+ 𝑇𝑟(𝐾𝑇𝑅𝐾Σ Annual Review of Control, Robotics , and AutonomousSys tems Toward aT heoretical Foundation of Policy Optimization for Learning Control Policies Bin Hu,1 Kaiqing Zhang,2,3 Na Li,4 Mehran Mesbahi,5 Maryam Fazel,6 and Tamer Ba¸ sar1 1Coordinated Science Laboratory and Department of Electrical and Computer Engineering, University of Illinois Urbana-Champaign, Urbana, Illinois, USA; email: binhu7@ illinois.edu, basar1@ illinois.edu 2Laboratory for Information and Decision Systems and Computer Science and Artif cial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, Massachusetts, USA 3Current aff liation: Department of Electrical and Computer Engineering and Institute for Systems Research, University of Maryland, College Park, Maryland, USA; email: kaiqing@ umd.edu 4School of Engineering and Applied Sciences, Harvard University, Cambridge, Massachusetts, USA; email: nali@ seas.harvard.edu 5Department of Aeronautics and Astronautics, University of Washington, Seattle, Washington, USA; email: mesbahi@ uw.edu 6Department of Electrical and Computer Engineering, University of Washington, Seattle, Washington, USA; email: mfazel@ uw.edu Annu. Rev. Control Robot. Auton. Syst. 2023. 6:123–58 T he Annual Review of Control, Robotics , and AutonomousSystemsisonline at control.annualreviews.org https://doi.org/10.1146/annurev-control-042920- 020021 Copyright © 2023 by the author(s). T his work is licensed under aCreative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. See credit lines of images or other third-party material in this article for license information. Keywords policy optimization, reinforcement learning, feedback control synthesis Abstract Gradient-based methodshave been widely used for system design and opti- mization in diverse application domains. Recently, there hasbeen arenewed interest in studying theoretical propertiesof thesemethodsin thecontext of control and reinforcement learning. T hisarticle surveyssome of the recent developments on policy optimization, a gradient-based iterative approach for feedback control synthesis that hasbeen popularized by successesof re- inforcement learning. We take an interdisciplinary perspective in our expo- sition that connects control theory, reinforcement learning, and large-scale Fact: For initial 𝐾0 stabilizing & small 𝜂, gradient descent 𝐾+ = 𝐾 − 𝜂 ∇𝐽 𝐾 converges linearly to 𝐾∗. where Σ = 𝐼 + 𝐴 + 𝐵𝐾 Σ 𝐴 + 𝐵𝐾 𝑇 Algorithm: model-based adaptive control via policy gradient 1. data collection: refresh (𝑋0 , 𝑈0 , 𝑋1 ) 2. identification of 𝐵, መ 𝐴 via recursive LS 3. policy gradient: 𝐾+ = 𝐾 − 𝜂 ∇𝐽 𝐾 using estimates 𝐵, መ 𝐴 & closed-loop Gramians Σ, 𝑃 actuate & repeat 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
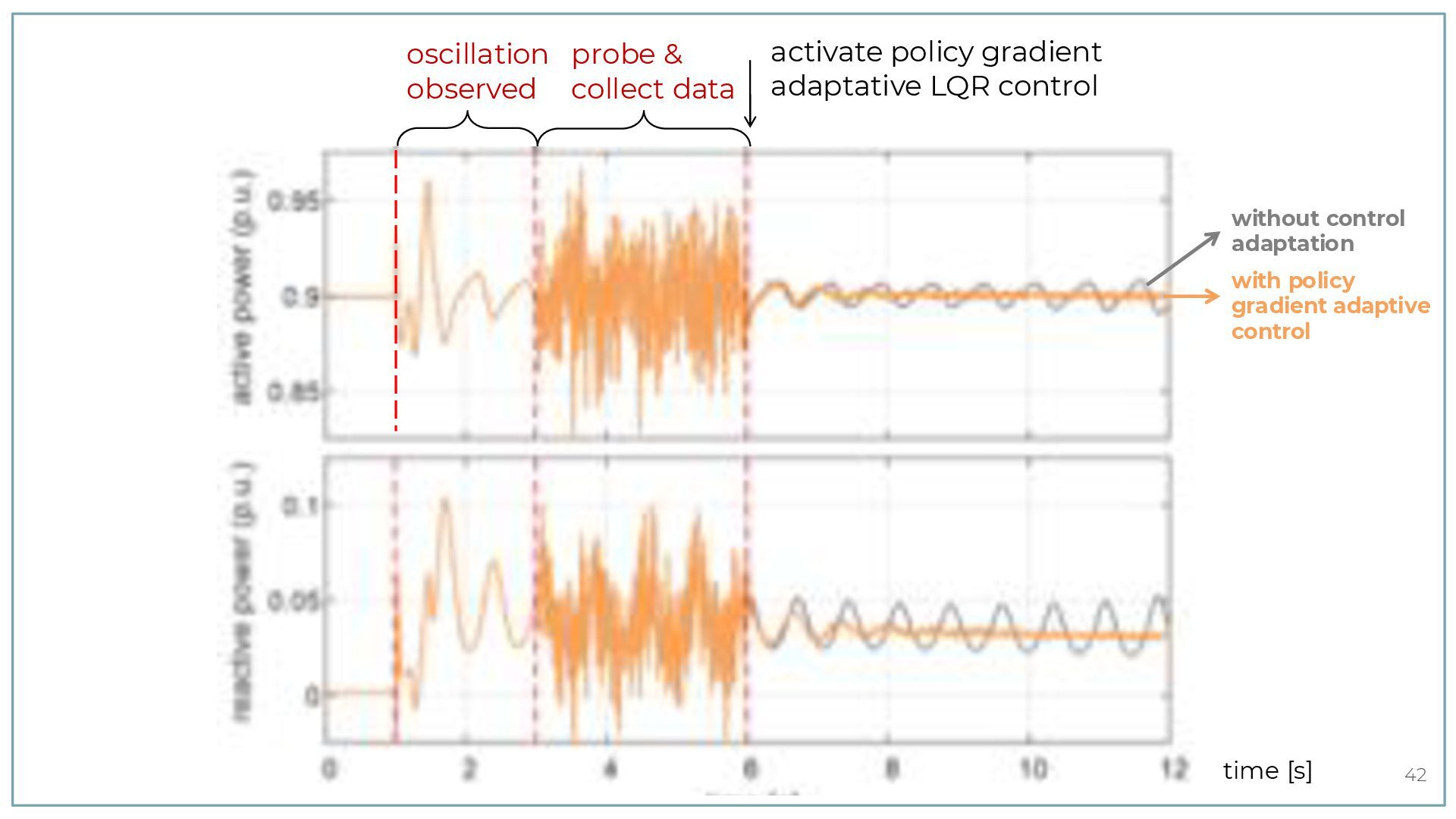{kind=link}
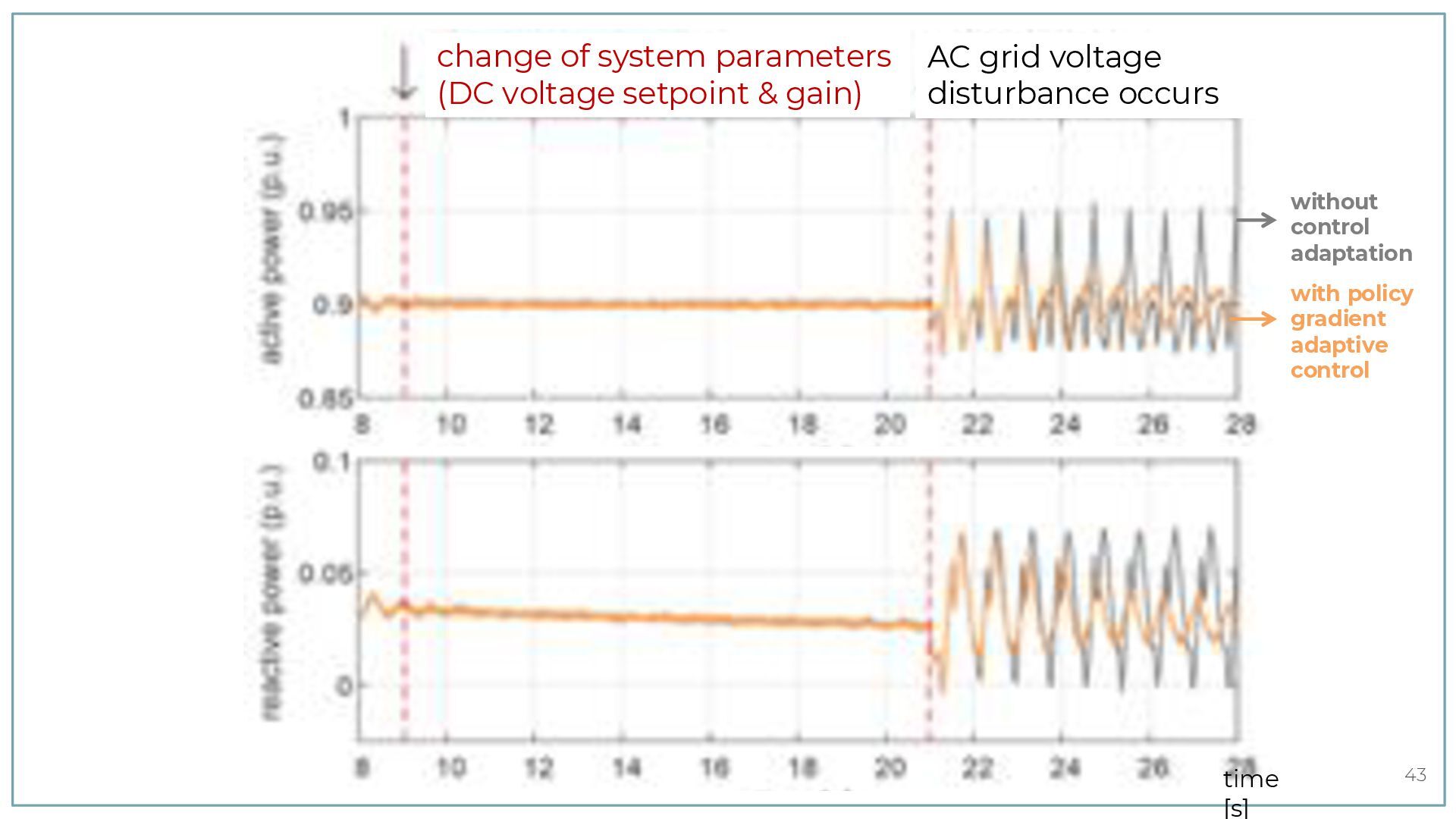{kind=link}
{kind=link}
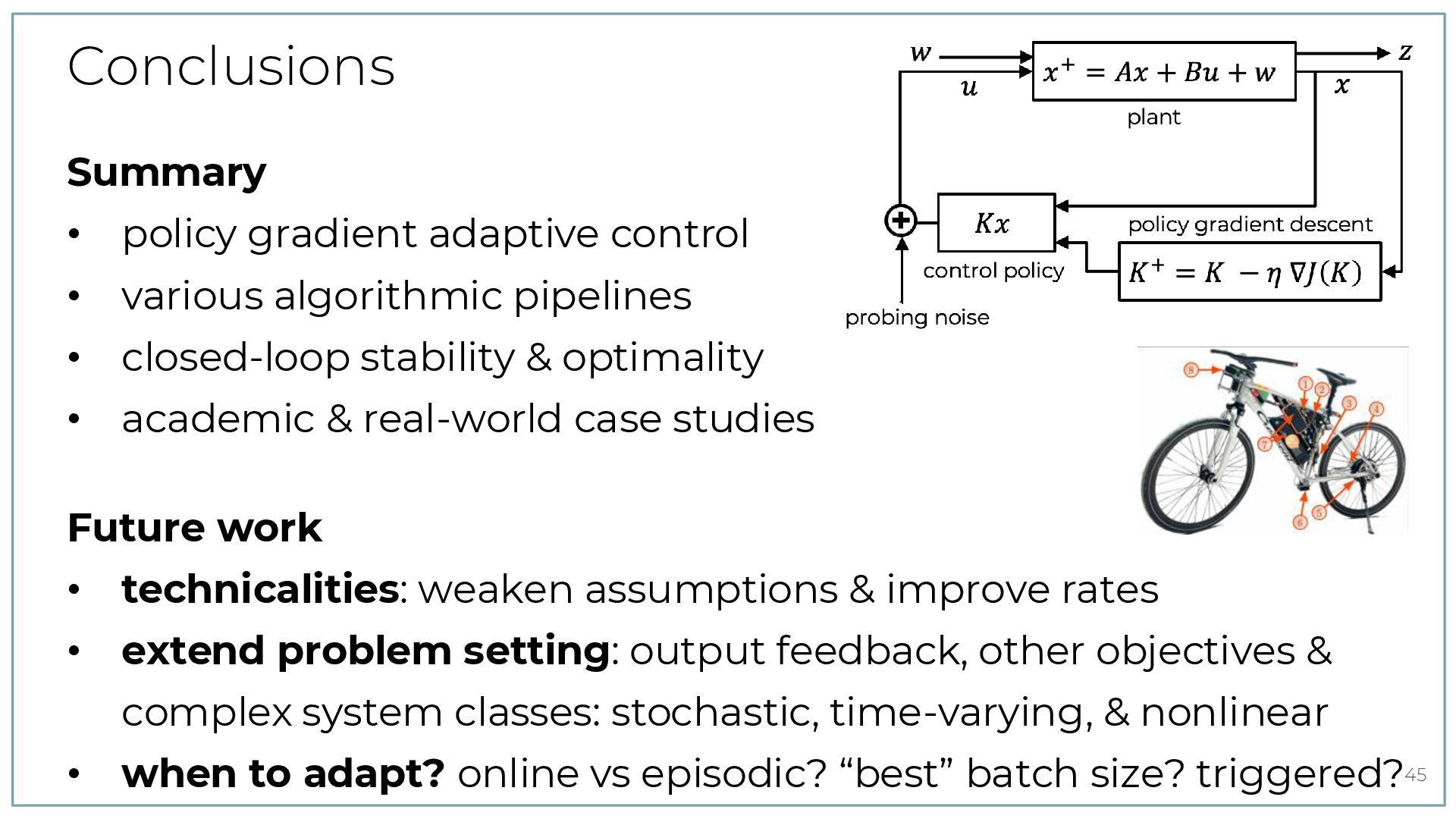{kind=link}
{kind=link}
{kind=link}