1. 各位好,今天要跟大家分享的主題是中文斷詞,中文斷詞在中文自然語言處理上是非常重要的前置處理工作,如果中文斷詞能夠正確地將最小有意義的詞辨識出來,我們才有辦法進行更高層次的自然語言分析,因此中文斷詞的正確性影響了許多自然語言處理應用的成敗,像是,問答系統、自動摘要、文件檢索、機器翻譯等應用都需要先處理中文斷詞。
2. 好,首先跟各位介紹一下我自己,我是林志傑,網路上常用的名字是 Fukuball,所以各位可以用 Fukuball 這個關鍵字找到我。我現在在 KKBOX 工作,之前在 iNDIEVOX 當過技術長、目前也是 CodeTengu 碼天狗技術週刊作者群之一,我使用 PHP 及 Python,最近對機器學習很有興趣,空閒時開發了著名的中文斷詞程式 Jieba 的 PHP 版本,所以對中文斷詞有一些研究,今天會把我所知道的都分享給大家,讓大家都有收穫。
3. 那,中文斷詞是什麼呢?簡單來說,就是讓電腦可以把中文詞彙以「意義」為單位切割出來,比如以「塵世中一個迷途小書僮」這個例子來說,沒有特別處理的話,電腦會將每個字分開處理,但這對我們來說是沒有意義的,因此在處理語意相關問題時,就會造成效果不佳。如果能夠斷成「塵世 / 中 / 一個 / 迷途 / 小 / 書僮」,這樣對我們來說就有意義多了,對於語意理解也會比較有幫助。
4. 這裡讓我們來說明一下中文斷詞有什麼特別的地方(說明投影片),以「我們在野生動物園玩」這句話來說,英文是「We play at the wildlife park」,在英文中我們可以直接以句子中的空白來斷詞,即可斷出有意義的詞出來。但中文我們沒有詞與詞之間的空白來斷詞,且中文中會有歧異詞的問題,因此「我們在野生動物園玩」可以斷出「我們 / 在野 / 生動 / 物 / 園 / 玩」或是「我們 / 在 / 野生 / 動物園 / 玩」,對我們來說,我們會希望電腦能斷出後面這個結果,但這個問題無法用簡單的 programming 來解決,這也是中文斷詞與英文斷詞不同的地方。
5. 如果我們能夠讓電腦處理好中文斷詞,我們就能夠將斷詞後的結果數值化進行文本分析研究,這樣的自然語言處理過程對問答系統、自動摘要、文件檢索、機器翻譯、語音辨識等應用都會有幫助。我們在這個講座會展示一個歌詞相似推薦的文件檢索系統,讓大家可以更清楚知道斷詞之後如何應用在實際的問題上。
6. 從剛才介紹中,大家應該有看出中文斷詞並不是一個簡單的問題,那目前中文斷詞系統主要的困難會分成哪些面向呢?
大致可以分成三個大難題,第一個是新詞識別這個難題,例如隨著語言的發展,我們會有新的詞被發明出來,像是特有名詞,例如:人名、地名,以及新發明的詞,例如:ptt 中的魯蛇、溫拿等等,這樣的新詞在最早以字典為基礎的斷詞系統中很難被辨識出來,只要字典中沒有,斷詞系統就無法辨識,所以現今的斷詞系統多少要能夠解決某種程度的新詞識別。
第二個難題就是歧異詞識別,例如「我們 / 在野 / 生動 / 物 / 園 / 玩 」或者是「我們 / 在 / 野生 / 動物園 / 玩」其實都是合法的斷詞結果,但意義卻完全不同,我們會希望斷詞系統能夠參考上下文斷出後面的結果,也就是能夠解決某種程度的歧異詞識別。
第三個難題就是目前越來越廣泛被使用到的表情符號,這本質上就是新詞識別,但有些斷詞系統會直接將符號忽略掉,因此就無法處理這個問題,因此如果文本中有大量的表情符號,在斷詞時就要好好注意有沒有處理到這個部分的問題。
7. 了解了中文斷詞技術主要的困難點之後,我們來看看現今大部份斷詞系統是如何解決中文斷詞這個問題的。第一個方法是使用正向最大批配法,我們會有一個詞典,將句子在詞典中由前向後比對,一一比對最長詞的匹配結果,就可以斷出「我們 / 在野 / 生動 / 物 / 園 / 玩」。
第二個方法是使用逆向最大批配法,我們將句子在詞典中由後向前比對,一一比對最長詞的匹配結果,就可以斷出「我們 / 在 / 野生 / 動物園 / 玩」。
另一個方法就是正向跟逆向都算一遍,取顆粒最大的,因此我們會斷出「我們 / 在 / 野生 / 動物園 / 玩」這個結果。
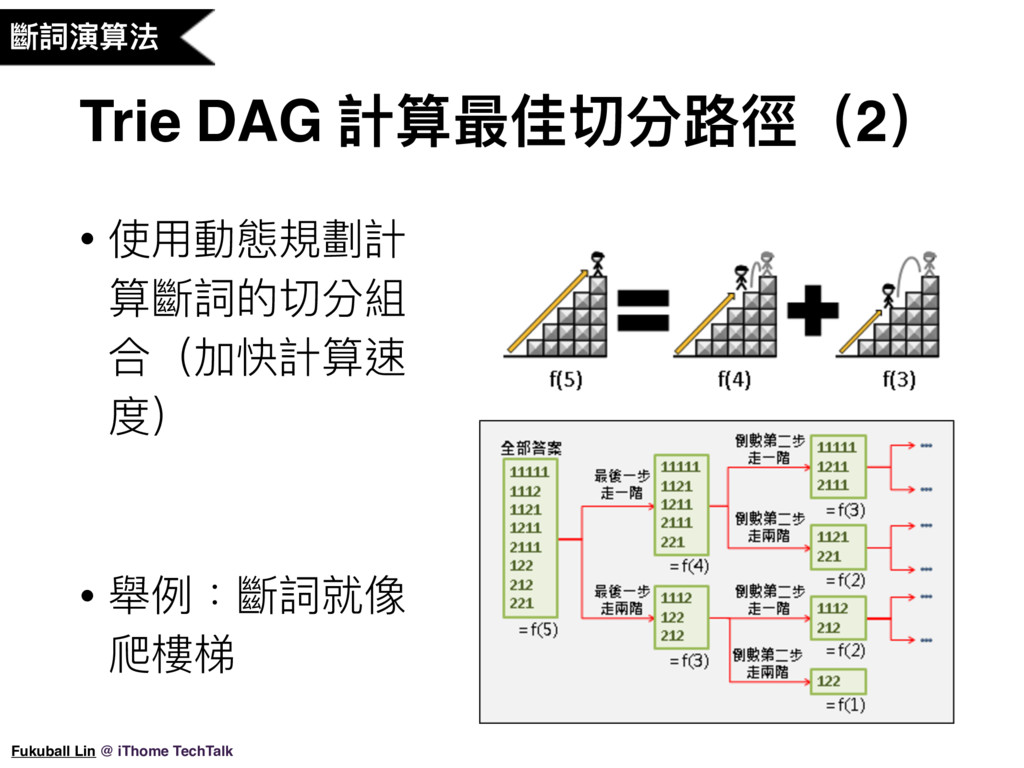
不過上面的做法都有缺點,只要詞典中沒有收錄句子中的詞,那可能效果會非常差。因此現在大部份比較好的斷詞系統都是使用全切分方法,切分出與詞庫匹配的所有可能,然後再運用統計模型決定最好的切分結果。我們這次要介紹的 jieba 中文斷詞程式就是使用類似這樣的方法完成的。
8. 了解了中文斷詞的背景知識之後,大家可能會想要知道那究竟要怎麼做中文斷詞,我在這邊會直接推薦使用 Jieba,因為我個人是工程師,還是以開發應用為導向,Jieba 應該是目前最穩定也最容易使用的中文斷詞程式。
9. 有人會問,中研院也有中文斷詞系統啊,那為何還要選擇使用 Jieba?
10. 其實曾經我也使用中研院斷詞系統,但使用過後才發覺問題很大,首先中研院斷詞系統很不穩定,常常回傳的資料有可能會有被截斷的情況,然後 API 也不夠完善,當功能不夠完整的時候,開發者就會想要去把它修改得更好,但中研院斷詞系統並非開源的 Project,我們也無法調整它,讓這個斷詞系統可以變得更好用,所以最後只能往外尋找其他的資源。
11. 後來就看到了 Jieba 這個斷詞程式,它最大的優點就是它是一個 open source 的 project,我們可以預期未來會有更多優秀的開發者加入開發 Jieba,Jieba 也會因為優秀開發者的加入而讓功能變得越來越完善,所以使用 Jieba 會是一個很好的選擇。
12. 接下來我要稍微介紹一下 Jieba 斷詞演算法的思路,讓大家可以了解結巴的核心是如何處理中文斷詞的,了解演算法可以讓大家知道 Jieba 的弱點在哪邊,未來如果想要手動改善 Jieba 的效果,也能知道如何改起。而這些知識也能夠在大家如果有需要開發自己的中文斷詞系統時帶來一些幫助。
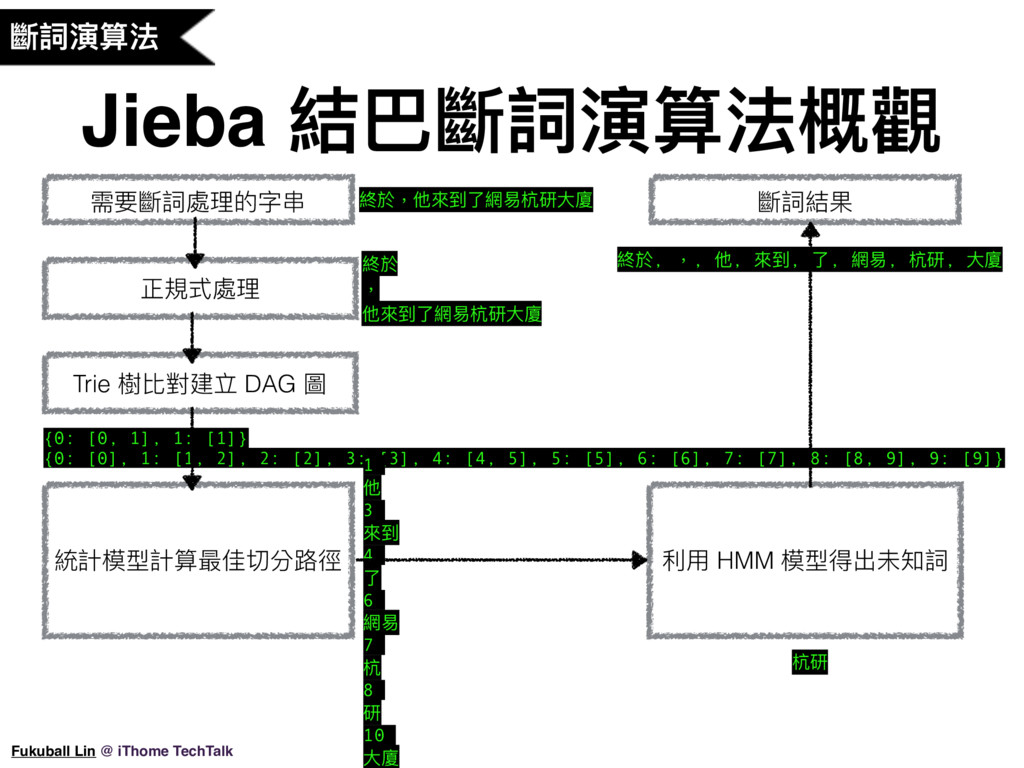
13. 結巴的斷詞演算法大概可分成兩個部份,第一個部分是建立 Trie DAG 資料結構,快速算出全切分法所有合法的切分組合,再使用統計模型計算最佳結果。最後一步再使用 HMM 模型計算來辨識新詞。
14. 我這邊大概整理了 Jieba 這個斷詞程式核心演算法如何運作的概觀,這是 Jieba 各個部份演算法大致的架構及處理流程,首先呢,我們輸入要進行斷詞的句子,這邊我們用 Jieba 它所提供的例子來說明,我們要將「終於,他來到了網易杭研大廈」這個句子進行斷詞,第一步就是使用正規式來將符號與文字切開,如此就會先斷成像投影片所顯示的這三個部分,第一個部分是「終於」,第二個部分是逗號,第三個部分是「他來到了網易杭研大廈」,然後結巴會把屬於文字的部分進行進一步的處理。第二步 Jieba 會載入字典,建立一個 Trie 字典樹,等一下我們會詳細說明 Trie 字典樹的結構長什麼樣子,有了 Trie 字典樹之後,Jieba 就開始比對句子中有沒有 Trie 字典樹中的詞,然後計算出句子有幾種切分組合,再把切分組合表示成一個有向無環圖,大致上這個無環圖可以這樣表示,(解釋),第三步再計算最佳的切分組合是什麼(解釋),在這邊我們就可以得到一個還不錯的結果,最後一步呢,我們看到有連續的單字詞出現,比如這個例子裡斷出的「杭」及「研」這個兩個單字詞,這時我們就可以把這些單字詞再組合起來丟到 HMM 模型計算看看是否能組成一個新的詞,計算結果是,「杭研」可以再組成一個詞,這就是整個 Jieba 斷詞程式的運作過程。我接下來會稍微介紹一下各部分演算法的概念。
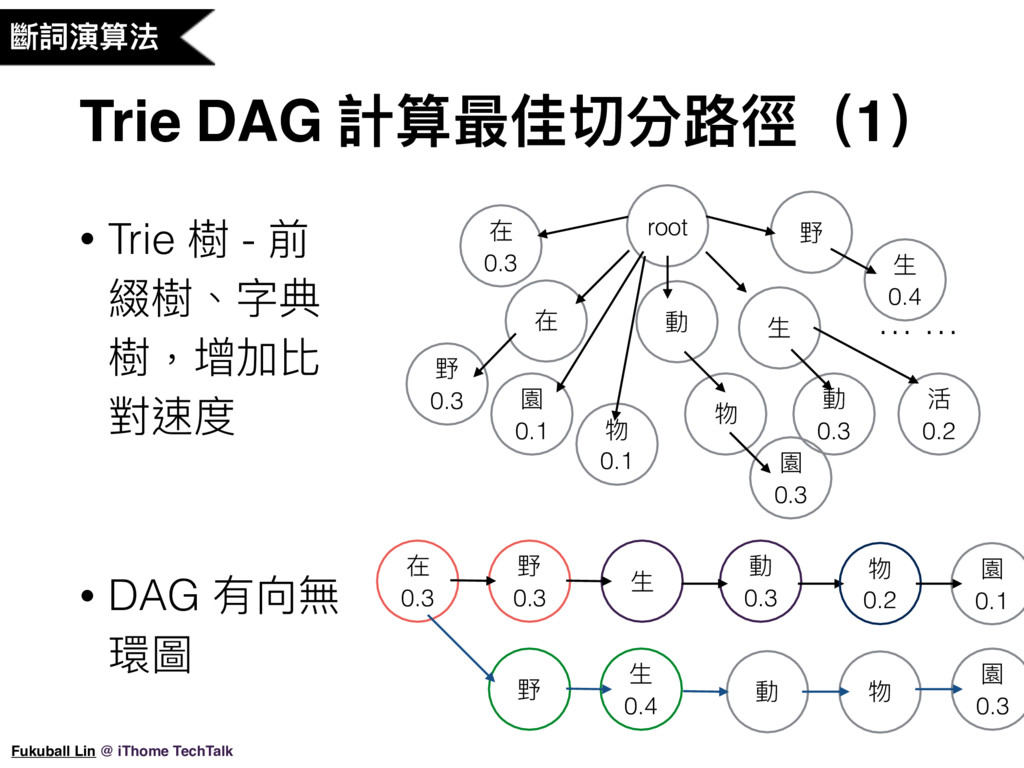
15. 由剛剛的 Jieba 核心程式概觀,我們可以知道 Jieba 斷詞是先用字典來解決大部份的斷詞,我們可以稍微看一下原始碼中的字典,(翻開原始碼),字典的格式是長這樣,Jieba 會載入這個字典,然後建立 Trie 樹,Trie 樹又可以叫做前綴樹、字典樹,它可以增加字詞比對的速度,Trie 樹的結構就是我投影片上畫出來的這個圖,上面會有每個字詞及它的機率值,程式在比對的時候,比如句子中出現了「在」這個字,那我們就可以得到 0.2 這個機率值,然後再把句子的下個字往後比對,如果剛好是「野」這個字,那就會得到 0.3 這個機率值,這兩個都算合法的斷詞結果,程式會把它記下來,然後就可以組合成底下這樣的有向無環圖,記錄了所有的斷詞切分組合及機率值,如此我們就可以根據統計模型的機率值計算出最佳的切分結果了。
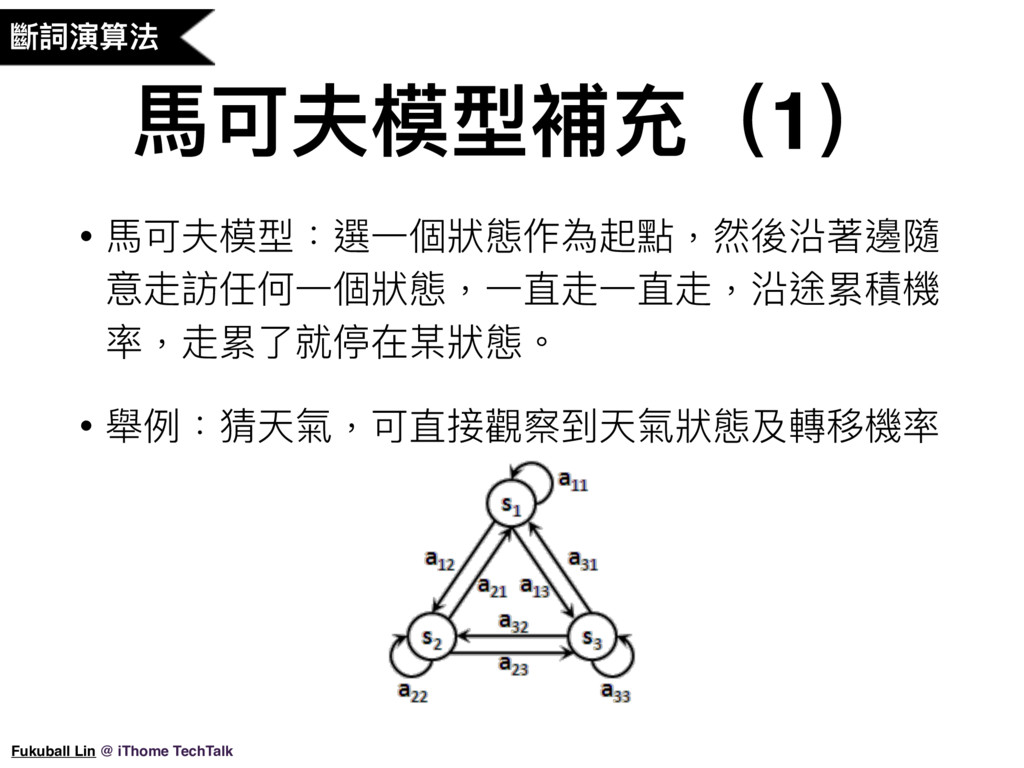
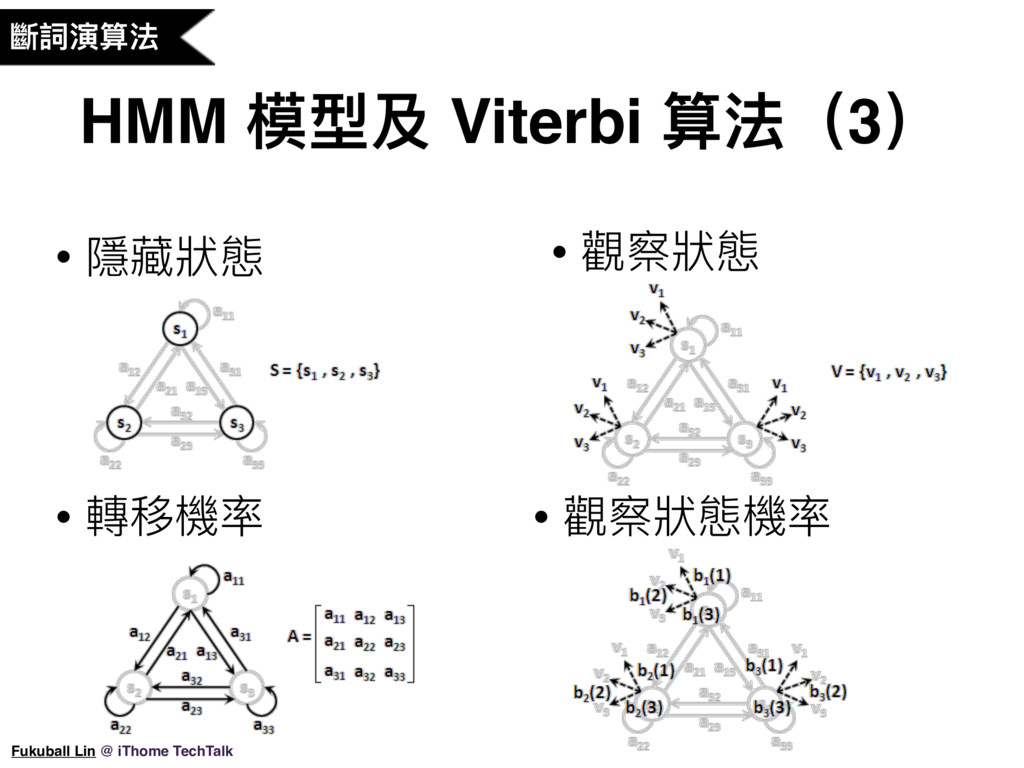
16. 再來,Jieba 會將字典比對的斷詞結果中出現的連續單字詞進行組合,然後使用 HMM 隱馬可夫模型來計算新詞的組成。隱馬可夫模型其實是由馬可夫模型所延伸過來的。我們知道馬可夫模型是由狀態機率及狀態轉移機率所組成,隱馬可夫模型跟馬可夫模型不同的地方就在於隱這個字,馬可夫模型的狀態是可以直接觀察到的,而隱馬可夫模型的狀態是無法直接觀察到的,我們只能從其他的可觀測資料來猜出實際的狀態可能長什麼樣子。
17. 隱馬可夫模型是由馬可夫模型延伸過來的,所以先來看一下什麼是馬可夫模型。基本上馬可夫模型的概念就是選定一個狀態作為起點,然後沿著邊隨意走訪任何一個狀態,一直走一直走,沿途累積機率,走累了就停在某狀態。舉例來說,猜天氣就可以使用到馬可夫模型,我們如果知道今天是雨天機率,也知道雨天跟晴天之間的轉移機率,那就可以猜猜看明天也是雨天或晴天的機率。
18. 這邊我用一個實際的例子來說明,有一名旅客,三天後想到台南遊玩,由氣象報告得知今天的降雨機率為 0.2,也知道晴天雨天的轉移機率如下,則此遊客三天後到台南遇到下雨的機率為多少?(解釋投影片)
19. 同樣的,我們用猜天氣的例子來舉例說明隱馬可夫模型,比如現在有個人是瞎子,他無法直接觀察到天氣情況,但他可以察覺到人們在各種天氣中所進行的活動,比如有人在走動、有人在購物、地上是潮濕等,如果已經累積到足夠的資料量可以知道晴天時有多少機率有人在走動、在購物、地上是潮濕,雨天時有多少機率有人在走動、在購物、地上是潮濕,然後也知道雨天跟晴天之間的狀態轉移機率,最後我們看了瞎子記錄的最新三天的可觀察狀態,我們要試著去推算這三天是晴天或雨天,並算出一個最佳的組合,這就是隱馬可夫所要解決的問題。
20. 隱馬可夫模型幾個重要的名詞我們再整理一下,我們有講到隱藏狀態,每個隱藏狀態會有他的初始機率值,在這個例子中的隱藏狀態就是晴天跟雨天。然後隱藏狀態之間會有轉移機率值,在今天是雨天的情況下,明天是雨天的機率是多少,今天是晴天的情況下,明天是雨天的機率是多少,用一個矩陣把所有轉移機率值記下來,然後隱馬可夫模型會有可觀察狀態,每個隱藏狀態都會有若干個可觀察狀態,我們可以在隱藏裝態中觀察到各個可觀察狀態的機率值,在這個例子中的可觀察狀態,就是有沒有人在走動或購物或是地上潮濕。
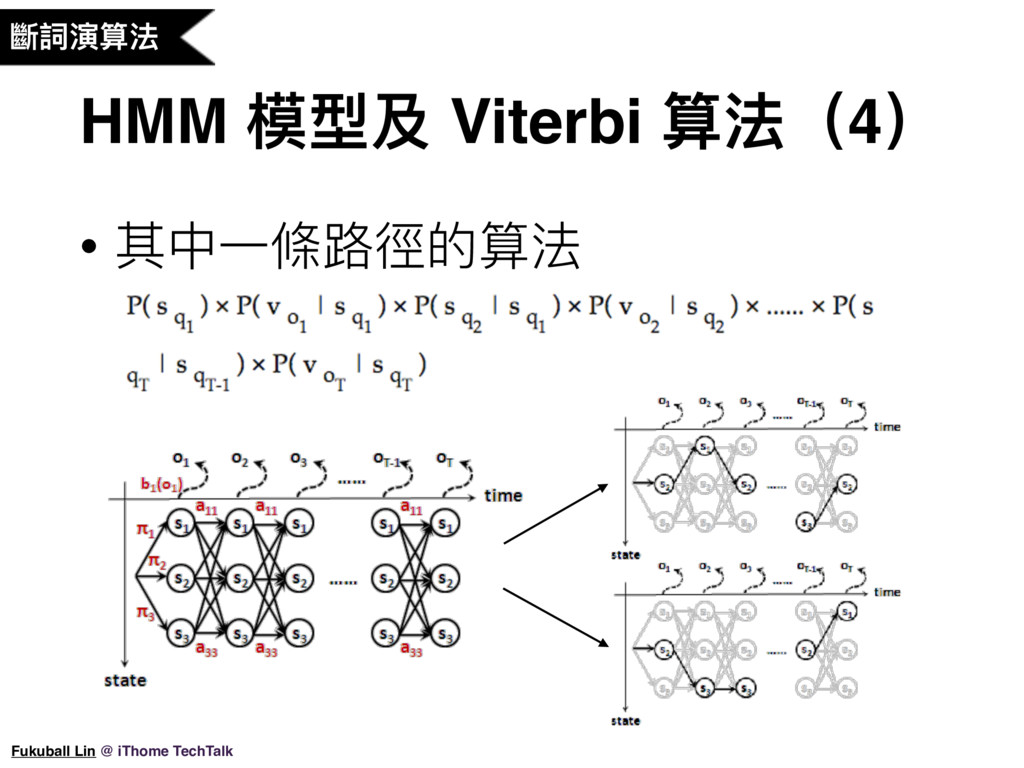
21. 好,從瞎子記錄的最新三天的可觀察狀態,我們要試著去推算這三天是晴天或雨天,並算出一個最佳的組合,它的其中一個組合路徑的算法公式大概就長這樣子。這樣直接看公式會覺得很抽象,我們可以直接代入例子來了解這個公式(解釋公式)假設瞎子記錄的這三天可觀察狀態都是人有在外面走動,那其中一個組合就是三天都是晴天,我們去計算這個組合的機率值。(解釋公式)所以我們就讓程式去把每一個組合的機率值都算出來,得到的最大值結果就可能是最符合真實的組合。
22. 如果大家還不清楚的話,這邊我們詳細算一次給大家看。(解釋投影片)
23. 把剛才的猜天氣例子舉一反三轉換到斷詞這個問題,斷詞其實就是我們要去猜字在句子中組合的結構,字在句子的結構可分成四種結構,我們稱為 BMES,B代表開頭,M代表中間,E代表結尾、S代表獨立成詞,而我們要去猜字是屬於這四種結構的哪一種,所以結構就是隱藏狀態,而我們可以看到字的序列,所以字的序列本身就是可觀察狀態。套到剛才猜天氣的計算公式,我們將每種結構的排列組合都計算出一個機率值,最大的機率值結果,其實就是最佳的斷詞結果。比如:「在野生動物園」可能就會算出 SBEBME 這個排列組合會得到最大的機率值。(看原始碼幫助理解)
24. 了解了結巴的演算法之後,我們來看看結巴斷詞程式如何使用。
25. Jieba 是使用 Python 寫的,需要裝好 Python 環境及 pip。裝好之後我們要先裝一下 Virtualenv 這個套件。這個套件可以讓我們在開發 Python 相關程式的時候可以創造一個分開且完全乾淨不會互相干擾的 Python 環境。相關指令如下:(說明投影片)
26. 今天的展示的程式碼大家都可以在這邊下載來自己玩玩看。
27. 那我們實際來使用一下 Jieba 的斷詞,這是我寫好的一個 Sample Code,斷詞模式是使用預設的精確斷詞模式,我們想要斷詞的句子是「塵世中一個迷途小書僮」、「我們在野生動物園玩」及「林志傑是結巴 PHP 的作者」,「我們在野生動物園玩」會有歧異詞的問題,「林志傑是結巴 PHP 的作者」會有新詞識別的問題,程式的語法就是使用 jieba.cut 來進行斷詞(解釋原始碼),我們來執行程式看一下結果。(開終端機)
28. 好,這就是我們剛剛執行程式的結果,感覺結果還不錯。
29. Jieba 還有提供另一個斷詞模式,叫做全模式,我們只要加上一個參數 cut_all,然後設成 True,就可以切換成全模式。全模式的斷詞結果會將所有可以成詞的部份都列出來。我們可以來實際執行一下看有沒有什麼不一樣的地方。(開終端機)
30. 好,這就是我們剛剛執行的結果,上面是精確模式,下面是全模式,大家應該可以很清楚的比較出不同,精確模式就是演算法得出的最精確斷詞結果。而全模式會把所有在句子中可以成為一個詞的詞都列出來。一般來說我們都會是使用上面的精確模式來斷詞,但有時,例如在做搜尋功能的時候,可能就會使用到全模式。
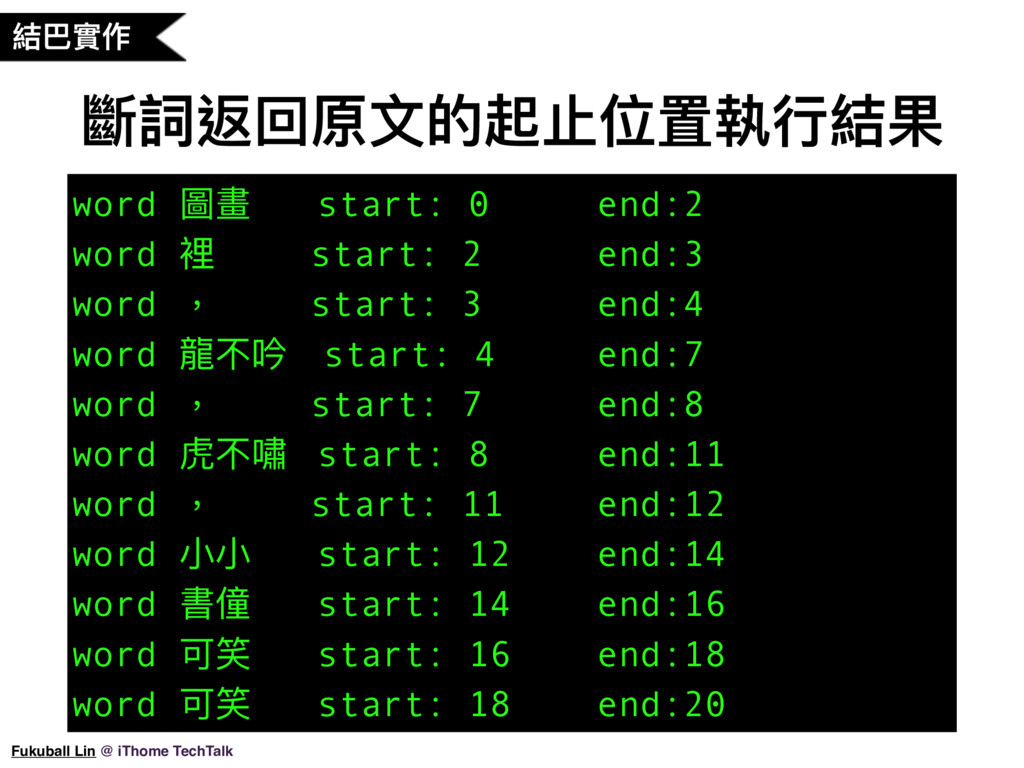
31. Jieba 還有一個功能可以列出斷詞結果在句子中的位置,語法就像這樣(解釋原始碼),jieba.tokenize,這邊要特別注意字串的前面要加一個 u 字,統一將字串都轉成 unicode 來處理。我們來執行程式實際看一下結果。(開終端機)
32. 結果就像這樣,從 0 斷到第 2 個字,以此類推。
33. Jieba 也有標注斷詞詞性的功能,語法就像這樣,使用 pseg.cut 來進行斷詞,得到斷詞詞性的結果。我們來執行程式實際看一下結果。(開終端機)
34. 左邊就是斷詞結果,右邊就是斷詞的詞性,我們要去對一下詞性的列表,才可以知道這些符號的意義。以上就是 Jieba 這個斷詞程式大概的使用方法及功能。
35. 接下來我們用一些實際的例子來看看 Jieba 的斷詞效果。因為我的公司主要是做音樂相關的資料,所以這邊就用歌詞分析來看看 Jieba 的斷詞效果。這裡我們用回聲樂團的座右銘這首歌來進行斷詞。投影片上就是這首歌的歌詞,也就是我們要進行斷詞的文本。
36. 這是歌詞斷詞的 Sample Code(解釋原始碼),我們在這邊沒有切換詞庫,直接使用預設的詞庫,我們來執行程式看一下結果。(開終端機)
37. 其實如果我們使用預設詞庫,我們會發現斷詞的結果很不理想(解釋投影片)
38. 我們再整理一下剛才的斷詞結果,「座右銘」被斷成了「座 / 右銘」,「墓誌銘」被斷成了「墓誌 / 銘」,主要是因為預設詞庫是簡體中文,因此這樣的斷詞結果大部分是使用 HMM 的演算法猜測出來的,所以也相對不準確。使用足夠的詞庫來進行斷詞會得到比較精確的斷詞結果。
39. 好,那就讓我們切換到繁體詞庫試試看,這是 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)
40. 其實如果我們使用繁體詞庫,我們會發現斷詞的結果很變理想了(解釋投影片)
41. 我們再整理一下剛才的斷詞結果,「座右銘」成功斷成「座右銘」, 「墓誌銘」也成功斷成「墓誌銘」了,所以只要有足夠的詞庫,加上 HMM 的演算法,就可以得到不錯的斷詞結果。
42. Jieba 還有一個功能,它可以算出文章中的關鍵字,語法就像這樣(解釋原始碼),我們來執行程式看一下結果。(開終端機)
43. 這就是 Jieba 算出來文章中的關鍵字,(解釋投影片)
44. 那 Jieba 究竟是怎麼算出文章的關鍵字的呢?其實他背後的演算法就是使用 TF-IDF 這個演算法,這個演算法的核心概念就是「某個詞在一篇文章中出現的頻率高,且在其他文章中很少出現,則此詞語為具代表性的關鍵詞」,(解釋公式),我們也可以從這個演算法知道,為何說斷詞會是文本分析的基礎,因為斷詞之後,我們才可以計算詞頻,將詞轉換成數值,進一步發展出更多的演算法。
45. 另外,Jieba 也可以設定停用詞,停用詞就是一些比較沒有意義的詞,我們可以直接去除掉的,我們可以看一下停用詞列表,大家可以一自己的文本情況設定自己的停用詞詞典。使用停用詞的方法如投影片。
46. 如此我們可以讓關鍵字更凸顯出來。
47. 從剛剛的例子,我們已經多少了解 Jieba 斷詞程式的斷詞效果了,那我們可以再提高斷詞的準確性嗎?大致上可以再做調整的方式有幾個,一個是調整文本資料,如 HMM 模型中的觀察機率及轉移機率以及詞典切分統計模型的機率值,但這需要搜集大量的資料,並整理分析才能完成。或者是我們可以再去調整斷詞的演算法,目前也有很多人繼續研究斷詞的演算法,可能可以增加斷詞的效率,或是增加斷詞的效果。另外一個比較快的方式就是使用自定義詞典,直接用較大的字典來增加斷詞的效果。目前 Jieba 就有 API 可以讓研究者使用自定義詞典來增進斷詞的效果。
48. 這邊就來跟大家說明一下 Jieba 使用自定義詞典的方法,語法就是 jieba.load_userdict,這樣就可以了。需要注意一下自定義詞典的格式,我們來看一下(看原始碼)
49. 除了事先定義好自訂義字典,jieba 也提供了一個可以在程式中動態增加字詞的方法,語法就像這樣(解釋原始碼),我們可以實際來使用看看(Live Demo)(全台大停電)
50. 剛剛我們用 Jieba 來實際看看國語歌詞的斷詞效果,現在如果是台語歌詞,不知道斷詞結果會如何,我們這邊就用滅火器的島嶼天光這首歌來試試看
51. 好,這是 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)
52. 其實斷詞的結果還算不錯,有些明顯是台語用法的詞才會有斷詞效果不好的問題(解釋投影片)
53. 我們再整理一下剛才的斷詞結果,「「袂當」斷成了「袂」「當」, 「袂記」斷成了「袂」「記」, 「袂有」斷成了「袂」「有」,這都是明顯的台語用詞,所以 jieba 目前無法處理,快速的解法就是使用自定義詞典。
54. 這是使用自定義詞典的 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)
55. 如此斷詞的效果就變得更好了(解釋投影片)
56. 所以從剛剛的結果來看,我們使用了自定義詞典之後,斷詞結果可以符合我們預期,這是因為我在自定義詞典裡加了這幾個台語用詞(解釋投影片)
57. 以上大概就是 Jieba 斷詞程式如何使用的所有內容,基本上我們可以利用 Jieba 來幫助我們完成中文斷詞的工作了,但斷完詞要幹嘛呢?當然要實際應用到真實的應用系統啊!
58. 大家可以思考看看中文斷詞後可以用在什麼樣的地方,想想自己可以做出什麼樣的應用。比如我們公司是做音樂的,我們就可以用在歌詞分析,或者是分析歌詞自動建立情境歌單,或者是為創作者做一個自動填詞的功能,或者是做一個相似歌詞推薦的功能。我這邊來展示一下如何將斷詞應用到一個相似歌詞推薦系統。
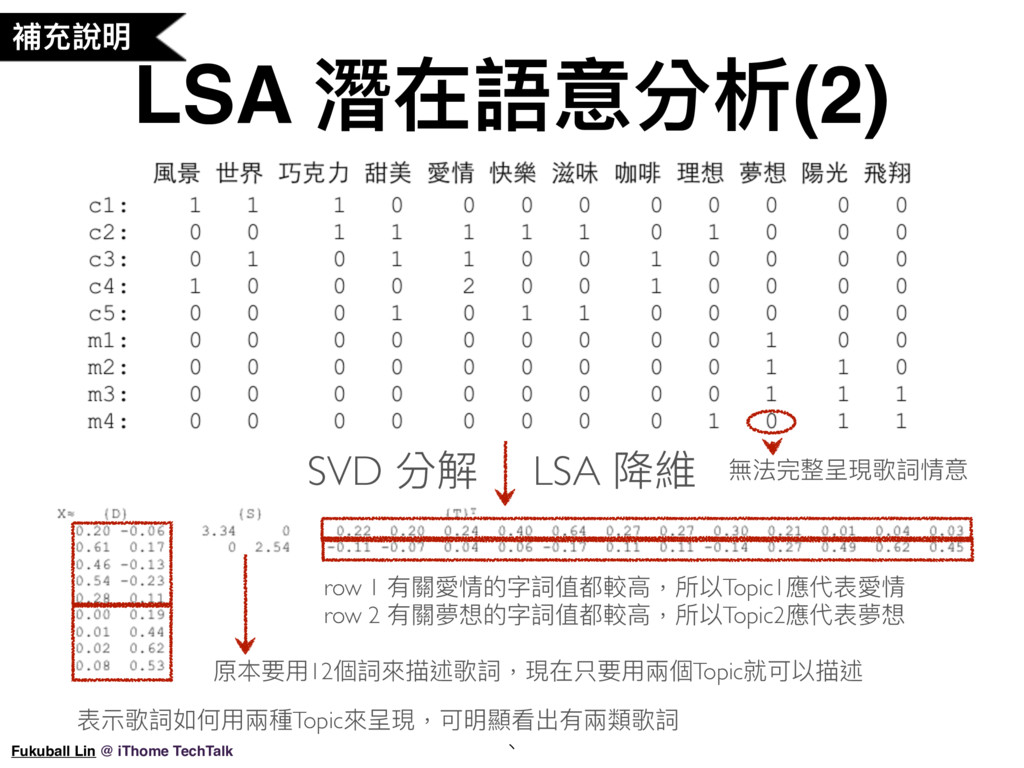
59. 相似歌詞推薦系統大致的開發訓練流程如下:第一步,我們使用結巴中文斷詞將斷好詞的歌詞集合成一個資料集;然後我們需要去掉一些無用的停用字;接下來將每首歌詞做 encoding,把歌詞轉成用向量來表示;接下來使用 LSA 語意分析演算法進行降維,讓歌詞的潛在語意被凸顯出來;最後我們就可以使用 cosin similarity 來計算歌詞之間的相似度了。我這邊使用了 gensim 套件處理步驟 2-5,但全部自幹也不算太難。
因此完成這個訓練之後,我們就可以輸入一首歌詞,讓系統能夠推薦出語意相似的歌詞。
60. 這是剛才輸入的歌詞:楊培安的「我的驕傲」,推薦出來的結果很理想,前五名是:「楊培安 我的驕傲」、「五月天 倔強」、「張雨生 我的未來不是夢」、「五月天 憨人」、「五月天 一顆蘋果」基本上都是有關「夢想」、「不放棄」、「勵志」相關的歌曲。
61. 如果我們把歌詞攤開來看,我們的確可以感覺到歌詞中的語意是很相似的(分析歌詞)
62 - 64. LSA 說明
65. 我們再展示一個例子,輸入周杰倫的「安靜」,推薦出來的結果很理想,前五名是:「周杰倫 安靜」、「黃品源 那麼愛你為什麼」、「孫燕姿 我不難過」、「陳奕迅 婚禮的祝福」、「周杰倫 斷了的弦」基本上都是有關「失戀」、「分手」、「心碎」相關的歌曲。
66. 以上我們展示了如何應用中文斷詞到實作一個簡單的相似歌詞推薦系統,接下來我們來看一些其他有趣的議題。
67. 網路上有人問「下雨天留客天留我不留」及「海水朝朝朝朝朝朝朝落;浮雲長長長長長長長消」會有什麼樣的斷詞結果,我們可以來實際試一下看看。
其實這樣的問題各種斷法都有其意義,因此不太算是中文斷詞需要去解決的問題。
68. 另外,從使用結巴的經驗來看,結巴對於新詞辨識的表現還算不錯,但對於歧異詞辨識可能還需要加強,有時會出錯。
歧異詞辨識前最有效的解法是使用 Deep Learning LSTM 模型來處理斷詞,我自己也有訓練出一個簡體中文的斷詞模型,能夠比較有效的解決歧異詞辨識的問題。
69. 這就是我今天這個講題所有的內容,希望大家都有得到收獲,如果有問題可以現在發問,或者用上面這些方式與我聯繫,謝謝!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Virtualenv 安裝與使⽤用 $ [sudo] pip install virtualenv $ virtualenv ENV](https://files.speakerdeck.com/presentations/9e8807ab2bde401c867acfbec757baf6/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}