Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIエージェントにおける評価指標と評価方法:本番環境での包括的検証戦略
Search
hayata-yamamoto
July 23, 2025
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIエージェントにおける評価指標と評価方法:本番環境での包括的検証戦略
このコンテンツはAIによって作成されています
hayata-yamamoto
July 23, 2025
More Decks by hayata-yamamoto
See All by hayata-yamamoto
東京でも_広島でも__ひろしま_でつながる.pdf
hayata_yamamoto
0
18
生成AI動向まとめ 2025年7月
hayata_yamamoto
1
84
テック系起業家のための 会計入門 数字を味方につける経営ガイド
hayata_yamamoto
0
59
バランスト・スコアカード(BSC)
hayata_yamamoto
0
52
データ同化入門
hayata_yamamoto
0
110
中小企業のための 行政デジタルID活用ガイド
hayata_yamamoto
0
56
統計的意思決定論の入門
hayata_yamamoto
0
270
コンテキストエンジニアリング入門
hayata_yamamoto
0
280
困難は分割せよ。既存のサービスにナレッジベースなAI駆動開発を導入していくための一つの方略
hayata_yamamoto
0
230
Featured
See All Featured
New Earth Scene 8
popppiees
3
2.4k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Raft: Consensus for Rubyists
vanstee
141
7.6k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
The browser strikes back
jonoalderson
0
1.4k
Making Projects Easy
brettharned
120
6.7k
A Tale of Four Properties
chriscoyier
163
24k
Transcript
COMPREHENSIVE STRATEGY AIエージェントにおける評価指標と評価方 AIエージェントにおける評価指標と評価方 法: 法: 本番環境での包括的検証戦略
本番環境での包括的検証戦略 本資料は、AIエージェントの実運用における評価指標・検証手法・ 監視技術の全体像と実践的ベストプラクティスをまとめたものです。
目次 1 はじめに 2 評価指標の全体像 3 パフォーマンス関連の評価指標 4 コスト・リソース関連の評価指標 5
信頼性・堅牢性・適応性の評価指標 6 マルチエージェント特有の指標 7 オフライン評価方法 8 ベンチマーク&シミュレーション設計 9 統計的・構造的分析手法 10 オンライン評価&リアルタイム監視 11 継続的評価フライホイール 12 Observabilityとトレーシング 13 主要ツールとフレームワーク 14 AgentOpsへの進化と運用パイプライン 15 今後の展望と推奨アクション AIエージェントにおける評価指標と評価方法 2
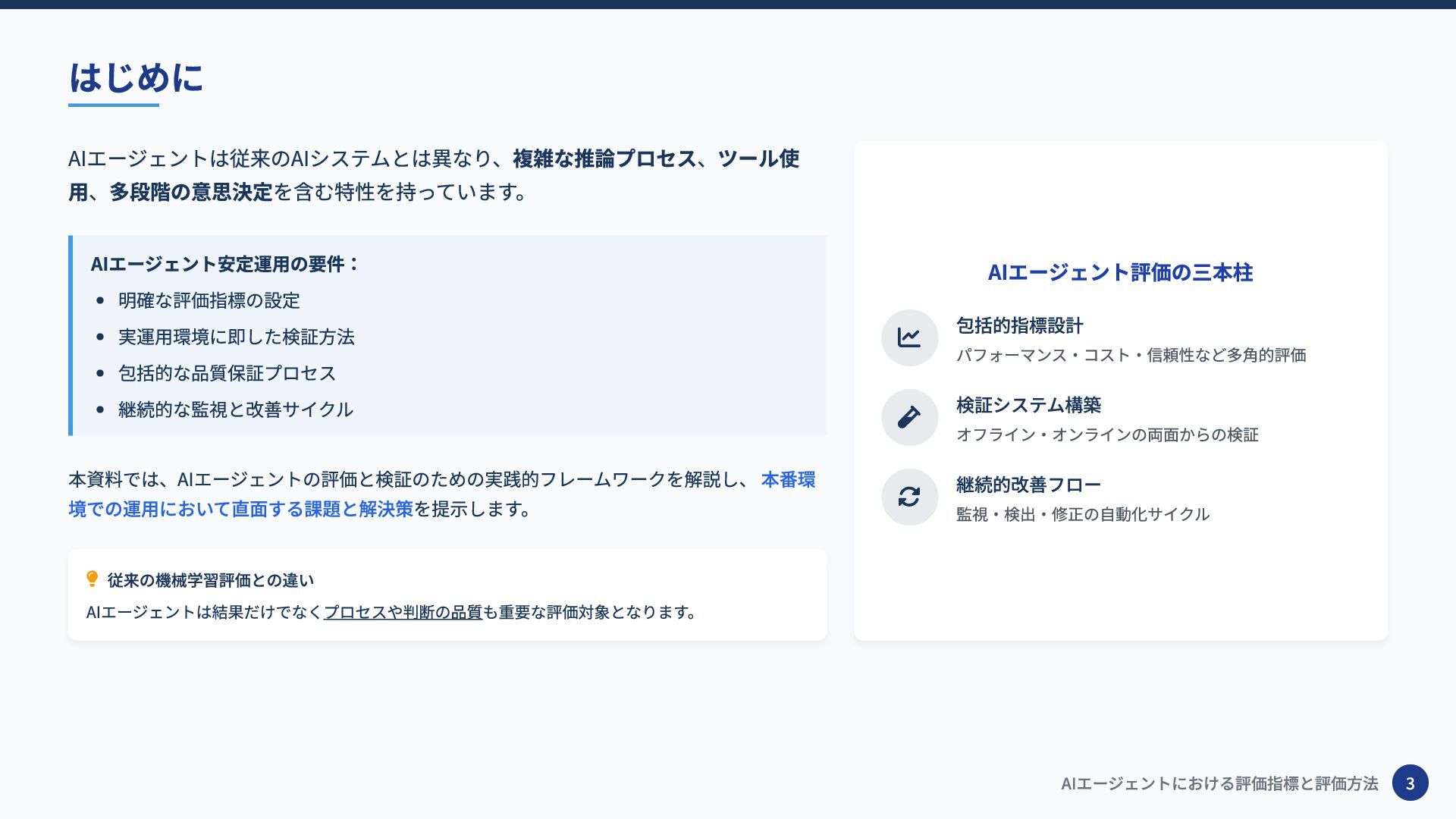
AIエージェントは従来のAIシステムとは異なり、複雑な推論プロセス、ツール使 用、多段階の意思決定を含む特性を持っています。 AIエージェント安定運用の要件: 明確な評価指標の設定 実運用環境に即した検証方法 包括的な品質保証プロセス 継続的な監視と改善サイクル 本資料では、AIエージェントの評価と検証のための実践的フレームワークを解説し、 本番環 境での運用において直面する課題と解決策を提示します。
従来の機械学習評価との違い AIエージェントは結果だけでなくプロセスや判断の品質も重要な評価対象となります。 AIエージェント評価の三本柱 包括的指標設計 パフォーマンス・コスト・信頼性など多角的評価 検証システム構築 オフライン・オンラインの両面からの検証 継続的改善フロー 監視・検出・修正の自動化サイクル はじめに AIエージェントにおける評価指標と評価方法 3
AIエージェントの総合的な評価では、複数の次元から多角的に指標を設定し、 それらを統合的に分析することが求められます。単一指標だけで は捉えきれない複雑な能力を評価するためです。 パフォーマンス指標 レイテンシ(応答時間) 精度・成功率(正確さ) スループット(処理能力) 実運用でのスピードと正確性を測定
コスト・リソース指標 API呼び出し費用 トークン使用量 計算リソース消費 運用コストと資源効率の最適化 信頼性・堅牢性指標 堅牢性(異常入力耐性) 適応性(変化対応力) 一貫性(結果の再現性) 変動・異常条件での動作安定性 協調・連携指標 エージェント間通信効率 タスク分散バランス 競合解決能力 複数エージェントの連携効果 評価指標の統合アプローチ AIエージェントの総合評価では、これらの指標を目的やステージに応じてバランスよく組み合わせることが重要で す。 また、指標間のトレードオフ(例:精度向上とコスト増加)を考慮した最適化が必要です。 ポイント:事業目標に沿った指標の重み付け設定と継続的な見直しを行いましょう。 評価指標の発展段階 基本指標(単一能力評価) 複合指標(複数能力の総合) ビジネス指標(業務KPI連動) 長期的価値指標(持続性) 評価指標の全体像 AIエージェントにおける評価指標と評価方法 4
リアルタイム性の評価ポイント: ユーザー体験を損なわない応答速度 時間的制約のある場面での安定した動作 複数同時リクエスト時のスケーラビリティ 長時間実行タスクの効率的な進捗報告 精度と速度のトレードオフ 高精度優先 重要決定・医療・法務 バランス型
一般業務・顧客サポート 高速応答優先 チャット・検索補助 ※ユースケースに応じた最適バランスを設定することが重要 重要ポイント:リアルタイム性と目標達成率を重視した評価が、AIエージェントの実用性を決定づけます。コンテキストに応じた柔軟な指標設定と継続 的なモニタリングが効果的です。 パフォーマンス関連の評価指標 レイテンシ 応答/タスク完了時間 応答開始時間(Time to First Token) 全体完了時間(Total Completion Time) 推論速度(Inference Speed) 目標値:ユースケースにより異なるが、対話型アプリケーションでは応答開 始 <1秒 が理想的 精度/成功率 Accuracy / Success Rate タスク完了率(Task Completion Rate) 回答精度(Answer Correctness) ツール使用正確性(Tool Use Accuracy) 目標値:タスク完了率 95%以上 、重要タスクでは 99%以上 AIエージェントにおける評価指標と評価方法 5
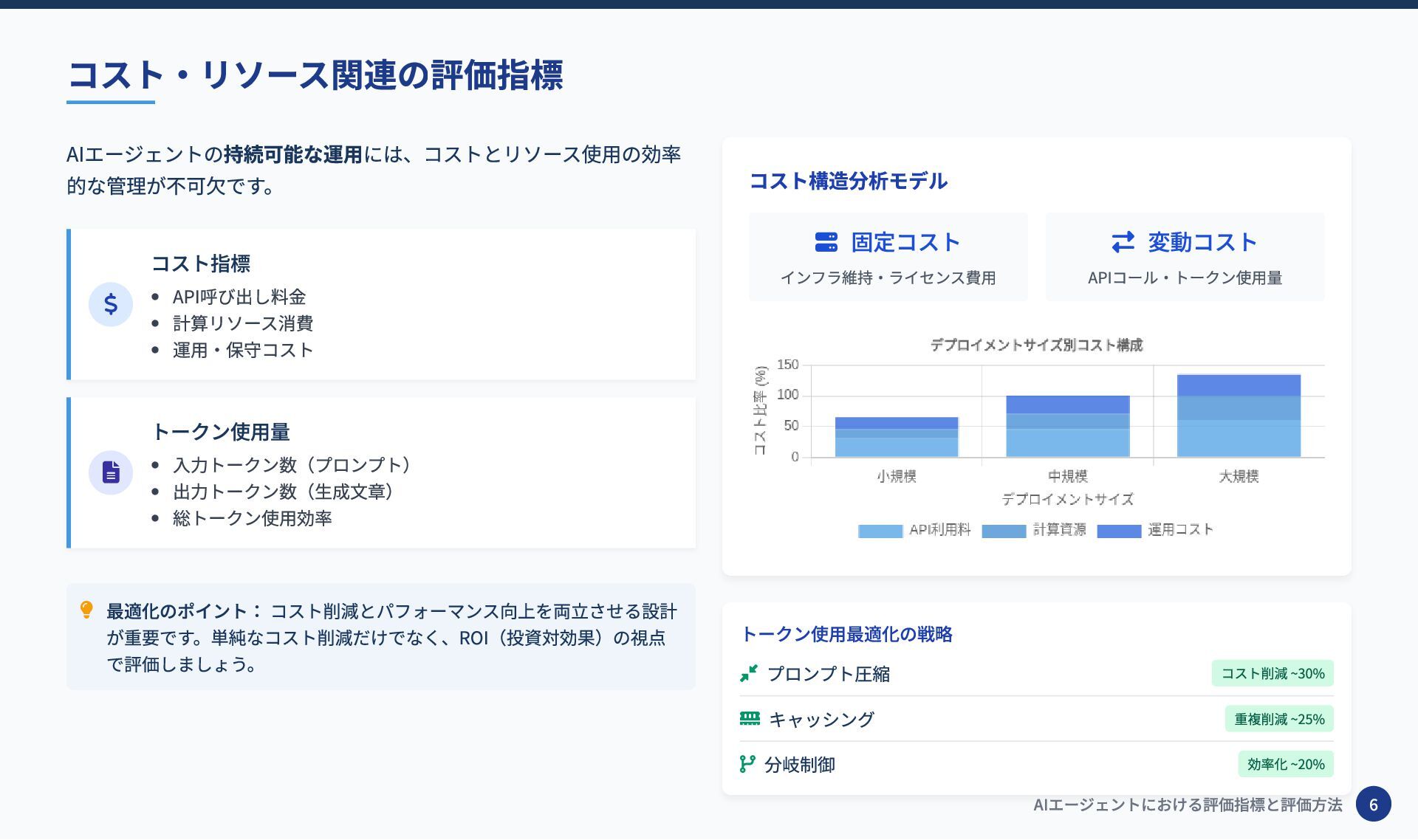
AIエージェントの持続可能な運用には、コストとリソース使用の効率 的な管理が不可欠です。 $ コスト指標 API呼び出し料金 計算リソース消費 運用・保守コスト トークン使用量 入力トークン数(プロンプト)
出力トークン数(生成文章) 総トークン使用効率 最適化のポイント: コスト削減とパフォーマンス向上を両立させる設計 が重要です。単純なコスト削減だけでなく、ROI(投資対効果)の視点 で評価しましょう。 コスト構造分析モデル 固定コスト インフラ維持・ライセンス費用 変動コスト APIコール・トークン使用量 トークン使用最適化の戦略 プロンプト圧縮 コスト削減 ~30% キャッシング 重複削減 ~25% 分岐制御 効率化 ~20% コスト・リソース関連の評価指標 AIエージェントにおける評価指標と評価方法 6
堅牢性 (Robustness) 異常入力や予期せぬ環境変動に対する耐性 評価方法 敵対的入力テスト ノイズ付加実験(入力の改変) エッジケースカバレッジ率 障害回復時間
適応性 (Adaptability) 新規タスクや要件変更への対応能力 評価方法 ゼロショット/フューショット学習性能 転移学習効率 新規ドメイン適応度 タスク切替スピード 信頼性 (Reliability) 結果の一貫性や再現性を示す指標 評価方法 再現性テスト(同条件での結果一致度) 平均故障間隔(MTBF) 変動係数(CV値) SLA達成率 指標間の関係性と総合評価 これら3つの指標は互いに影響し合い、トレードオフの関係にあることも多 く、バランスの取れた設計が必要です。 例: 堅牢性を高めるための制約が、新規タスクへの適応性を低下させる場合があ る 成熟度評価の視点 基本:正常動作の確認(基本機能テスト) 発展:異常処理とリカバリー(回復能力) 応用:予測不能な状況への適応(学習能力) 先進:自己修復と最適化(自律性) 信頼性・堅牢性・適応性の評価指標 AIエージェントにおける評価指標と評価方法 7
協調性指標 通信効率 エージェント間のメッセージ交換量とその有効性 タスク分散バランス 作業負荷の均等分散度と適切な役割分担 競合解決時間 リソース競合や目標衝突の解決速度 システム全体指標
スループット 単位時間あたりの処理タスク数(複数エージェント連携時) 可用性 システム全体としての稼働率と障害復旧能力 スケーラビリティ エージェント数増加時のパフォーマンス変化率 マルチエージェントシステムでは、個別エージェントの性能だけでなく、 システム全体としての協調性と効率を測定する必要があります。 マルチエージェント特有の評価指標 マルチエージェント評価の視覚化 92% タスク完了率 1.2秒 平均調整時間 85% 負荷分散効率 99.5% システム可用性 AIエージェントにおける評価指標と評価方法 8
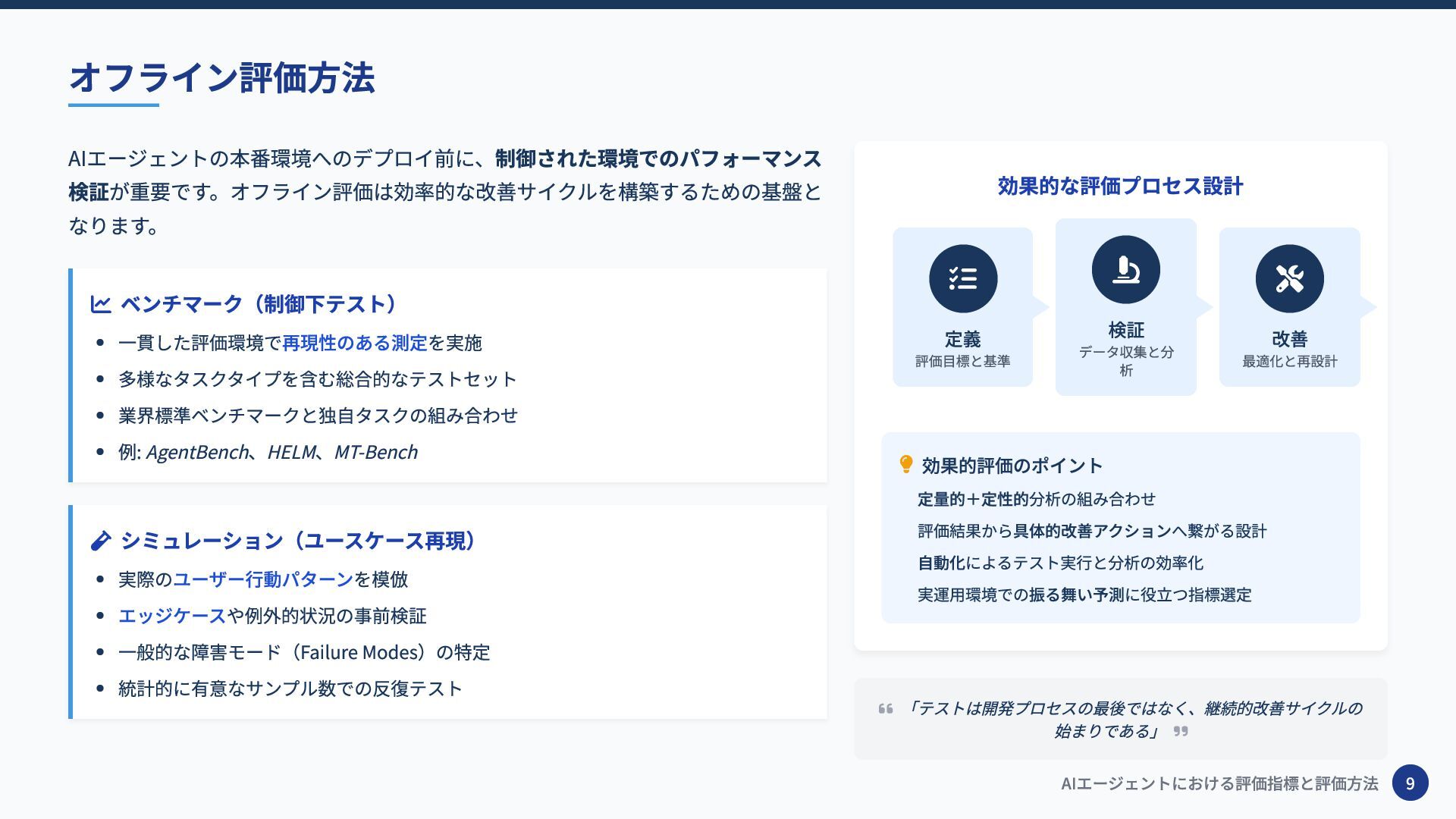
AIエージェントの本番環境へのデプロイ前に、制御された環境でのパフォーマンス 検証が重要です。オフライン評価は効率的な改善サイクルを構築するための基盤と なります。 ベンチマーク(制御下テスト) 一貫した評価環境で再現性のある測定を実施 多様なタスクタイプを含む総合的なテストセット 業界標準ベンチマークと独自タスクの組み合わせ 例: AgentBench、HELM、MT-Bench
シミュレーション(ユースケース再現) 実際のユーザー行動パターンを模倣 エッジケースや例外的状況の事前検証 一般的な障害モード(Failure Modes)の特定 統計的に有意なサンプル数での反復テスト 効果的な評価プロセス設計 効果的評価のポイント 定量的+定性的分析の組み合わせ 評価結果から具体的改善アクションへ繋がる設計 自動化によるテスト実行と分析の効率化 実運用環境での振る舞い予測に役立つ指標選定 「テストは開発プロセスの最後ではなく、継続的改善サイクルの 始まりである」 オフライン評価方法 定義 評価目標と基準 検証 データ収集と分 析 改善 最適化と再設計 AIエージェントにおける評価指標と評価方法 9
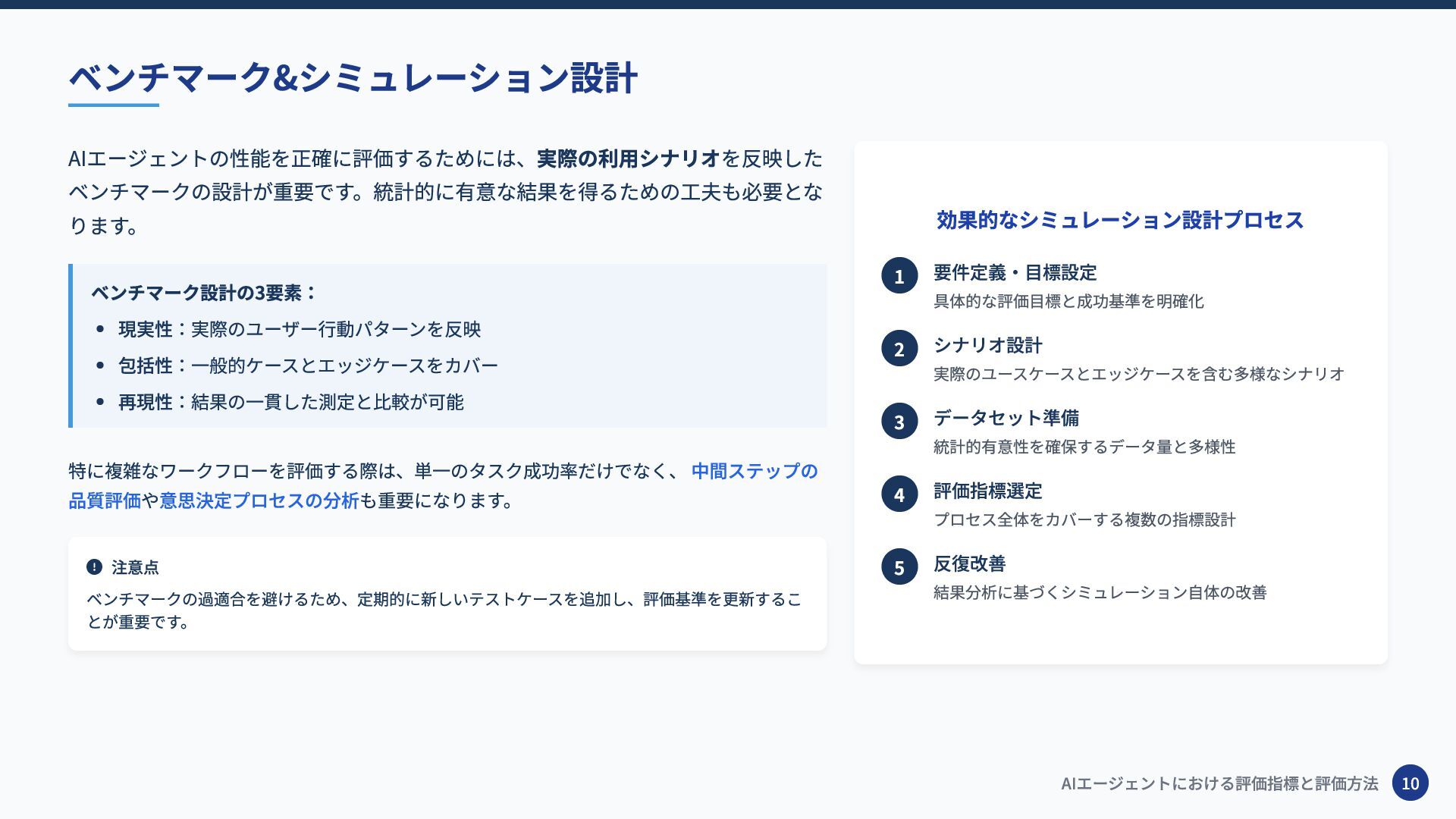
AIエージェントの性能を正確に評価するためには、実際の利用シナリオを反映した ベンチマークの設計が重要です。統計的に有意な結果を得るための工夫も必要とな ります。 ベンチマーク設計の3要素: 現実性:実際のユーザー行動パターンを反映 包括性:一般的ケースとエッジケースをカバー 再現性:結果の一貫した測定と比較が可能 特に複雑なワークフローを評価する際は、単一のタスク成功率だけでなく、 中間ステップの 品質評価や意思決定プロセスの分析も重要になります。
注意点 ベンチマークの過適合を避けるため、定期的に新しいテストケースを追加し、評価基準を更新するこ とが重要です。 効果的なシミュレーション設計プロセス 1 要件定義・目標設定 具体的な評価目標と成功基準を明確化 2 シナリオ設計 実際のユースケースとエッジケースを含む多様なシナリオ 3 データセット準備 統計的有意性を確保するデータ量と多様性 4 評価指標選定 プロセス全体をカバーする複数の指標設計 5 反復改善 結果分析に基づくシミュレーション自体の改善 ベンチマーク&シミュレーション設計 AIエージェントにおける評価指標と評価方法 10
平均二乗誤差 (MSE) 予測値と実際値の差の二乗の平均。AIエージェントの出力精度を数値化し、誤差のば らつきも加味した評価が可能。 MSE = 1/n Σ( 予測値
- 実際値)² グラフエディット距離 (GED) エージェントの思考プロセスや意思決定グラフ間の差異を定量化。操作(ノードの追 加/削除/置換)コストの合計で算出。 グラフ比較 変動係数・その他統計指標 変動係数 (CV): 標準偏差を平均値で割った値。安定性評価に有効 四分位範囲 (IQR): 外れ値の影響を受けにくく堅牢な評価が可能 相関係数: 複数メトリクス間の関連性を分析 タスクフロー・失敗パターン分類 質的評価手法。エージェントの動作や失敗を構造的に分析し、パターン化することで 改善ポイントを特定。 主なタスクフロー分析 決定ポイント追跡 ツール使用効率 リソース消費パターン 失敗パターン分類 誤解釈エラー 実行順序ミス リソース枯渇 多軸評価のアプローチ AIエージェントの複雑な振る舞いを適切に評価するには、単一指標ではなく複数の評価軸を組み合わせることが効果的です。 統計的手法と構造的手法を併用し、定量的評価と定性 的評価を相互補完させることで、より包括的な性能把握が可能になります。 統計的・構造的分析手法 AIエージェントにおける評価指標と評価方法 11
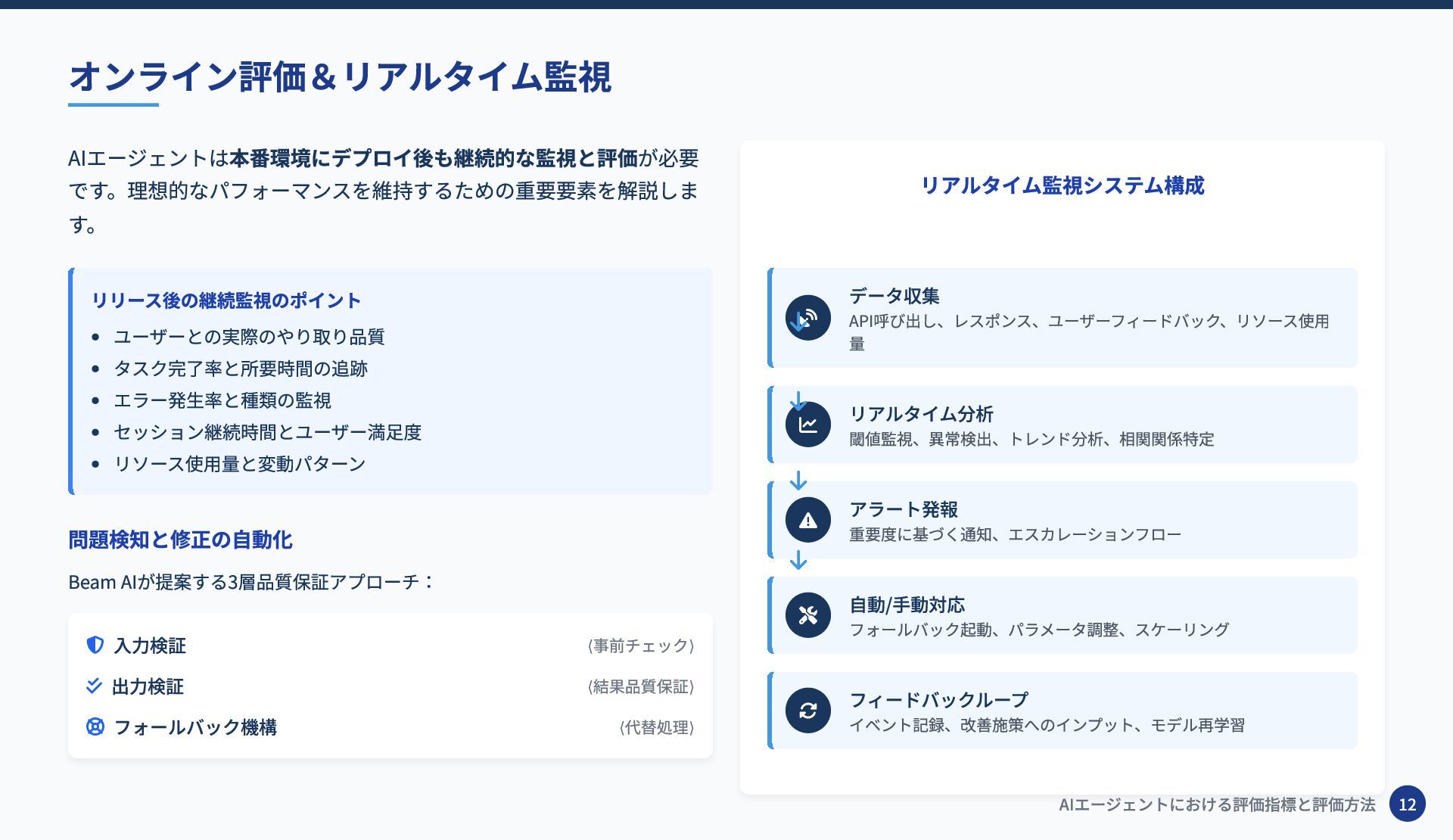
AIエージェントは本番環境にデプロイ後も継続的な監視と評価が必要 です。理想的なパフォーマンスを維持するための重要要素を解説しま す。 リリース後の継続監視のポイント ユーザーとの実際のやり取り品質 タスク完了率と所要時間の追跡 エラー発生率と種類の監視 セッション継続時間とユーザー満足度 リソース使用量と変動パターン 問題検知と修正の自動化
Beam AIが提案する3層品質保証アプローチ: 入力検証 ⟨ 事前チェック ⟩ 出力検証 ⟨ 結果品質保証 ⟩ フォールバック機構 ⟨ 代替処理 ⟩ オンライン評価&リアルタイム監視 リアルタイム監視システム構成 データ収集 API呼び出し、レスポンス、ユーザーフィードバック、リソース使用 量 リアルタイム分析 閾値監視、異常検出、トレンド分析、相関関係特定 アラート発報 重要度に基づく通知、エスカレーションフロー 自動/手動対応 フォールバック起動、パラメータ調整、スケーリング フィードバックループ イベント記録、改善施策へのインプット、モデル再学習 AIエージェントにおける評価指標と評価方法 12
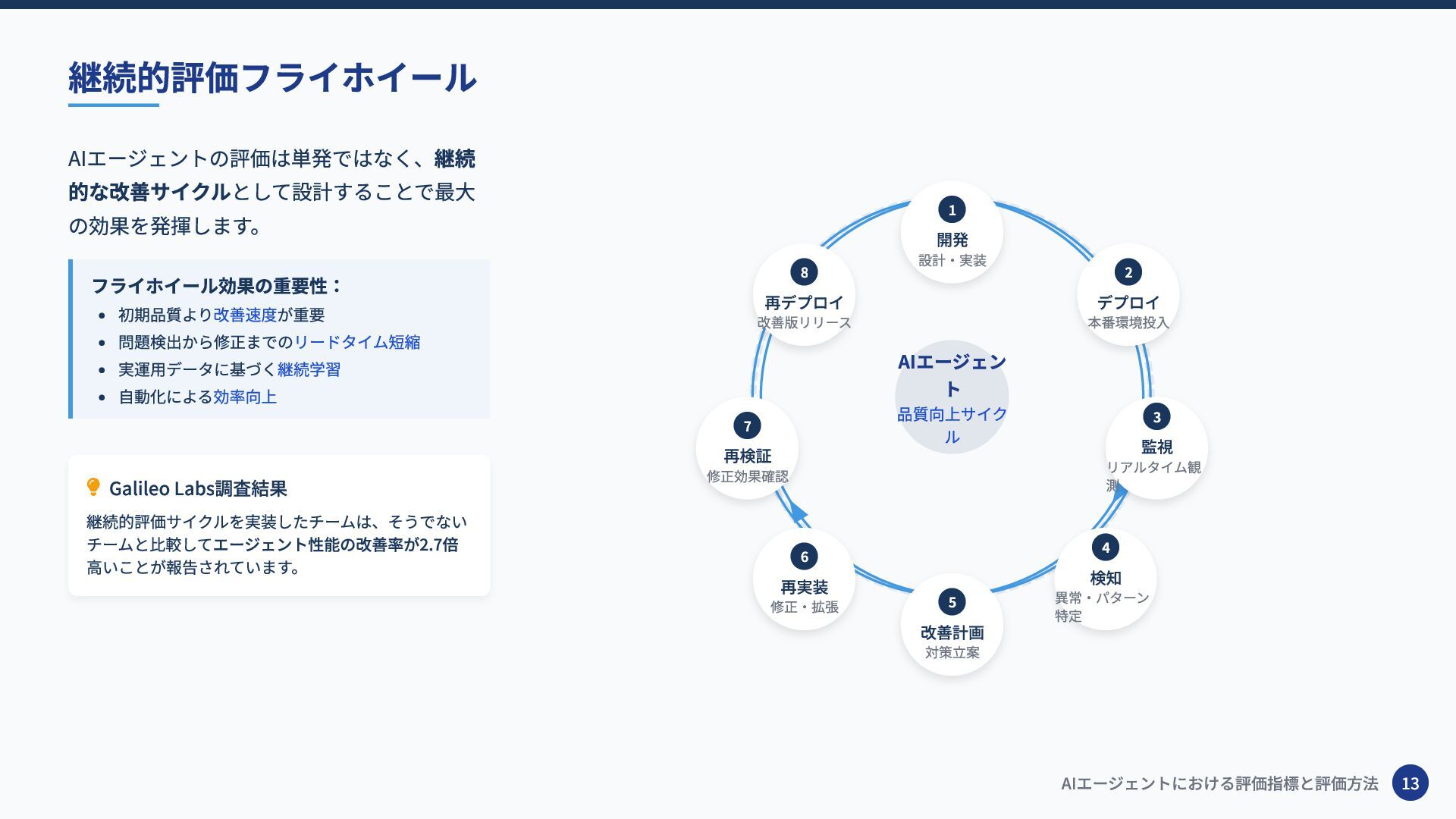
AIエージェントの評価は単発ではなく、継続 的な改善サイクルとして設計することで最大 の効果を発揮します。 フライホイール効果の重要性: 初期品質より改善速度が重要 問題検出から修正までのリードタイム短縮 実運用データに基づく継続学習 自動化による効率向上 Galileo
Labs調査結果 継続的評価サイクルを実装したチームは、そうでない チームと比較してエージェント性能の改善率が2.7倍 高いことが報告されています。 継続的評価フライホイール AIエージェントにおける評価指標と評価方法 13 1 開発 設計・実装 2 デプロイ 本番環境投入 3 監視 リアルタイム観 測 4 検知 異常・パターン 特定 5 改善計画 対策立案 6 再実装 修正・拡張 7 再検証 修正効果確認 8 再デプロイ 改善版リリース AIエージェン ト 品質向上サイク ル
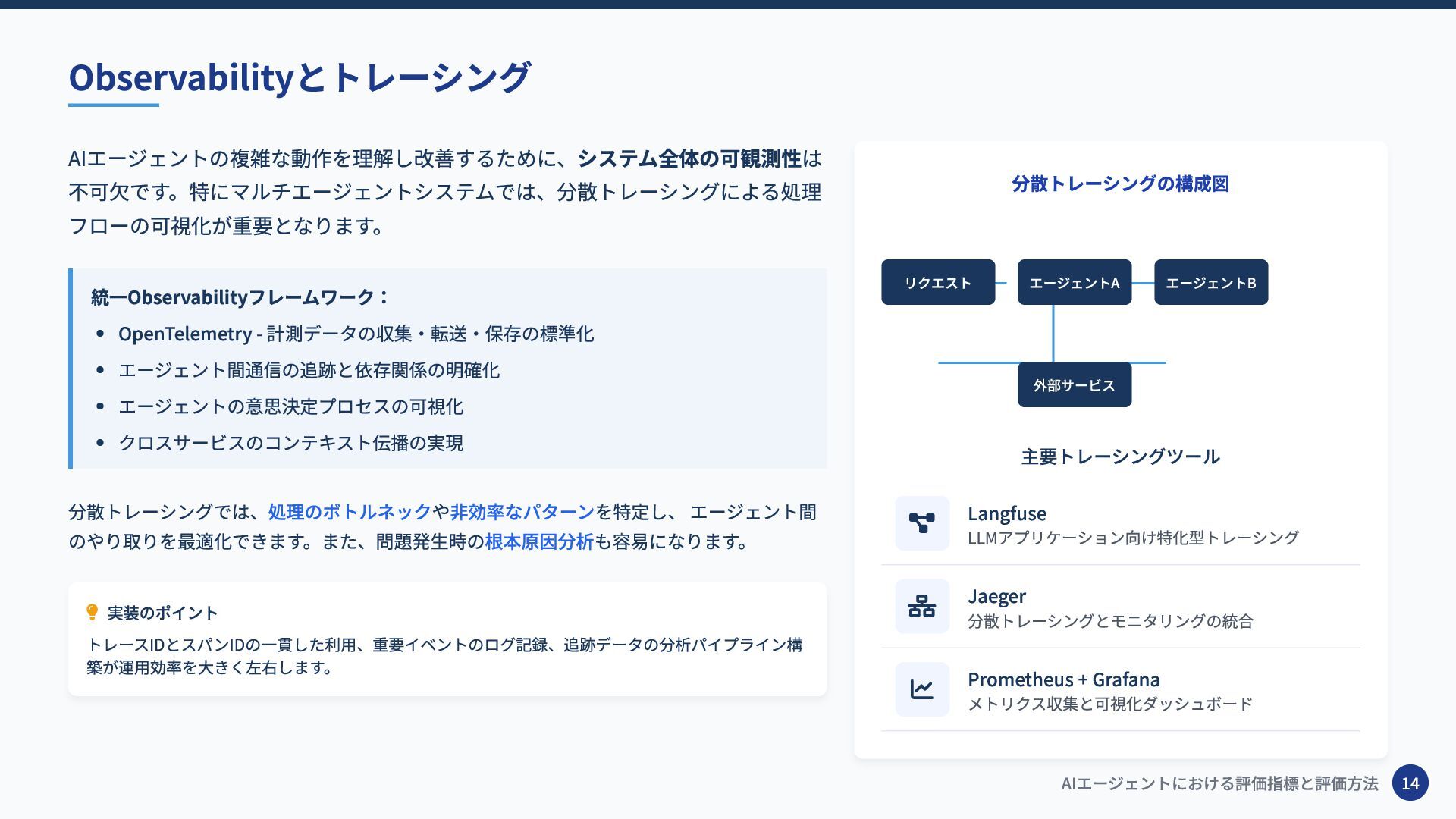
AIエージェントの複雑な動作を理解し改善するために、システム全体の可観測性は 不可欠です。特にマルチエージェントシステムでは、分散トレーシングによる処理 フローの可視化が重要となります。 統一Observabilityフレームワーク: OpenTelemetry - 計測データの収集・転送・保存の標準化 エージェント間通信の追跡と依存関係の明確化 エージェントの意思決定プロセスの可視化 クロスサービスのコンテキスト伝播の実現
分散トレーシングでは、処理のボトルネックや非効率なパターンを特定し、 エージェント間 のやり取りを最適化できます。また、問題発生時の根本原因分析も容易になります。 実装のポイント トレースIDとスパンIDの一貫した利用、重要イベントのログ記録、追跡データの分析パイプライン構 築が運用効率を大きく左右します。 分散トレーシングの構成図 主要トレーシングツール Langfuse LLMアプリケーション向け特化型トレーシング Jaeger 分散トレーシングとモニタリングの統合 Prometheus + Grafana メトリクス収集と可視化ダッシュボード Observabilityとトレーシング リクエスト エージェントA エージェントB 外部サービス AIエージェントにおける評価指標と評価方法 14
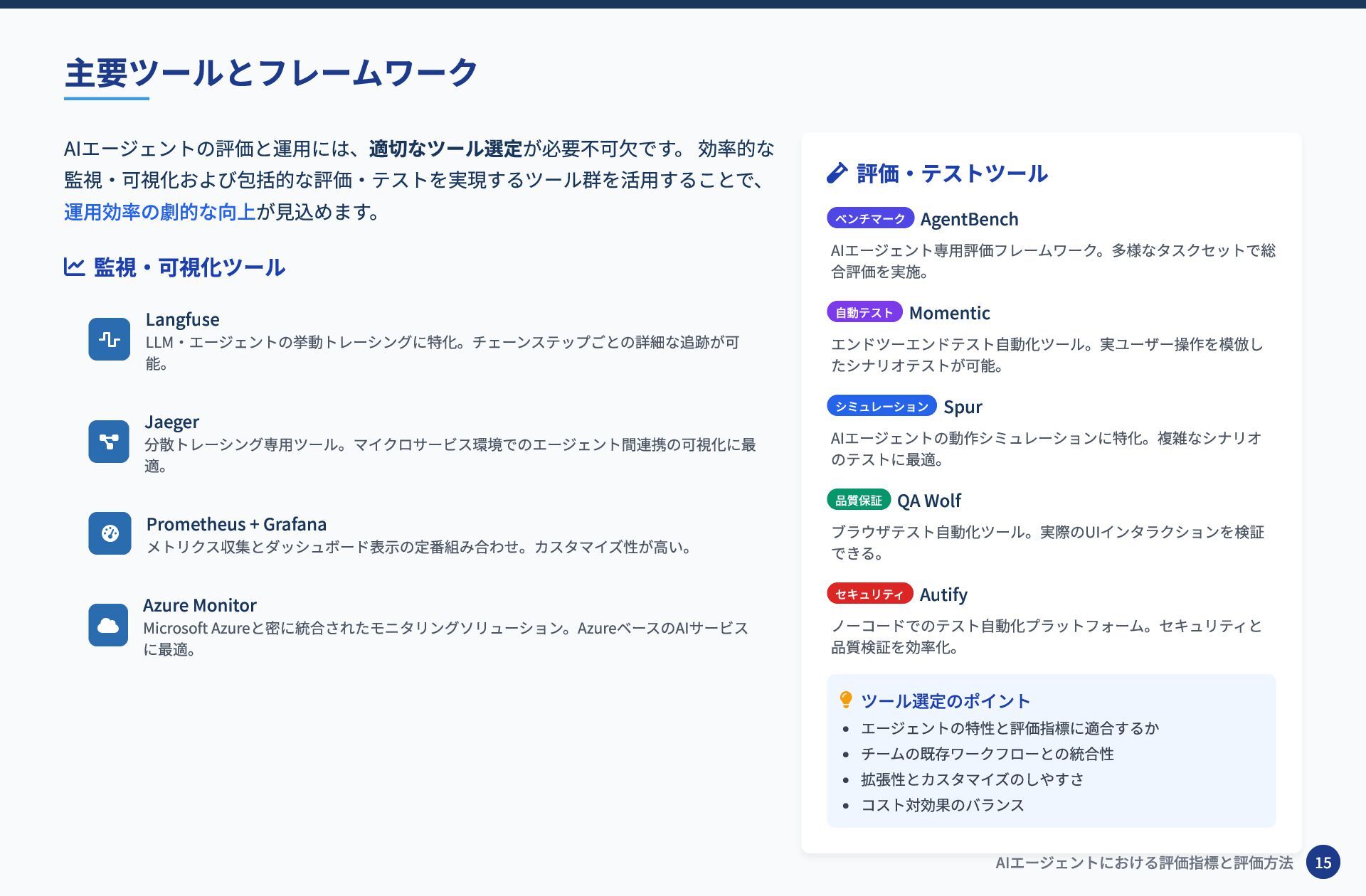
AIエージェントの評価と運用には、適切なツール選定が必要不可欠です。 効率的な 監視・可視化および包括的な評価・テストを実現するツール群を活用することで、 運用効率の劇的な向上が見込めます。 監視・可視化ツール Langfuse LLM・エージェントの挙動トレーシングに特化。チェーンステップごとの詳細な追跡が可 能。
Jaeger 分散トレーシング専用ツール。マイクロサービス環境でのエージェント間連携の可視化に最 適。 Prometheus + Grafana メトリクス収集とダッシュボード表示の定番組み合わせ。カスタマイズ性が高い。 Azure Monitor Microsoft Azureと密に統合されたモニタリングソリューション。AzureベースのAIサービス に最適。 評価・テストツール ベンチマーク AgentBench AIエージェント専用評価フレームワーク。多様なタスクセットで総 合評価を実施。 自動テスト Momentic エンドツーエンドテスト自動化ツール。実ユーザー操作を模倣し たシナリオテストが可能。 シミュレーション Spur AIエージェントの動作シミュレーションに特化。複雑なシナリオ のテストに最適。 品質保証 QA Wolf ブラウザテスト自動化ツール。実際のUIインタラクションを検証 できる。 セキュリティ Autify ノーコードでのテスト自動化プラットフォーム。セキュリティと 品質検証を効率化。 ツール選定のポイント エージェントの特性と評価指標に適合するか チームの既存ワークフローとの統合性 拡張性とカスタマイズのしやすさ コスト対効果のバランス 主要ツールとフレームワーク AIエージェントにおける評価指標と評価方法 15
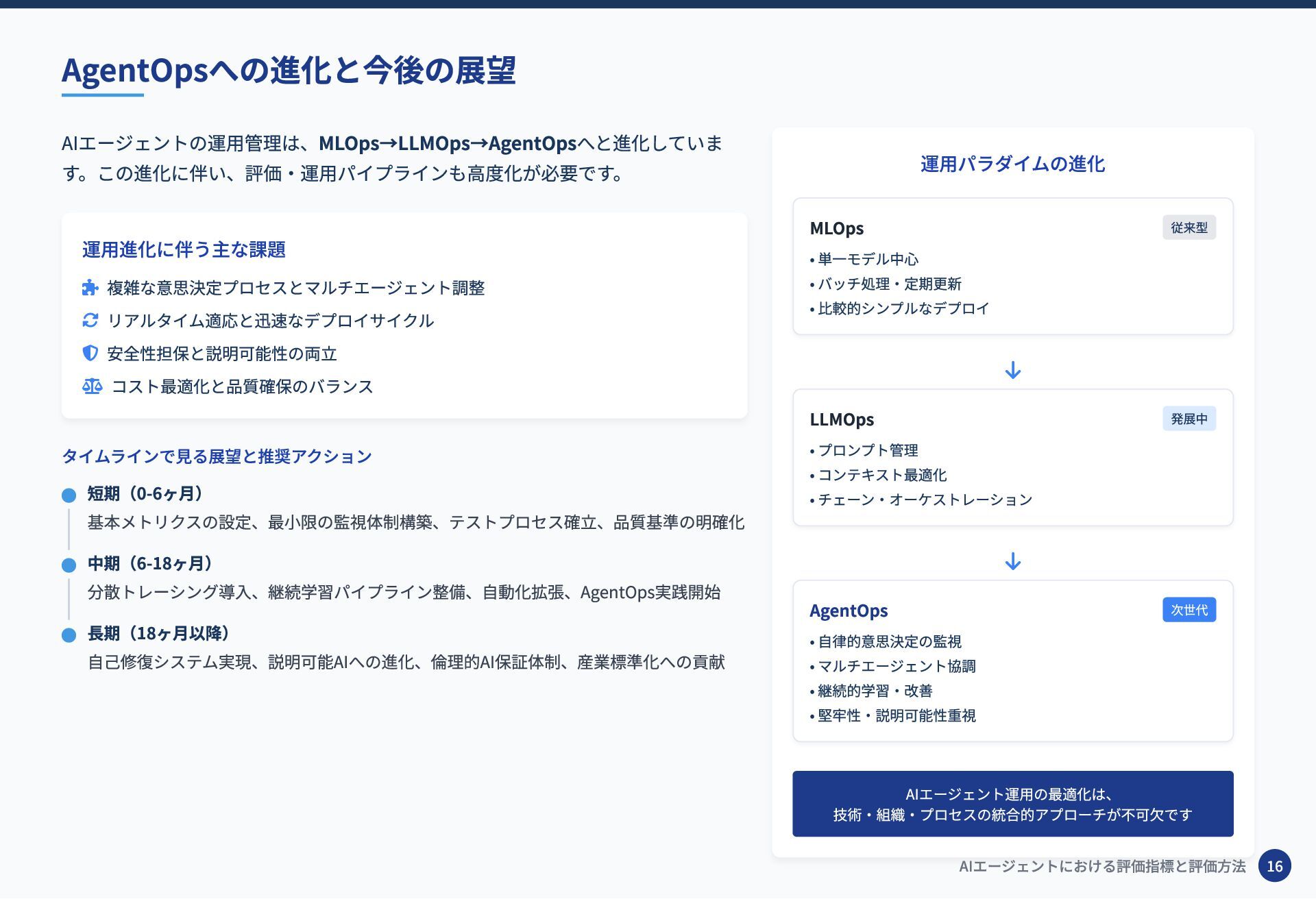
AIエージェントの運用管理は、MLOps→LLMOps→AgentOpsへと進化していま す。この進化に伴い、評価・運用パイプラインも高度化が必要です。 運用進化に伴う主な課題 複雑な意思決定プロセスとマルチエージェント調整 リアルタイム適応と迅速なデプロイサイクル 安全性担保と説明可能性の両立
コスト最適化と品質確保のバランス タイムラインで見る展望と推奨アクション 運用パラダイムの進化 MLOps 従来型 • 単一モデル中心 • バッチ処理・定期更新 • 比較的シンプルなデプロイ LLMOps 発展中 • プロンプト管理 • コンテキスト最適化 • チェーン・オーケストレーション AgentOps 次世代 • 自律的意思決定の監視 • マルチエージェント協調 • 継続的学習・改善 • 堅牢性・説明可能性重視 AIエージェント運用の最適化は、 技術・組織・プロセスの統合的アプローチが不可欠です AgentOpsへの進化と今後の展望 短期(0-6ヶ月) 基本メトリクスの設定、最小限の監視体制構築、テストプロセス確立、品質基準の明確化 中期(6-18ヶ月) 分散トレーシング導入、継続学習パイプライン整備、自動化拡張、AgentOps実践開始 長期(18ヶ月以降) 自己修復システム実現、説明可能AIへの進化、倫理的AI保証体制、産業標準化への貢献 AIエージェントにおける評価指標と評価方法 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}