iNDIEVOX Open Data 及 API 是近期 iNDIEVOX 開源出來的資料集,iNDIEVOX 使用了這些資料做出了一些有趣的智慧音樂應用,在這次的分享當中我會詳細介紹,並說明一下如何使用這些資料。
1.各位老師、各位同學好,今天要跟大家分享的主題是 iNDIEVOX Open Data 及 API 智慧音樂應用。
2. 好,那跟各位介紹一下我自己,我是林志傑,網路上常用的名字是 Fukuball,所以各位可以用 Fukuball 這個關鍵字找到我。我目前在 iNDIEVOX 獨立音樂網工作,而今天的主題也就是我在 iNDIEVOX 工作時做的一些音樂分析實驗,應該對各位的研究也會有些幫助。
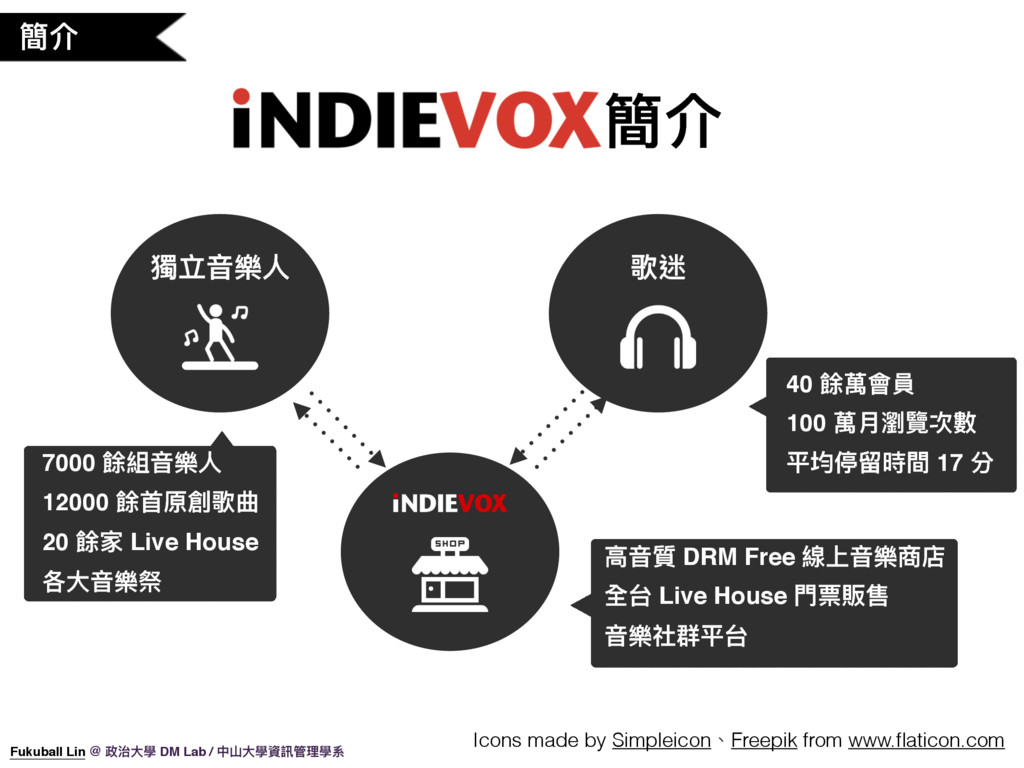
3. 首先跟大家介紹一下 iNDIEVOX,iNDIEVOX 是怎樣的一家公司呢?
4. iNDIEVOX 這個網站主要專注於台灣獨立音樂相關的電子商務服務,獨立音樂人可以在這邊上傳他們的作品、或販售演唱會票券,樂迷就可以在這邊直接購買到創作者的數位音樂及演唱會票券,我們希望透過這個平台,讓台灣的獨立音樂生態可以像國外的獨立音樂那樣完善。歡迎大家有空也可以到 iNDIEVOX 上面逛逛、聽聽音樂~
5. 很多人會問,要讓台灣的獨立音樂跟歐美日一樣蓬勃,iNDIEVOX 只做數位音樂及演唱會門票販售這樣夠嗎?
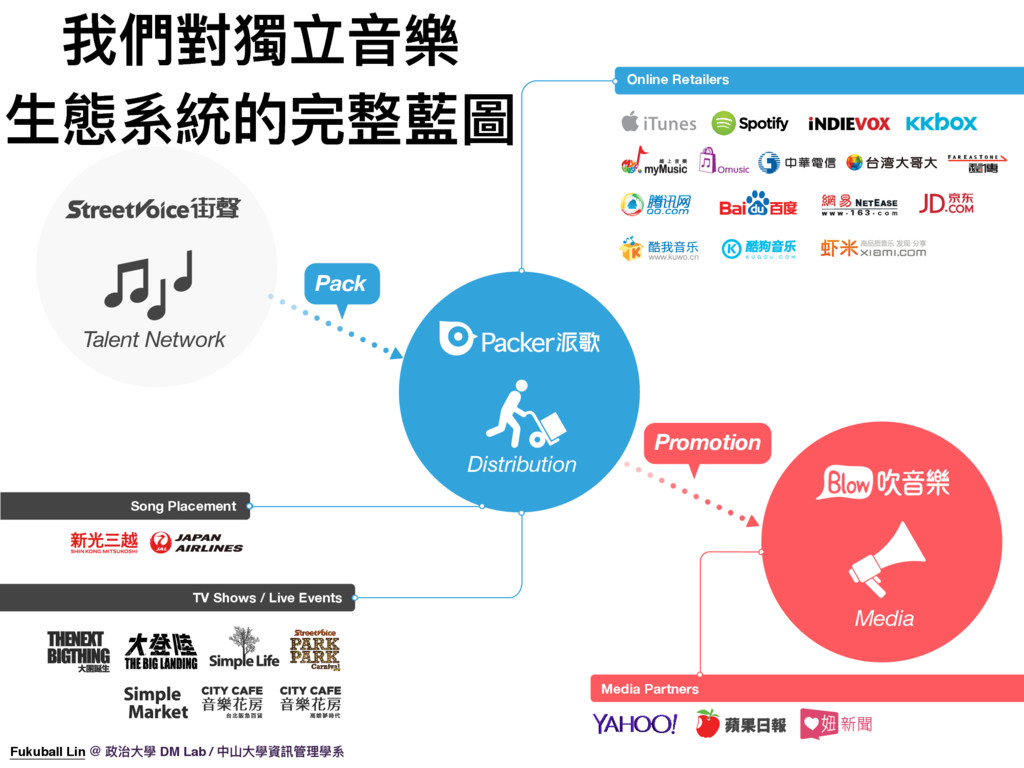
6. 其實,當然不夠。所以我們公司對整個獨立音樂生態系統的完整藍圖是這樣的。iNDIEVOX 目前屬於中子文化集團的一員,我們集團底下還有 StreetVoice、Packer、Blow 等等服務。StreetVoice 主要專注於獨立音樂社群,還未成熟的獨立音樂人可以在這邊發表作品、互相交流,大家可以把 StreetVoice 想成是華人世界的 SoundCloud。而當獨立音樂人的作品更成熟了,我們有 Packer 這個服務來將音樂人的作品發佈到各種線上音樂服務比如 iTunes、Spotify、iNDIEVOX 以及 KKBOX、甚至中國的蝦米、百度。而我們公司也會提供各種線下的資源,比如音樂節的演出機會,像是簡單生活節、音樂花房以及見證大團,讓這些獨立藝人可以用線下的方式與歌迷們互動。最後,我們還自創了音樂品牌媒體吹音樂,致力於宣傳獨立音樂相關新聞,而我們目前也是 Yahoo! 音樂及蘋果酷音樂的合作夥伴,在音樂線上媒體這個部分非常有影響力,也因此可以將好的獨立音樂推銷出去。
7. 所以 iNDIEVOX 只是完整獨立音樂生態系統中的一小塊,大家可以把我們網站想成是一個獨立音樂的電子商務平台,所以其他部分我們需要跟其他服務一起合作,這樣我們才可以專注於做好獨立音樂的電子商務。
8. 當然,我們今天只談智慧音樂這一塊。
9. 那麽,所謂的智慧音樂是否就跟最近很有名的 PPAP 一樣把智慧與音樂加在一起就是智慧音樂了呢?其實簡單說是這樣沒錯,智慧音樂應用通常就是把機器學習、資訊萃取、資料探勘等方法應用在音樂系統服務上,藉此來創造出能讓人們覺得系統很聰明的音樂系統應用。
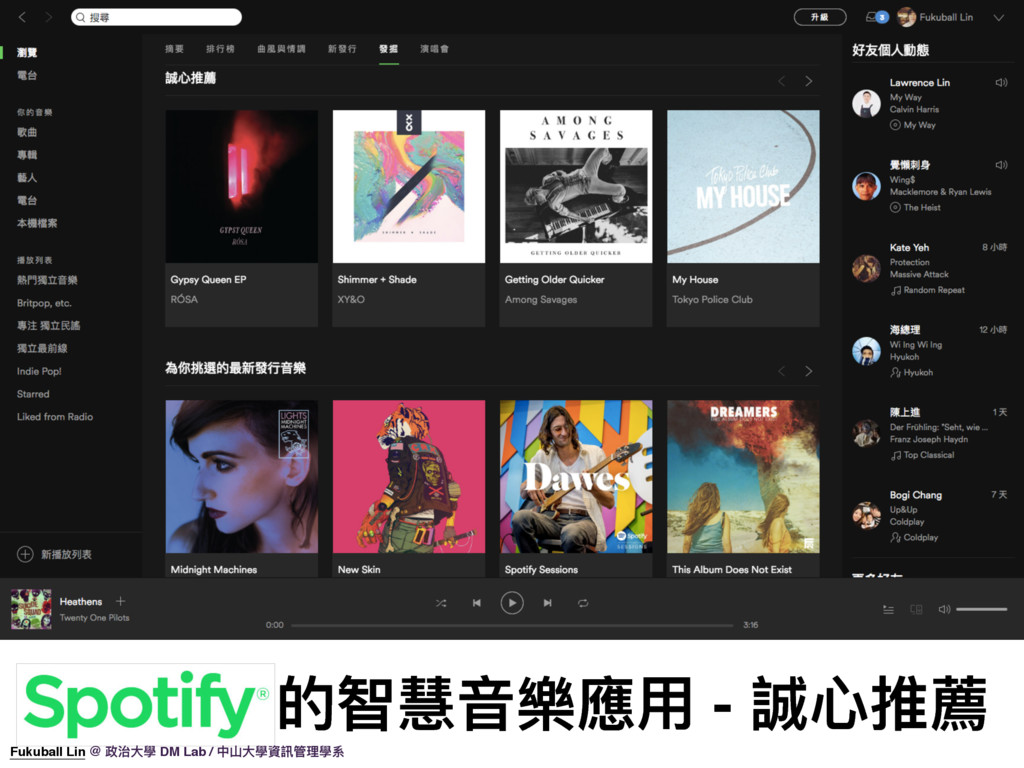
10. 用說得很模糊,所以我們可以看看一些智慧音樂應用的例子,比如說國外知名音樂網站 Spotify 「誠心推薦」這個功能就是一種智慧音樂的應用,他會根據你聽過的音樂去做相應的推薦。
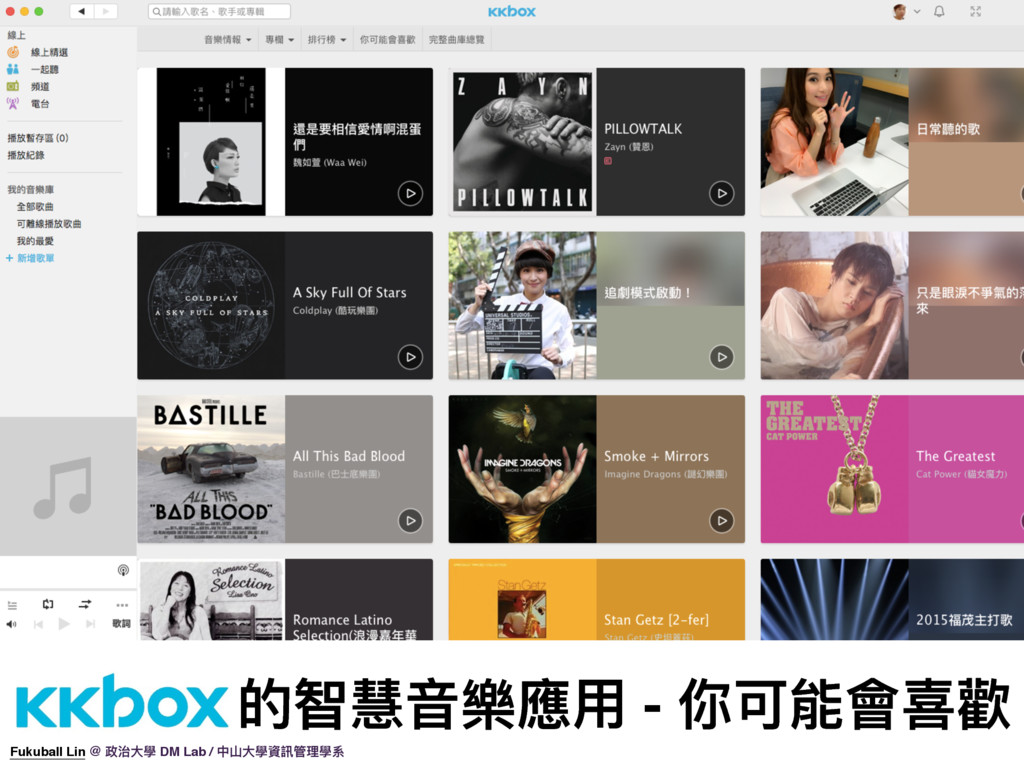
11. 而國內的知名音樂網站 KKBOX 也有智慧音樂功能,像是「你可能會喜歡」這功能就是一個智慧音樂的應用,如果大家有在使用以上音樂網站,可能都會在使用這些功能的時候感到驚訝,感覺系統好像真的能夠知道自己的喜好來推薦音樂,這都是因為系統背後的機器學習演算法運算的結果。
12. 為何現在的多媒體娛樂網站都要發展智慧系統呢?根據 Netflix 的研究,如果不能在 90 秒內抓住使用者的注意力,讓使用者選擇到他想要看的影片,那麼下個月這位使用者就可能不會繼續訂閱,Netflix 就會失去這名使用者了。這件事情攸關 Netflix 的盈利,所以 Netflix 一直都在發展更好的影片推薦系統。Netflix 深知智慧推薦的重要性,所以還開了 Netflix Prize 吸引各路 Machine Learning 好手參與推薦系統競賽,如果能夠改善系統的推薦準確性,Netflix 就提供 100 萬美金的獎金!可見 Netflix 對智慧推薦系統的重視!
13. 當然,iNDIEVOX 也有智慧音樂系統!而且據我所知發展的時間可能還比 KKBOX 早!
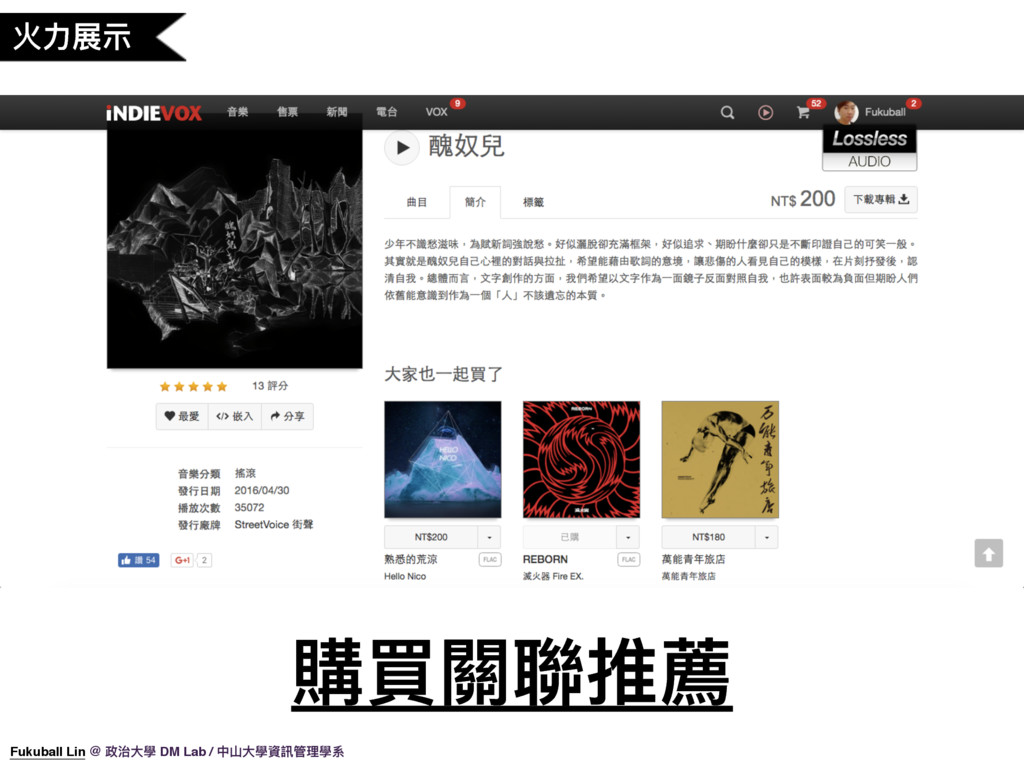
14. 我們稍微來火力展示一下,首先是購買關聯推薦,這個智慧音樂功能我們是使用歌曲與歌曲之間或專輯與專輯之間共同購買的關聯性來做計算推薦的,這樣推薦出來的結果通常較為多元,會有曲風相類似的歌曲,比如這個例子的萬年青年旅店,也會有近期熱門的歌曲,比如這個例子中的 Hello Nico、滅火器。我們讓專業音樂編輯看了推薦的結果,也覺得這個推薦準確度相當高。讓我們來實際前往網站看一下。
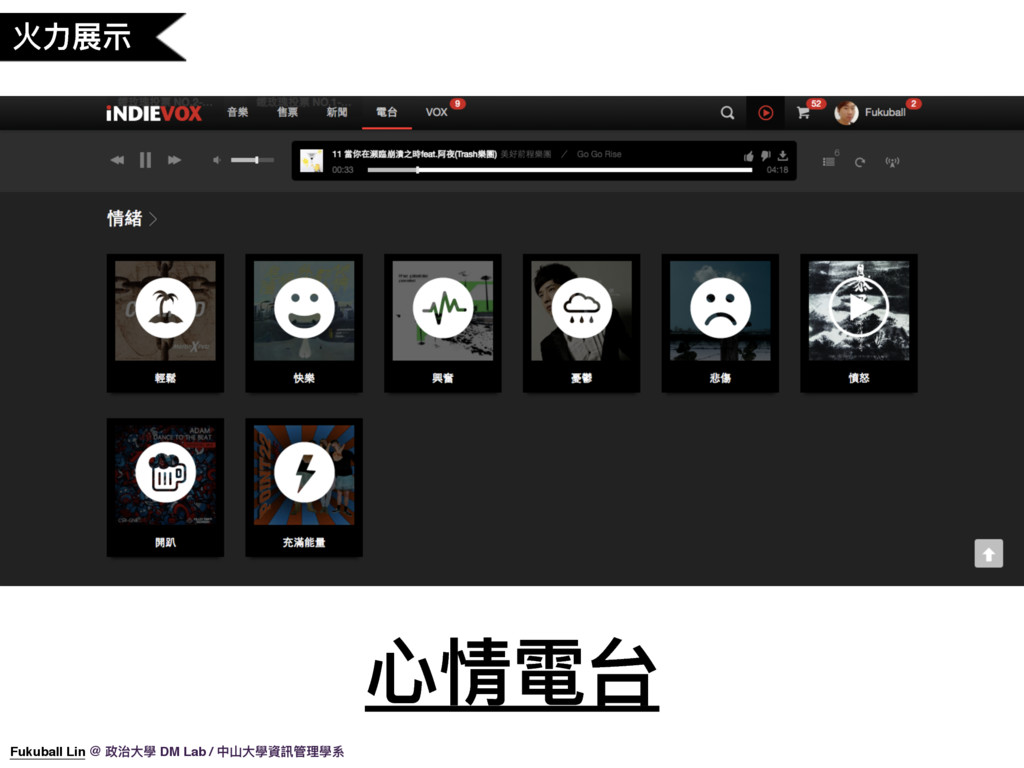
15. 再來是心情電台,由於 iNDIEVOX 上面的內容幾乎都是較為冷門的音樂,平常有在聽獨立音樂的人可能可以使用曲風來找自己想聽的音樂,但對於一般使用者,曲風分類對他們來說還是太難,像是雷鬼、放客、龐克、藍調等等,這些他們可能都不知道什麼,也就很難在我們網站上找到想聽的音樂,我們使用機器學習方法分析音訊,來將音樂分成輕鬆、快樂、興奮、憂鬱、悲傷、憤怒等心情類型,由於心情這樣的詞彙對於一般使用者比較直覺,這樣的心情電台也開啟了一般使用者接觸獨立音樂的一個更友善的管道。讓我們來實際前往網站看一下。
16. 最後是我們最近完成還在實驗中的 VA 心情 DJ 電台,VA 的意思分別代表 Valence 跟 Arousal,Valence 代表情緒的正向程度,在這個平面上越右邊就代表越正面、越左邊就代表越負面,然後 Arousal 代表情緒的強度,在這個平面上越上面就代表越強烈、越下面就代表越平靜。這個模型可以將情緒表示成一個座標平面,讓情緒可以用一個二維數值來表示,用以表達更多元的情緒,比如右上方的部份可能就是快樂、興奮等情緒,左下方的部份可能就是悲傷、憂鬱等情緒,我們可以像 DJ 一樣,用這個平面調整心情電台播放歌曲,這樣的功能除了可以用來挑歌單之外,對於一般使用者也是一個接觸獨立音樂的友善管道。讓我們來實際前往網站看一下。
17. 好,看過了這些 iNDIEVOX 的智慧音樂功能,其中的背後技術是怎麼做到的呢?這就是我們今天的主題了~
18. 剛才有說,智慧音樂大概就是智慧與音樂的結合,智慧的部份指的就是機器學習演算法,這邊我們使用了 fuku-ml 及 Apriori 這兩個套件。fuku-ml 是我個人開發的一個機器學習套件,與其他機器學習套件比較來較為簡易使用,目前已支援 Perceptron、Regression、Logistic Regression、Support Vector Machine、Decision Tree、Neural Network 等知名的機器學習演算法。然後 Apriori 是我從網路上找來個一個套件,可以用來計算購買關聯性。音樂的部份,其實就是指 Datasets,這邊我們是使用 iNDIEVOX-Dataset,這是 iNDIEVOX 近期開源出來的 Open Data 及 API,我們幾乎沒有看到台灣的軟體公司或是開發者在 Datasets 這一塊有開源貢獻,所以 iNDIEVOX 就拋磚引玉開源了 iNDIEVOX Datasets。只要結合這些演算法以及資料集,我們就可以做到剛剛介紹的智慧音樂系統!
19. 今天會介紹的所有內容我都有把範例程式碼放到 GitHub 上面去了,如果大家有興趣也可以上去載下來玩玩看。
20. 首先我們來看看購買關聯推薦怎麼做到。
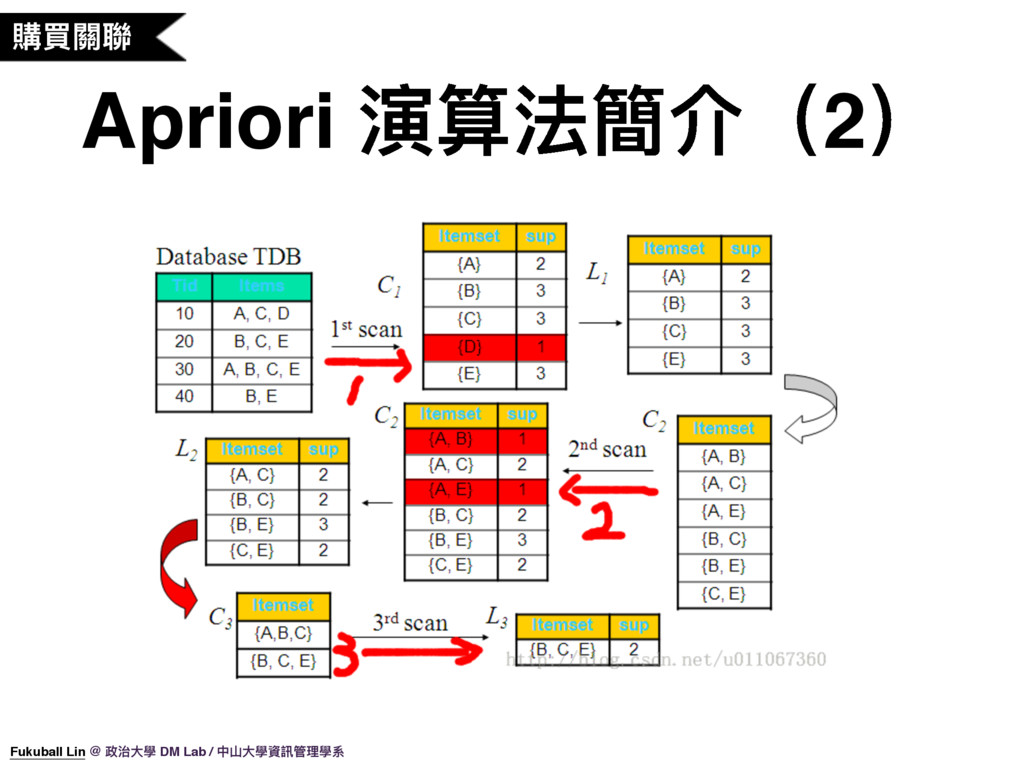
21. 其實購買關聯推薦的背後演算法就是使用 Apriori 演算法,Aprior 是一個非常知名的關聯規則演算法,我在這邊稍微簡介一下。所謂的關聯規則就是符合「支持度」及「信任度」的交易品項集合,支持度就是計算品項 A 與 品項 B 同時出現在交易中的機率,信任度就是計算交易中有品項 A 然後也會有品項 B 的機率。如果支持度太低其實就沒有什麼代表性,信任度太低作為共同推薦就不夠準確。我們會設定支持度及信任度的機率門檻值,高於我們所設定門檻的集合某種程度就具有關聯性,Apriori 可以快速計算符合「支持度」及「信任度」的交易品項集合。
22. 我們可以用這個圖示來說明 Apriori 的計算過程,在圖中我們總共有 4 筆交易,便於說明,我們設定的支持度是 2 筆紀錄就代表符合支持度。Apriori 會以 buttom up 的方式計算出子集合的支持度,慢慢將所有符合支持度的子集合算出來。(看圖說明)過程中我們也會計算信任度,比如 B 這個子集支持度是 3,BC 這個子集合的支持度是 2,那 B 推薦 C 的信任度就是 2/3。BE 這個子集合的支持度是 3,那 B 推薦 E 的信任度就是 3/3。如果我們設定的信任度門檻值是 70%,那麼 BE 就是符合我們設定條件的關聯歸則。
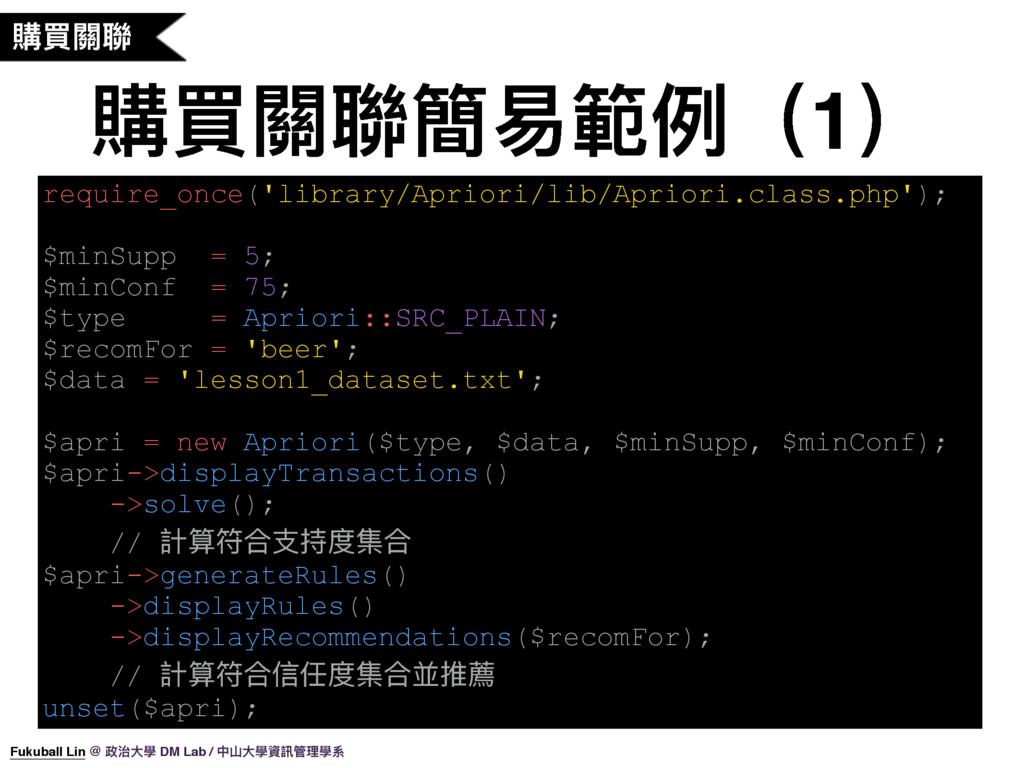
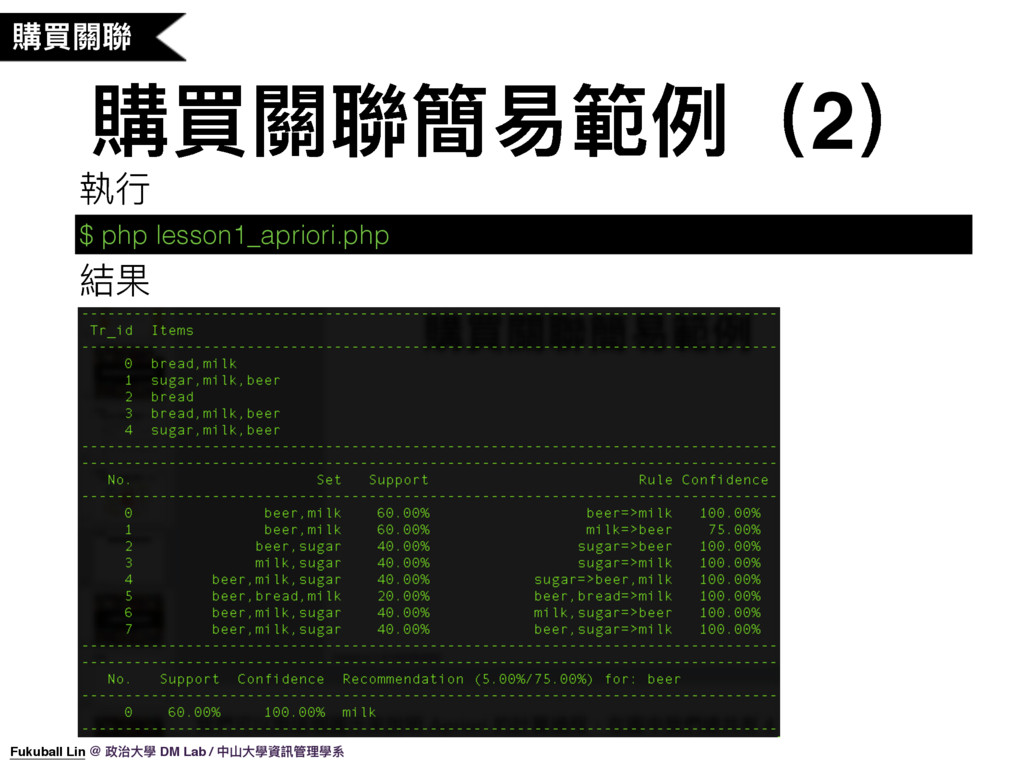
23. 那我們實際來使用一下 Apriori 計算關聯規則,這是我寫好的一個 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)
24. 好,這就是我們剛剛執行程式的結果,如果要推薦使用者買了 ‘beer’ 還要再買什麼,我們可以從關聯規則中推薦出 milk。
25. iNDIEVOX 購買關聯就是用 Apriori 及 Buy Together Discs Dataset 和 Buy Together Songs Dataset 實做出來的,我在這邊沒有辦法實際跑一次給大家看,不過可以告訴大家,實務上支持度及信任度都要設很低才跑得出結果,會有這樣的情況主要是因為交易資料品項非常多,關聯規則較為稀疏的關係。
26. 接下來我們來看看心情電台是怎麼做到。
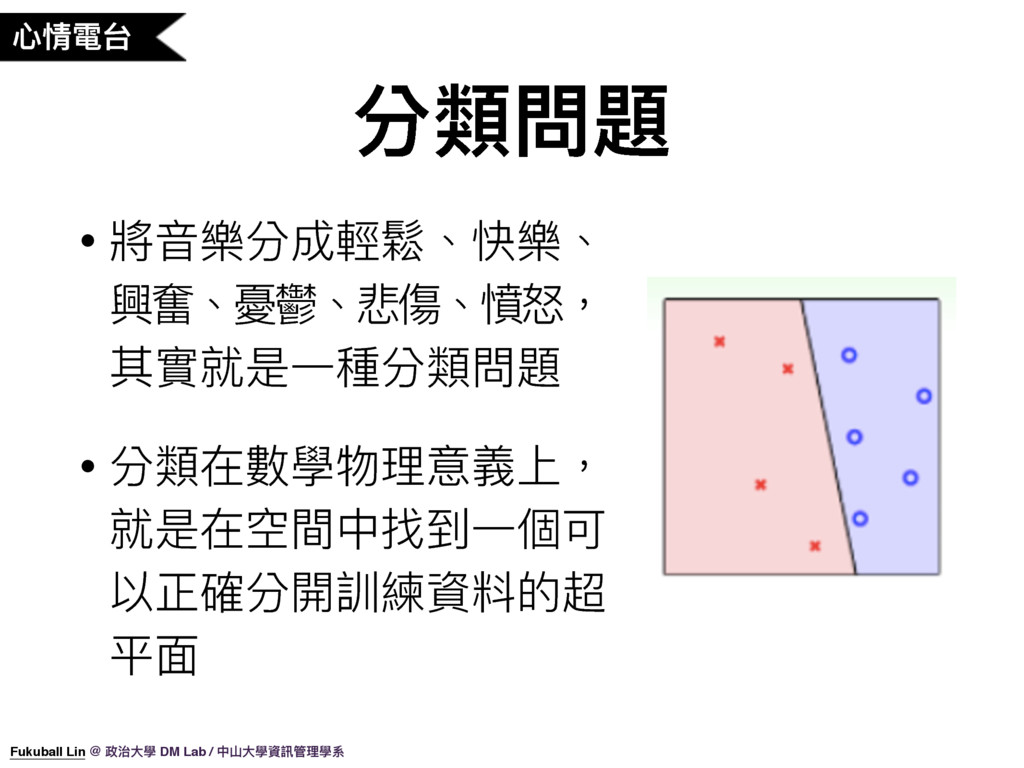
27. 心情電台主要分成輕鬆、快樂、興奮、憂鬱、悲傷、憤怒六個頻道,將音樂分成六個頻道其實就是一種分類問題。分類在數學物理意義上,就是在資料空間中找到一個可以正確分開訓練資料的超平面,以二維平面來說,我們可以將資料依據特徵值放進平面對應的位置,然後將資料分類的標示以 x 或 o 來表示,我們要訓練電腦找出可以正確分類的線出來,未來就可以用這條線來預測新資料的分類。
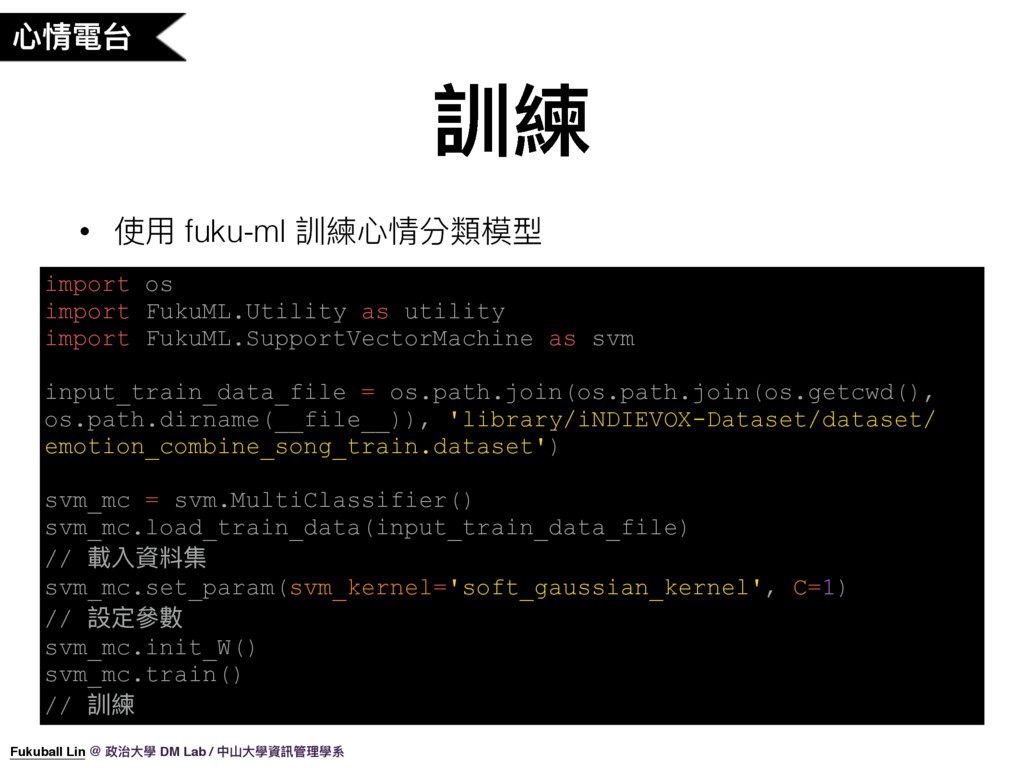
28. 其實機器學習中用來分類的模型有很多,在心情電台這個功能我們是使用 Soft Gaussian SVM 這個模型。SVM 這個模型具有不易 overfitting、雜訊容忍度較高的特性,所以我們選用了這個模型來實作心情電台這個功能。
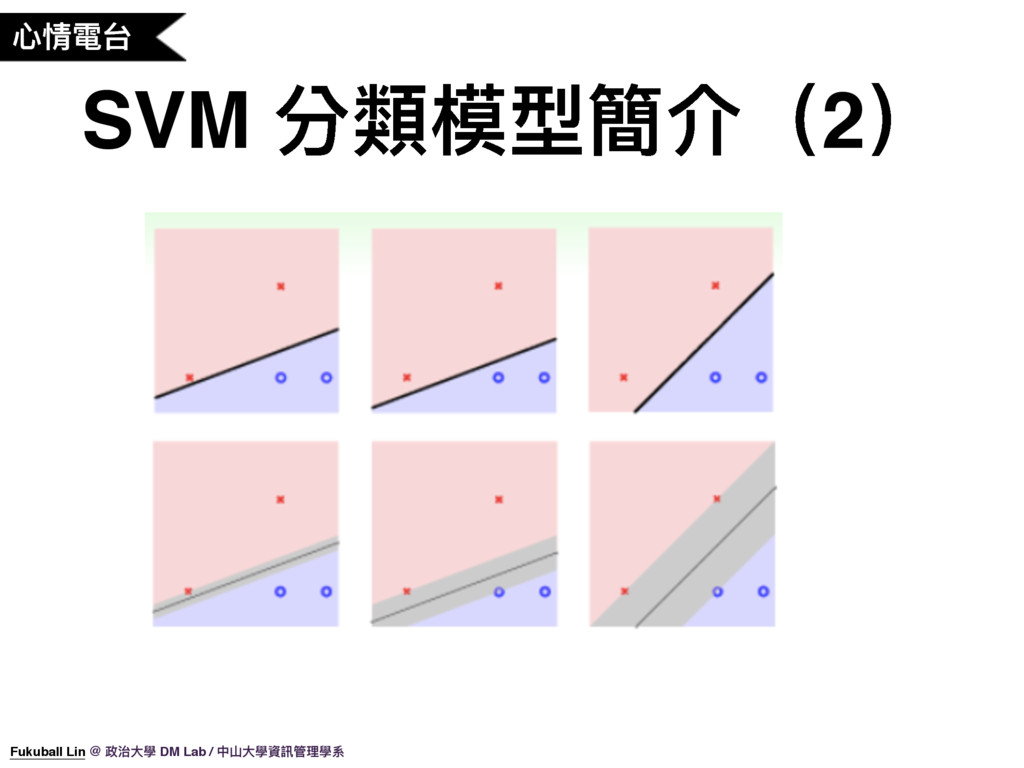
29. 我們可以用這些圖示來說明 SVM 的特性,像上面三張圖,我們可以在平面中找到無限多條線來將資料分類開來,但哪一條線才是最好的呢?有些分類演算法並沒有辦法決定哪條線是最好的,所以會隨機選擇一條線出來。但依我們直覺,我們會發現當新的資料進來的時候,最左邊的線有可能會因為雜訊而將分類分錯,最右邊的線則比較能容忍一些雜訊。而 SVM 演算法的目的就是在訓練過程中找出一條最胖的分類線,也因此可以找到圖示中最右邊的線,所以對於雜訊的容忍度就會比較高。
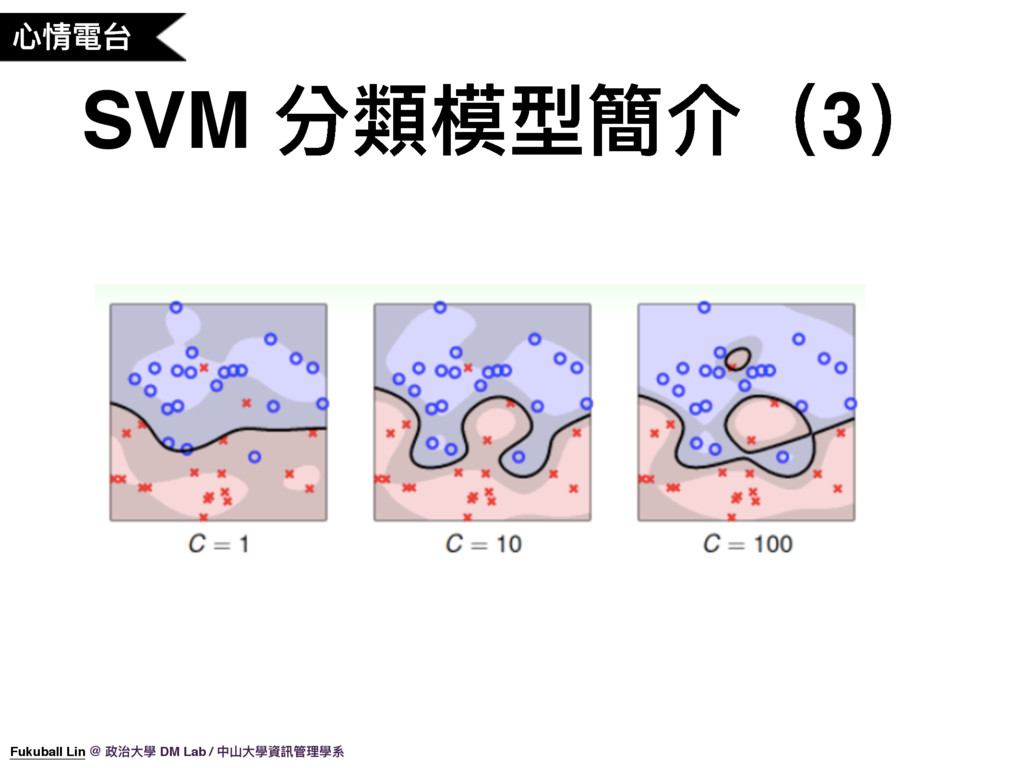
30. 前面有說心情電台這個功能是使用 Soft Gaussian SVM 作為分類模型,Gaussian 是 SVM 的一種 Kernel,不同的 Kernel 可以產生不同的分類線,Gaussian Kernel 就是可以依據訓練資料產生彎彎曲曲的分類曲線。而 Soft 就代表模型可以容忍一些分類錯誤,不一定硬要將所有的點都分類好,因為我們拿到的資料常常會有雜訊。 Soft Gaussian SVM 有一個 C 參數用來調整分類線的自由度,C = 1 時代表自由度較低,可以容忍較多的雜訊,但這樣可能會無法將資料好好分類(很多資料分錯),當 C 越高時自由度越高,Gaussian 曲線可以做越出越彎曲的線,這對複雜的資料做分類可能會有用。但當 C 調得太高了,Gaussian 曲線就會去模擬雜訊,這樣對於未來做預測可能會不準確,這就是所謂的 Overfitting。
31. 從剛剛看來,Soft Gaussian SVM 的 C 參數如果調得太低,可能會沒辦法正確分類資料,C 如果調得太高,那又可能會模擬到雜訊。所以怎麼調參數就是一個問題。這邊學術上發展了一個叫 Cross Validation 的方法來驗證哪個參數比較好。Cross Validation 訓練模型時,會將訓練資料分成 10 份,每次訓練時將一份留下來做驗證,其他用來做訓練,重複將 10 份資料全部做過一遍再算平均準確度。Cross Validation 準確率較高的參數理論上在未來做預測時也會表現比較好。
32. 我們這邊沒辦法詳細介紹 SVM 的演算法,但了解了 SVM 的特性其實就可以知道怎麼使用 SVM 了。接下來就是使用 SVM 跑完一個完整的機器學習流程。完整的機器學習流程會經過特徵萃取、產生資料集、訓練、Cross Validation 及最後的預測,我們一個一個步驟帶大家走過一遍。
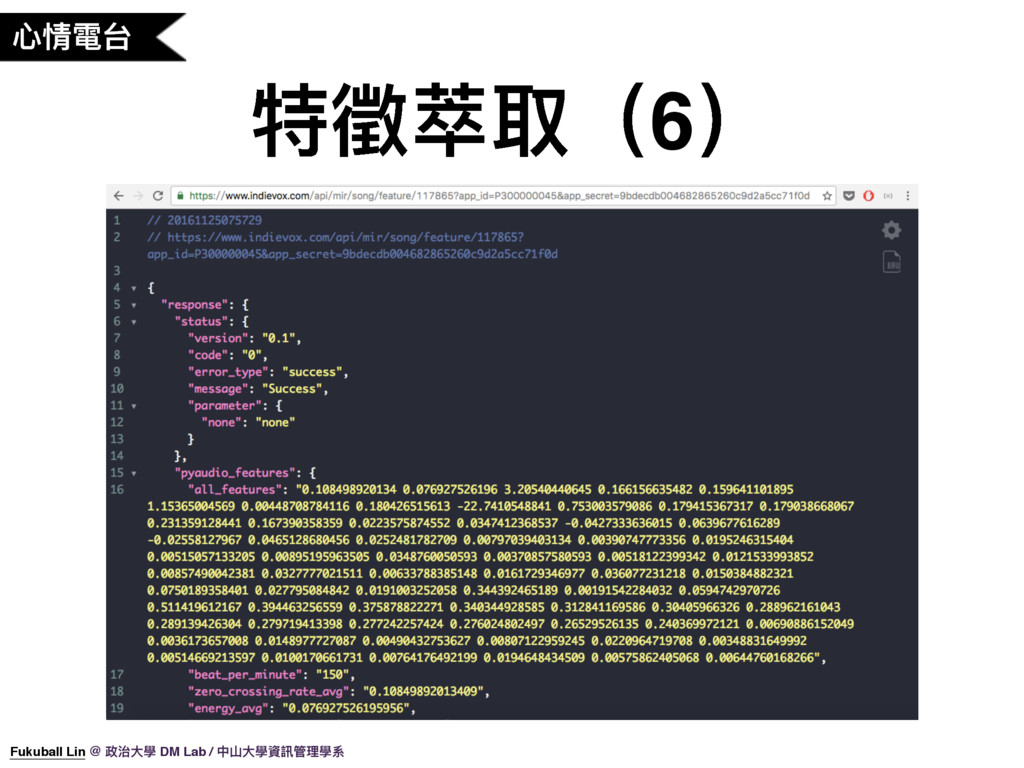
33. 首先我們需要將音樂轉換成一個向量來方便做運算,這個轉換成向量的過程就是特徵萃取,特徵萃取的工具我們是使用 PyAudio,但我們這邊不能直接透露我們使用了 PyAudio 的哪些參數,所以會利用 iNDIEVOX 的上傳音樂功能來萃取音樂特徵,再透過 API 取得特徵值。
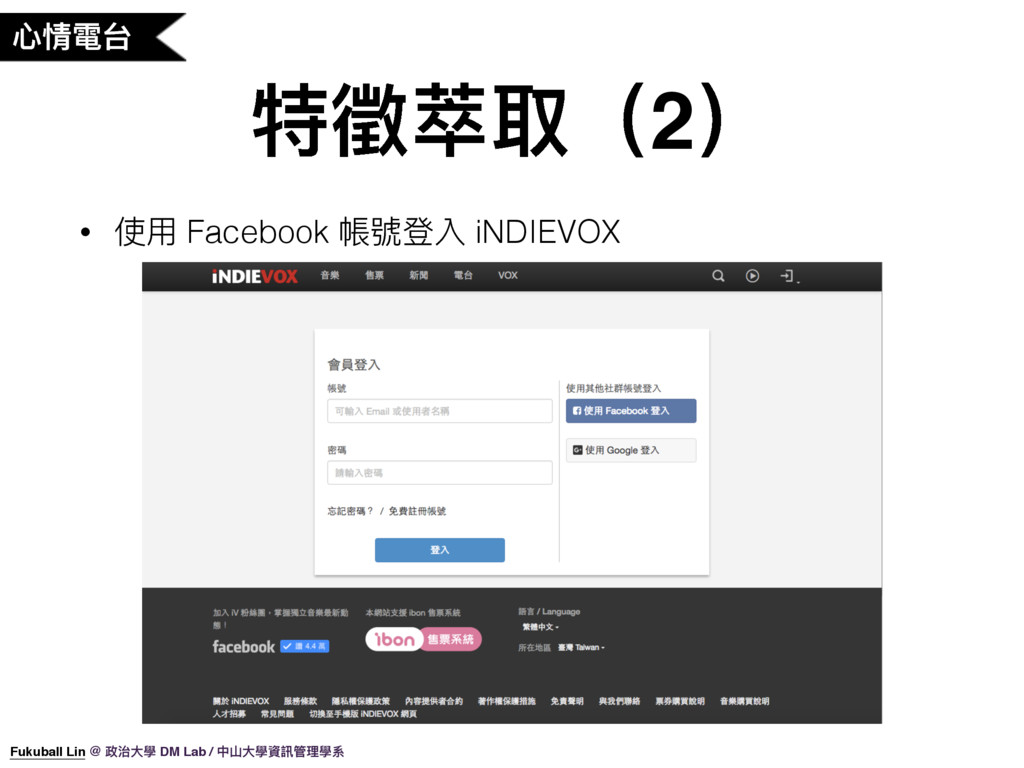
34. 第一步,使用 Facebook 帳號登入 iNDIEVOX
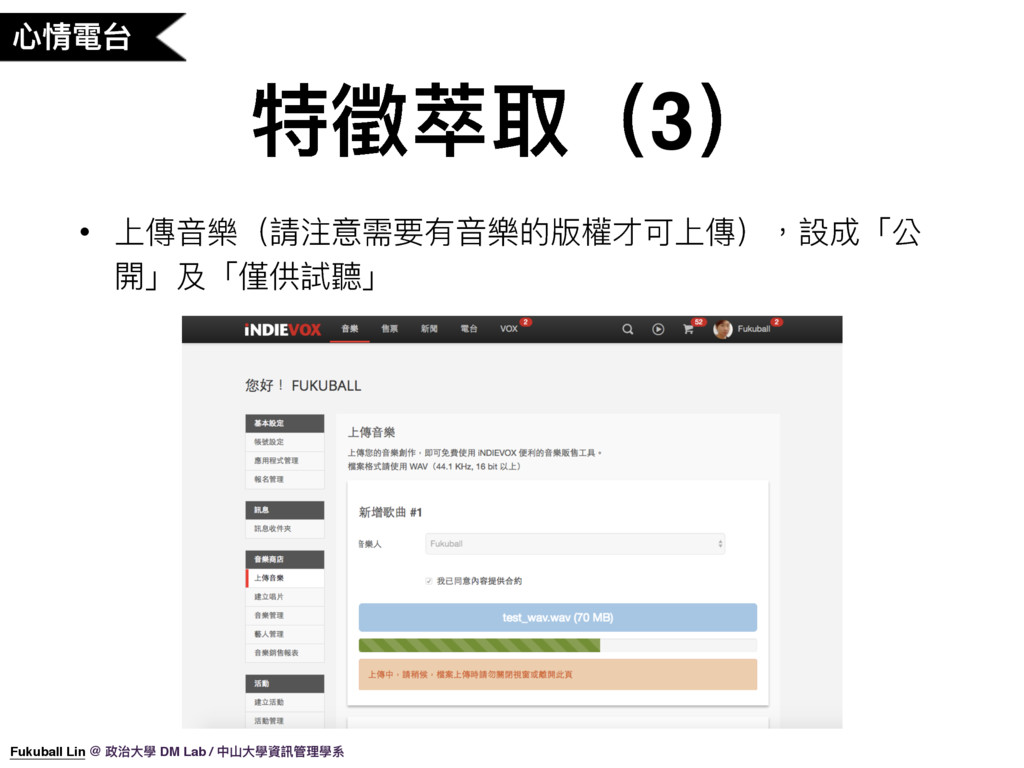
35. 第二步,上傳音樂,不過請注意需要有音樂的版權才可上傳,否則會有侵權的疑慮,上傳後填好資料,請將歌曲設成「公開」及「僅供試聽」
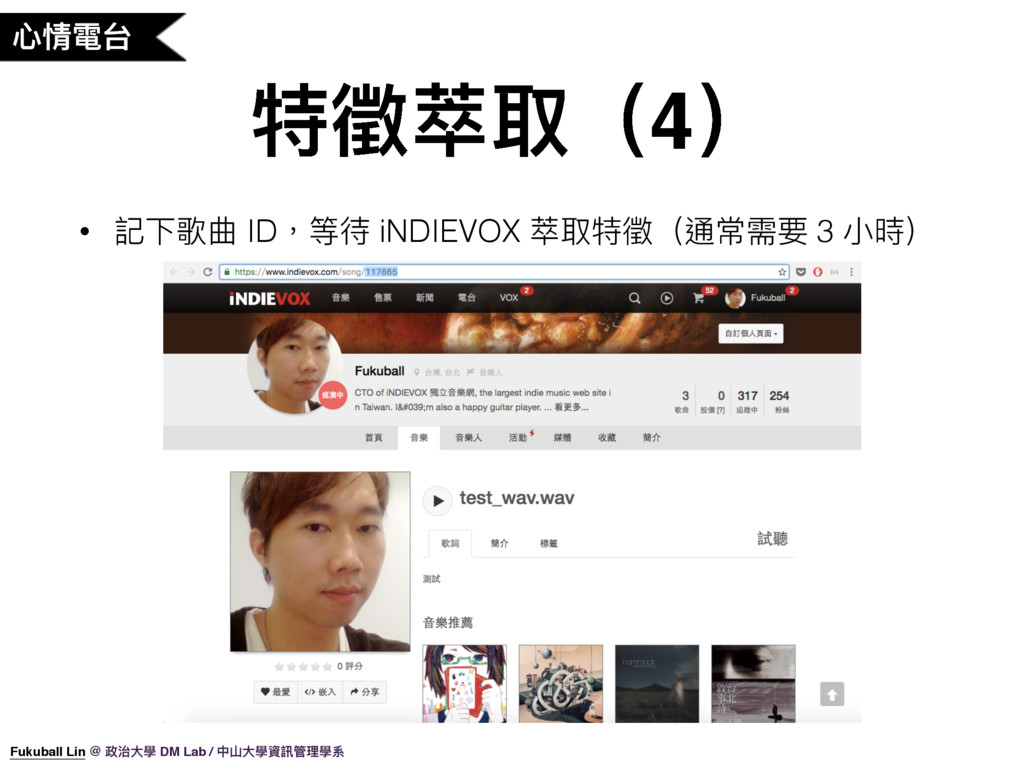
36. 第三步,記下歌曲 ID,等待 iNDIEVOX 萃取特徵,通常需要 3 小時左右才會完成
37. 第四步,透過 iNDIEVOX Open API 取得特徵值
38. 其中的 all_features 就是我們會拿來使用的音樂特徵值,共有 68 維的特徵
39. 音樂特徵萃取好之後,我們就可以將這些資料組合成一個訓練資料集。由於這邊我們是要解一個分類問題,在組成訓練資料集時,就需要將資料上標籤,這邊我們就是要為歌曲標上分類。我們使用 1 代表輕鬆、2 代表快樂、3 代表興奮、4 代表憂鬱、5 代表悲傷、6 代表憤怒,如果覺得這首歌曲聽起來感覺是快樂的,那就標上 2。將多筆資料組合起來就可以成為一個心情資料集,大家可以自己組一個資料集出來,在這邊我們可以直接使用 iNDIEVOX 開源出來的 Emotion Combine Training Dataset。
40. 有了訓練資料集之後,我們就可以丟進去 fuku-ml 的 SVM 去做模型訓練。
41. 如果想嘗試調整參數,可以使用 cross validator 來幫助選擇使用什麼參數。
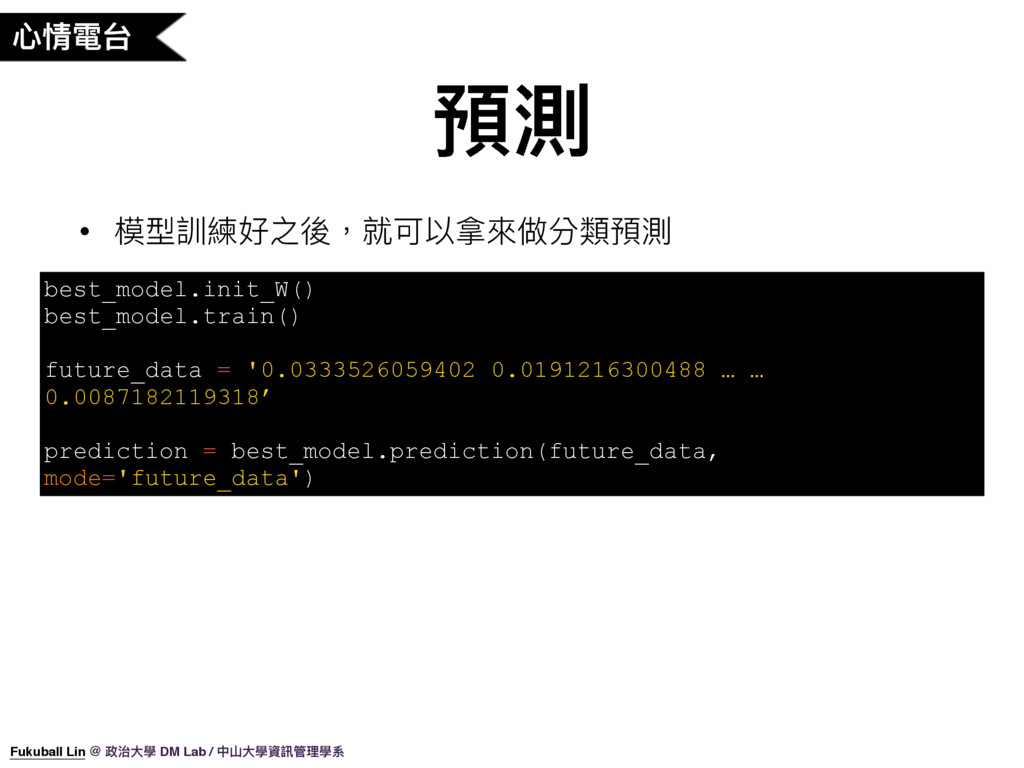
42. 模型訓練好之後,我們就可以拿來做分類預測了。
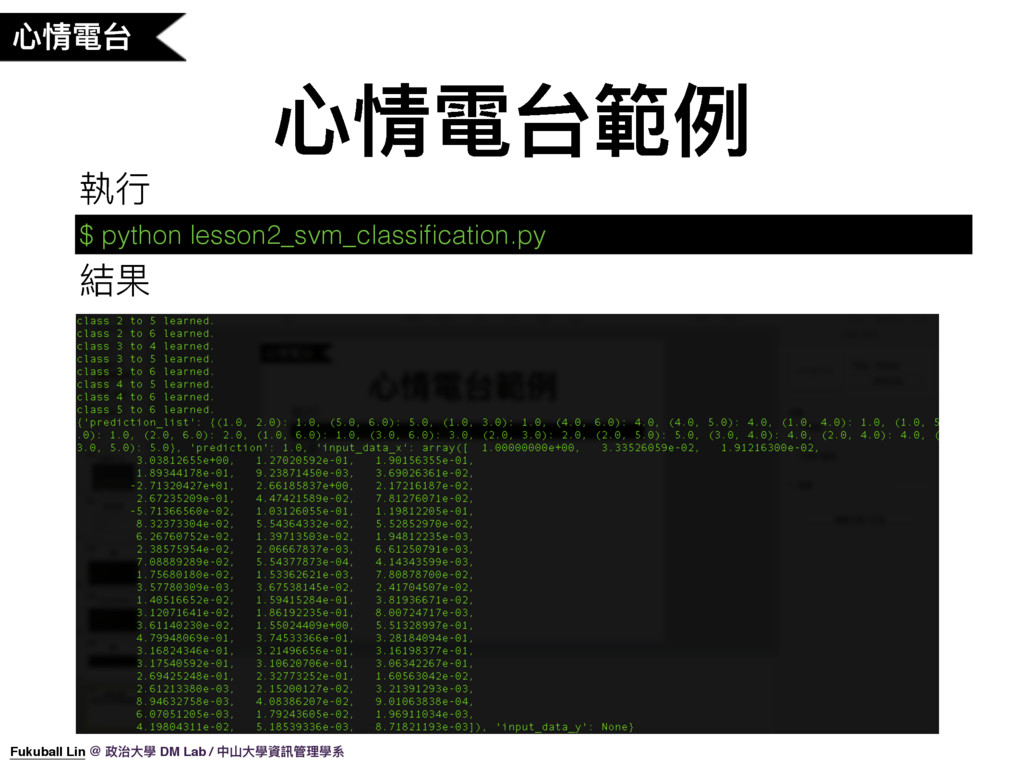
43. 那我們實際來使用這個 Dataset 來訓練一個音樂心情分類模型,我有寫好的一個 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)好,這就是我們剛剛執行程式的結果。
44. 最後讓我們來看看 VA 心情電台是怎麼做到。
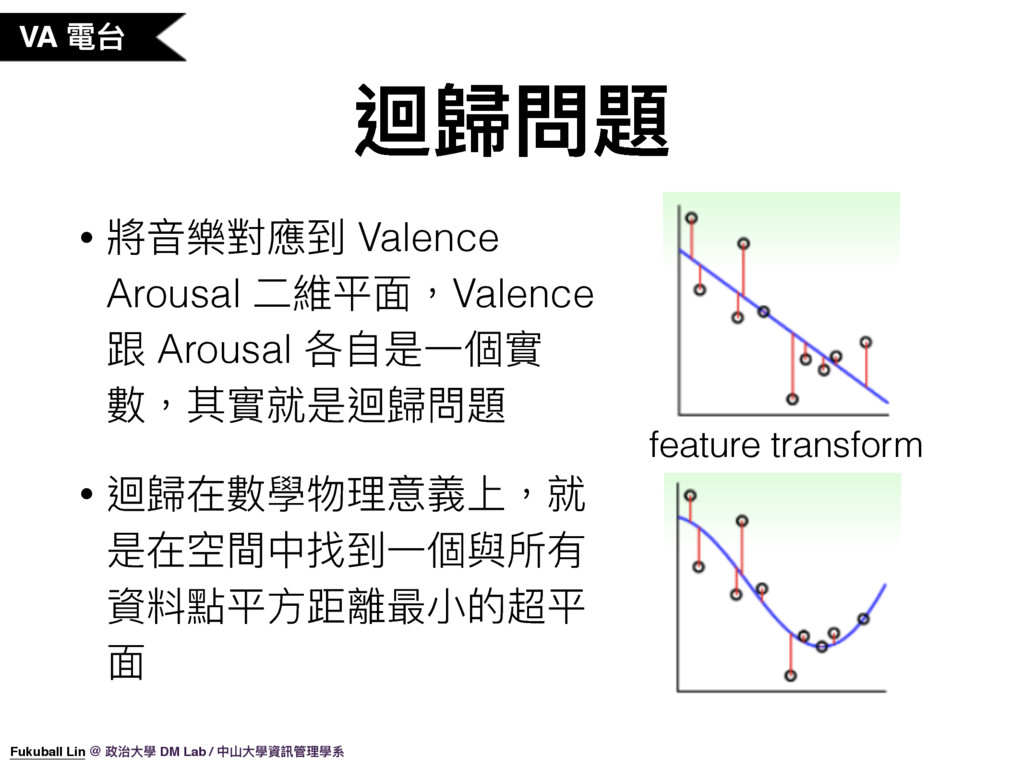
45. 在 VA 心情電台這個問題,我們是將音樂對應到一個 Valence Arousal 的二維平面,我們先將 Valence Arousal 分開來看,在 Valence 這邊,我們希望能夠依據音樂特徵預測出音樂的 Valence 值,這樣其實就是一個迴歸問題。因此我們會分別對 Valence 及 Arousal 做迴歸訓練。而所謂迴歸在數學物理意義上,就是要在空間中找到一個與所有資料點平方距離最小的超平面,如右邊的圖片所示。簡單的模型我們可以使用線性模型,我們也可以透過 feature transform 的方法讓迴歸模型做非線性的轉換,這樣就可以用來解更複雜的問題。
46. 由於使用特徵轉換可以讓迴歸解決更複雜的問題,我們可能不小心就會讓模型的複雜度太強,造成左圖這個模擬雜訊 overftting 的現象。所以我們會使用 Ridge Regression 這個模型來避免 overfitting,Ridge Regression 使用了 lambda 這個參數來調整模型的自由度,讓迴歸在做高維的特徵轉換時不會過度模擬雜訊,與 SVM 的 C 參數的效果是相同的,只是 lambda 為 0 代表是自由度最高,可能會有 overffiting 的現象,lambda 越大代表自由度越低,可能會有 underfitting 的現象,剛好與 C 參數的調整方向相反。在 VA 心情電台這邊我們就是使用 Ridge Regression 模型,如此就可以非線性的迴歸模型,然後調整 lambda 避免 overfitting。
47. 我們一樣進行一次完整的機器學習過程來做看看 VA 心情電台。
48. 一樣我們需要先萃取音樂音訊特徵,這邊萃取特徵的方法跟之前的一樣,馬上就可以繼續使用了~
49. 接下來我們需要為資料上標籤,在這邊就是為歌曲標上 Valence 值。Valence 的值域為 0 ~ 1 的浮點數,數值越靠近 0 就代表情緒越負面,越靠近 1 就代表情緒越正面。比如我們可以為這首歌標上 0.4。將多筆資料組合起來就可以成為一個資料集,在這邊我們可以直接使用 iNDIEVOX 開源出來的 Valence Training Dataset。
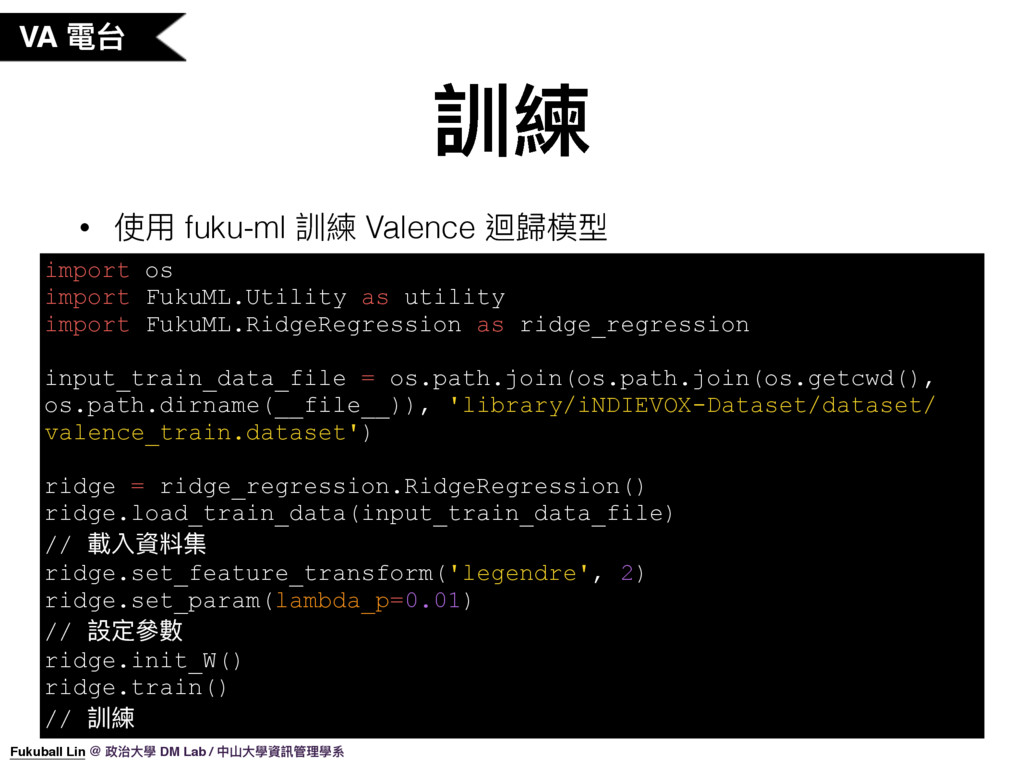
50. 有了訓練資料集之後,我們就可以丟進去 fuku-ml 的 ridge regression 去做模型訓練。
51. 如果想嘗試調整參數,可以使用 cross validator 來幫助選擇使用什麼參數。
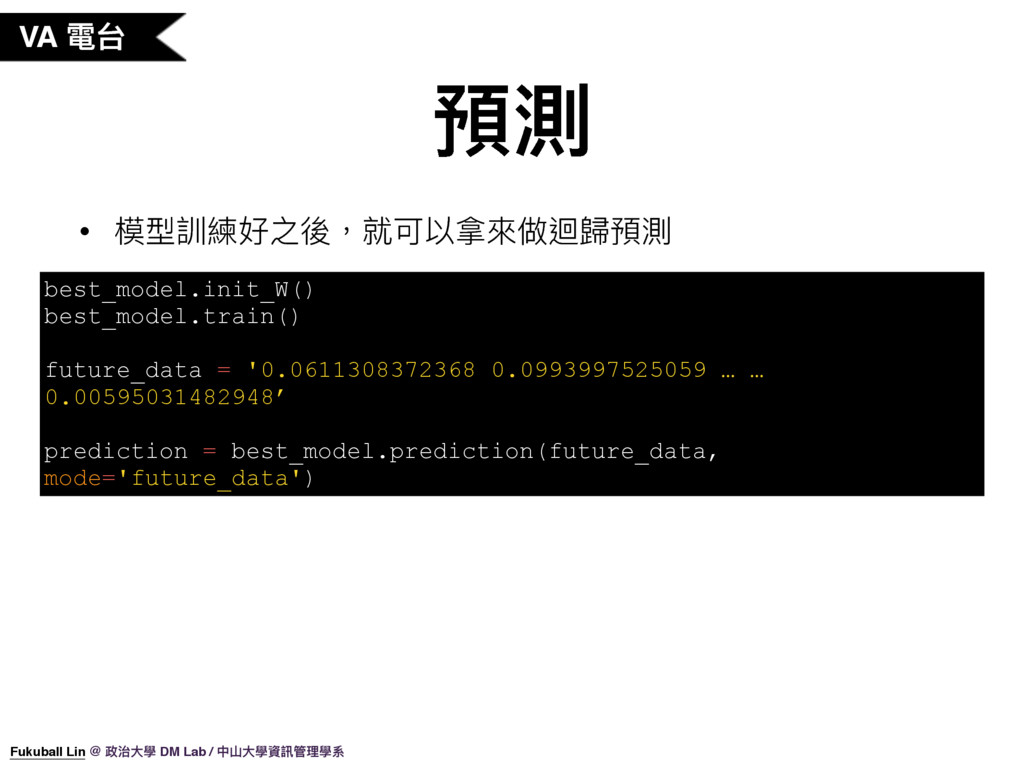
52. 模型訓練好之後,我們就可以拿來做迴歸預測了。
53. 那我們實際來使用這個 Dataset 來訓練一個音樂 Valence 迴歸模型,我有寫好的一個 Sample Code(解釋原始碼),我們來執行程式看一下結果。(開終端機)好,這就是我們剛剛執行程式的結果。了解了如何訓練 Valence 迴歸模型,Arousal 迴歸模型也是同樣的作法就可以完成了。
54. 經過剛剛的講解,大家某種程度應該對如何使用 iNDIEVOX Open Data 及 API 製作智慧音樂系統有一些了解了。
55. 開源 Data 及 API 除了可以提供給有興趣的研究者使用之外,其實也是希望大家可以幫忙貢獻資料。我現在來說明一下如何貢獻資料。首先大家可在 iNDIEVOX 聽音樂。
56. 決定要標示的歌曲之後,透過 iNDIEVOX Open API 取得特徵值。
57. 然後將歌曲標示上心情分類、Valence 值、Arousal 值。像是你啊你啊這首歌我們可能會這樣標示。最後再將標示好的資料放至對應的 Dataset,使用 github 發出 pull request。
58. 只要這樣大家就可以貢獻資料,讓大家有更好的 Dataset 可以使用,一起擁抱開放源始碼!
59. 這就是我今天這個講題所有的內容,希望大家都有得到收獲,如果有問題可以現在發問,或者用上面這些方式與我聯繫,謝謝!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}