Share
Presentation at "OpenTelemetry Meetup 2025-07" https://opentelemetry.connpass.com/event/360245/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
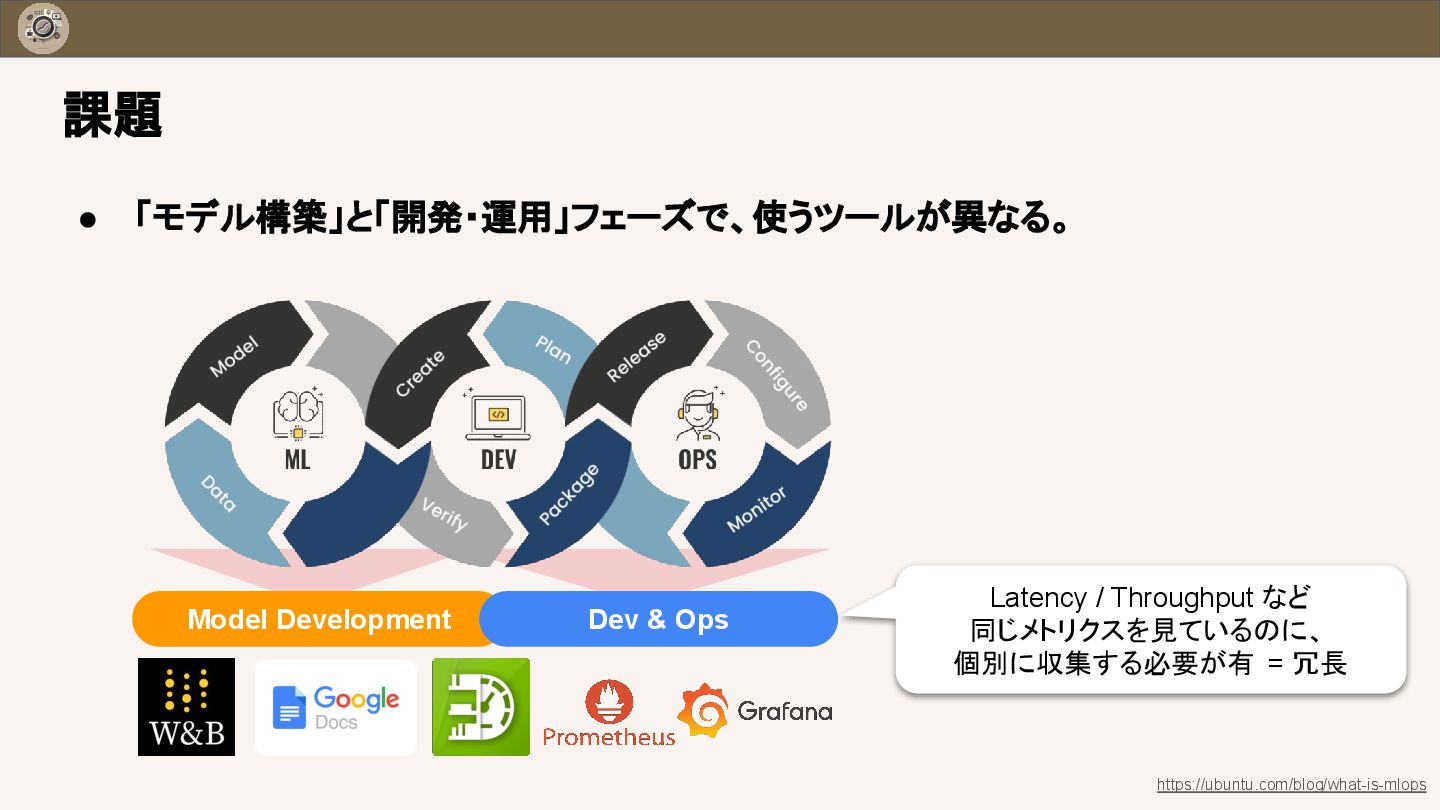{kind=link}
![[補足] 実験管理ツール (Weights & Biases) • 機械学習の難しい点 ⇒ 再現性の担保 ◦](https://files.speakerdeck.com/presentations/005a11e5242c46bb94e4f4d61e0ff532/slide_7.jpg){kind=link}
![[補足] モデルの最適化 & プロファイラ • ML Pipeline のボトルネック ⇒ モデルの推論時間](https://files.speakerdeck.com/presentations/005a11e5242c46bb94e4f4d61e0ff532/slide_8.jpg){kind=link}
{kind=link}
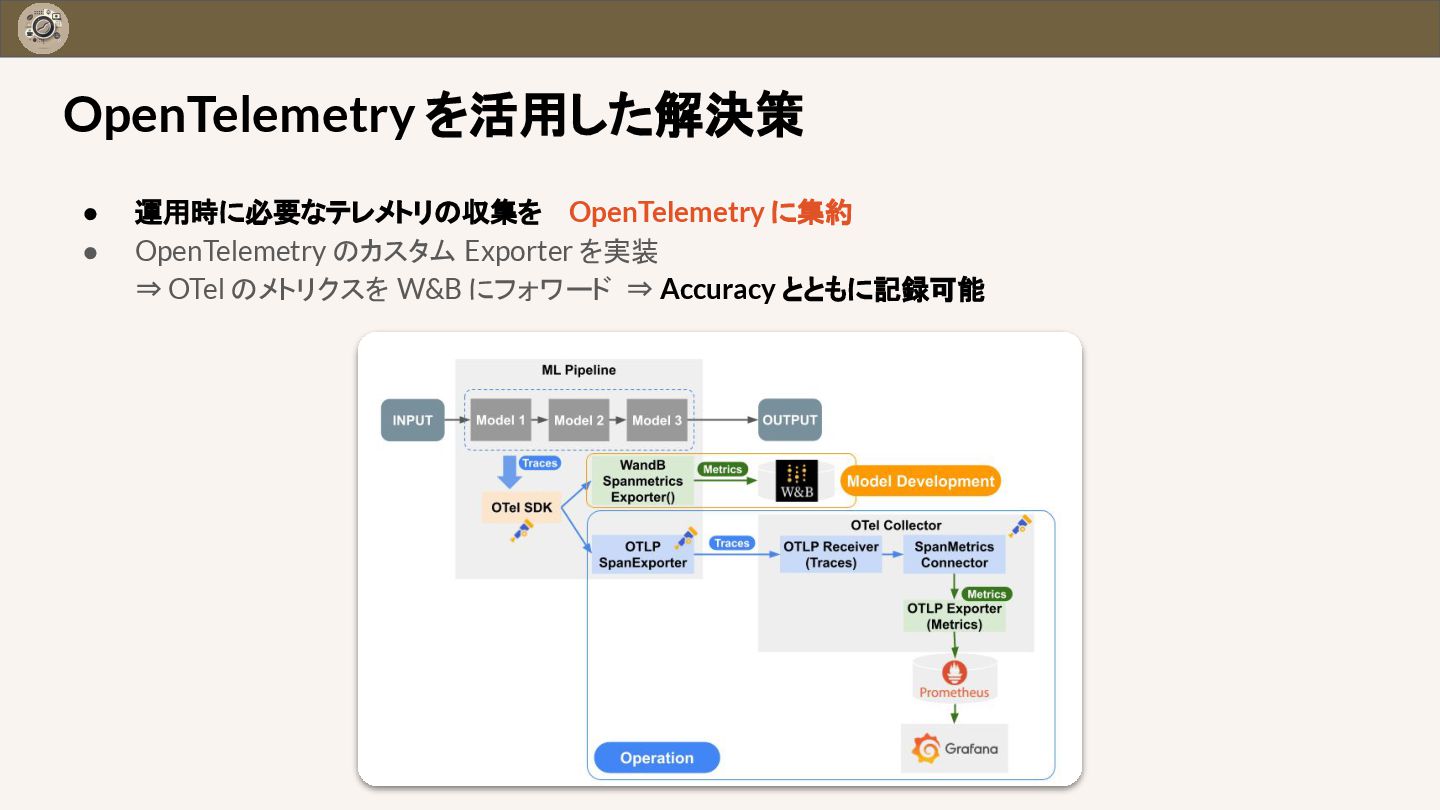{kind=link}
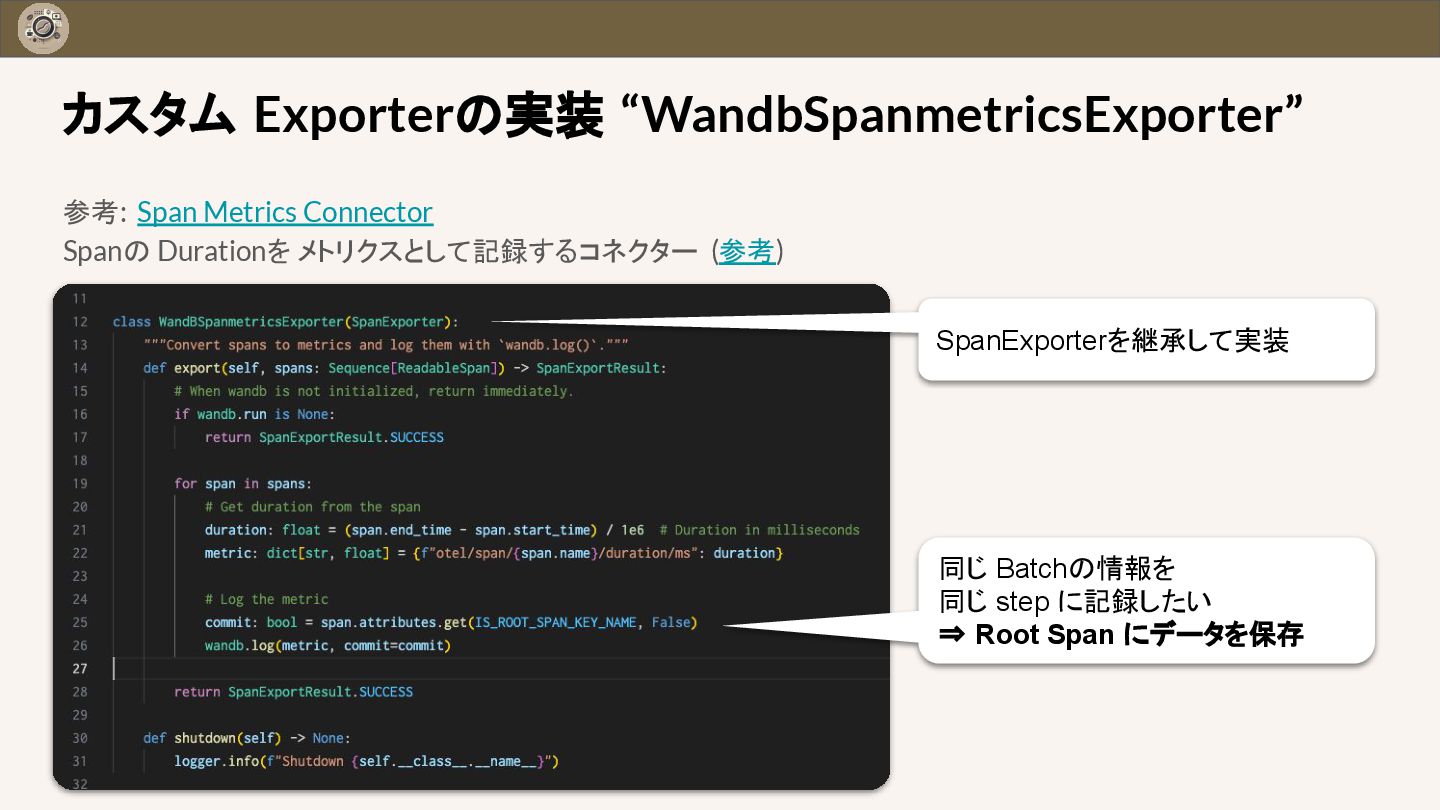{kind=link}
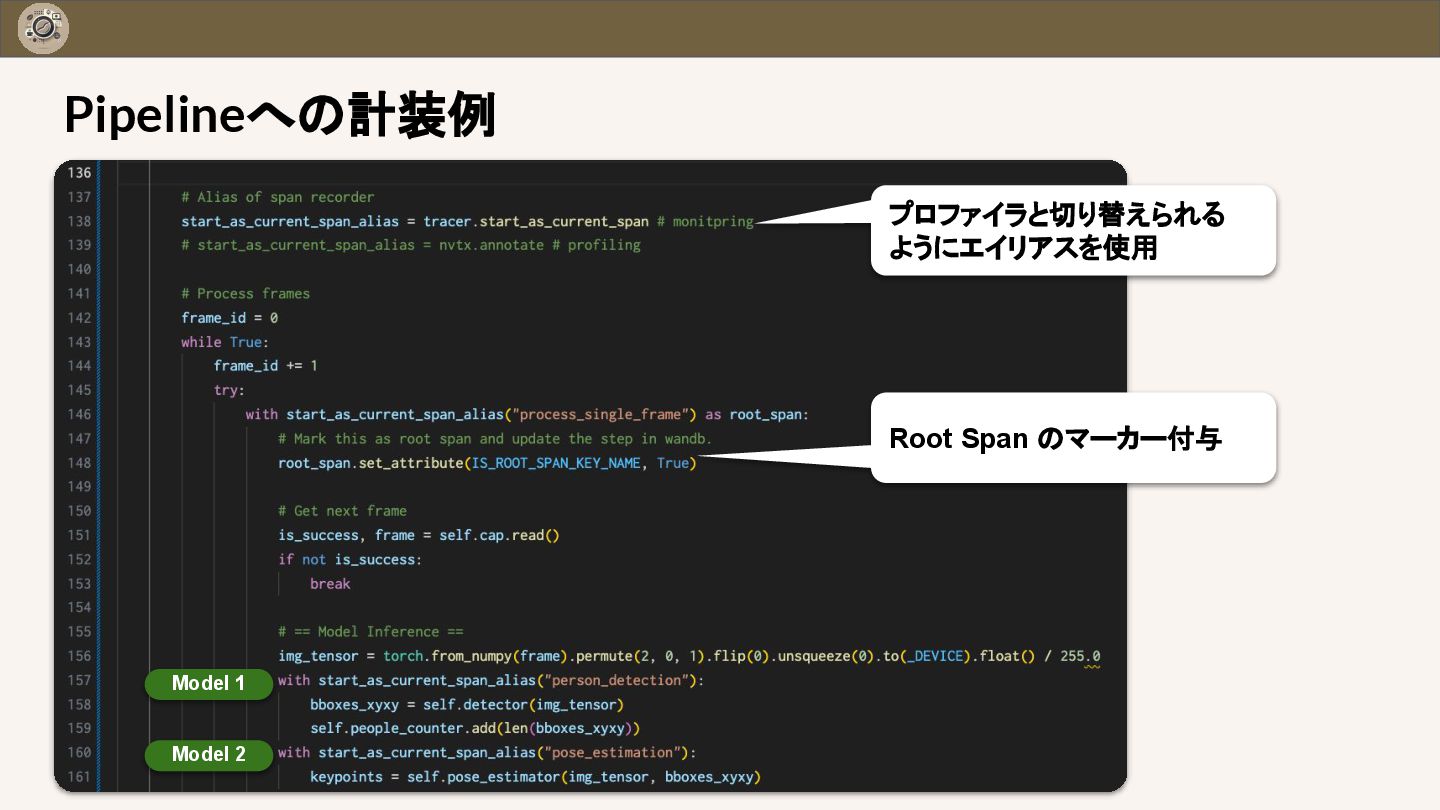{kind=link}
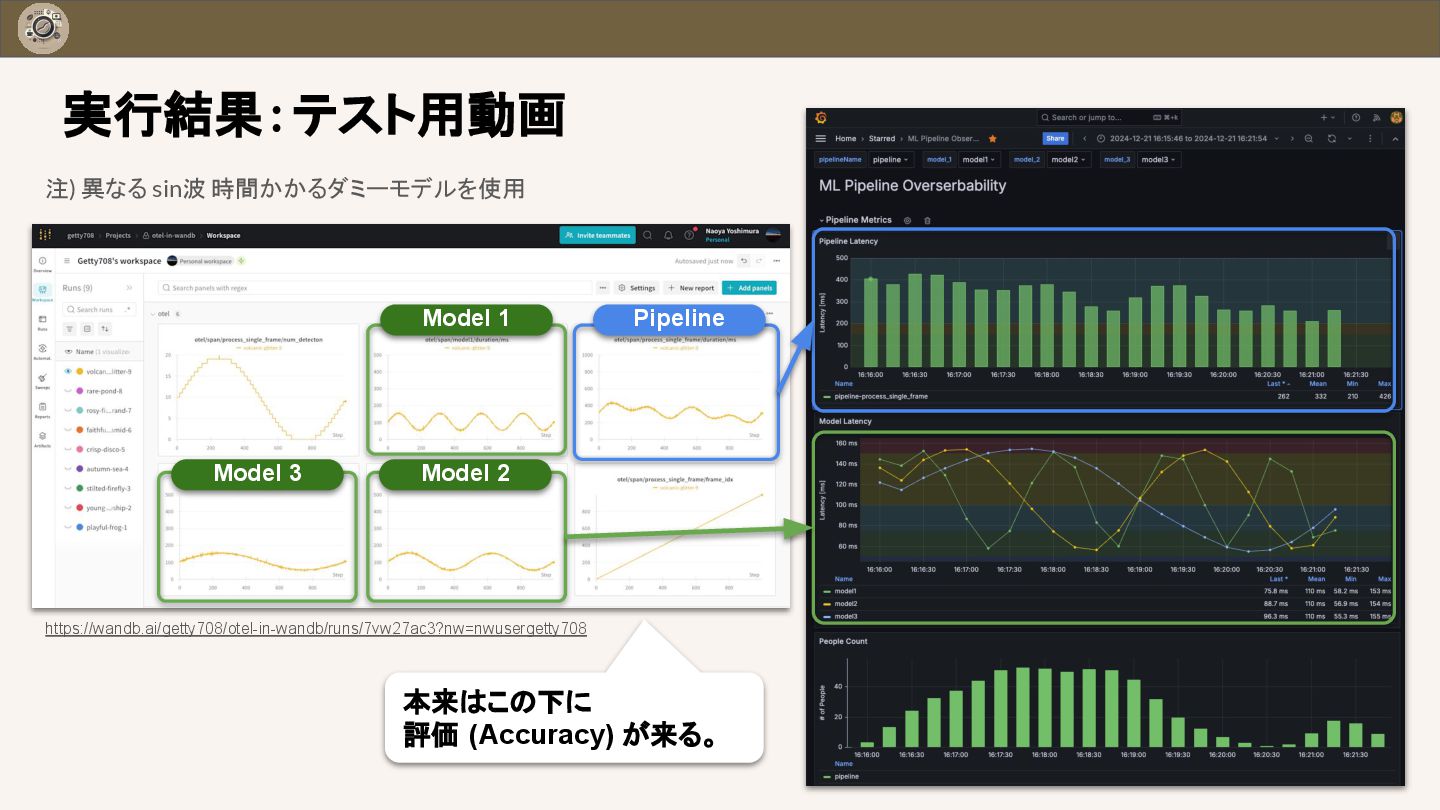{kind=link}
{kind=link}
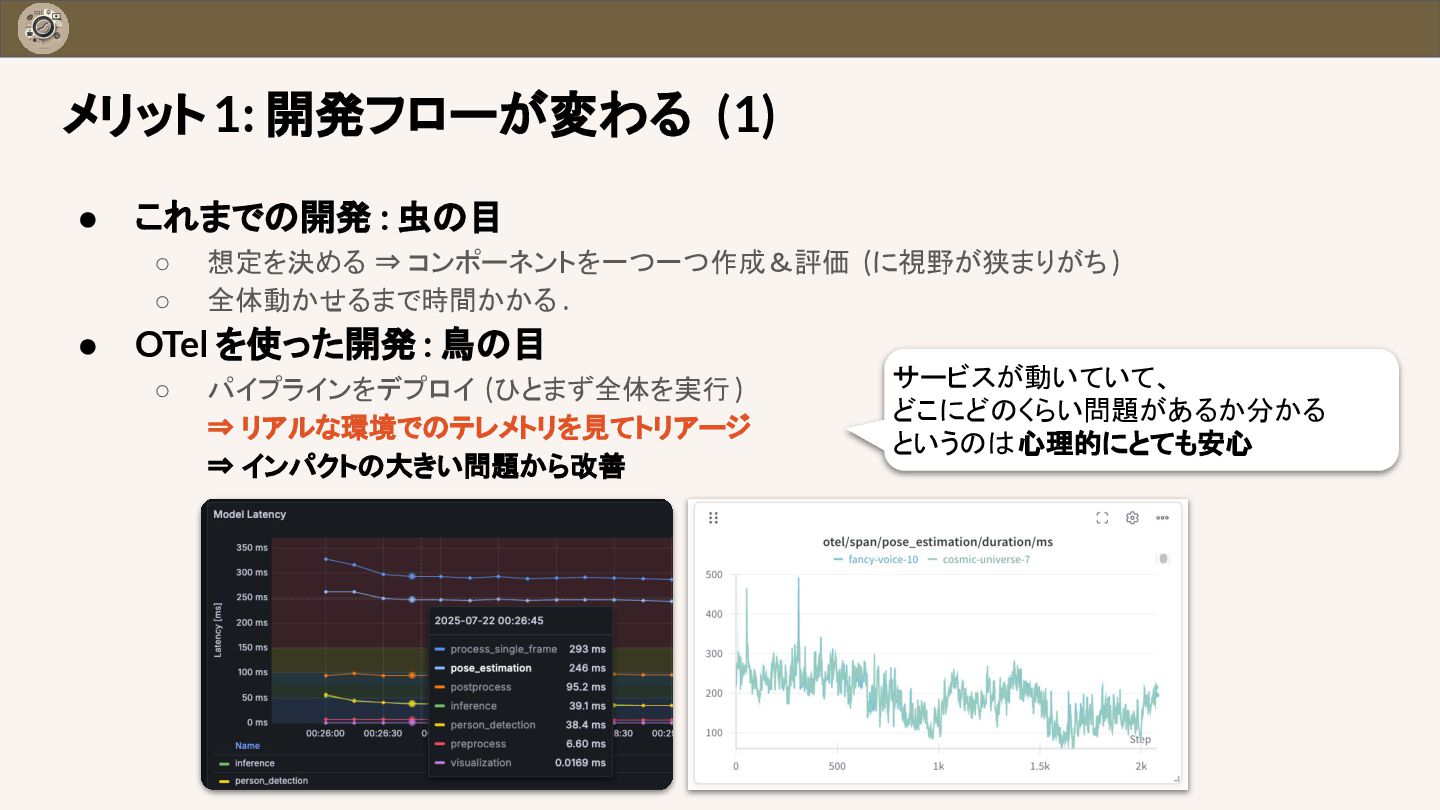{kind=link}
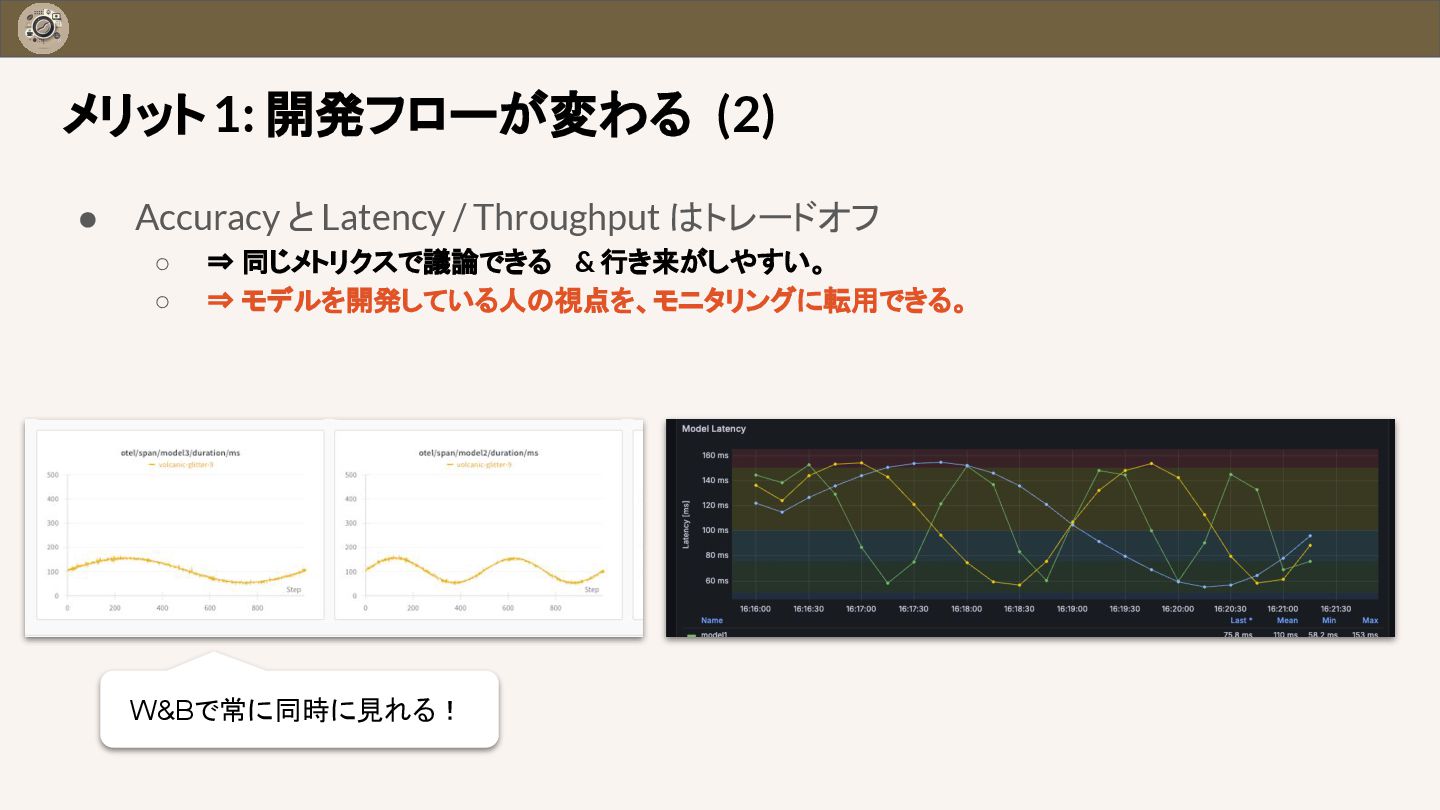{kind=link}
{kind=link}
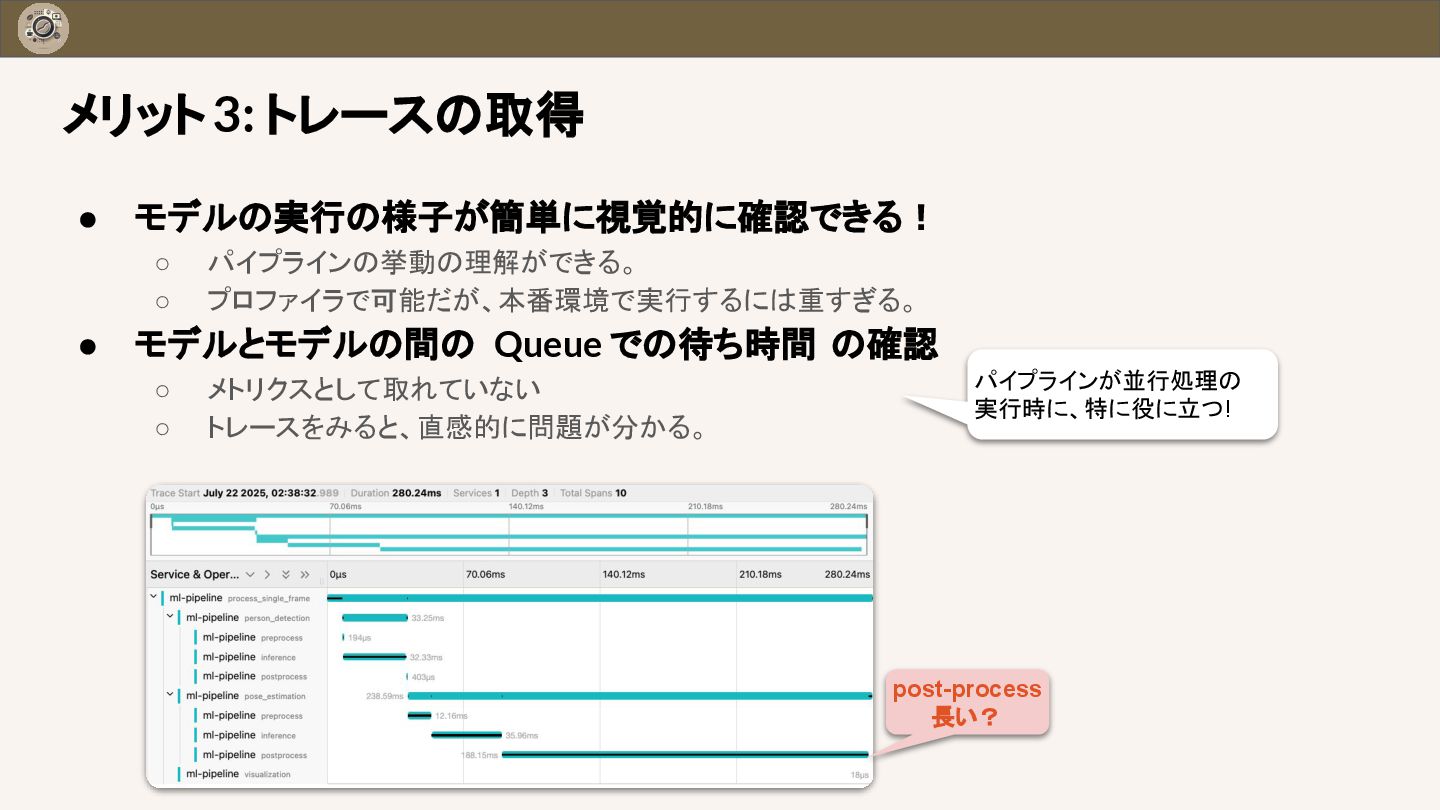{kind=link}
{kind=link}
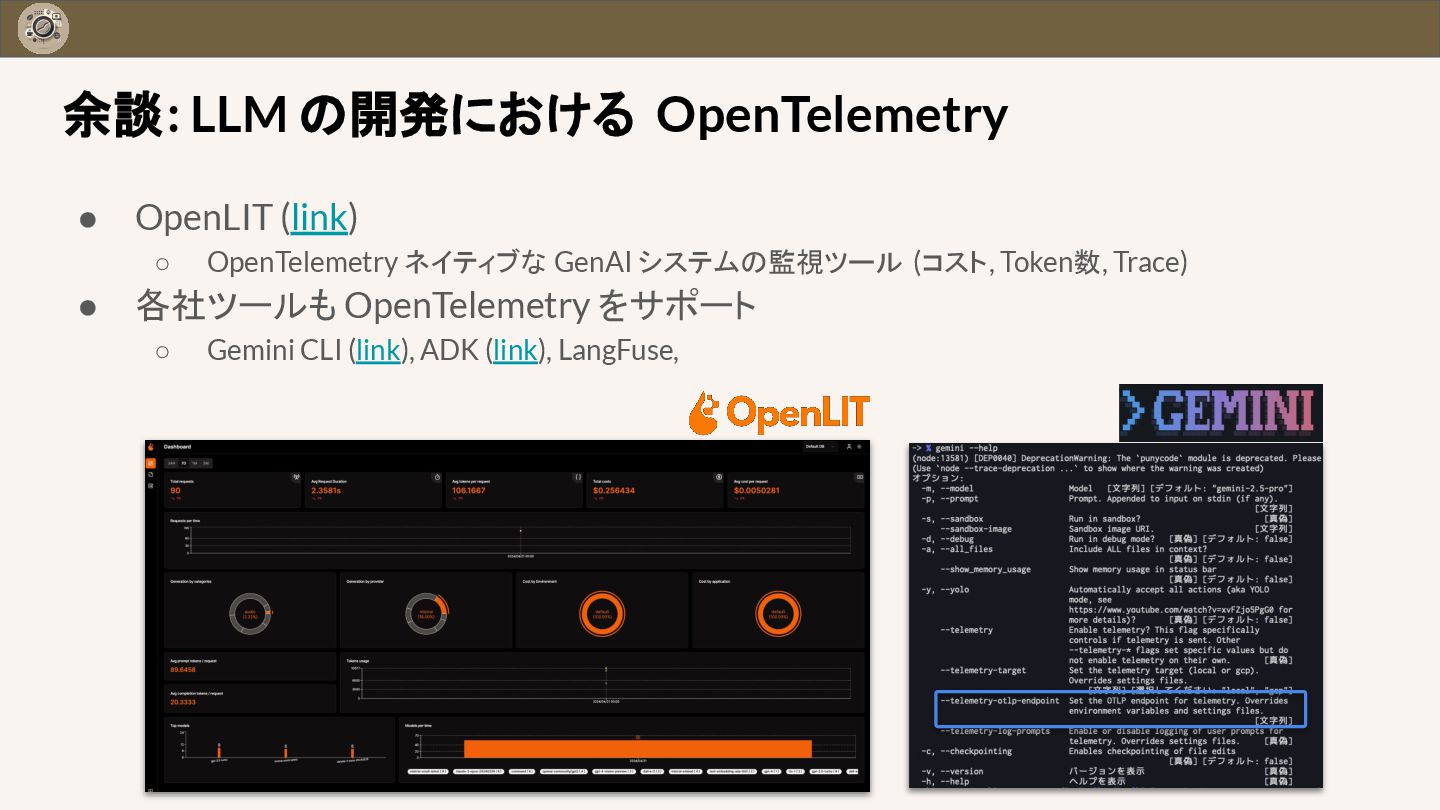{kind=link}