第9回 全日本コンピュータビジョン勉強会 ICCV2021論文読み会 にて、
"Panoptic Narrative Grounding" [González et al., ICCV 2021]
のご紹介をさせていただきました。
◆イベント詳細 URL:
https://kantocv.connpass.com/event/228283/
◆発表日:
2021/12/12
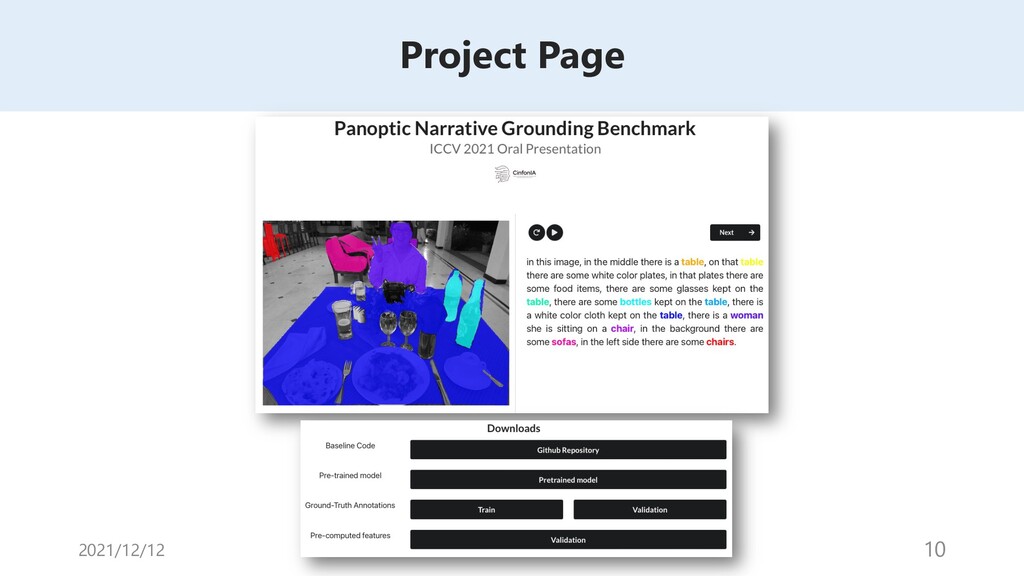
◆紹介論文のプロジェクトページ
https://bcv-uniandes.github.io/panoptic-narrative-grounding/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![今回ご紹介する論⽂ 2021/12/12 9 [PDF] [Project Page]](https://files.speakerdeck.com/presentations/9c0be5ed88714c5f826223f1de6bc821/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Localized Narratives [Pont-Tuset et al., ECCV 2020] 2021/12/12 20 •](https://files.speakerdeck.com/presentations/9c0be5ed88714c5f826223f1de6bc821/slide_19.jpg){kind=link}
{kind=link}
![Panoptic Segmentation [Kirillov et al., CVPR 2019]*1 2021/12/12 22 •](https://files.speakerdeck.com/presentations/9c0be5ed88714c5f826223f1de6bc821/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
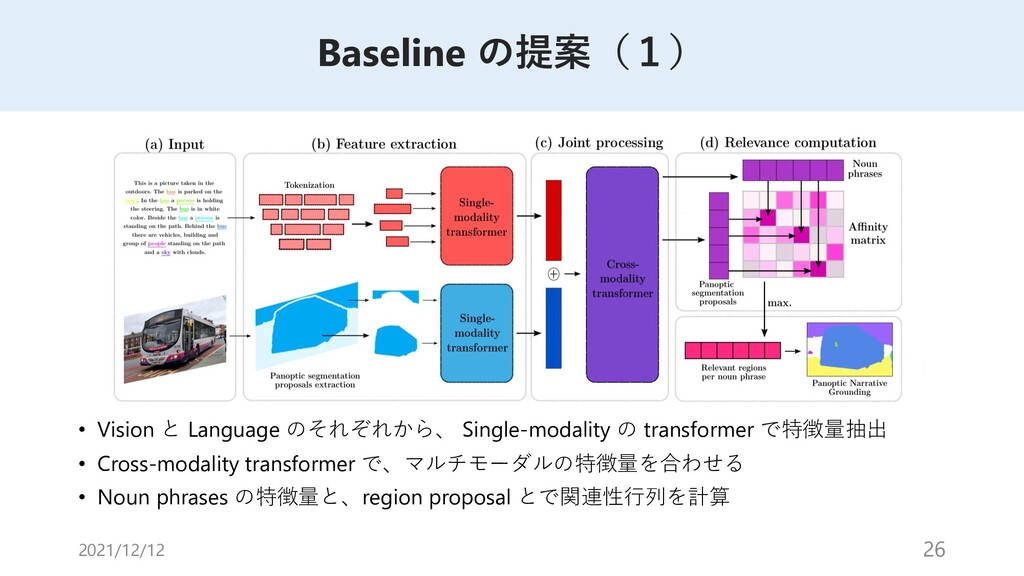{kind=link}
{kind=link}
{kind=link}
{kind=link}
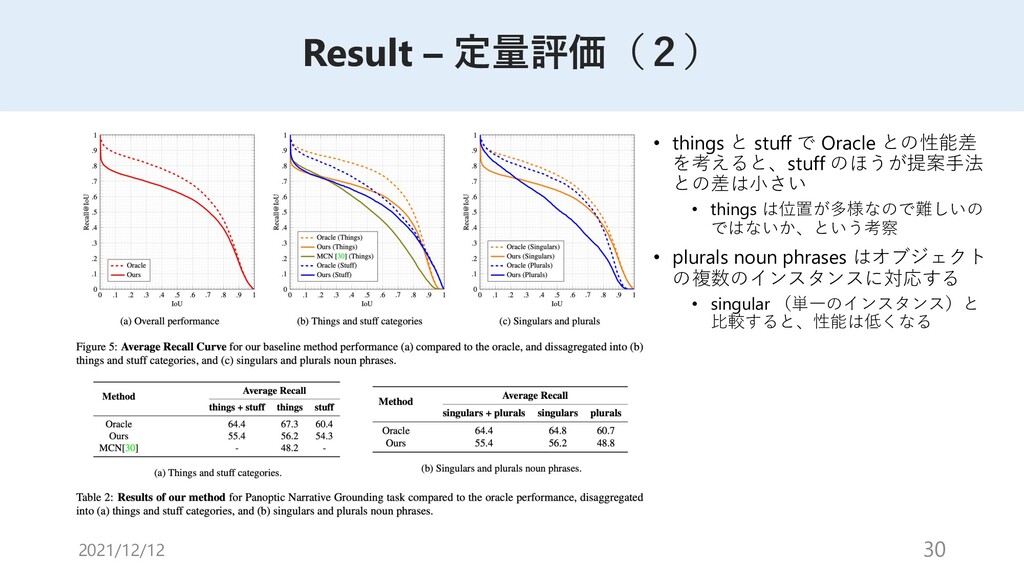{kind=link}
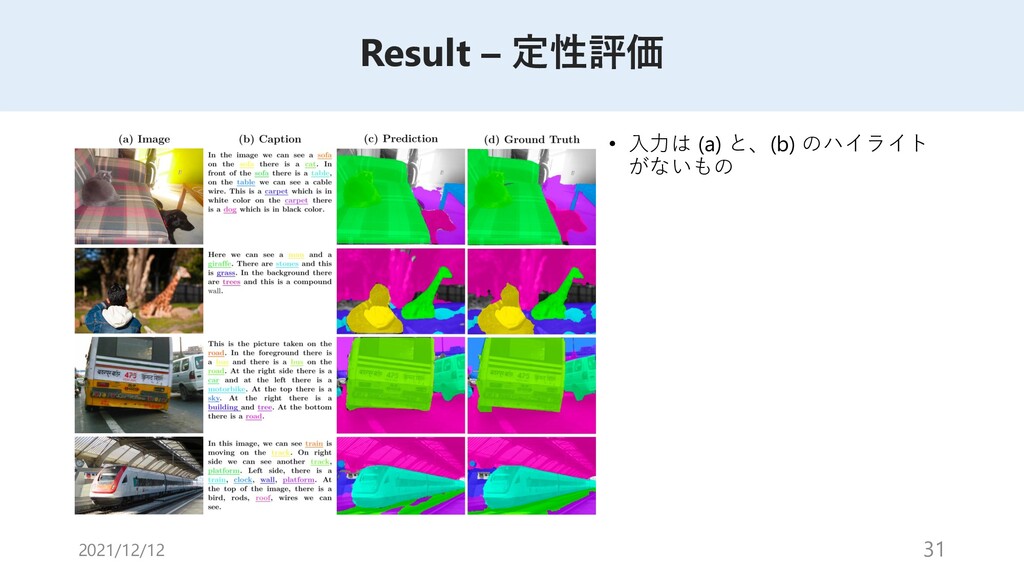{kind=link}
{kind=link}
{kind=link}