Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Improving Language Understanding by Generative ...
Search
himura467
August 16, 2024
Research
0
76
Improving Language Understanding by Generative Pre-Training
ChatGPT の中身について研究室内で勉強会をした際に発表した資料です!
himura467
August 16, 2024
Tweet
Share
More Decks by himura467
See All by himura467
基盤モデルのアーキテクチャを改造してみよう - 時系列基盤モデルのマルチモーダル拡張事例の紹介 -
himura
1
170
Python アプリケーションの裏側とその機序 -WSGI, ASGI 編-
himura
0
70
人生における期待効用の最大化について考える
himura
0
96
CA_kube-scheduler
himura
0
10
Other Decks in Research
See All in Research
病院向け生成AIプロダクト開発の実践と課題
hagino3000
0
220
言語モデルの地図:確率分布と 情報幾何による類似性の可視化
shimosan
8
2.1k
EOGS: Gaussian Splatting for Efficient Satellite Image Photogrammetry
satai
4
770
カスタマーサクセスの視点からAWS Summitの展示を考える~製品開発で活用できる勘所~
masakiokuda
2
220
「どう育てるか」より「どう働きたいか」〜スクラムマスターの最初の一歩〜
hirakawa51
0
1k
AIスパコン「さくらONE」の オブザーバビリティ / Observability for AI Supercomputer SAKURAONE
yuukit
2
730
EcoWikiRS: Learning Ecological Representation of Satellite Images from Weak Supervision with Species Observation and Wikipedia
satai
3
330
とあるSREの博士「過程」 / A Certain SRE’s Ph.D. Journey
yuukit
11
4.8k
なめらかなシステムと運用維持の終わらぬ未来 / dicomo2025_coherently_fittable_system
monochromegane
0
4.7k
IMC の細かすぎる話 2025
smly
2
730
学習型データ構造:機械学習を内包する新しいデータ構造の設計と解析
matsui_528
3
1k
国際論文を出そう!ICRA / IROS / RA-L への論文投稿の心構えとノウハウ / RSJ2025 Luncheon Seminar
koide3
10
5.9k
Featured
See All Featured
Bootstrapping a Software Product
garrettdimon
PRO
307
110k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
How to train your dragon (web standard)
notwaldorf
97
6.4k
Balancing Empowerment & Direction
lara
5
740
How to Ace a Technical Interview
jacobian
280
24k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
140
34k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
8k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Making Projects Easy
brettharned
120
6.4k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
658
61k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
11
920
Transcript
Improving Language Understanding by Generative Pre-Training Alec Radford, Karthik Narasimhan,
Tim Salimans, Ilya Sutskever 設楽朗人 1/10
従来のAIによる自然言語理解と課題 自然言語理解(NLP) ・様々なタスクに対応する必要がある - Textual Retailing - Question Answering -
Semantic Similarity Assessment - Document Classification ・大量の Labeled な Dataset が必要 これは手作業であり、しんどい ・学習モデルを調整するために、最適化されていない heuristic な” 秘伝のタレ”が必要 2/10
自然言語理解AIに求められている要素 ・様々なタスクに汎用的に通用する ・学習のためのラベリングの負担が少ない 従来の手作業でのラベリングのコストを削減 ・学習モデルの細かい調整というタスクが必要ない 学習モデルのパラメータ調整の大部分を 人間がやる必要がないように 3/10
本稿の手法による自然言語理解 本稿の目標: 様々なタスクに汎用的に通用するモデル作成 提案する手法: Unlabeled なコーパスと手作業でターゲットタスクに特化させた学習 例のみを学習対象とする。 これらは同じ領域(Domain)の文章である必要はない。 学習の手順: 1.
Unlabeled Data に対して言語モデリングを行い初期パラメータを 決定 2. 学習例を用いてターゲットタスクに適合させる 4/10
事前学習 Train フェーズ: Unlabeled な Corpus を Byte Pair Encoding(BPE)
という手法で tokenize し、以下で与えられる尤度を最大化する。 ※Θ は学習モデルのパラメータ, k は window size Predict フェーズ: 右の計算により 予測を出力 5/10
Transformer Transformer Block の処理 ・Multi-headed self-attention layer 予測すべきトークン以降のトー クンの情報を隠した状態でトー クンを予測できるよう学習
・Feed forward layer 実験時は活性化関数として GELU 関数を用いている ・最適化アルゴリズム 実験時は ADAM を使用している Ref: [1] 6/10 [1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need, 2017.
Supervised fine-tuning 7/10 タスクに合わせたファインチューニングを行いながら言語モデ ル自体の学習も並行して実行することで、汎化性能の向上と収 束の高速化を実現 ファインチューニングの目標としては上記の L3 を最大化すること ・L2
は各タスク毎のファインチューニングを行う尤度関数 ・L1 は事前学習における尤度関数 ・λ でそれらの割合を設定する
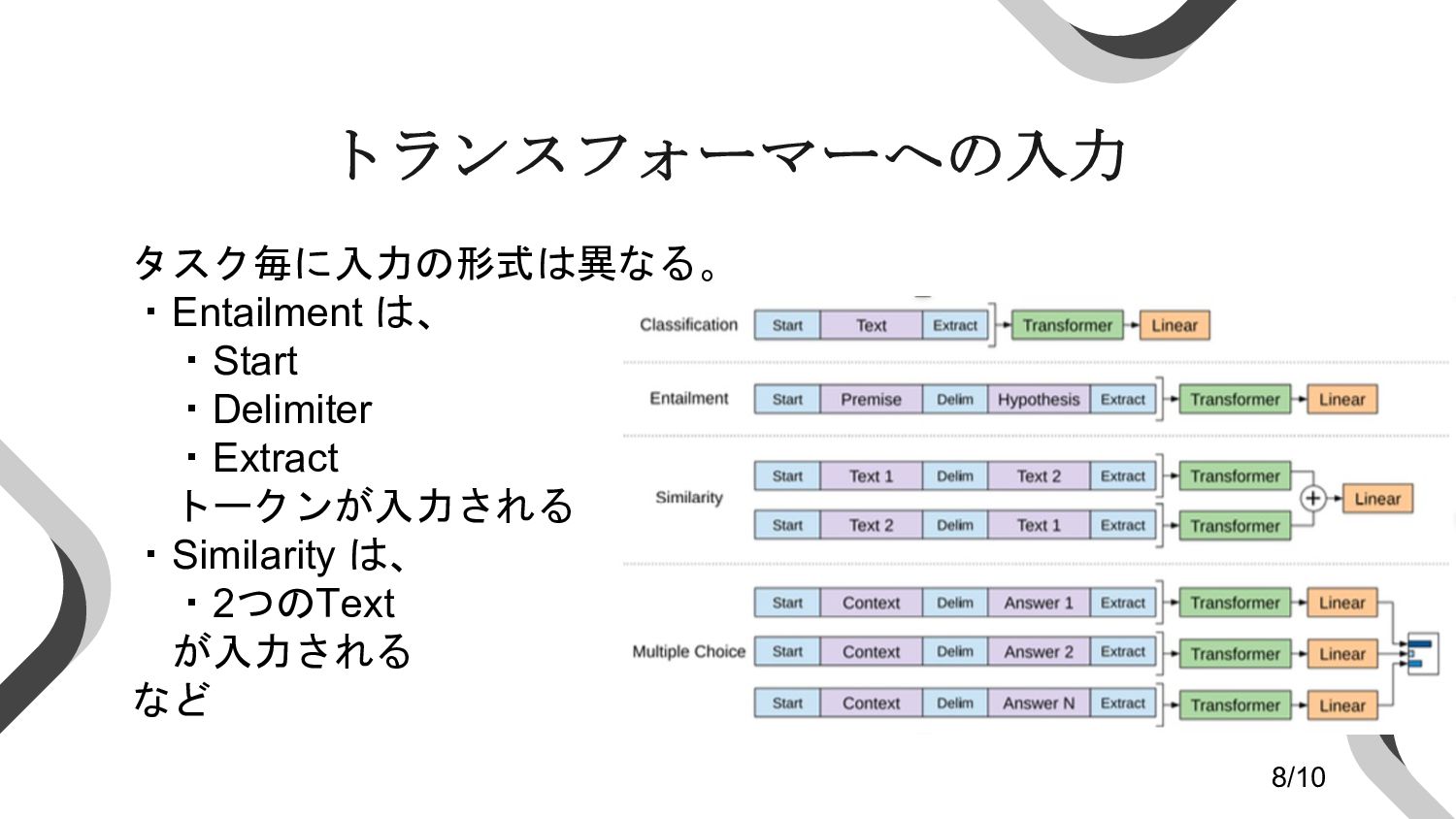
トランスフォーマーへの入力 タスク毎に入力の形式は異なる。 ・Entailment は、 ・Start ・Delimiter ・Extract トークンが入力される ・Similarity は、
・2つのText が入力される など 8/10
本稿の手法による成果 自然言語理解(NLP)のタスクとして挙げた - Textual Retailing - Question Answering - Semantic
Similarity Assessment - Document Classification を含む12タスクのうち、9タスクで従来の最高記録を更新した。 Zero-shot(未知の Domain に対する振る舞い)についても 有用な言語知識を有していることを実証した。 9/10
まとめ 10/10 ・AI の自然言語理解のための学習手法を提案 ・様々なタスクに汎用的に通用する ・学習のためのラベリングの負担が少ない ・学習モデルの細かい調整というタスクが必要ない - 事前学習 -
Transformer - Fine-Tuning - トランスフォーマーへの入力 ・本稿の手法の成果 ・各タスクに汎用的に高水準の結果 ・Zero-shot に対しても有用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}