years as a software engineer • 3+ years as a data engineer (big data) • Lead Data Engineer, Traveloka • Working remotely from Malang • Lead, FB DevC Malang • Big Data and JavaScript lover • Father of 3+ years old son • Gamer ◦ Steam Account: hellowin_cavemen ◦ Battle Tag: Hellowin#11826
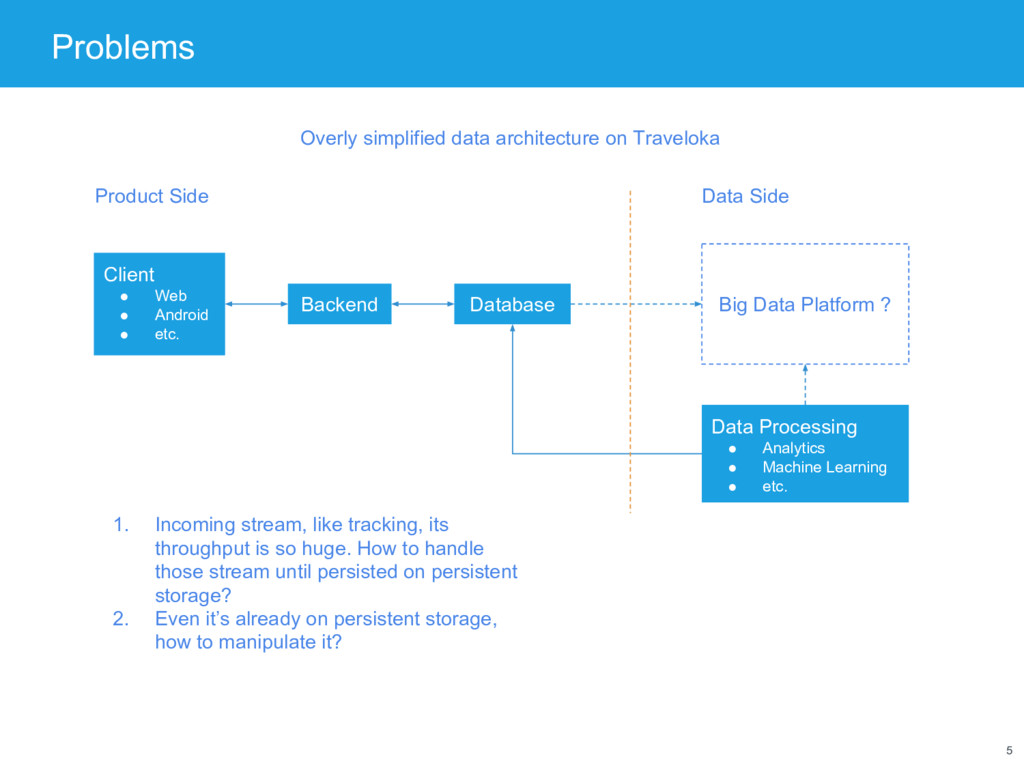
Database Big Data Platform ? Data Processing • Analytics • Machine Learning • etc. Overly simplified data architecture on Traveloka Product Side Data Side 1. Incoming stream, like tracking, its throughput is so huge. How to handle those stream until persisted on persistent storage? 2. Even it’s already on persistent storage, how to manipulate it?
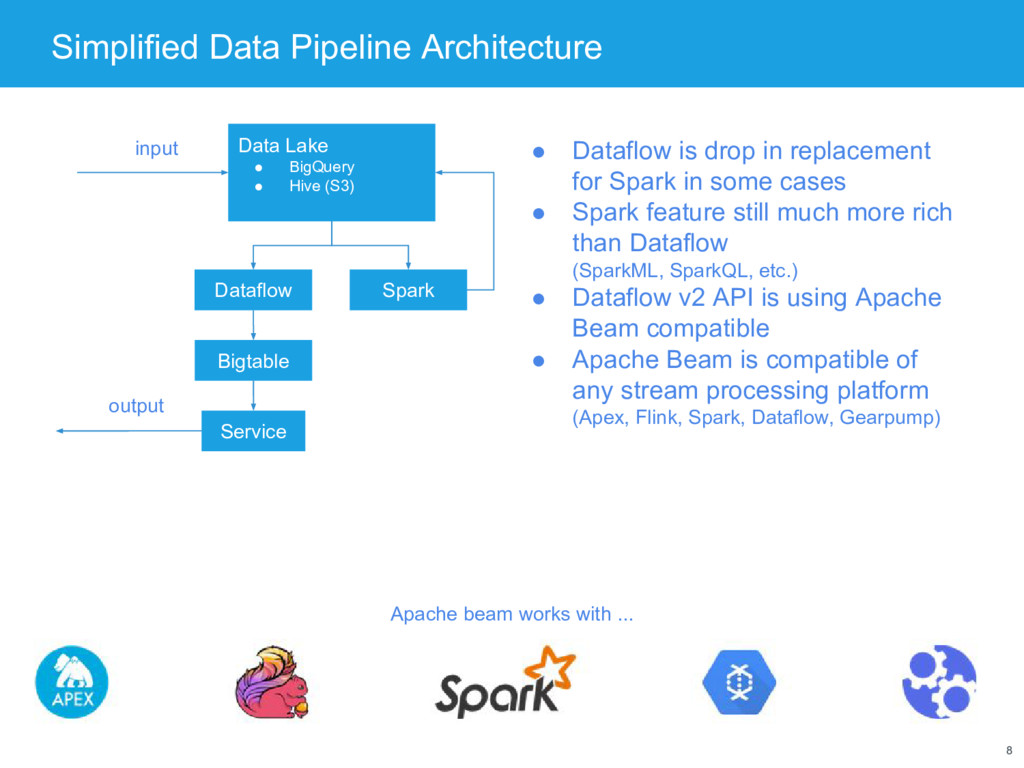
Hive (S3) Bigtable Service Dataflow input output Spark • Dataflow is drop in replacement for Spark in some cases • Spark feature still much more rich than Dataflow (SparkML, SparkQL, etc.) • Dataflow v2 API is using Apache Beam compatible • Apache Beam is compatible of any stream processing platform (Apex, Flink, Spark, Dataflow, Gearpump) Apache beam works with ...
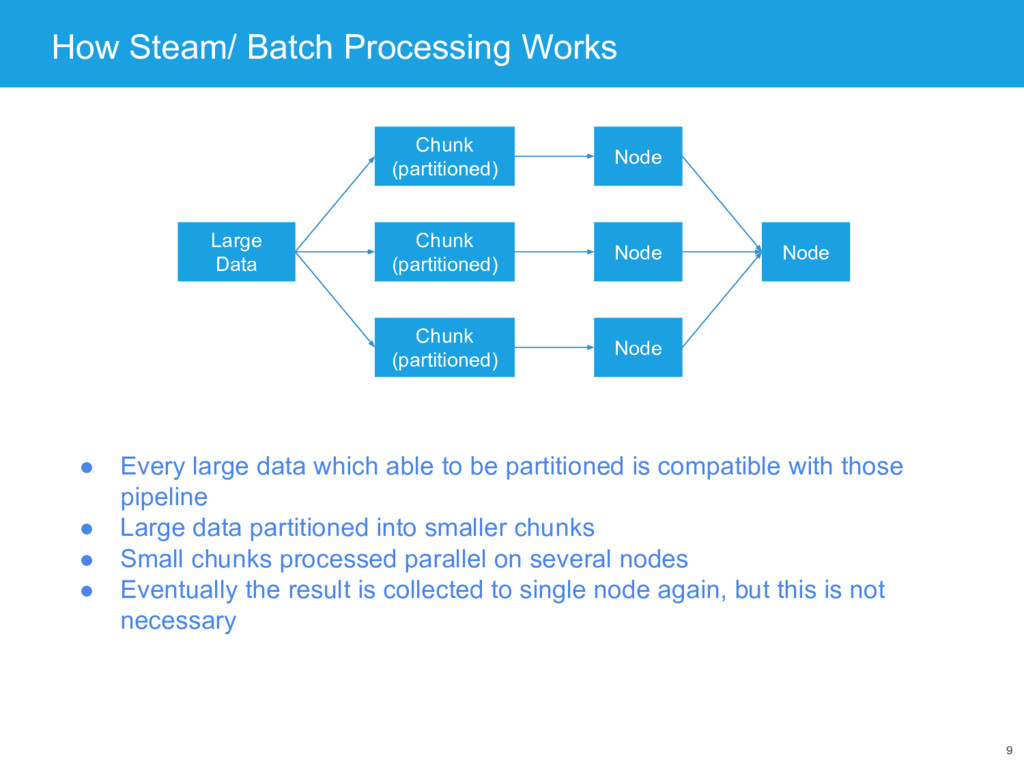
Chunk (partitioned) Chunk (partitioned) Node Node Node Node • Every large data which able to be partitioned is compatible with those pipeline • Large data partitioned into smaller chunks • Small chunks processed parallel on several nodes • Eventually the result is collected to single node again, but this is not necessary
can be used as Data Lake as well • It’s columnar NoSQL • Support high throughput • Row-key as a primary key and also atomic • It’s “get” API claimed as O(1) complexity • More details can be read on its paper https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf • Service consume data from Bigtable instead of Data Lake Persistent Storage for Large Pre-computed Data is Needed Bigtable Service Dataflow
Good integration with other GCP managed tools ◦ BigQuery ◦ PubSub ◦ Cloud Storage • Enterprise ready, support is 24/7 Dataflow Pros Cons Cons • Less mature compared to Hadoop ecosystem • Limited API yet (not supported Scala API) • Have no ML API as SparkML • Have no Query API as SparkQL • Close sourced
of total data pipeline being use in Traveloka • Data Pipeline technology is very dynamic, current pipeline might be obsolete next year, and migration is needed • We still using Databricks, Kafka, PubSub, in some services More Data Pipeline Still In Use
forget to put proper monitoring effort • Data pipeline technology stack is evolving so fast, it’s Data Engineer responsibility to adapt with every changes • There’s no silver bullet or one solution fits all technology Conclusions
• How to Improve Data Warehouse Efficiency using S3 over HDFS on Hive (https://blog.andi.dirgantara.co/how-to-improve-data-warehouse-efficiency-using-s3-over-hdfs-on-hive-e9da90ea378c) References and Other Presentations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}