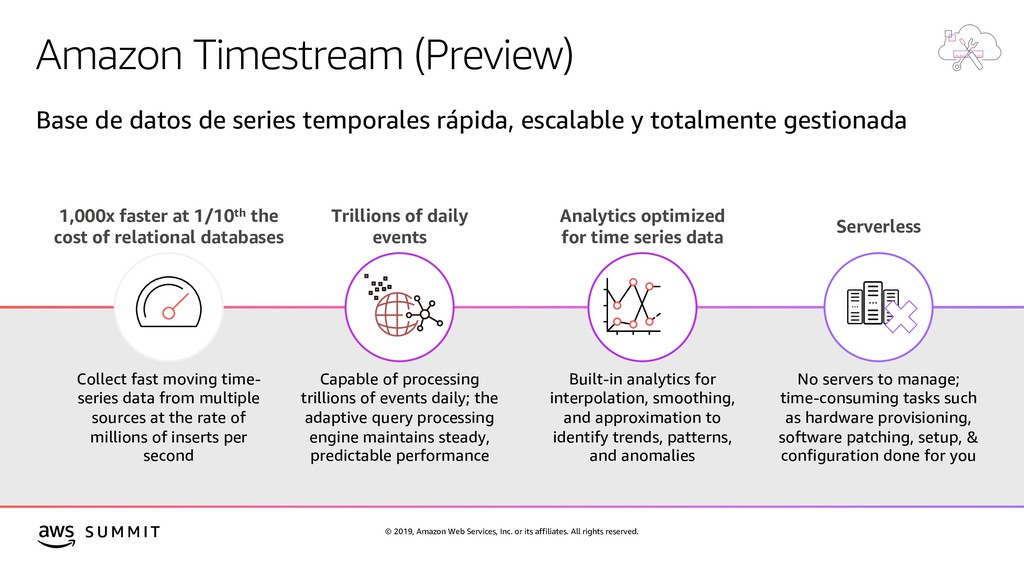
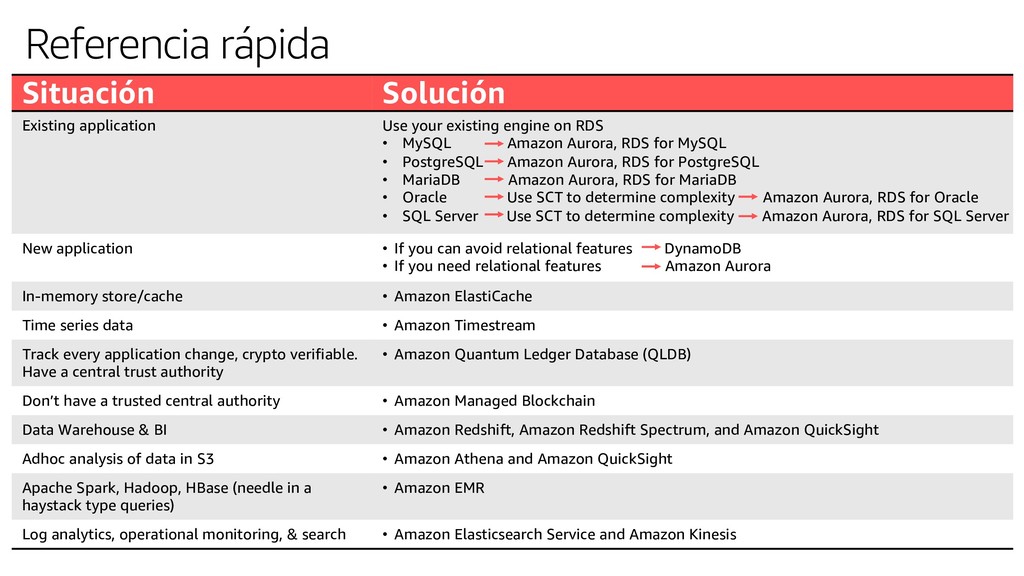
rights reserved. S U M M I T Modelos de datos híbridos Relational Referential integrity, ACID transactions, schema- on-write Lift and shift, ERP, CRM, finance Key-value High throughput, low- latency reads and writes, endless scale Real-time bidding, shopping cart, social, product catalog, customer preferences Document Store documents and quickly access querying on any attribute Content management, personalization, mobile In-memory Query by key with microsecond latency Leaderboards, real-time analytics, caching Graph Quickly and easily create and navigate relationships between data Fraud detection, social networking, recommendation engine Time-series Collect, store, and process data sequenced by time IoT applications, event tracking Ledger Complete, immutable, and verifiable history of all changes to application data Systems of record, supply chain, health care, registrations, financial
{kind=link}
{kind=link}
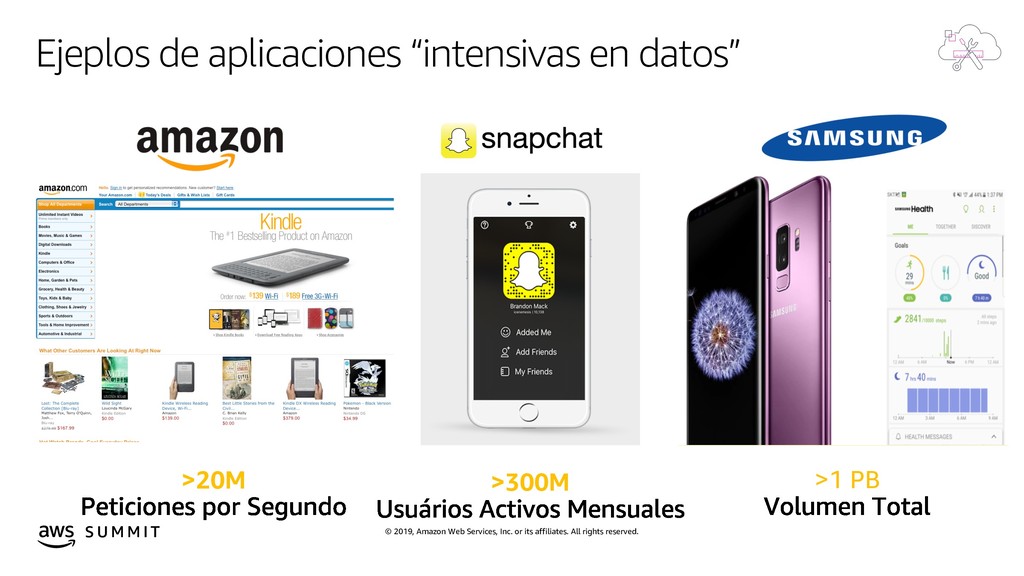{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
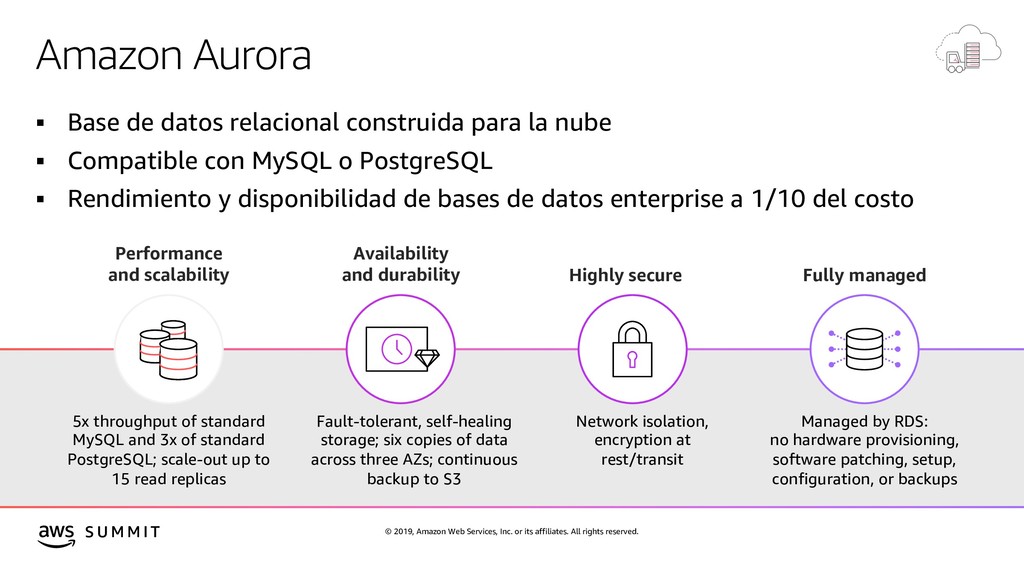{kind=link}
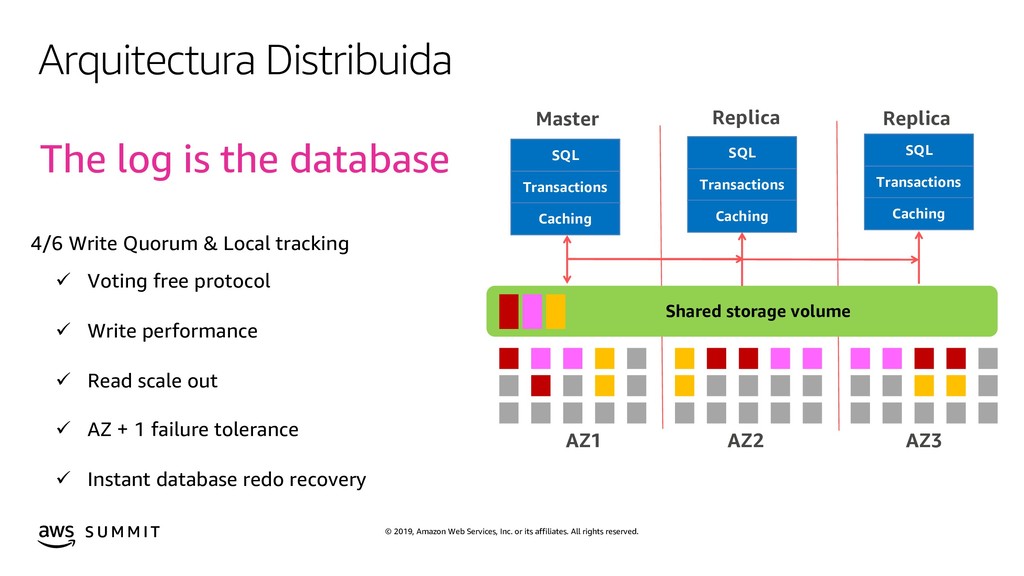{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}