• Last 4 years focused at data engineering (big data) • Lead Data Engineer at Traveloka • Lead Facebook Developer Circles Malang • Working remotely from Malang • Urban and Regional Planning Graduate • Owner The Bros Coffee and Coworking Space (@thebros_co) • Owner Cahayu Aesthetic and Slimming Center (@cahayu.clinic)
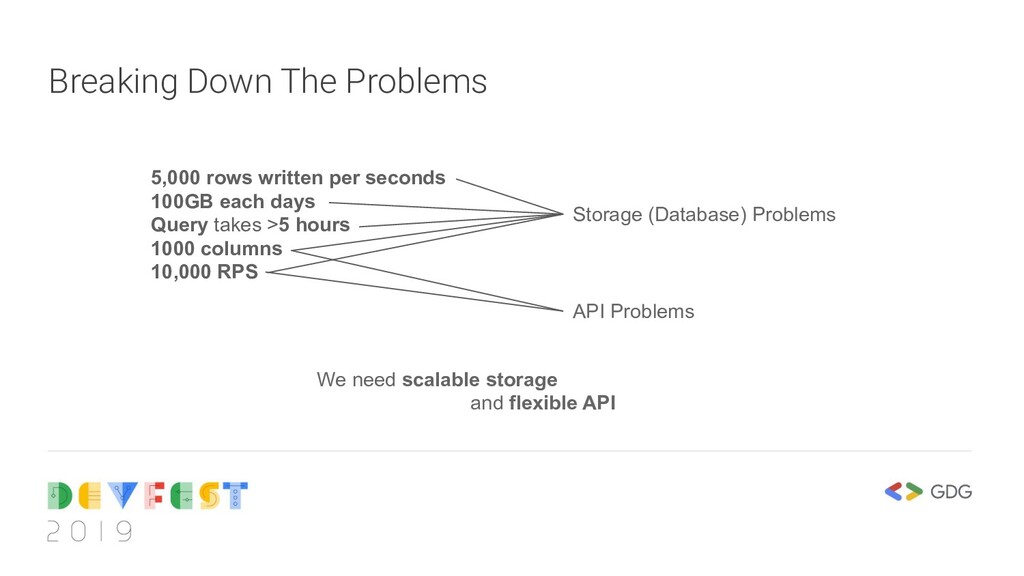
API Everything went well until… We faced 5,000 rows written per seconds (1.8 millions rows per hour) Storage consume more than 100GB each day Single query can takes more than 5 hours Single row can have up to 1000 columns The system hit by 10,000 RPS What should we do?
storage • Eventually consistent to leverage high throughput and high availability through replication (it can be set to strong consistency too if we want) • Columnar storage which able to store millions of columns More informations go to https://cloud.google.com/bigtable/ Machine 1 Data 1 Write Read Machine 2 Data 2 Machine n Data n
each product have at least 10 columns some products have 50 columns how much REST endpoint should we provide? who will maintain each endpoints? what if some system need to consume more than 5 endpoints? We need queryable API...
graph • Just query what you need • Has dashboard playground • Reduces network requests to 1 for multiple “endpoints” requests More informations visit https://graphql.org/
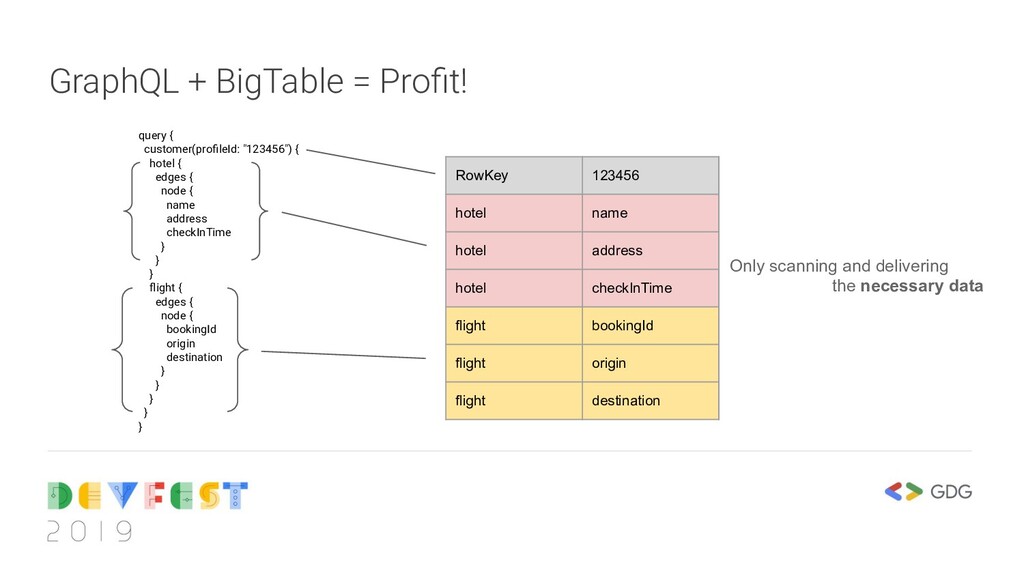
hotel { edges { node { name address checkInTime } } } flight { edges { node { bookingId origin destination } } } } } RowKey 123456 hotel name hotel address hotel checkInTime flight bookingId flight origin flight destination Only scanning and delivering the necessary data
Optimizing/ leveraging optional data storage for more complex use cases (CockroachDB, Spanner, CitusDB, etc.) • Access control system per column • … suggestion? ... Tradeoff • The learning curve is steep • Hard to find talent which experienced in our tech. stack (GoLang, GraphQL, BigTable, etc.) • BigTable cluster is relatively expensive, so proper data modelling is necessary to avoid wasting resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}