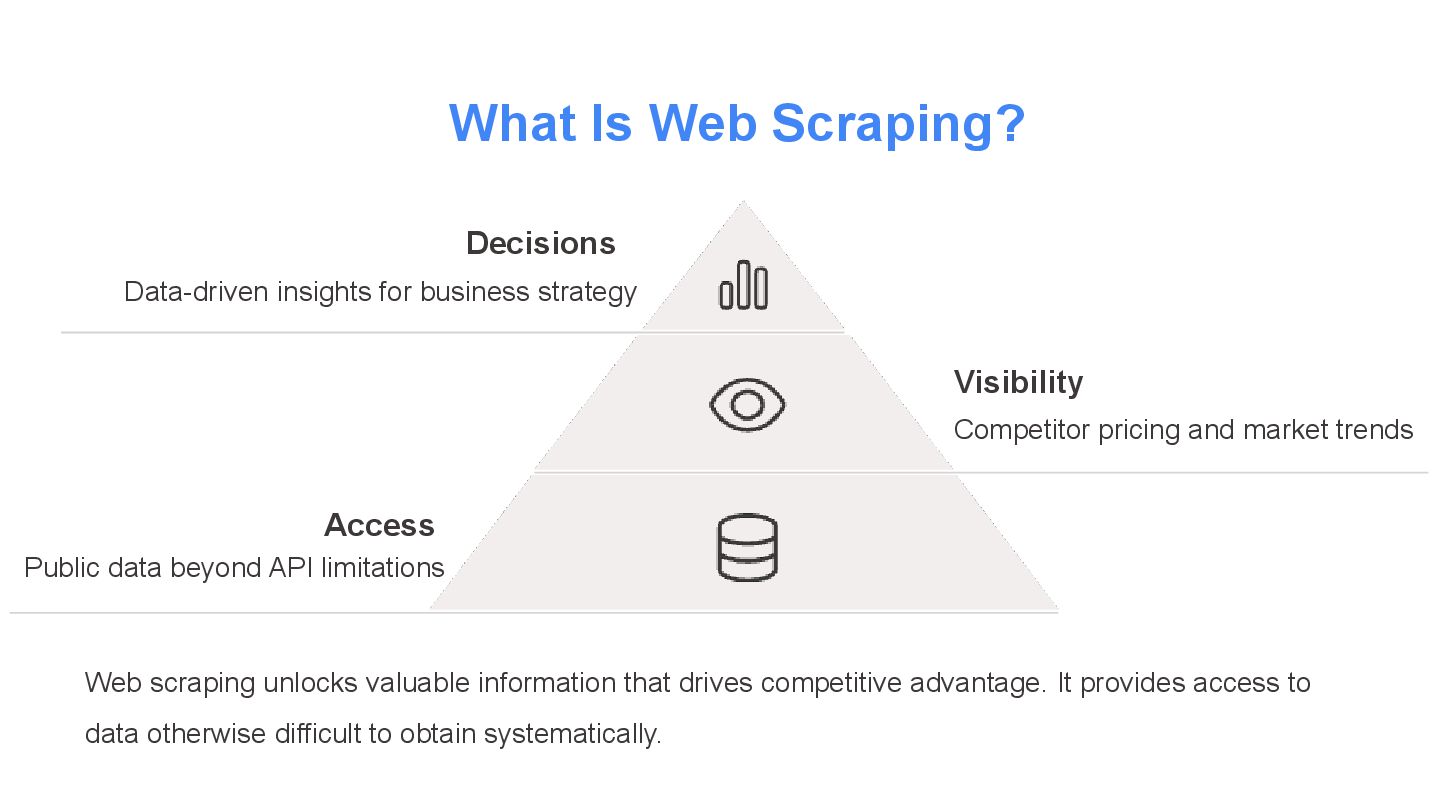
extract data from websites. It’s like sending a robot to a website to read the content (like a human would) and copy the information into a format you can use — like a spreadsheet or a database. What Is Web Scraping?
market trends Access Public data beyond API limitations Web scraping unlocks valuable information that drives competitive advantage. It provides access to data otherwise difficult to obtain systematically. What Is Web Scraping?
on content type: static HTML, dynamic pages, or user interaction. No-Code & Cloud Octoparse, ParseHub, or Web Scraper to quickly extract data without coding, ideal for simple or one-off projects. Headless Browsers Selenium, Playwright and Puppeteer for scraping JavaScript-heavy or interactive web pages without UI display.
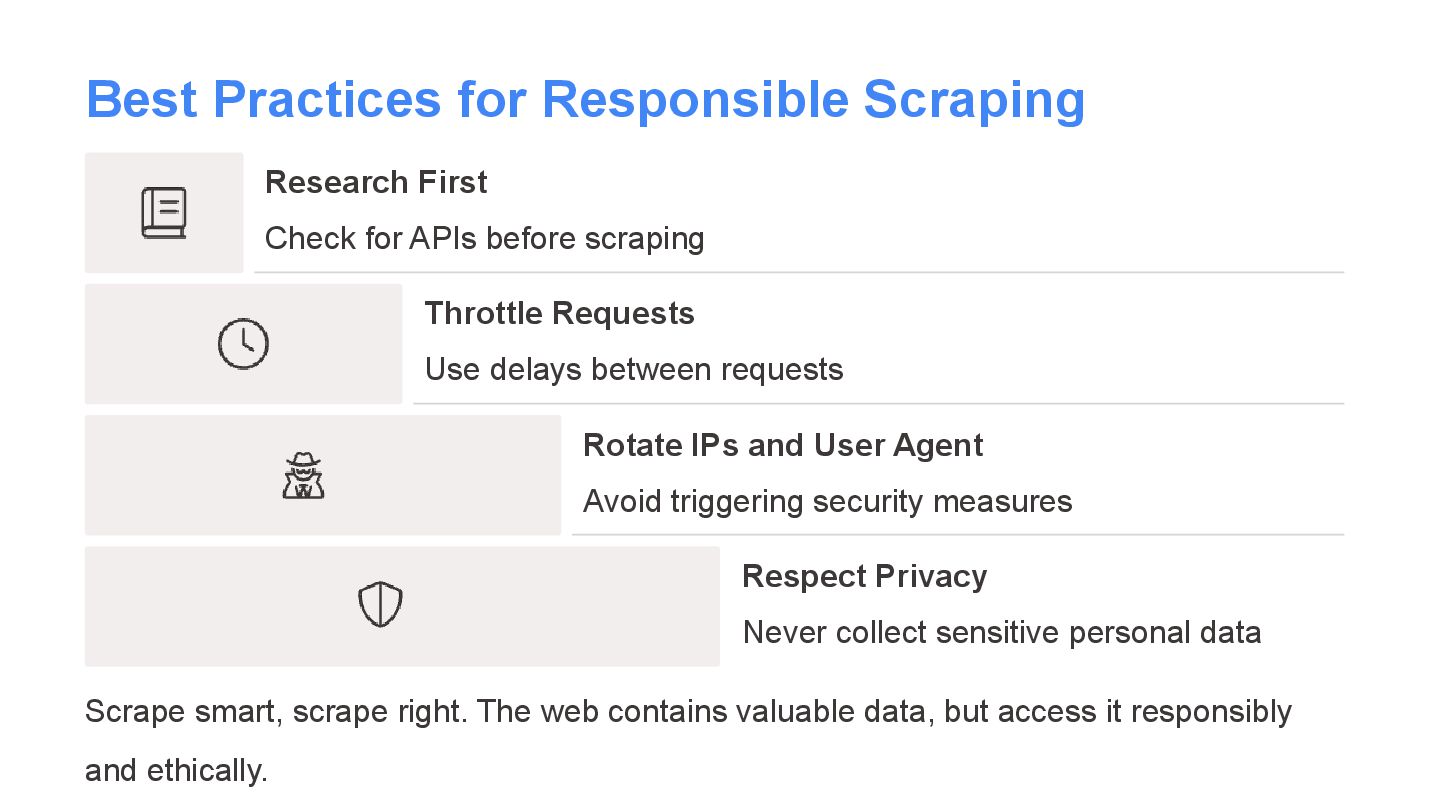
before scraping Throttle Requests Use delays between requests Rotate IPs and User Agent Avoid triggering security measures Respect Privacy Never collect sensitive personal data Scrape smart, scrape right. The web contains valuable data, but access it responsibly and ethically.
prohibit scraping in their terms. Robots.txt This file indicates which parts of a site can be crawled. Server Load Excessive requests can overload websites and disrupt service. Privacy Collecting personal data raises serious ethical and legal issues. The LinkedIn vs. hiQ Labs case highlighted the legal gray areas. Public data accessibility doesn't automatically mean scraping is permitted.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}