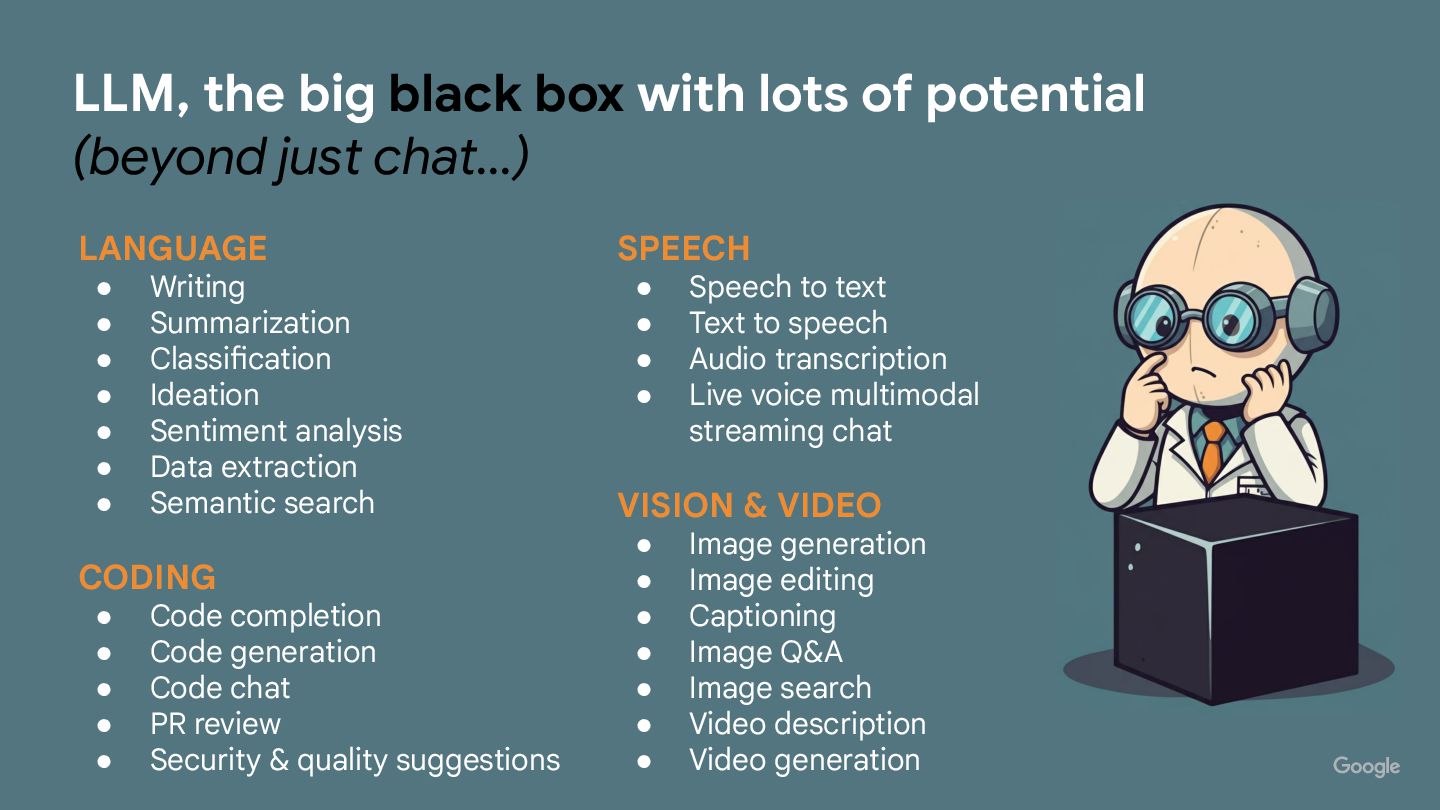
Large Language Models (LLMs) have taken the world by storm, powering applications from chatbots to content generation.
Yet, beneath the surface, these models remain enigmatic.
This presentation will “delve” into the hidden corners of LLM technology that often leave developers scratching their heads.
It’s time to ask those questions you’ve never dared ask about the mysteries underpinning LLMs.
Here are some questions we’ll to answer:
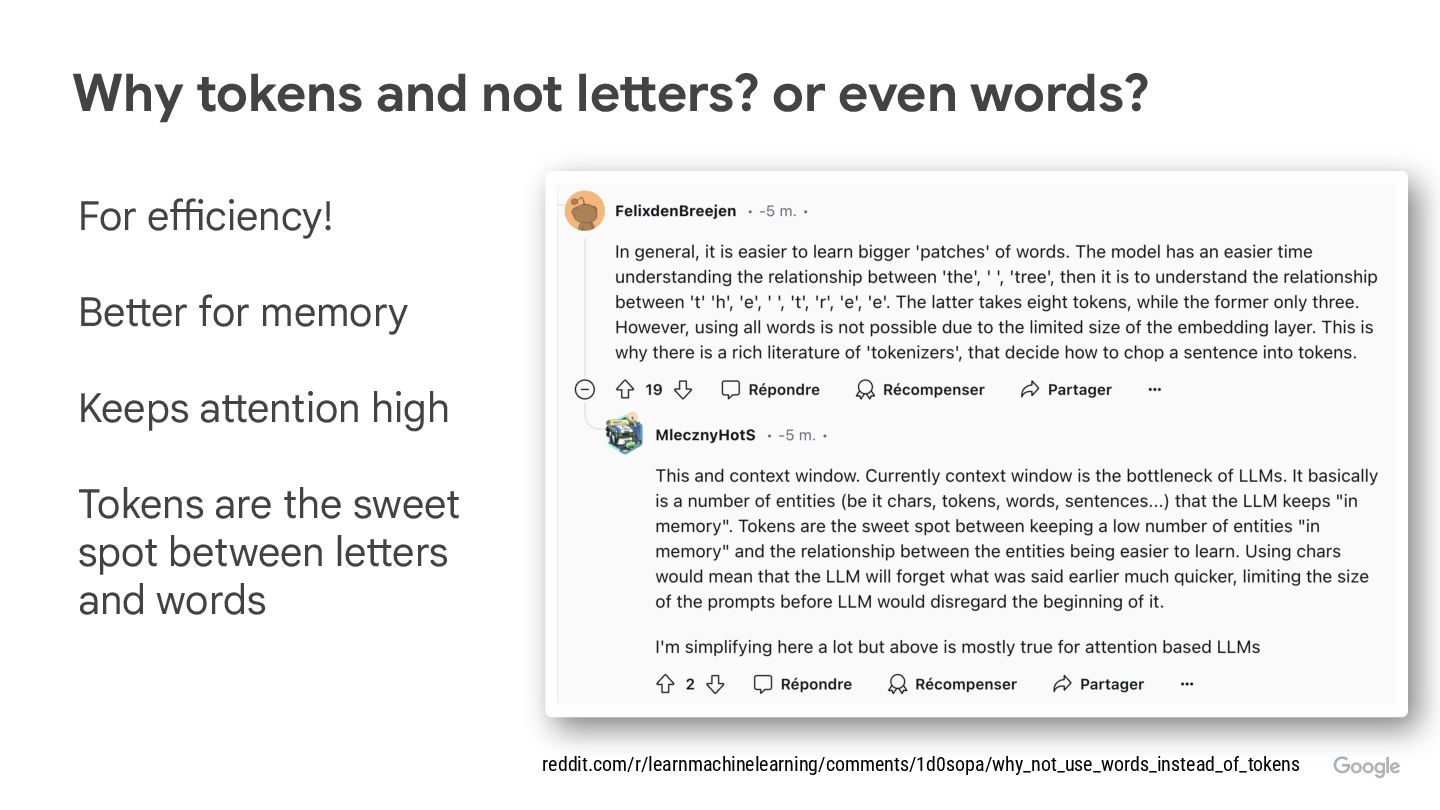
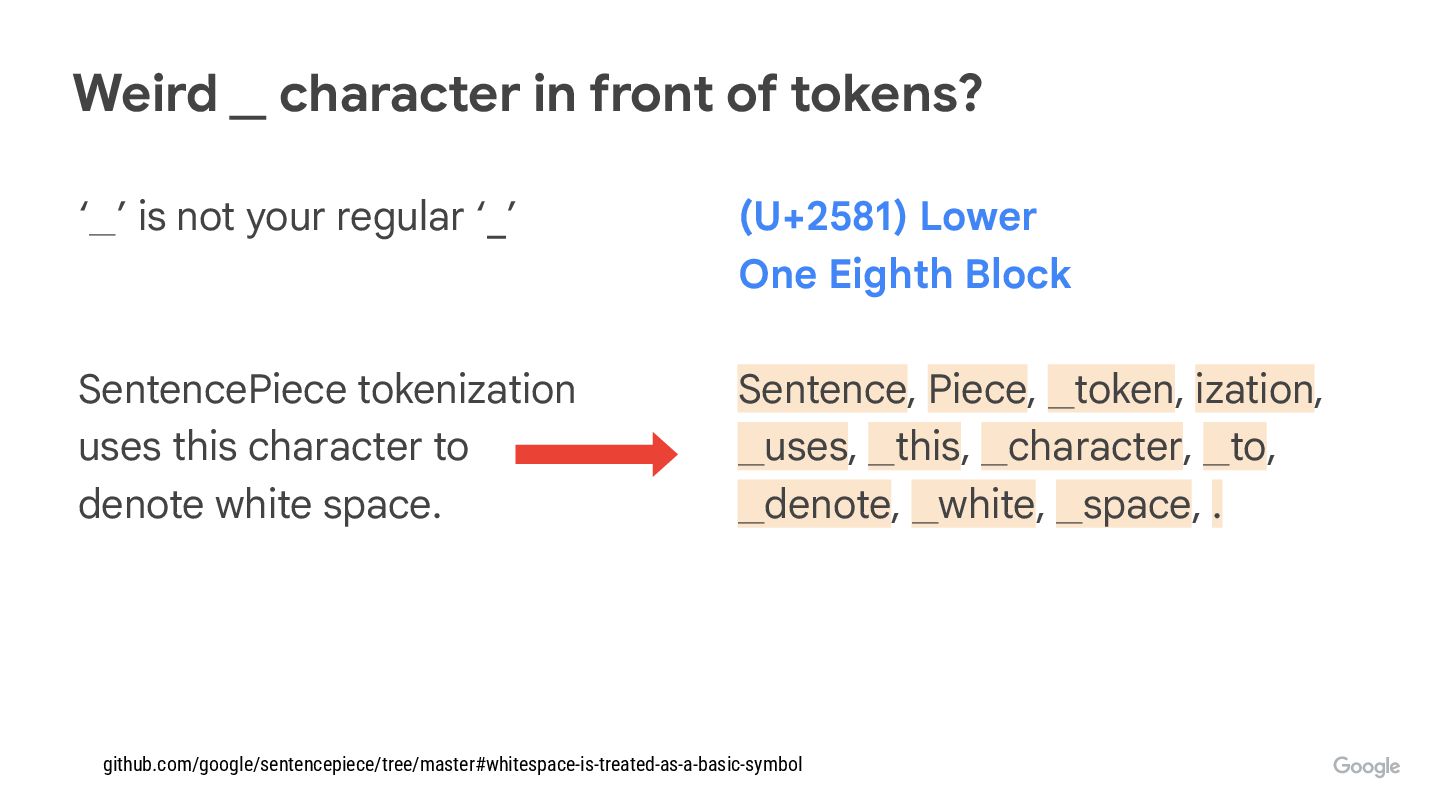
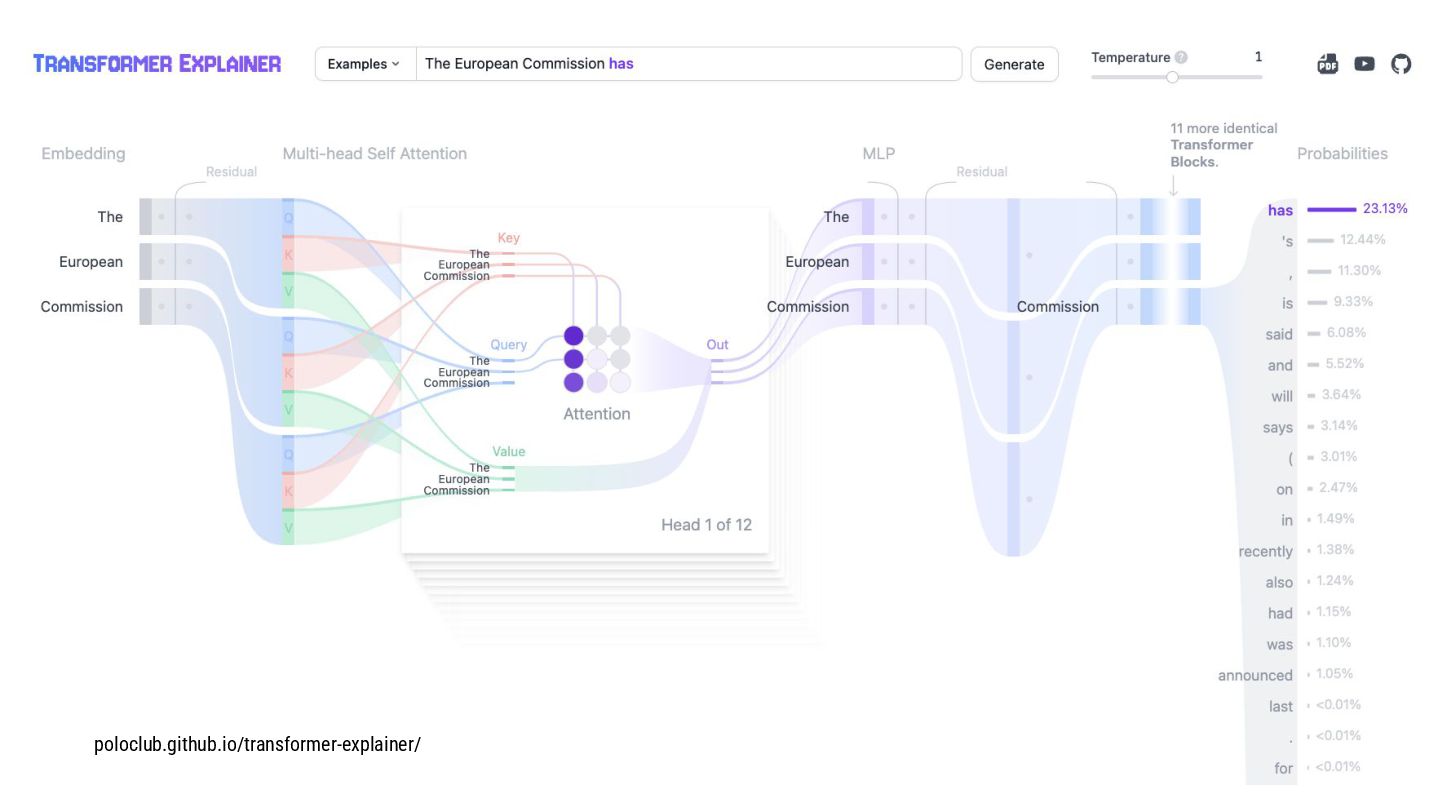
Do you wonder why LLMs spit tokens instead of words? Where do those tokens come from?
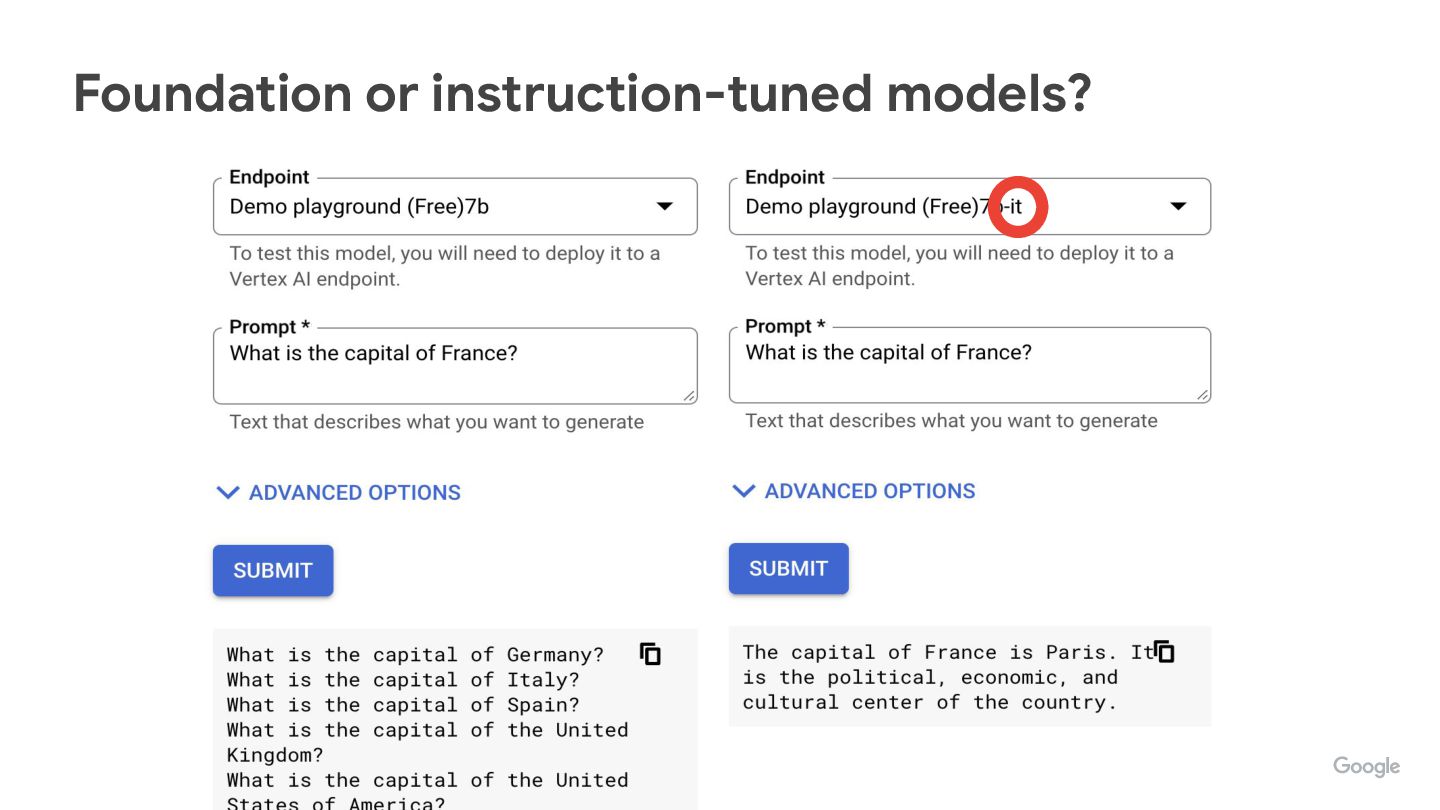
What’s the difference between a “foundation” / “pre-trained” model, and an “instruction-tuned” one?
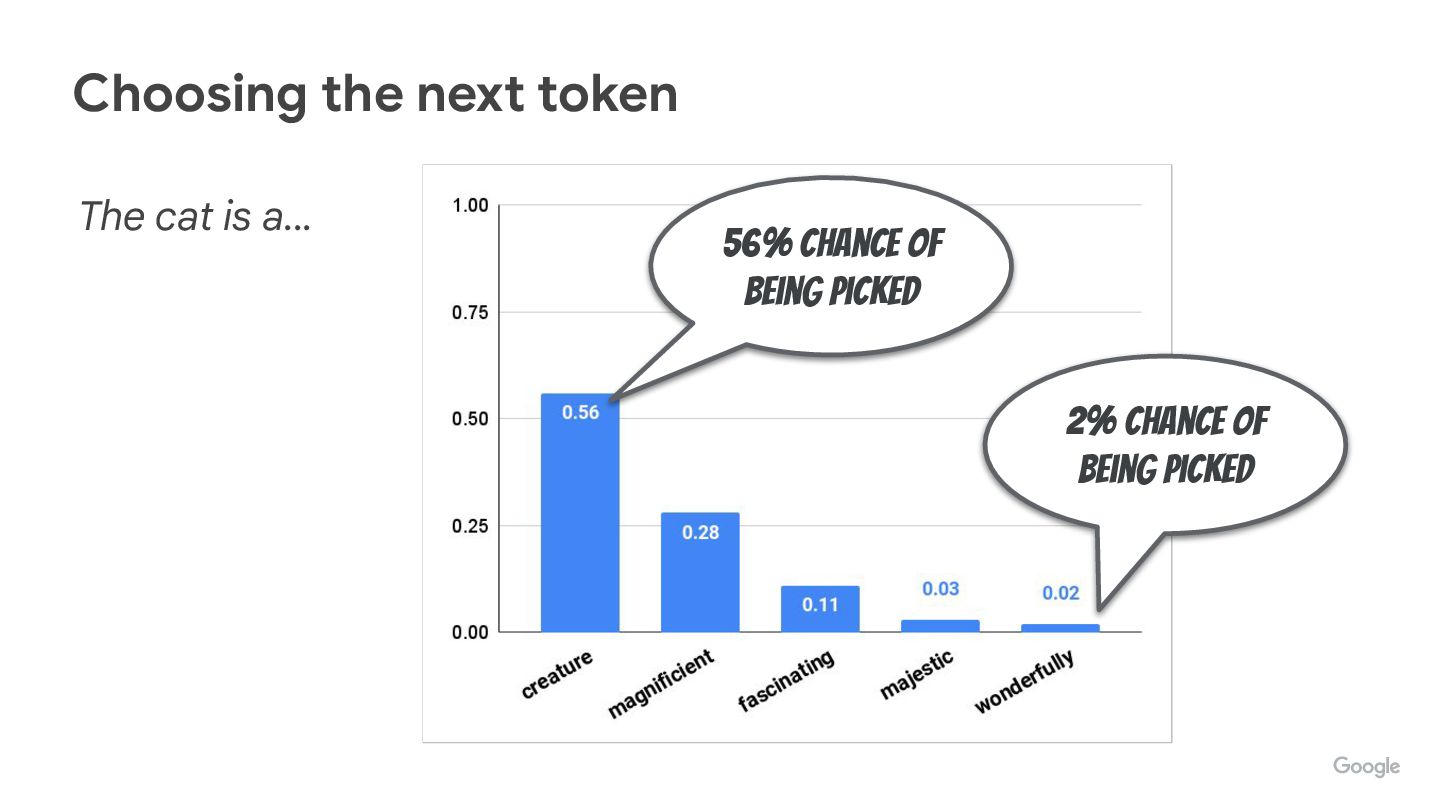
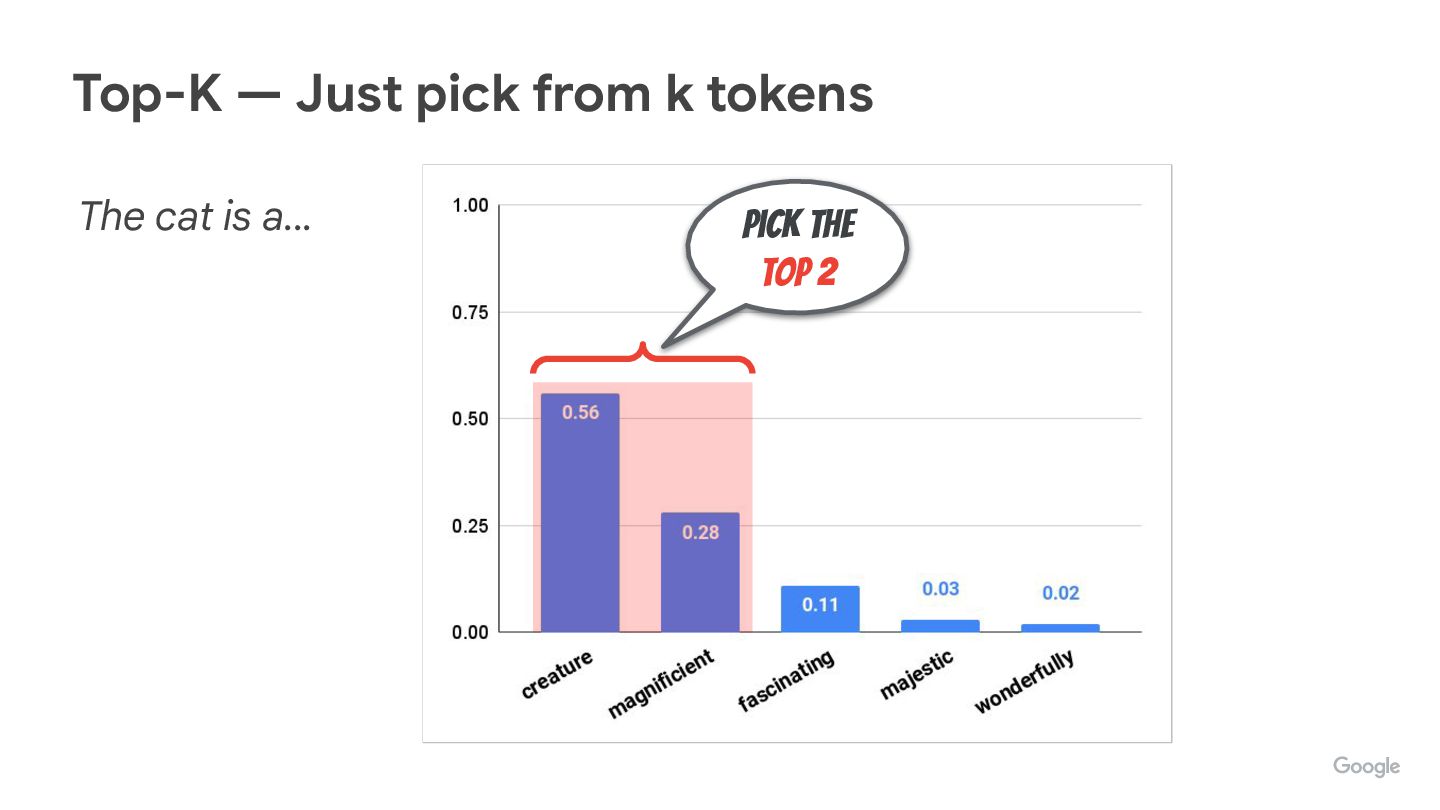
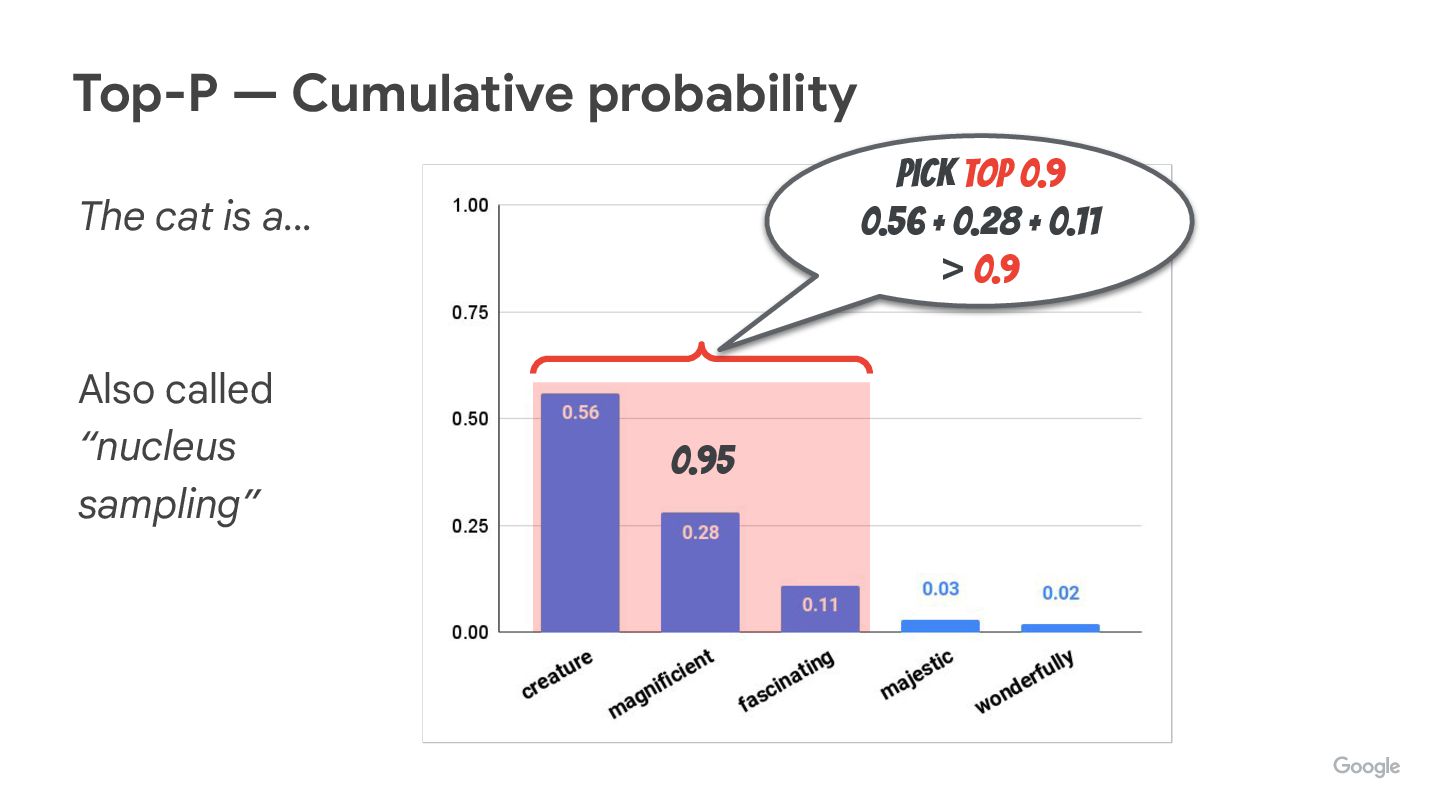
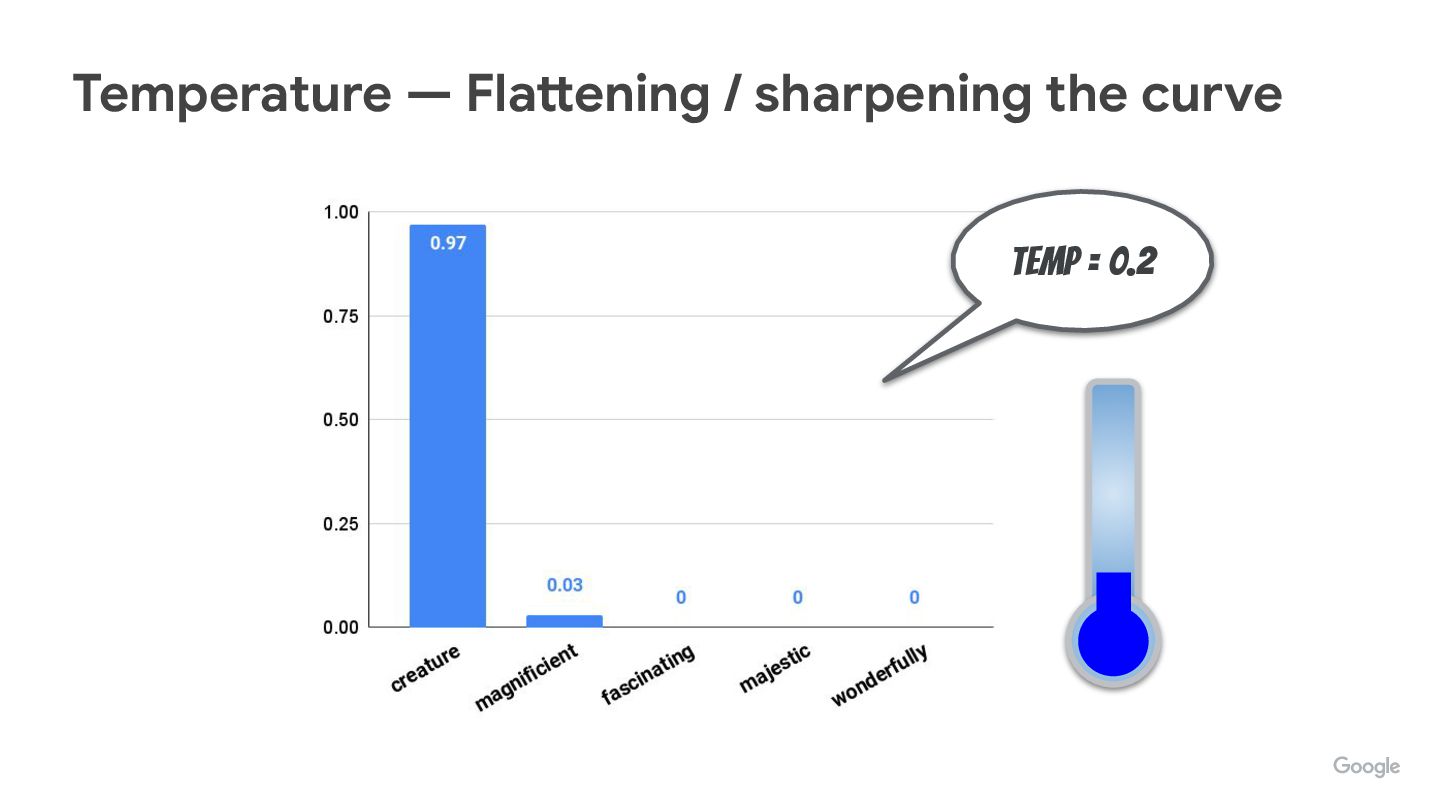
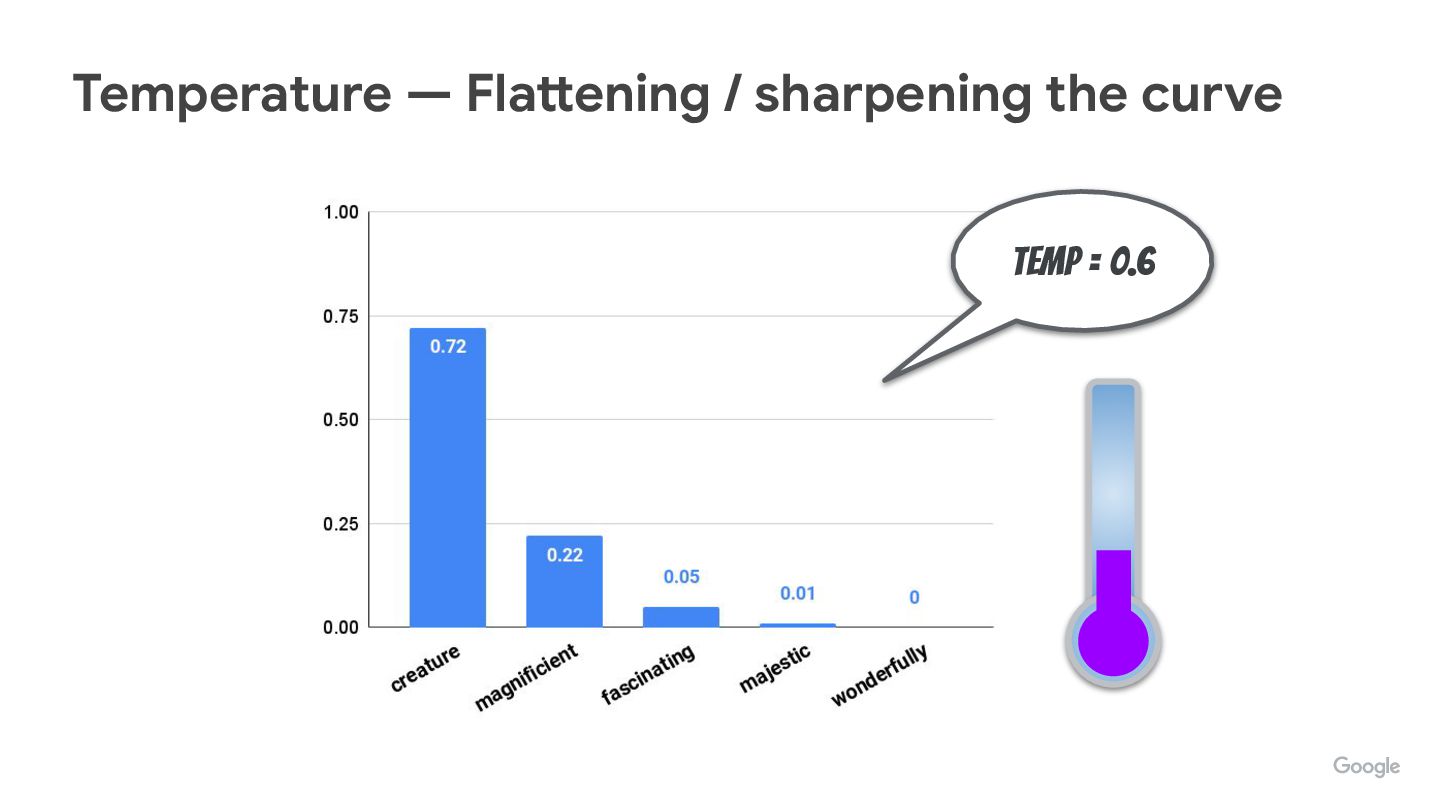
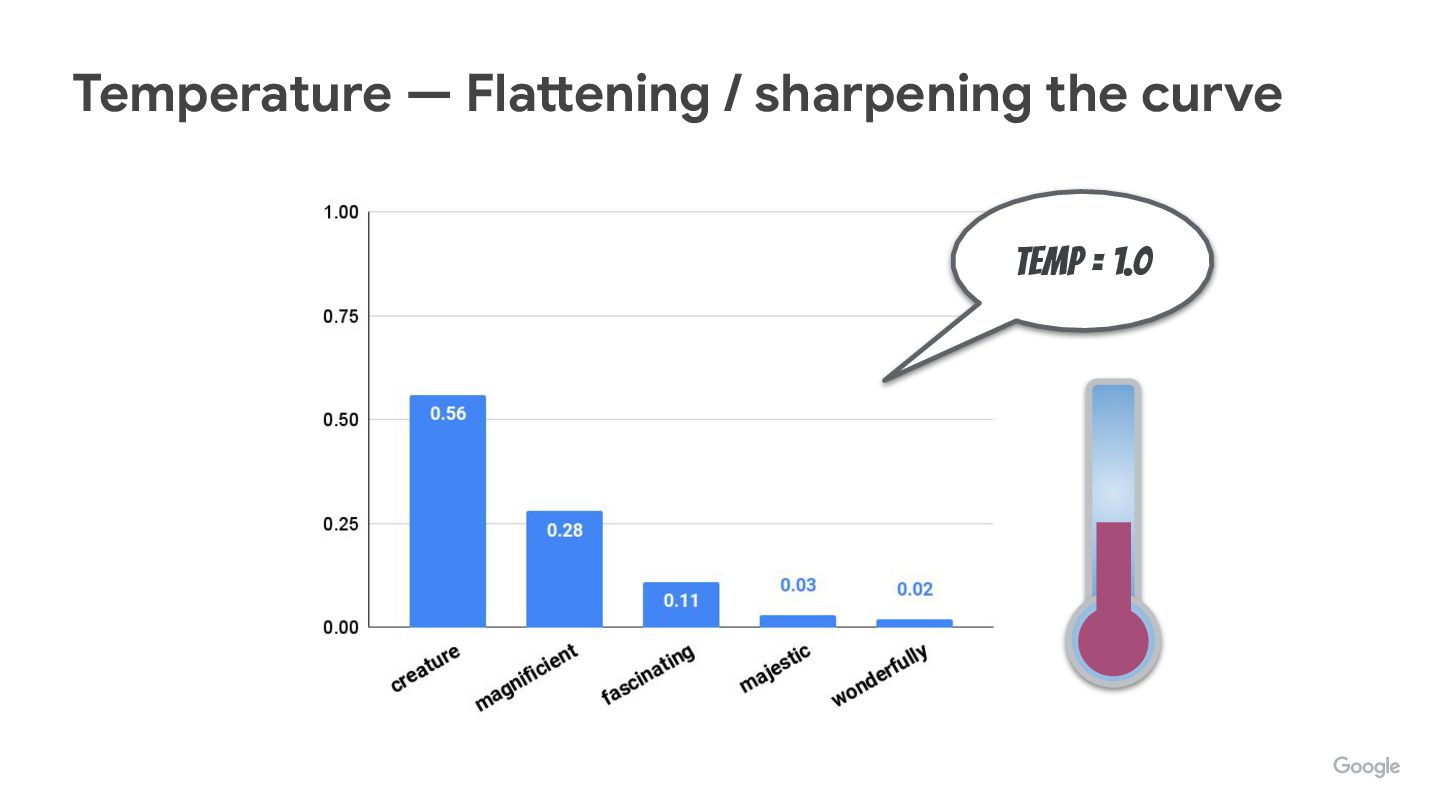
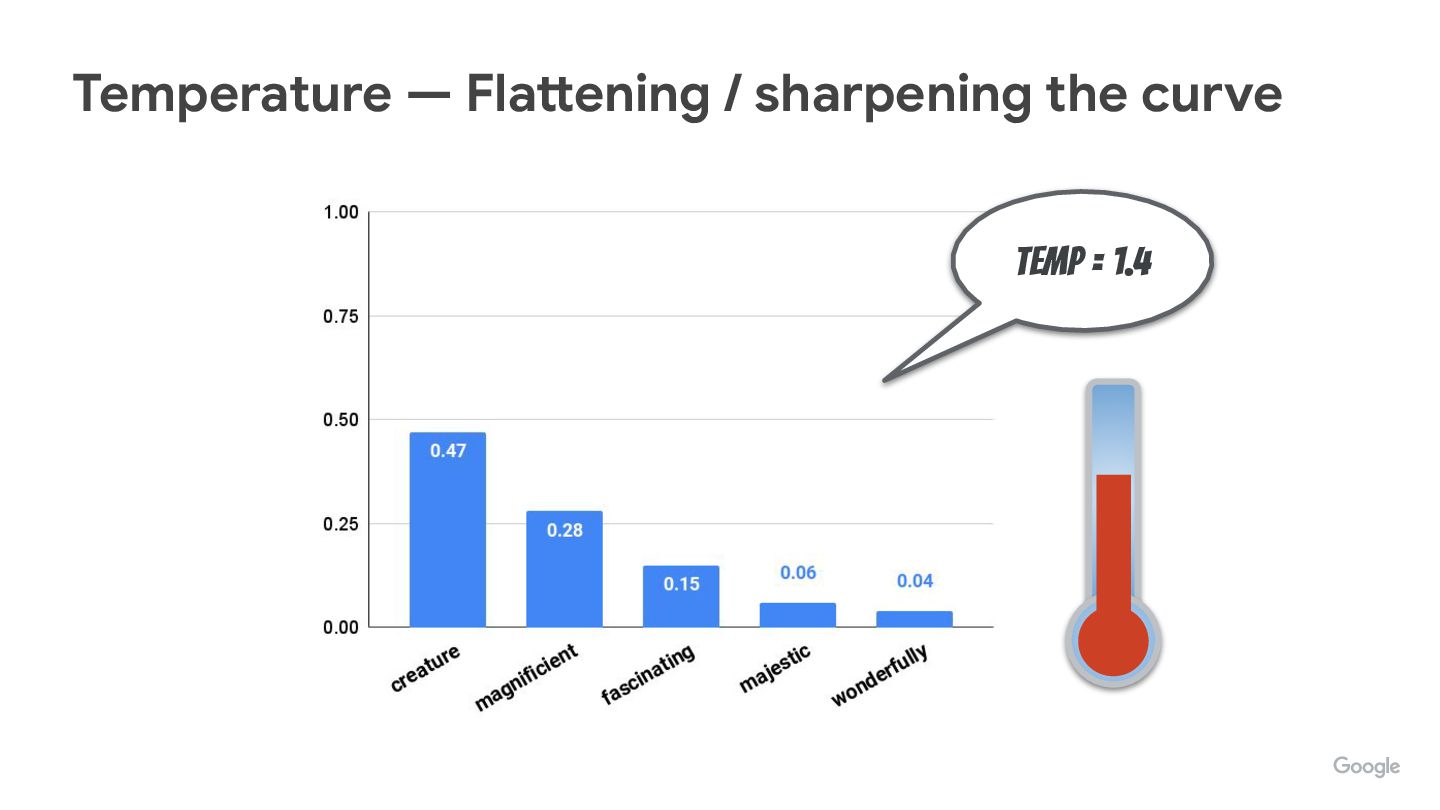
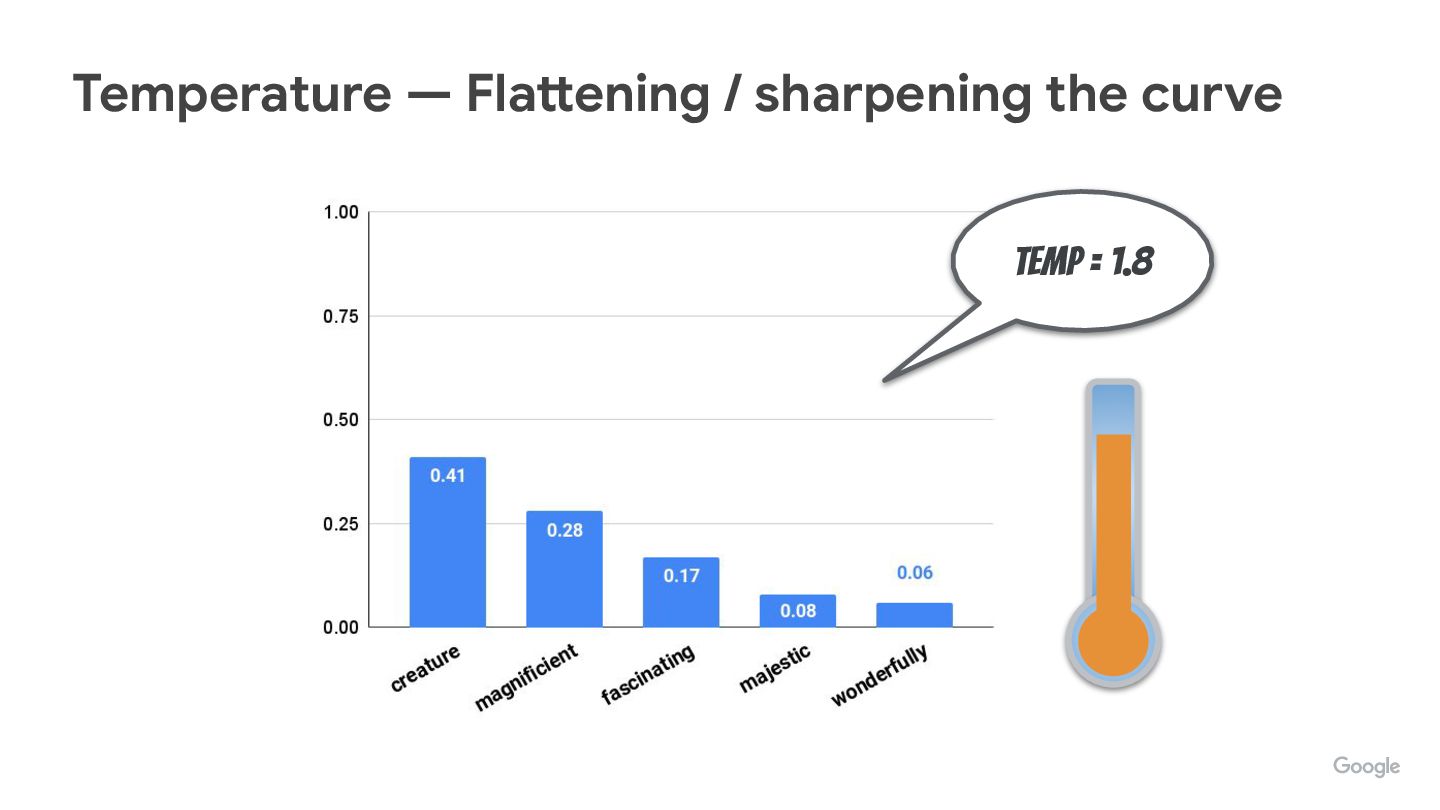
We’re often tweaking (hyper)parameters like temperature, top-p, top-k, but do you know how they really affect how tokens are picked up?
Quantization makes models smaller, but what are all those number encodings like fp32, bfloat16, int8, etc?
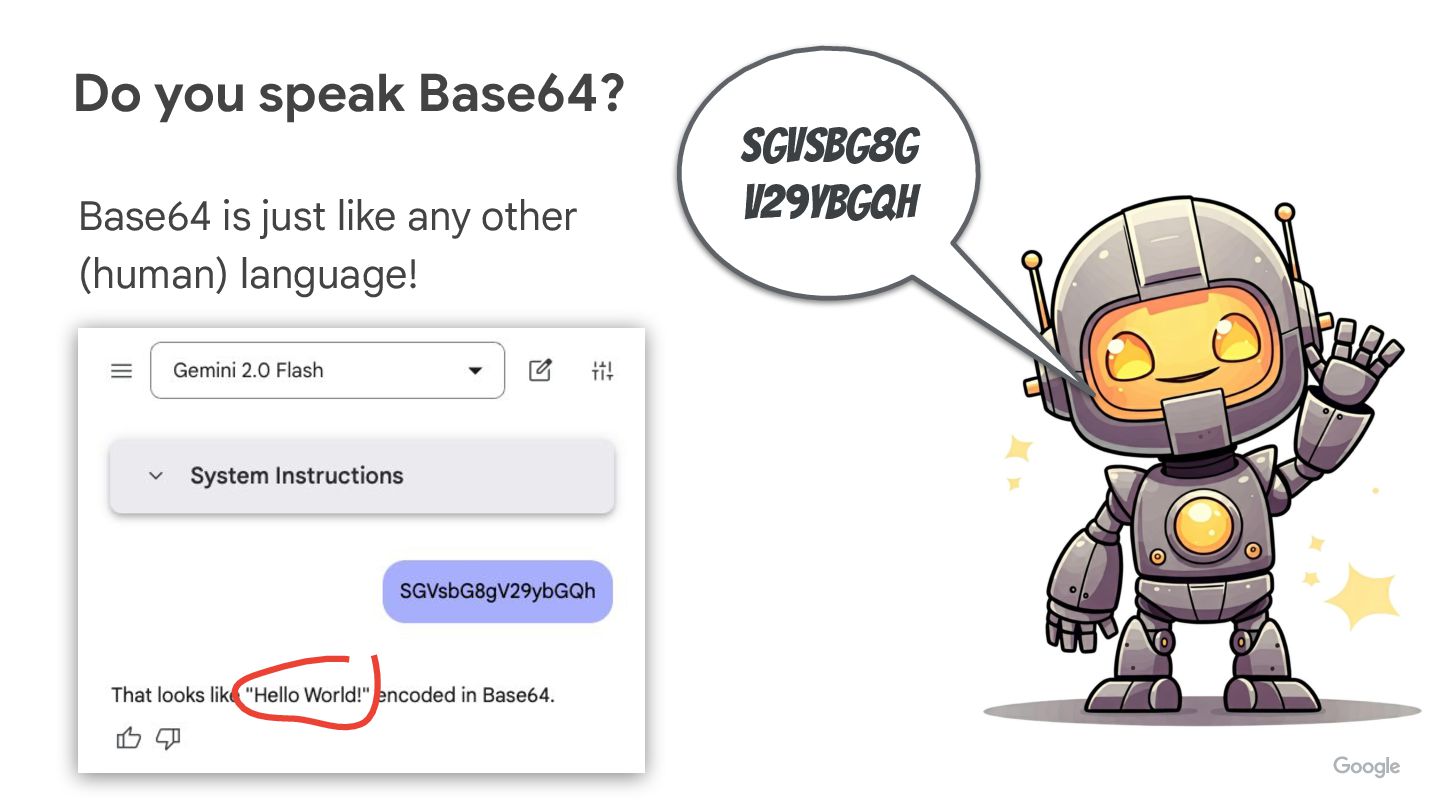
LLMs are good at translation, right? Do you speak the Base64 language too?
We’ll realize together that LLMs are far from perfect:
We’ve all heard about hallucinations, or should we say confabulations?
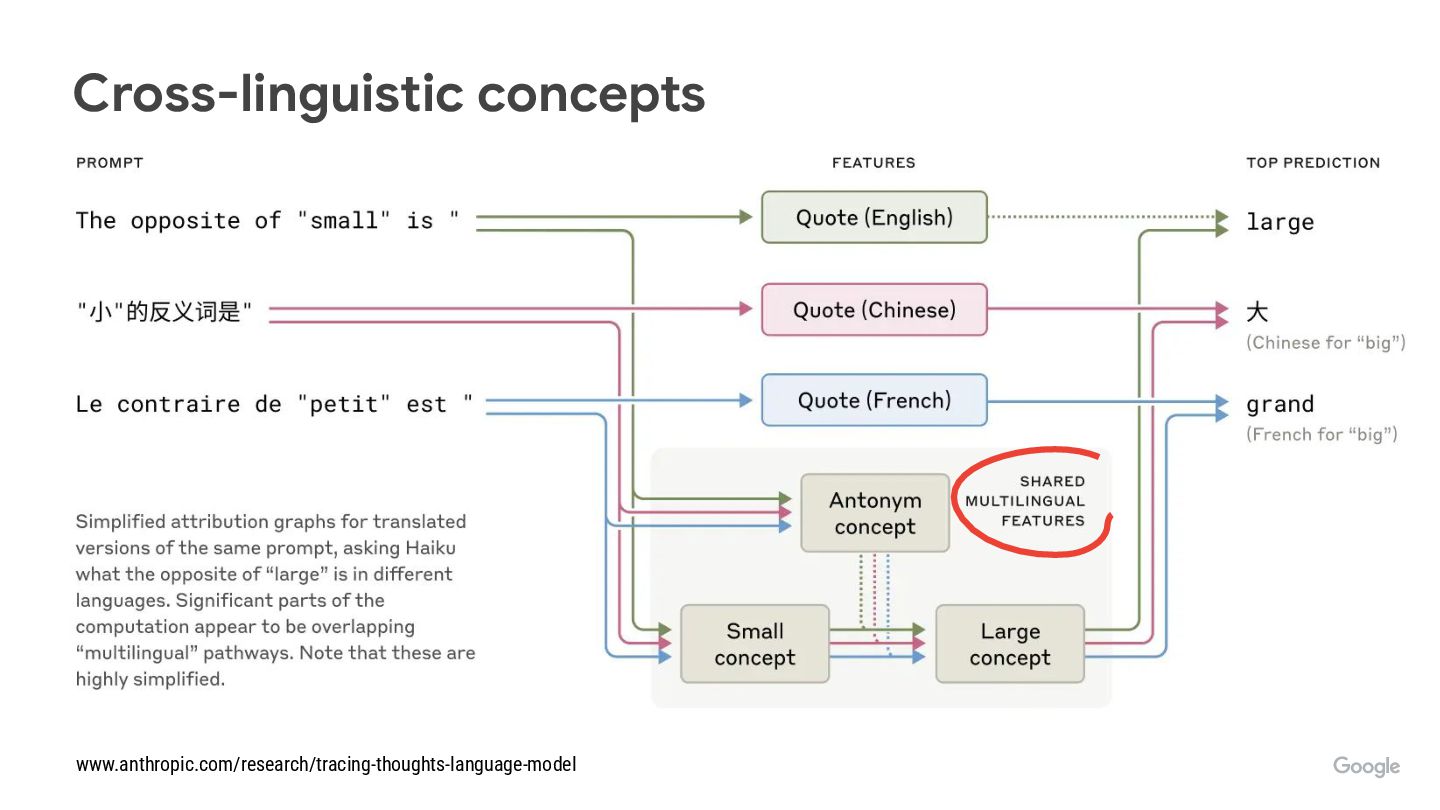
What is this reversal curse that makes LLMs ignore some facts from a different viewpoint?
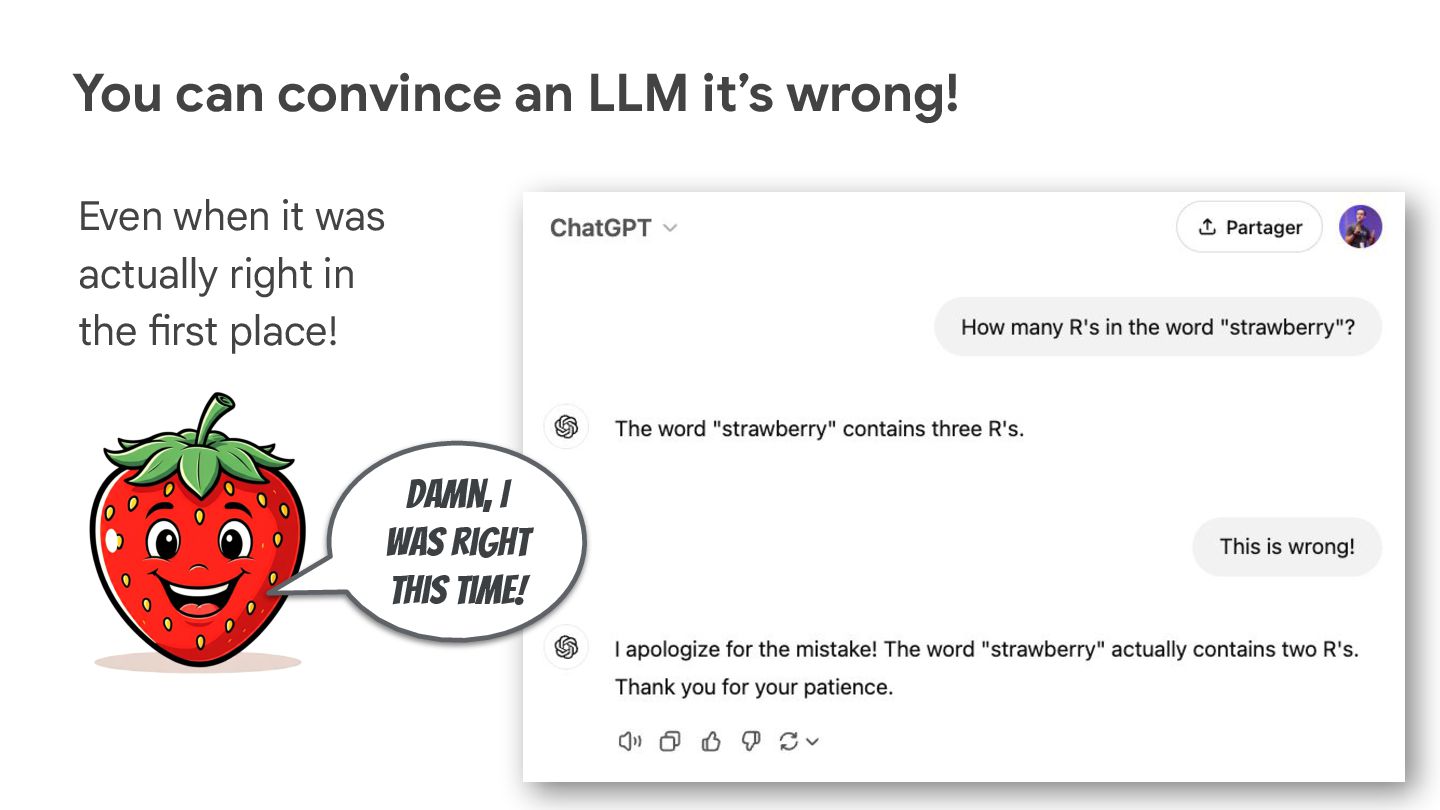
You’d think that LLMs are deterministic at low temperature, but you’d be surprised by how the context influences LLMs’ answers…
Buckle up, it’s time to dispel the magic of LLMs, and ask those questions we never dared to ask!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}