Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
コンテキストエンジニアリング入門
Search
hayata-yamamoto
July 22, 2025
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
コンテキストエンジニアリング入門
https://chatgpt.com/s/dr_68804336a4648191b22d1119600a5822
を元に作成しています
hayata-yamamoto
July 22, 2025
More Decks by hayata-yamamoto
See All by hayata-yamamoto
東京でも_広島でも__ひろしま_でつながる.pdf
hayata_yamamoto
0
18
生成AI動向まとめ 2025年7月
hayata_yamamoto
1
84
テック系起業家のための 会計入門 数字を味方につける経営ガイド
hayata_yamamoto
0
59
バランスト・スコアカード(BSC)
hayata_yamamoto
0
52
データ同化入門
hayata_yamamoto
0
110
中小企業のための 行政デジタルID活用ガイド
hayata_yamamoto
0
56
AIエージェントにおける評価指標と評価方法:本番環境での包括的検証戦略
hayata_yamamoto
0
110
統計的意思決定論の入門
hayata_yamamoto
0
270
困難は分割せよ。既存のサービスにナレッジベースなAI駆動開発を導入していくための一つの方略
hayata_yamamoto
0
230
Featured
See All Featured
30 Presentation Tips
portentint
PRO
1
350
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
900
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
It's Worth the Effort
3n
188
29k
Making Projects Easy
brettharned
120
6.7k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Believing is Seeing
oripsolob
1
170
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The Curse of the Amulet
leimatthew05
2
13k
Transcript
コンテキストエンジニアリング: コンテキストエンジニアリング: 生成AI エージェント構築入門 生成AI エージェント構築入門 ― AI 時代を支える新しい知識管理と設計技術 ―
資料ベース:生成AI エージェント構築入門/コンテキストエンジニアリング 発表者:日本太郎 2025 年7 月23 日 Genspark で作成
目次/ 目次/ アジェンダ アジェンダ 本日のフローチャート 1 タイトル 2 目次/アジェンダ
3 コンテキストエンジニアリングとは? 4 従来手法との比較 5 LLM におけるコンテキストの役割 6 コンテキストの制限と課題 7 戦略①:圧縮 8 戦略②:選別 9 戦略③:動的スイッチ・分割統治 10 戦略④:集約とメモリ管理 11 Python 実装例 12 ベストプラクティス 13 実応用例 14 まとめ・今後 15 質疑応答 Genspark で作成
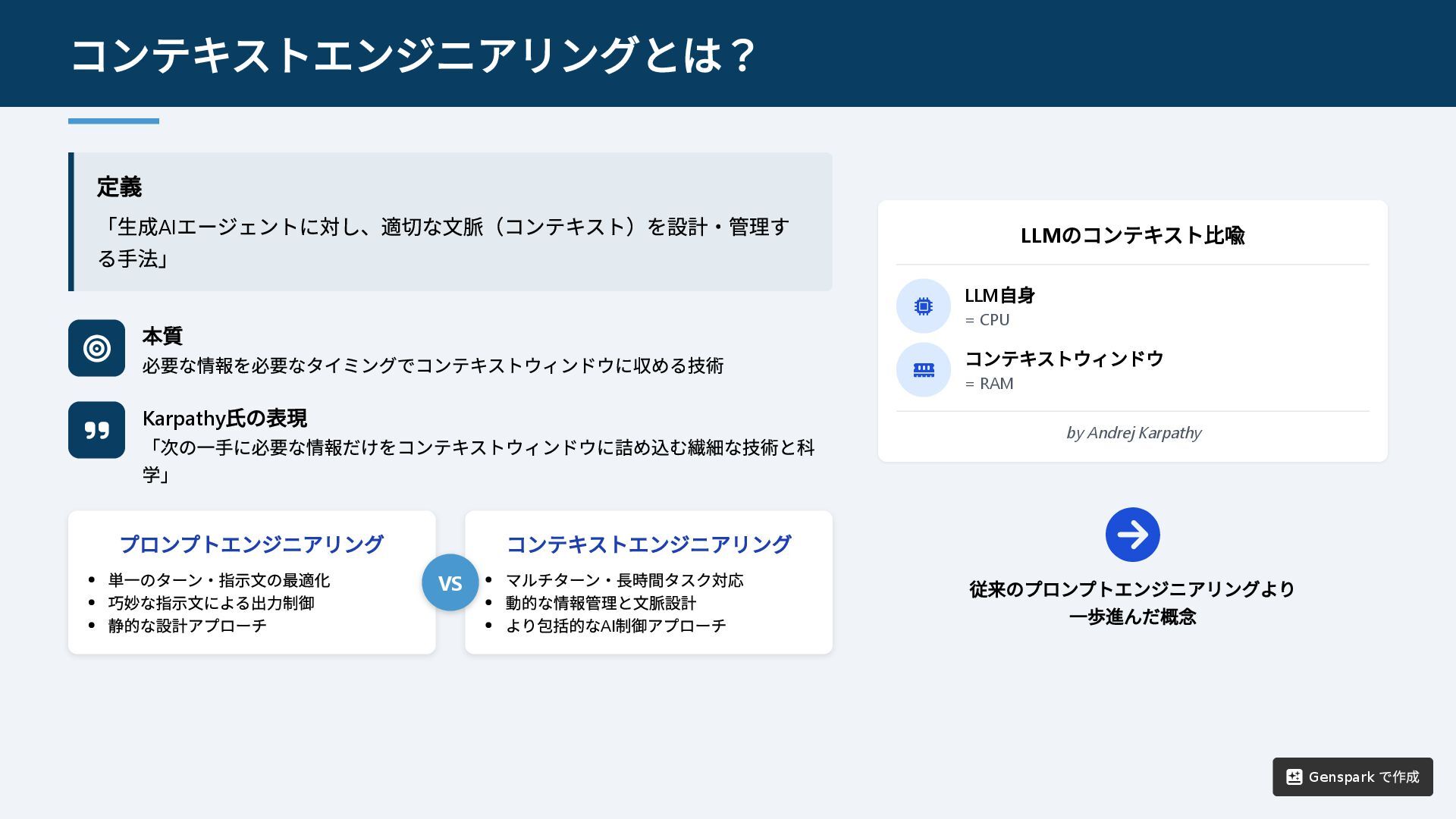
定義 「生成AI エージェントに対し、適切な文脈(コンテキスト)を設計・管理す る手法」 本質 必要な情報を必要なタイミングでコンテキストウィンドウに収める技術 Karpathy 氏の表現
「次の一手に必要な情報だけをコンテキストウィンドウに詰め込む繊細な技術と科 学」 LLM のコンテキスト比喩 LLM 自身 = CPU コンテキストウィンドウ = RAM by Andrej Karpathy 従来のプロンプトエンジニアリングより 一歩進んだ概念 コンテキストエンジニアリングとは? プロンプトエンジニアリング 単一のターン・指示文の最適化 巧妙な指示文による出力制御 静的な設計アプローチ コンテキストエンジニアリング マルチターン・長時間タスク対応 動的な情報管理と文脈設計 より包括的なAI 制御アプローチ VS Genspark で作成
両者の基本的な違い プロンプトエンジニアリングが「巧妙な指示文での出力制御」なのに対し、 コンテキストエンジニアリングは「必要な情報の動的管理」を重視します 観点 プロンプトエンジニアリング コンテキストエンジニアリン グ 対話形式 主に単発的なやり取り マルチターン・長時間に及ぶ
タスク 設計対象 指示文(プロンプト)の最適 化 文脈全体(指示+知識+履 歴)の管理 アプローチ 静的な設計・調整 動的な情報選別・圧縮・切替 長期記憶 基本的に考慮しない 積極的に管理・活用する マルチターン対話での優位性 Anthropic 社の研究では、コンテキストエンジニアリングを活用したマルチエージェ ント方式が単一エージェント方式より90% 以上の性能向上を示しました 対話の複雑さによる適切な手法 タスクの複雑さと持続時間に応じて 適切なアプローチが変わります コンテキストエンジニアリングの利点 長期間に及ぶ一貫した対話の維持 大量の知識・情報を必要に応じて参照 文脈切替による柔軟なタスク対応 システムの自己最適化・動的適応能力 従来手法との比較 ― プロンプトエンジニアリングと何が違う? プロンプト エンジニアリング 両方の 組み合わせ コンテキスト エンジニアリング シンプルな質問 中程度の複雑さ 複雑なタスク Genspark で作成
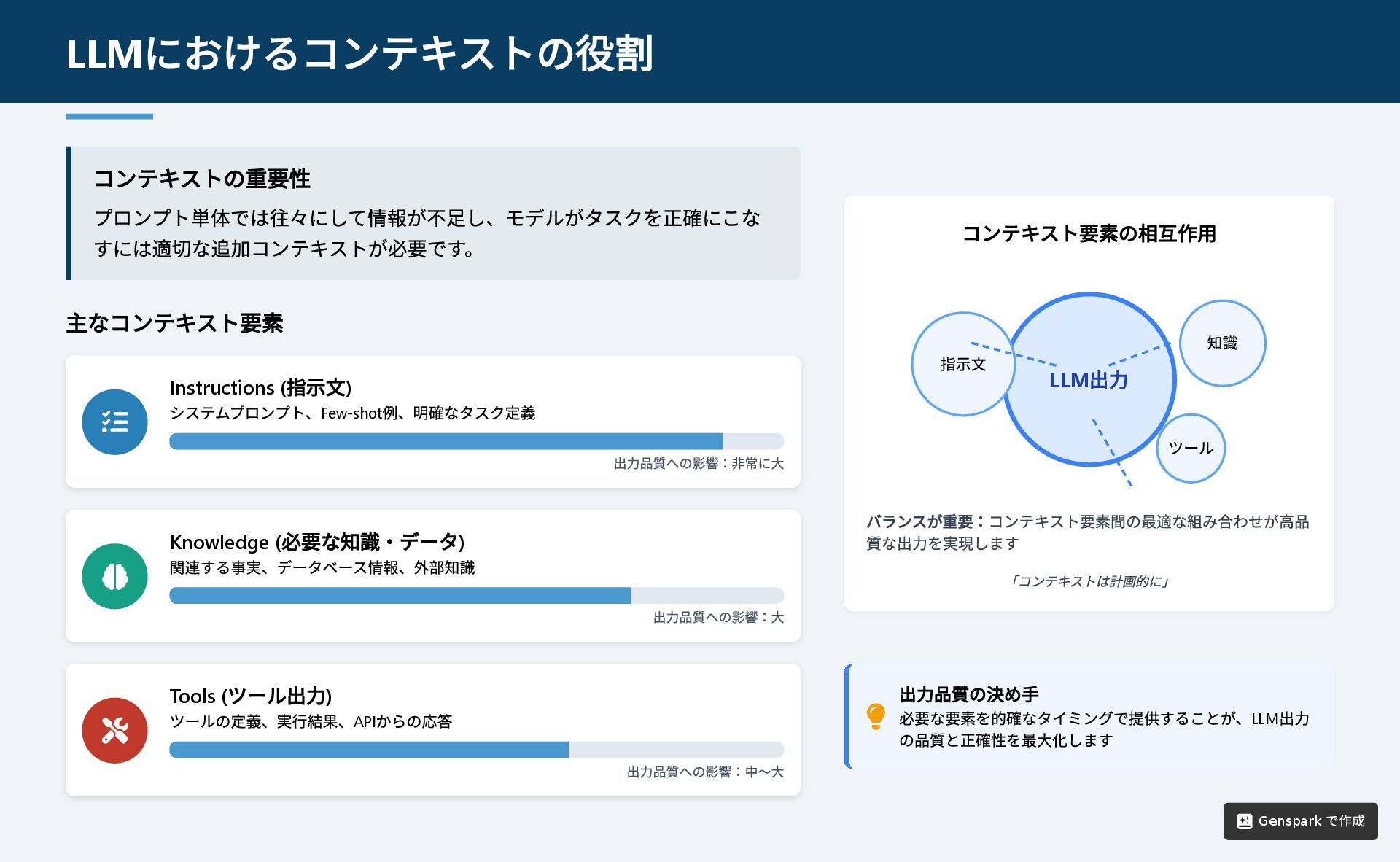
コンテキストの重要性 プロンプト単体では往々にして情報が不足し、モデルがタスクを正確にこな すには適切な追加コンテキストが必要です。 主なコンテキスト要素 Instructions ( 指示文) システムプロンプト、Few-shot 例、明確なタスク定義
出力品質への影響:非常に大 Knowledge ( 必要な知識・データ) 関連する事実、データベース情報、外部知識 出力品質への影響:大 Tools ( ツール出力) ツールの定義、実行結果、API からの応答 出力品質への影響:中~大 コンテキスト要素の相互作用 バランスが重要:コンテキスト要素間の最適な組み合わせが高品 質な出力を実現します 「コンテキストは計画的に」 出力品質の決め手 必要な要素を的確なタイミングで提供することが、LLM 出力 の品質と正確性を最大化します LLM におけるコンテキストの役割 LLM 出力 指示文 知識 ツール Genspark で作成
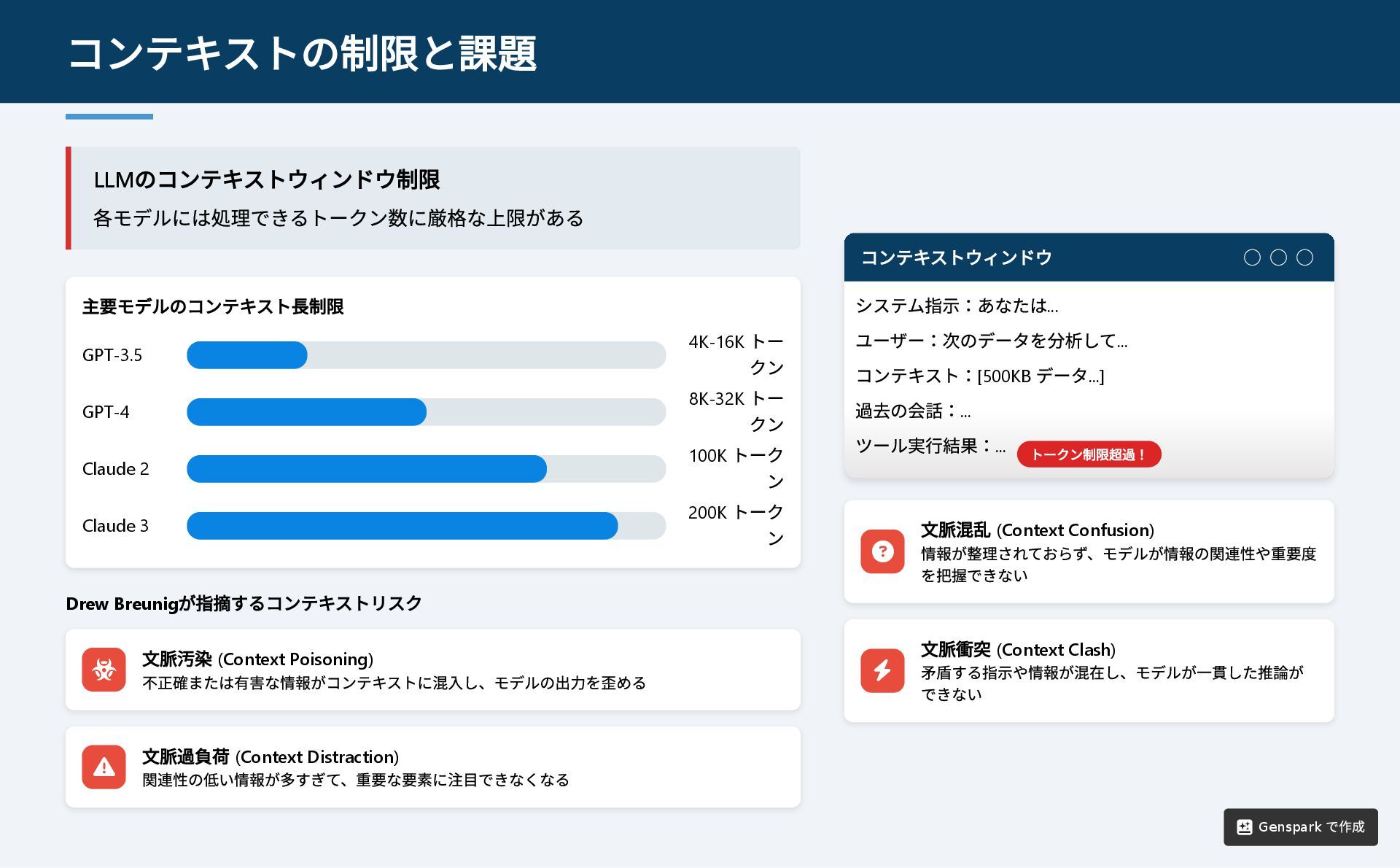
LLM のコンテキストウィンドウ制限 各モデルには処理できるトークン数に厳格な上限がある 主要モデルのコンテキスト長制限 GPT-3.5 4K-16K トー クン GPT-4 8K-32K
トー クン Claude 2 100K トーク ン Claude 3 200K トーク ン Drew Breunig が指摘するコンテキストリスク 文脈汚染 (Context Poisoning) 不正確または有害な情報がコンテキストに混入し、モデルの出力を歪める 文脈過負荷 (Context Distraction) 関連性の低い情報が多すぎて、重要な要素に注目できなくなる コンテキストウィンドウ ◯ ◯ ◯ 文脈混乱 (Context Confusion) 情報が整理されておらず、モデルが情報の関連性や重要度 を把握できない 文脈衝突 (Context Clash) 矛盾する指示や情報が混在し、モデルが一貫した推論が できない コンテキストの制限と課題 トークン制限超過! システム指示:あなたは... ユーザー:次のデータを分析して... コンテキスト:[500KB データ...] 過去の会話:... ツール実行結果:... Genspark で作成
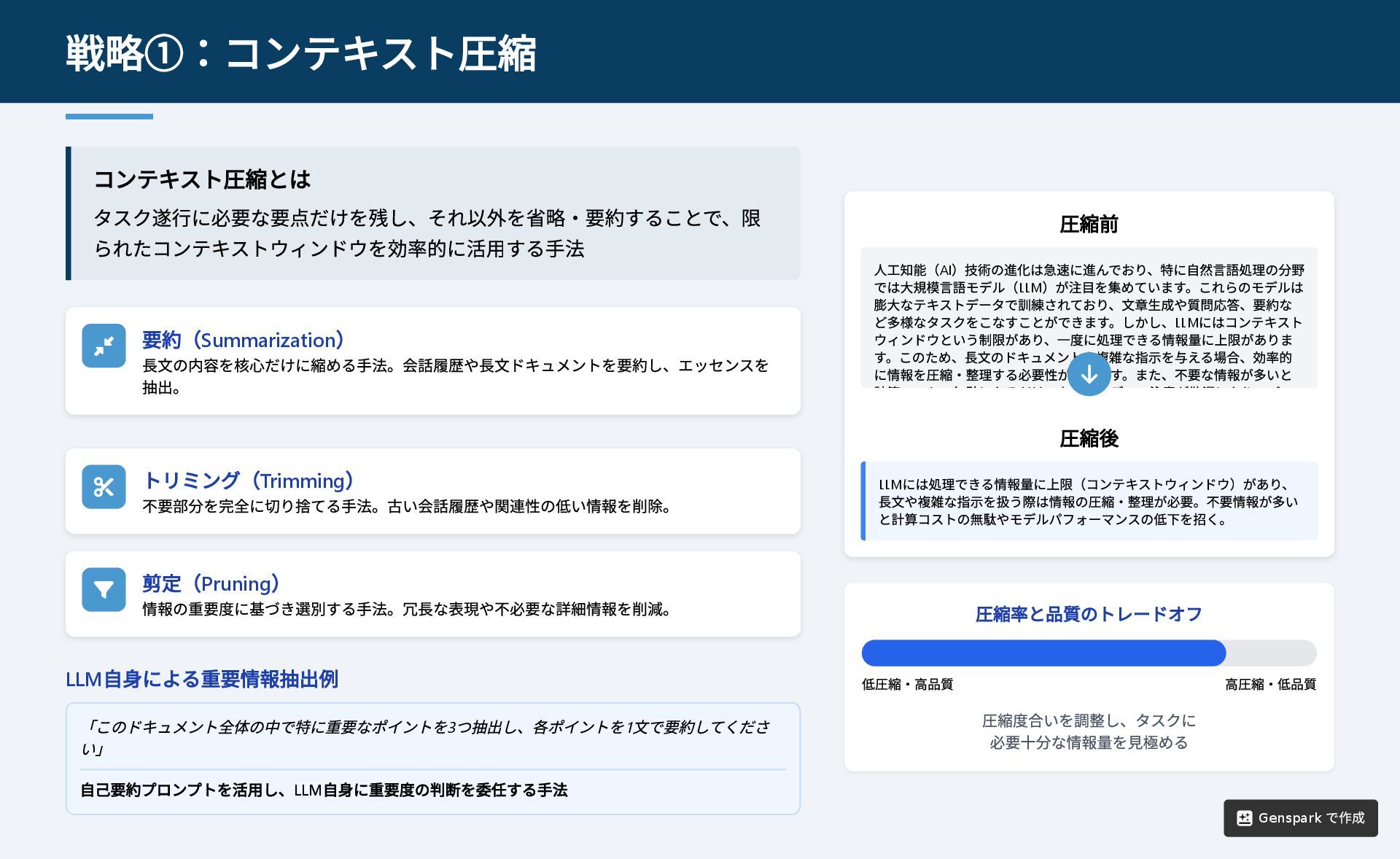
コンテキスト圧縮とは タスク遂行に必要な要点だけを残し、それ以外を省略・要約することで、限 られたコンテキストウィンドウを効率的に活用する手法 要約(Summarization ) 長文の内容を核心だけに縮める手法。会話履歴や長文ドキュメントを要約し、エッセンスを 抽出。 トリミング(Trimming
) 不要部分を完全に切り捨てる手法。古い会話履歴や関連性の低い情報を削除。 剪定(Pruning ) 情報の重要度に基づき選別する手法。冗長な表現や不必要な詳細情報を削減。 LLM 自身による重要情報抽出例 「このドキュメント全体の中で特に重要なポイントを3 つ抽出し、各ポイントを1 文で要約してくださ い」 自己要約プロンプトを活用し、LLM 自身に重要度の判断を委任する手法 圧縮率と品質のトレードオフ 低圧縮・高品質 高圧縮・低品質 圧縮度合いを調整し、タスクに 必要十分な情報量を見極める 戦略①:コンテキスト圧縮 圧縮前 人工知能(AI )技術の進化は急速に進んでおり、特に自然言語処理の分野 では大規模言語モデル(LLM )が注目を集めています。これらのモデルは 膨大なテキストデータで訓練されており、文章生成や質問応答、要約な ど多様なタスクをこなすことができます。しかし、LLM にはコンテキスト ウィンドウという制限があり、一度に処理できる情報量に上限がありま す。このため、長文のドキュメントや複雑な指示を与える場合、効率的 に情報を圧縮・整理する必要性が生じます。また、不要な情報が多いと 計算 ト 無駄になるだけ なく デ 注意が散漫になり パ 圧縮後 LLM には処理できる情報量に上限(コンテキストウィンドウ)があり、 長文や複雑な指示を扱う際は情報の圧縮・整理が必要。不要情報が多い と計算コストの無駄やモデルパフォーマンスの低下を招く。 Genspark で作成
コンテキスト選別(セレクション)とは 大量の知識や過去の記憶から、その都度関連する部分だけを抽出して提示す る手法 RAG (Retrieval-Augmented Generation ) 外部知識ベースから関連情報を検索し、LLM の生成に活用する手法
→ プロンプト内の情報不足を補い、事実に基づいた正確な回答が可能に ベクトル検索(Embedding 検索) 文書やクエリを数値ベクトルに変換し、意味的な類似性で検索 → キーワードだけでなく、文脈や意味を捉えた高精度な関連情報抽出 RetrievalQA の基本フロー ユーザー 質問 文書から関連 情報検索 検索結果を コンテキスト に追加 LLM による 回答生成 Embedding ・チャンク分割・関連度スコアリングを駆使して 情報の鮮度と適切性を最大化 動的コンテキスト選別の利点 コンテキスト窓の最適化 重要情報のみを選別し、トークン使用を効率化 最新情報へのアクセス LLM の訓練データ以降の情報も参照可能 専門知識の強化 特定ドメインの正確性を向上 幻覚(誤情報)の軽減 事実に基づいた回答を促進 実装アプローチ FAISS やChromaDB などのベクトルDB 活用 セマンティック検索とキーワード検索の併用 リランキングによる関連性向上 ユーザー行動分析による選別最適化 戦略②:コンテキスト選別 Genspark で作成
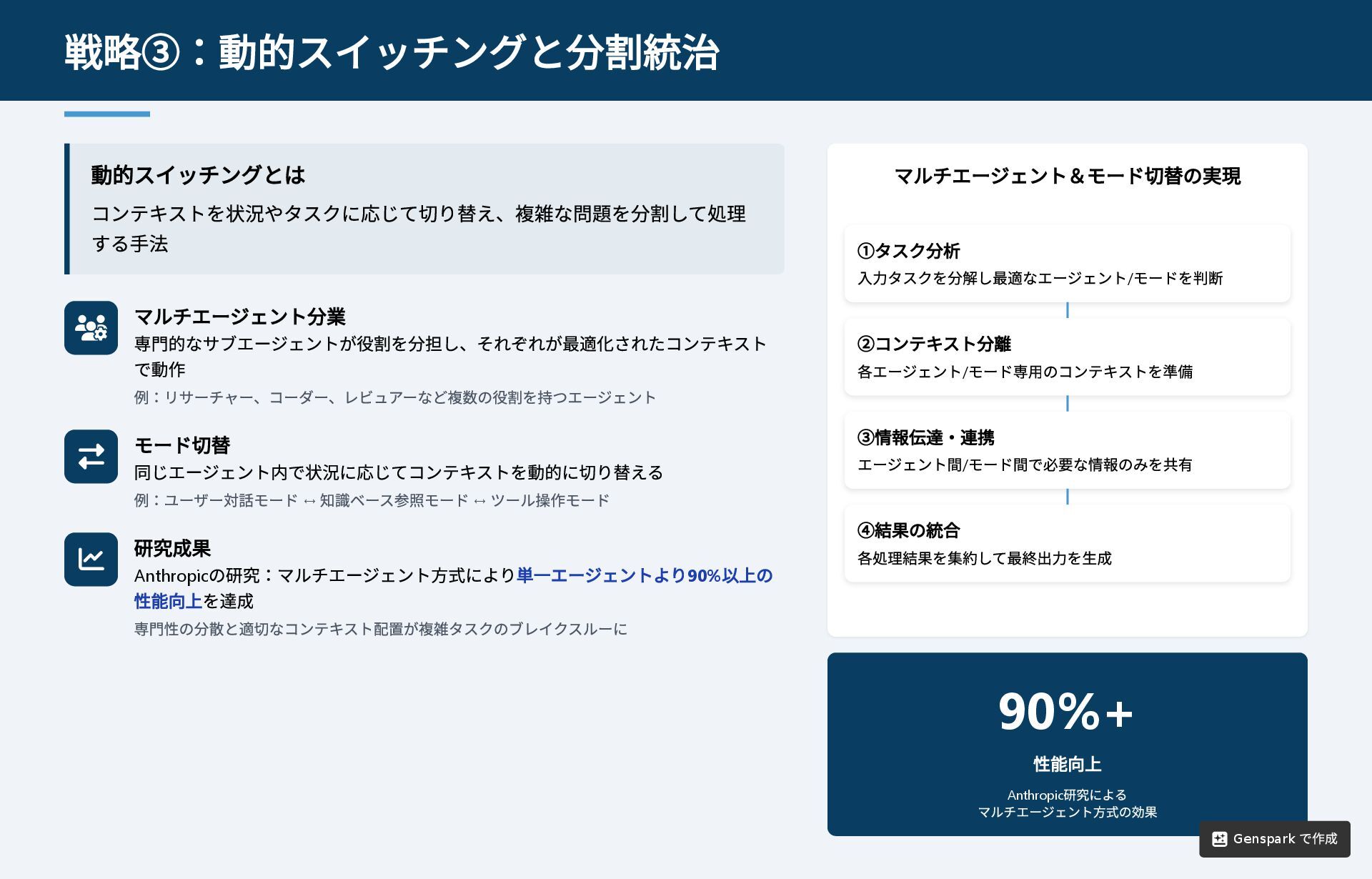
動的スイッチングとは コンテキストを状況やタスクに応じて切り替え、複雑な問題を分割して処理 する手法 マルチエージェント分業 専門的なサブエージェントが役割を分担し、それぞれが最適化されたコンテキスト で動作 例:リサーチャー、コーダー、レビュアーなど複数の役割を持つエージェント モード切替
同じエージェント内で状況に応じてコンテキストを動的に切り替える 例:ユーザー対話モード ↔ 知識ベース参照モード ↔ ツール操作モード 研究成果 Anthropic の研究:マルチエージェント方式により単一エージェントより90% 以上の 性能向上を達成 専門性の分散と適切なコンテキスト配置が複雑タスクのブレイクスルーに マルチエージェント&モード切替の実現 90%+ 性能向上 Anthropic 研究による マルチエージェント方式の効果 戦略③:動的スイッチングと分割統治 ①タスク分析 入力タスクを分解し最適なエージェント/ モードを判断 ②コンテキスト分離 各エージェント/ モード専用のコンテキストを準備 ③情報伝達・連携 エージェント間/ モード間で必要な情報のみを共有 ④結果の統合 各処理結果を集約して最終出力を生成 Genspark で作成
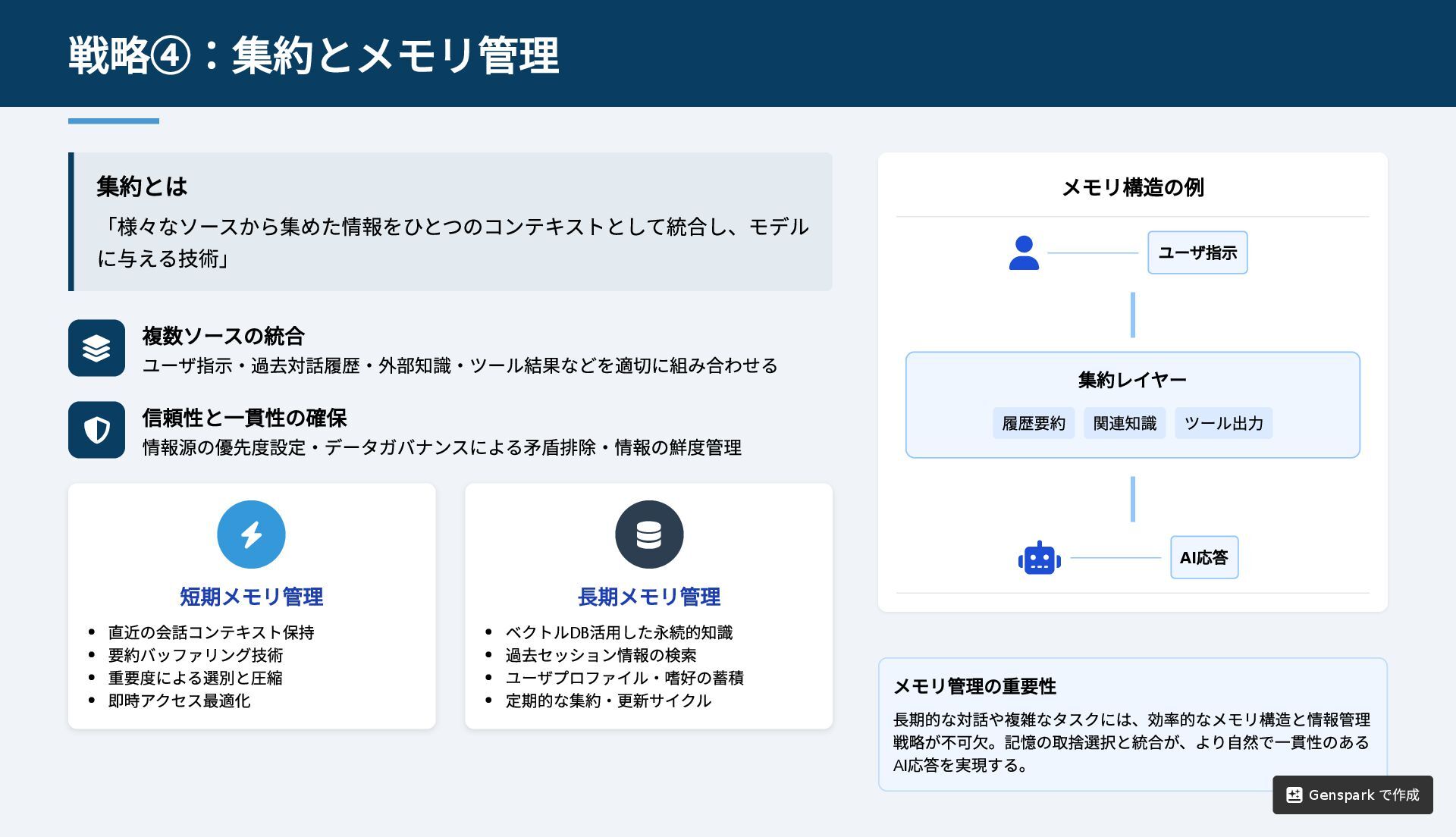
集約とは 「様々なソースから集めた情報をひとつのコンテキストとして統合し、モデル に与える技術」 複数ソースの統合 ユーザ指示・過去対話履歴・外部知識・ツール結果などを適切に組み合わせる 信頼性と一貫性の確保 情報源の優先度設定・データガバナンスによる矛盾排除・情報の鮮度管理
短期メモリ管理 直近の会話コンテキスト保持 要約バッファリング技術 重要度による選別と圧縮 即時アクセス最適化 長期メモリ管理 ベクトルDB 活用した永続的知識 過去セッション情報の検索 ユーザプロファイル・嗜好の蓄積 定期的な集約・更新サイクル メモリ構造の例 ユーザ指示 集約レイヤー 履歴要約 関連知識 ツール出力 AI 応答 メモリ管理の重要性 長期的な対話や複雑なタスクには、効率的なメモリ構造と情報管理 戦略が不可欠。記憶の取捨選択と統合が、より自然で一貫性のある AI 応答を実現する。 戦略④:集約とメモリ管理 Genspark で作成
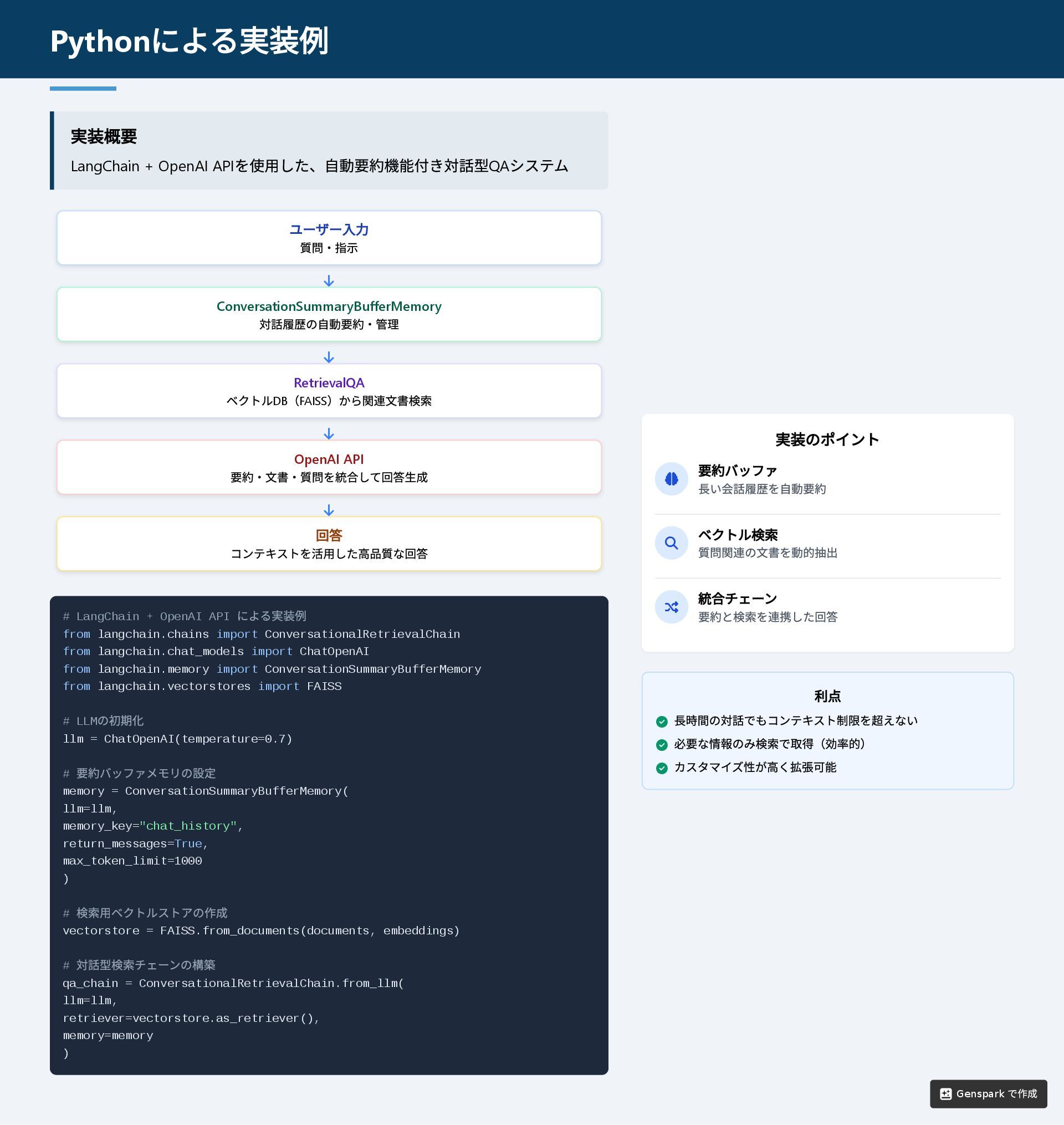
実装概要 LangChain + OpenAI API を使用した、自動要約機能付き対話型QA システム # LangChain +
OpenAI API による実装例 from langchain.chains import ConversationalRetrievalChain from langchain.chat_models import ChatOpenAI from langchain.memory import ConversationSummaryBufferMemory from langchain.vectorstores import FAISS # LLM の初期化 llm = ChatOpenAI(temperature=0.7) # 要約バッファメモリの設定 memory = ConversationSummaryBufferMemory( llm=llm, memory_key="chat_history", return_messages=True, max_token_limit=1000 ) # 検索用ベクトルストアの作成 vectorstore = FAISS.from_documents(documents, embeddings) # 対話型検索チェーンの構築 qa_chain = ConversationalRetrievalChain.from_llm( llm=llm, retriever=vectorstore.as_retriever(), memory=memory ) 実装のポイント 要約バッファ 長い会話履歴を自動要約 ベクトル検索 質問関連の文書を動的抽出 統合チェーン 要約と検索を連携した回答 利点 長時間の対話でもコンテキスト制限を超えない 必要な情報のみ検索で取得(効率的) カスタマイズ性が高く拡張可能 Python による実装例 ユーザー入力 質問・指示 ConversationSummaryBufferMemory 対話履歴の自動要約・管理 RetrievalQA ベクトルDB (FAISS )から関連文書検索 OpenAI API 要約・文書・質問を統合して回答生成 回答 コンテキストを活用した高品質な回答 Genspark で作成
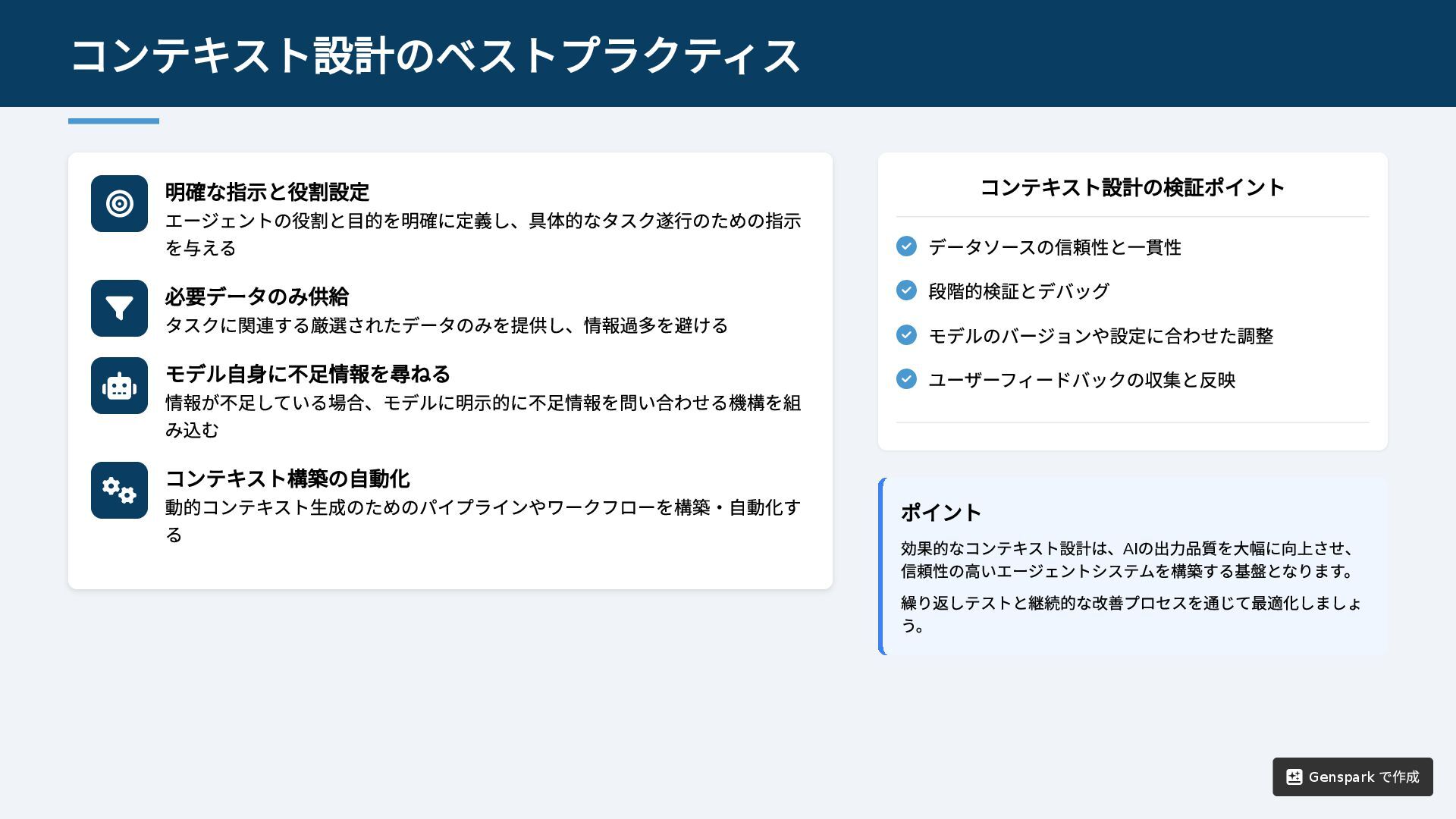
明確な指示と役割設定 エージェントの役割と目的を明確に定義し、具体的なタスク遂行のための指示 を与える 必要データのみ供給 タスクに関連する厳選されたデータのみを提供し、情報過多を避ける モデル自身に不足情報を尋ねる 情報が不足している場合、モデルに明示的に不足情報を問い合わせる機構を組
み込む コンテキスト構築の自動化 動的コンテキスト生成のためのパイプラインやワークフローを構築・自動化す る コンテキスト設計の検証ポイント データソースの信頼性と一貫性 段階的検証とデバッグ モデルのバージョンや設定に合わせた調整 ユーザーフィードバックの収集と反映 ポイント 効果的なコンテキスト設計は、AI の出力品質を大幅に向上させ、 信頼性の高いエージェントシステムを構築する基盤となります。 繰り返しテストと継続的な改善プロセスを通じて最適化しましょ う。 コンテキスト設計のベストプラクティス Genspark で作成
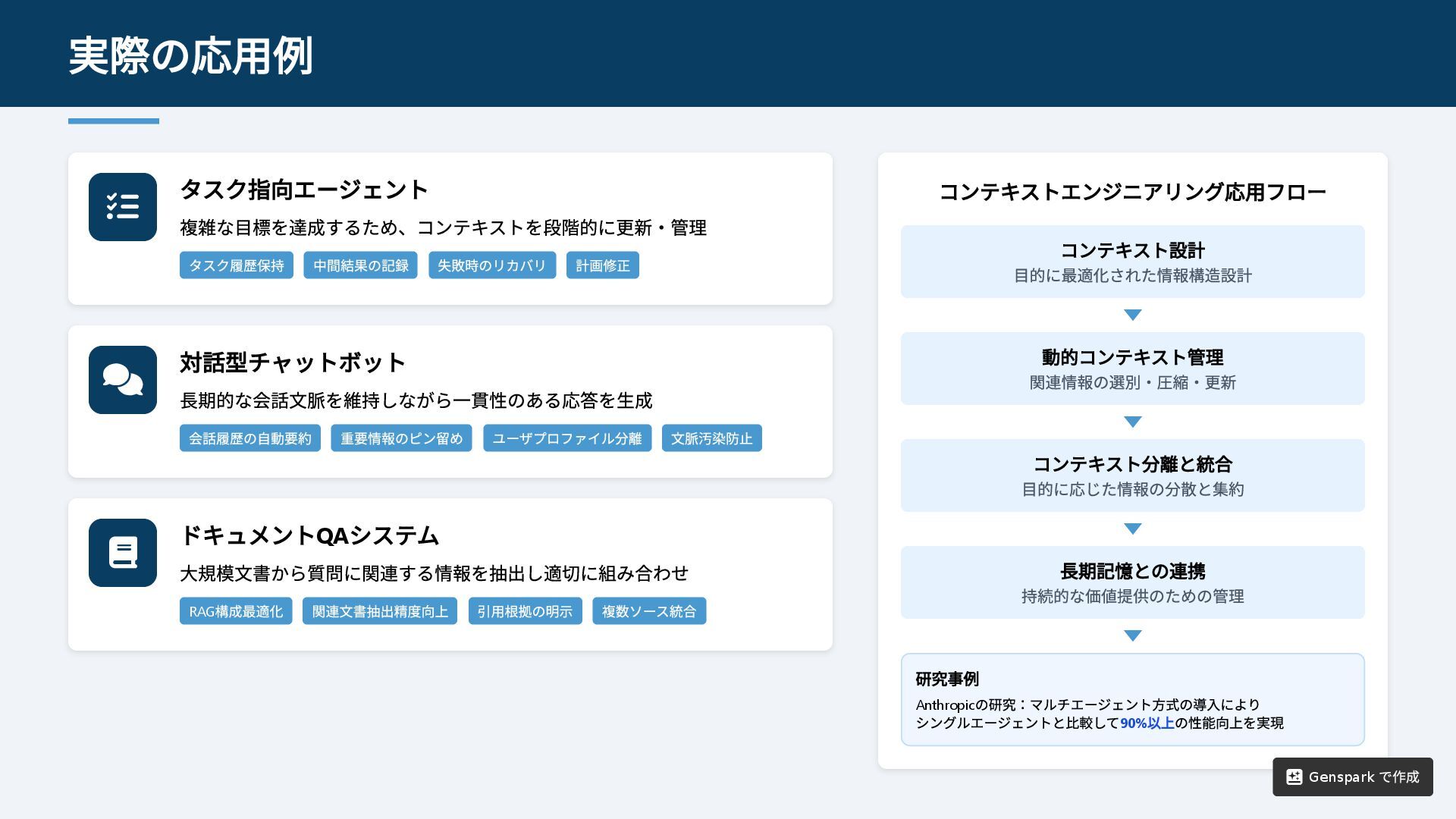
タスク指向エージェント 複雑な目標を達成するため、コンテキストを段階的に更新・管理 タスク履歴保持 中間結果の記録 失敗時のリカバリ 計画修正 対話型チャットボット 長期的な会話文脈を維持しながら一貫性のある応答を生成
会話履歴の自動要約 重要情報のピン留め ユーザプロファイル分離 文脈汚染防止 ドキュメントQA システム 大規模文書から質問に関連する情報を抽出し適切に組み合わせ RAG 構成最適化 関連文書抽出精度向上 引用根拠の明示 複数ソース統合 コンテキストエンジニアリング応用フロー 研究事例 Anthropic の研究:マルチエージェント方式の導入により シングルエージェントと比較して90% 以上の性能向上を実現 実際の応用例 コンテキスト設計 目的に最適化された情報構造設計 動的コンテキスト管理 関連情報の選別・圧縮・更新 コンテキスト分離と統合 目的に応じた情報の分散と集約 長期記憶との連携 持続的な価値提供のための管理 Genspark で作成
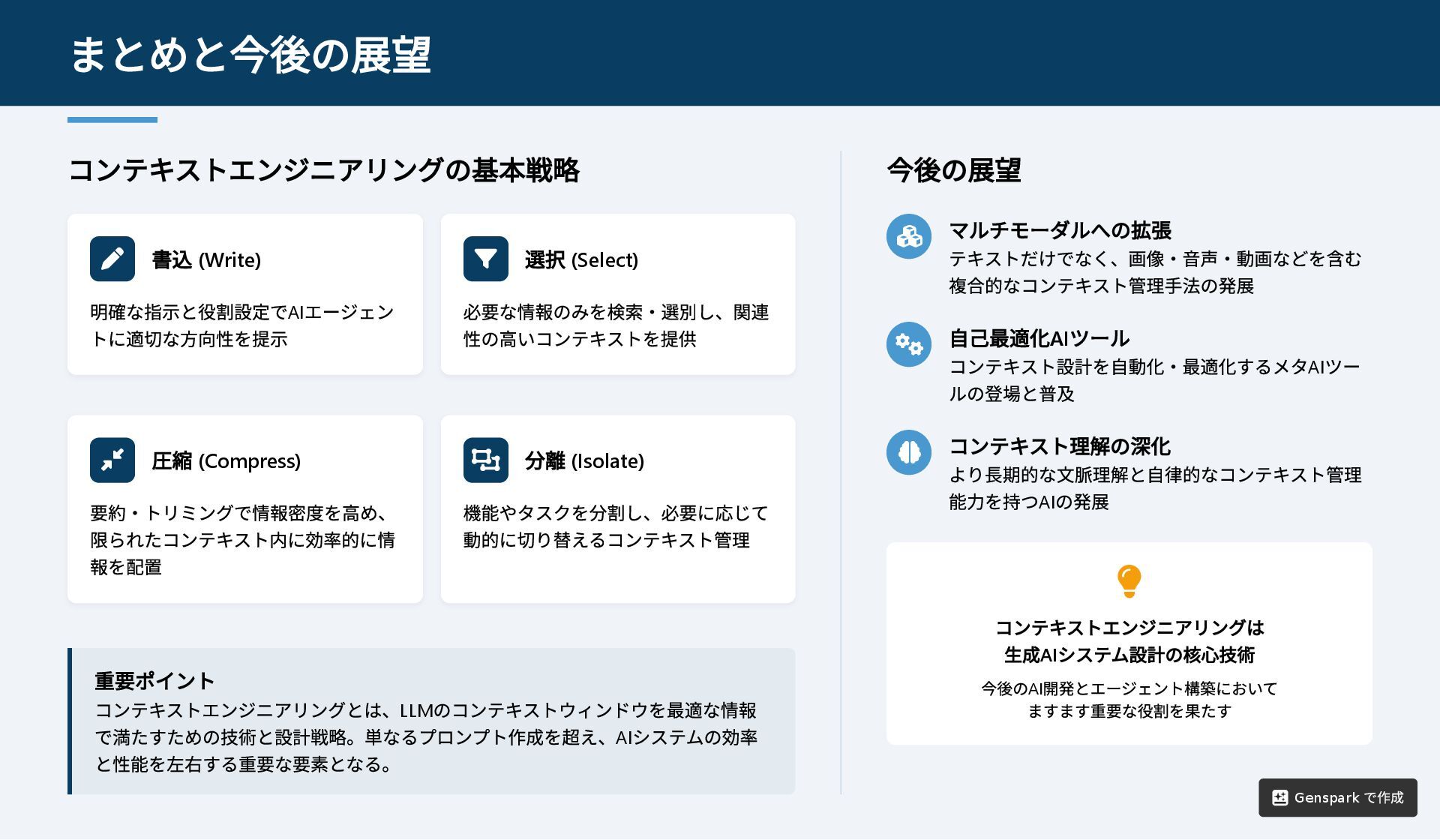
コンテキストエンジニアリングの基本戦略 書込 (Write) 明確な指示と役割設定でAI エージェン トに適切な方向性を提示 選択 (Select)
必要な情報のみを検索・選別し、関連 性の高いコンテキストを提供 圧縮 (Compress) 要約・トリミングで情報密度を高め、 限られたコンテキスト内に効率的に情 報を配置 分離 (Isolate) 機能やタスクを分割し、必要に応じて 動的に切り替えるコンテキスト管理 重要ポイント コンテキストエンジニアリングとは、LLM のコンテキストウィンドウを最適な情報 で満たすための技術と設計戦略。単なるプロンプト作成を超え、AI システムの効率 と性能を左右する重要な要素となる。 今後の展望 マルチモーダルへの拡張 テキストだけでなく、画像・音声・動画などを含む 複合的なコンテキスト管理手法の発展 自己最適化AI ツール コンテキスト設計を自動化・最適化するメタAI ツー ルの登場と普及 コンテキスト理解の深化 より長期的な文脈理解と自律的なコンテキスト管理 能力を持つAI の発展 コンテキストエンジニアリングは 生成AI システム設計の核心技術 今後のAI 開発とエージェント構築において ますます重要な役割を果たす まとめと今後の展望 Genspark で作成
ご質問をお待ちしております コンテキストエンジニアリングに関する質問がありましたら、お気軽にどうぞ。 Q よくある質問の例: コンテキスト圧縮と選別の使い分けはどうすればよいですか? Q よくある質問の例: 特定の業界でのコンテキストエンジニアリング適用事例はありますか? ディスカッションを通じて理解を深めましょう どんな小さな疑問でも歓迎します
フォローアップ セッション後の質問も受付中 メールでのお問い合わせ
[email protected]
ウェブサイト www.context-engineering.example.com 追加資料 今日の資料は後日共有いたします 質疑応答 Genspark で作成
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}