years as a software engineer • 3+ years as a data engineer (big data) • Lead Data Engineer, Traveloka • Lead, FB DevC Malang • Big Data and JavaScript lover • Father of 3+ years old son • Gamer ◦ Steam Account: hellowin_cavemen ◦ Battle Tag: Hellowin#11826
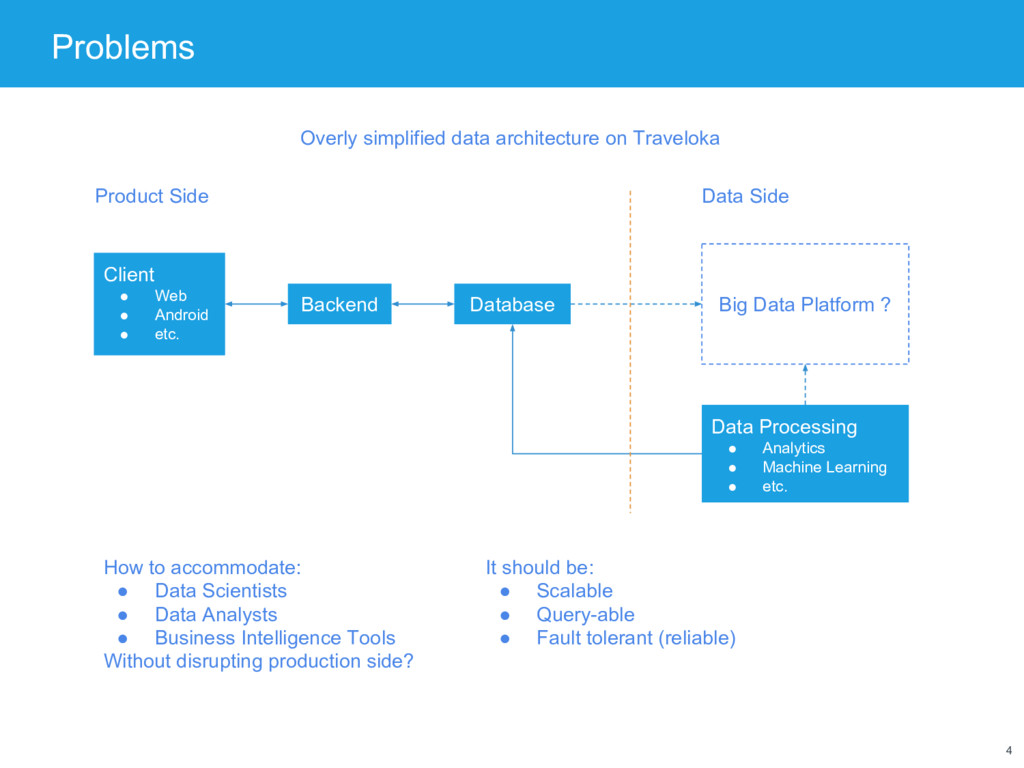
Database Big Data Platform ? Data Processing • Analytics • Machine Learning • etc. Overly simplified data architecture on Traveloka Product Side Data Side How to accommodate: • Data Scientists • Data Analysts • Business Intelligence Tools Without disrupting production side? It should be: • Scalable • Query-able • Fault tolerant (reliable)
holds a vast amount of raw data in its native format until it is needed. - http://searchaws.techtarget.com • A data lake is a storage repository that holds a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is needed. - Tamara Dull, (SAS), https://www.kdnuggets.com • It store the data in its native/ raw format • The schema applied when on query time • Sometimes it’s also just a “marketing label” to simplified people saying the technology which complied with Hadoop, just like “big data” terms for distributed storing and query engine Data Lake by Definitions
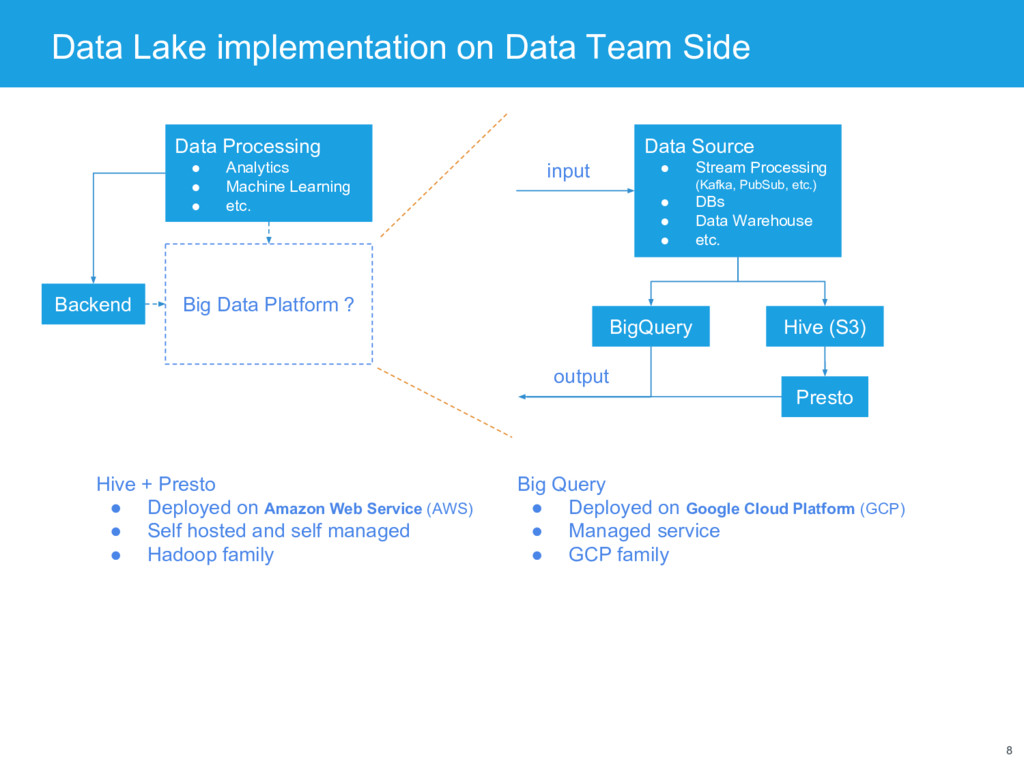
Platform ? Data Processing • Analytics • Machine Learning • etc. Backend Data Source • Stream Processing (Kafka, PubSub, etc.) • DBs • Data Warehouse • etc. Hive (S3) Presto BigQuery input output Hive + Presto • Deployed on Amazon Web Service (AWS) • Self hosted and self managed • Hadoop family Big Query • Deployed on Google Cloud Platform (GCP) • Managed service • GCP family
(self managed) ◦ Able to define nodes, replication factor, cluster, etc. ◦ Able to specify node specs. • Good integration with other Hadoop ecosystem ◦ Spark ◦ Kafka ◦ Impala • More mature • Open sourced Hive + Presto Pros and Cons Cons • Harder to maintain (also because of self managed)
Good integration with other GCP managed tools ◦ Dataflow ◦ PubSub ◦ Cloud Storage • Enterprise ready, support is 24/7 Big Query Cons • Less mature compared to Hadoop ecosystem • Limited API yet (not supported Scala API) • Unable to store data on S3, need to be on Cloud Storage • Close sourced
by side • Maintainability is one thing, but in industry its value is everything • Big Data stack is moving so fast • It’s Data Engineer’s responsibility to make the migration agile • There’s no “one thing fits all” solution Conclusions
• How to Improve Data Warehouse Efficiency using S3 over HDFS on Hive (https://blog.andi.dirgantara.co/how-to-improve-data-warehouse-efficiency-using-s3-over-hdfs-on-hive-e9da90ea378c) References and Other Presentations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}