While data-science talks a lot about machine learning, much of the work is preparing and assembling dataframes. Such work is very manual. Here I introduce Skrub, a young package that ease machine-learning with dataframes. It provides a variety of tools to plug any scikit-learn type machine-learning on complex and messy dataframes with no manual work.
I also cover the exciting "DataOps" plans, in the new release, which wrap and record any data assembling or wrangling pipeline and can apply machine-learning workflow on it: applying the plan on new data, cross-validation or tuning it to maximize prediction accuracy on a task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
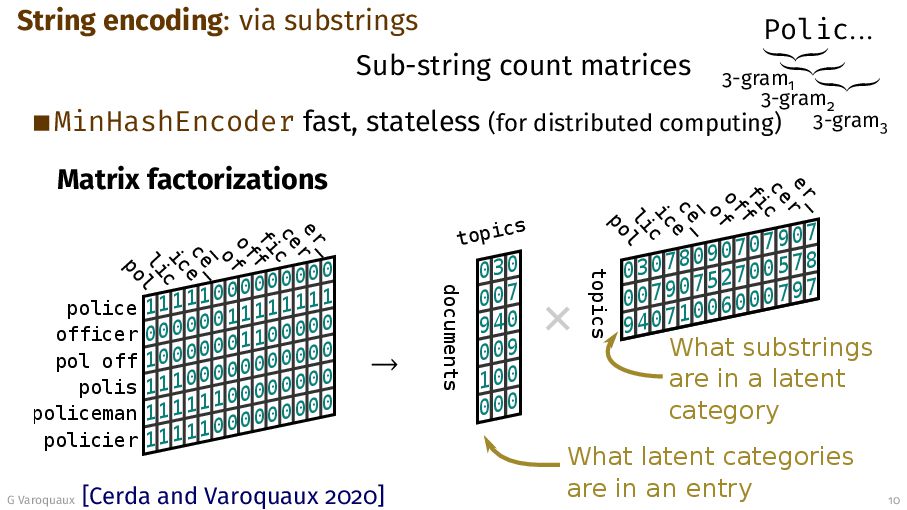{kind=link}
{kind=link}
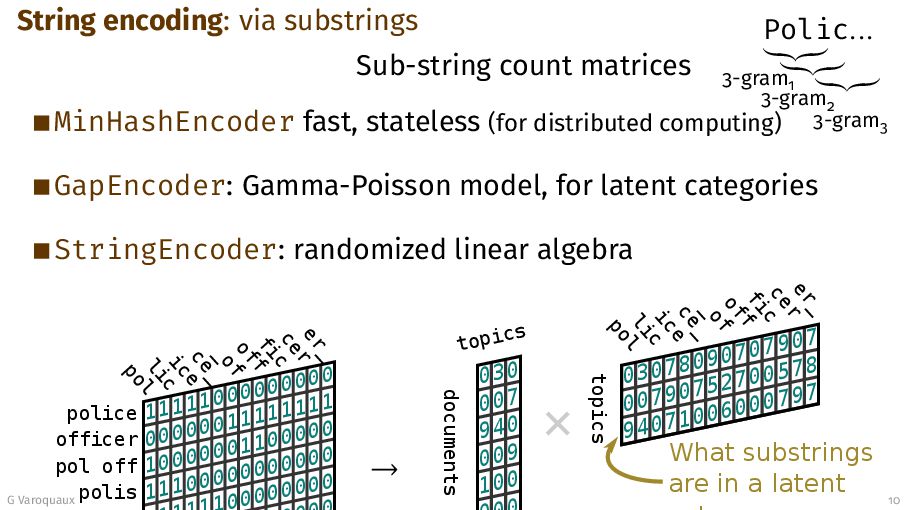{kind=link}
{kind=link}
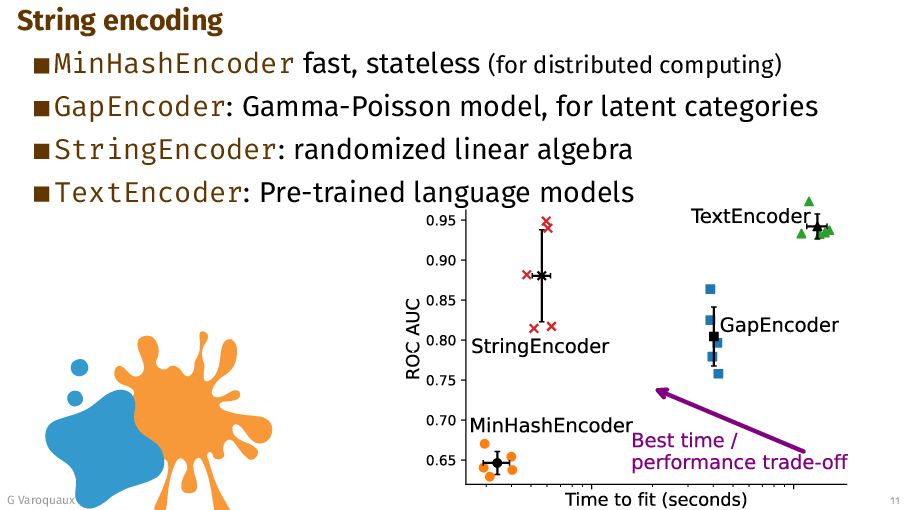{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
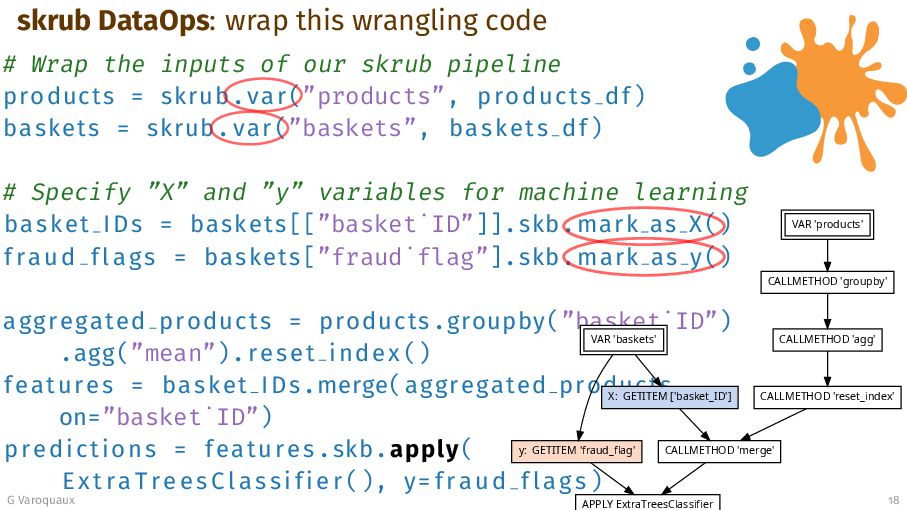{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}