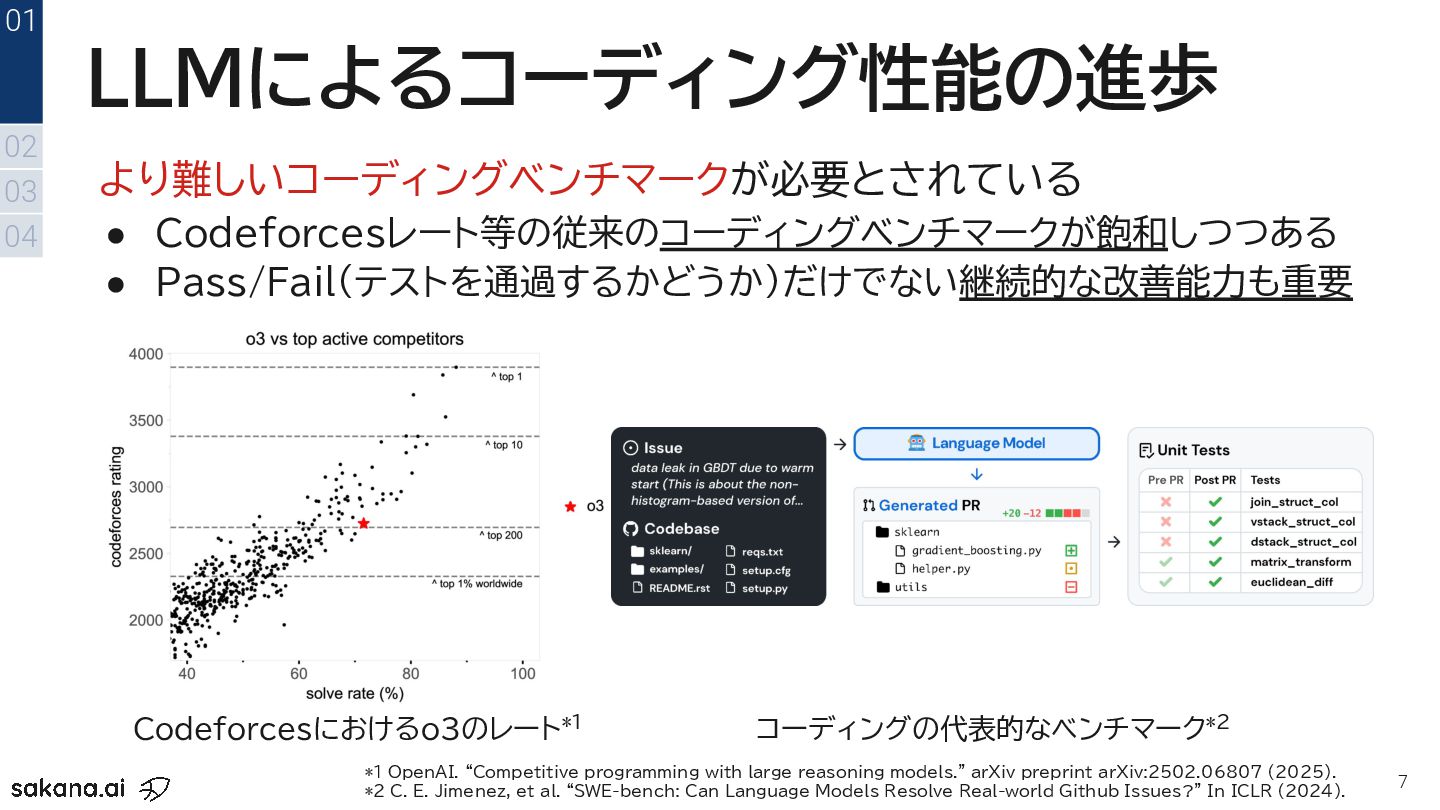
01 *1 OpenAI. “Competitive programming with large reasoning models." arXiv preprint arXiv:2502.06807 (2025). *2 C. E. Jimenez, et al. “SWE-bench: Can Language Models Resolve Real-world Github Issues?” In ICLR (2024). Codeforcesにおけるo3のレート*1 コーディングの代表的なベンチマーク*2
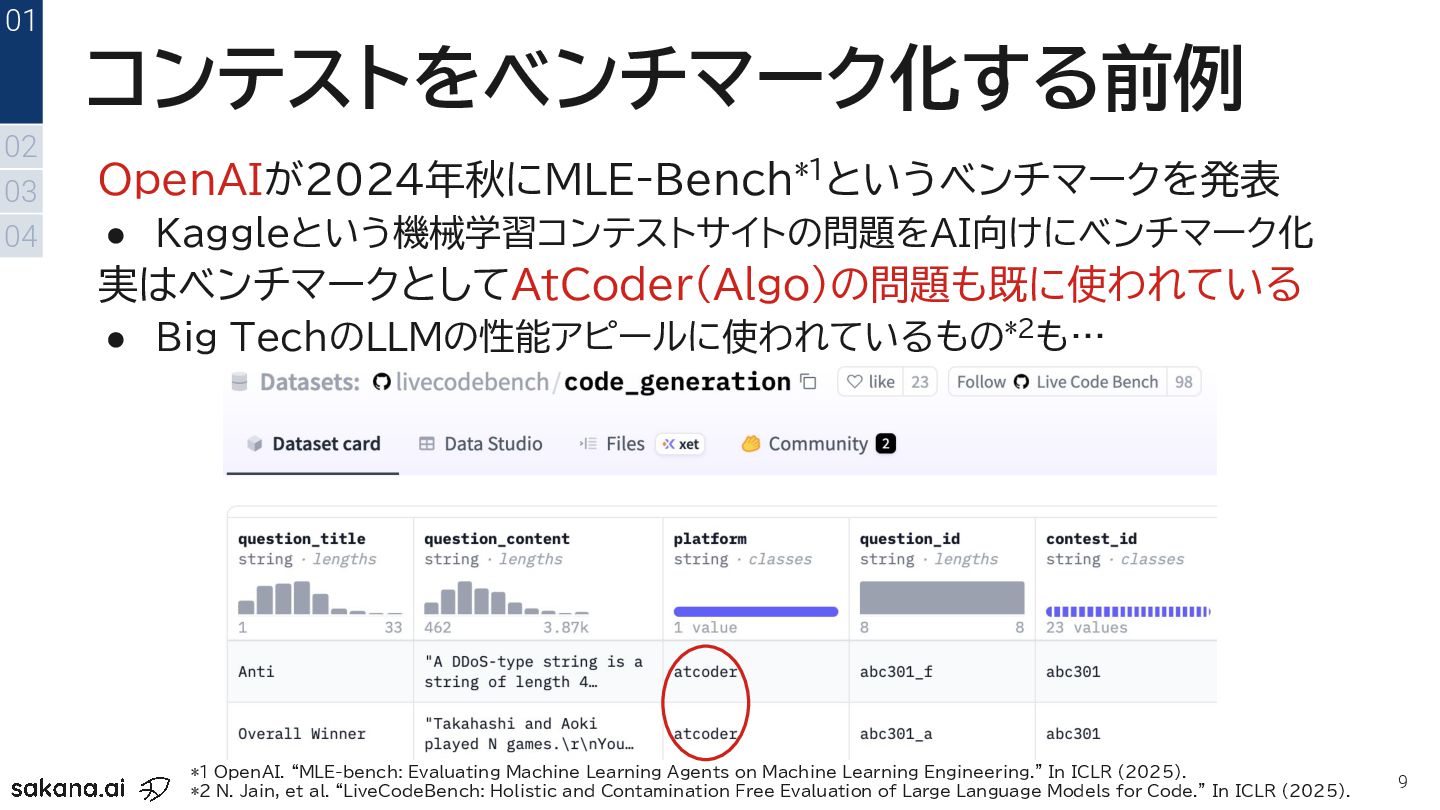
03 04 01 *1 OpenAI. “MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering." In ICLR (2025). *2 N. Jain, et al. “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.” In ICLR (2025).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
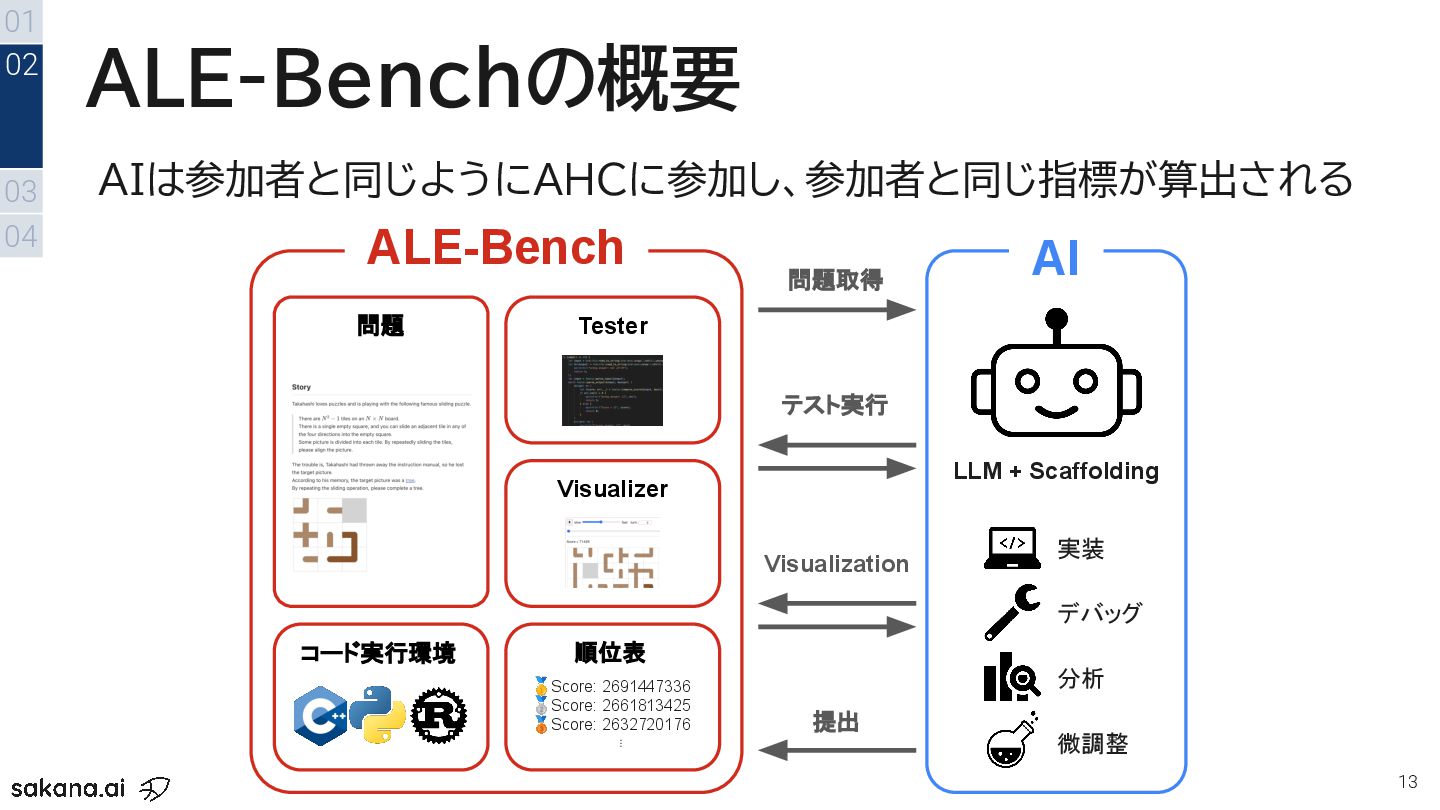{kind=link}
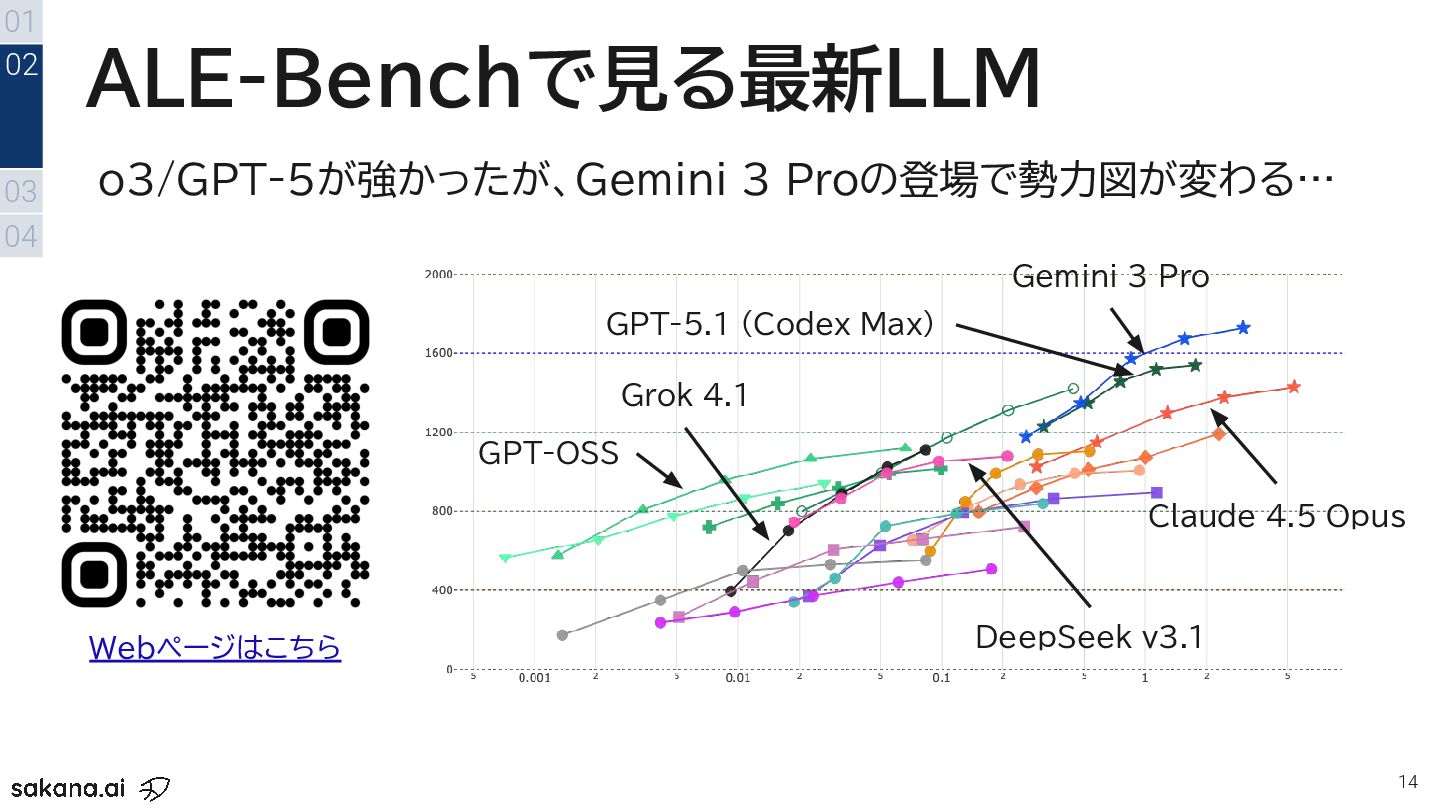{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
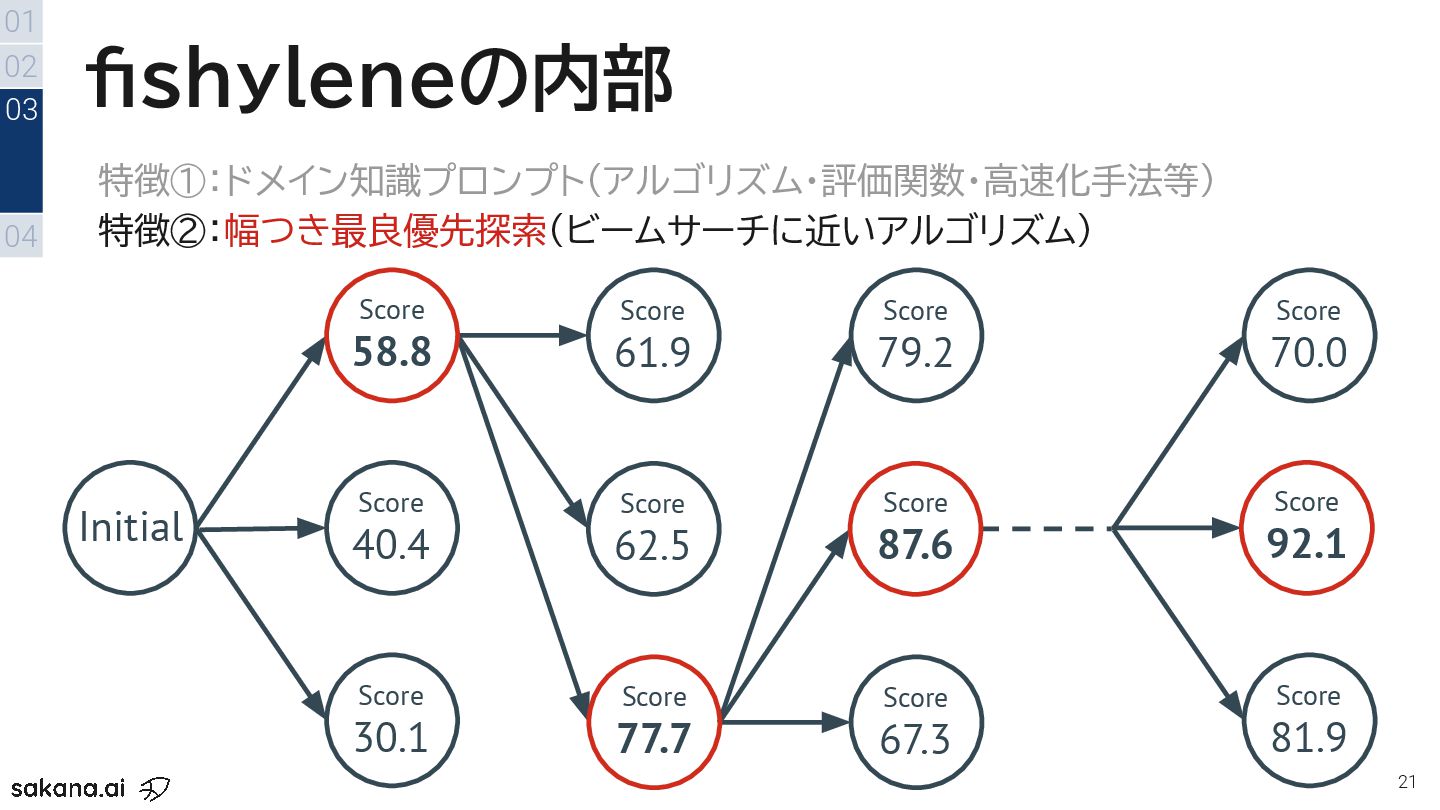{kind=link}
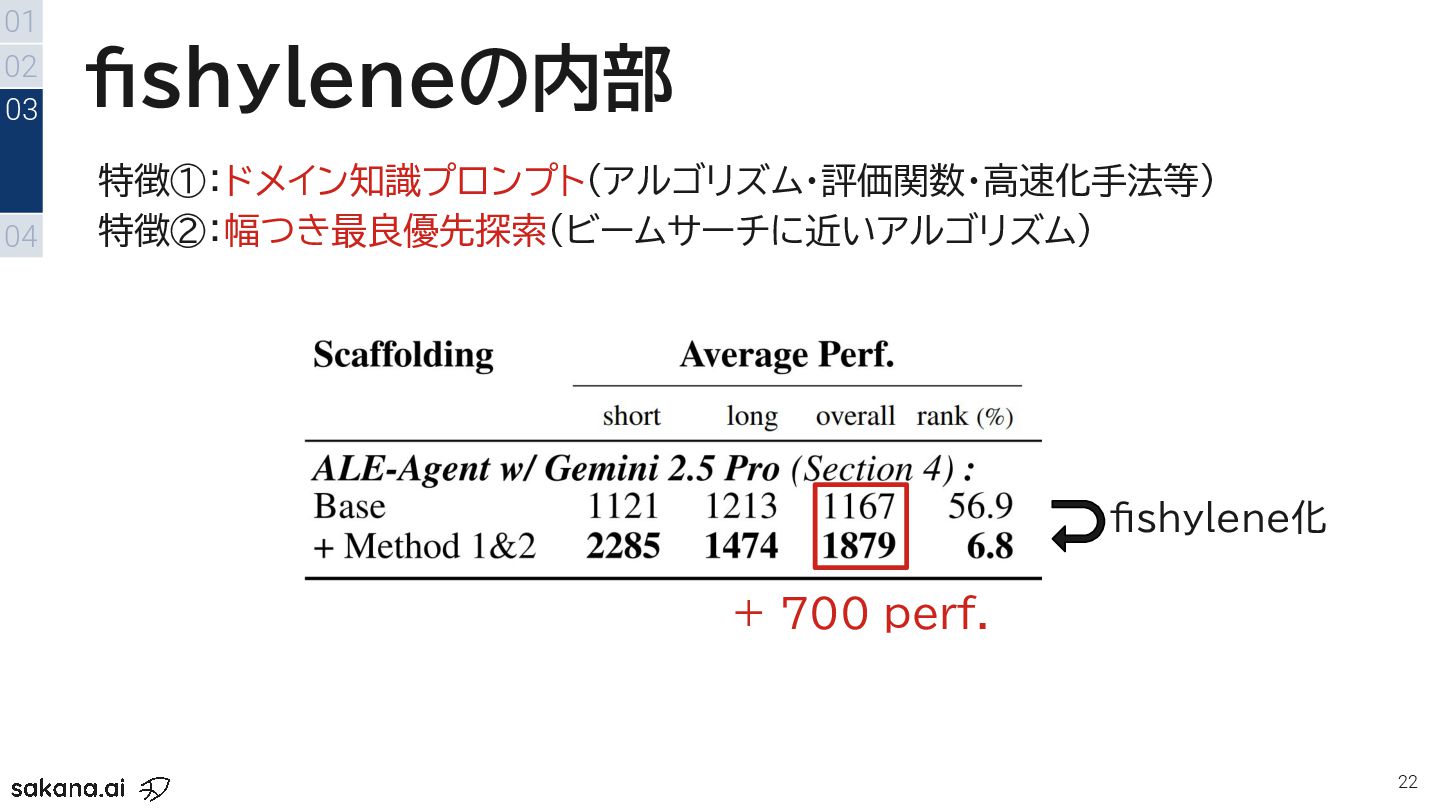{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}