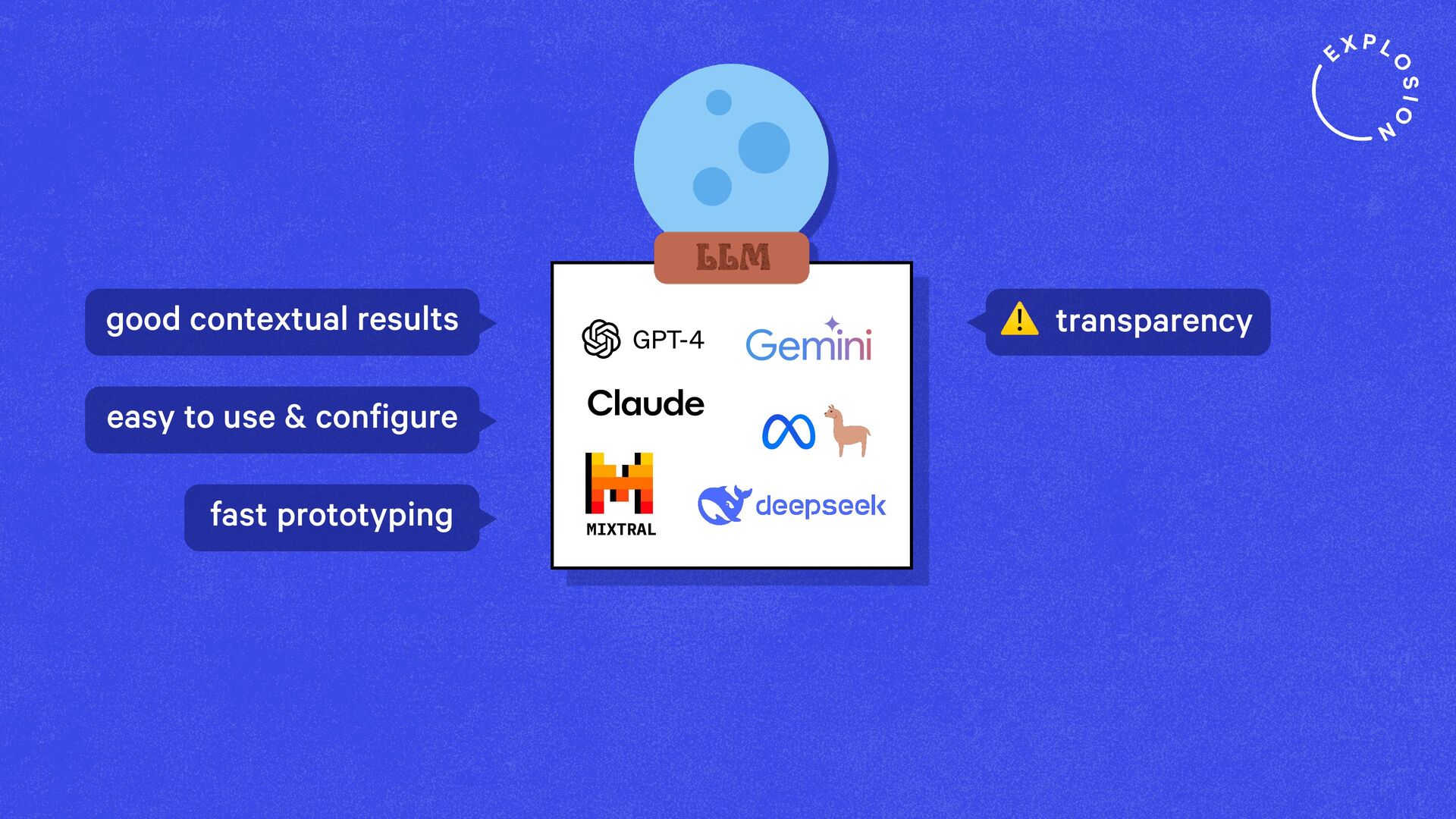
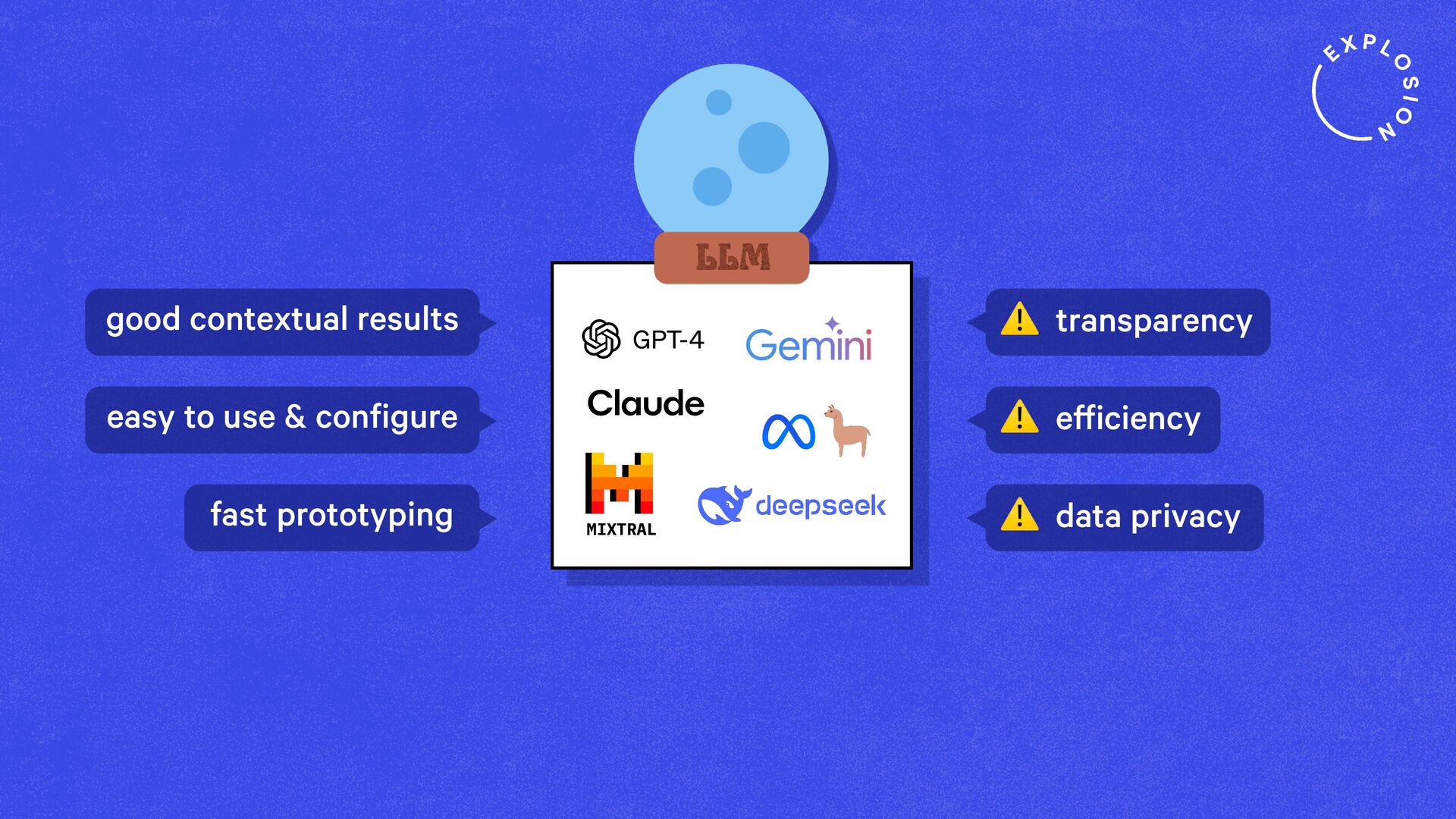
Large Language Models (LLMs) and in-context learning have introduced a new paradigm for developing natural language understanding systems: prompts are all you need! Prototyping has never been easier, but not all prototypes give a smooth path to production. Many new ideas that are emerging also challenge existing workflows in industry that require modularity, transparency and data privacy. In this talk, I'll share the most important lessons we've learned from solving real-world information extraction problems in industry, and show you a new approach and mindset for building modular and future-proof NLP pipelines in-house.
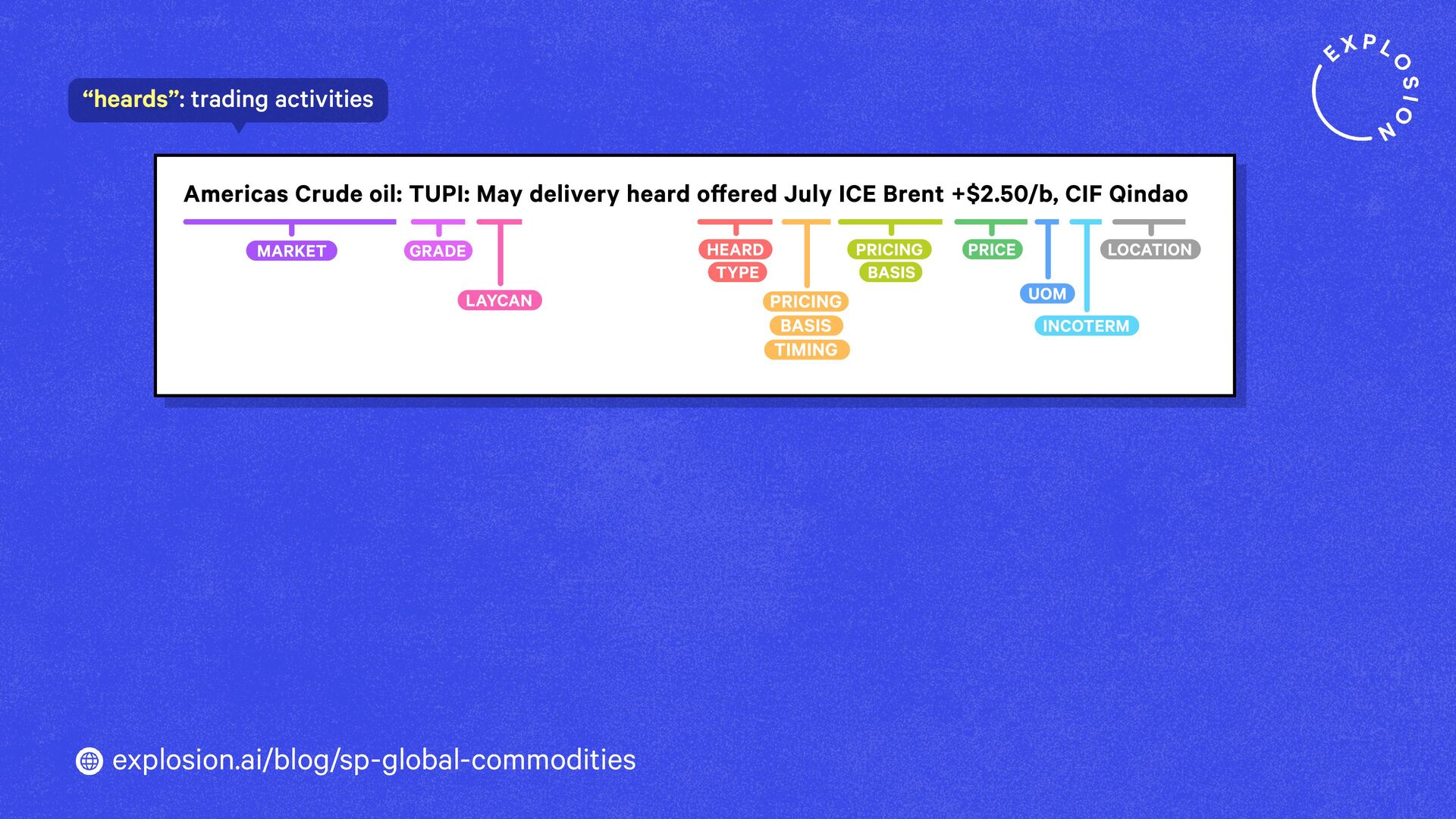
https://explosion.ai/blog/sp-global-commodities
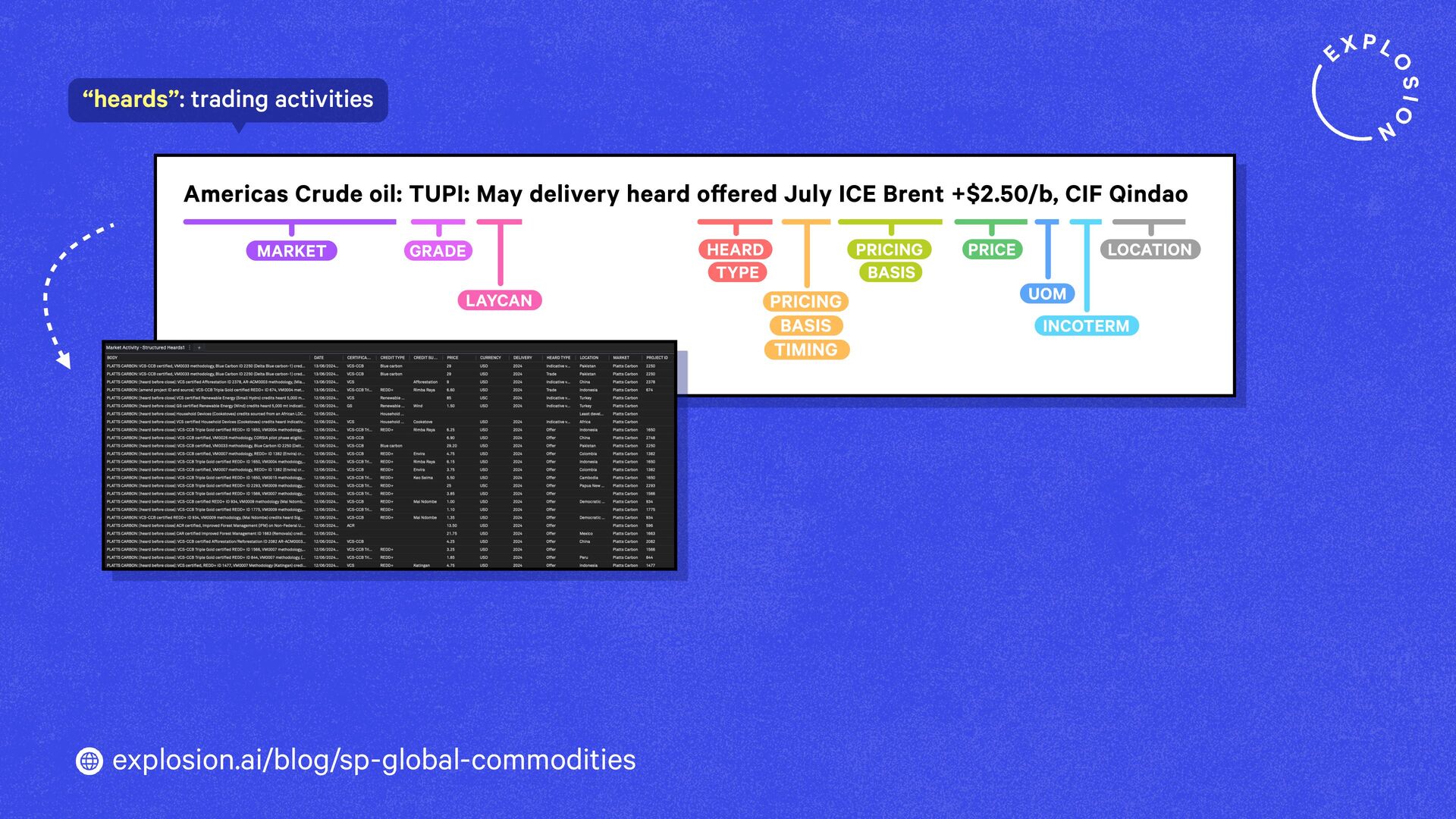
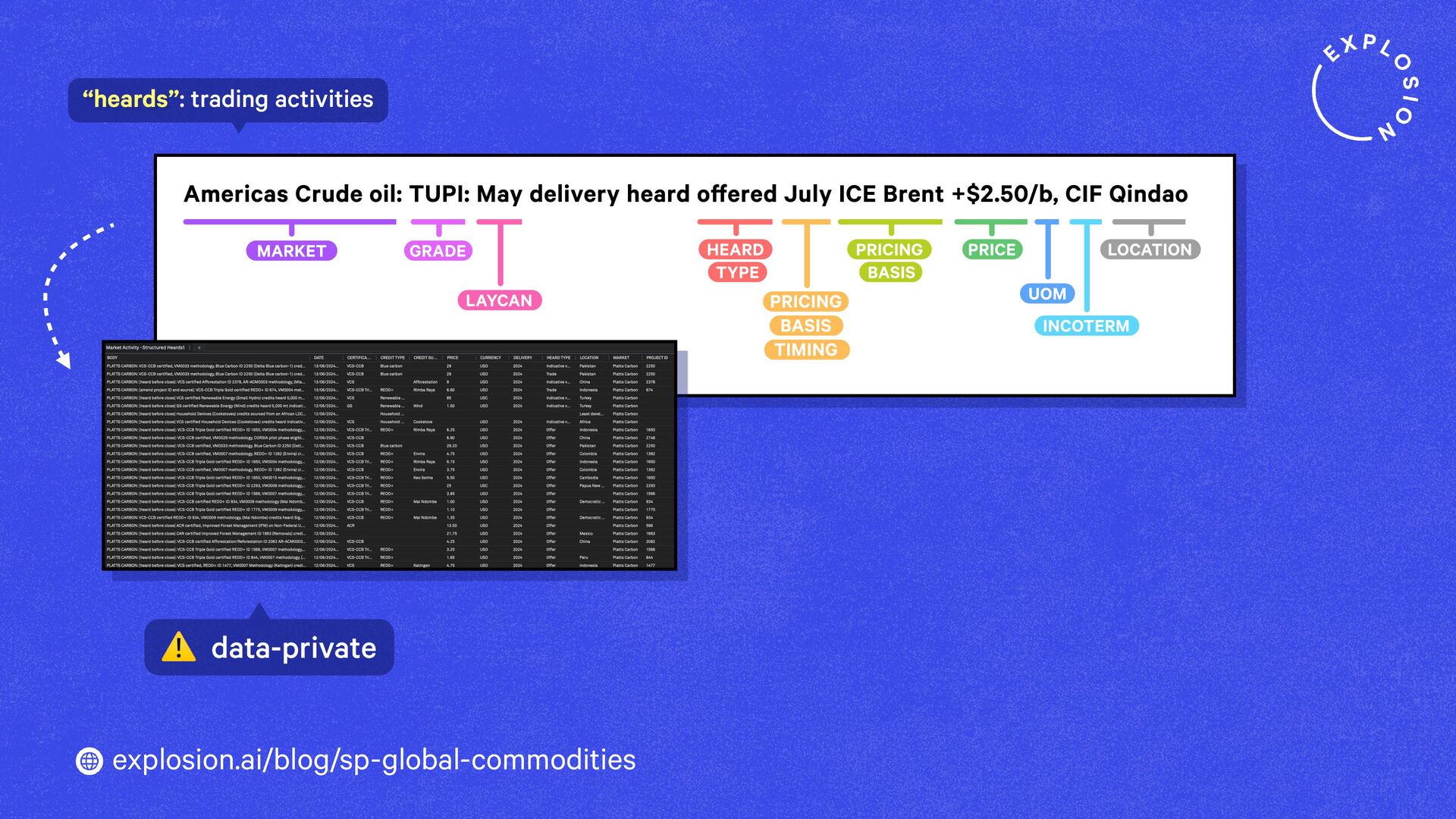
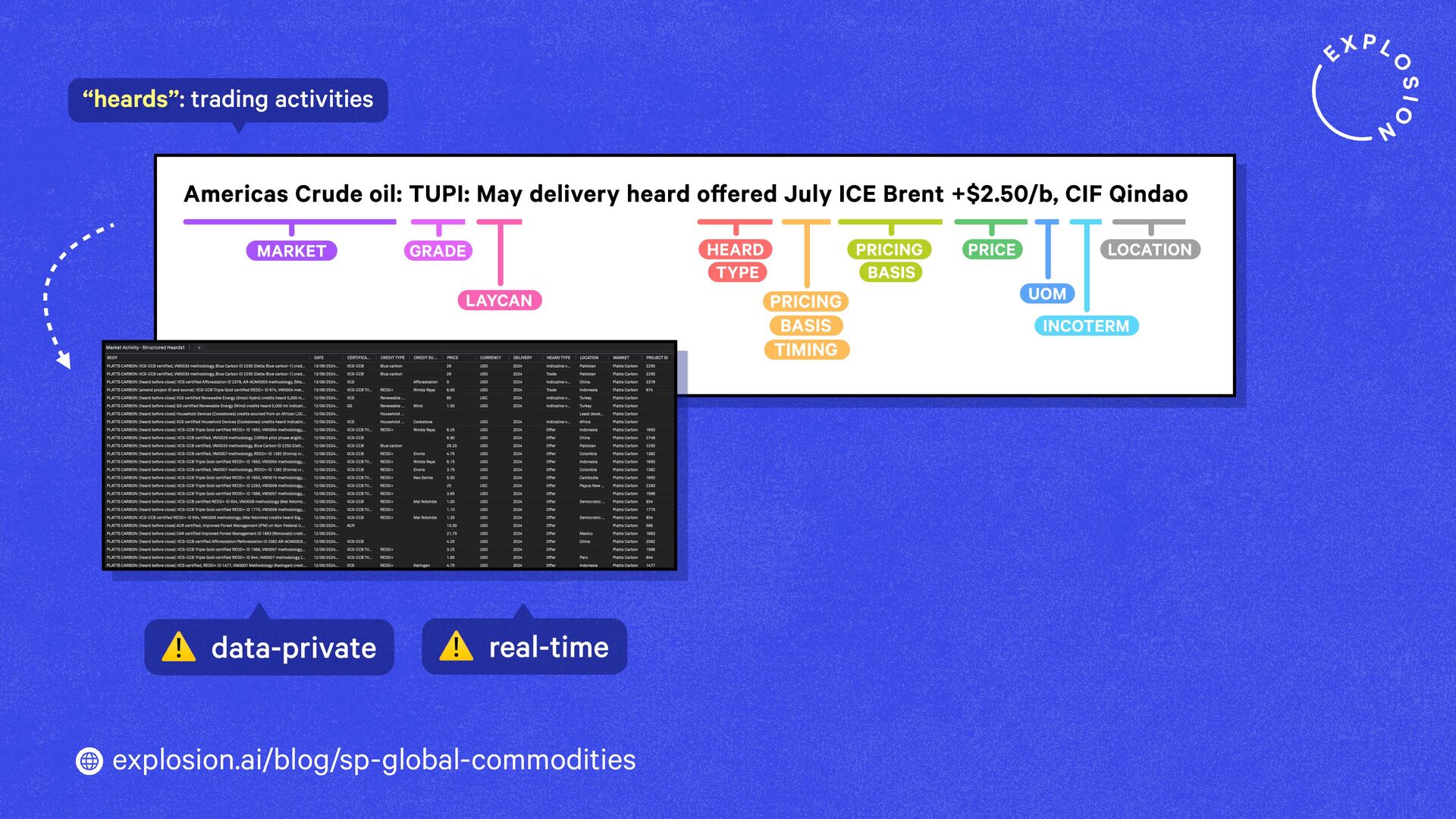
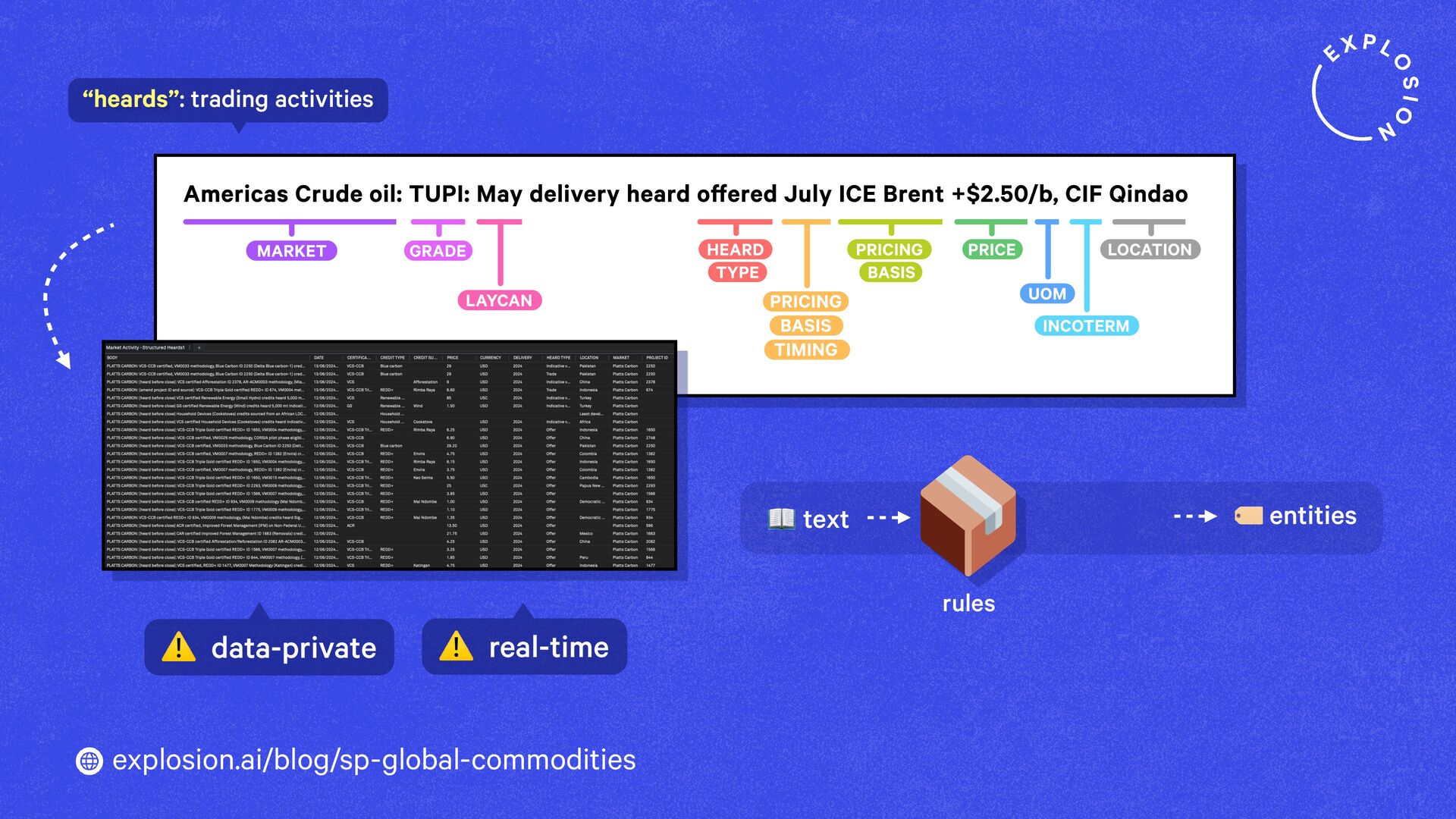
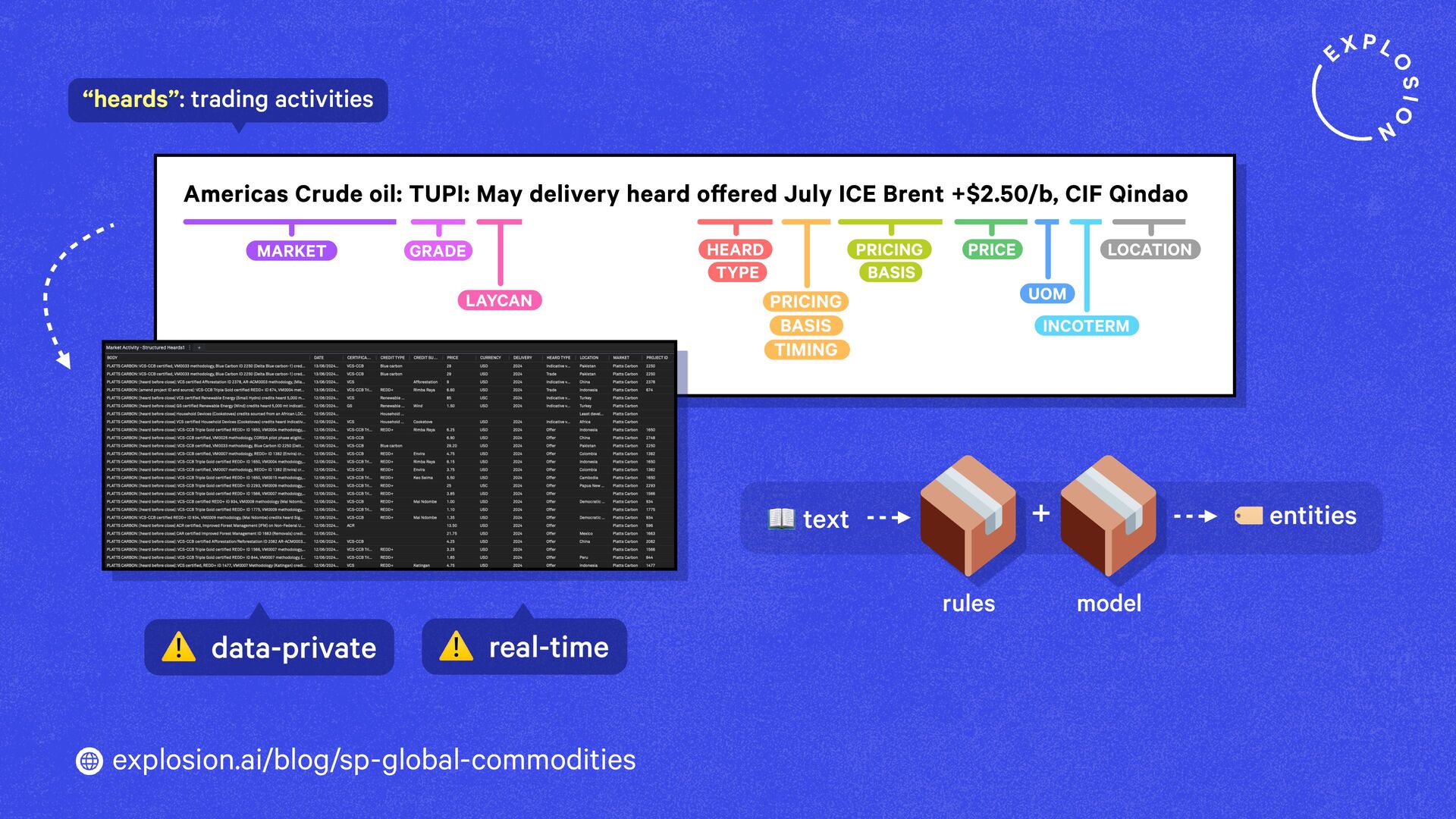
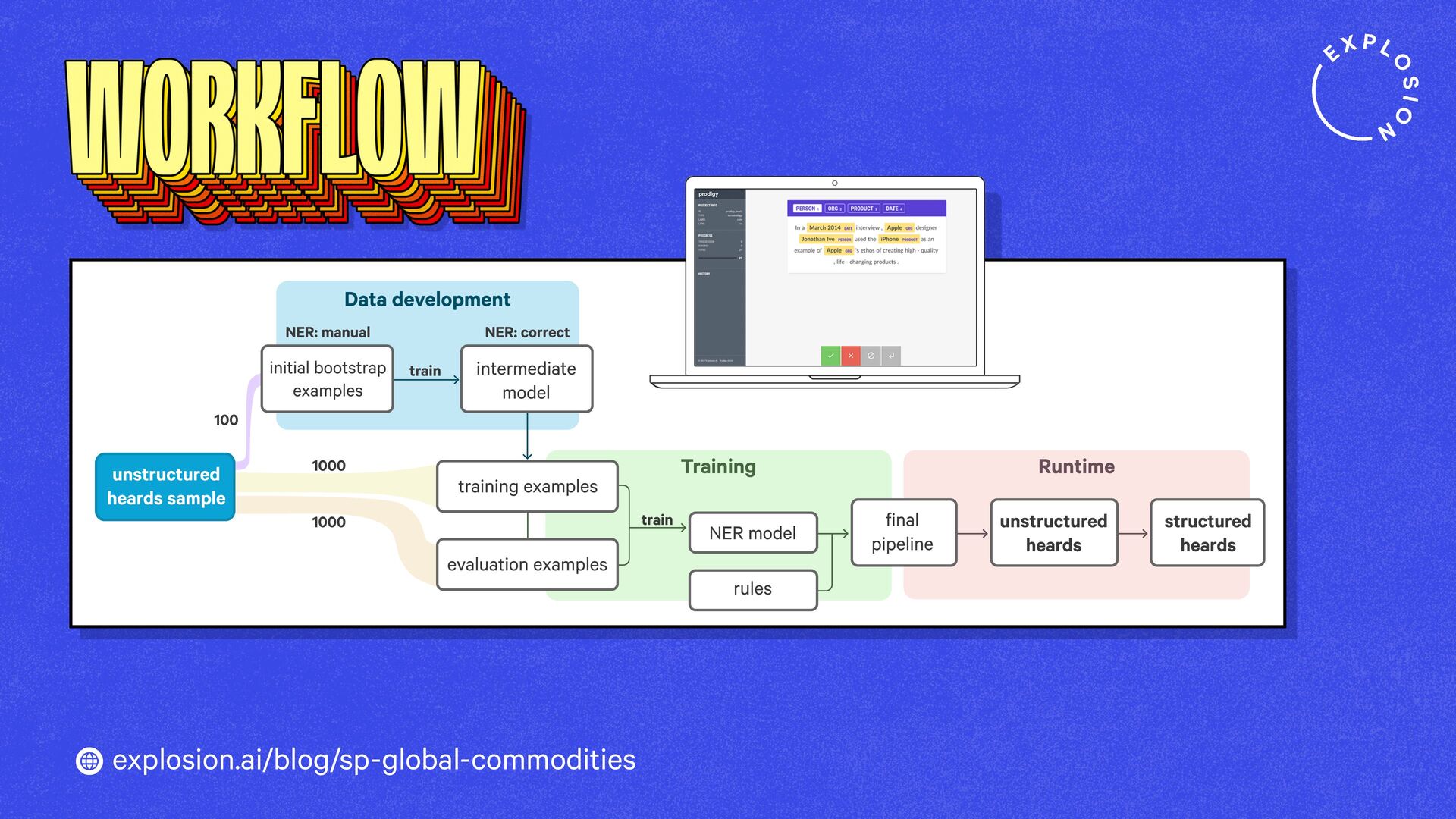
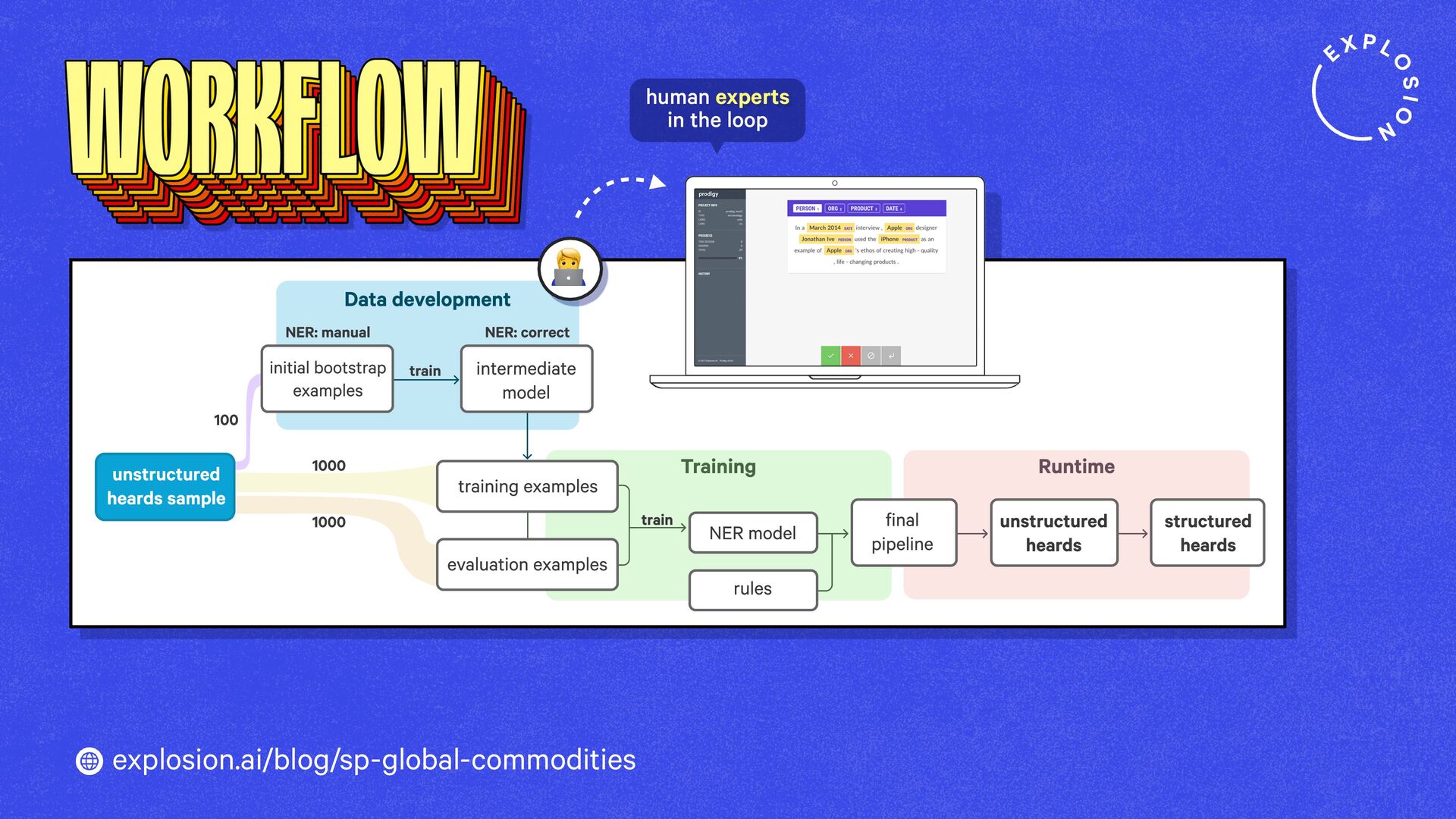
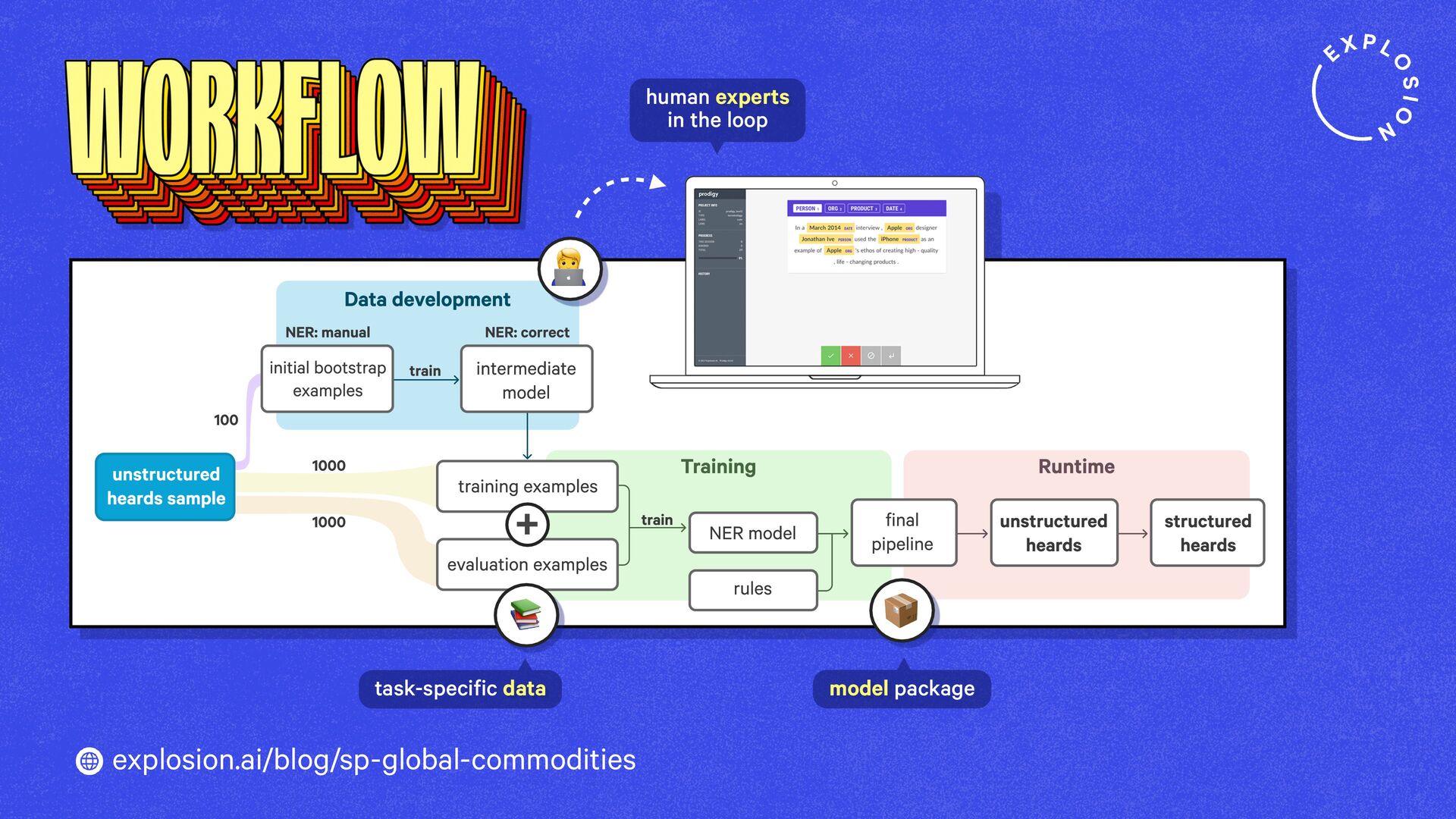
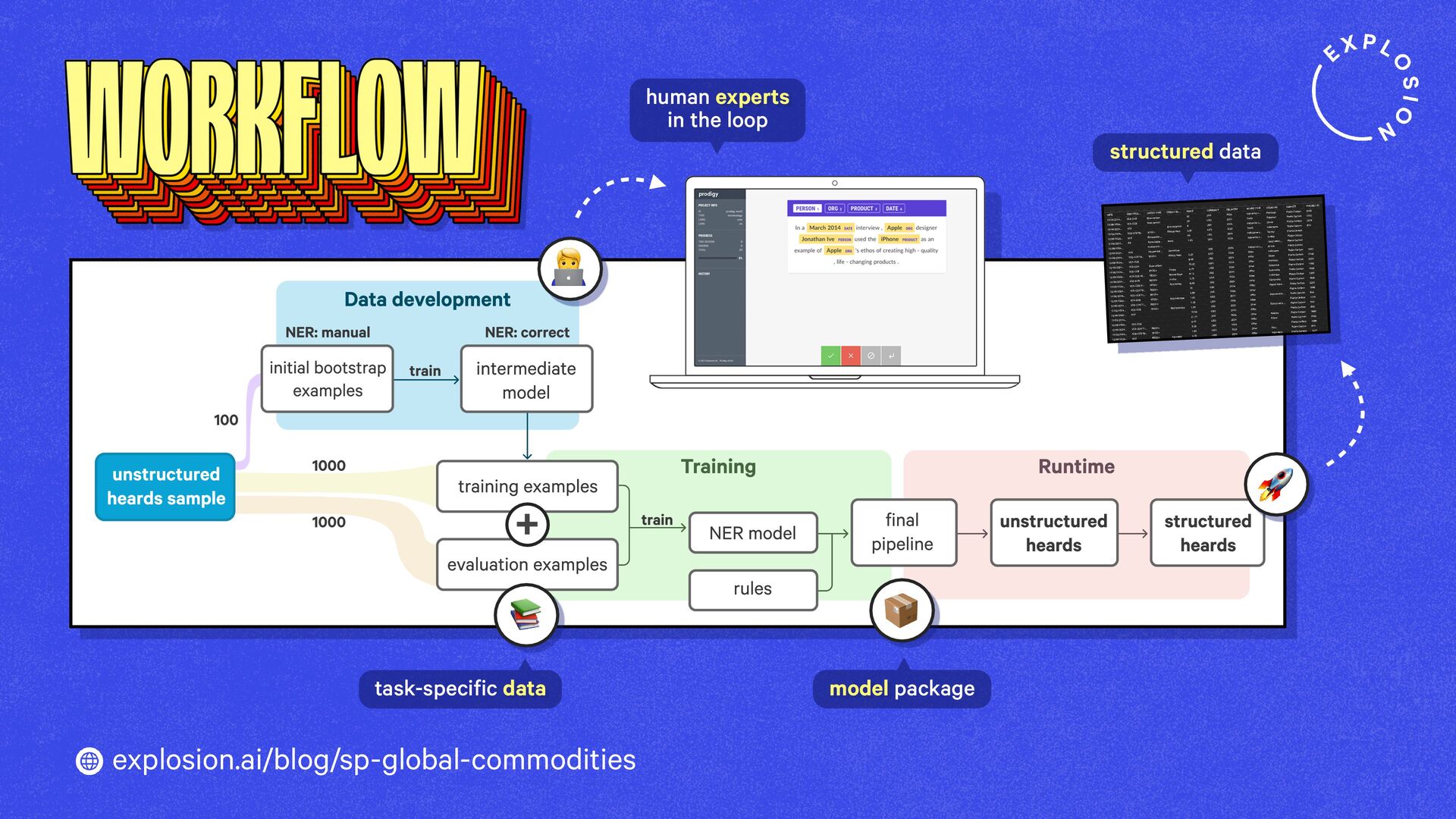
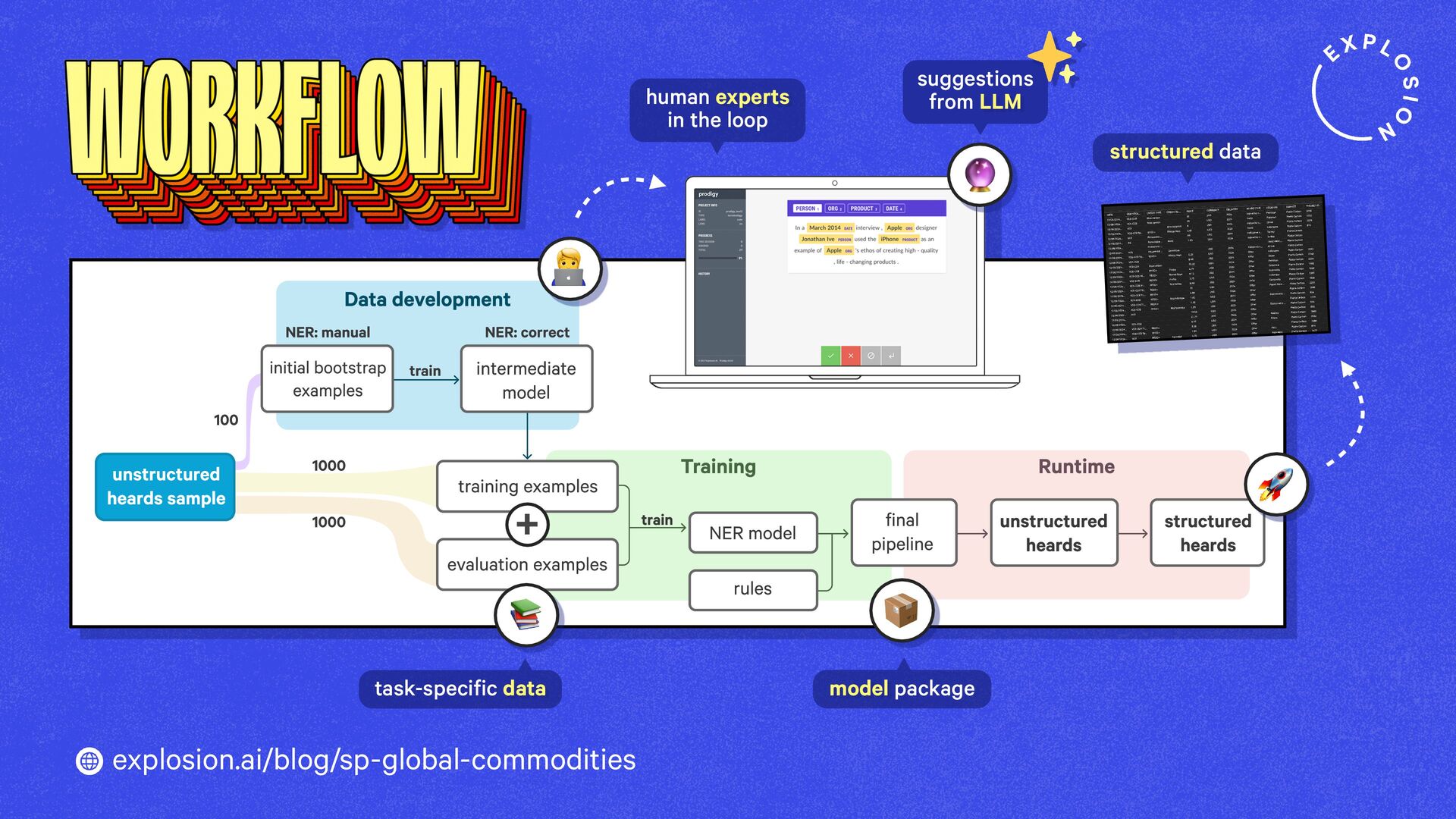
A case study on S&P Global’s efficient information extraction pipelines for real-time commodities trading insights in a high-security environment using human-in-the-loop distillation.
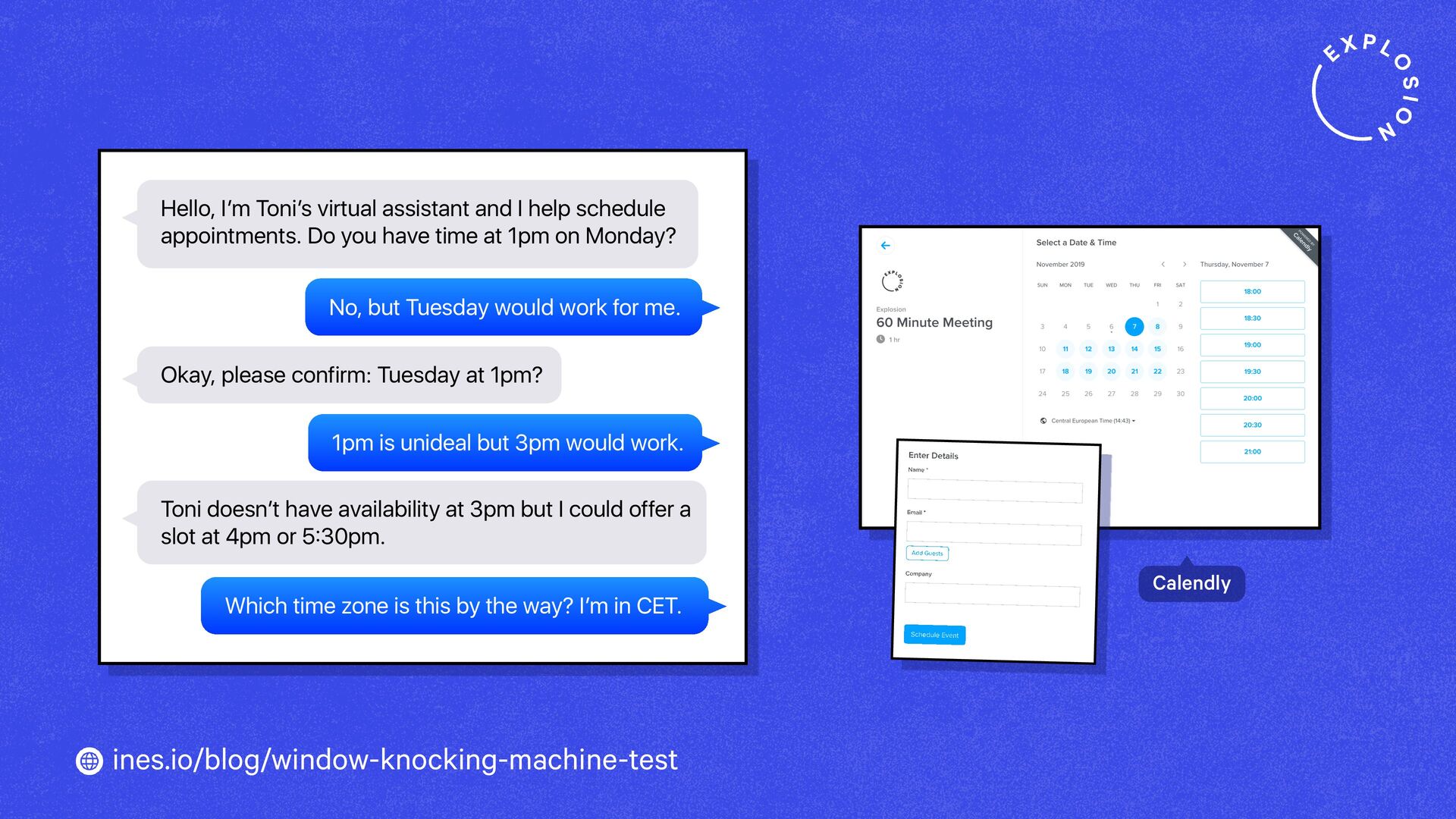
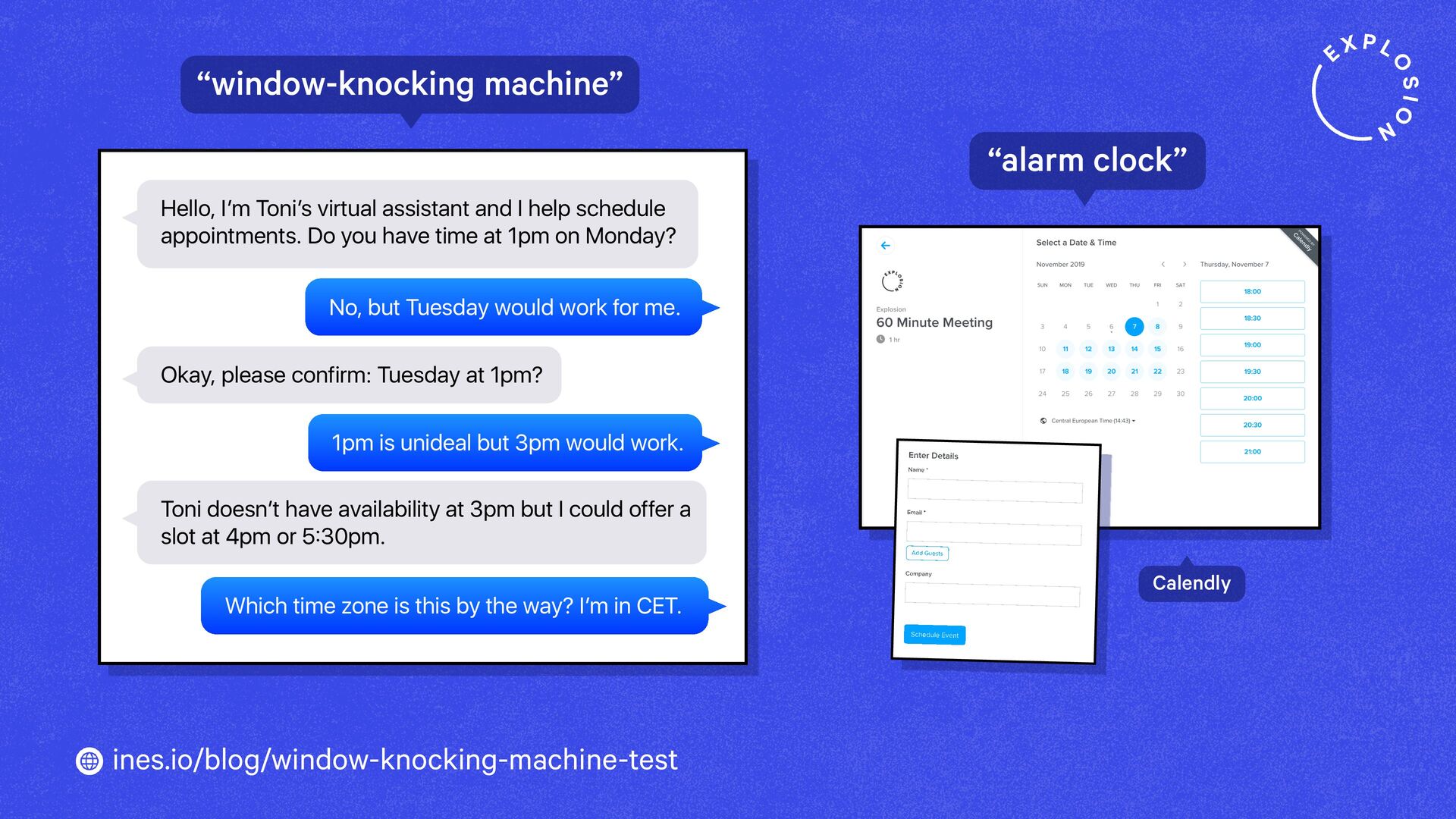
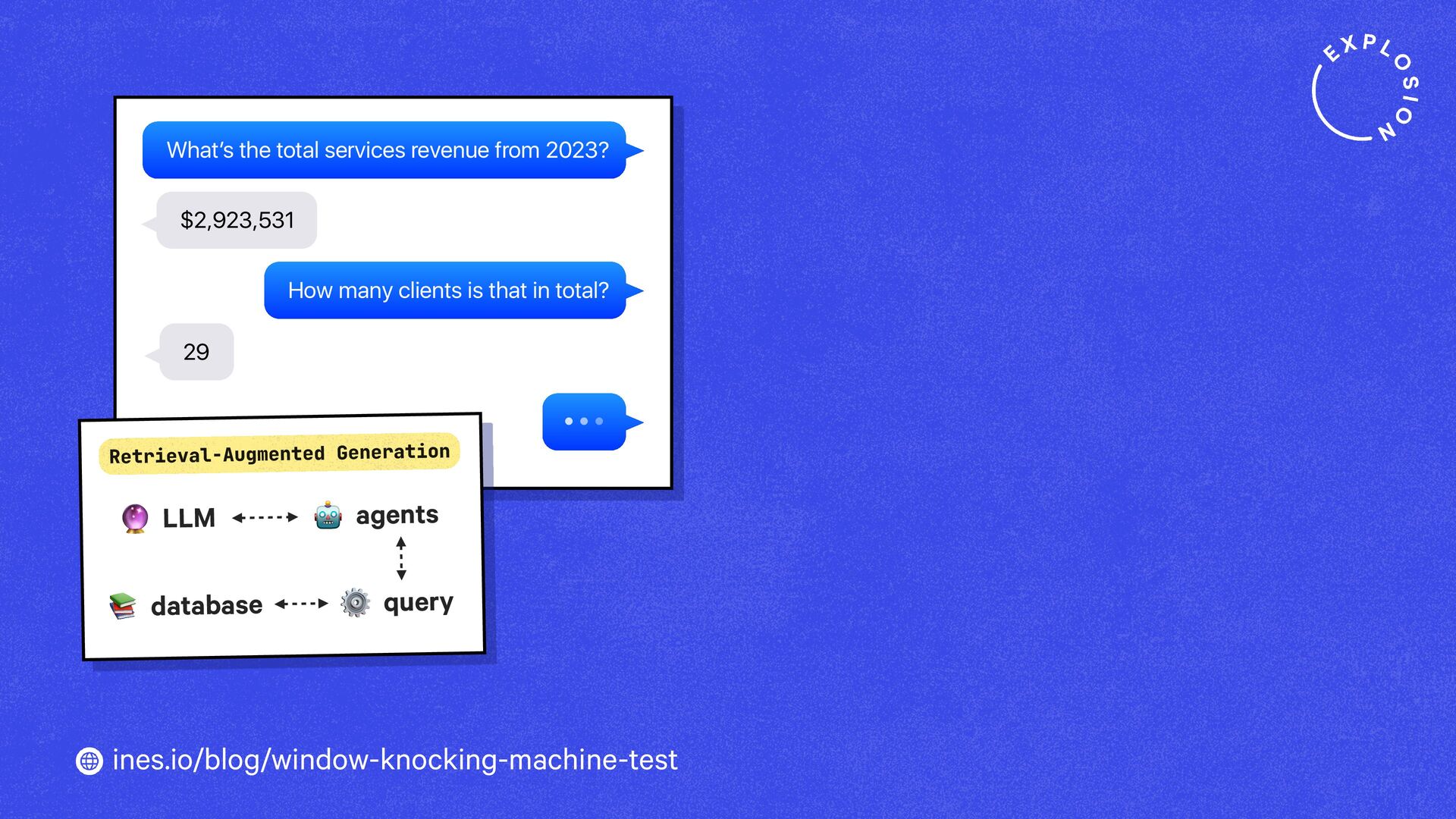
https://ines.io/blog/window-knocking-machine-test/
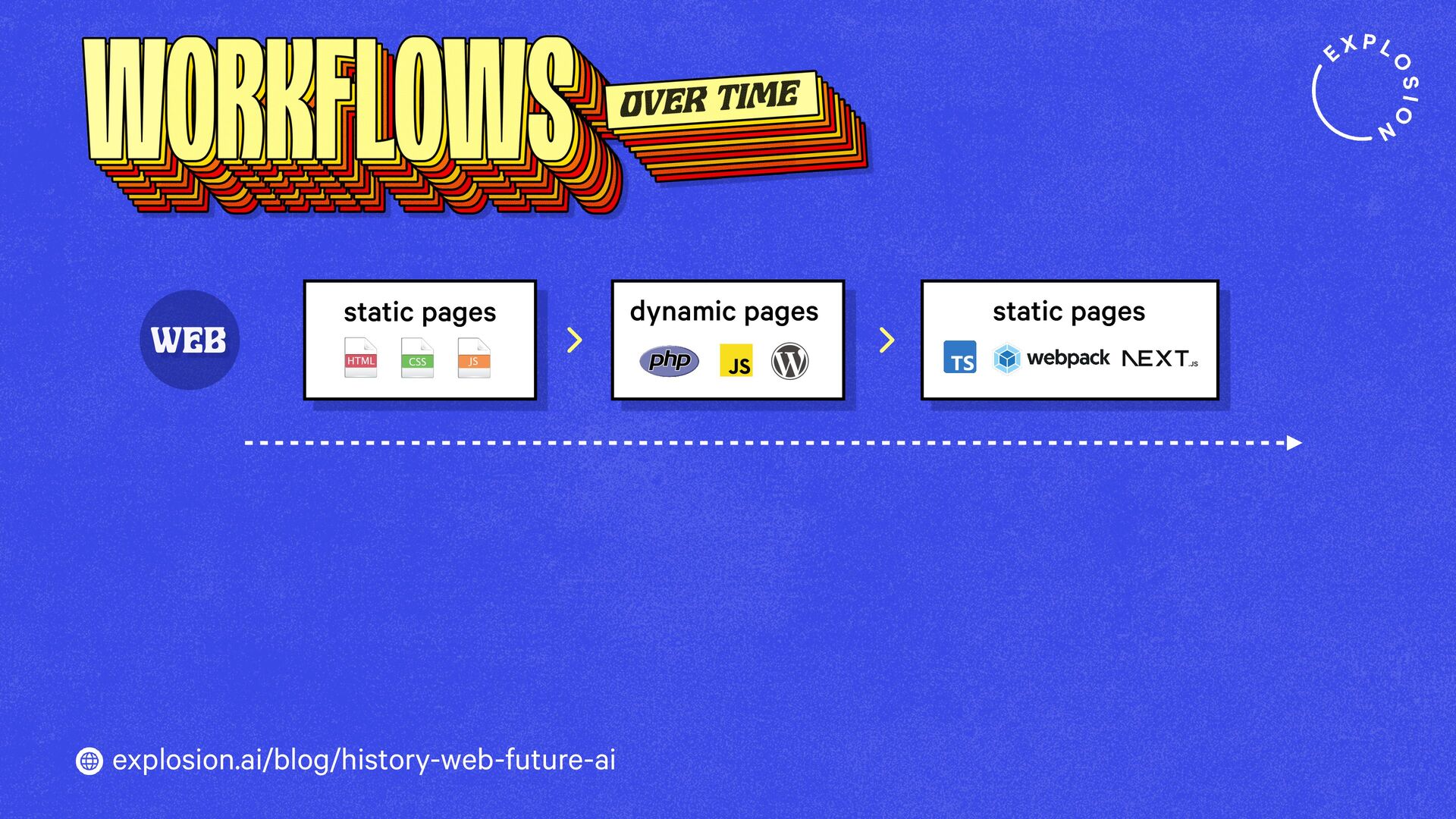
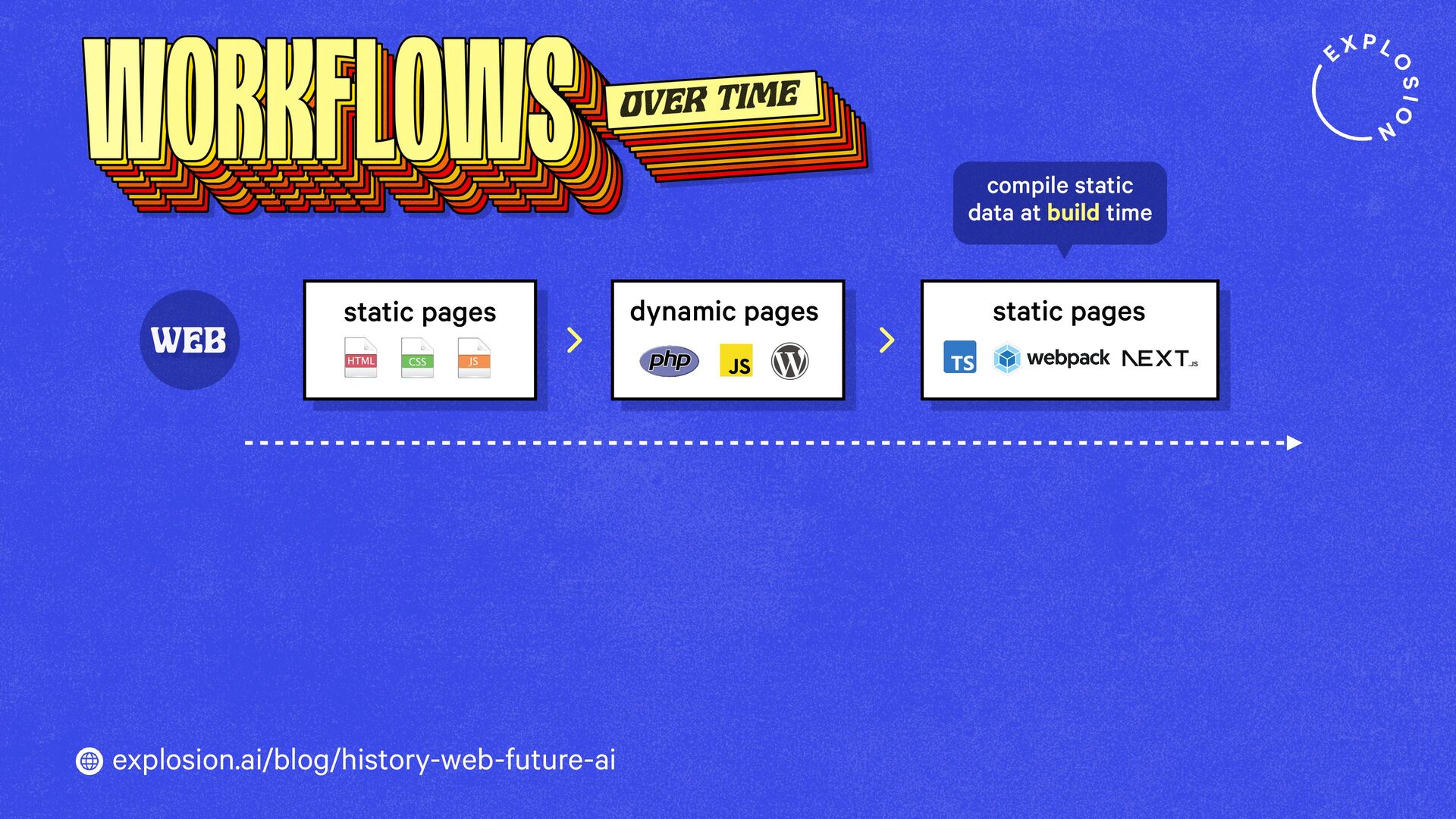
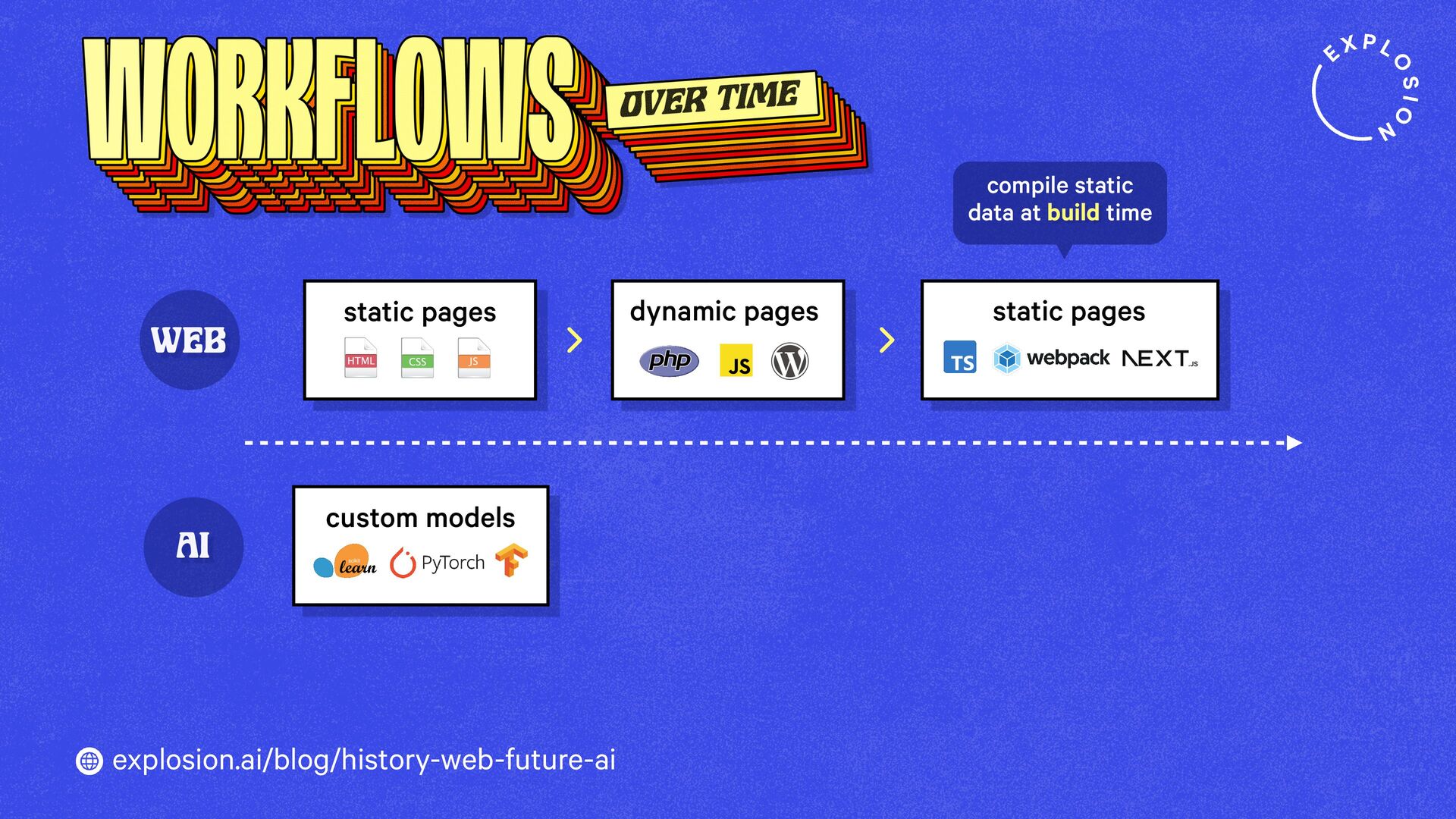
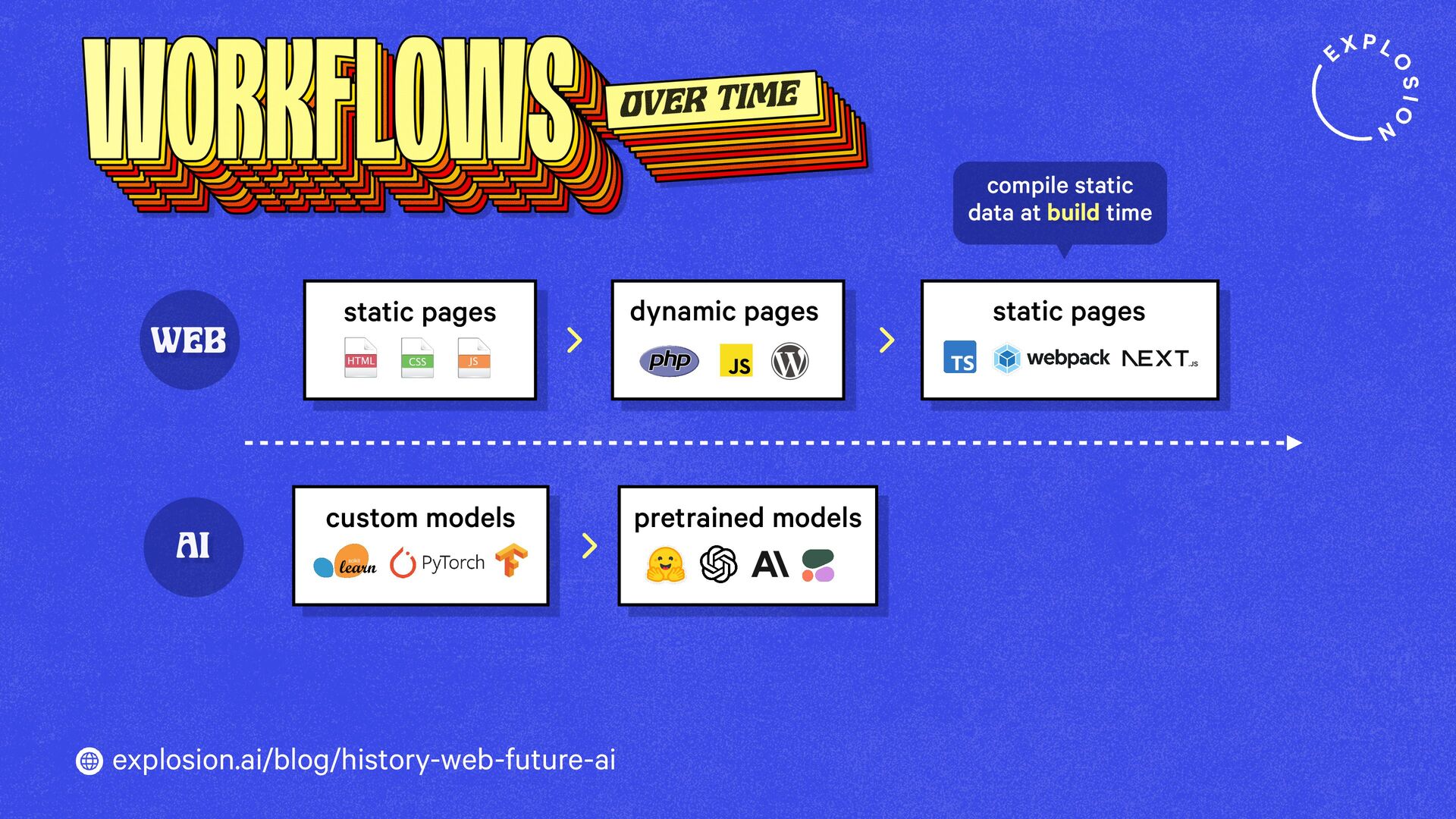
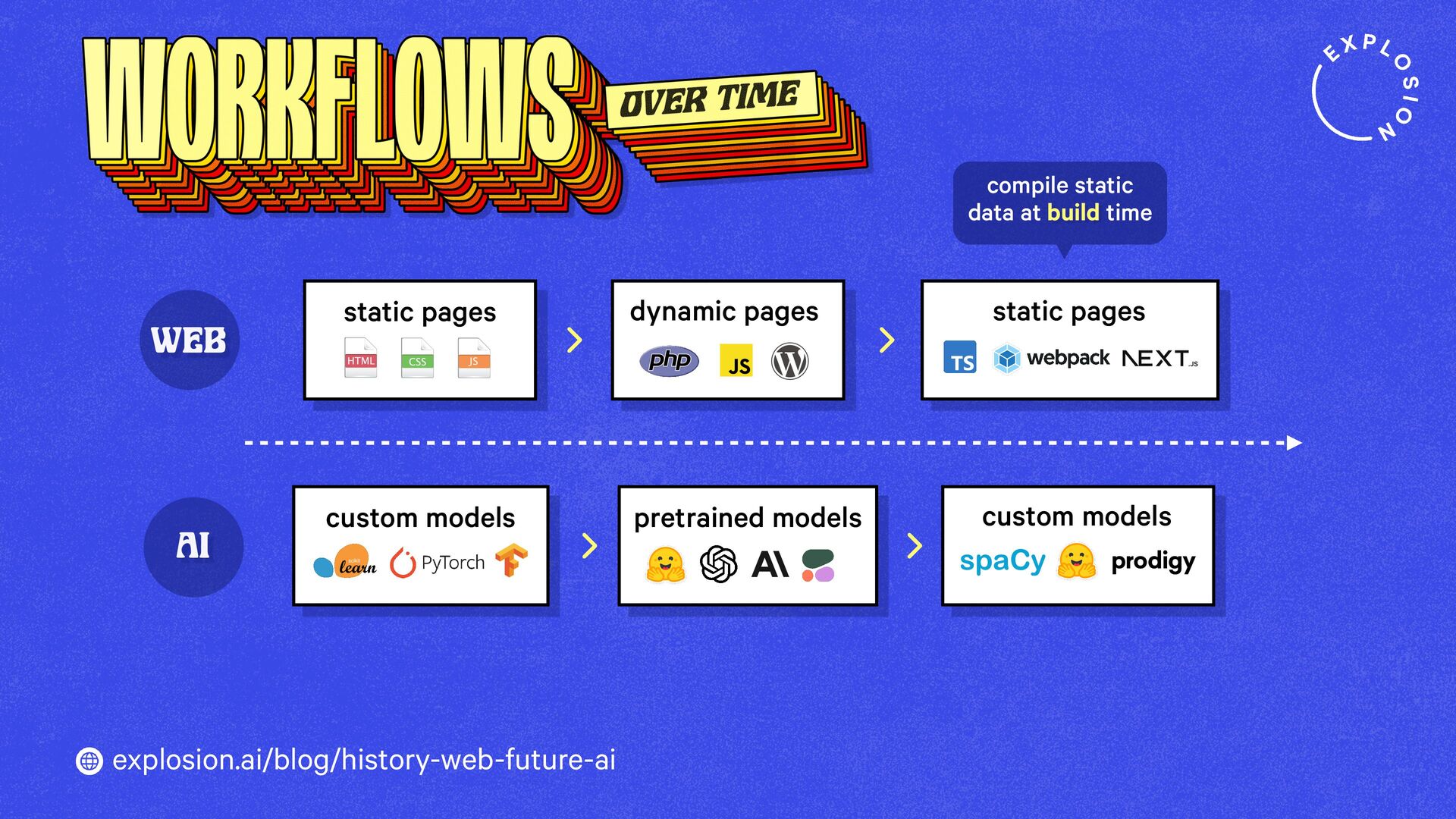
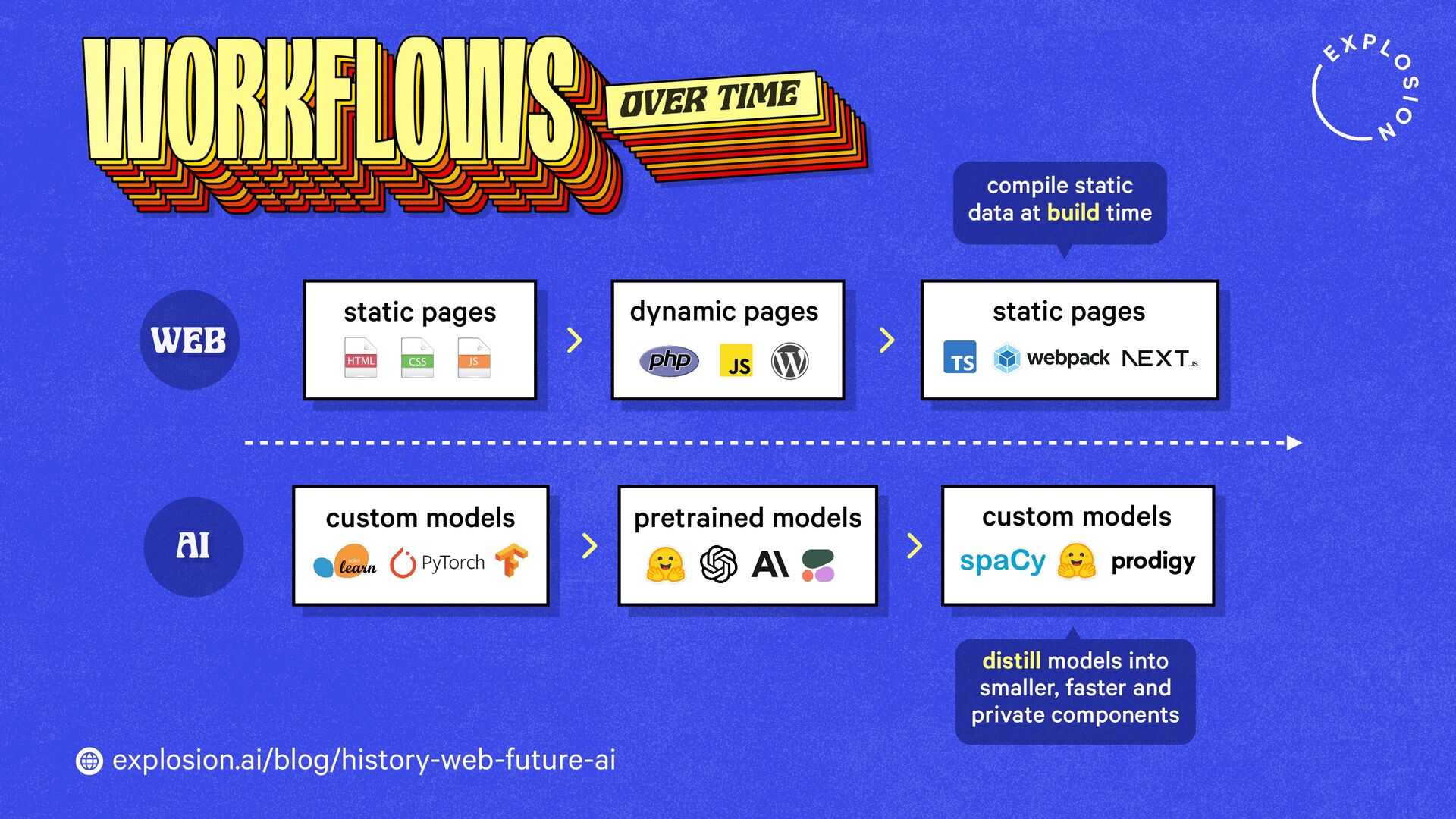
How will technology shape our world going forward? And what tools and products should we build? When imagining what the future could look like, it helps to look back in time and compare past visions to our reality today.
https://explosion.ai/blog/history-web-future-ai
This blog post takes a look at what the history of the web can teach us, and what this means for developers, models, open source and regulation.
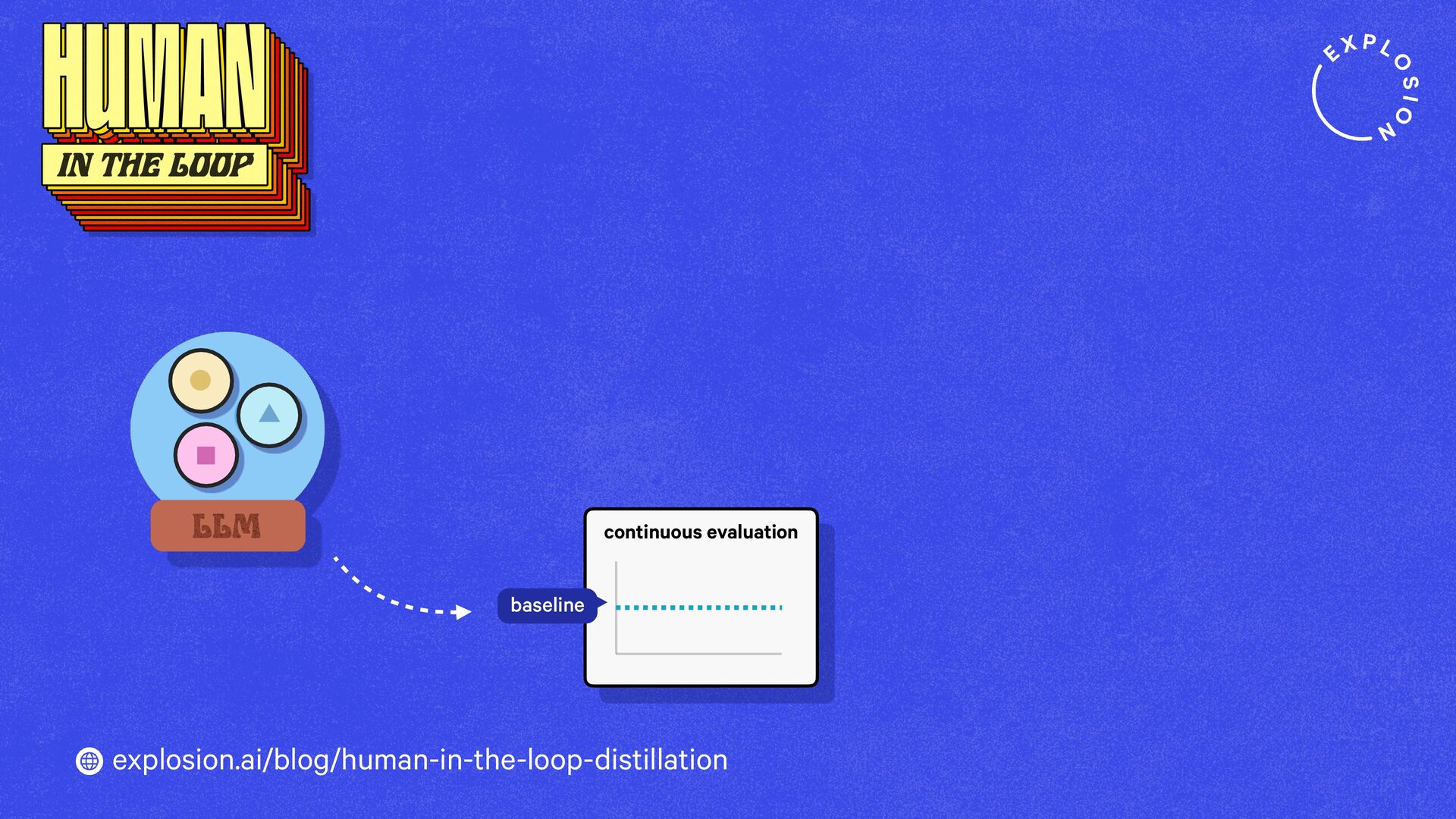
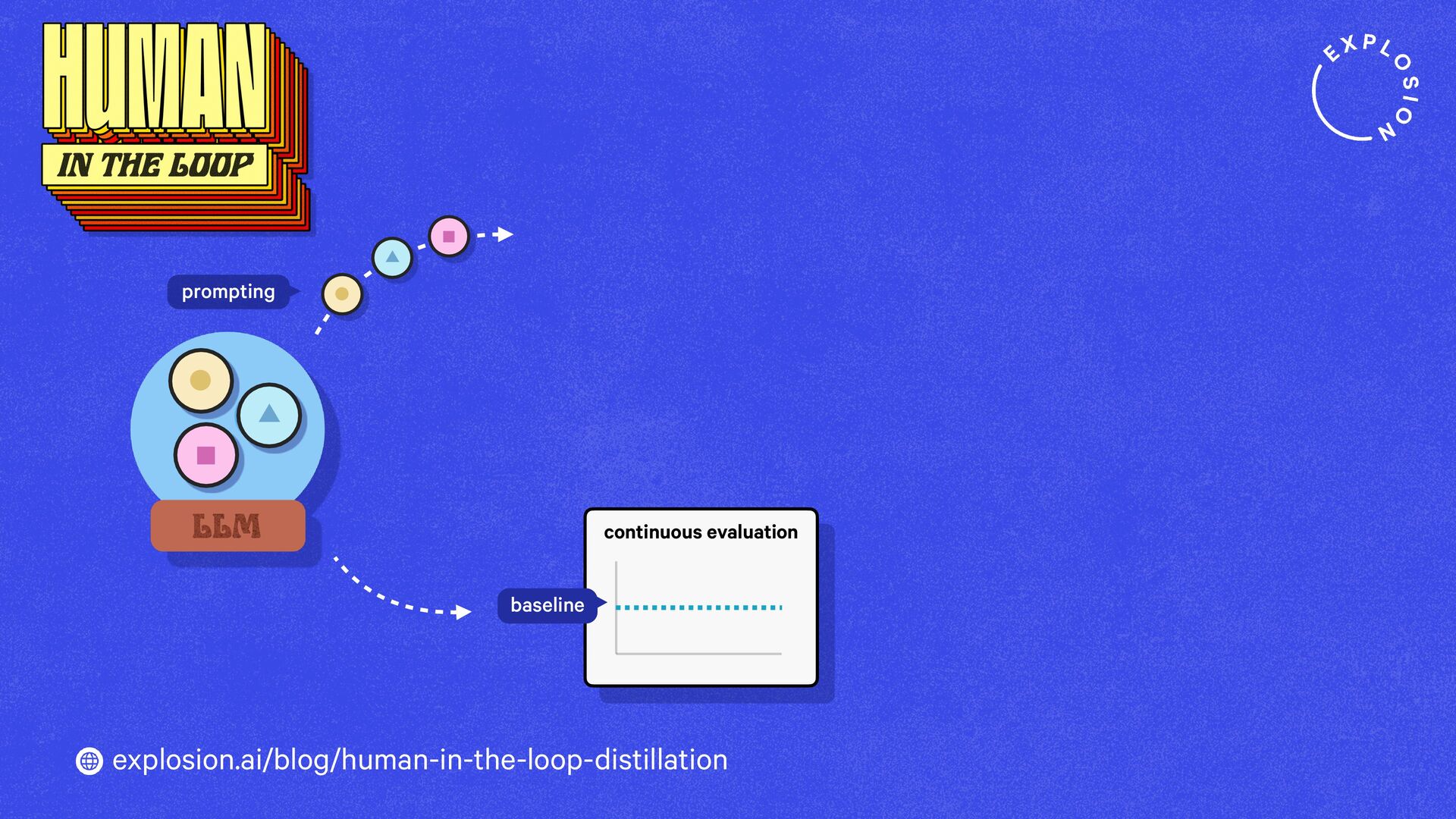
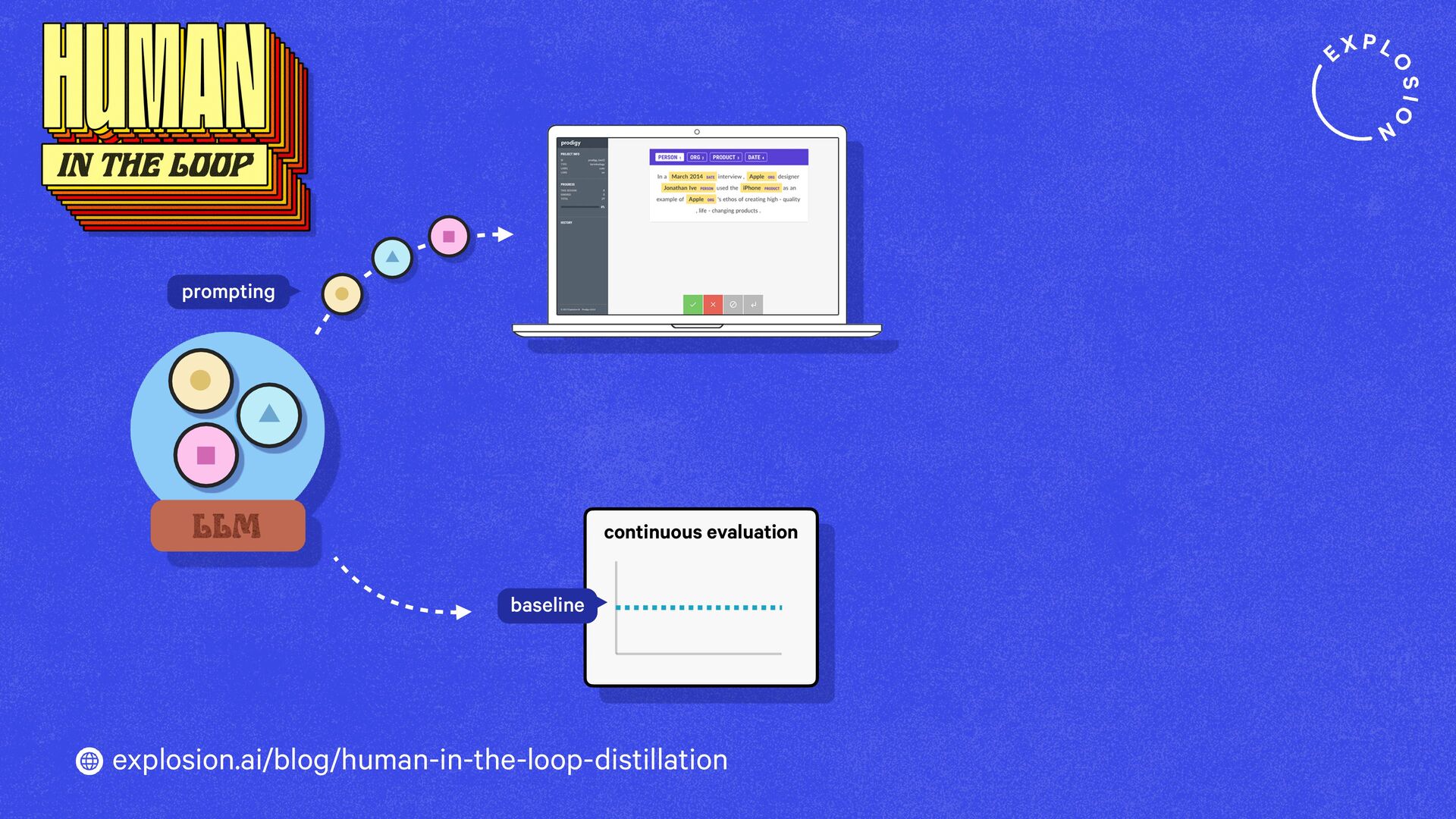
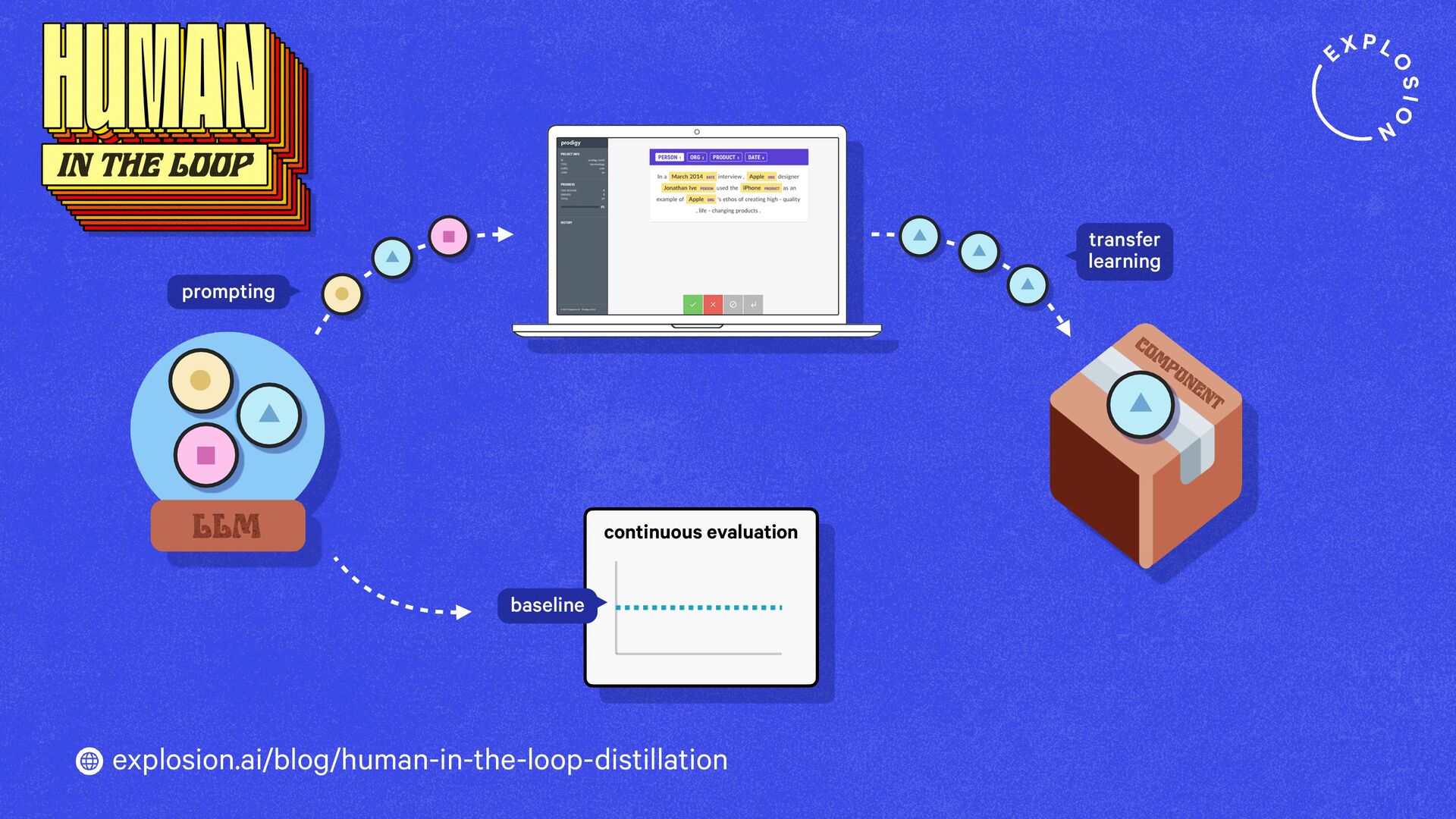
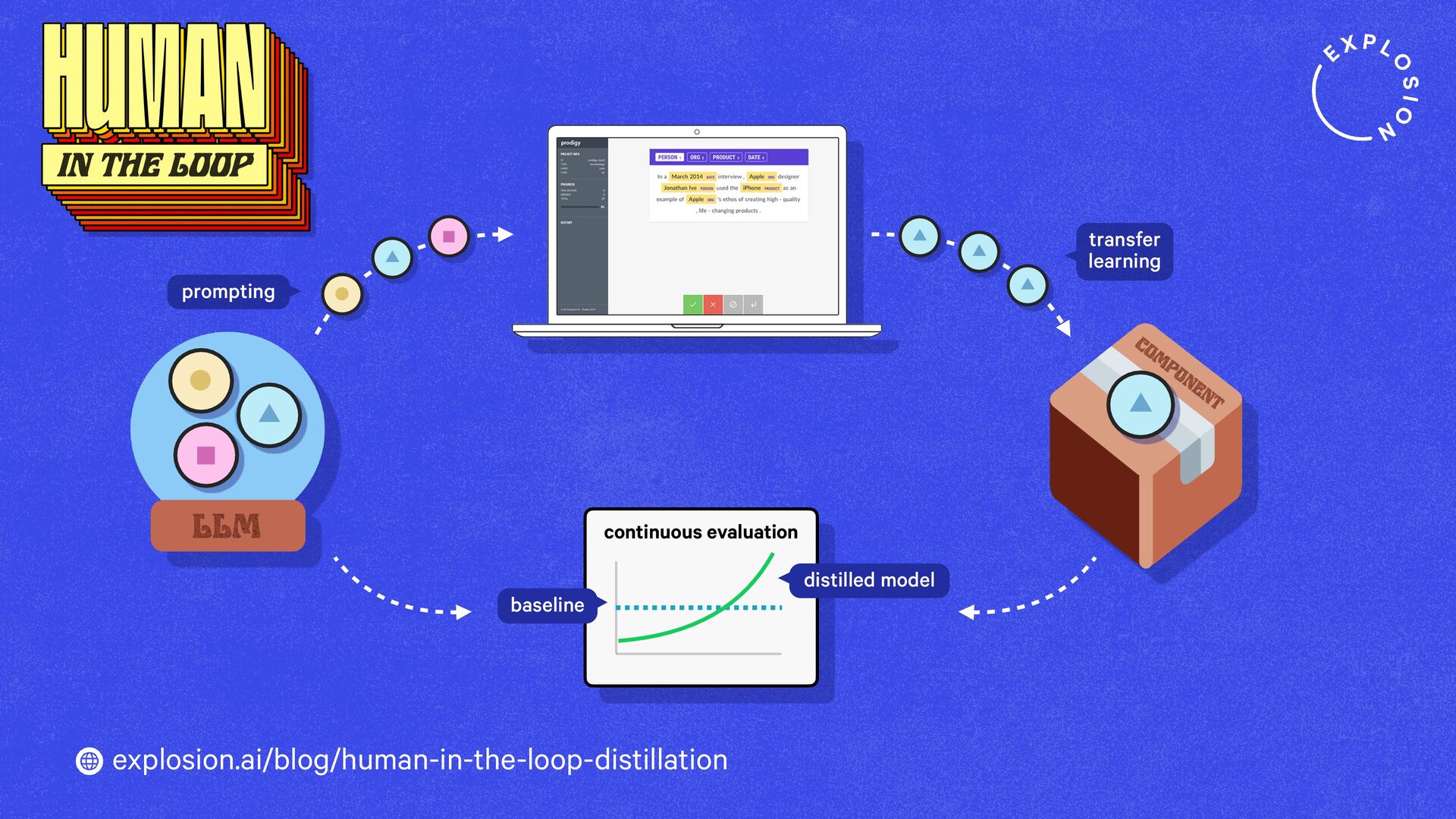
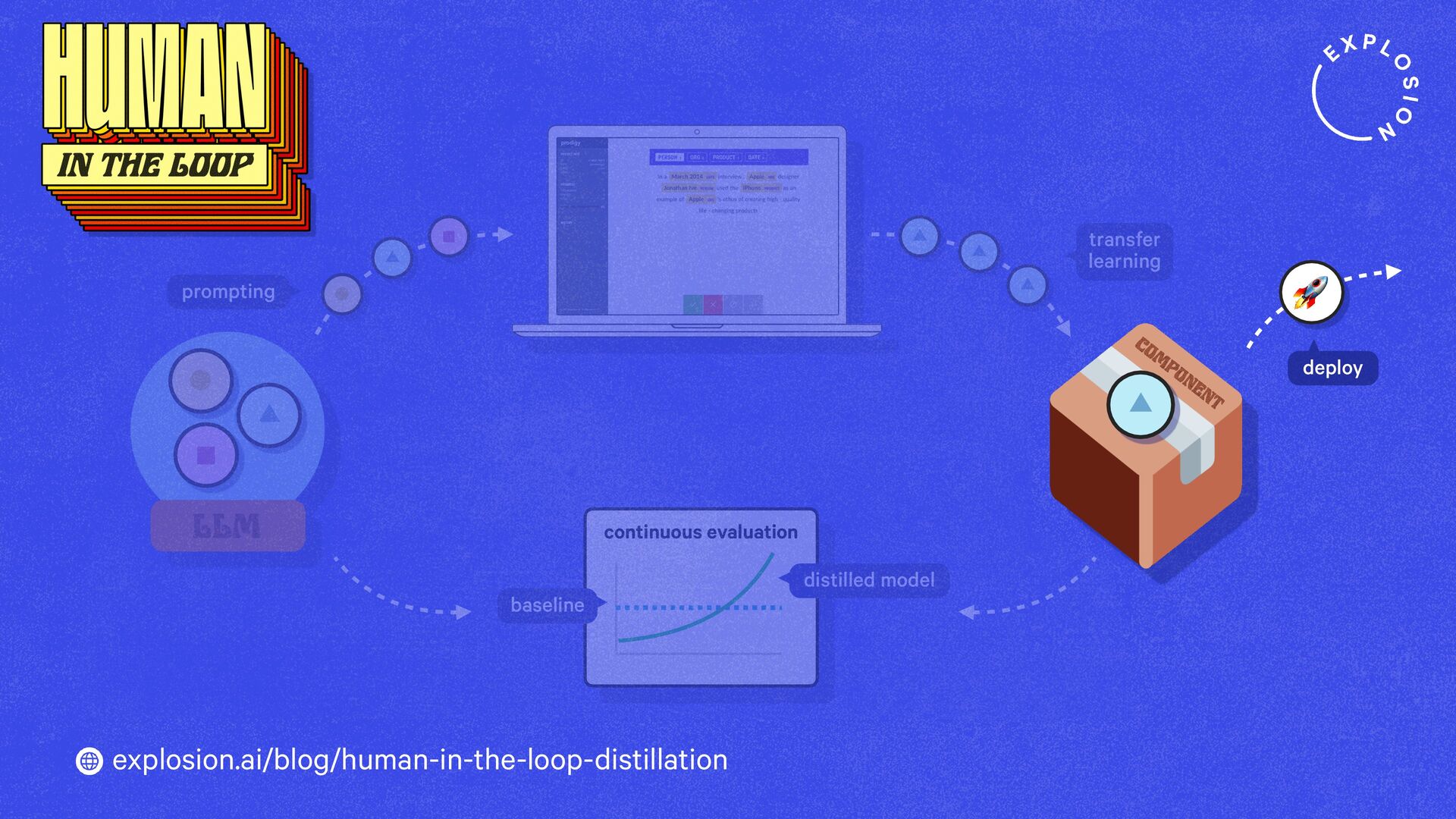
https://explosion.ai/blog/human-in-the-loop-distillation
This blog post presents practical solutions for using the latest state-of-the-art models in real-world applications and distilling their knowledge into smaller and faster components that you can run and maintain in-house.
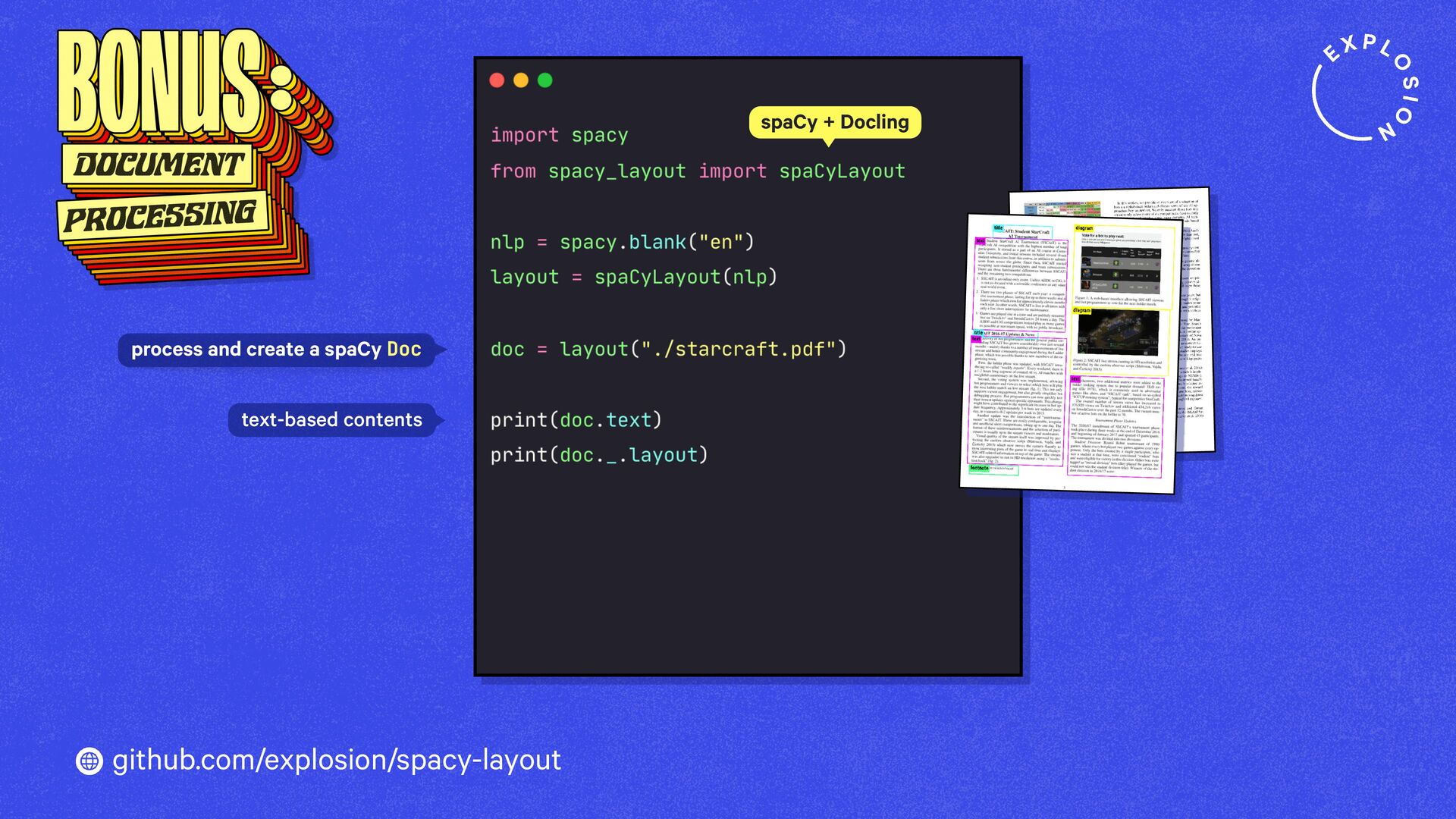
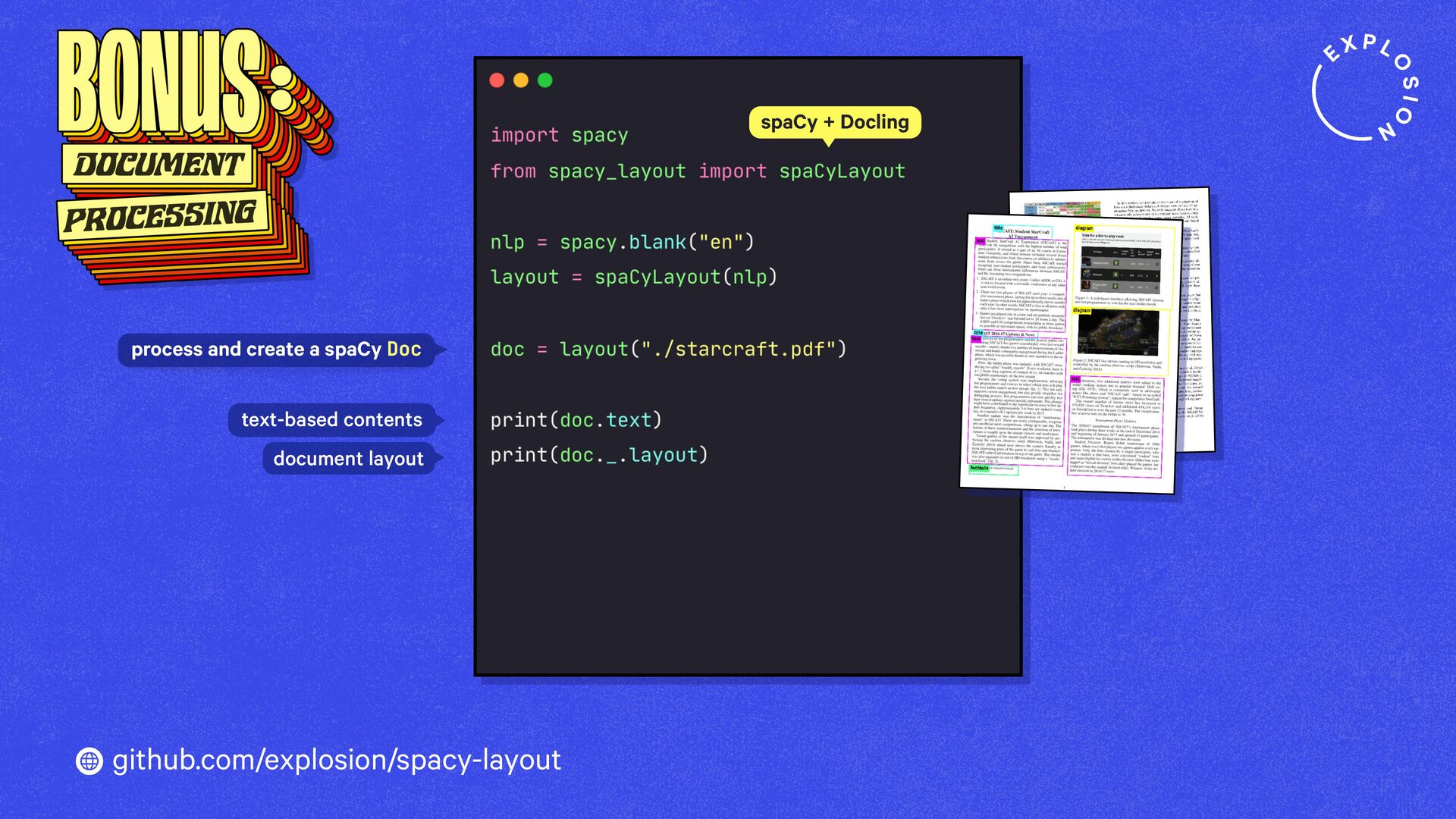
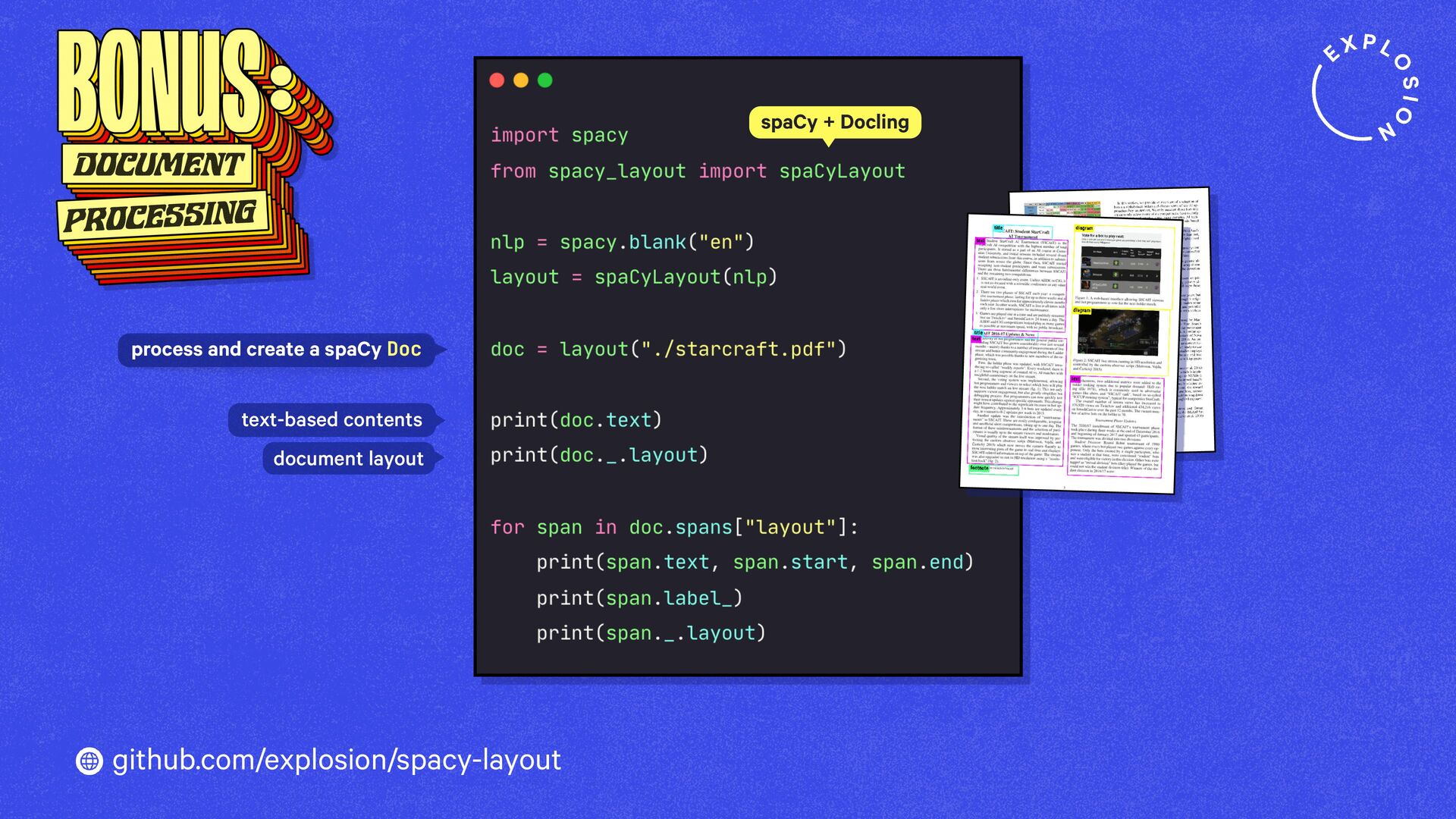
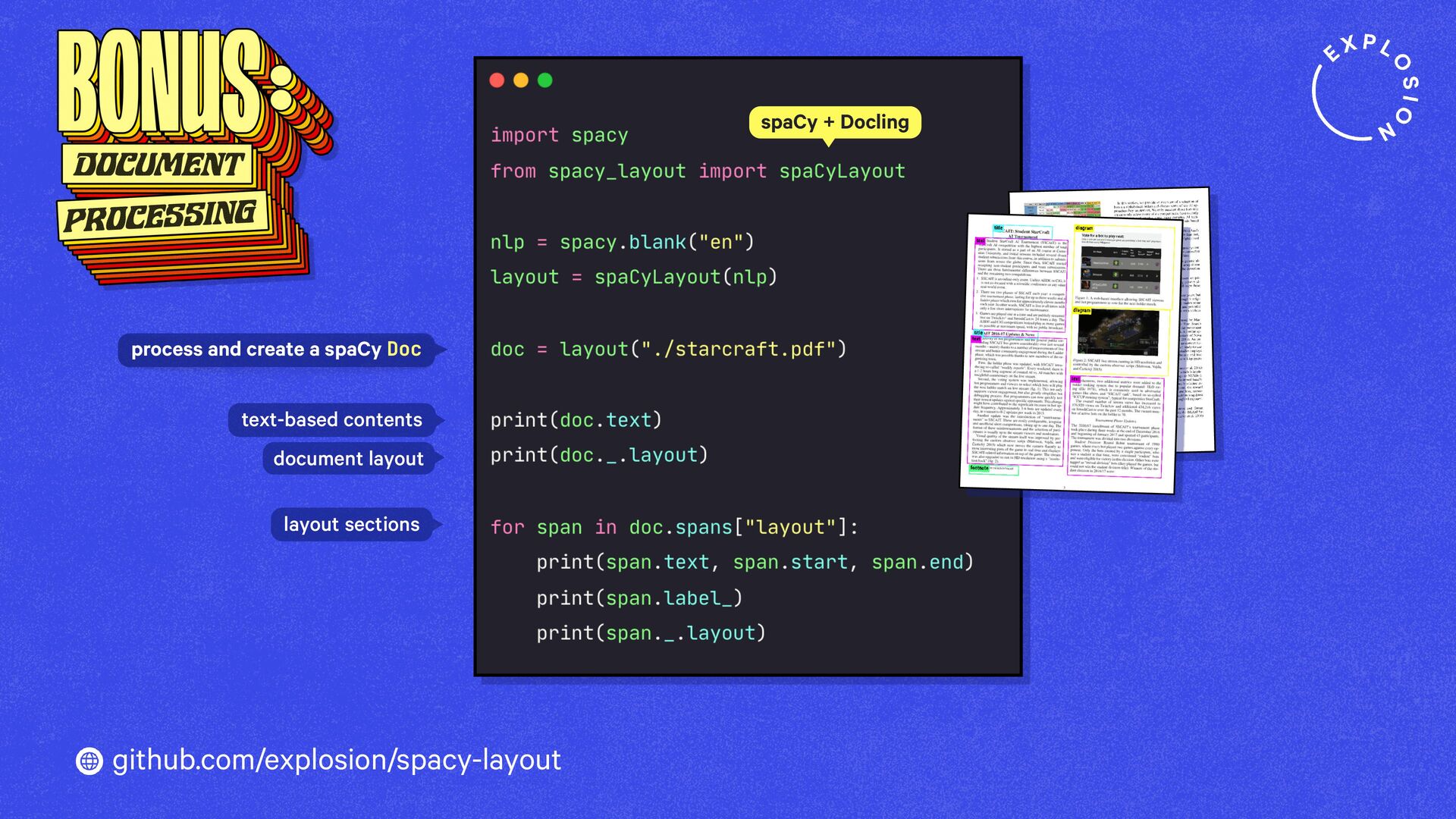
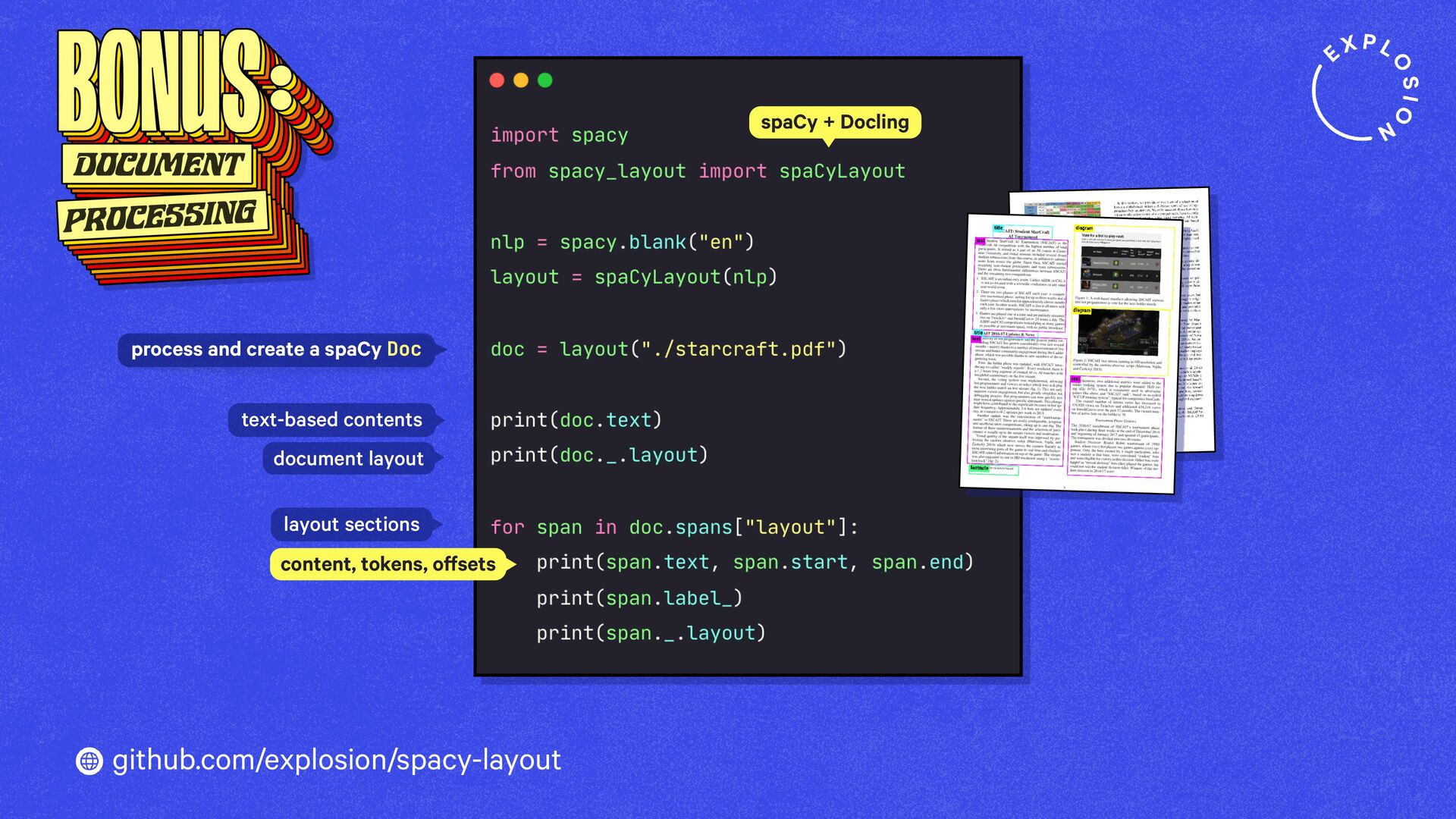
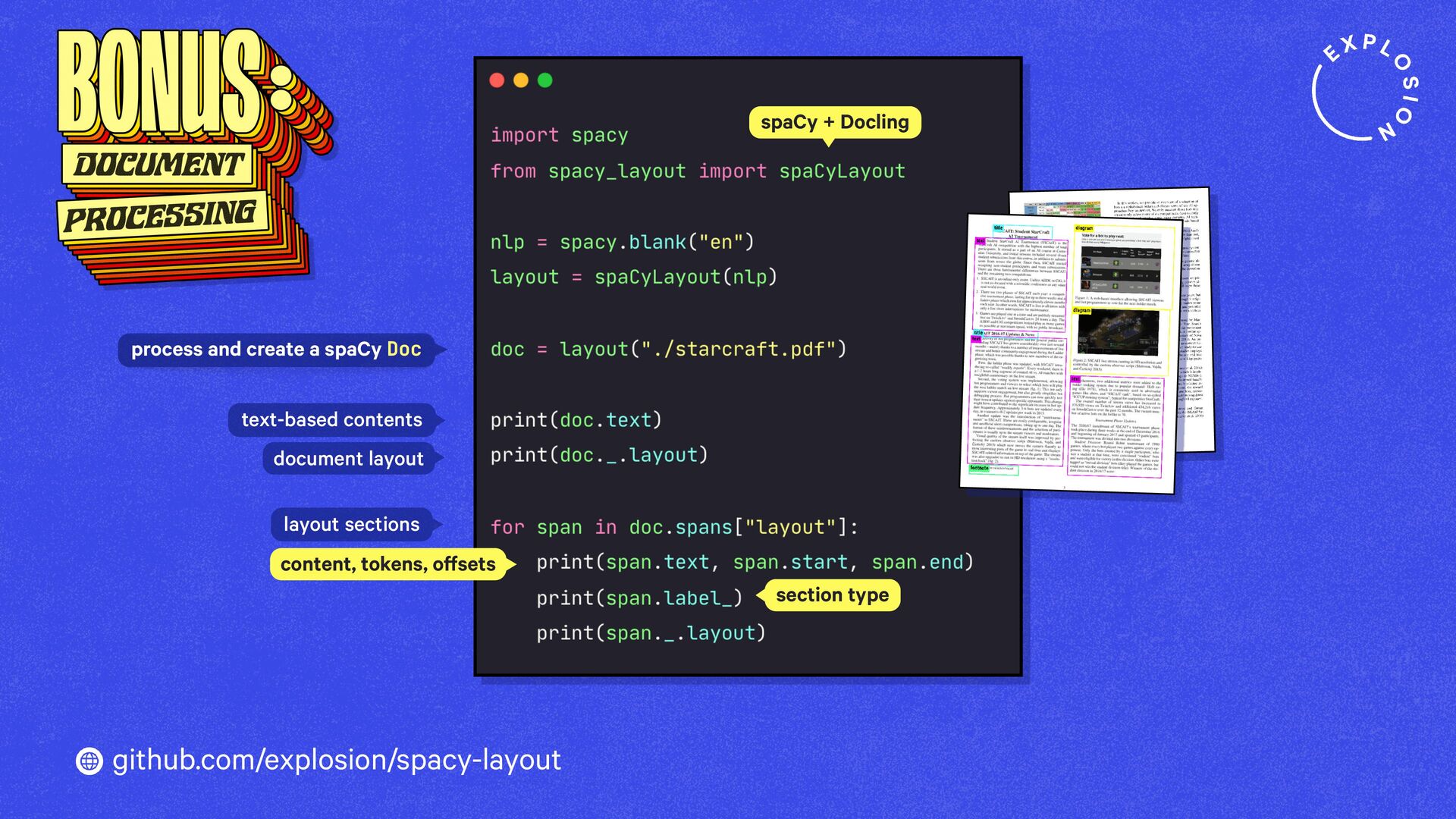
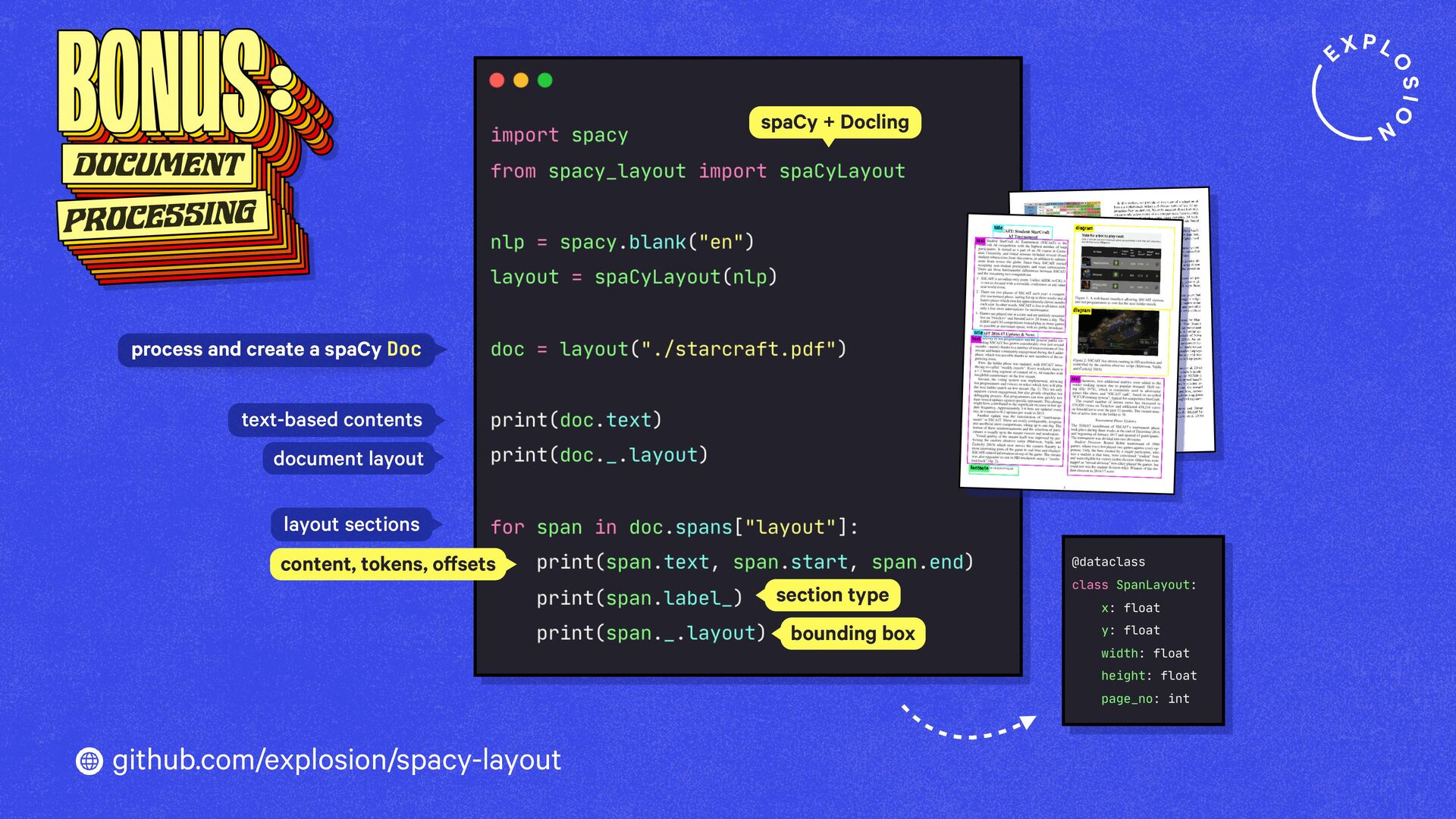
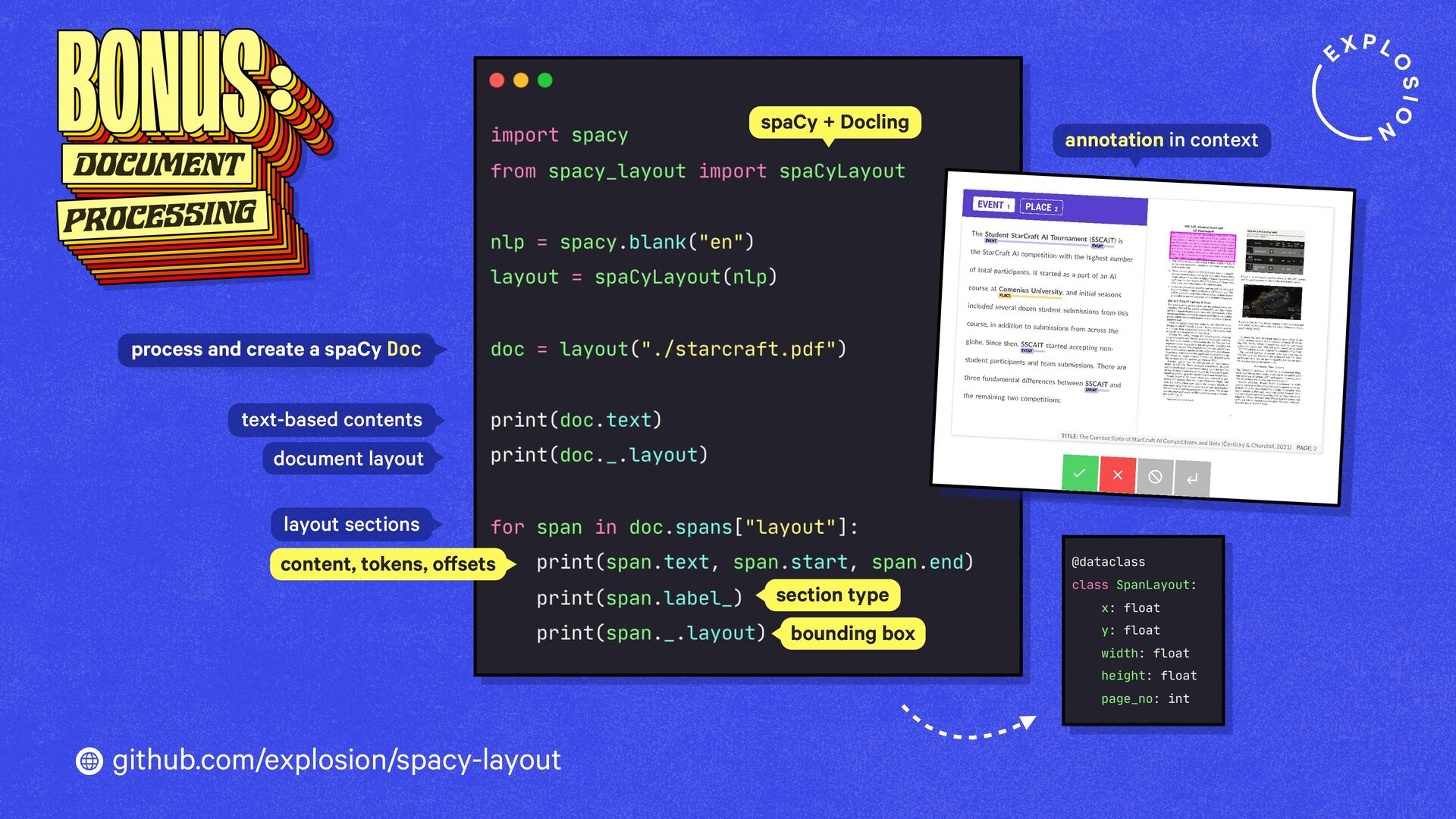
https://explosion.ai/blog/pdfs-nlp-structured-data
How to build end-to-end document understanding and information extraction pipelines for industry use cases.
https://prodi.gy/docs/large-language-models
Prodigy comes with preconfigured workflows for using LLMs to speed up and automate annotation and create datasets for distilling large generative models into more accurate, smaller, faster and fully private task-specific components.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Explosion spaCy Prodigy Bluesky Mastodon explosion.ai spacy.io prodigy.ai @inesmontani.bsky.social @[email protected]](https://files.speakerdeck.com/presentations/d3fe2f83f3d34cf2ad3543442a40d6e5/slide_93.jpg){kind=link}