Genomics as an application of HPC “Next-generation” of genomics and computing platform 3. Docker container on HPC for biology Machine readable format and sharing platform Agenda
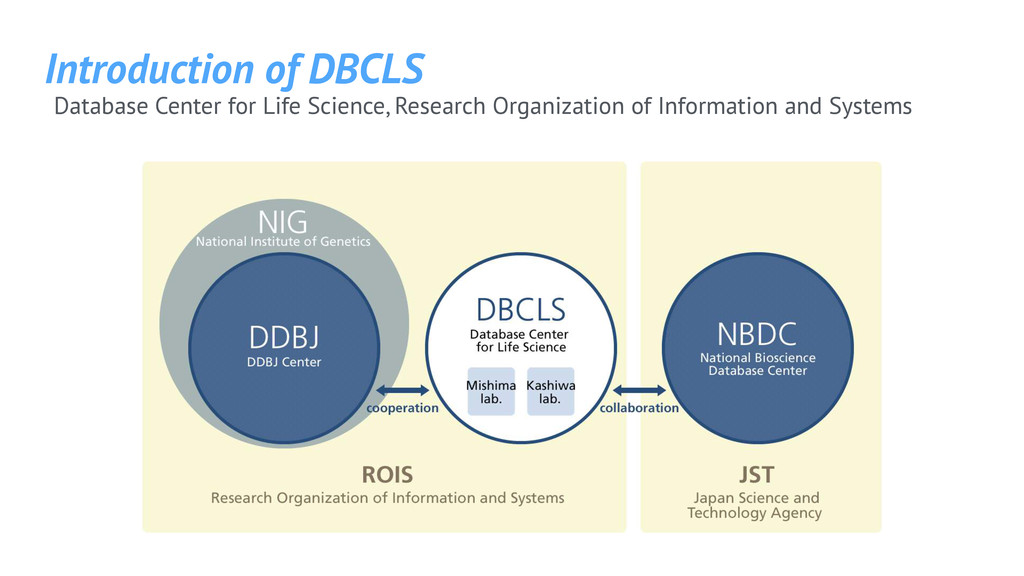
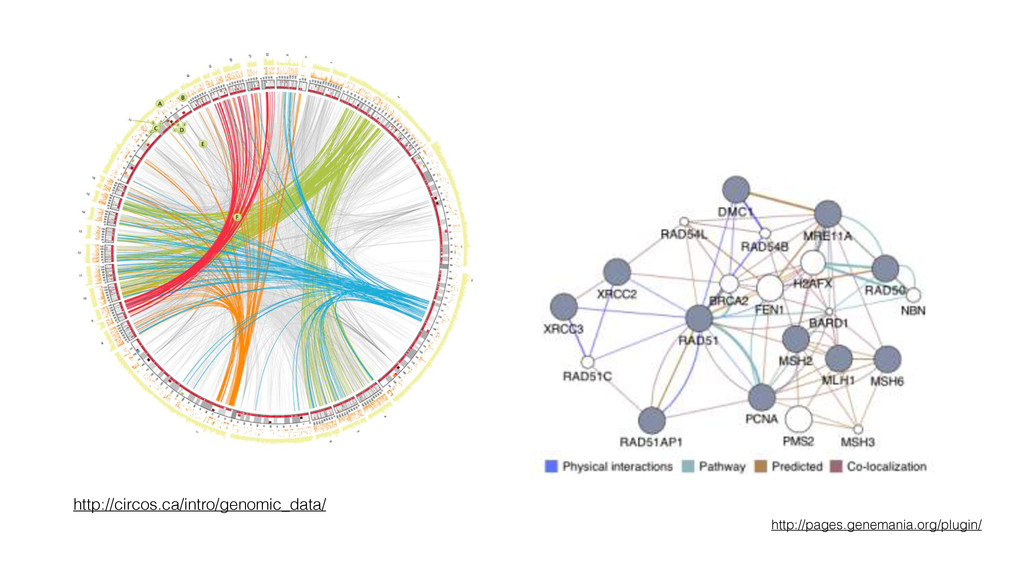
• Availability, Accessibility, and Accountability of DBs • Linked Data and Semantic Web • Data analysis platform • Text mining • Funding from NBDC • Collaboration with DDBJ Database Center for Life Science, Research Organization of Information and Systems
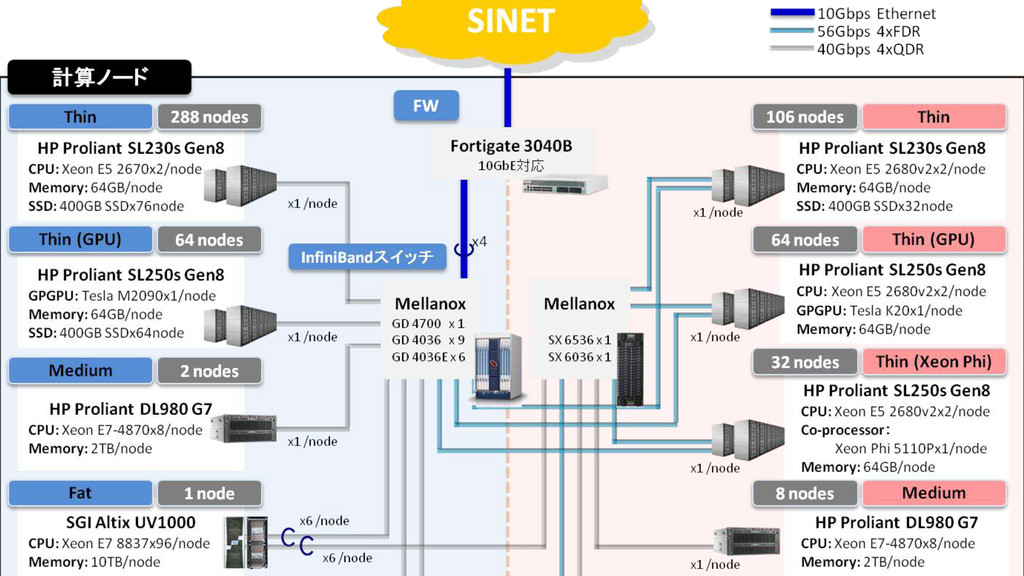
of Genetics • Collaborating with NCBI, EBI • Supercomputer system *for free* to academic users DNA Data Bank of Japan, National Institute of Genetics, Research Organization of Information and Systems
status of “next generation” 2. General research workflow How biologists use computer 3. Problems and challenges What biologists expect for “high-performance” computing platform Genomics as an application of HPC
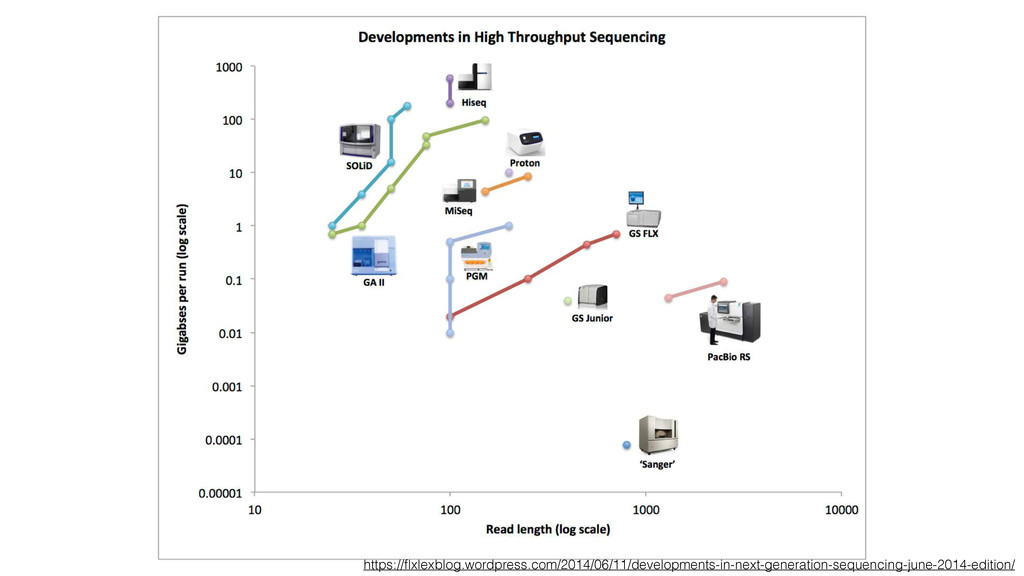
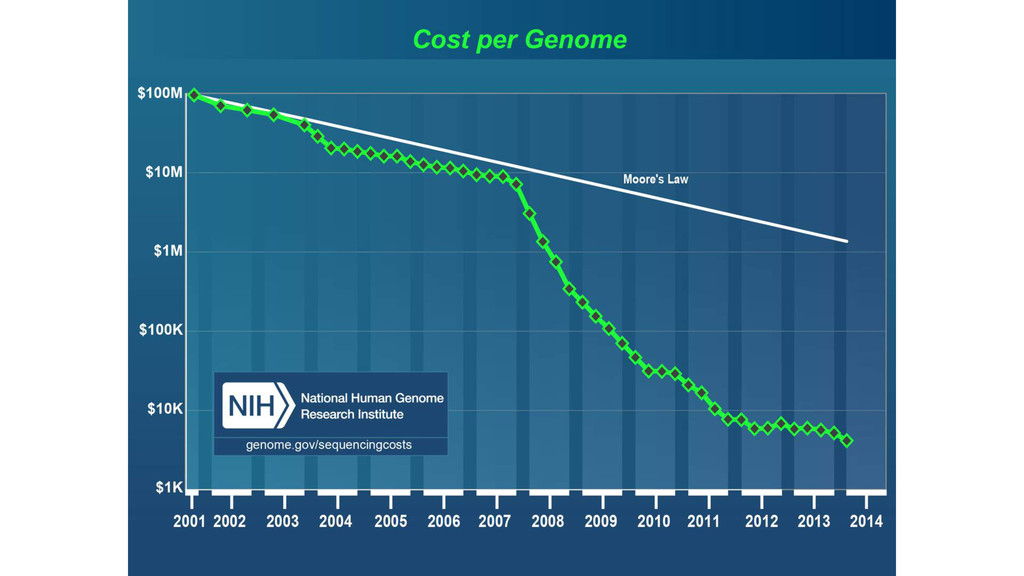
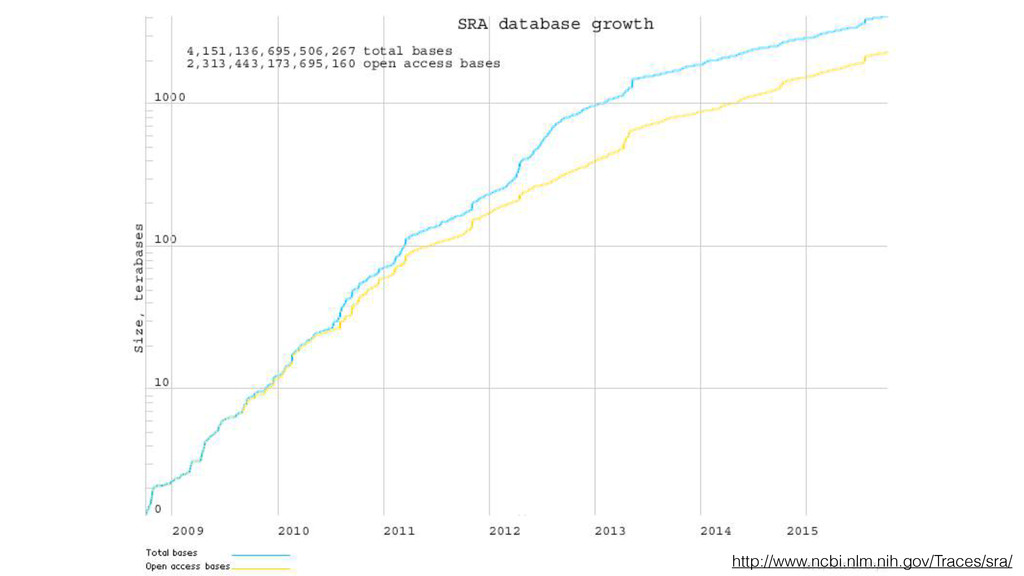
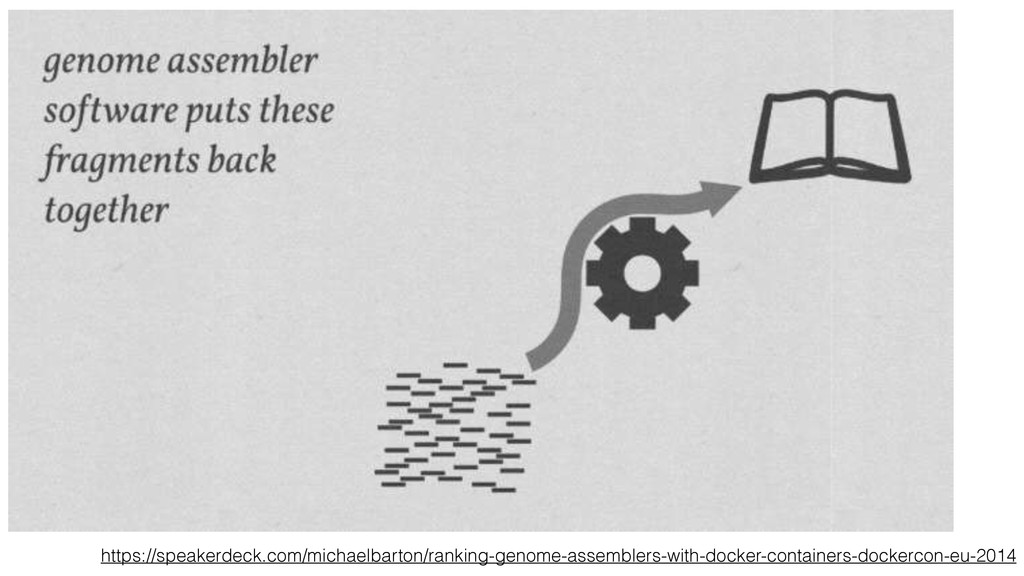
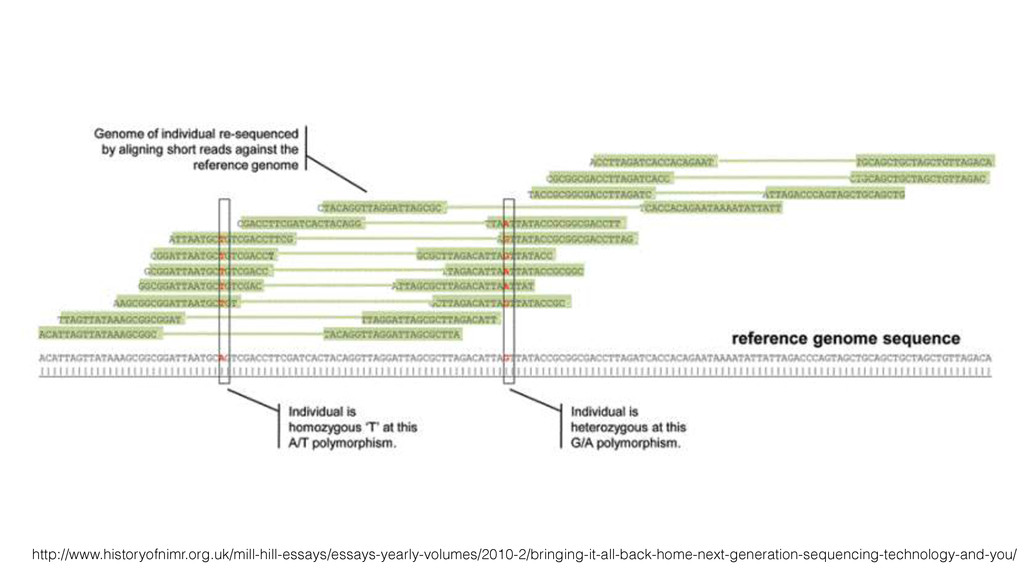
to next-generation sequencing 2. Public repository for data sharing Reference genome, 1000 genomes, Sequencing Read Archive DNA sequencing and big data for biology
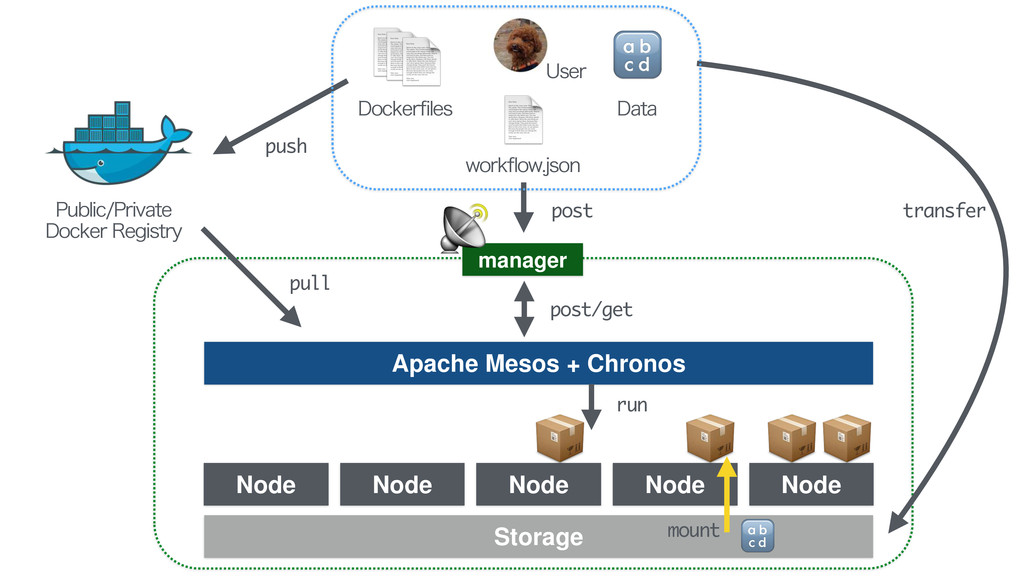
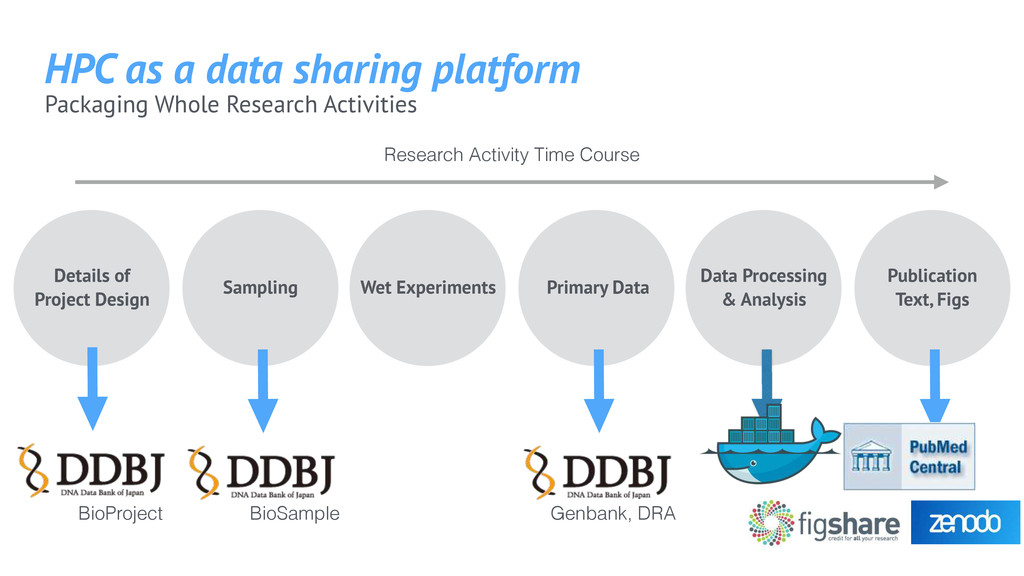
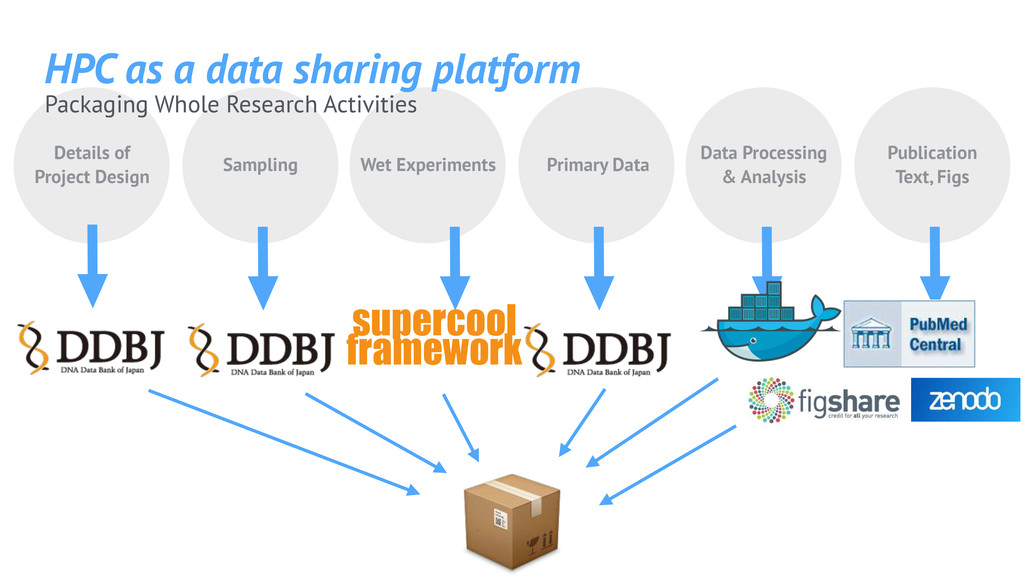
Project Design Sampling Primary Data Data Processing & Analysis Publication Text, Figs Wet Experiments BioProject BioSample Genbank, DRA HPC as a data sharing platform
process model by study plan construction client to generate process model 2. Allocate resources for each process by resource allocation client 3. <execute experiments> 4. Input data to get output Plan and Experiments model
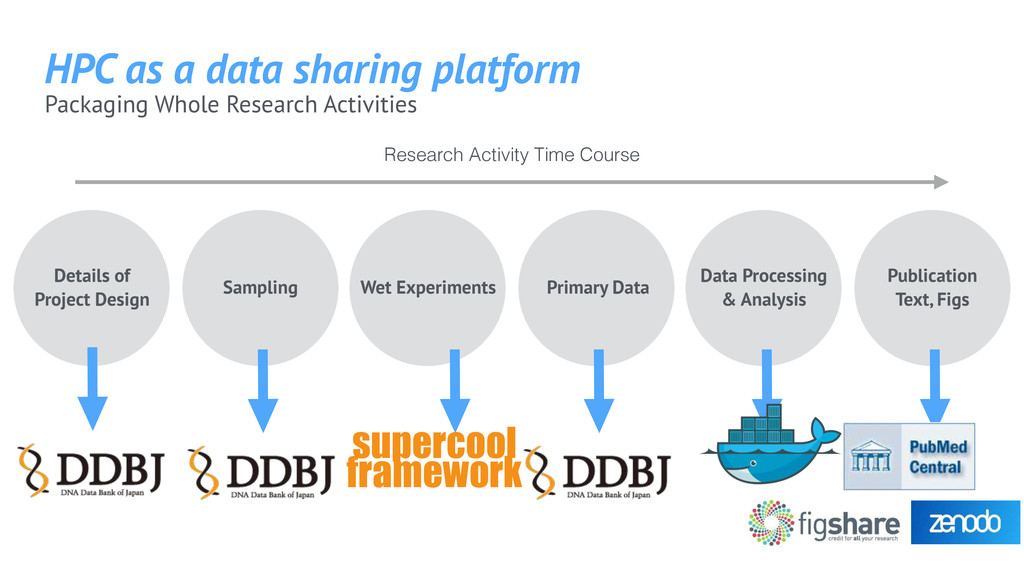
Project Design Sampling Primary Data Data Processing & Analysis Publication Text, Figs Wet Experiments supercool framework HPC as a data sharing platform
by ROIS URA Grant “༥߹γʔζ୳ࡧ” 2014. • The Institute of Statistical Mathematics • Dr. Yoshiyasu Tamura • Dr. Junji Nakano • Dr. Keisuke Honda • National Institute of Informatics • Dr. Kenjiro Yamanaka • Dr. Kento Aida • Dr. Shigetoshi Yokoyama • Dr. Yoshinobu Masatani • National Institute of Genetics • Dr. Osamu Ogasawara • Dr. Takeshi Tsurusawa • NIG SuperComputer Facilities SE team • Information and Mathematical Science and Bioinformatics Co., Ltd. • Tatsuya Nishizawa • Tokyo Institute of Technology • Dr. Shinichi Miura • Dr. Satoshi Matsuoka • Colleagues and Members of DBCLS, DDBJ, and Open-Bio • BioHackathon Hackers • Jean-Luc Perret, Alexander Garcia, and Erick Antezana for wet-lab protocols • Bruno Vieira, Jeremy Nguyen, and Evan Bolton for the fantastic help to write my abstract Acknowledgement
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}