本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
紹介する論文は、「Self-supervised audiovisual representation learning for remote sensing data」です。 本研究では、ジオタグ付きの音声情報とその位置情報から取得した航空写真のペアデータセットSoundingEarthを提案、音声情報と航空写真の対照学習の性能を向上するための学習方法Batch Triplet Lossを提案しています。航空写真認識において、視覚情報だけでなく、音声情報を活用することで高精度な認識が行えることを示した。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
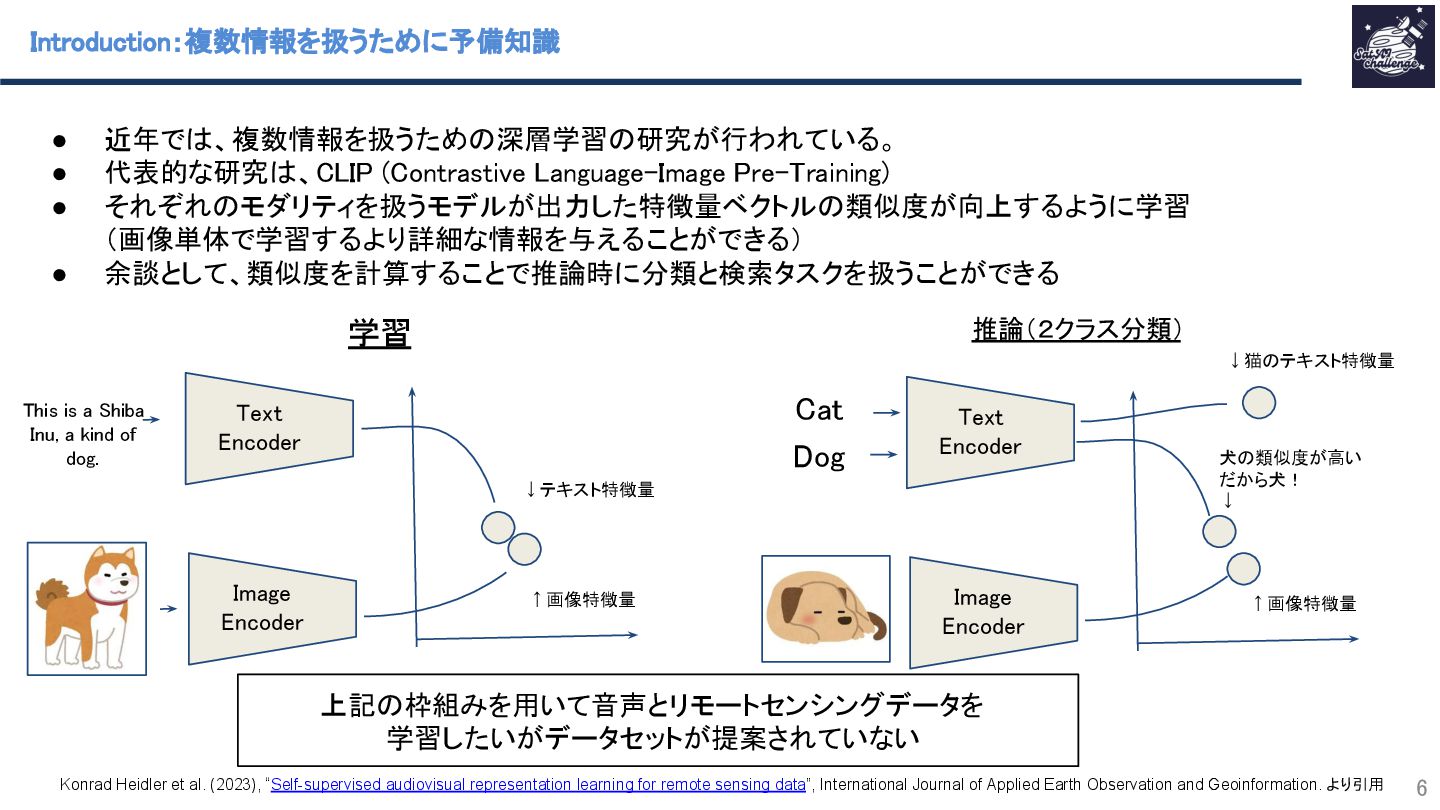{kind=link}
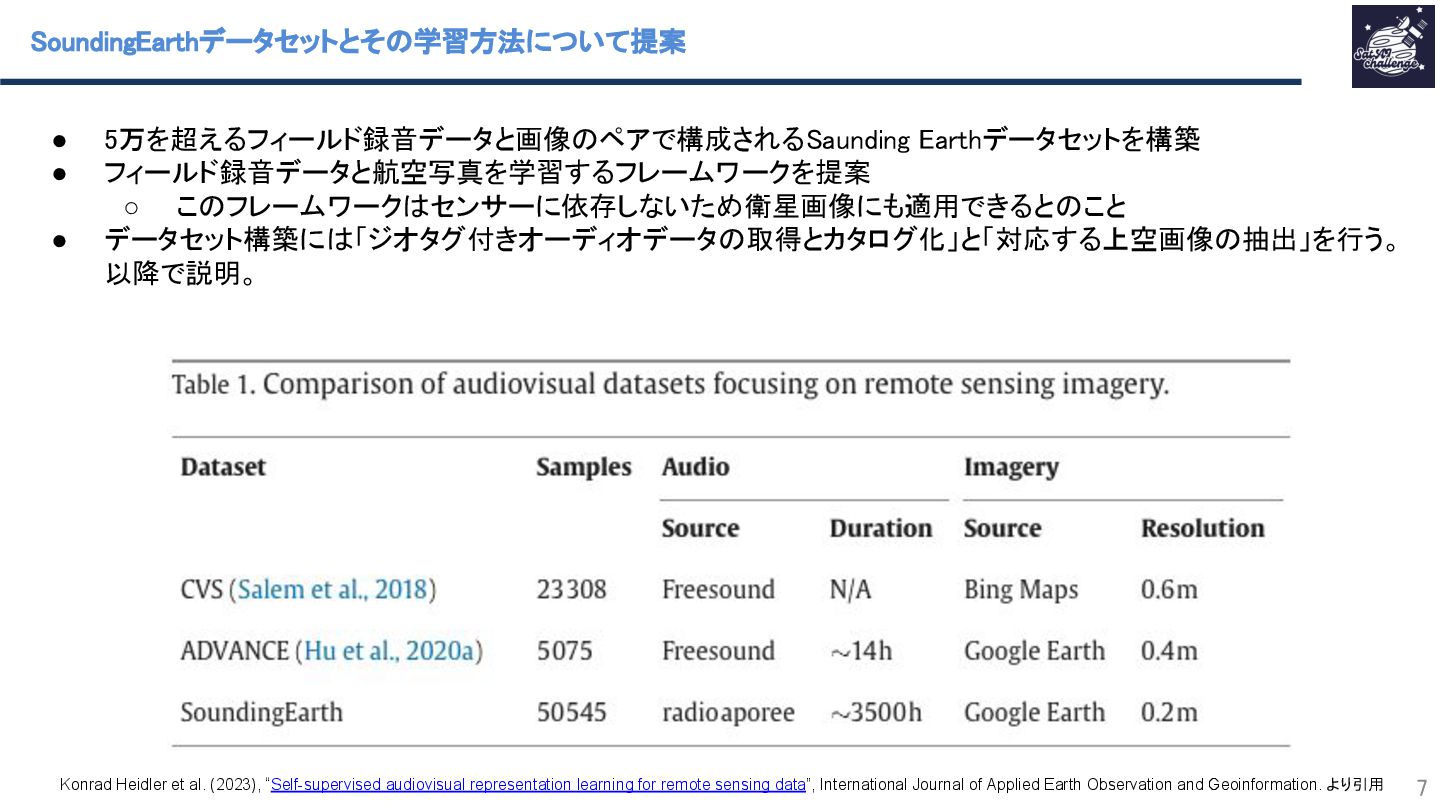{kind=link}
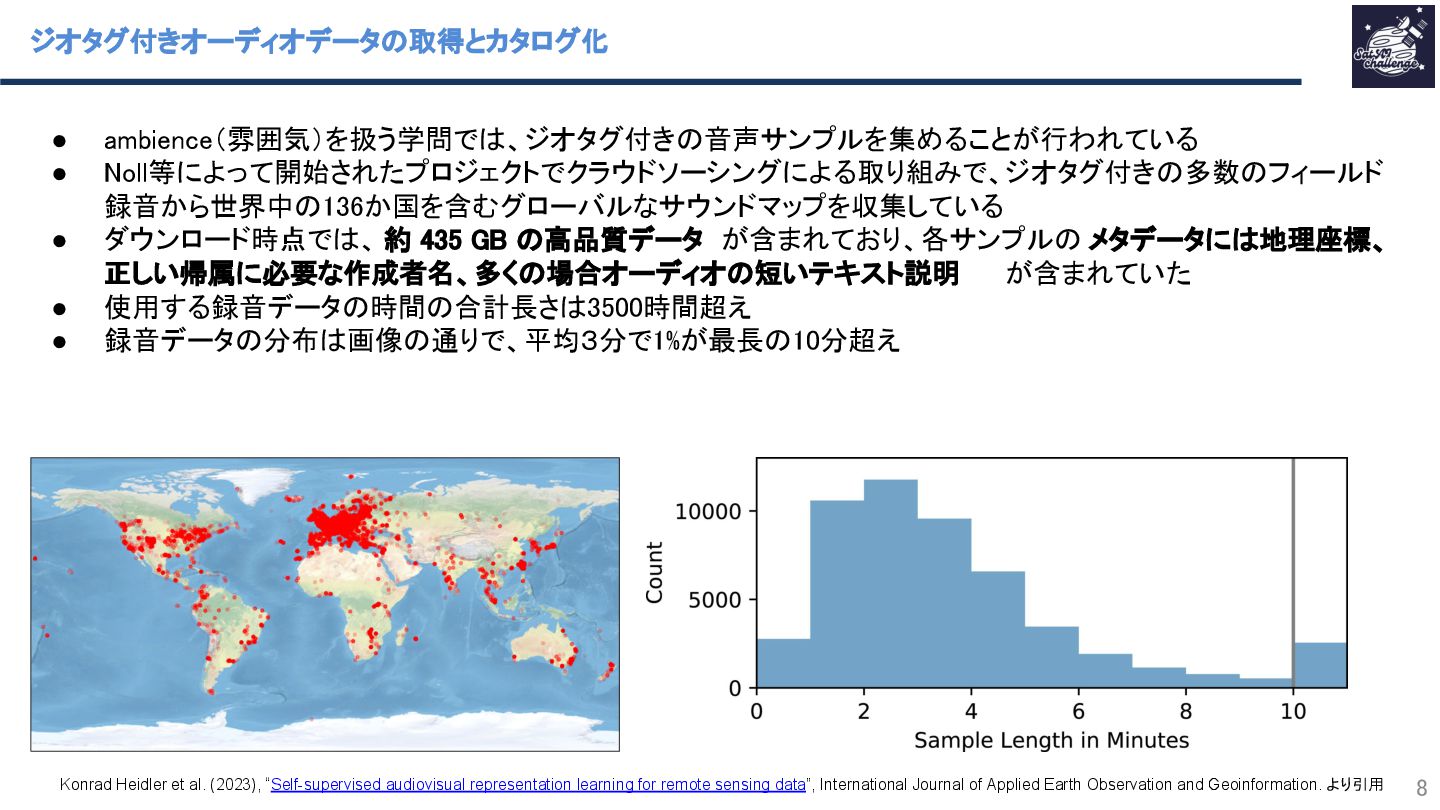{kind=link}
{kind=link}
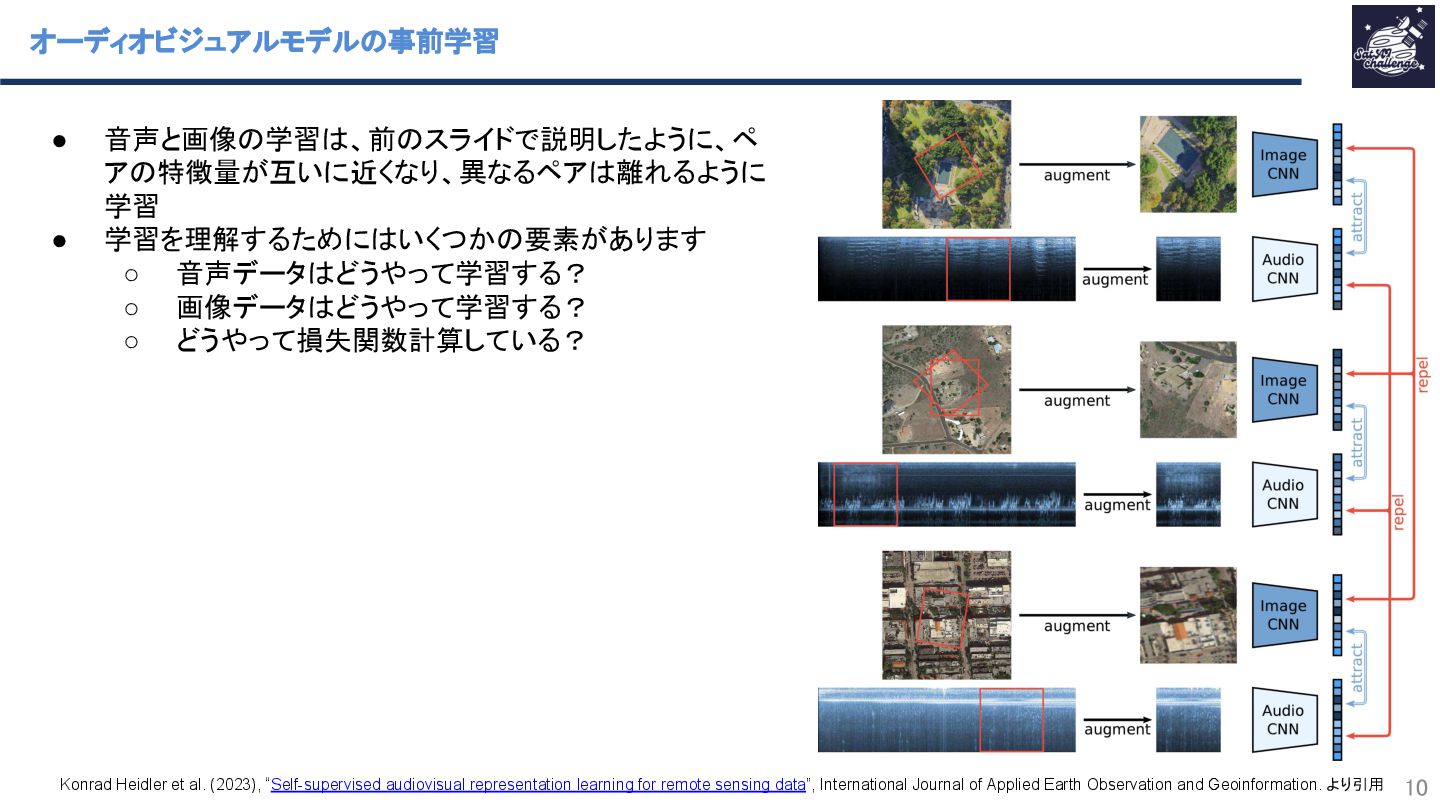{kind=link}
{kind=link}
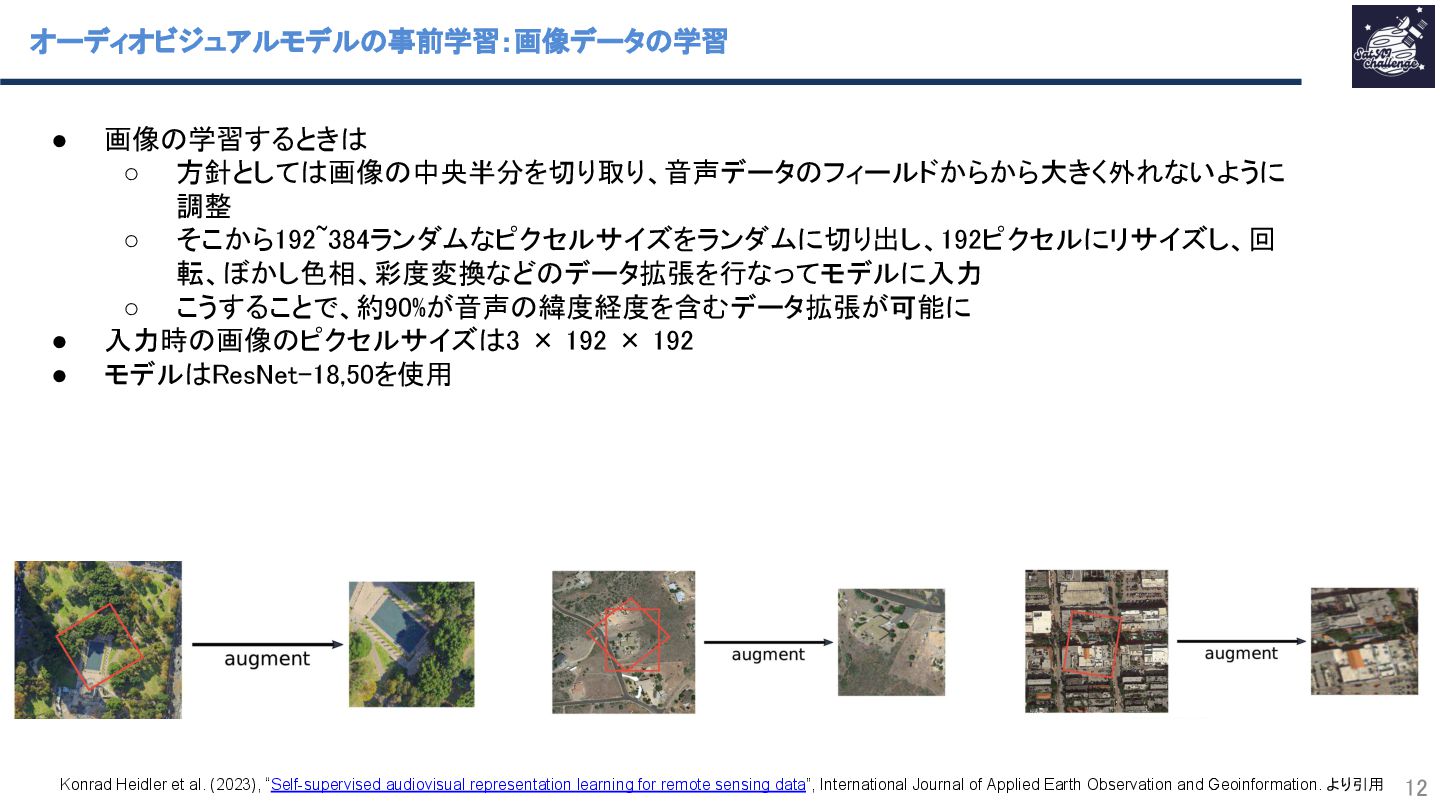{kind=link}
{kind=link}
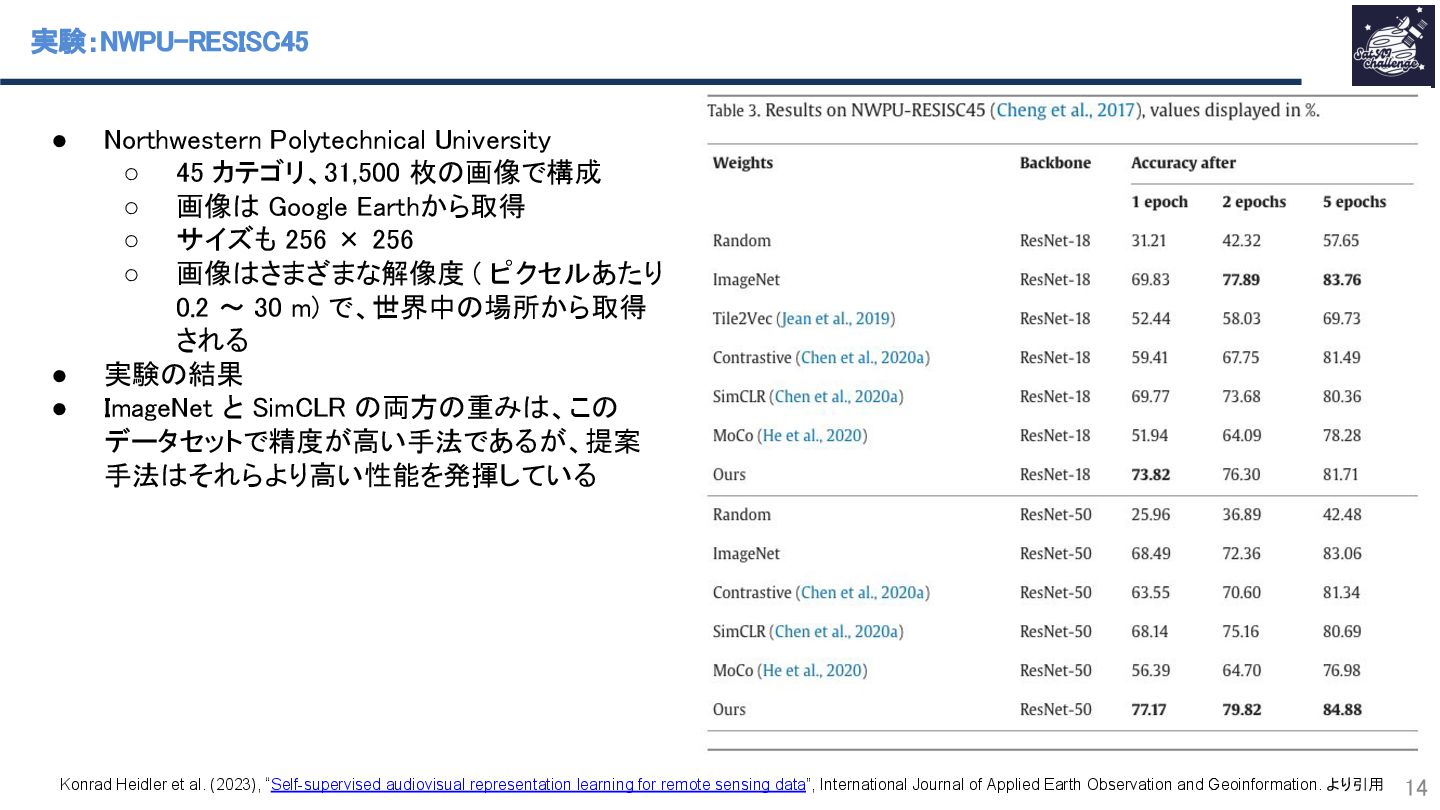{kind=link}
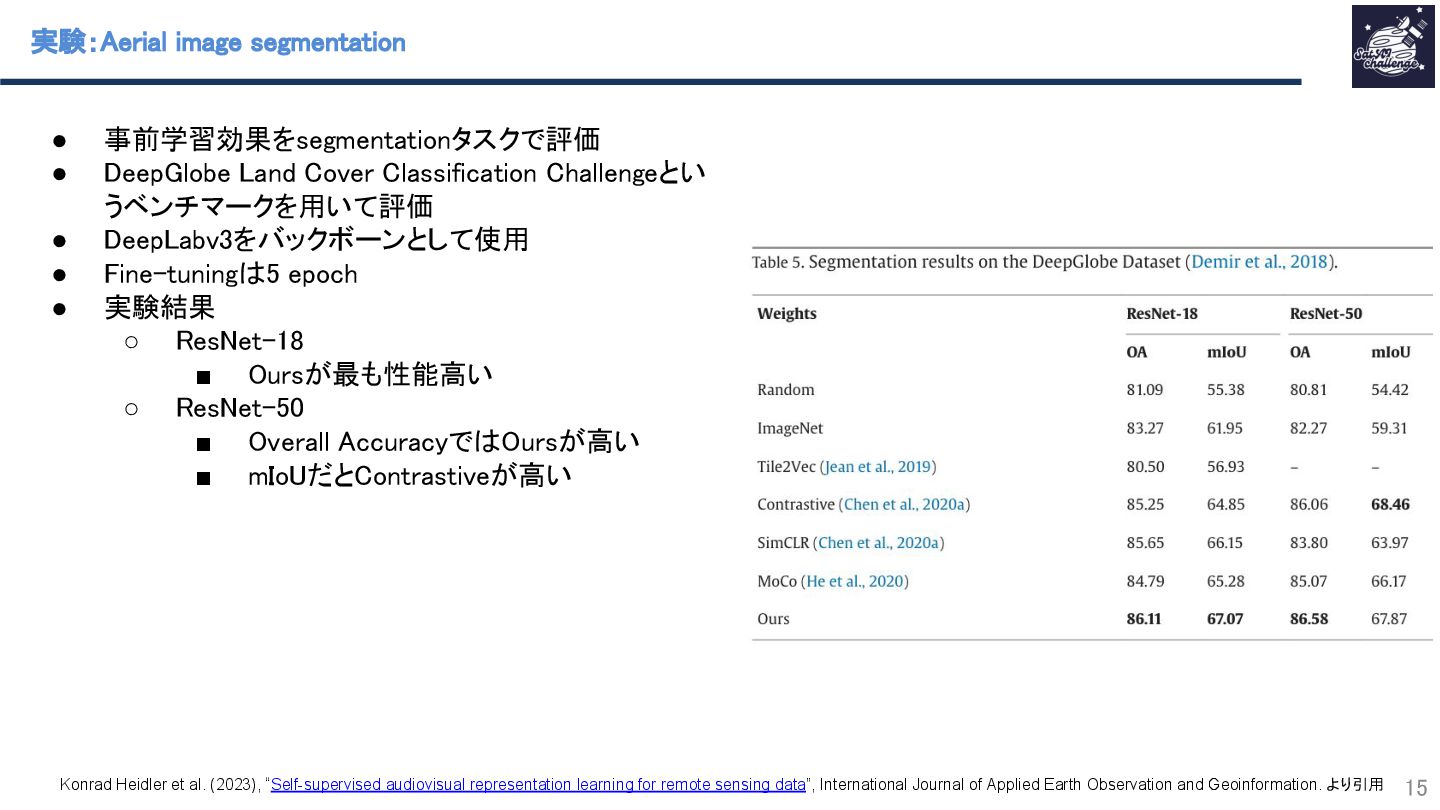{kind=link}
{kind=link}
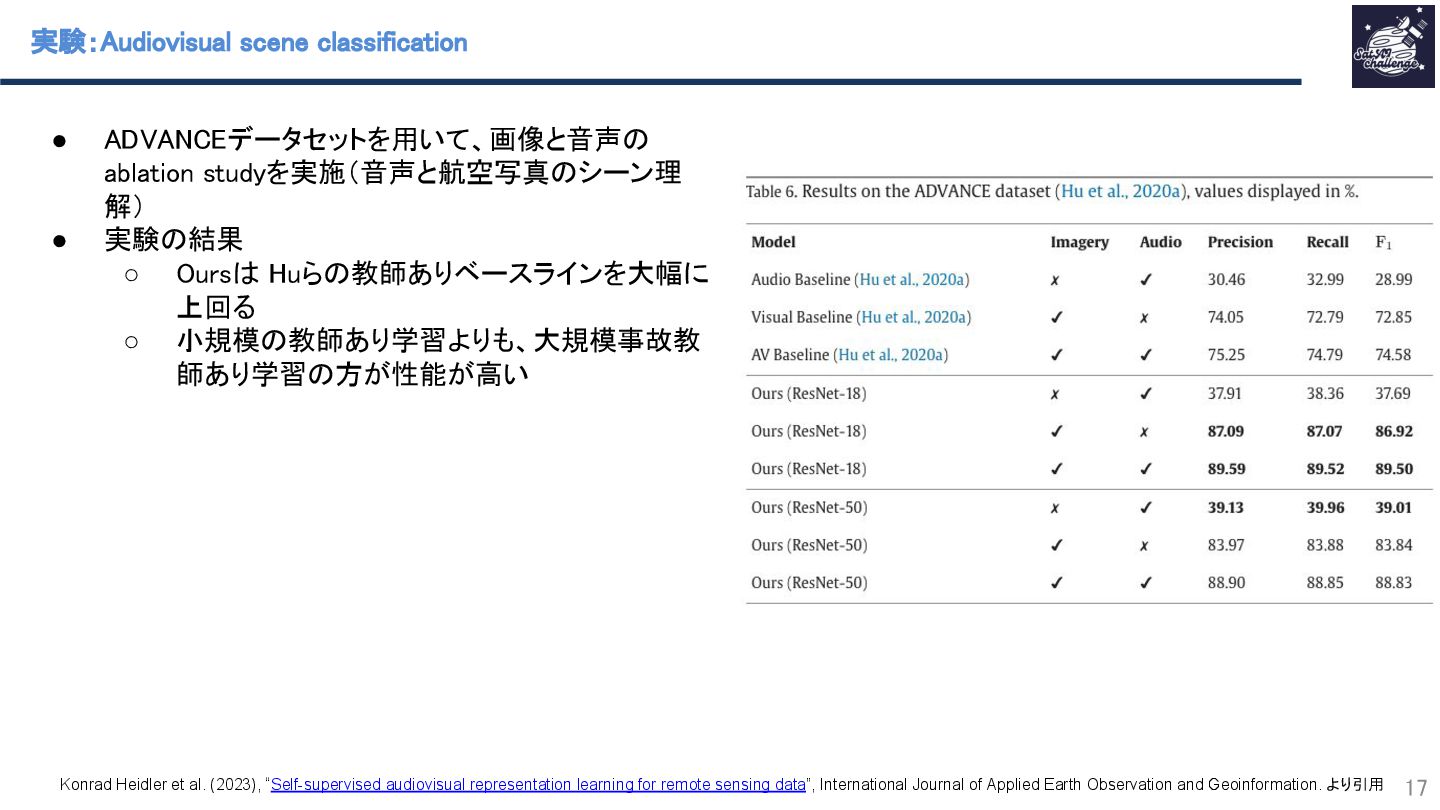{kind=link}
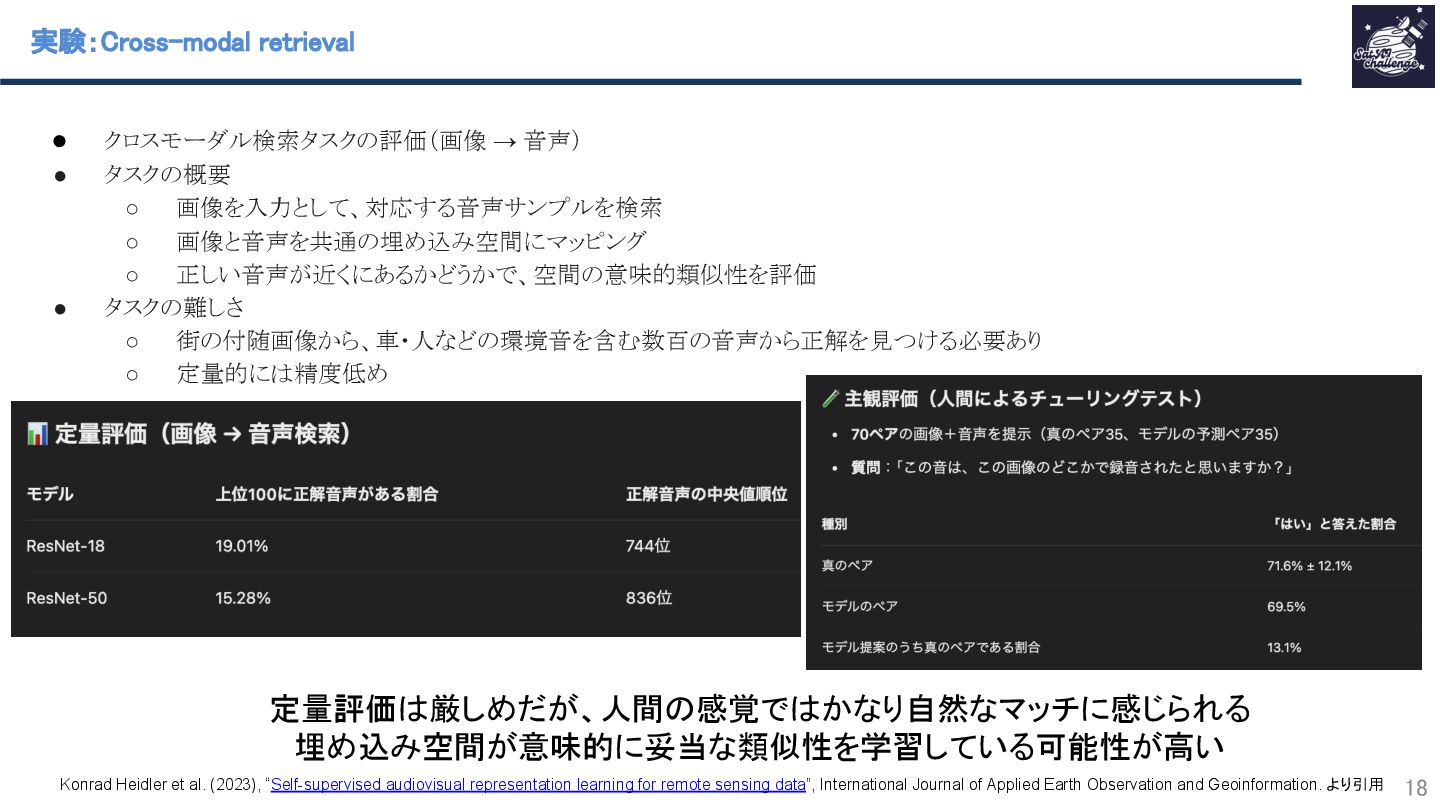{kind=link}
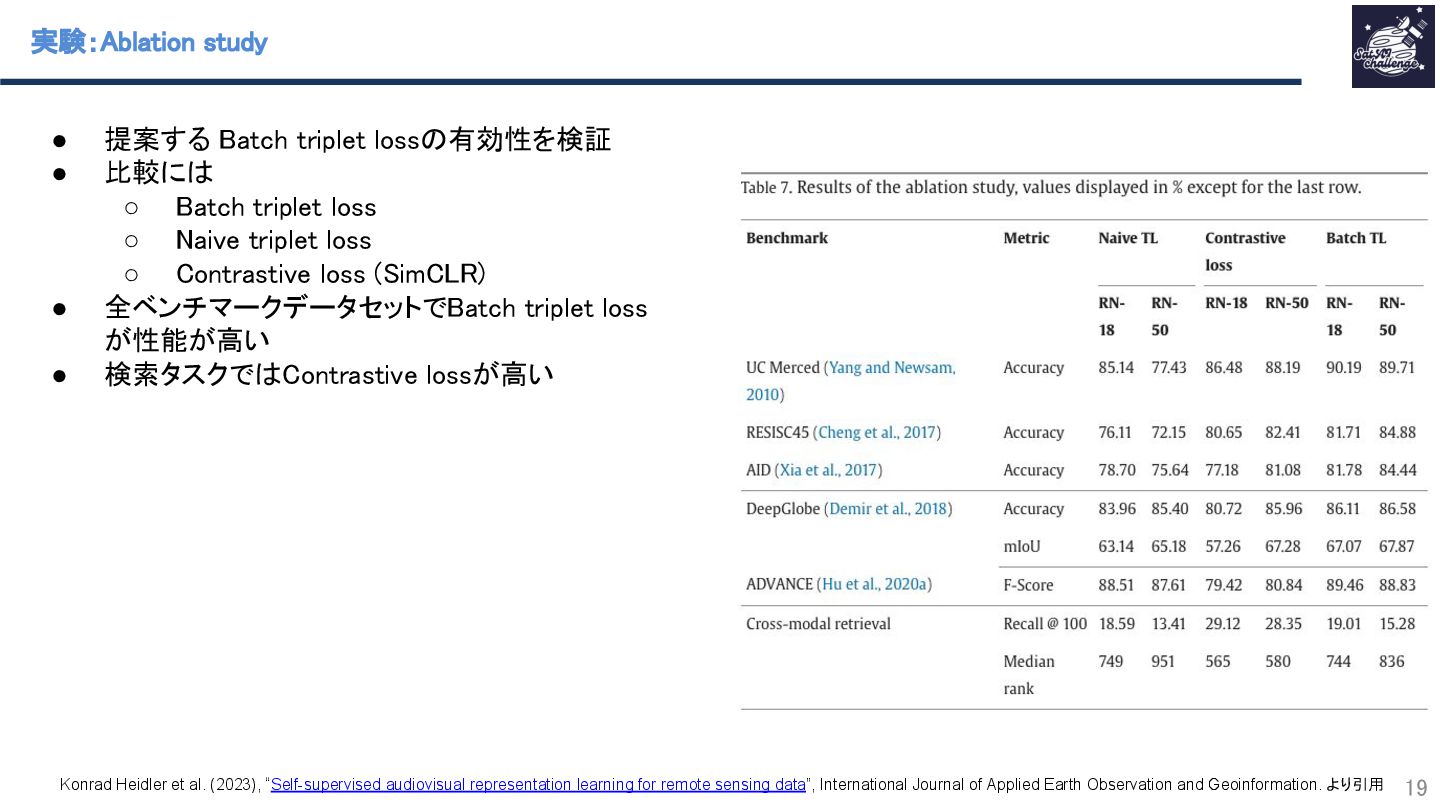{kind=link}
{kind=link}
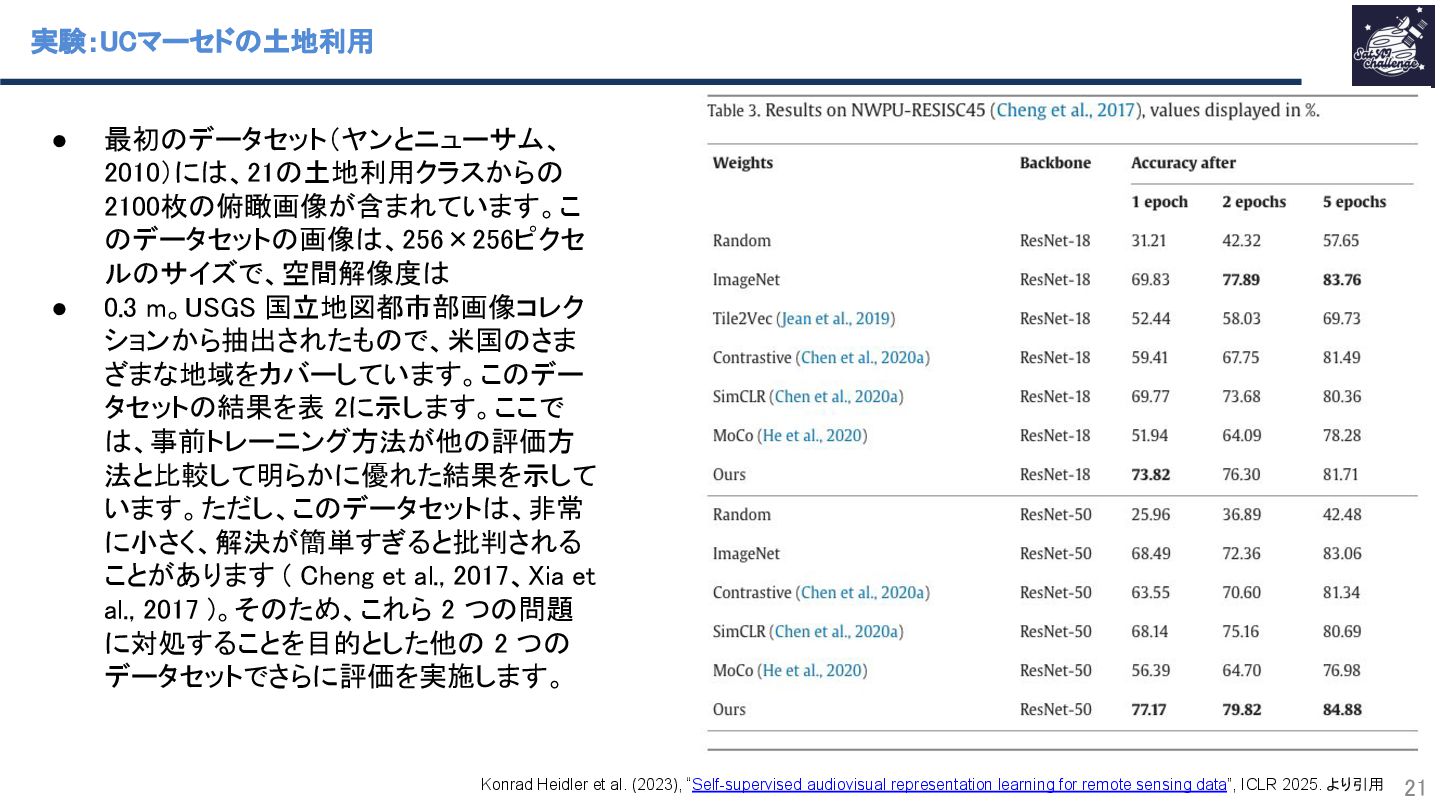{kind=link}
{kind=link}
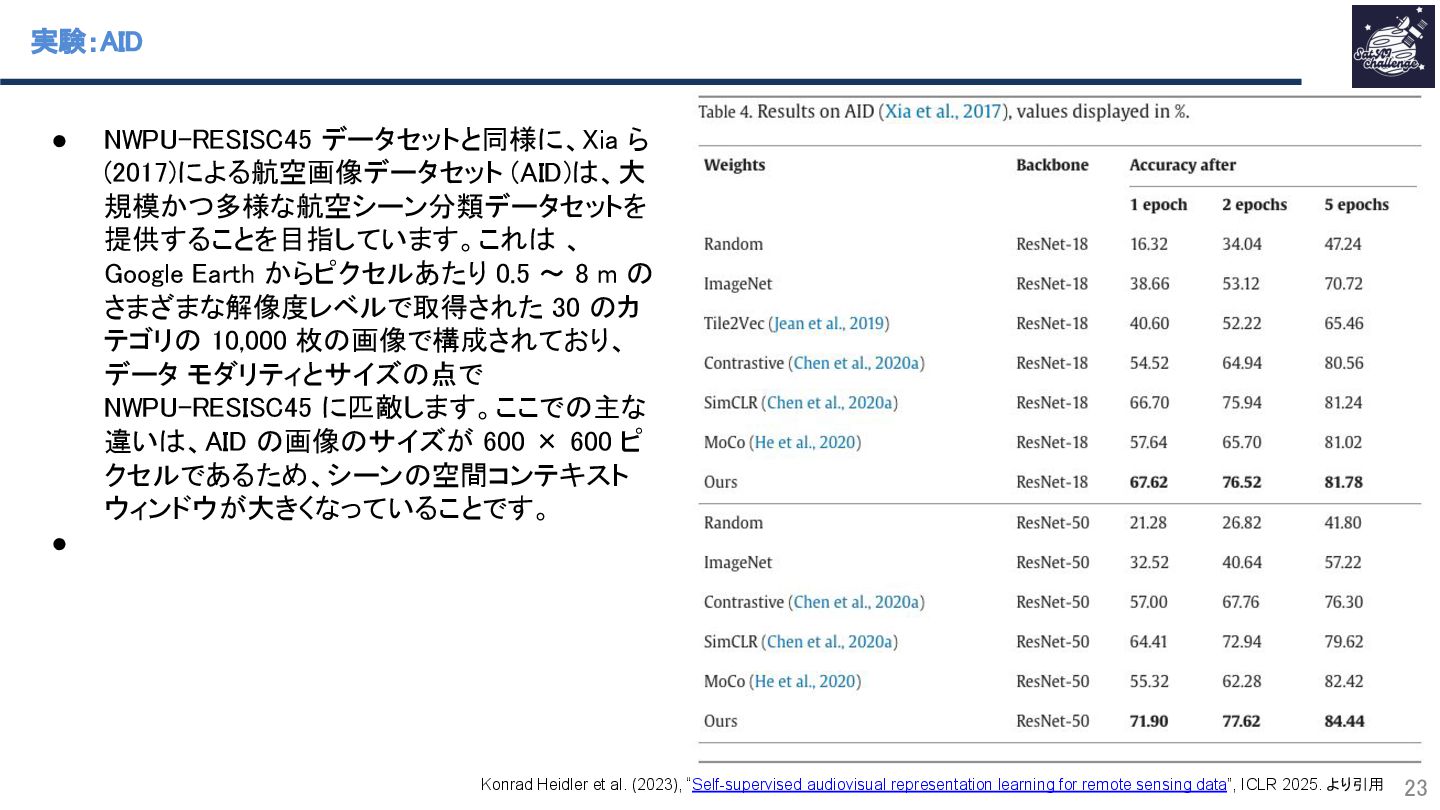{kind=link}
{kind=link}