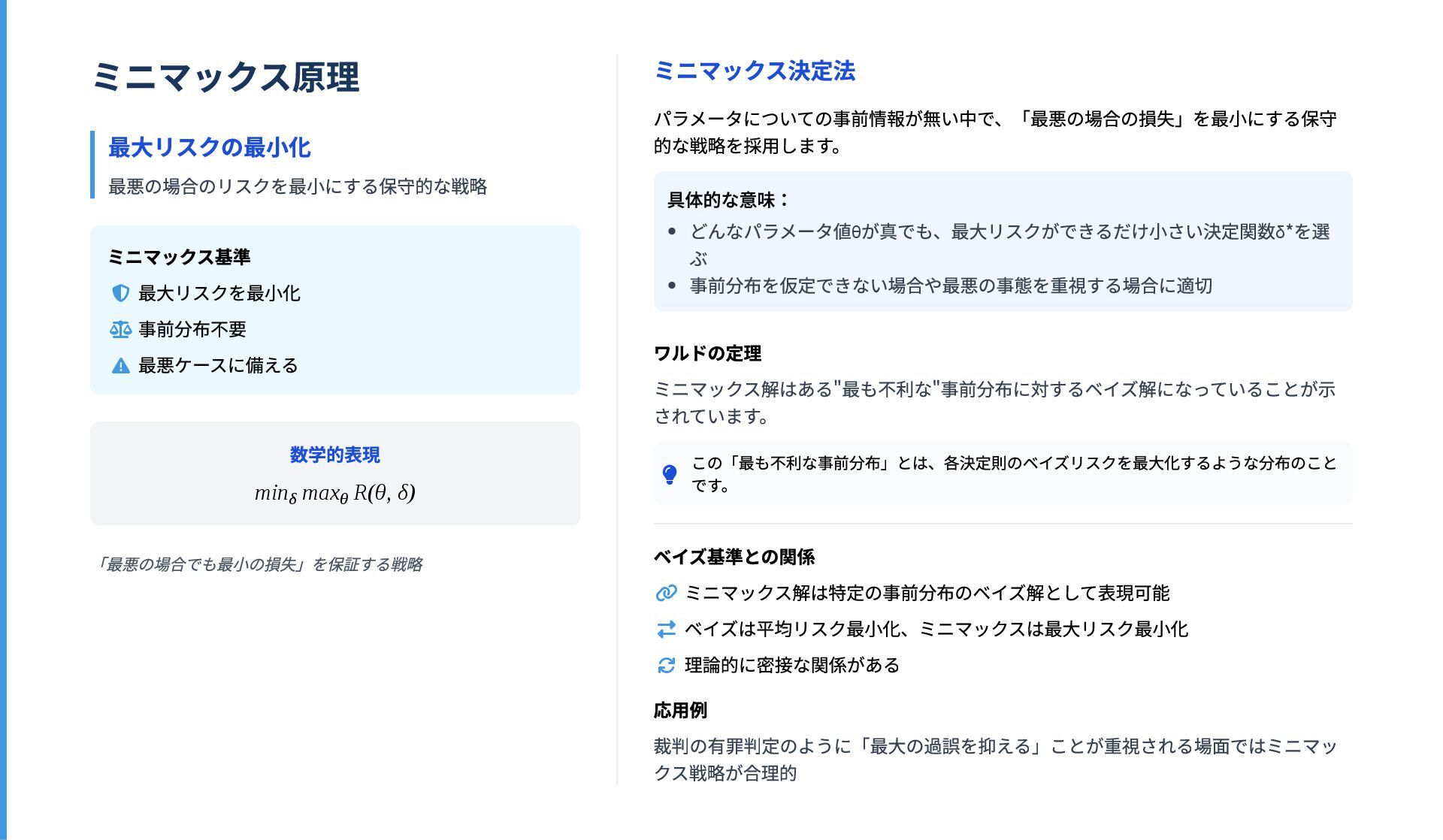
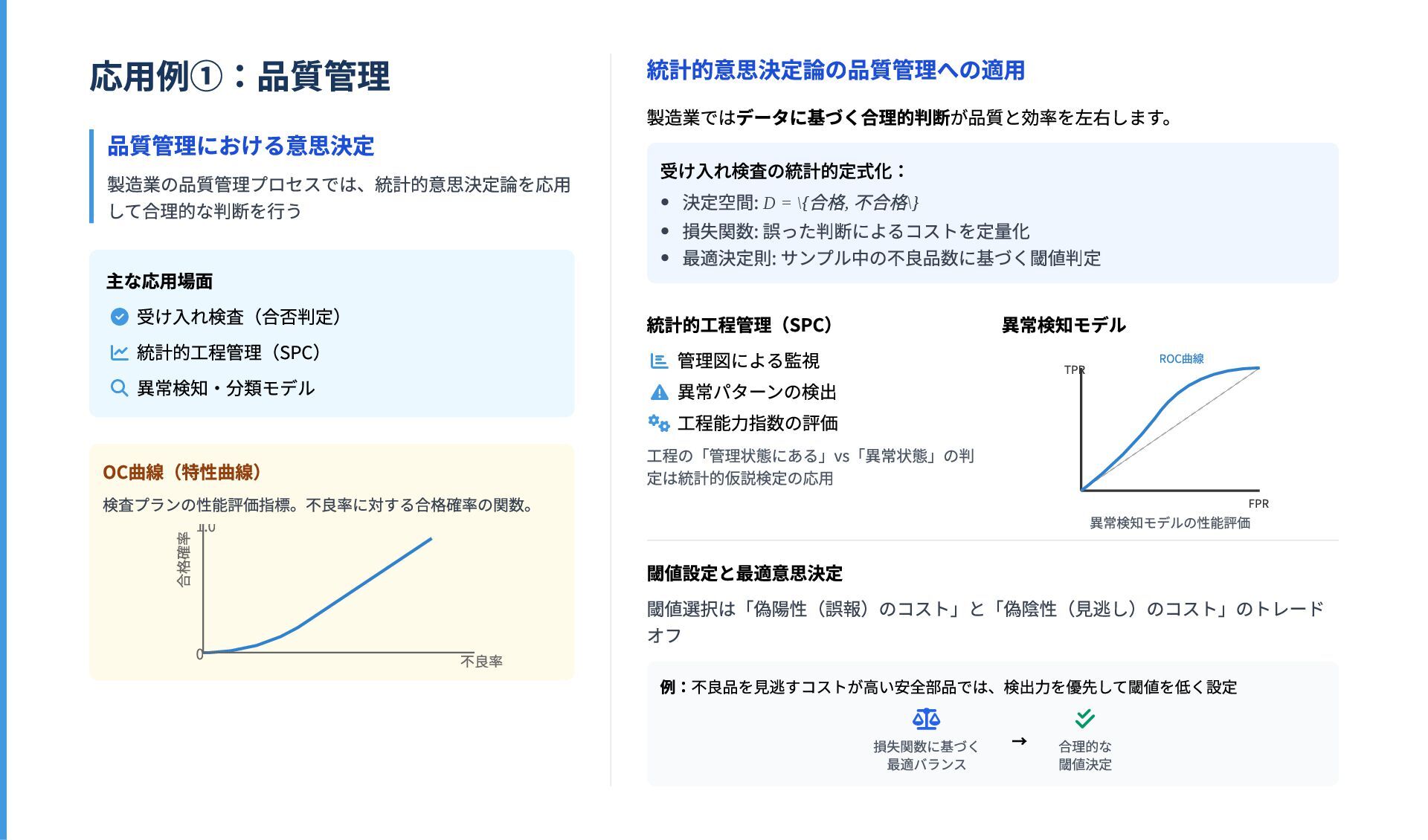
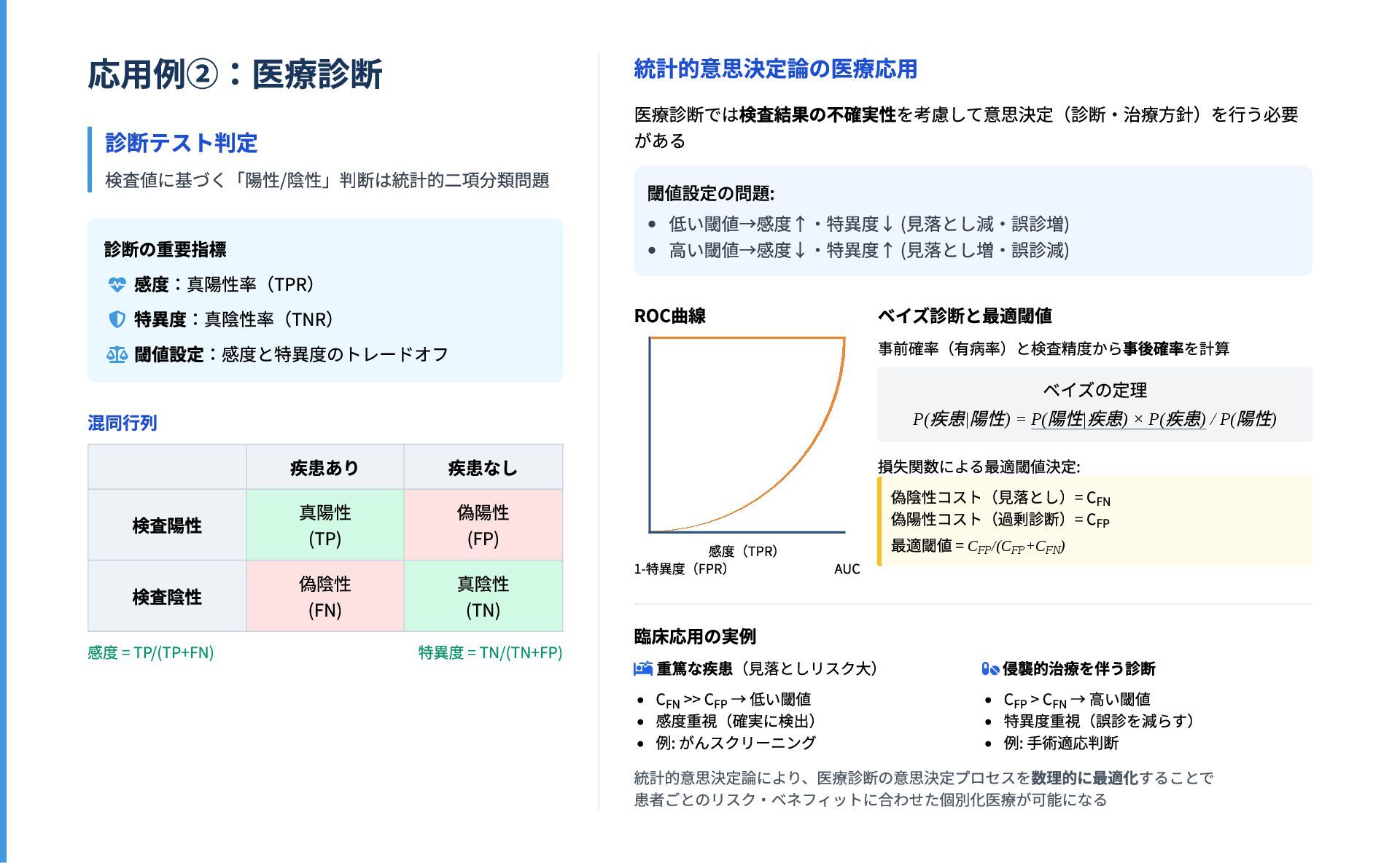
の集合 決定関数 :観測から行動への写像 決定関数の役割 データ 行動 「観測 を得たときに選択する行動 」を与えるルール 決定関数の一般形: 統計的意思決定の具体例 点推定問題 標本空間: データ の空間 決定空間: (パラメータ空間) 決定関数: 推定量 例:標本 から母平均 を推 定する問題では、 という決定関数を 採用 仮説検定問題 標本空間: データ の空間 決定空間: 決定関数: 検定関数 例: 検定では、検定統計量 が臨界値を超え たら帰無仮説を棄却するというルールを採用 統一的な視点 あらゆる統計的推測は「データを基に行動を選択する」という視点で捉えられる 推定問題 検定問題 分類問題 経済的意思決定 X x D d δ : X → D x d = δ(x) x d δ : X → D x D = Θ (x) θ ^ x = (x , ..., x ) 1 n μ (x) = μ ^ x ˉ x D = { 採択, 棄却} ϕ(x) t t
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
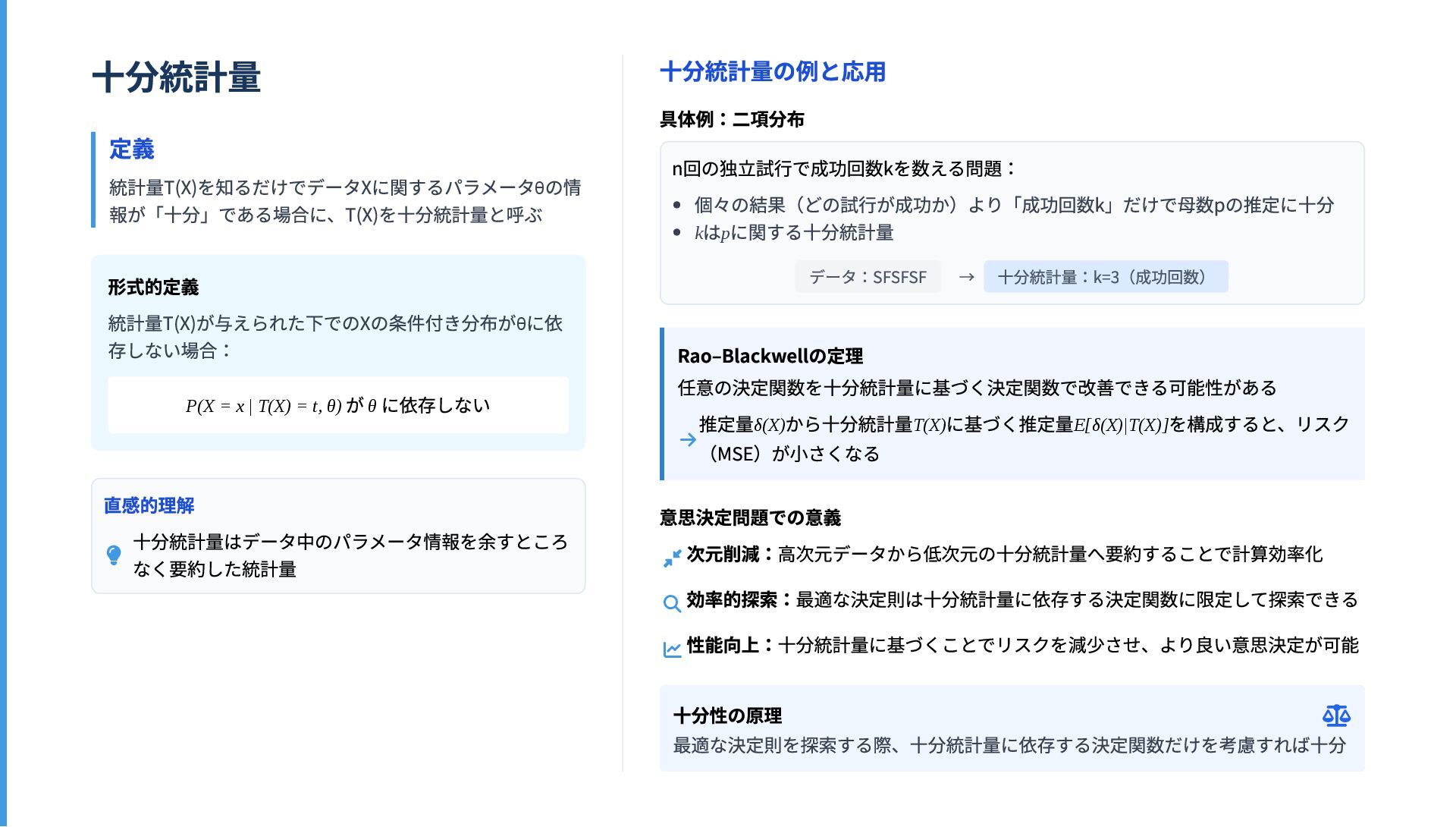
![不偏推定量とその性質 不偏推定量の定義 推定量の期待値が真のパラメータに一致する性質を持つ推 定量 E [θ̂(X)] = θ 具体例 ](https://files.speakerdeck.com/presentations/8029637d52c847f6abb240b801314b9d/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}