Share
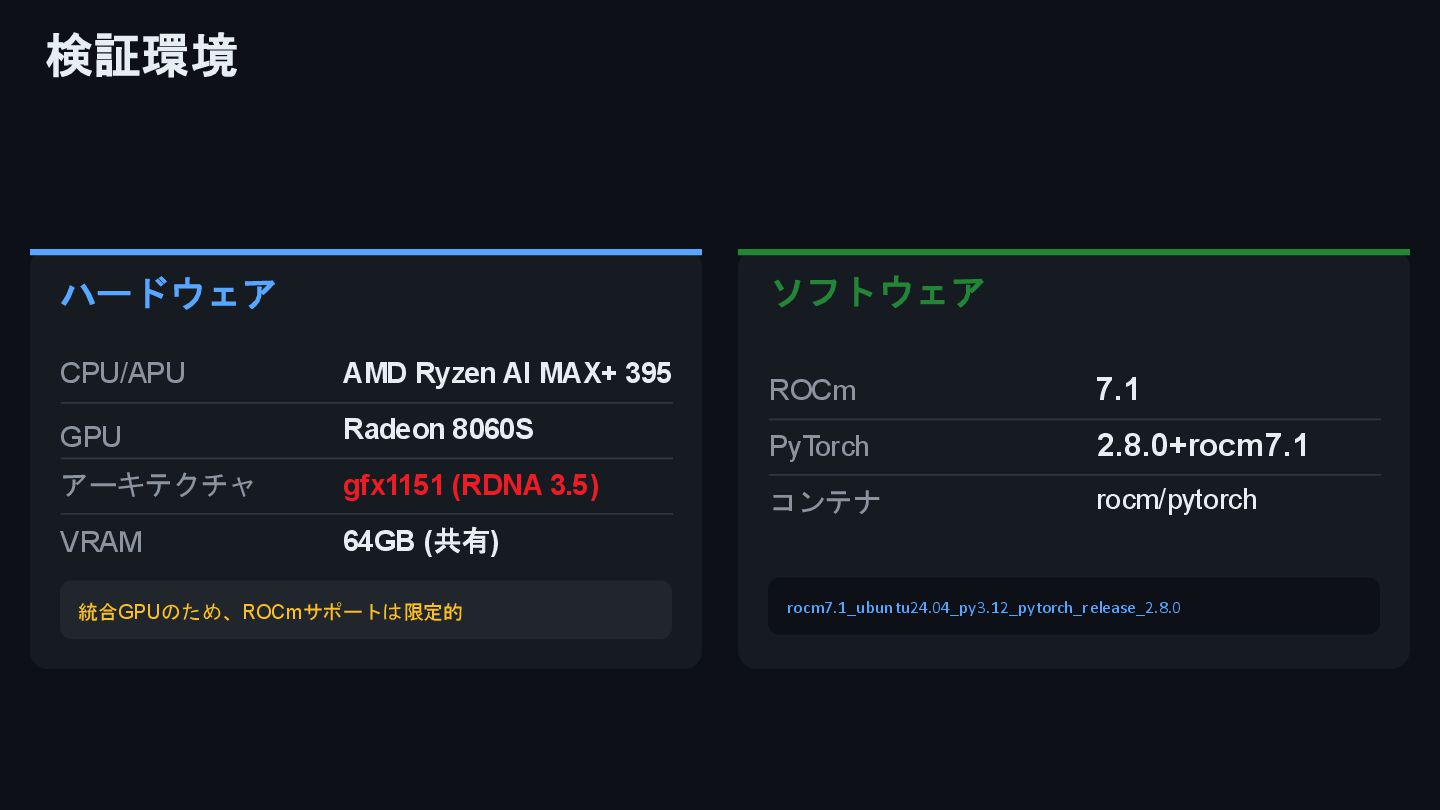
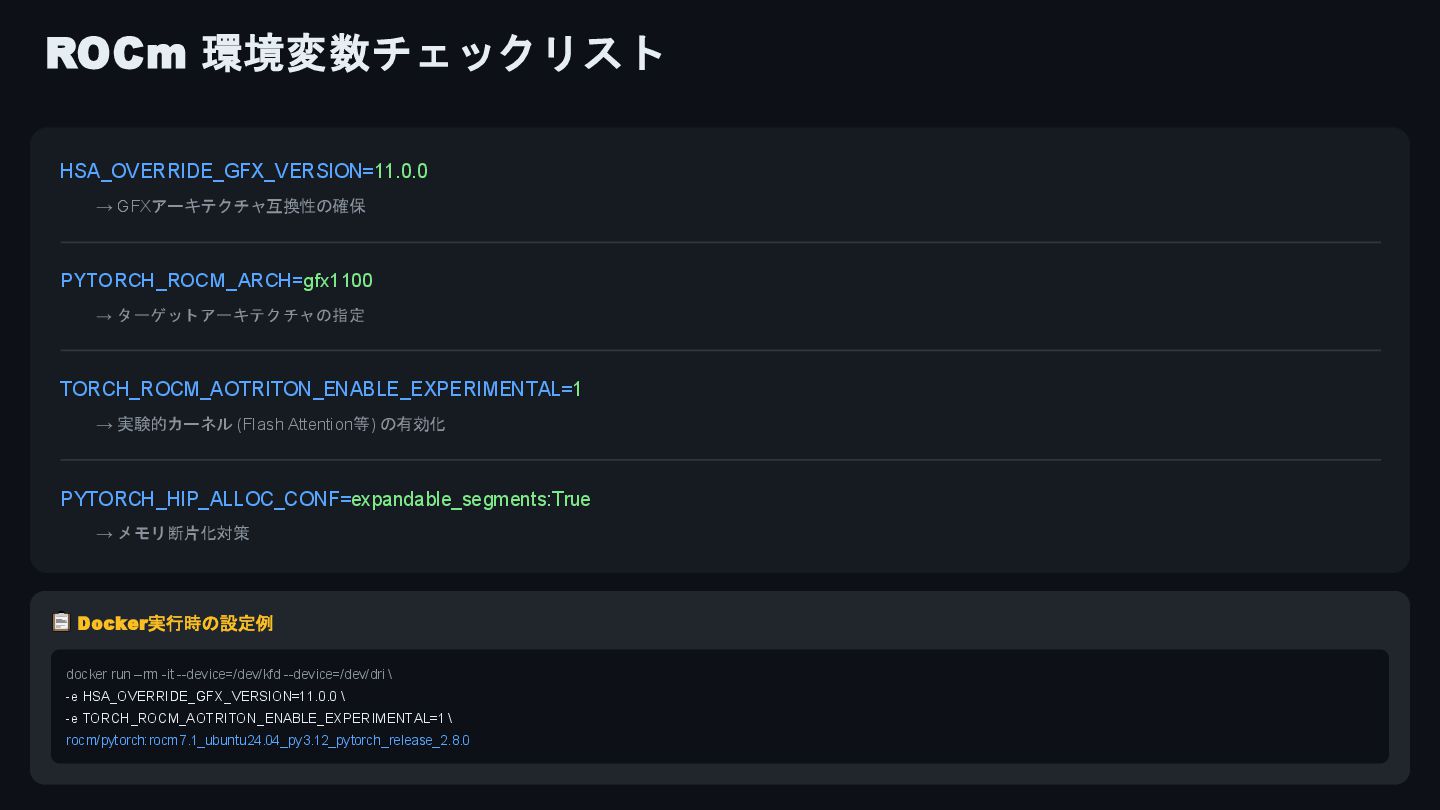
NVIDIA製GPU前提で構築されている Hunyuan 3D -2.1を、Ryzen AI Max+ 395搭載のEVO-X2 (128GB RAM)で動作させるべくチャレンジした結果を、『ローカルAIに向き合う展示会』(https://techplay.jp/event/987584)でのLT向けにまとめたものです。
結局、不完全な動作であったため、当該コードベースをGitHubを公開する予定はありません。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}