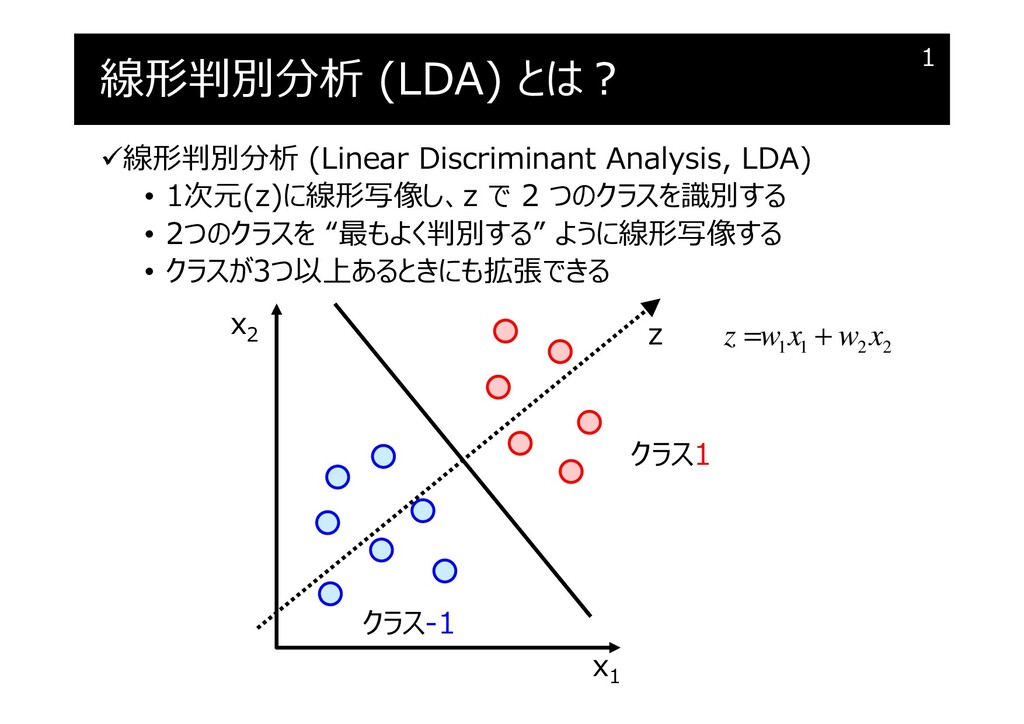
VWz z でのクラス間のばらつき VBz ( )2 Bz [1] [ 1] V z z − = − ( ) ( ) 2 2 ( ) ( ) Wz [1] [ 1] 1 i i i i V z z z z − ∈ ∈ = − + − クラス クラス-1 [ ] k z : クラス k のみの zの平均
1] [1] [ 1] B V − − = − − x x x x ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 2 [1] [ 1] 2 2 ( ) ( ) [1] [ 1] 1 T T [1] [ 1] [1] [ 1] T T T ( ) ( ) ( ) ( ) [1] [1] [ 1] [ 1] 1 1 T T i i i i i i i i i i B W z z J z z z z V V − − ∈ ∈ − − − − ∈ ∈ − − = − + − − − = − − + − − = w x x x x w w x x x x x x x x w w w w w クラス クラス2 クラス クラス 1 1 2 2 z w x w x = + = xw [ ] 1 1 2 2 , w x x w = = x w ( ) ( ) ( ) ( ) T T ( ) ( ) ( ) ( ) [1] [1] [ 1] [ 1] 1 1 i i i i W i i V − − ∈ ∈ − = − − + − − x x x x x x x x クラス クラス : クラス k のみの x の平均ベクトル [ ] k x ただし、
) T T 2 T 2 0 B W W B W V V V V J V − ∂ = = ∂ w w w w w w w w w J が最大値 J を w で偏微分して0 ( ) ( )( ) ( ) T T T [1] [ 1] [1] [ 1] 0 B W W V V V − − − − − = w w w w w x x x x w ( )( ) ( ) ( ) T T [1] [ 1] [1] [ 1] T W W B V V V − − − = − w w x x w w x x w w スカラ ( ) 1 [1] [ 1] W V − − − w x x ∝ wの大きさは気にしなくてよい J が極大値
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![J の整理 4 ( ) ( ) T [1] [](https://files.speakerdeck.com/presentations/45a48ed5d55d4d659a365c78a8cdf754/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}