Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
サービスの危機に立ち向かうリーダーシップ~インシデントコマンダーの役割と戦略~
Search
Kazuto Kusama
February 15, 2024
Technology
9.6k
20
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
サービスの危機に立ち向かうリーダーシップ~インシデントコマンダーの役割と戦略~
Developers Summit 2024で発表した資料です
Kazuto Kusama
February 15, 2024
More Decks by Kazuto Kusama
See All by Kazuto Kusama
趣味でイベント配信をやっている者だ
jacopen
1
24
自宅LLMの話
jacopen
2
840
プラットフォームエンジニアリングはAI時代の開発者をどう救うのか
jacopen
9
5.4k
OpenClawで回す組織運営
jacopen
3
1.2k
SREの仕事を自動化する際にやっておきたい5つのポイント
jacopen
6
1.6k
AI時代のインシデント対応 〜時代を切り抜ける、組織アーキテクチャ〜
jacopen
4
410
AI時代の開発とPlatform Engineeringについて考える
jacopen
0
260
AI によってシステム障害が増える!? ~AI エージェント時代だからこそ必要な、インシデントとの向き合い方~
jacopen
4
420
インシデント対応に必要となるAIの利用パターンとPagerDutyの関係
jacopen
0
450
Other Decks in Technology
See All in Technology
Claude Code 珍プレー好プレー
shinyasaita
0
320
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
490
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
230
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
SRE Next 2026 何でも屋からの脱却
bto
0
620
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
2
270
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
210
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
170
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
0
150
Featured
See All Featured
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Bash Introduction
62gerente
615
220k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
BBQ
matthewcrist
89
10k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Agile that works and the tools we love
rasmusluckow
331
22k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Transcript
サービスの危機に立ち向かうリー ダーシップ ~インシデントコマンダーの役割と戦略~ PagerDuty Kazuto Kusama @jacopen
Kazuto Kusama @jacopen Product Evangelist @PagerDuty Japan Organizer @Platform Engineering
Meetup Founder @Cloud Native Innovators Association
みなさん ってご存じでしたか?
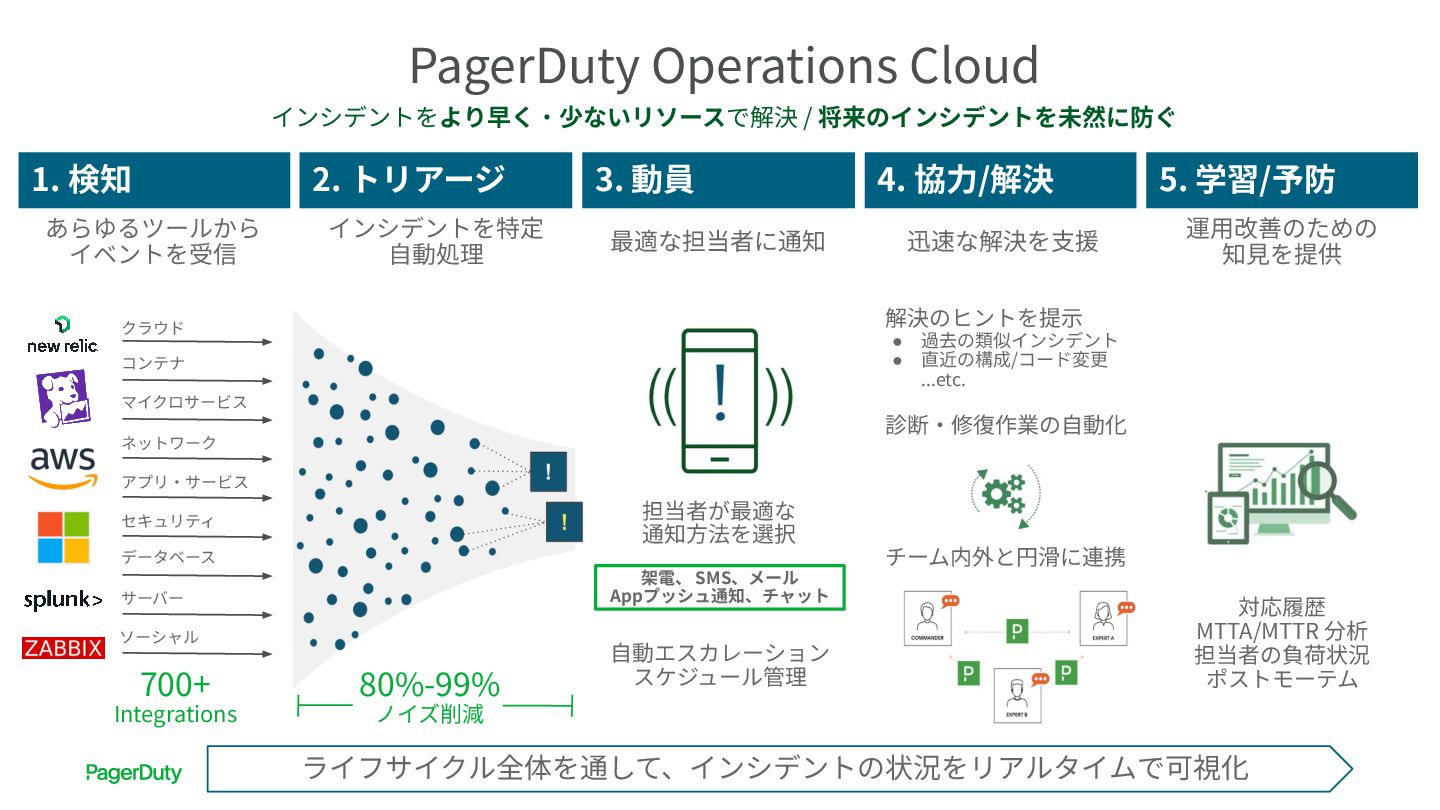
1. 検知 2. トリアージ 3. 動員 4. 協⼒/解決 5. 学習/予防
ライフサイクル全体を通して、インシデントの状況をリアルタイムで可視化 インシデントを特定 ⾃動処理 運⽤改善のための 知⾒を提供 最適な担当者に通知 迅速な解決を⽀援 あらゆるツールから イベントを受信 架電、 SMS、メール Appプッシュ通知、チャット ⾃動エスカレーション スケジュール管理 診断‧修復作業の⾃動化 チーム内外と円滑に連携 クラウド コンテナ マイクロサービス ネットワーク アプリ‧サービス セキュリティ データベース サーバー ソーシャル PagerDuty Operations Cloud インシデントをより早く‧少ないリソースで解決 / 将来のインシデントを未然に防ぐ 担当者が最適な 通知⽅法を選択 対応履歴 MTTA/MTTR 分析 担当者の負荷状況 ポストモーテム 解決のヒントを提⽰ • 過去の類似インシデント • 直近の構成/コード変更 ...etc. 80%-99% ノイズ削減 700+ Integrations
今日覚えて帰ってほしいこと① インシデント対応には
今日覚えて帰ってほしいこと② これからは インシデントコマンダーの時代
突然ですが 皆さんはエンジニアとして どうやって育ちましたか?
自分は 障害対応で育ちました!
これまで何をやってきたか • 某会計システムの会社でカスタマーエンジニア • スタートアップ企業で何でも屋・ひとり情シス • 某通信事業者でPaaSの開発・運用 リードエンジニア • Pivotal
/ VMwareでプロフェッショナルサービス • HashiCorpでプリセールスエンジニア • PagerDutyでプロダクトエバンジェリスト (Now)
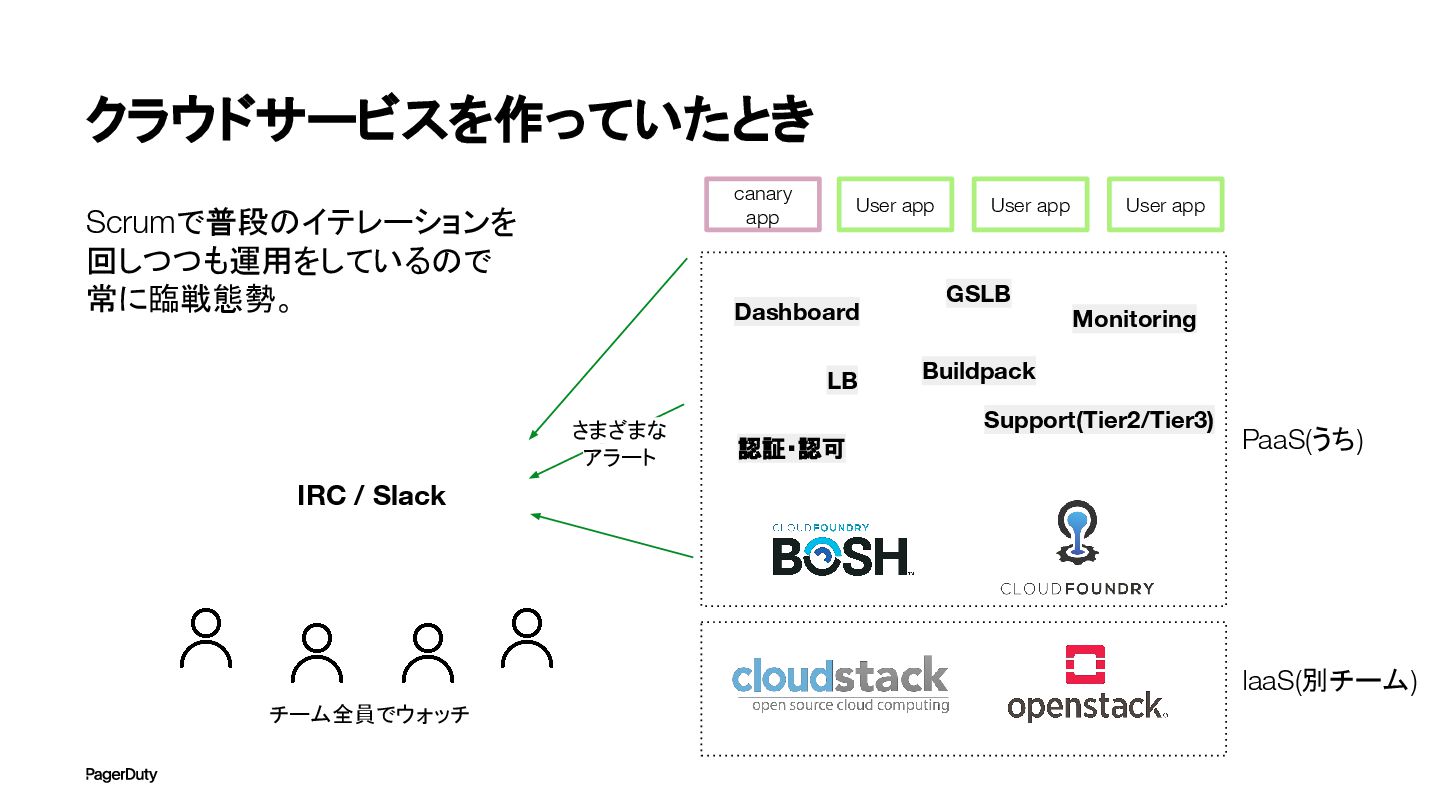
クラウドサービスを作っていたとき Cloud Foundryを活用したPaaSの開発。コ アの構築および周辺機能の開発。 IaaSは社内の別部隊が運用。 その上にPaaSをデプロイする形。 そのPaaSの上にユーザーのアプリが デプロイされる。 機能の開発だけでなく運用も全て担当 IaaS(別チーム)
PaaS(うち) 認証・認可 LB GSLB Monitoring Dashboard Buildpack Support(Tier2/Tier3) canary app User app User app User app
クラウドサービスを作っていたとき Scrumで普段のイテレーションを 回しつつも運用をしているので 常に臨戦態勢。 IaaS(別チーム) PaaS(うち) 認証・認可 LB GSLB Monitoring
Dashboard Buildpack Support(Tier2/Tier3) User app User app User app canary app IRC / Slack チーム全員でウォッチ さまざまな アラート
24時間体制 深夜であっても休日であっても1チームで運用して いた。 会社としてNOCはあったが、複雑な アーキテクチャを理解してもらうことは 出来ず、10分後に電話かけるくらいしかしてもらえ なかった。 どのチームよりも洗練された運用体制を 作ったため、どのチームよりも早くインフラの障害 に気づくという状態になった
当時出たばかりの Philips Hueでアラートが起 きると家中の照明をパカパカさせてた NOCにこれを理解して貰うの無理 ※注 これはNOCを責めているわけじゃなく て、複雑なものの運用だけを他のチームに 押しつけるってのは無理だよねと。オー ナーシップは作った人が持つべきだと個人 的には思います
障害発生!
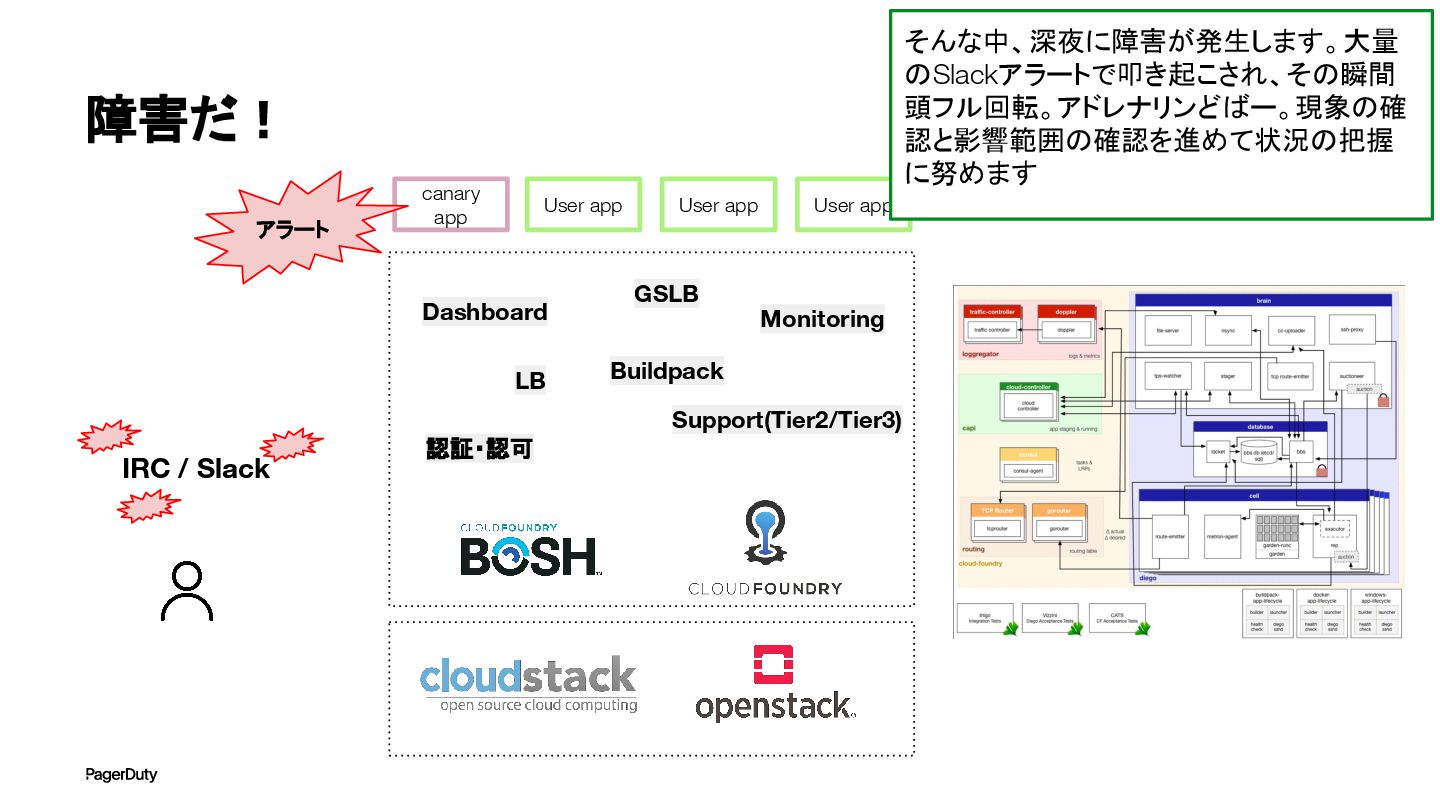
障害だ! 認証・認可 LB GSLB Monitoring Dashboard Buildpack Support(Tier2/Tier3) User app
User app User app canary app アラート IRC / Slack そんな中、深夜に障害が発生します。大量 のSlackアラートで叩き起こされ、その瞬間 頭フル回転。アドレナリンどばー。現象の確 認と影響範囲の確認を進めて状況の把握 に努めます
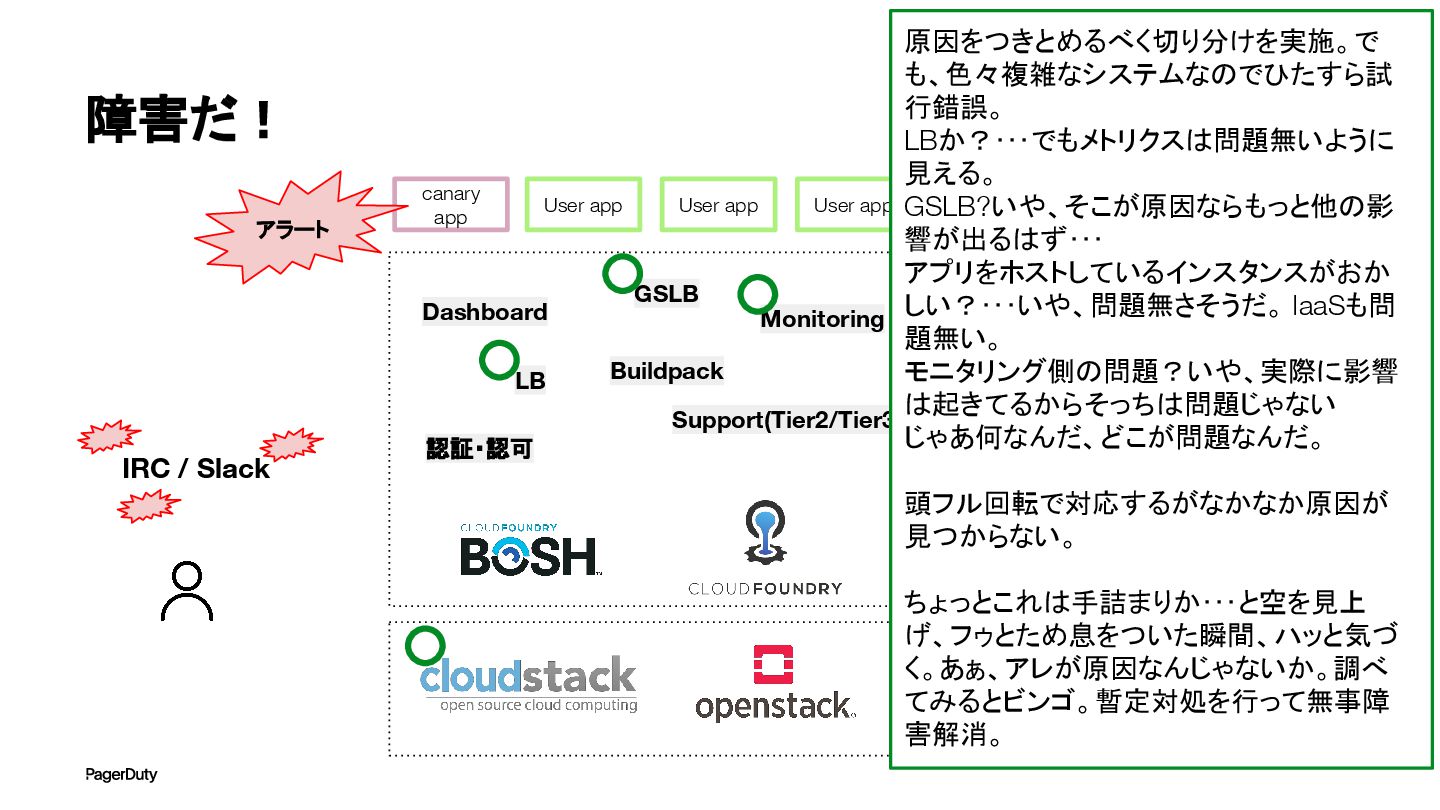
障害だ! 認証・認可 LB GSLB Monitoring Dashboard Buildpack Support(Tier2/Tier3) User app
User app User app canary app アラート IRC / Slack 原因をつきとめるべく切り分けを実施。で も、色々複雑なシステムなのでひたすら試 行錯誤。 LBか?・・・でもメトリクスは問題無いように 見える。 GSLB?いや、そこが原因ならもっと他の影 響が出るはず・・・ アプリをホストしているインスタンスがおか しい?・・・いや、問題無さそうだ。 IaaSも問 題無い。 モニタリング側の問題?いや、実際に影響 は起きてるからそっちは問題じゃない じゃあ何なんだ、どこが問題なんだ。 頭フル回転で対応するがなかなか原因が 見つからない。 ちょっとこれは手詰まりか・・・と空を見上 げ、フゥとため息をついた瞬間、ハッと気づ く。あぁ、アレが原因なんじゃないか。調べ てみるとビンゴ。暫定対処を行って無事障 害解消。
解決!
本当にこれで良かったのか? 🤔
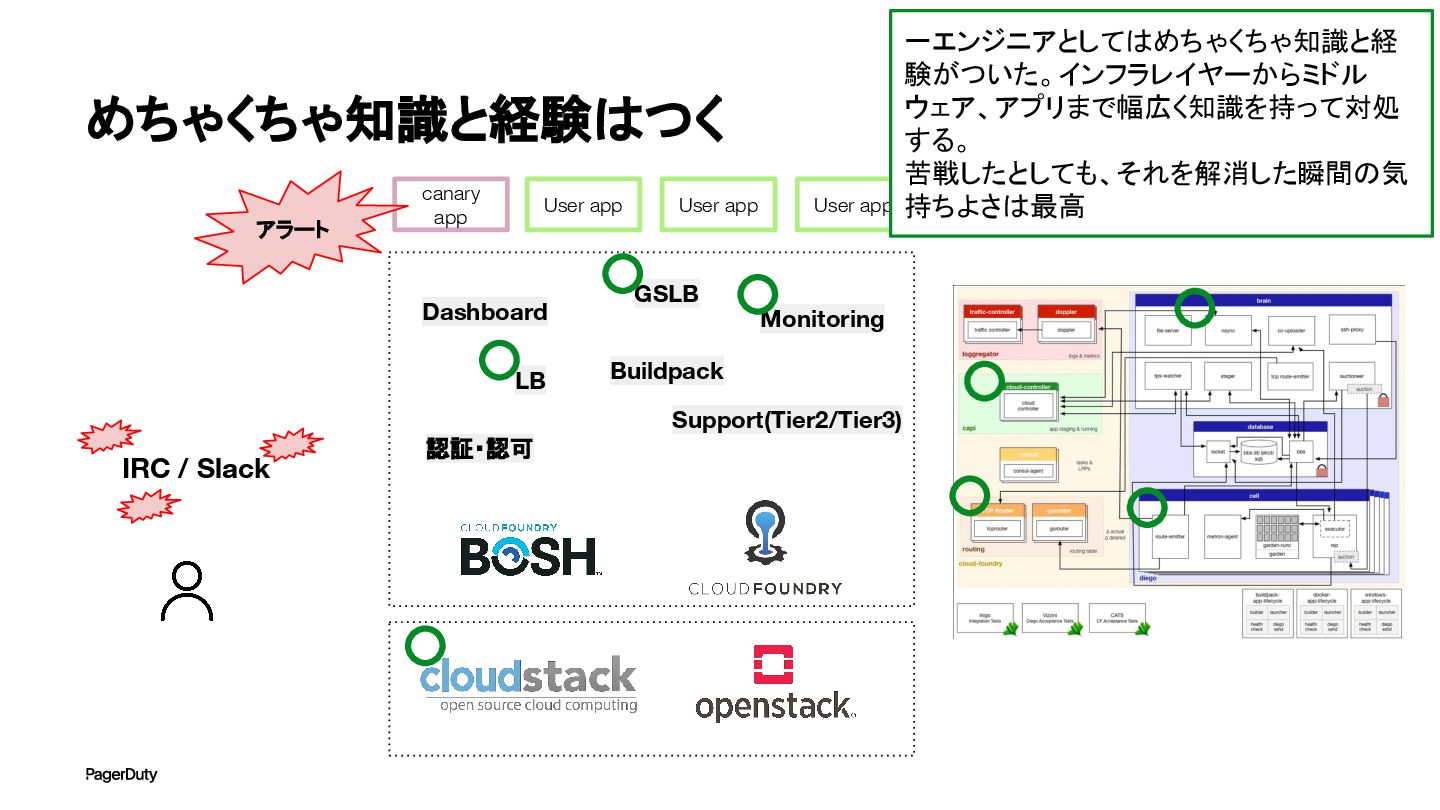
めちゃくちゃ知識と経験はつく 認証・認可 LB GSLB Monitoring Dashboard Buildpack Support(Tier2/Tier3) User app
User app User app canary app アラート IRC / Slack 一エンジニアとしてはめちゃくちゃ知識と経 験がついた。インフラレイヤーからミドル ウェア、アプリまで幅広く知識を持って対処 する。 苦戦したとしても、それを解消した瞬間の気 持ちよさは最高
何もいい話じゃない 認証・認可 LB GSLB Monitoring Dashboard Buildpack Support(Tier2/Tier3) User app
User app User app canary app IRC / Slack • 体制を組んで取り組めばもっと早く解消したのでは? • 思い込みで明後日の方向を切り分けてしまった可能性は? • もし全員が起きなかったらどうなった? • 眠たい頭でミスオペして二次災害が起こる可能性があったのでは? • このノウハウは組織に受け継がれたか? 自分が抜けた後にも役に立つ内容となったか? 様々な組織で同じことが起きている ただ、個人としてではなく組織として見た場 合はどうだろうか。
今日の講演の目的 インシデント対応を進化させて、 世の中に少しでも貢献したい その中で、PagerDutyが 貢献出来るところを紹介したい
おや? • 主語が変わってる? • 障害対応→インシデント対応
言葉の整理 • インシデント→「何らかの原因でユーザーがサービスを正常に利用できない状態」 • システム障害 • ネットワークトラブル • 人的ミス •
等々 • インシデントは「状態」 • システム障害はインシデントを起こしうる原因のひとつ • インシデントに対応することが重要 (Incident Response) • 障害を完全に解消しないこともありうる
なぜインシデント対応が重要なのか • 世の中におけるサービスの重要性が高まった • APIで連携し合うのはごく普通になってきた。 1つのインシデントがさまざまな場所に波及する 確率も高まってきた • 構成要素の複雑化、障害対応の難化 •
クラウド、オンプレなどさまざまな選択肢 • コンテナをはじめとしたクラウドネイティブ技術 • マイクロサービス化の流れ • コミュニケーション要素の増大 • 上記の要素により組織が拡大し、コミュニケーションパスが複雑化
体系的な取り組みが必要不可欠に • 一人(ないしは少数)が単騎で動くことの危うさ • システムの複雑化にともなう対応の長期化 • 暗黙知 • 二次災害の危険性 •
恒久対応や再発防止策が後回しに • 組織として対応能力を高めていかないといけない • 体系だった指揮系統 • 組織としてのノウハウの継承 • サステナブルな組織作り
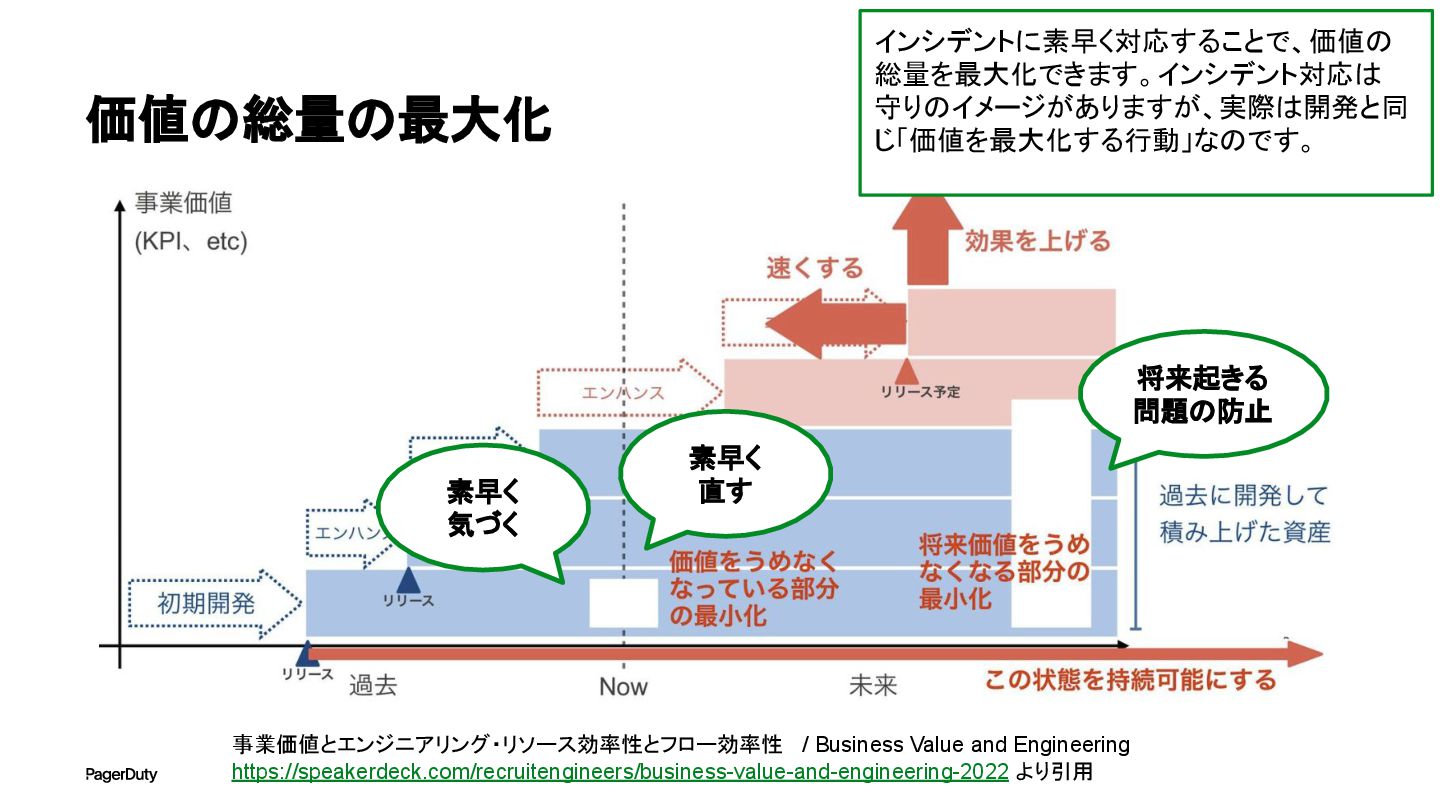
価値の総量の最大化 事業価値とエンジニアリング・リソース効率性とフロー効率性 / Business Value and Engineering https://speakerdeck.com/recruitengineers/business-value-and-engineering-2022 より引用 リクルートさんが出している資料からの引用で
す。グラフの面積が生み出した価値の総量と すると、インシデント中の価値はぽっかりと空 いてしまうといえます。
価値の総量の最大化 事業価値とエンジニアリング・リソース効率性とフロー効率性 / Business Value and Engineering https://speakerdeck.com/recruitengineers/business-value-and-engineering-2022 より引用 素早く
気づく 素早く 直す 将来起きる 問題の防止 インシデントに素早く対応することで、価値の 総量を最大化できます。インシデント対応は 守りのイメージがありますが、実際は開発と同 じ「価値を最大化する行動」なのです。
ヒーローを目指してはいけない 正義の味方 悪の組織 自分自身の具体的な目標がない 大きな夢、野望を抱いている 相手の夢を阻止するのが生き甲斐 目標達成のための研究開発を怠らない 常に何かが起こってから行動 日々努力を重ね、夢に向かって手を尽くして いる
受け身の姿勢 失敗してもへこたれない 単独〜少人数での行動 組織で行動 いつも怒っている よく笑う 場当たり的なインシデント対応は「正義の味方」的な行動です。解決したときの気 持ちよさもまさにヒーロー。ですが、目指す先はそこではありません。悪の組織に なるべきとは言いませんが、あるべき心持ちは右側です
インシデントコマンダー そこで重要になってくるのが、インシデントコマ ンダーです。
インシデントコマンダーのもと、体系的な対応をする インシデントコマンダーは、インシデント対応の指揮者。 重大インシデントを解決に導くことを目的とし、意思決定を行う。 日々の地位に関係なく、重大インシデントでは最も位の高い人 インシデントコマンダー 作業担当
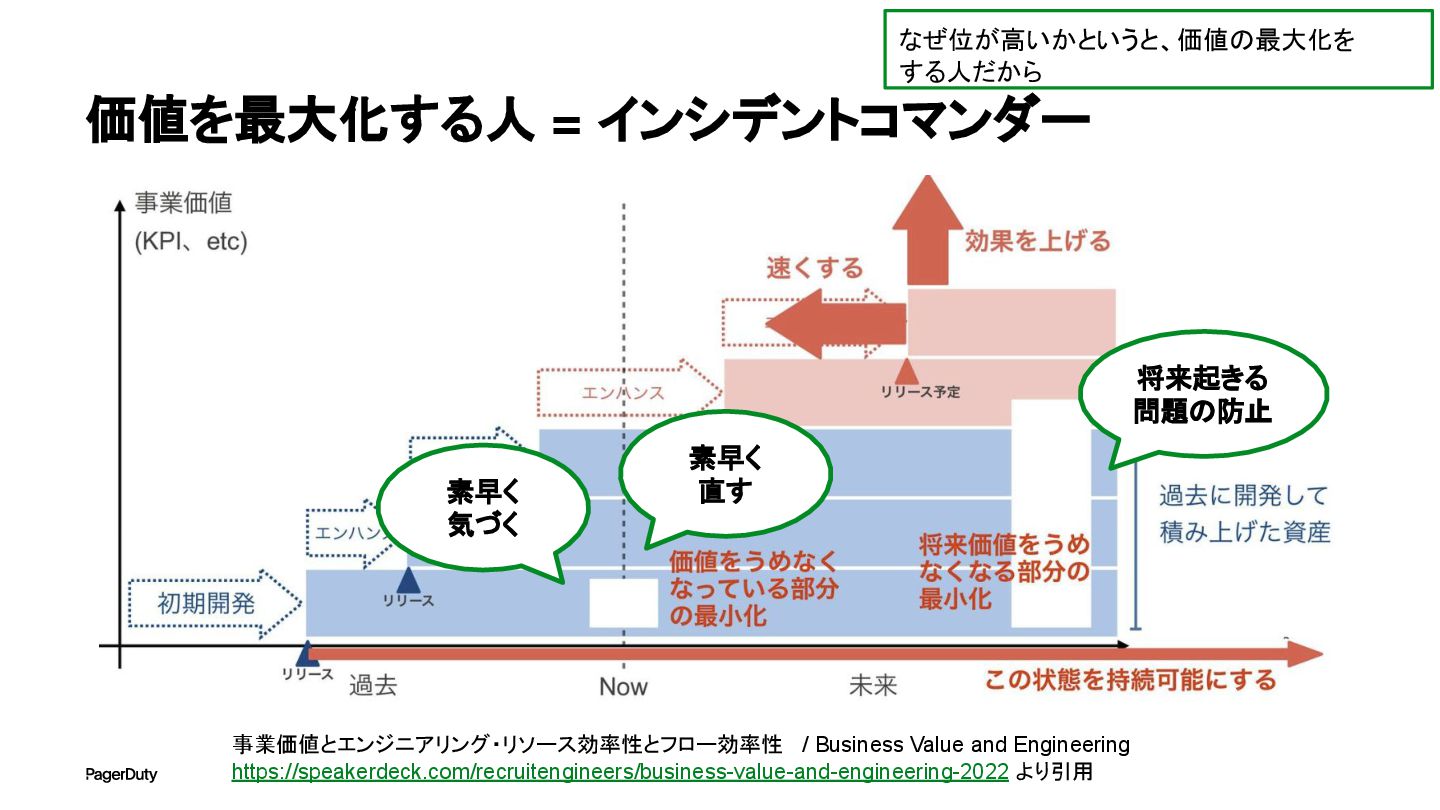
価値を最大化する人 = インシデントコマンダー 事業価値とエンジニアリング・リソース効率性とフロー効率性 / Business Value and Engineering https://speakerdeck.com/recruitengineers/business-value-and-engineering-2022
より引用 素早く 気づく 素早く 直す 将来起きる 問題の防止 なぜ位が高いかというと、価値の最大化を する人だから
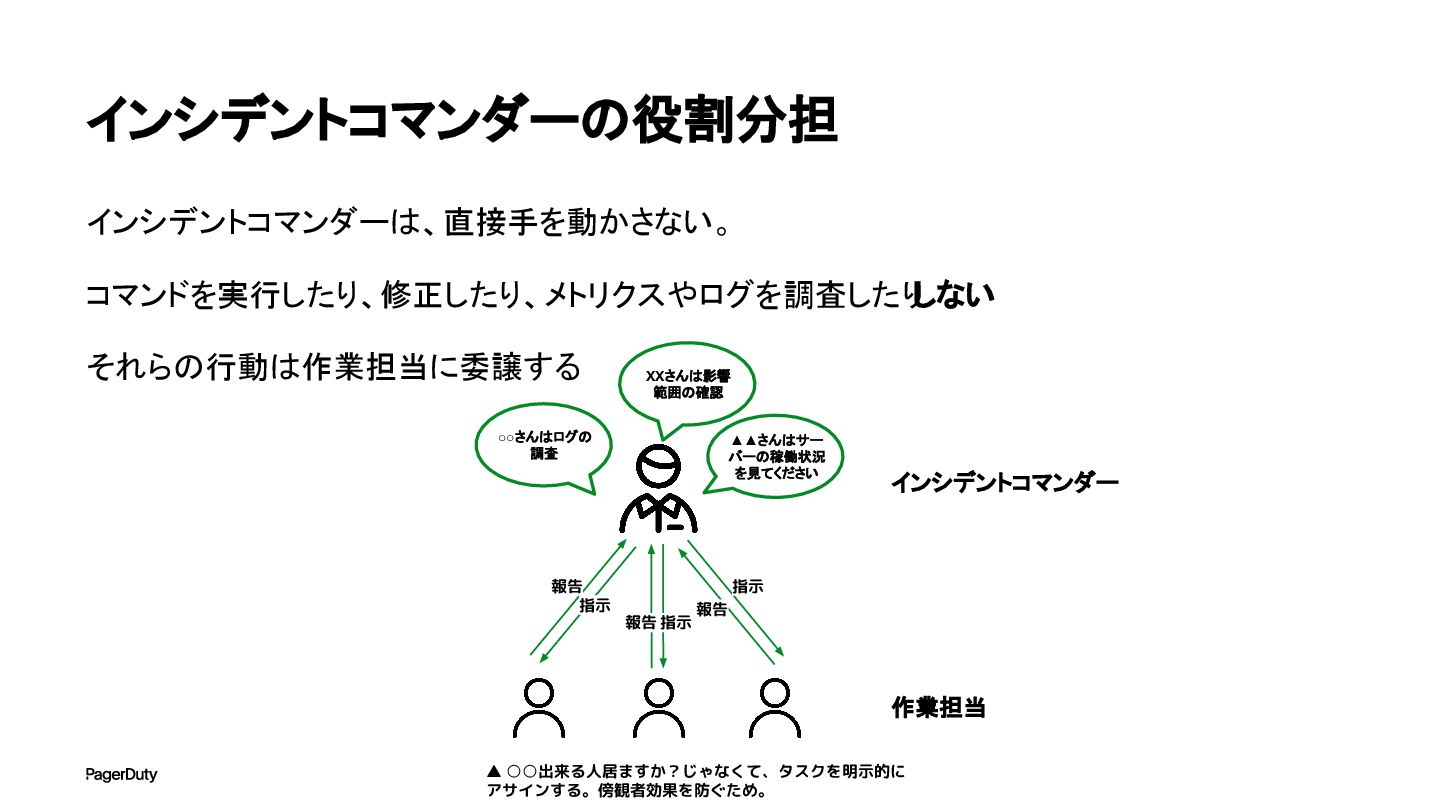
インシデントコマンダーの役割分担 インシデントコマンダーは、直接手を動かさない。 コマンドを実行したり、修正したり、メトリクスやログを調査したり しない それらの行動は作業担当に委譲する インシデントコマンダー 作業担当 指示 報告 指示
報告 指示 報告 ◦◦さんはログの 調査 XXさんは影響 範囲の確認 ▲▲さんはサー バーの稼働状況 を見てください ▲ ◦◦出来る人居ますか?じゃなくて、タスクを明示的に アサインする。傍観者効果を防ぐため。
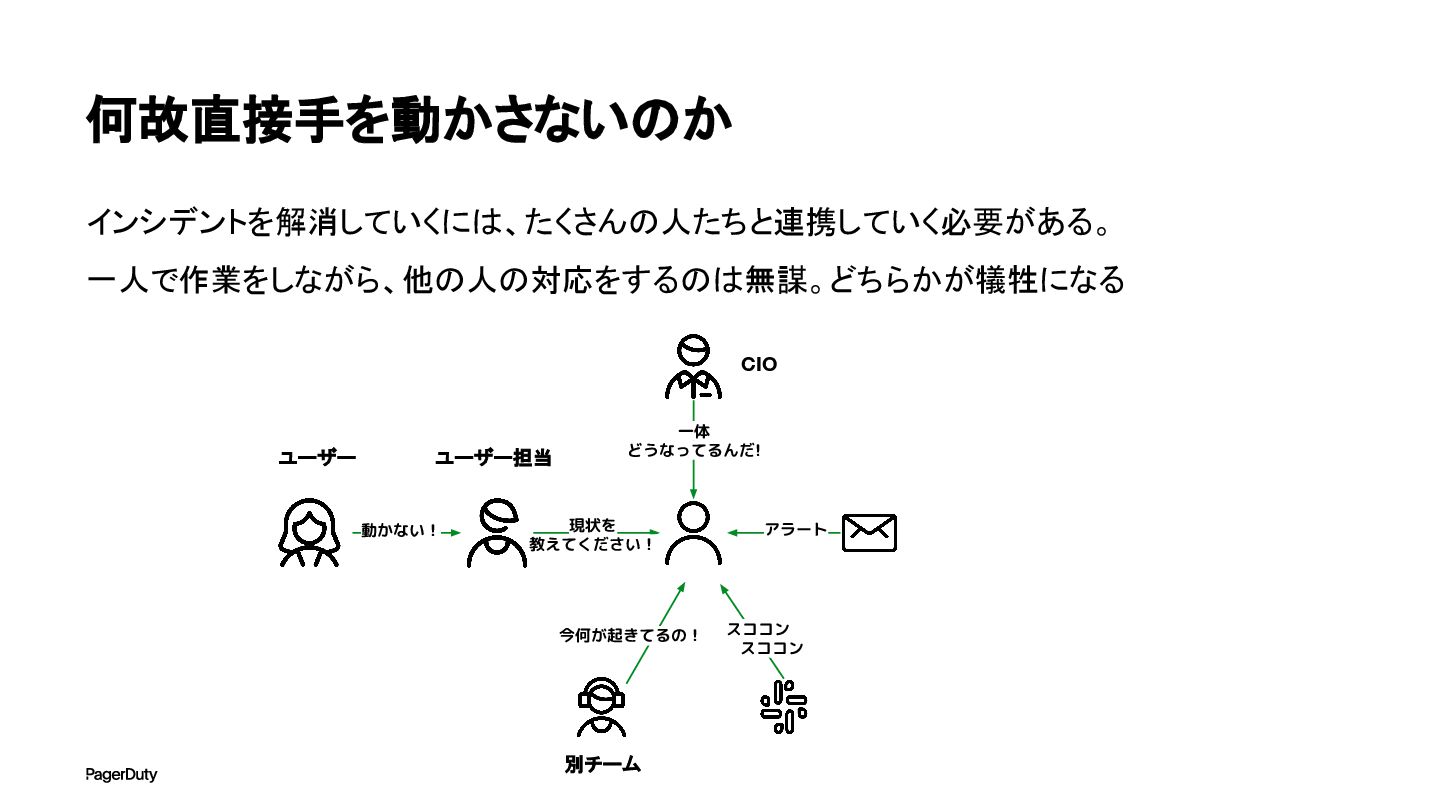
何故直接手を動かさないのか インシデントを解消していくには、たくさんの人たちと連携していく必要がある。 一人で作業をしながら、他の人の対応をするのは無謀。どちらかが犠牲になる CIO 一体 どうなってるんだ! 現状を 教えてください! 今何が起きてるの! スココン
スココン アラート 動かない! ユーザー担当 別チーム ユーザー
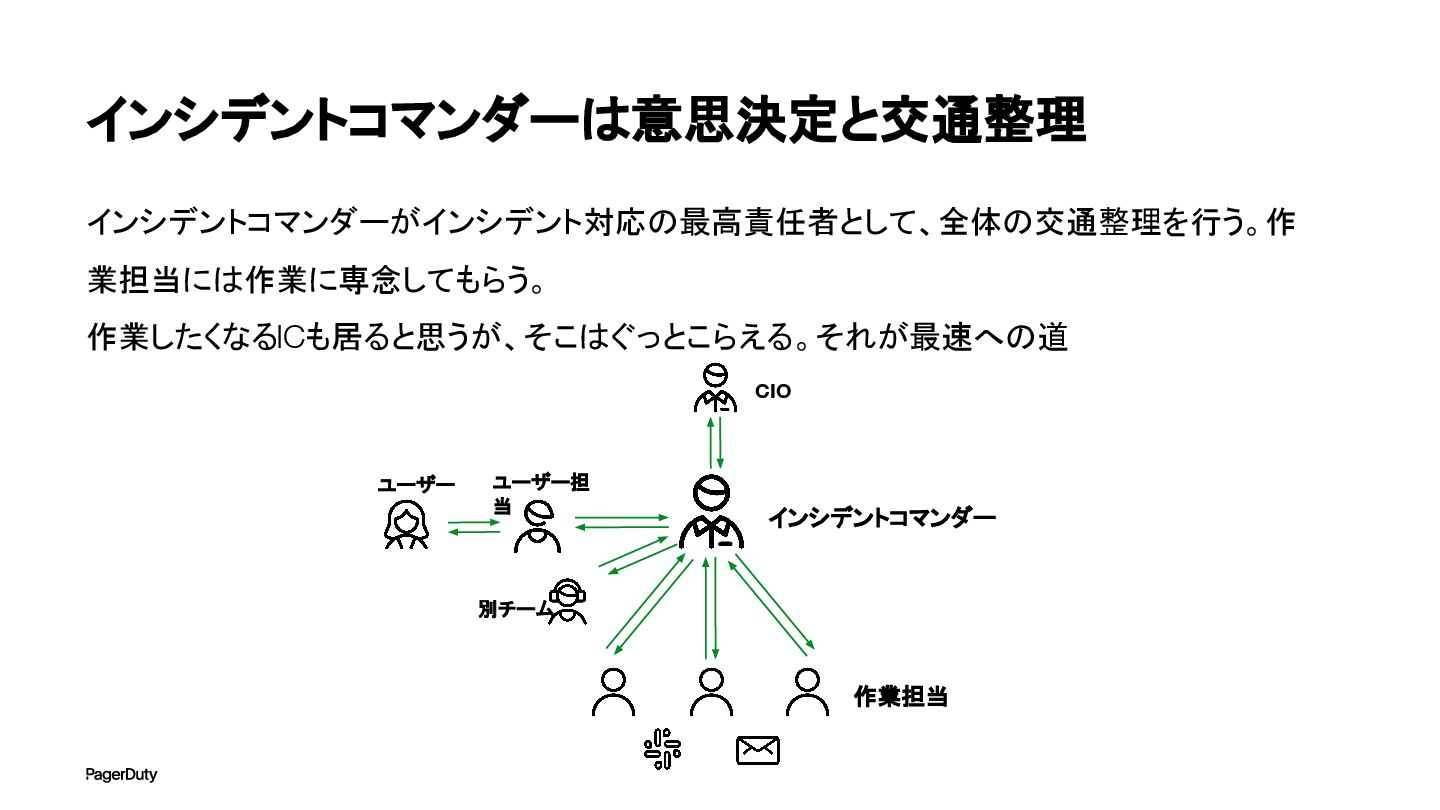
インシデントコマンダーは意思決定と交通整理 インシデントコマンダーがインシデント対応の最高責任者として、全体の交通整理を行う。作 業担当には作業に専念してもらう。 作業したくなるICも居ると思うが、そこはぐっとこらえる。それが最速への道 インシデントコマンダー 作業担当 CIO ユーザー担 当 別チーム
ユーザー
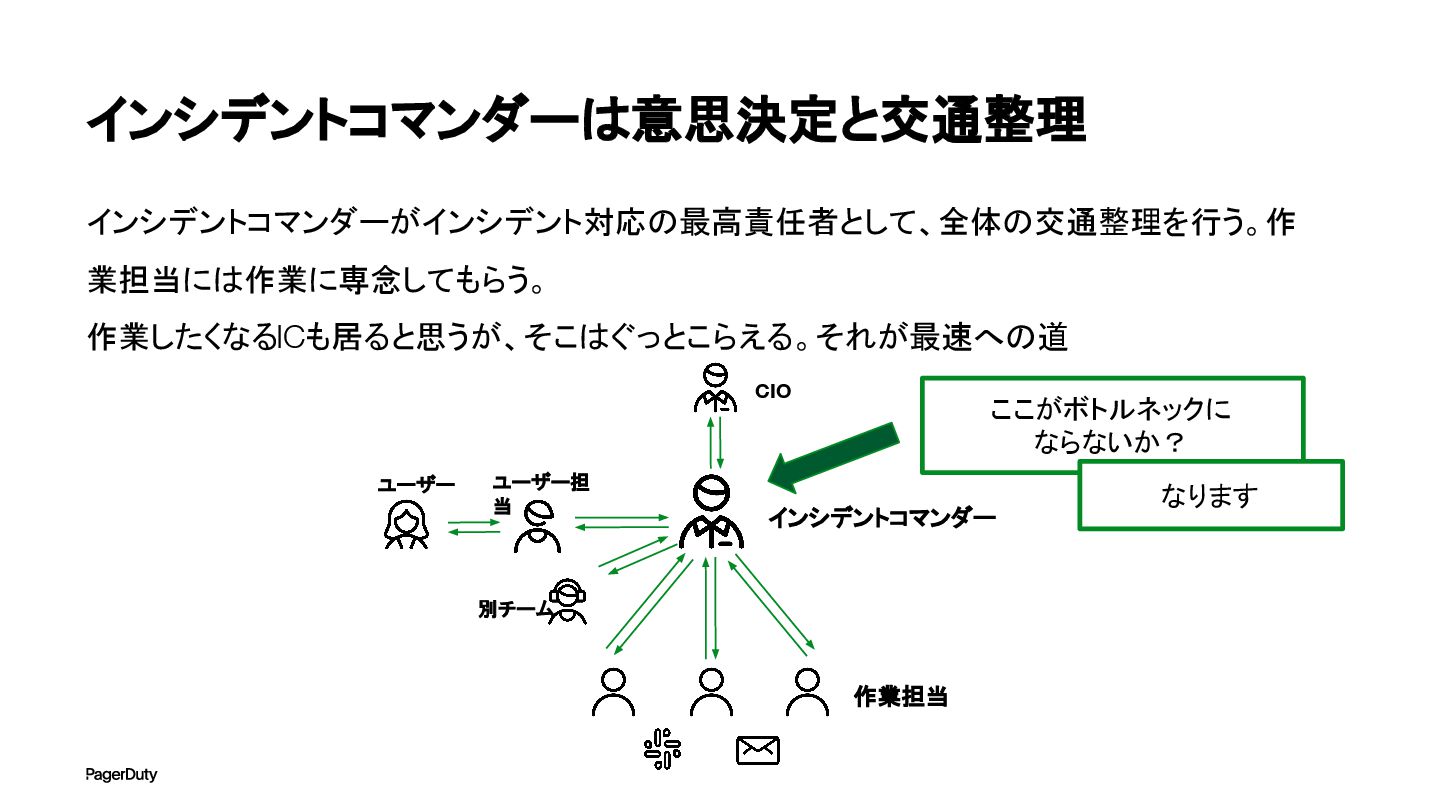
インシデントコマンダーは意思決定と交通整理 インシデントコマンダーがインシデント対応の最高責任者として、全体の交通整理を行う。作 業担当には作業に専念してもらう。 作業したくなるICも居ると思うが、そこはぐっとこらえる。それが最速への道 インシデントコマンダー 作業担当 CIO ユーザー担 当 別チーム
ユーザー ここがボトルネックに ならないか? なります
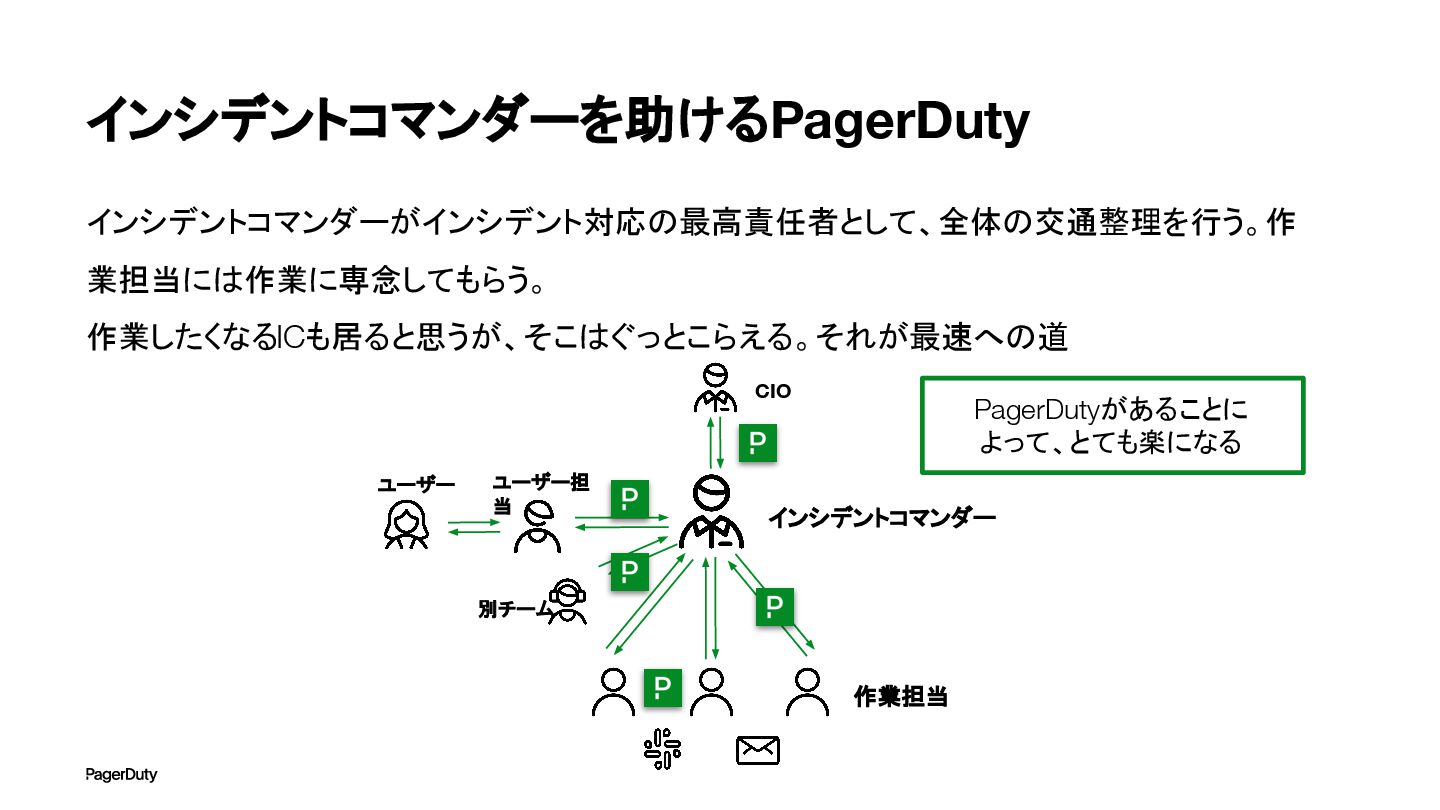
インシデントコマンダーを助けるPagerDuty インシデントコマンダーがインシデント対応の最高責任者として、全体の交通整理を行う。作 業担当には作業に専念してもらう。 作業したくなるICも居ると思うが、そこはぐっとこらえる。それが最速への道 インシデントコマンダー 作業担当 CIO ユーザー担 当 別チーム
ユーザー PagerDutyがあることに よって、とても楽になる
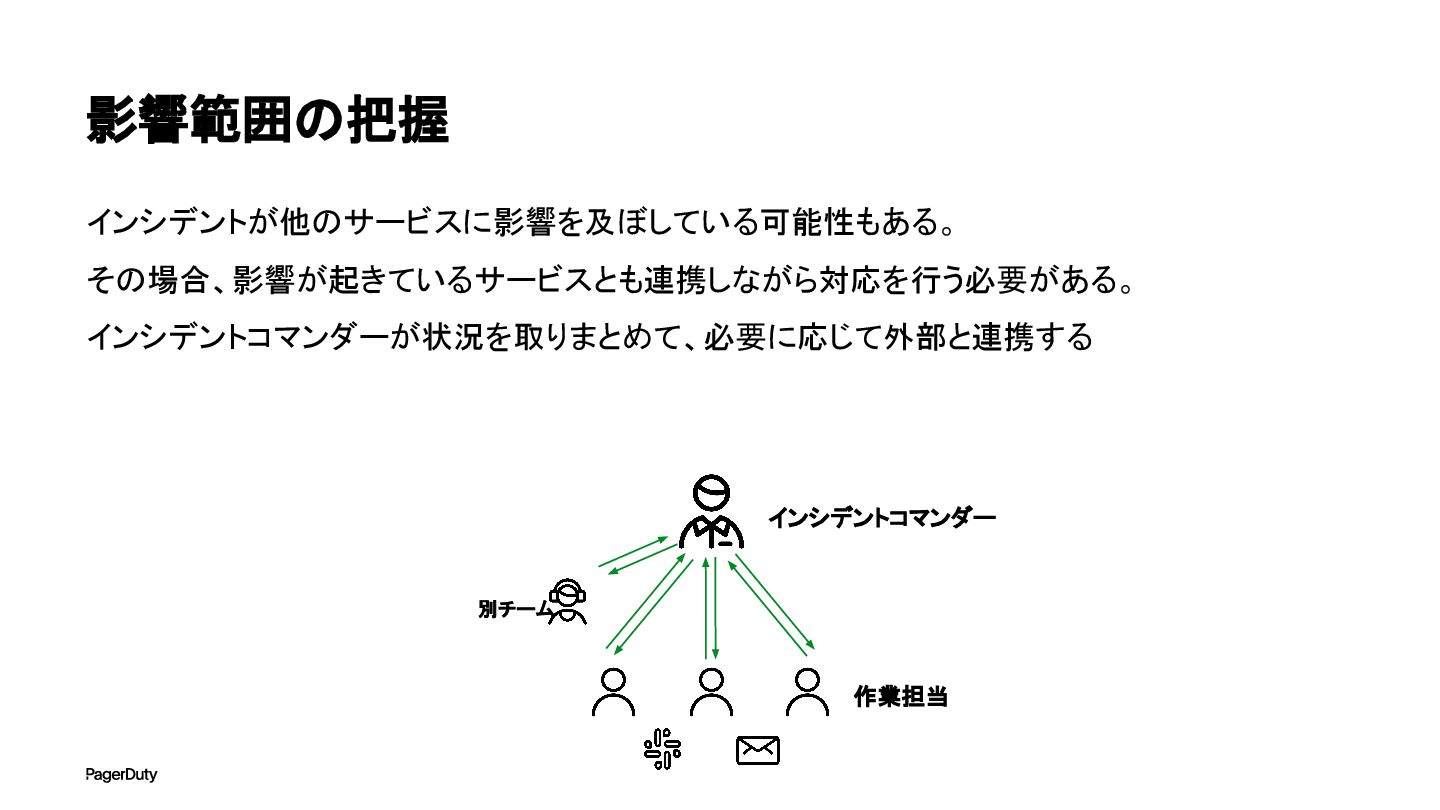
影響範囲の把握 インシデントが他のサービスに影響を及ぼしている可能性もある。 その場合、影響が起きているサービスとも連携しながら対応を行う必要がある。 インシデントコマンダーが状況を取りまとめて、必要に応じて外部と連携する インシデントコマンダー 作業担当 別チーム
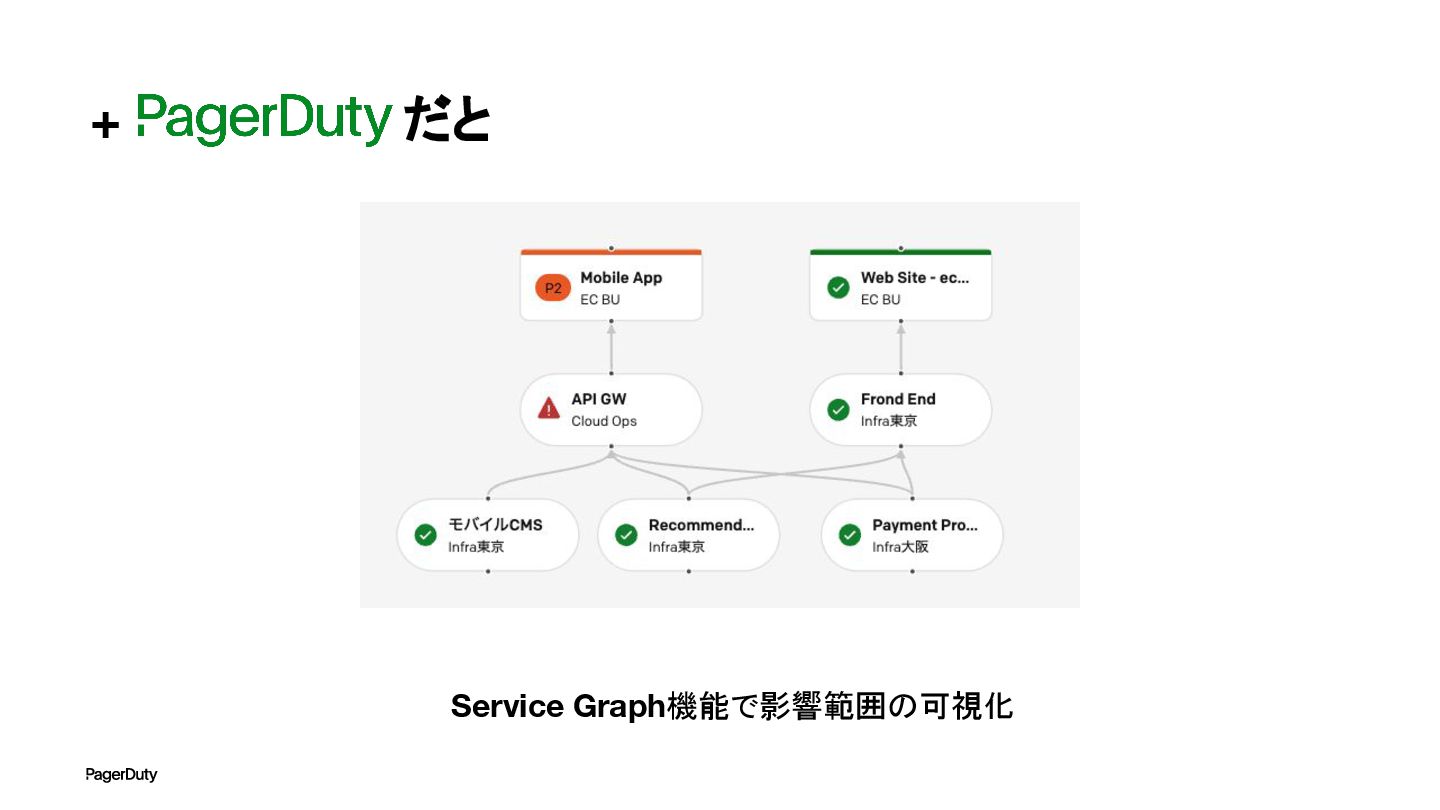
+ だと Service Graph機能で影響範囲の可視化
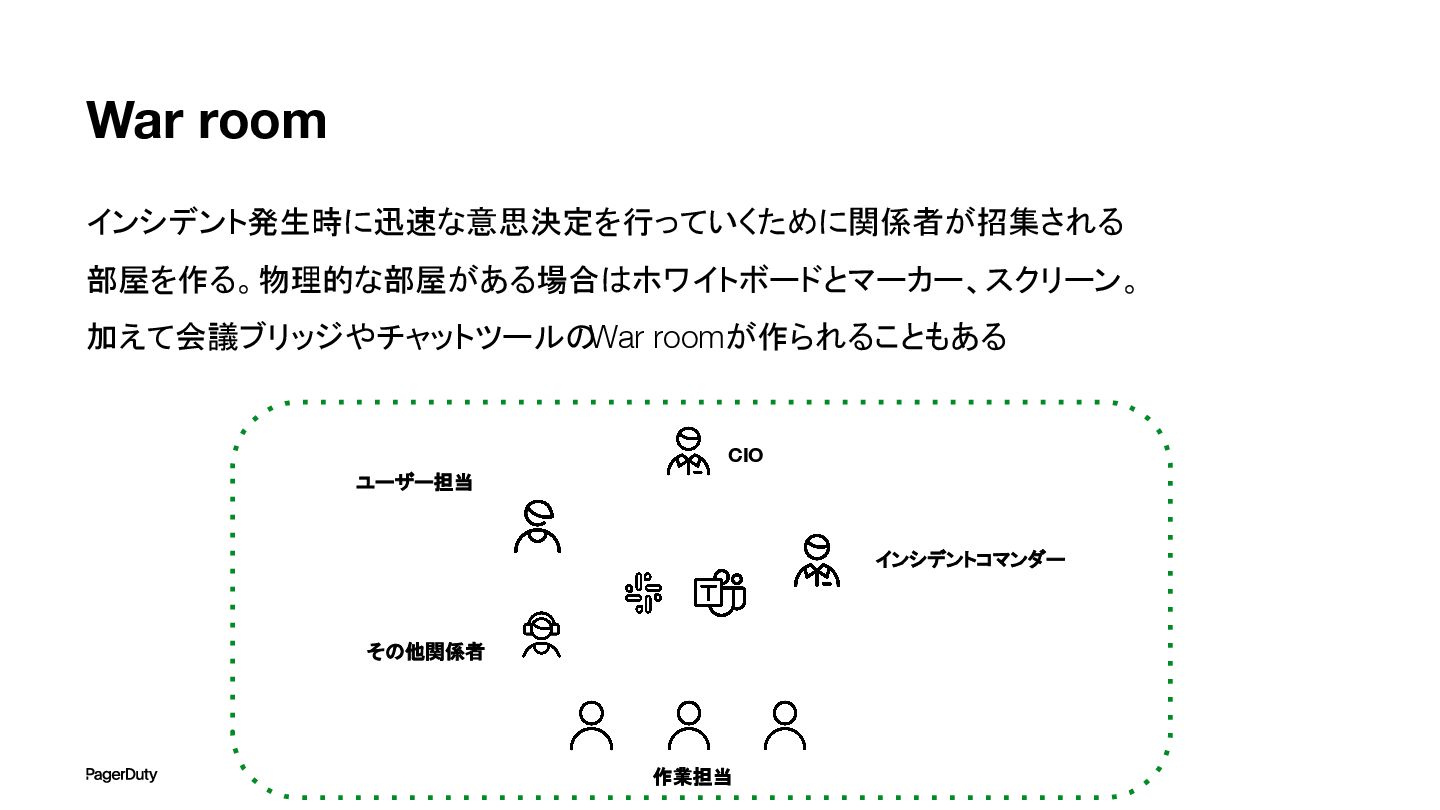
War room インシデント発生時に迅速な意思決定を行っていくために関係者が招集される 部屋を作る。物理的な部屋がある場合はホワイトボードとマーカー、スクリーン。 加えて会議ブリッジやチャットツールの War roomが作られることもある 作業担当 CIO ユーザー担当
その他関係者 インシデントコマンダー
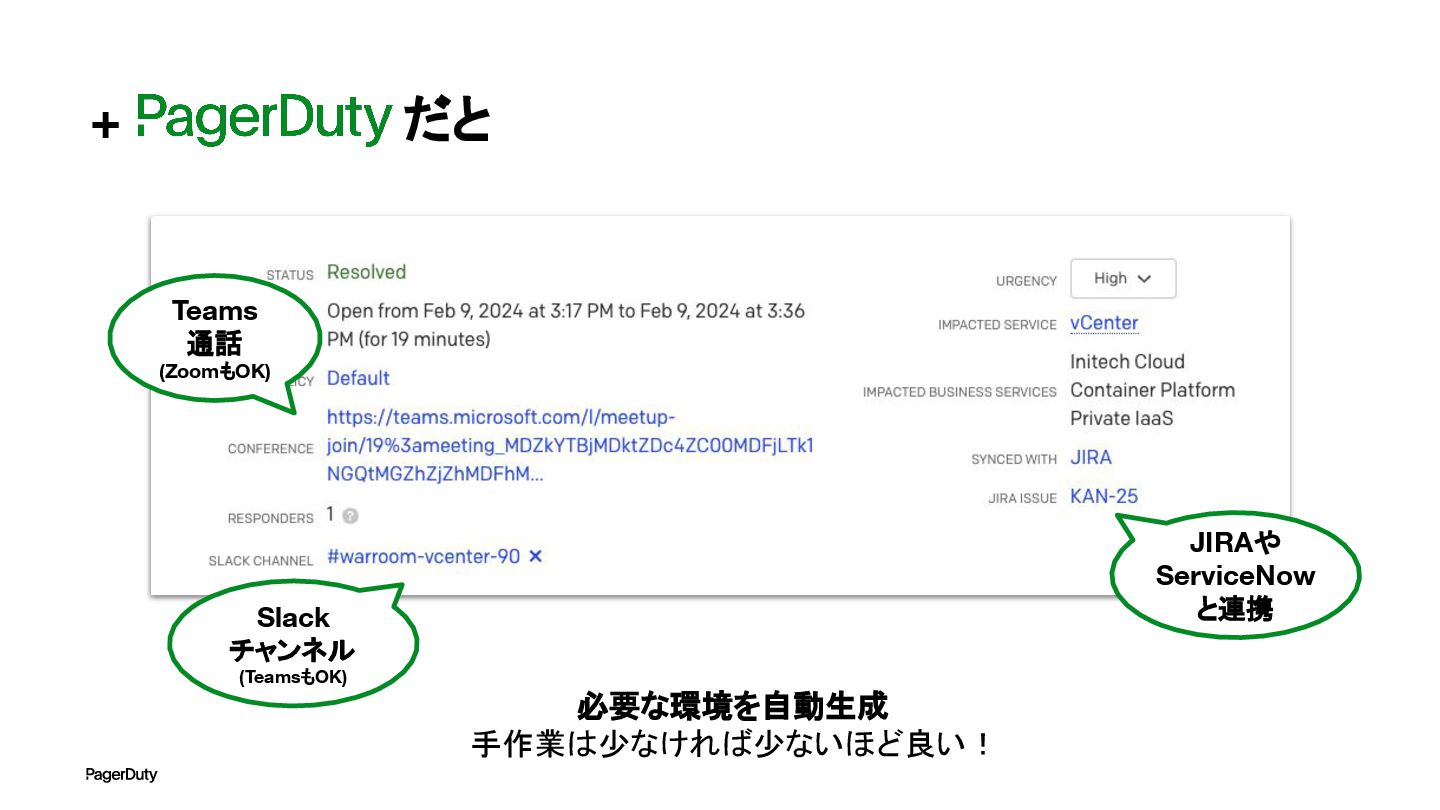
+ だと Teams 通話 (ZoomもOK) Slack チャンネル (TeamsもOK) JIRAや ServiceNow
と連携 必要な環境を自動生成 手作業は少なければ少ないほど良い!
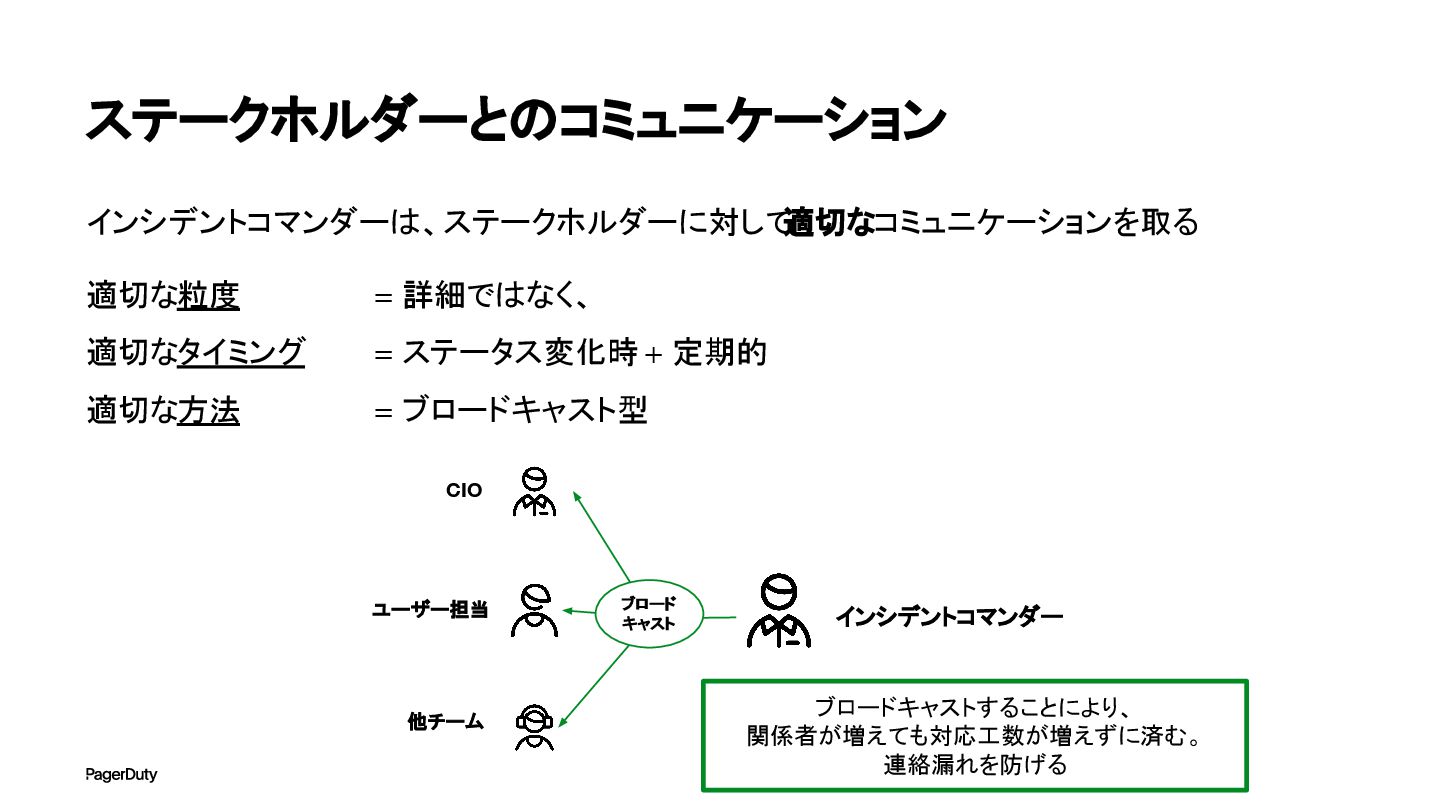
ステークホルダーとのコミュニケーション インシデントコマンダーは、ステークホルダーに対して 適切なコミュニケーションを取る 適切な粒度 = 詳細ではなく、 適切なタイミング = ステータス変化時 +
定期的 適切な方法 = ブロードキャスト型 インシデントコマンダー CIO ユーザー担当 他チーム ブロード キャスト ブロードキャストすることにより、 関係者が増えても対応工数が増えずに済む。 連絡漏れを防げる
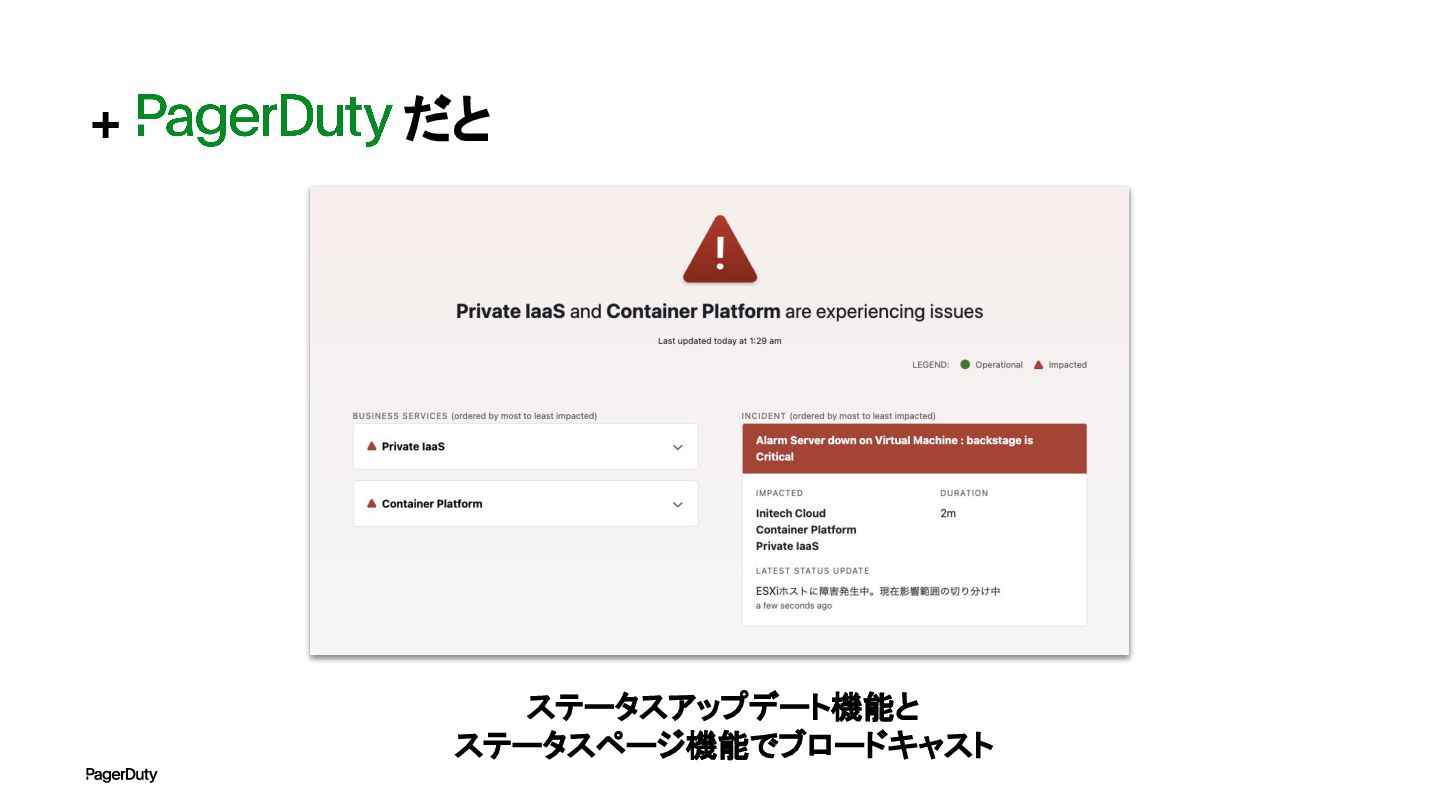
+ だと ステータスアップデート機能と ステータスページ機能でブロードキャスト
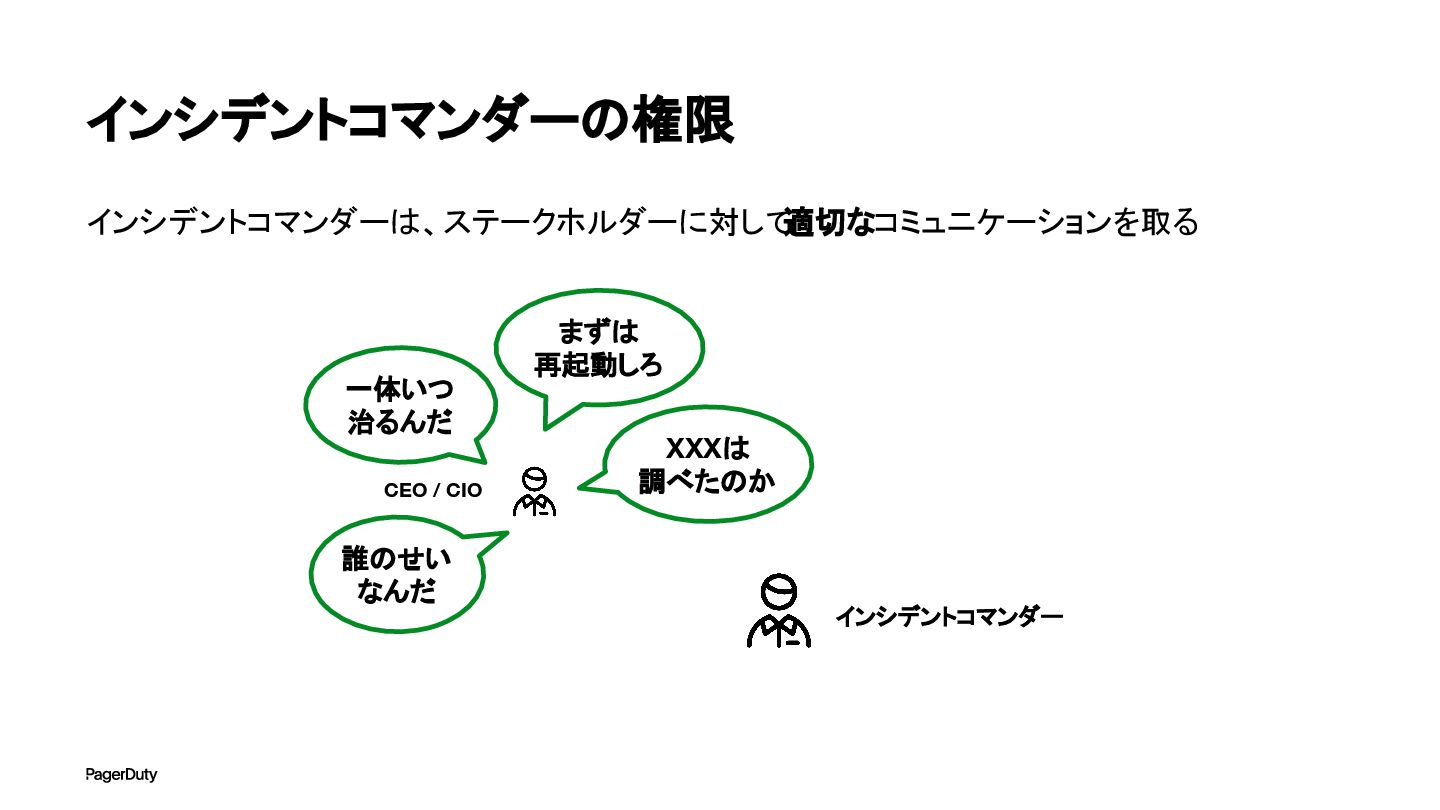
インシデントコマンダーの権限 インシデントコマンダーは、ステークホルダーに対して 適切なコミュニケーションを取る インシデントコマンダー CEO / CIO 一体いつ 治るんだ まずは
再起動しろ XXXは 調べたのか 誰のせい なんだ
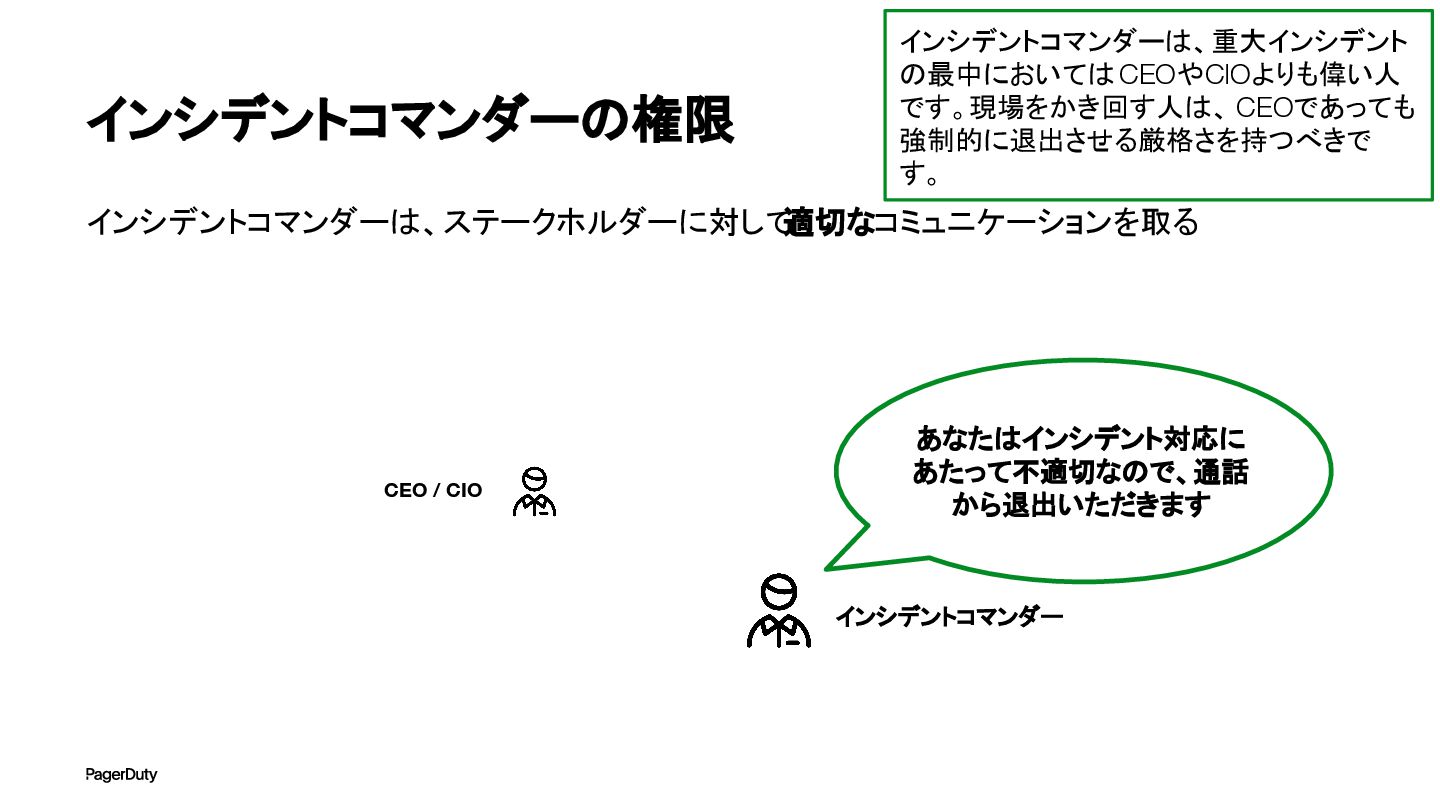
インシデントコマンダーの権限 インシデントコマンダーは、ステークホルダーに対して 適切なコミュニケーションを取る インシデントコマンダー CEO / CIO あなたはインシデント対応に あたって不適切なので、通話 から退出いただきます
インシデントコマンダーは、重大インシデント の最中においてはCEOやCIOよりも偉い人 です。現場をかき回す人は、 CEOであっても 強制的に退出させる厳格さを持つべきで す。
インシデントコマンダーのもと、体系的な対応をする インシデントコマンダーは、インシデント対応の指揮者。 重大インシデントを解決に導くことを目的とし、意思決定を行う。 日々の地位に関係なく、重大インシデントでは最も位の高い人 インシデントコマンダー 作業担当
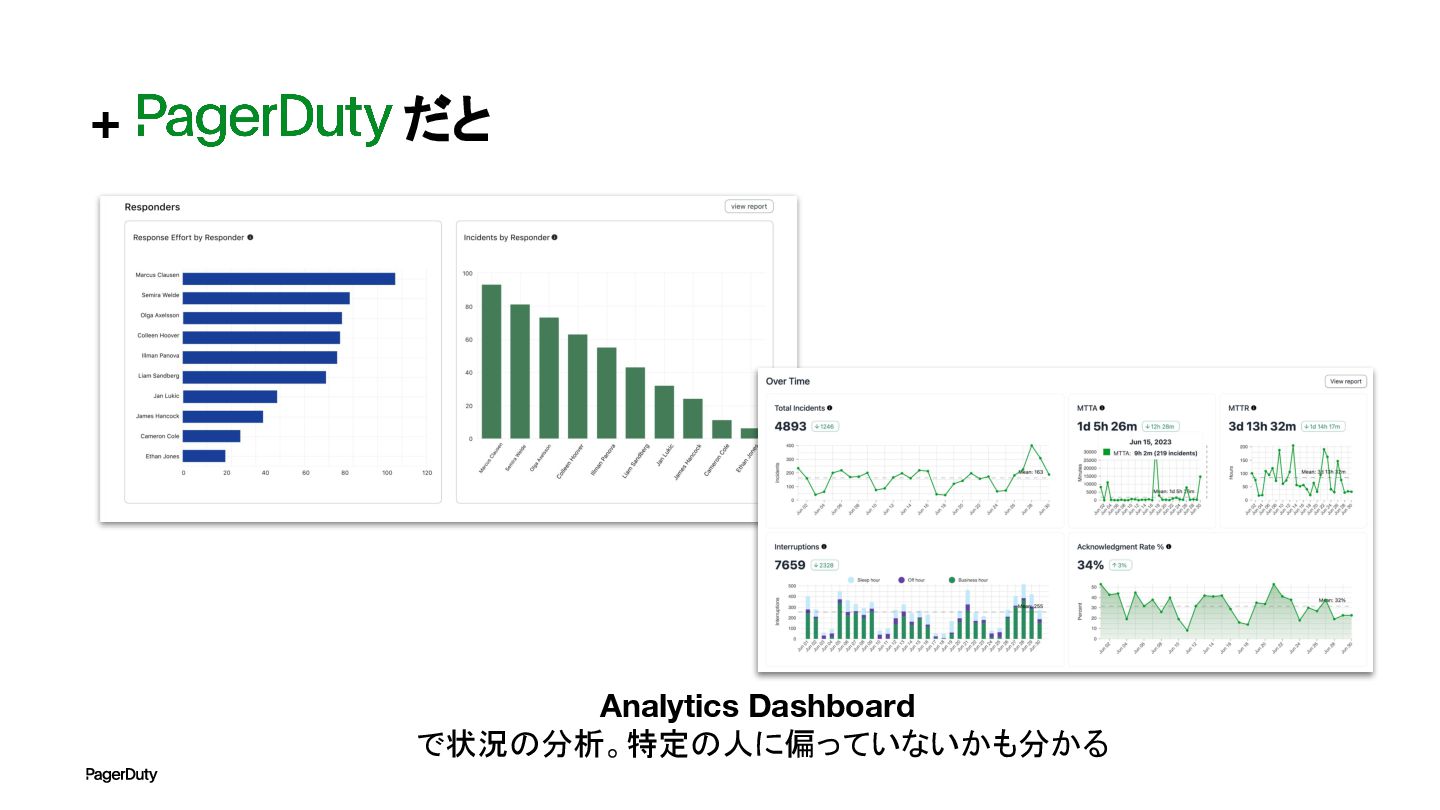
要員の管理 インシデント対応は長時間にわたることもある。インシデントコマンダーは、要員の体調面に 気を配り、適切に休ませる。申告が無くても休ませる。 食事や宿泊などの兵站にも気を配ること (実際の手配は委譲したほうが良い ) インシデントコマンダー 作業担当
+ だと Analytics Dashboard で状況の分析。特定の人に偏っていないかも分かる
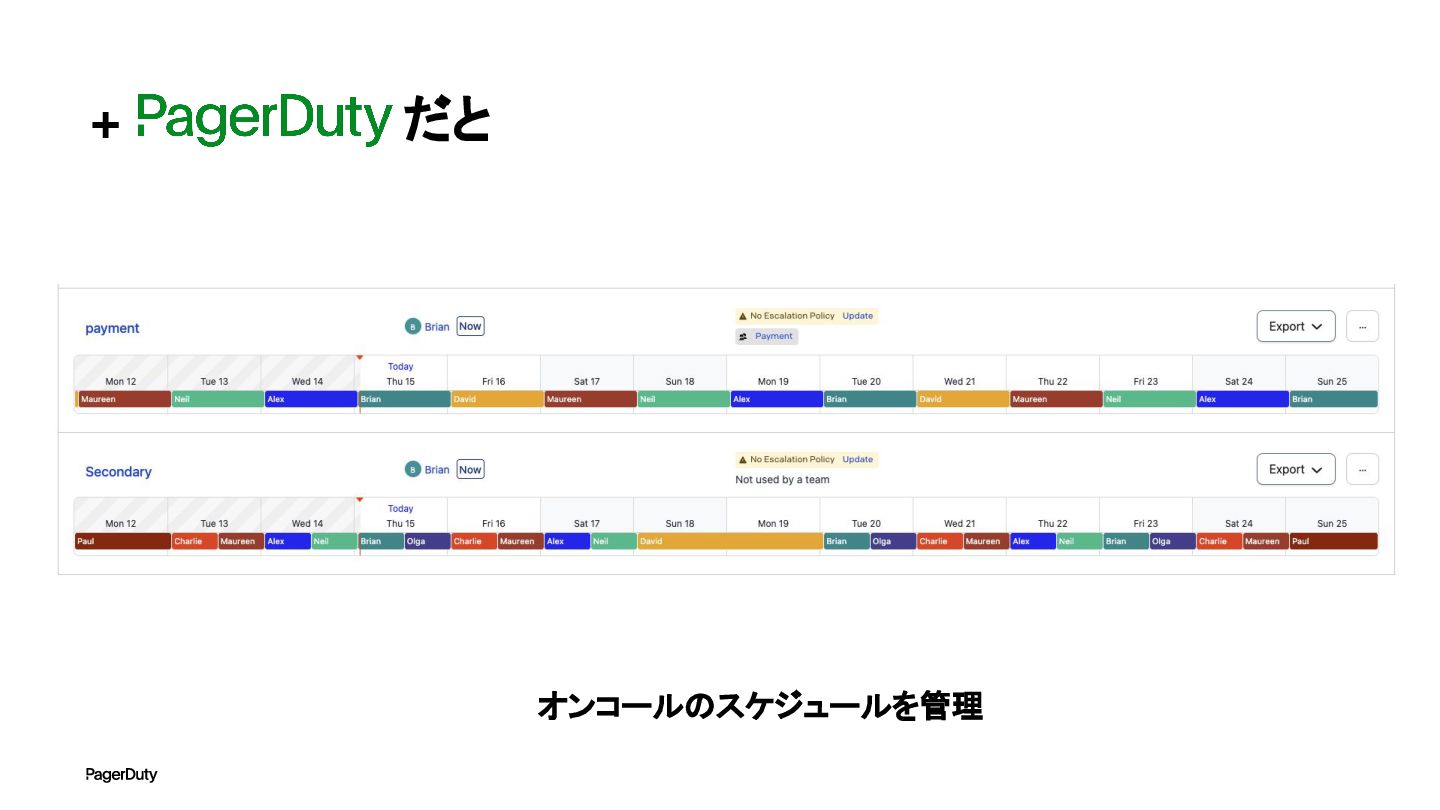
+ だと オンコールのスケジュールを管理
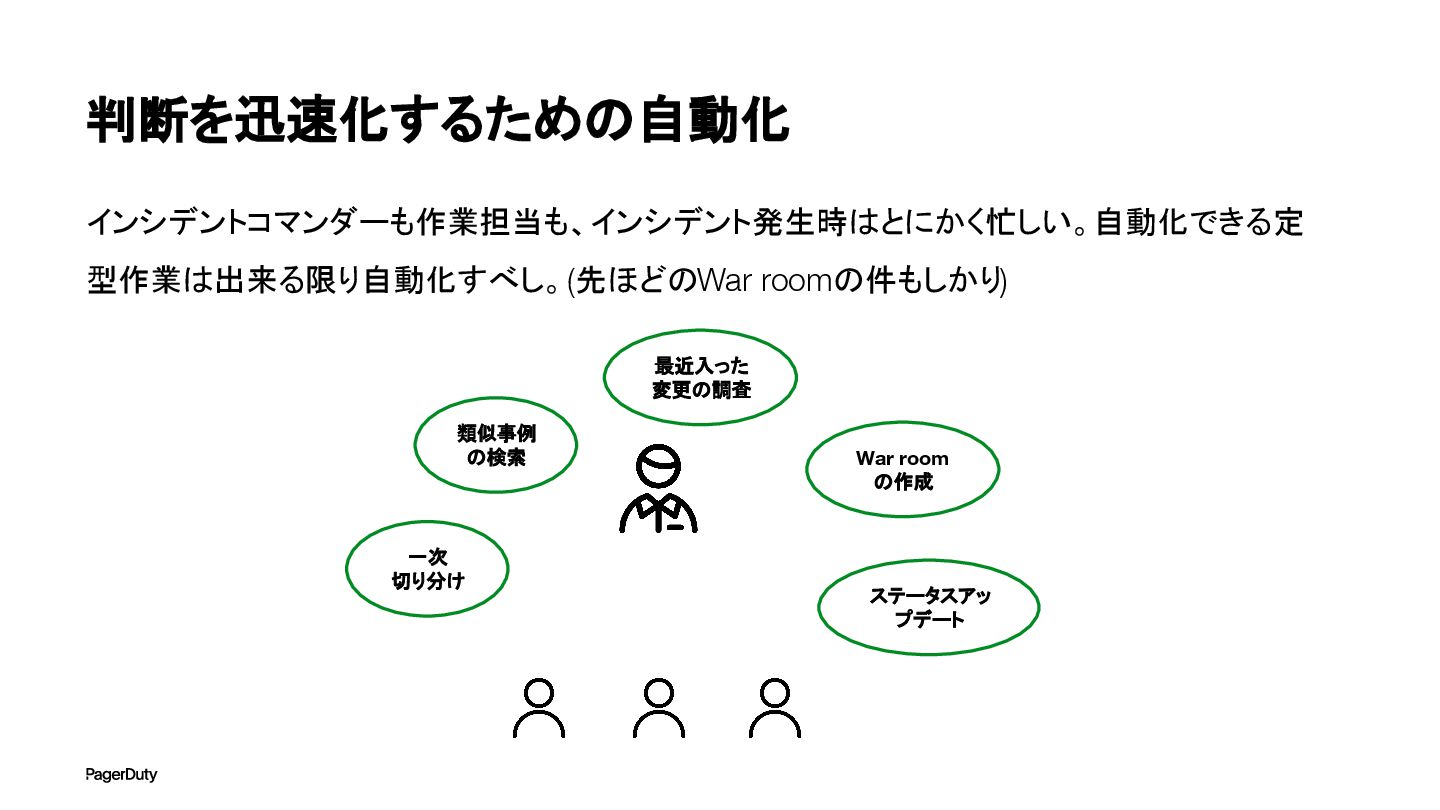
判断を迅速化するための自動化 インシデントコマンダーも作業担当も、インシデント発生時はとにかく忙しい。自動化できる定 型作業は出来る限り自動化すべし。 (先ほどのWar roomの件もしかり) 一次 切り分け 類似事例 の検索 最近入った
変更の調査 War room の作成 ステータスアッ プデート
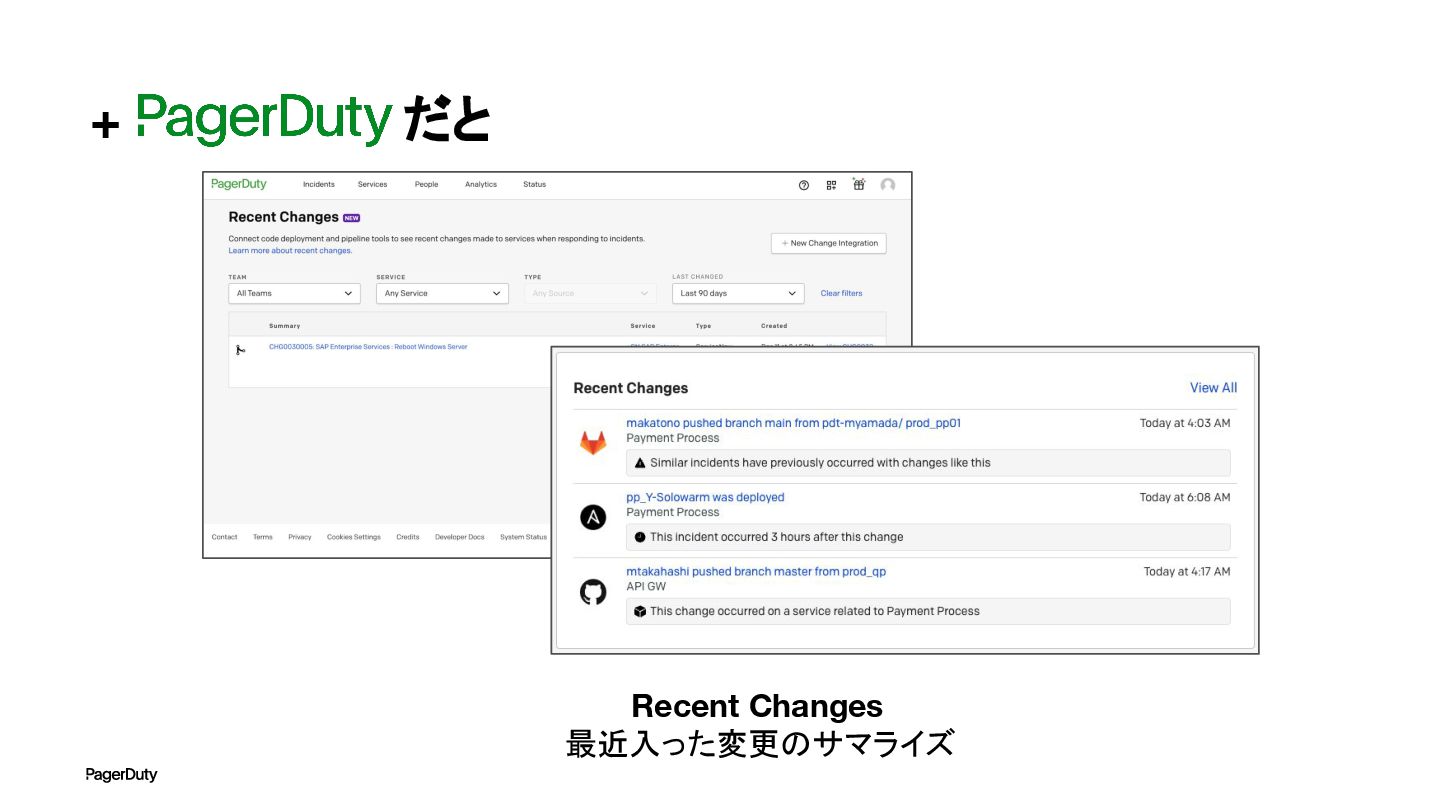
+ だと Recent Changes 最近入った変更のサマライズ
+ だと Past Incidents 過去の類似インシデント一覧と、 発生時期・回数のヒートマップを表示。
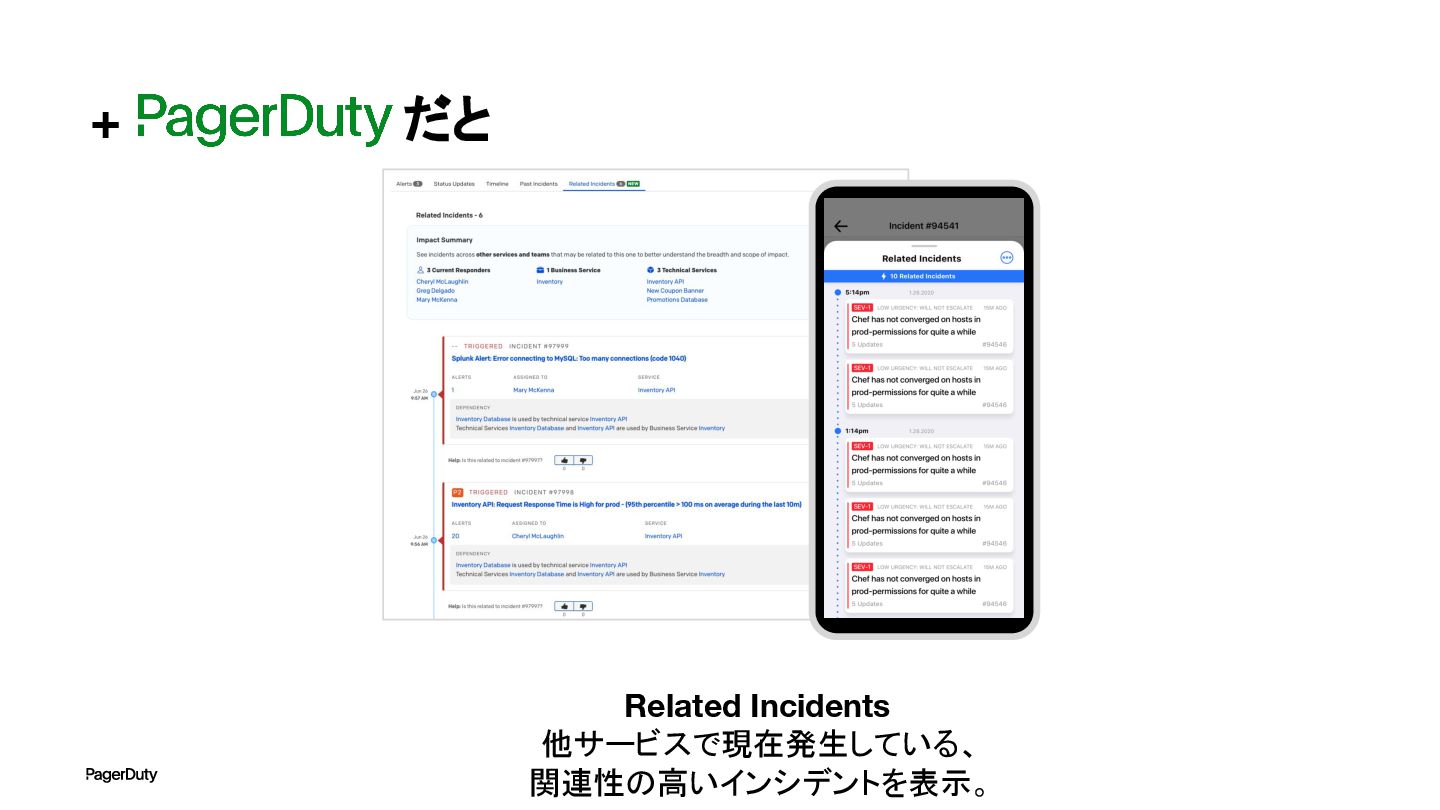
+ だと Related Incidents 他サービスで現在発生している、 関連性の高いインシデントを表示。
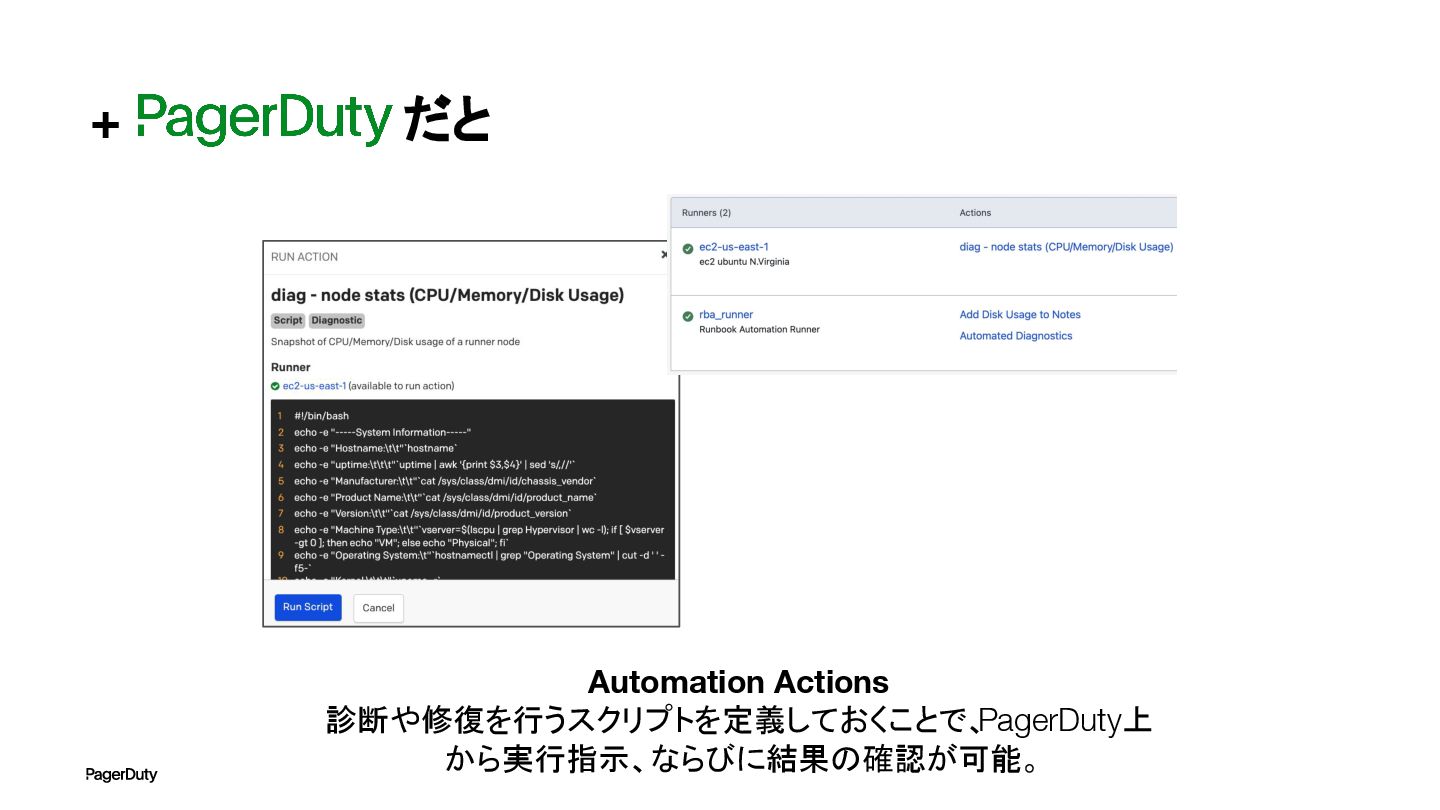
+ だと Automation Actions 診断や修復を行うスクリプトを定義しておくことで、 PagerDuty上 から実行指示、ならびに結果の確認が可能。
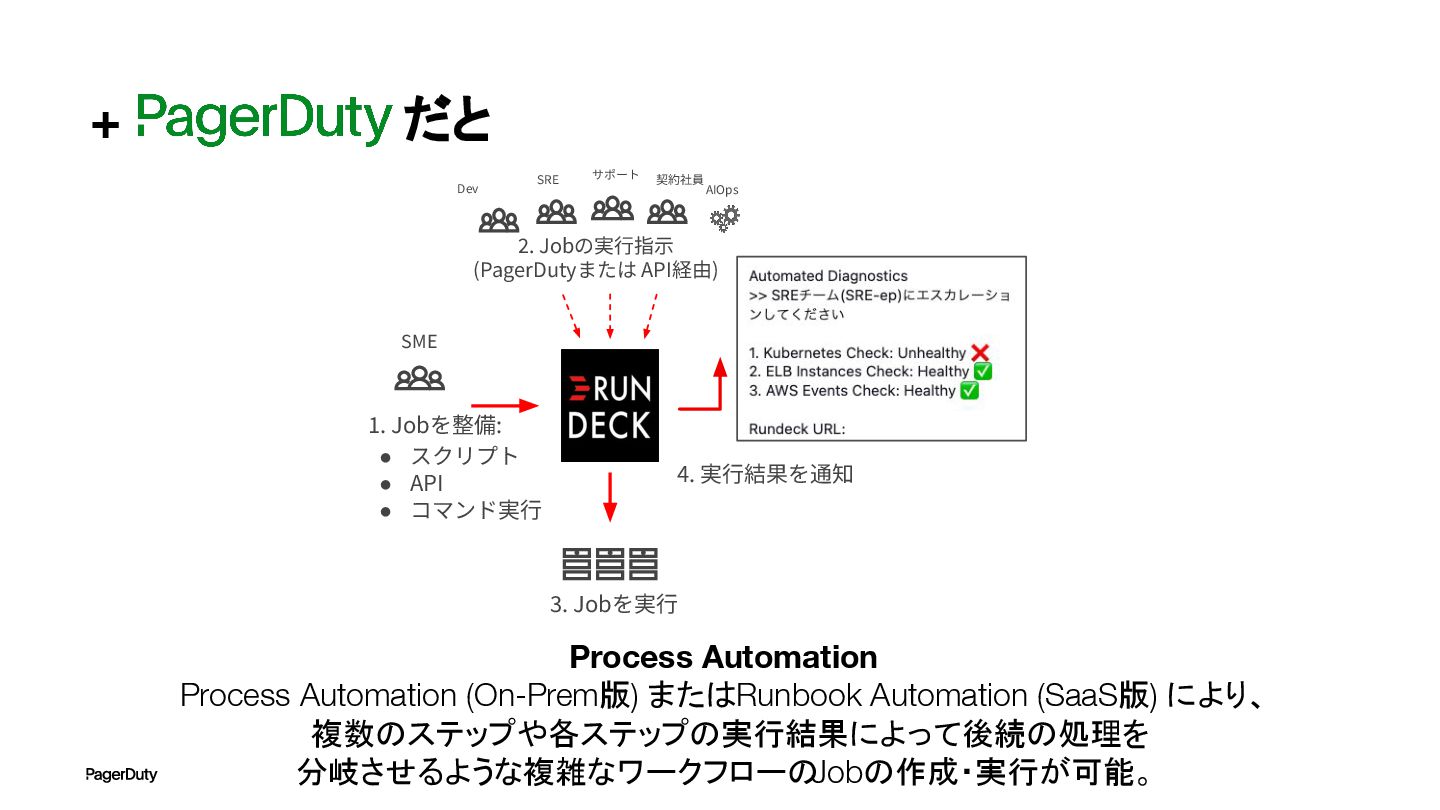
+ だと Process Automation Process Automation (On-Prem版) またはRunbook Automation (SaaS版)
により、 複数のステップや各ステップの実行結果によって後続の処理を 分岐させるような複雑なワークフローの Jobの作成・実行が可能。 1. Jobを整備: SME • スクリプト • API • コマンド実⾏ サポート 契約社員 AIOps SRE Dev 2. Jobの実⾏指⽰ (PagerDutyまたは API経由) 3. Jobを実⾏ 4. 実⾏結果を通知
ポストモーテム SREのプラクティスでおなじみ • インシデントのインパクト • 緩和や解消のために行われたアクション • 根本原因 • インシデントの再発を避けるためのフォローアップ
きちんと纏めておくことで、組織としての成長に繋がる。スタンドプレーだとこのあたりの取り組みが 行われないことが多い
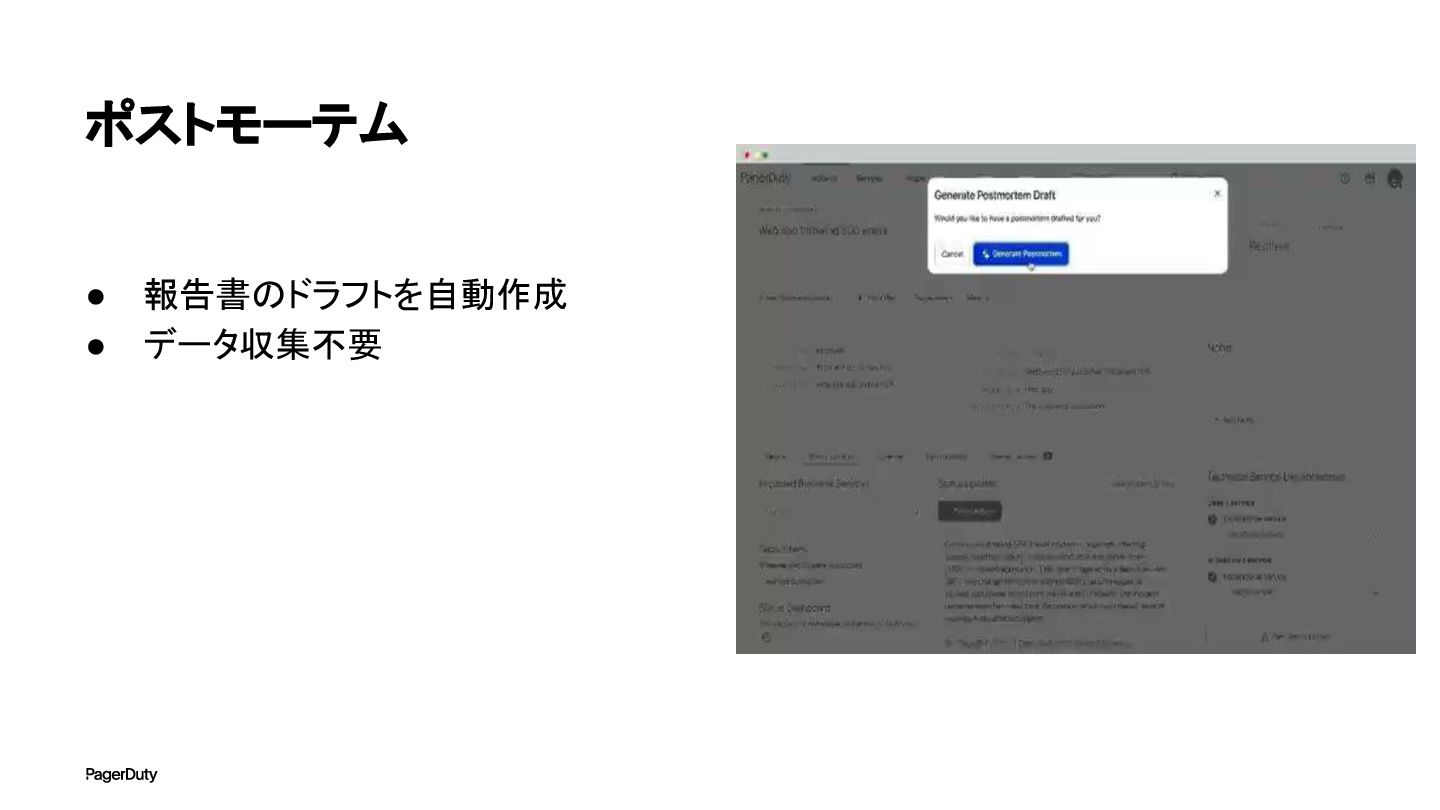
+ だと Postmotems ポストモーテムの作成を支援。受信したイベント、ステータスアップデート、インシデント ノート、Slackの会話などからタイムラインを作成
インシデントコマンダーになれる人はどんな人か システムの深い技術知識は必要なし。 インシデントコマンダーの役割はインシデント対応を調整することであって、 技術的な変更を行うことではない • コミュニケーションスキル • サービスがどのように連携しているかの理解 • 状況を判断して、行動方針に対する迅速な意思決定ができる
• フィードバックに耳を傾け、必要に応じてその場で計画を変更できる柔軟性がある • 直近の2つの重大インシデントに、見学または対応者として関わっている • 指揮を執り、CEOであっても通話の妨げとなる人を通話から追い出すことのできる厳格さがあ る
今日覚えて帰ってほしいこと① インシデント対応には
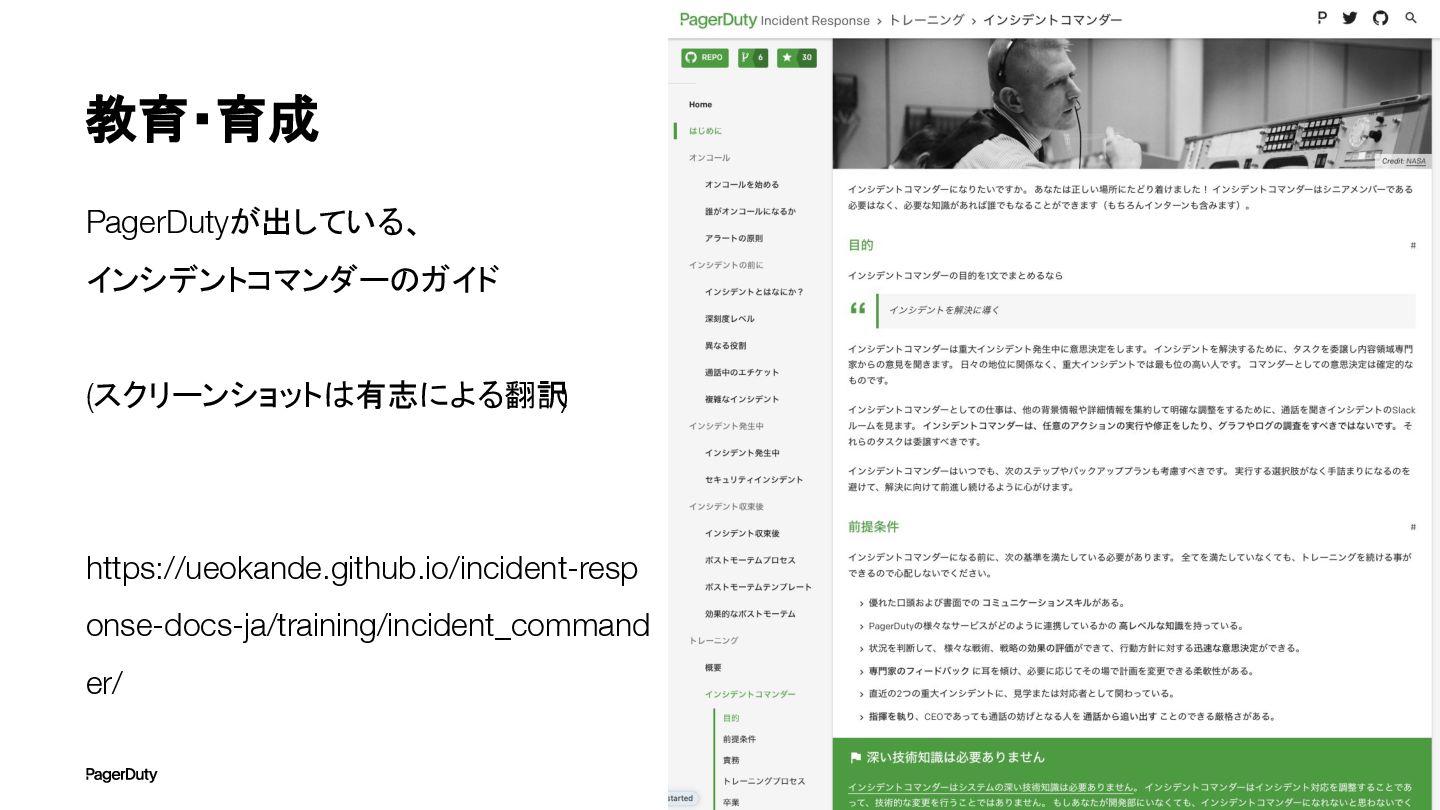
教育・育成 PagerDutyが出している、 インシデントコマンダーのガイド (スクリーンショットは有志による翻訳 ) https://ueokande.github.io/incident-resp onse-docs-ja/training/incident_command er/
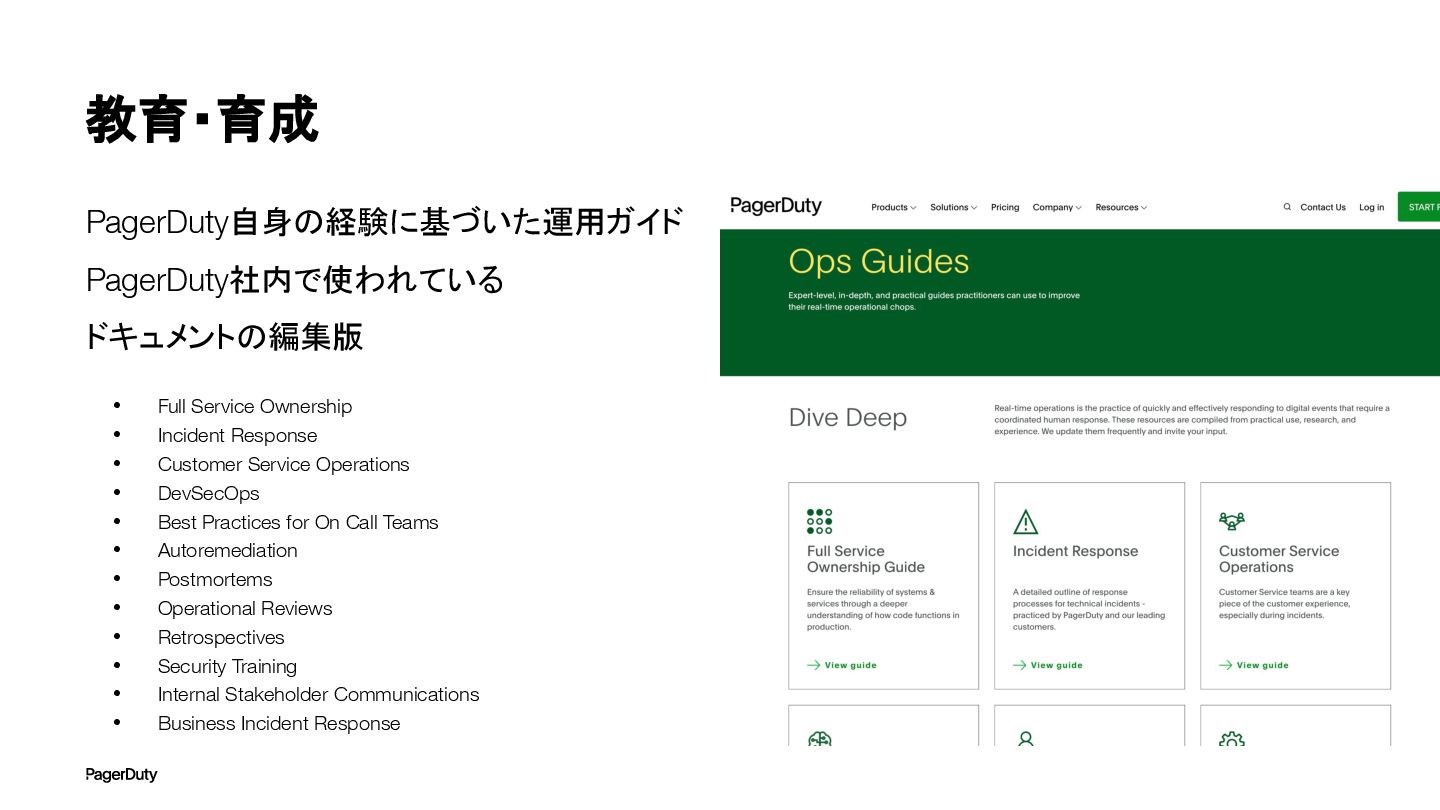
教育・育成 PagerDuty自身の経験に基づいた運用ガイド PagerDuty社内で使われている ドキュメントの編集版 • Full Service Ownership • Incident
Response • Customer Service Operations • DevSecOps • Best Practices for On Call Teams • Autoremediation • Postmortems • Operational Reviews • Retrospectives • Security Training • Internal Stakeholder Communications • Business Incident Response
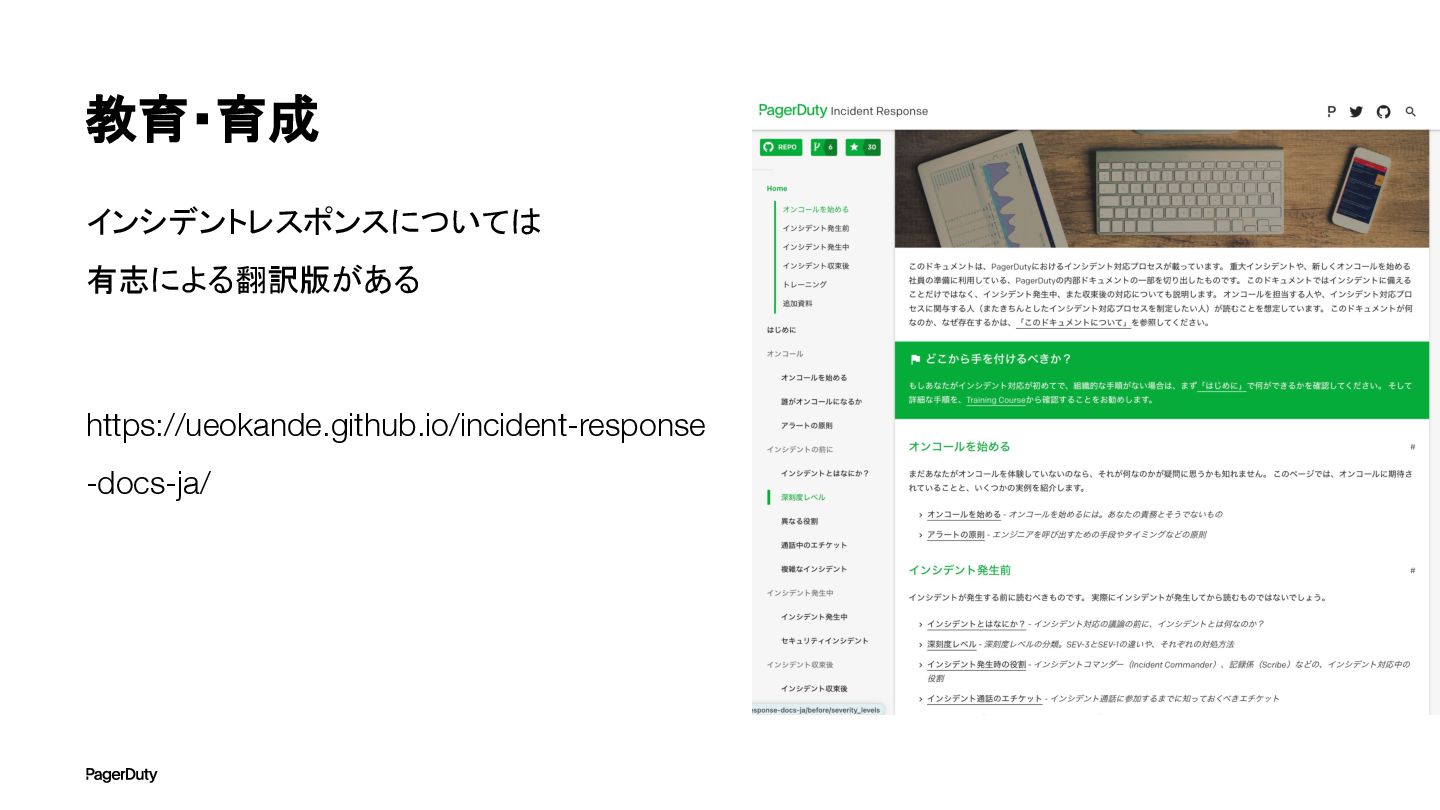
教育・育成 インシデントレスポンスについては 有志による翻訳版がある https://ueokande.github.io/incident-response -docs-ja/
PagerDuty Copilot https://www.pagerduty.co.jp/copilot/ • AWS re:Invent 2023にて発表 • 生成AIによる自動化支援の機能群 ◦
AIアシスタント ◦ 自動化ジョブ構築 ◦ ステータスアップデート ◦ ポストモーテム
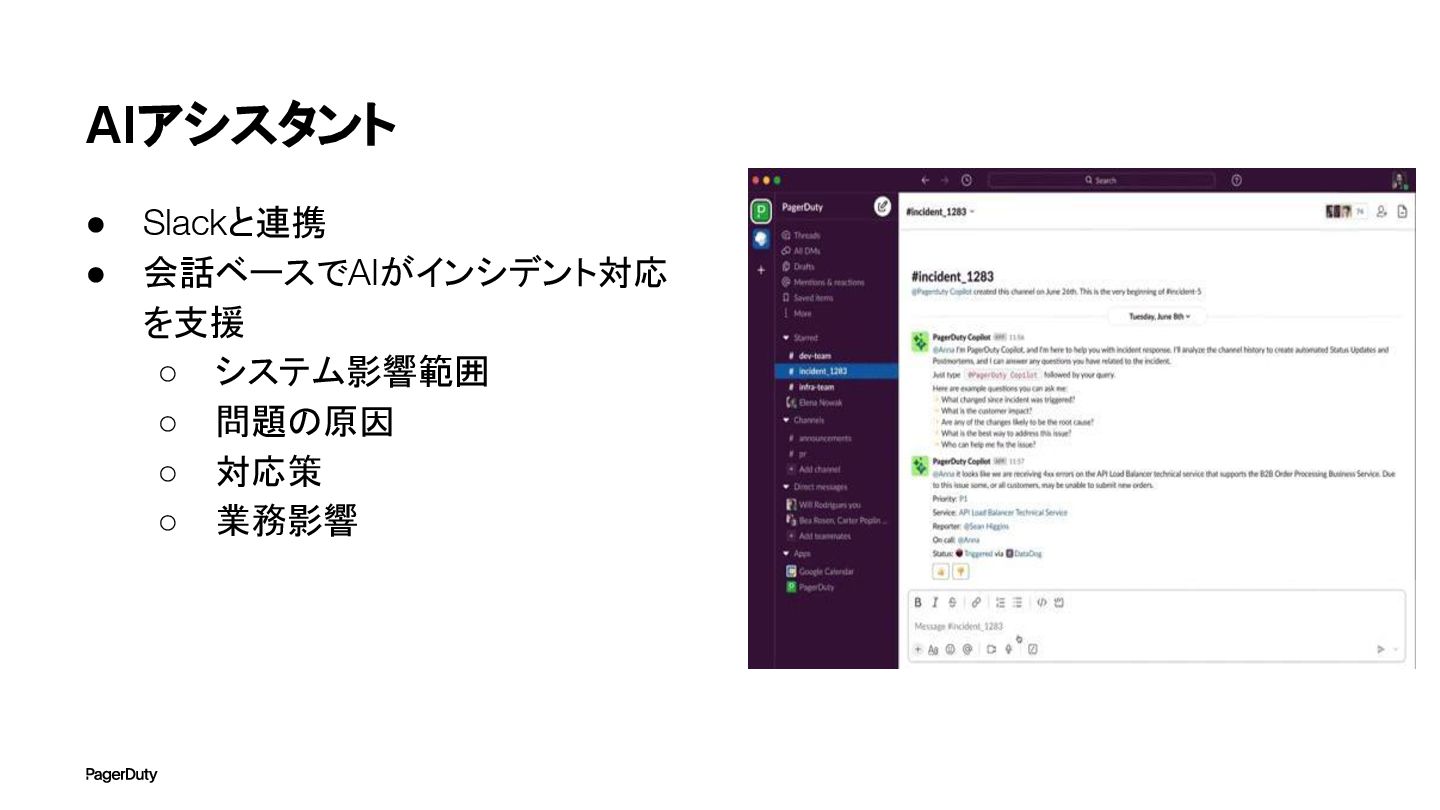
AIアシスタント • Slackと連携 • 会話ベースでAIがインシデント対応 を支援 ◦ システム影響範囲 ◦ 問題の原因
◦ 対応策 ◦ 業務影響
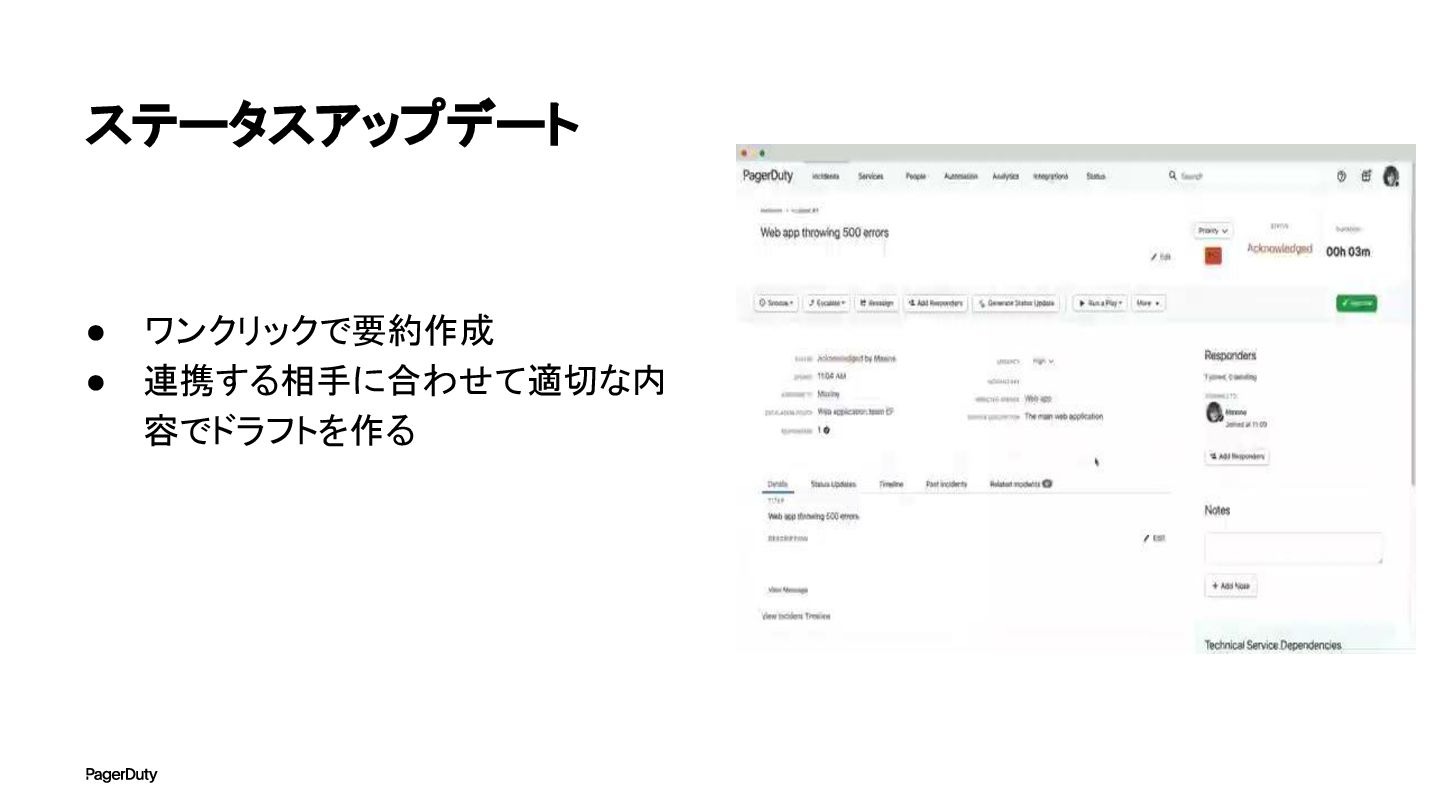
ステータスアップデート • ワンクリックで要約作成 • 連携する相手に合わせて適切な内 容でドラフトを作る
ポストモーテム • 報告書のドラフトを自動作成 • データ収集不要
これからは インシデントコマンダーの時代
インシデント対応には
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}