Современный микропроцессор — это не просто совокупность транзисторов, а уже настоящий «живой организм» со своими тайнами и парадоксами. В его конвейерной системе каждый такт имеет значение, а решения о будущем принимаются в доли наносекунд. Процессор пытается предсказывать будущее, изменяет сгенерированные инструкции, стараясь минимизировать простои и максимизировать производительность, хотя порой и ошибается.
Обсудим, как все эти «фокусы» улучшают производительность Java. Вы узнаете, как из кода можете влиять на поведение процессора, чего стоит избегать. И, наконец, вы убедитесь, что микроархитектура может влиять на исполнение кода. Мы также рассмотрим примеры, где подобные оптимизации дают реальный прирост, а где могут стать источником неожиданных проблем.
Видео: https://youtu.be/ADrKGEWGVig
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
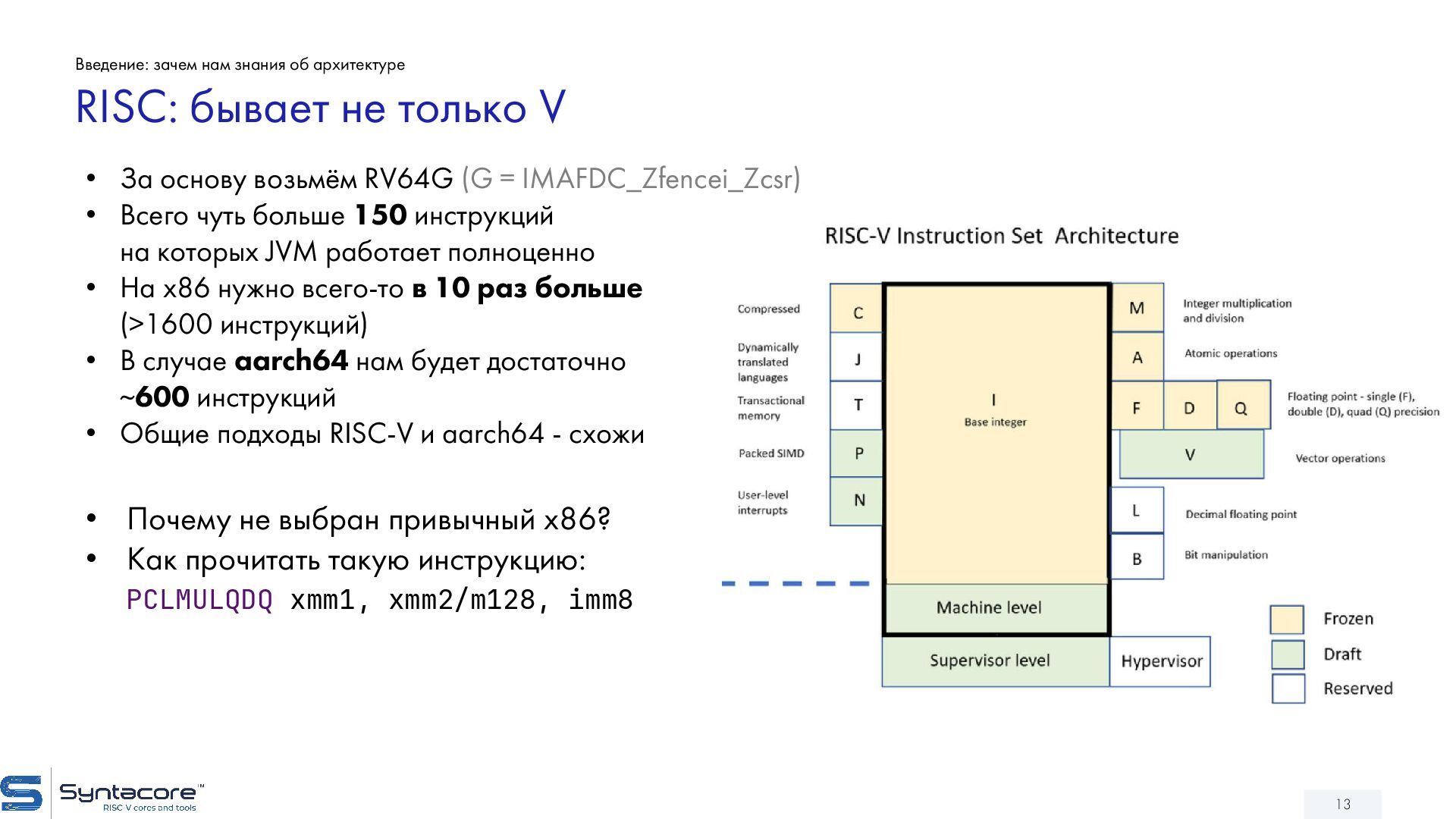{kind=link}
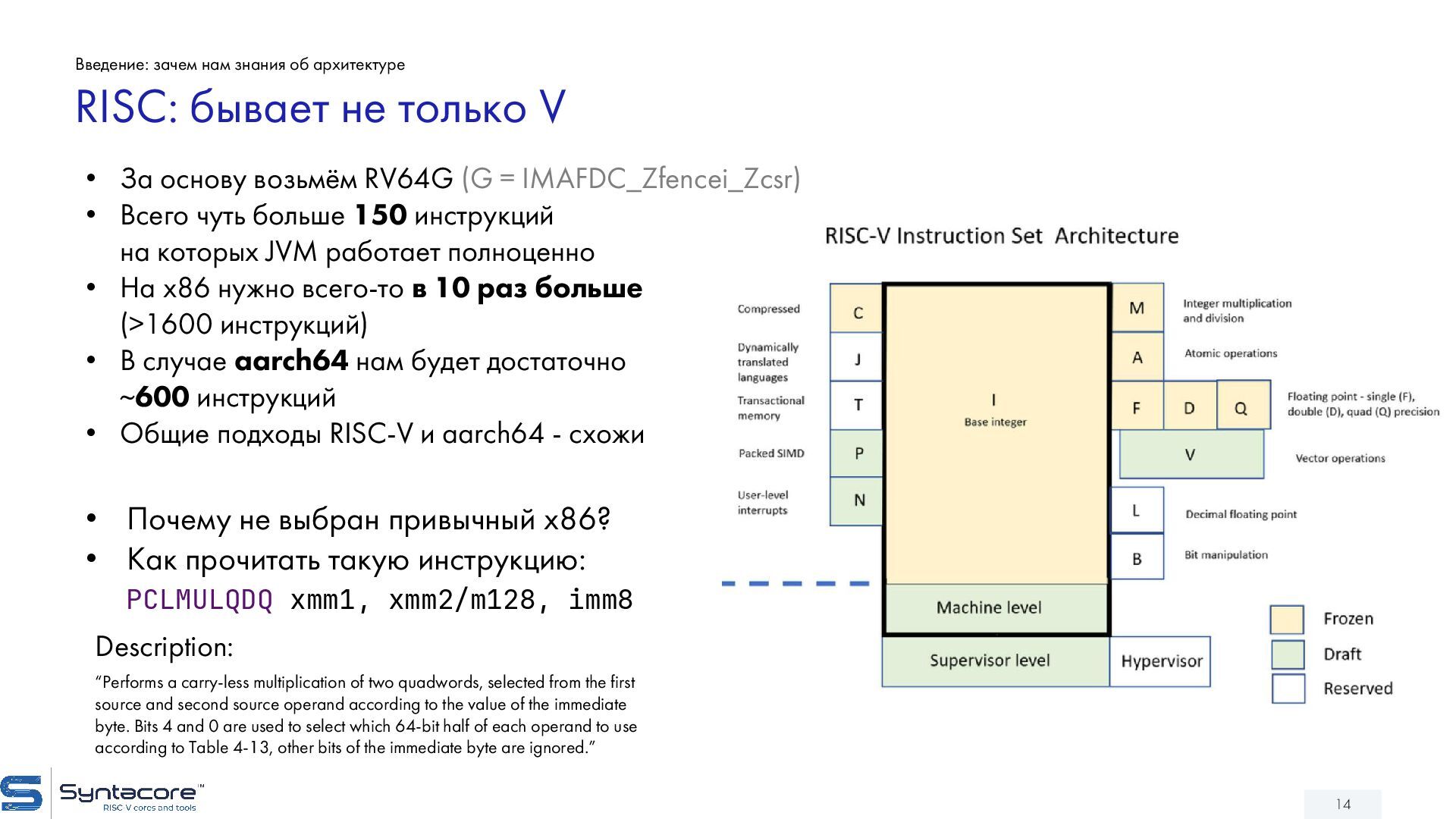{kind=link}
{kind=link}
{kind=link}
{kind=link}
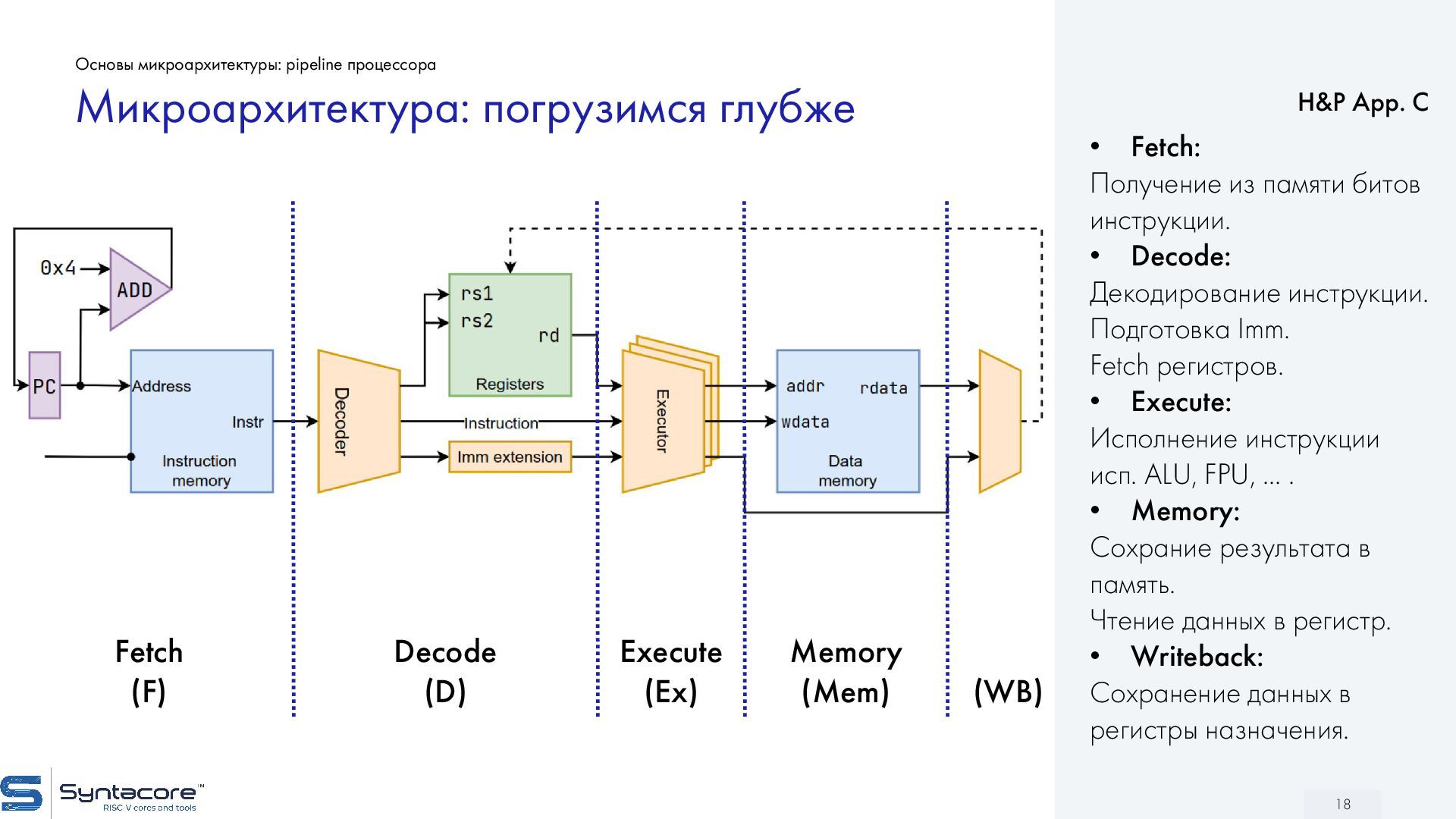{kind=link}
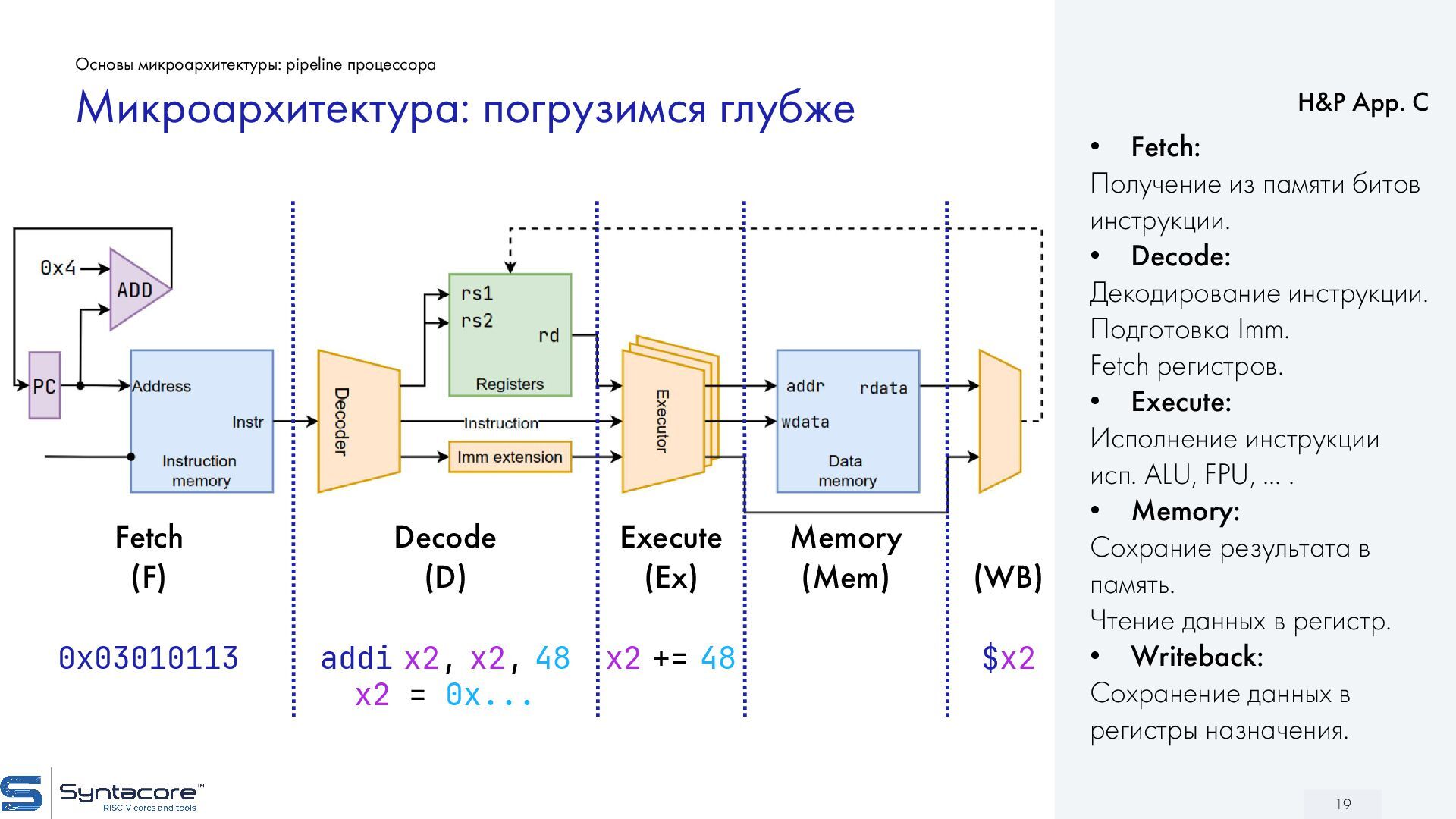{kind=link}
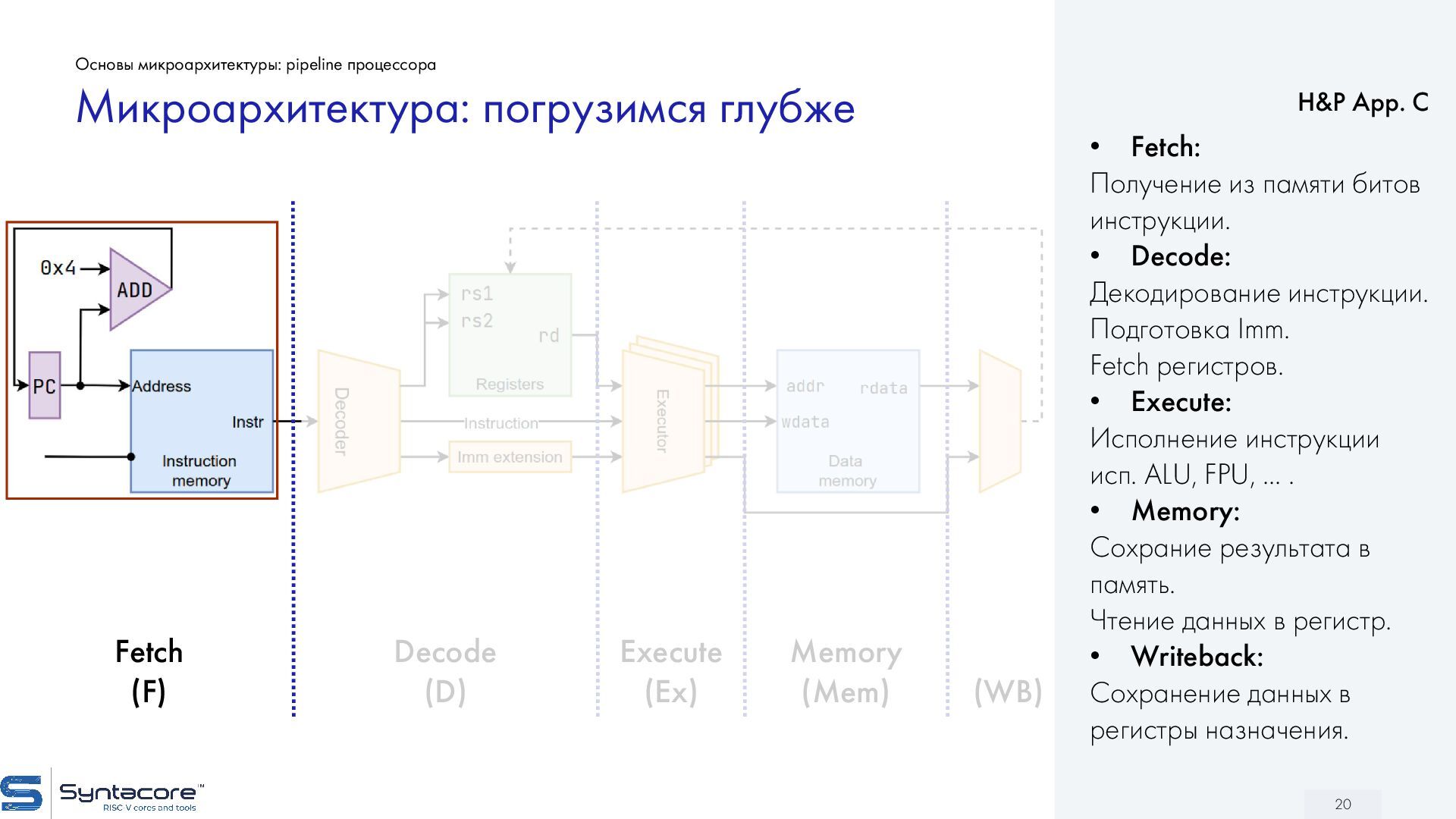{kind=link}
{kind=link}
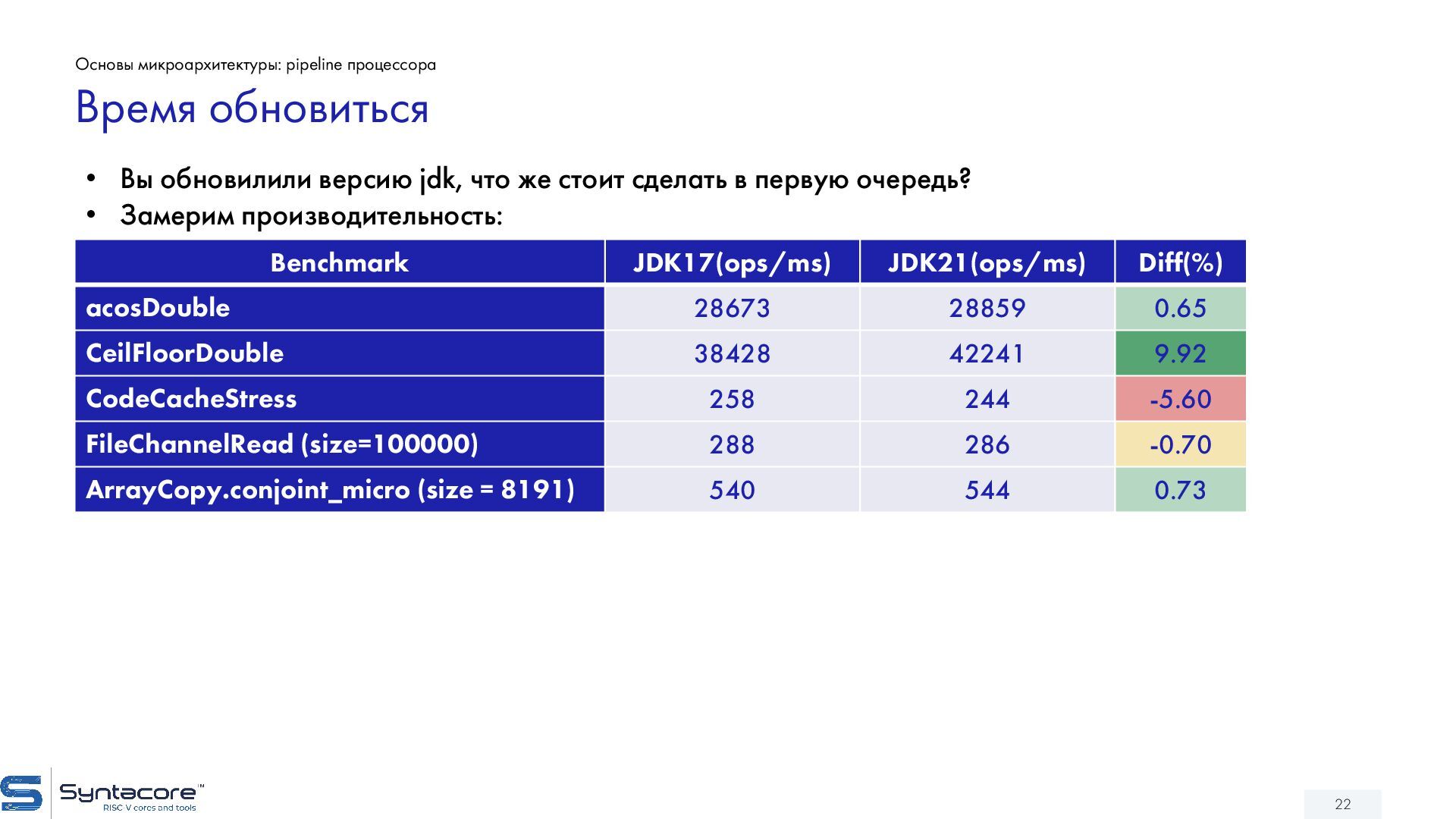{kind=link}
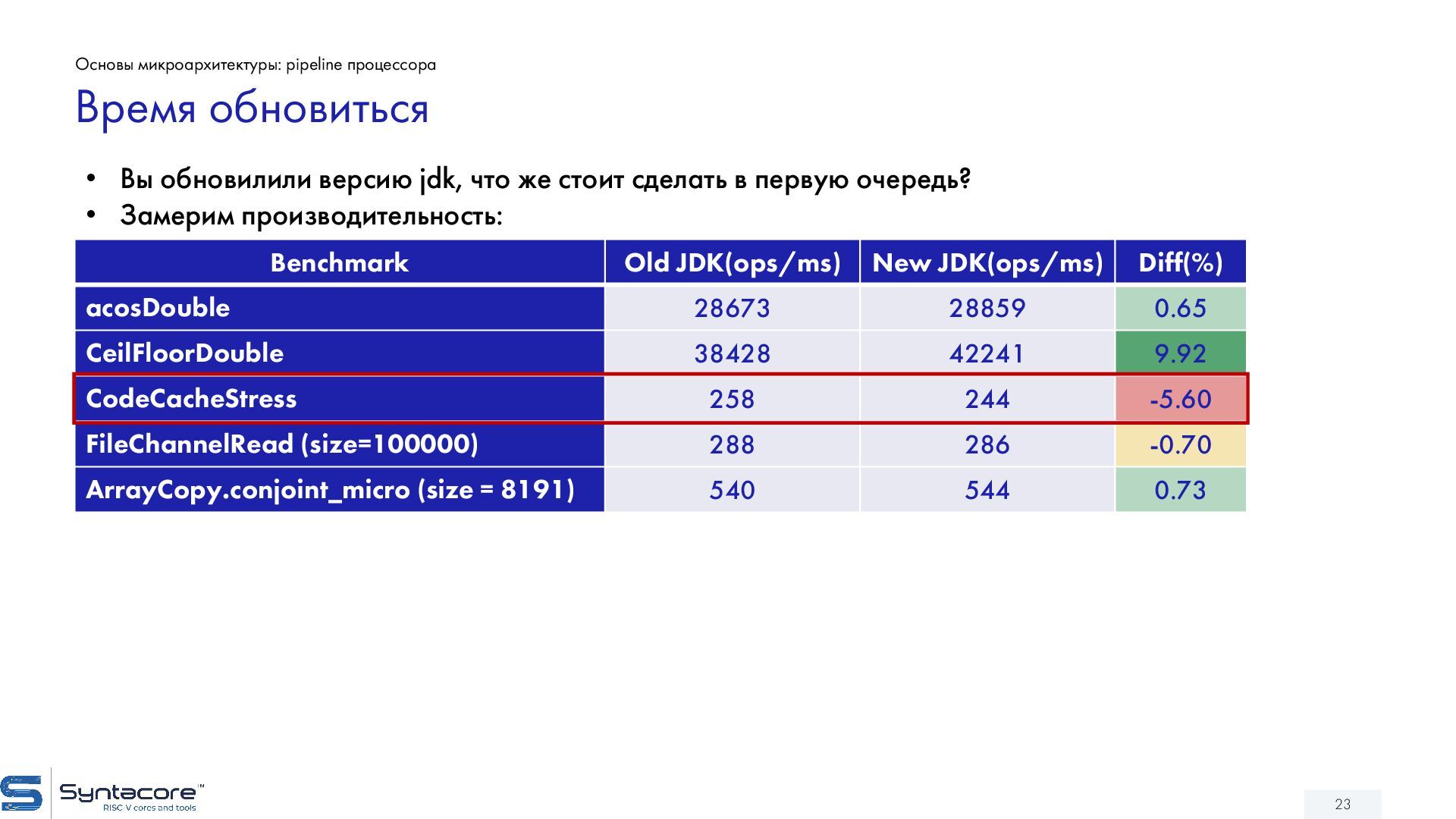{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
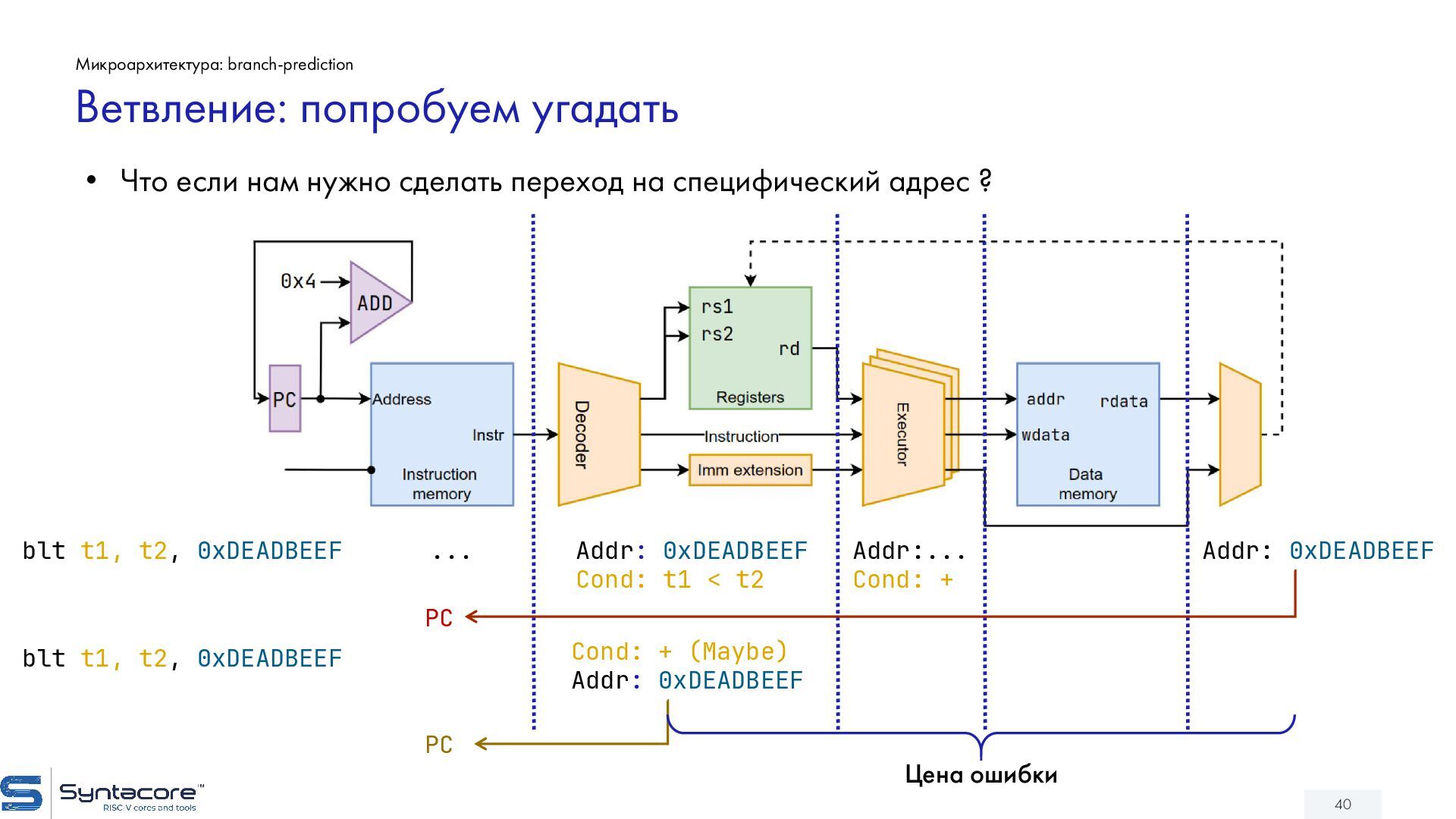{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
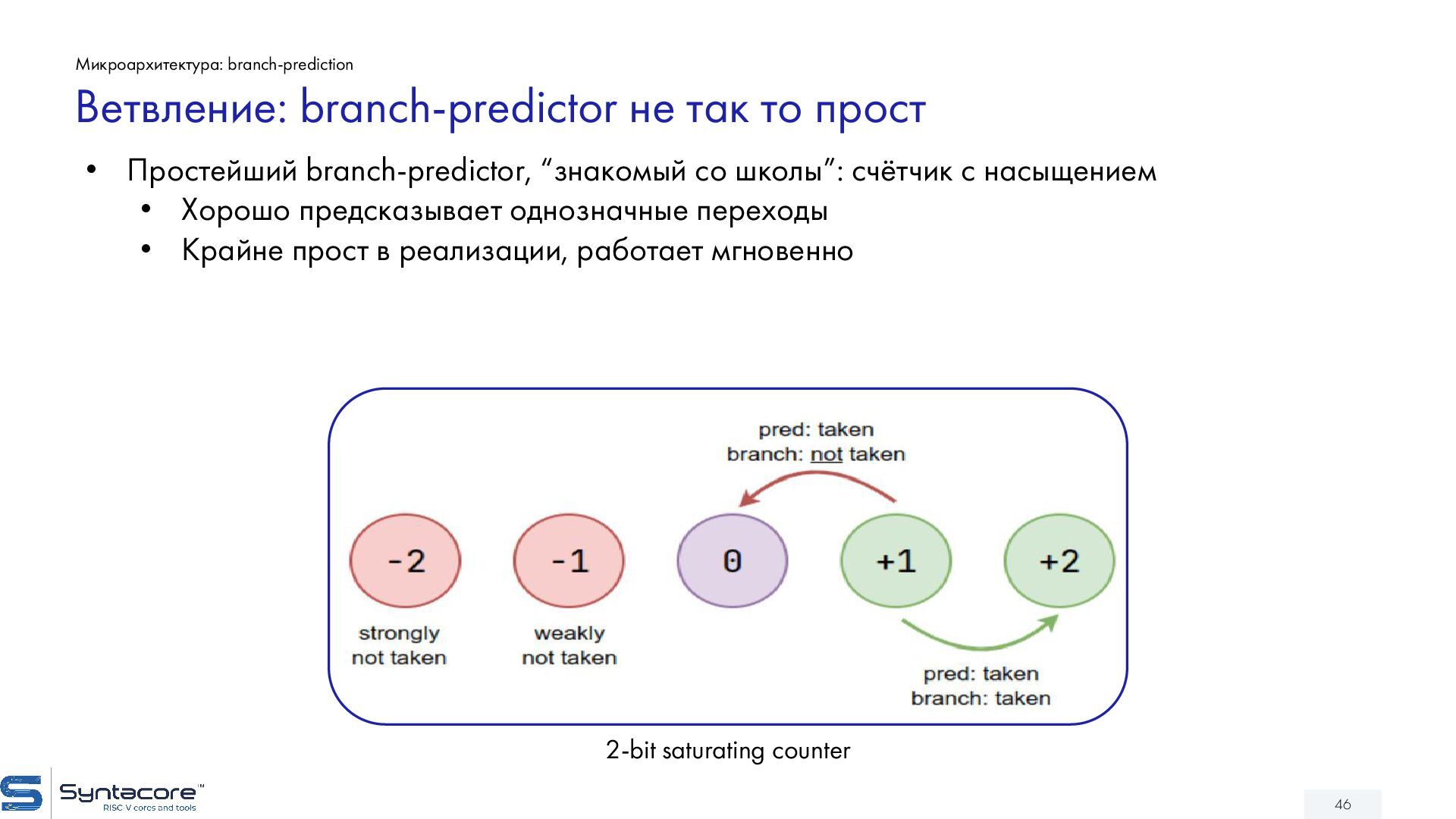{kind=link}
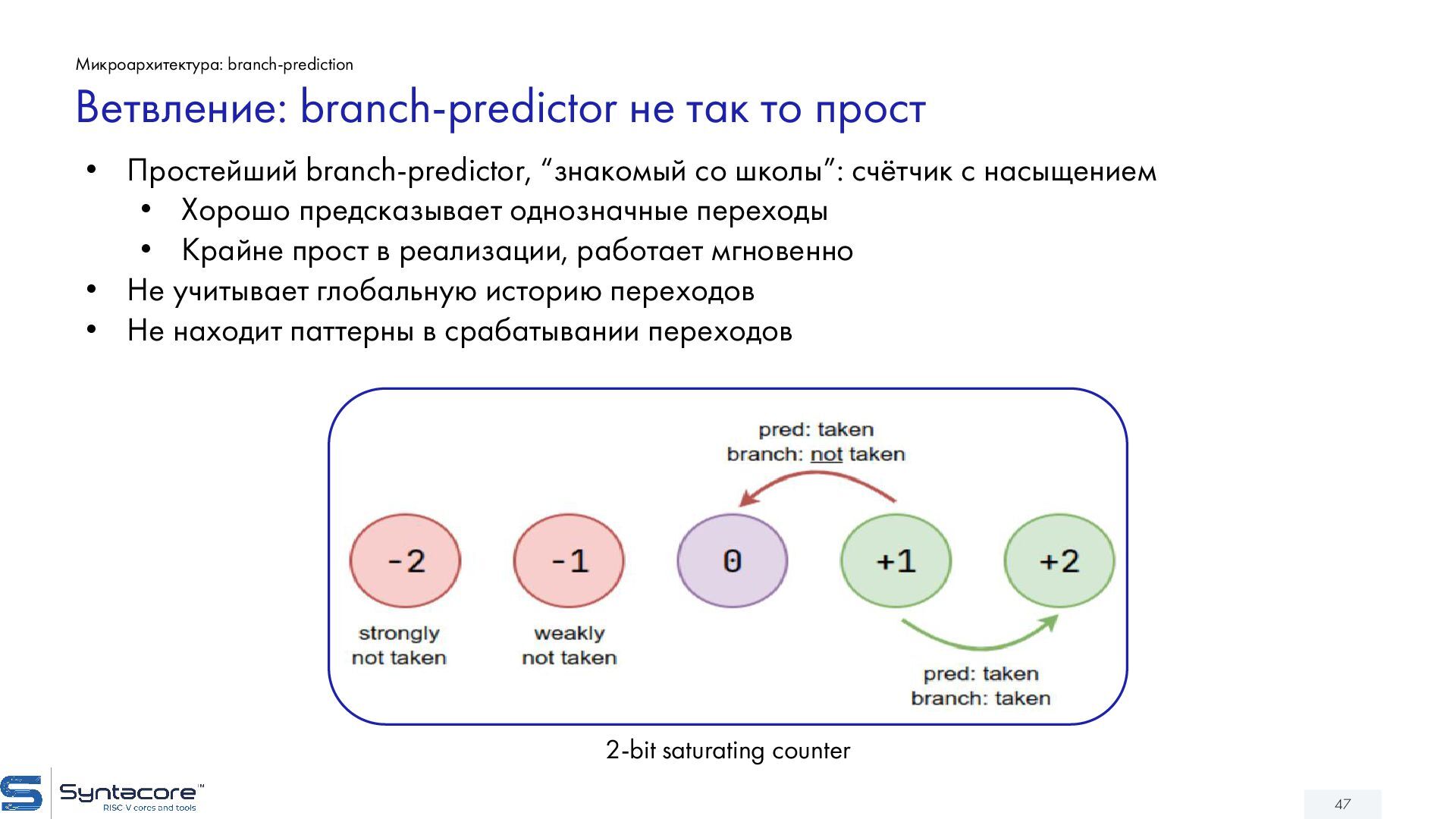{kind=link}
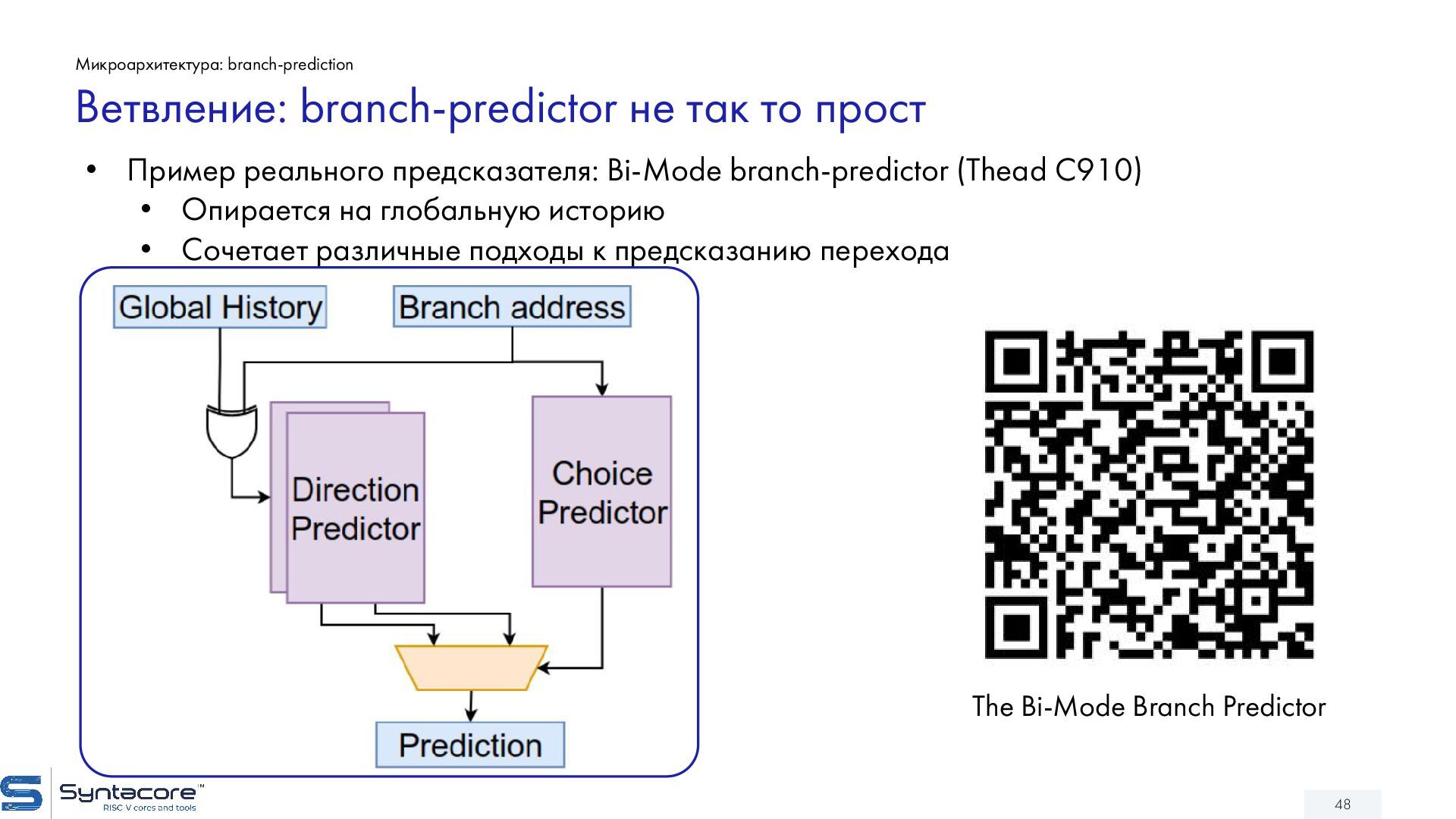{kind=link}
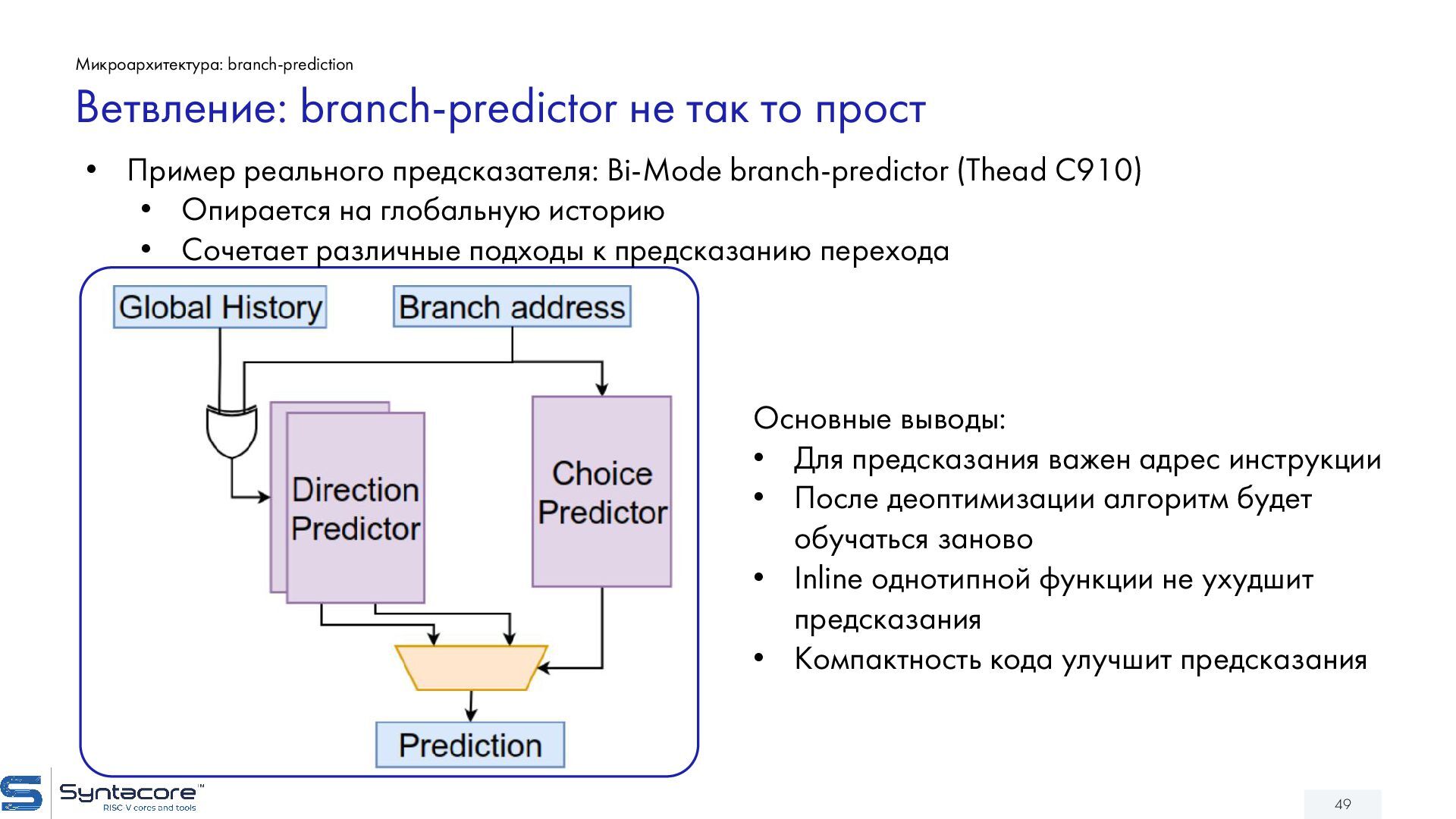{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
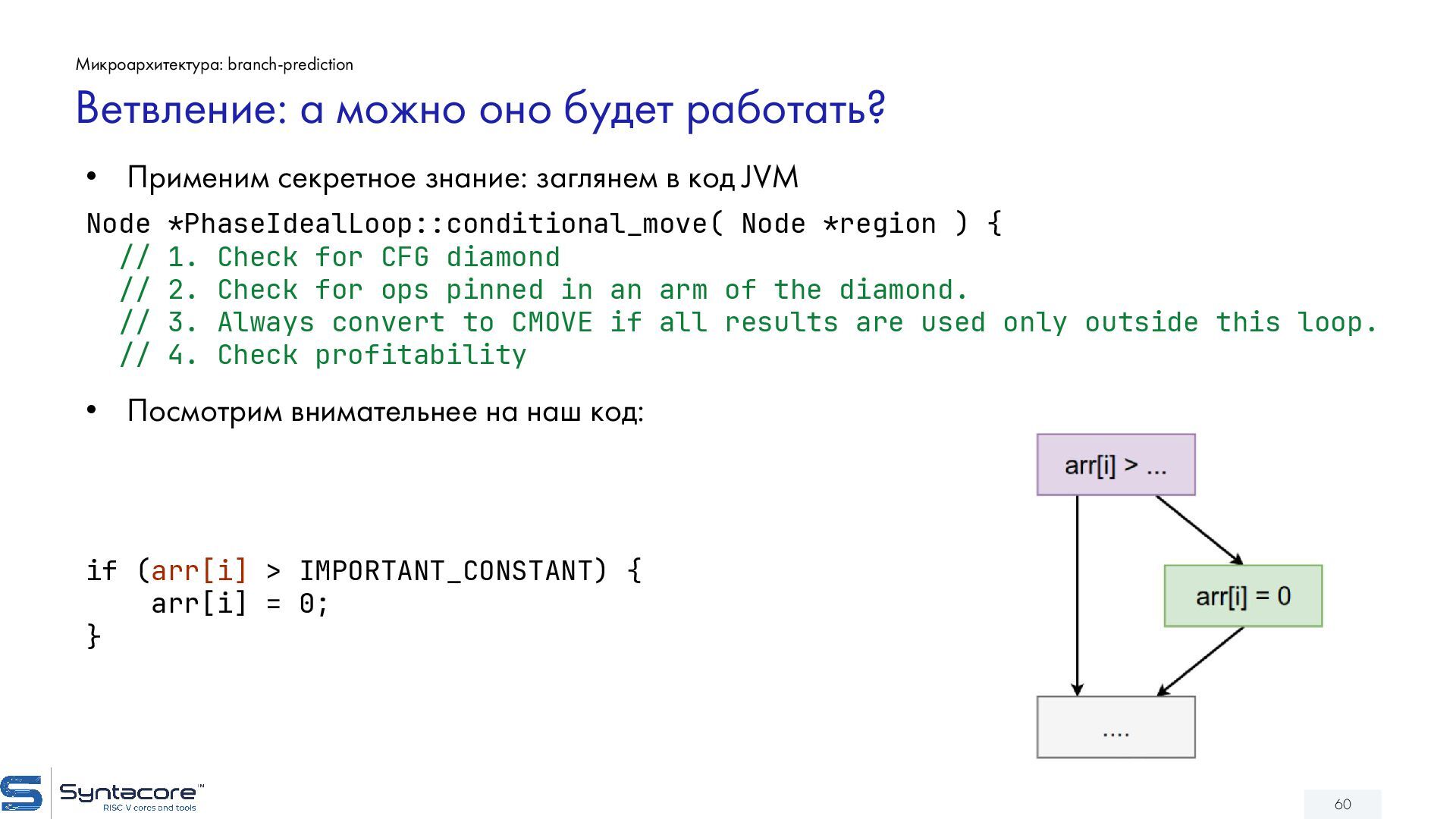{kind=link}
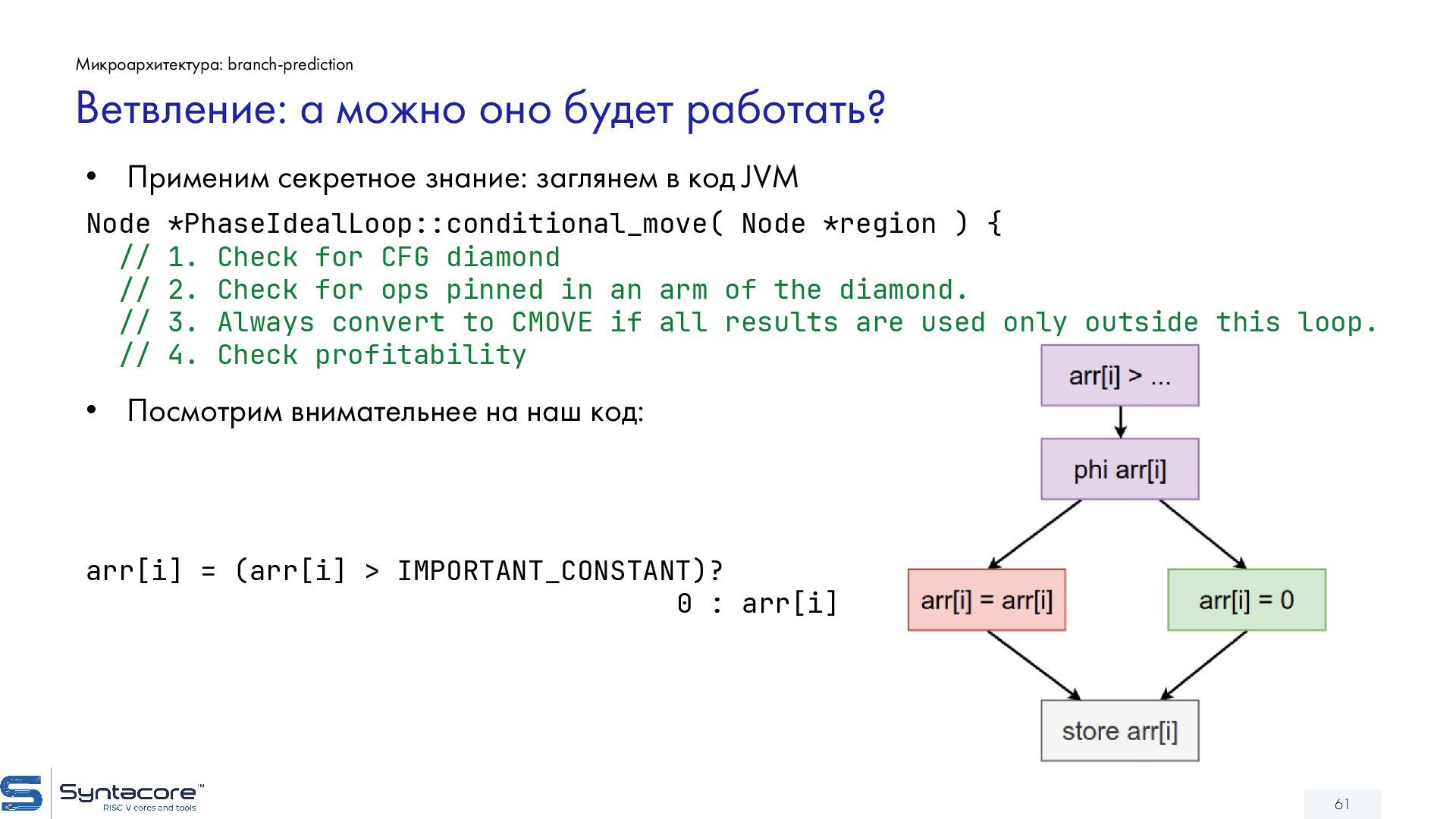{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
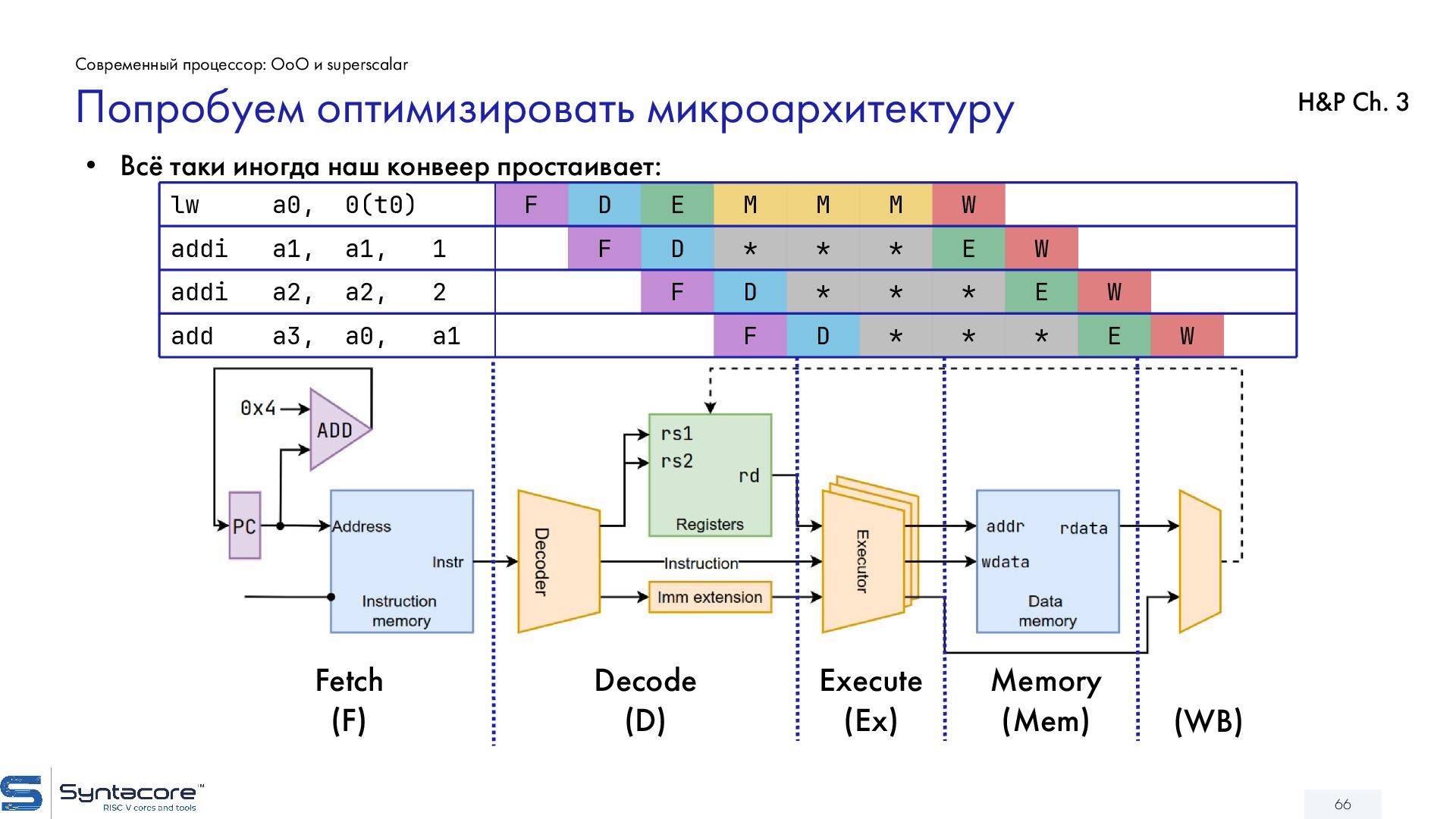{kind=link}
{kind=link}
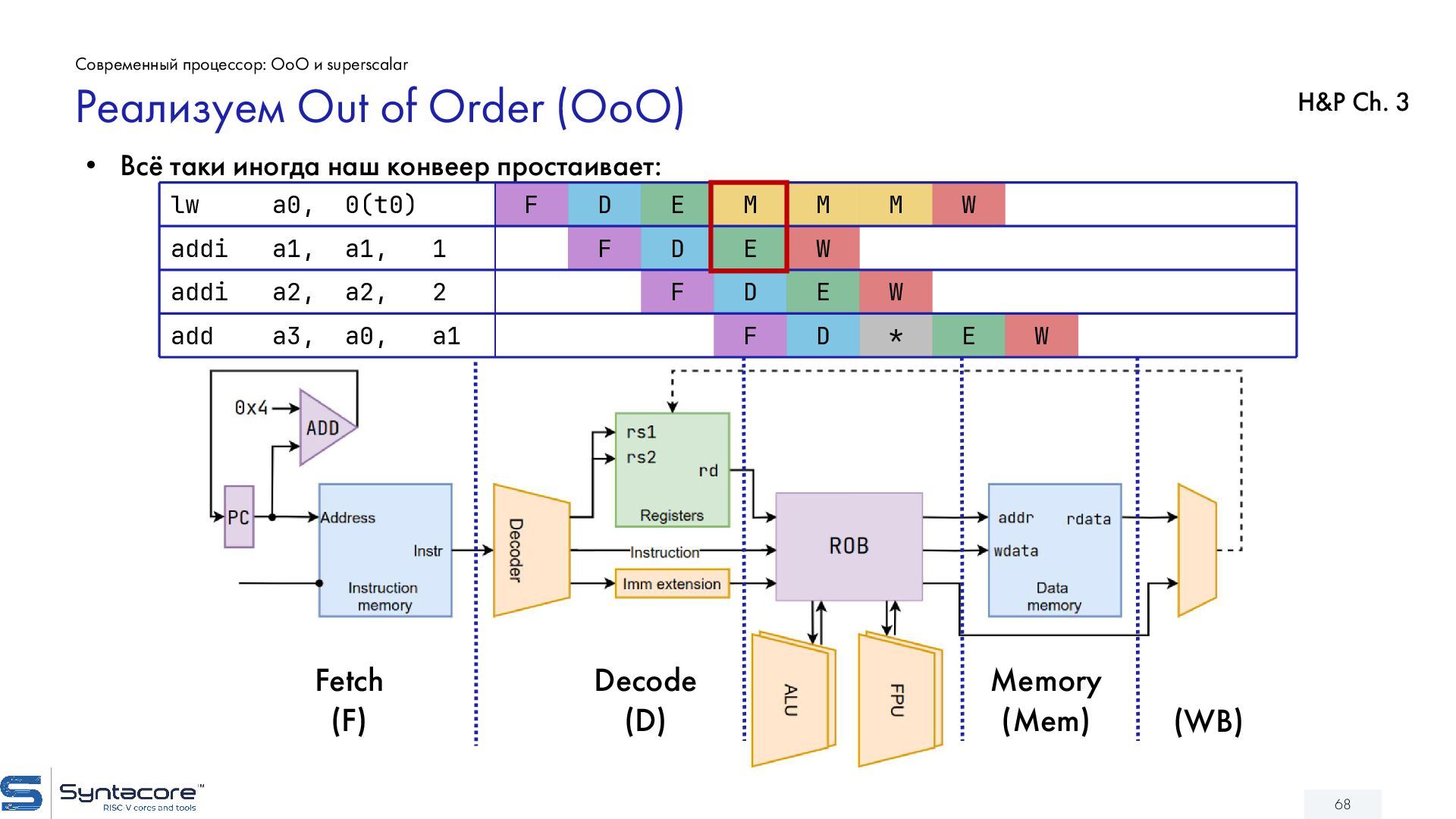{kind=link}
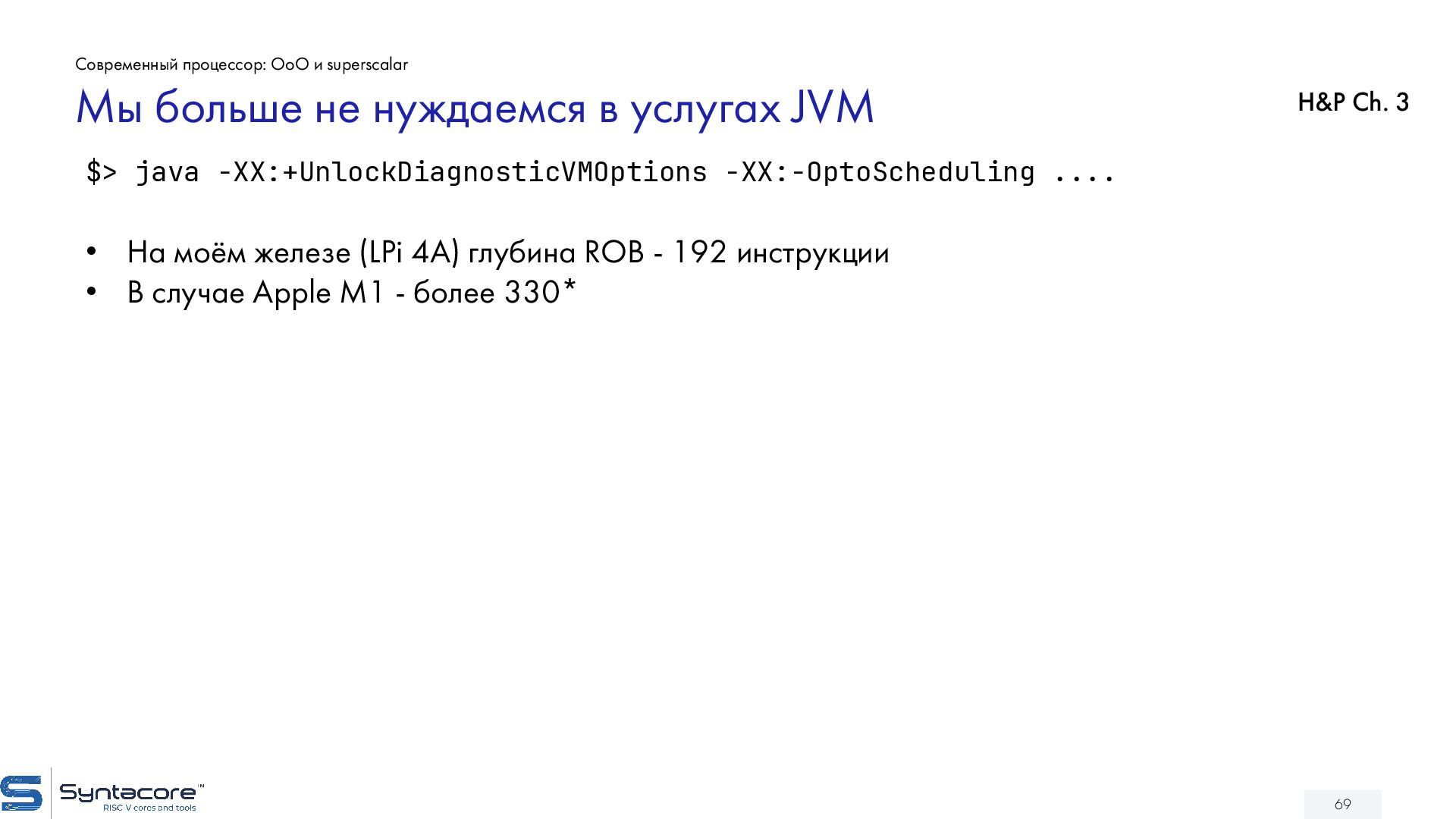{kind=link}
{kind=link}
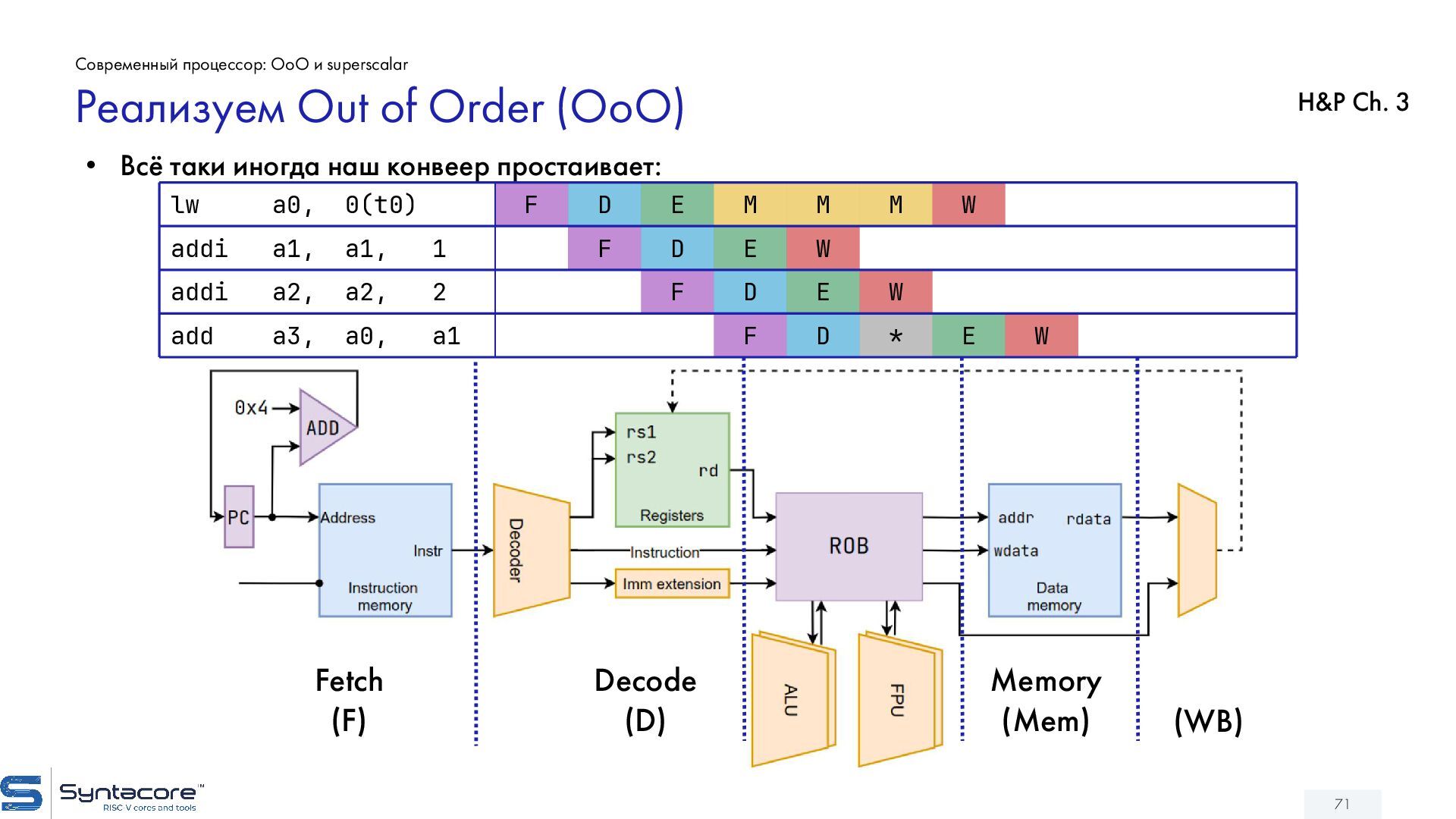{kind=link}
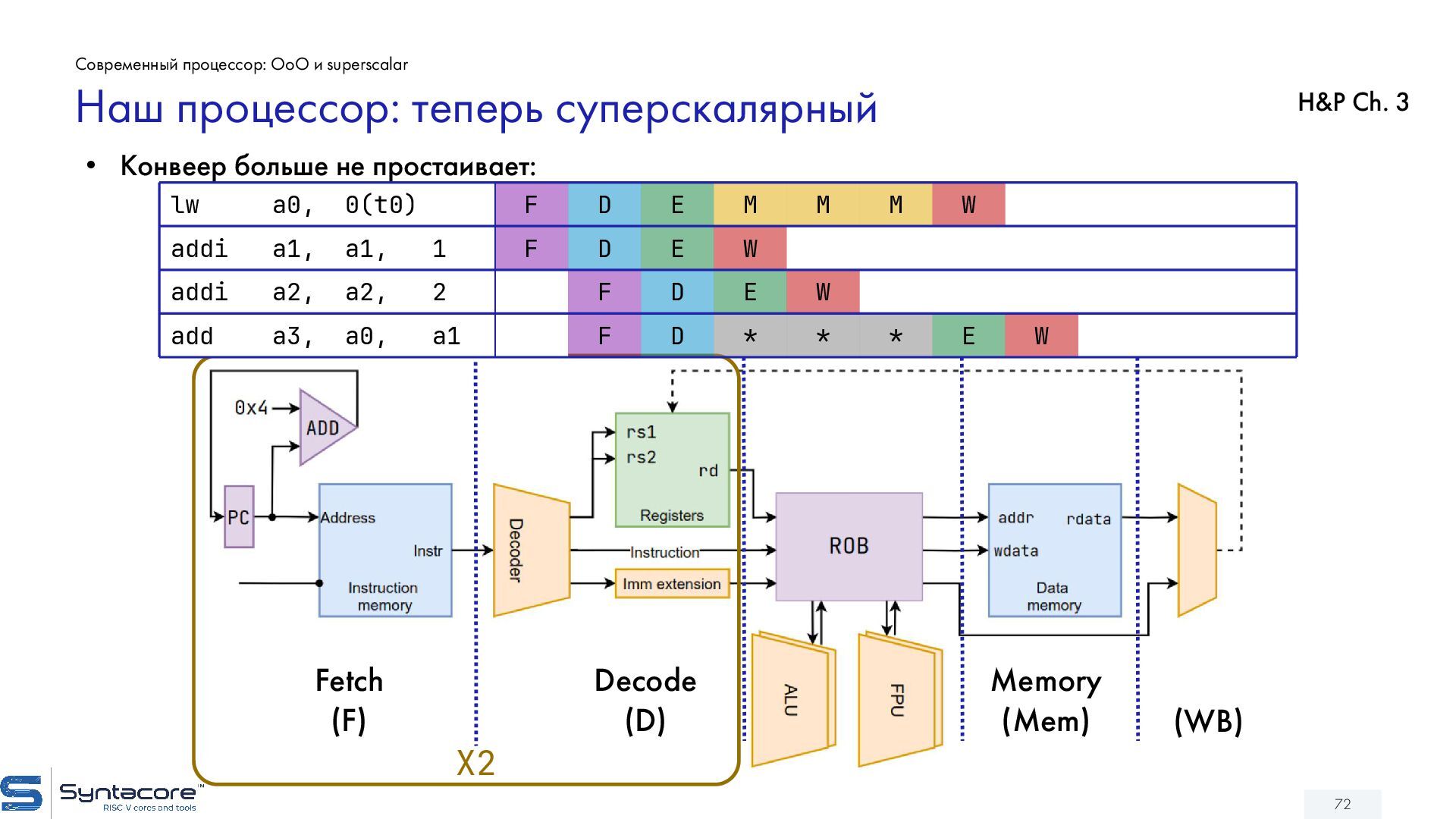{kind=link}
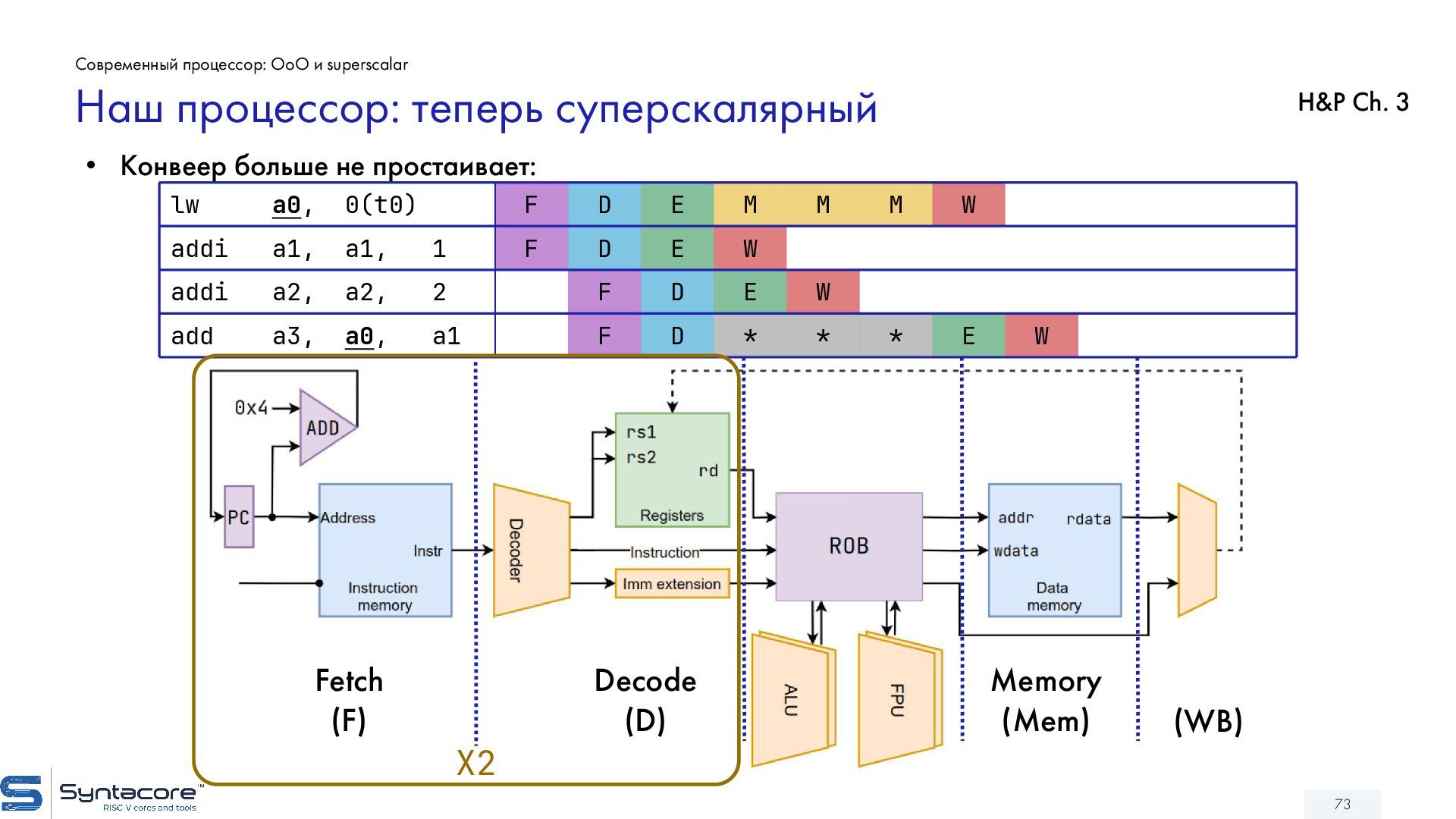{kind=link}
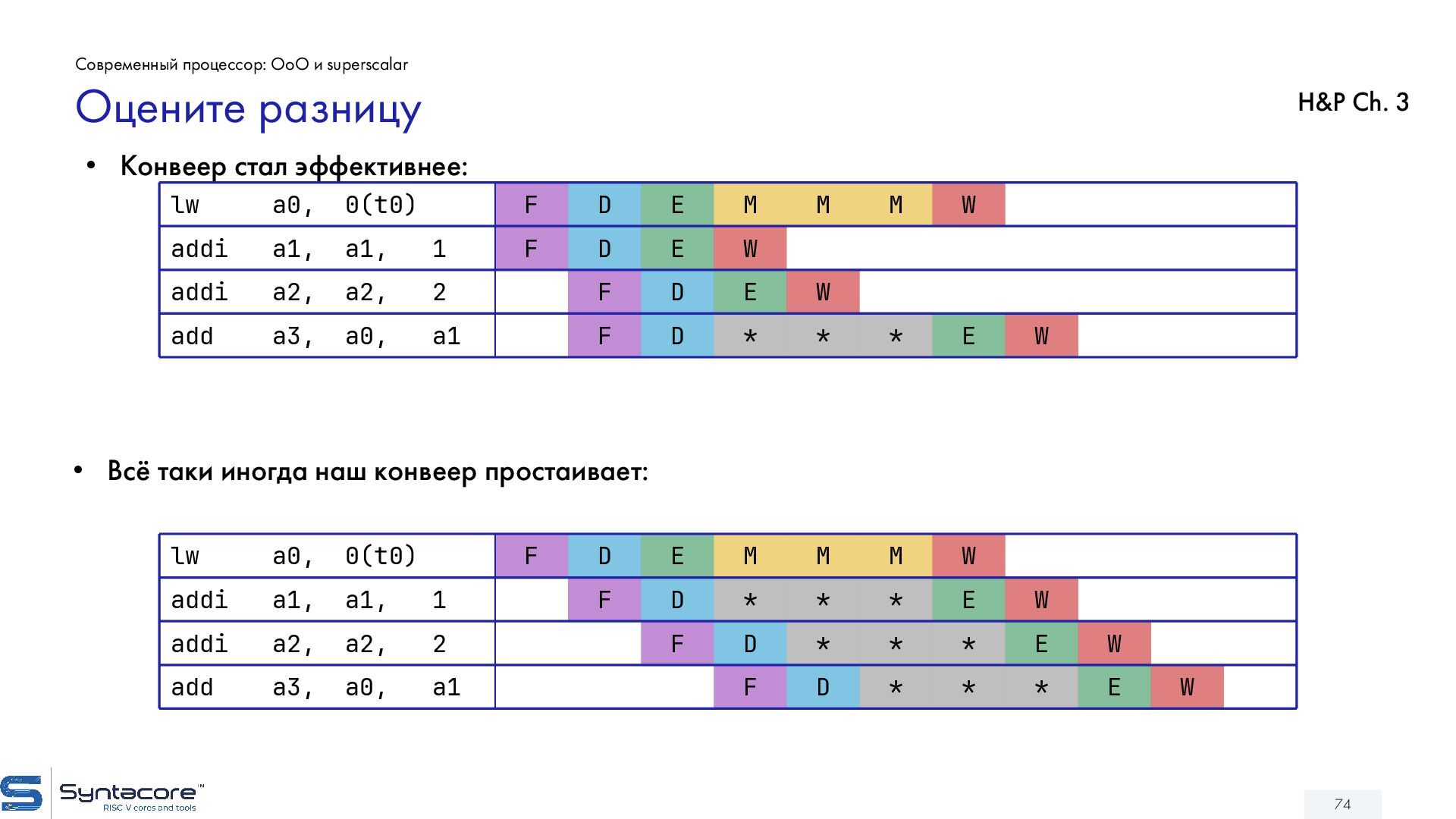{kind=link}
{kind=link}
{kind=link}
{kind=link}
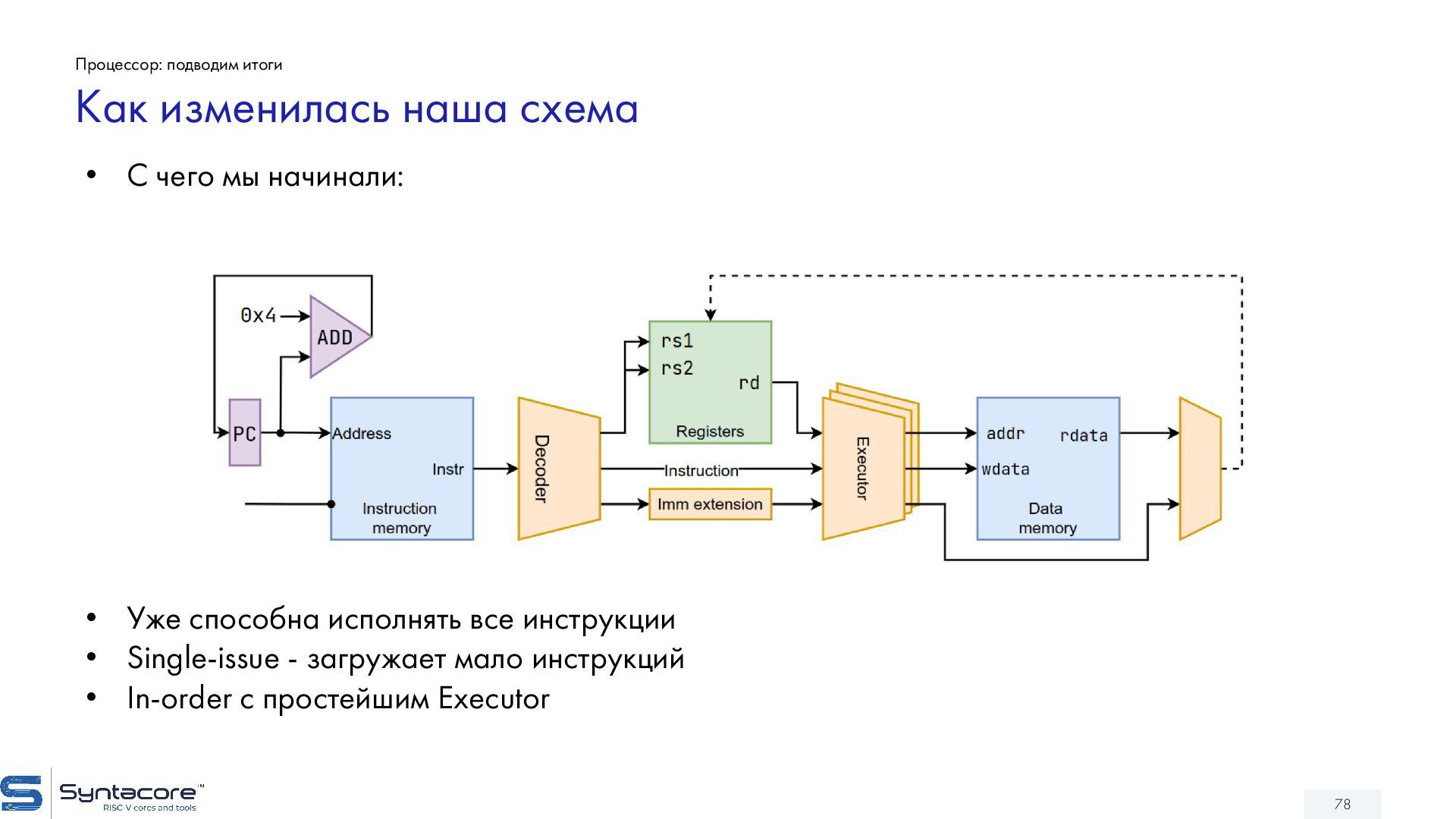{kind=link}
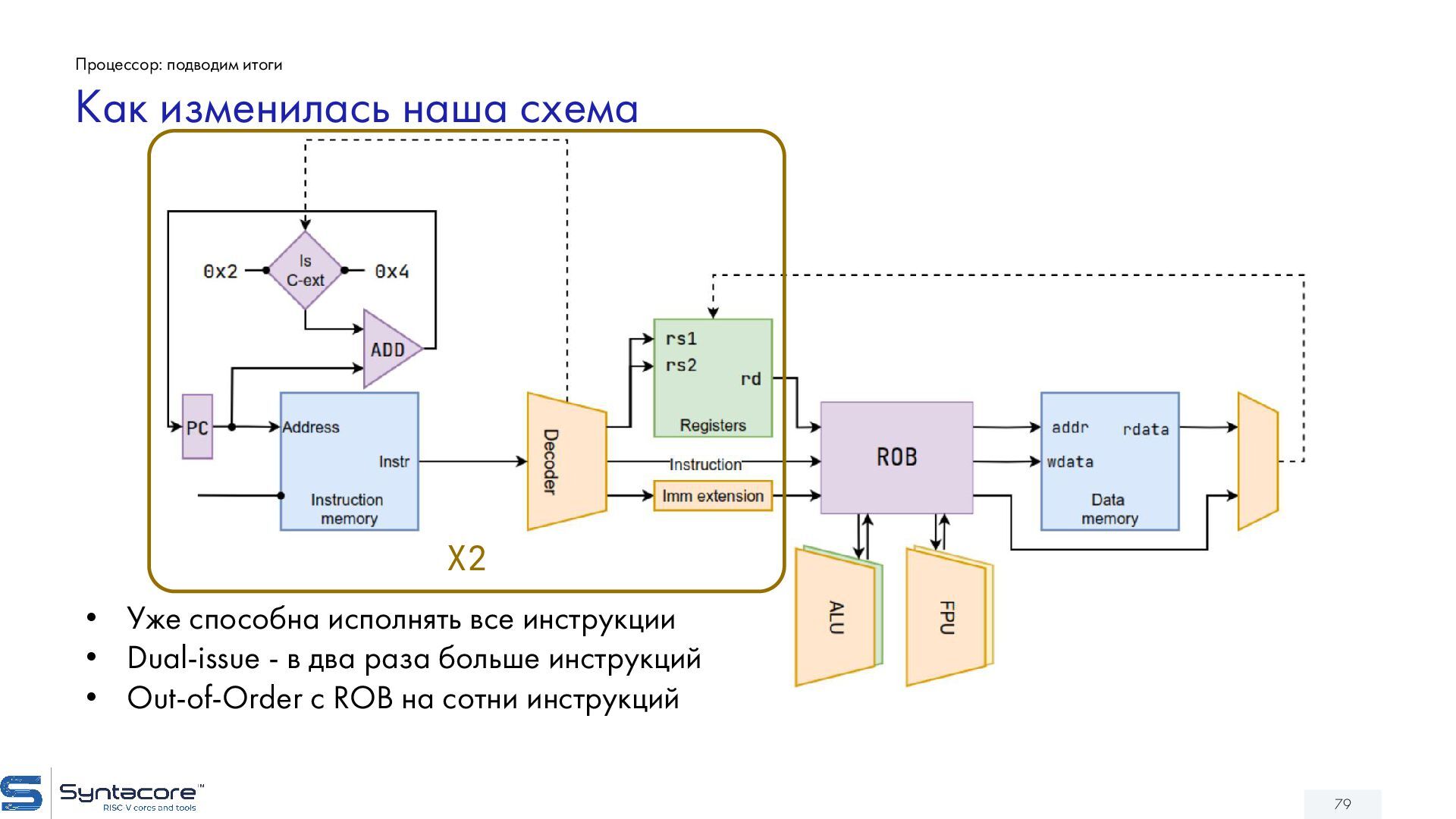{kind=link}
{kind=link}
{kind=link}