Ruby's M17N is CSI (Character Set Independent): each String carries an encoding tag ˒ Most languages are UCS: internal form is always Unicode (Python / Java) ˒ How much does CSI actually cost? ˒ Scope: per-char String ops only. String#encode / IO conversion / Regexp are out. Motivation 3
˒ 1.00x~1.05x slower or faster ˒ No change ˒ Why: non-builtin encodings are dynamically loaded. If unused, they never touch memory — zero hot-path cost. 1. Shrink encodings 8
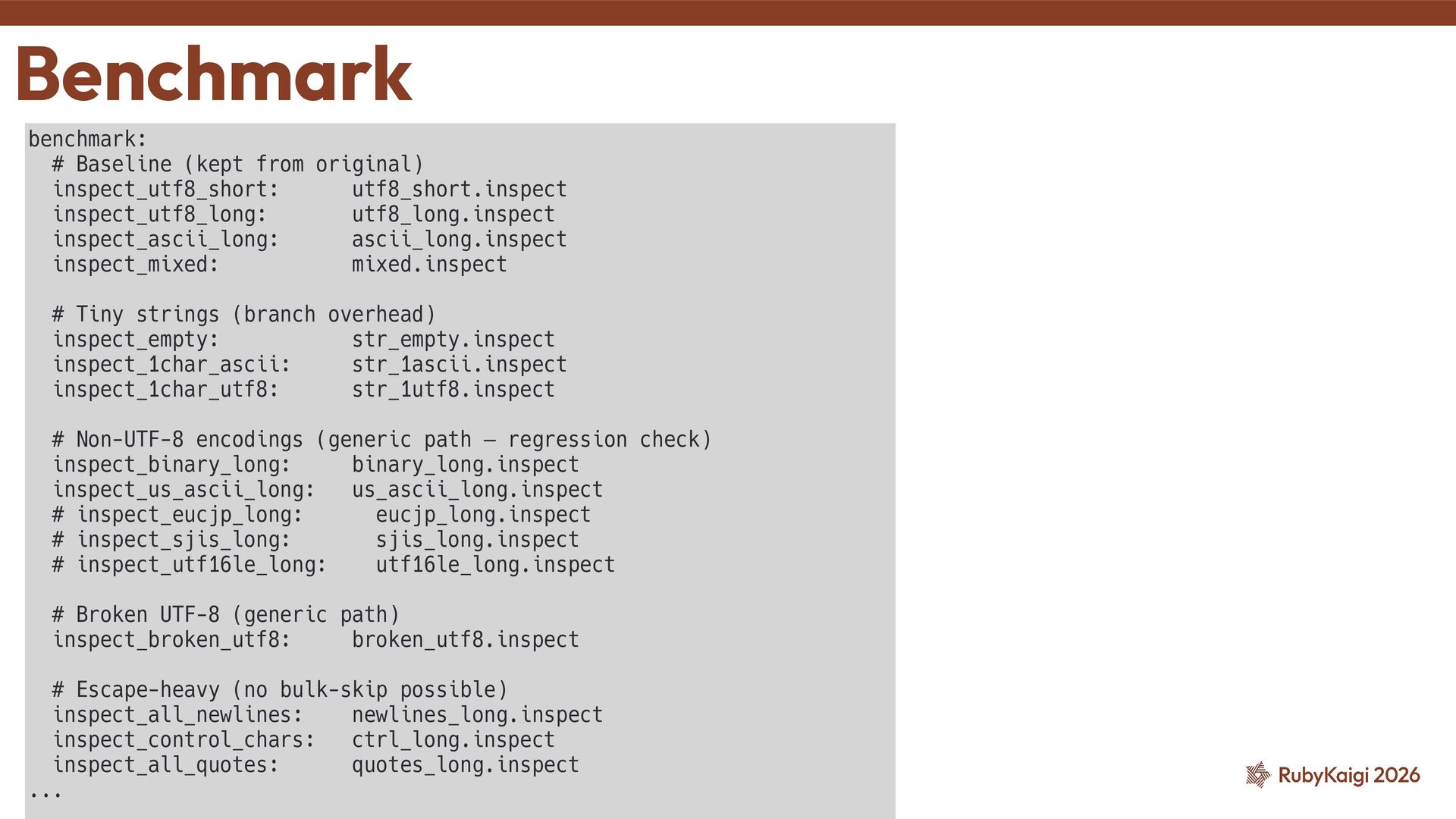
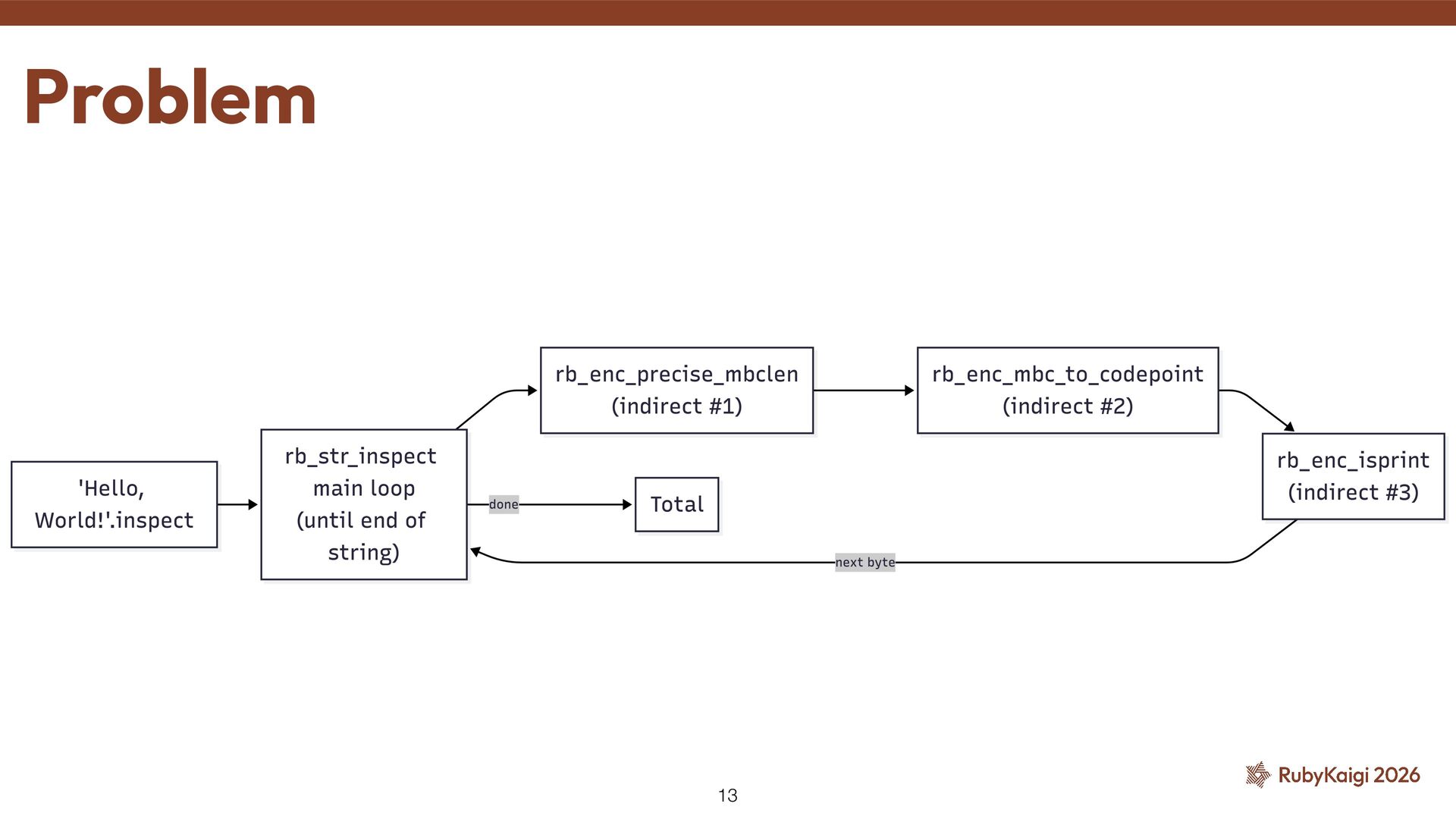
(String#length, String#+) ˒ 2. The predictor handles the rest — encoding is stable ˒ 3. Non-UTF-8 pays a dead compare — then takes the indirect anyway 2. Direct calls 10
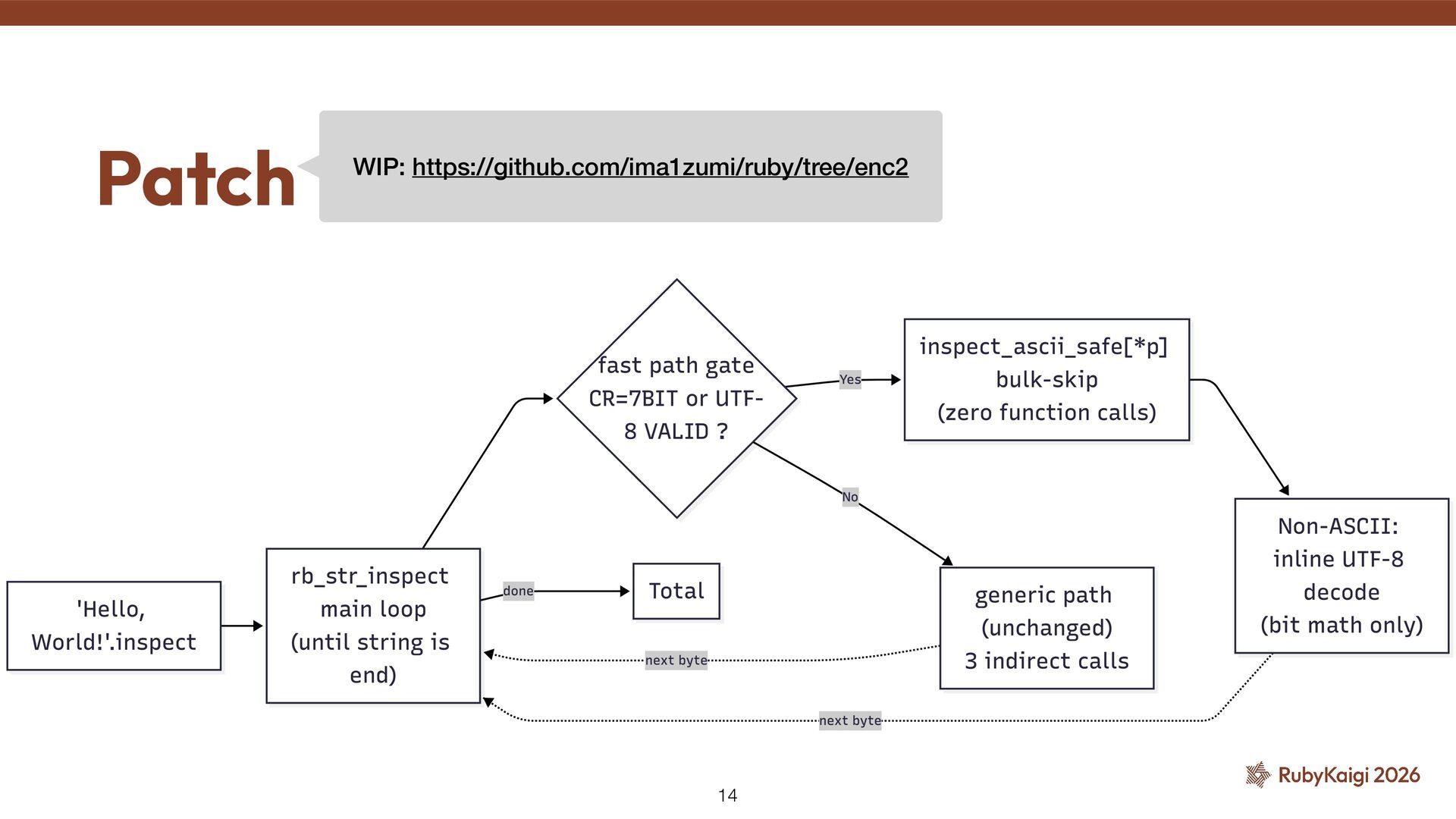
bo tt leneck = per-char work itself (3 indirect calls per char) ˒ reduce the whole thing ˒ Add UTF-8-speci fi c fast paths ˒ See also: byroot's blog — h tt ps://byroot.github.io/ruby/ performance/2026/04/18/faster-paths.html So what actually works? 11
encoding layer itself is cheap ˒ But there's still room to bolt UTF-8 / ASCII fast paths on top of CSI — `inspect` gives up to 10x ˒ Same trick should work anywhere per-char indirect calls still live in the loop Takeaway 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}