Xiaofeng Gao1, Qiaozi Gao2, Ran Gong1, Kaixiang Lin2, Govind Thattai2, Gaurav Sukhatme2,3 (1UCLA, 2Amazon Alexa AI, 3USC Viterbi School of Engineering) IEEE RA-L 2022 慶應義塾大学 杉浦孔明研究室 是方諒介 Gao, X., Qiaozi, G., Ran, G., Kaixiang, L., Govind, T., Gaurav, S. "DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following." IEEE RA-L 7.4 (2022): 10049-10056.
{kind=link}
{kind=link}
![背景:自然言語指示による家事タスク実行 ◼ ALFRED [Shridhar+, CVPR20] ◼ 物体操作を含むVision-and-Language Navigationタスクの標準ベンチマーク ◼ 抽象度の異なる指示文が存在](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼ 前提:3種類の質問テンプレート 1) Location: “where is [object]?” 2) Appearance: “what](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![② Performer:Episodic Transformer [Pashevich+, ICCV21] ◼ transformerを用いて,画像・言語・行動に関する過去の系列をエンコード ◼ 訓練集合において考えられるすべての質問とoracle answerで事前学習](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_10.jpg){kind=link}
![実験設定:DialFREDベンチマーク ◼ シミュレータ:AI2-THOR [Kolve+, 17] ◼ 1000ステップ超過または10回以上の行動失敗で終了 ◼ 評価指標 ①](https://files.speakerdeck.com/presentations/09dbf5f44fc649228d5d28f46eece101/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
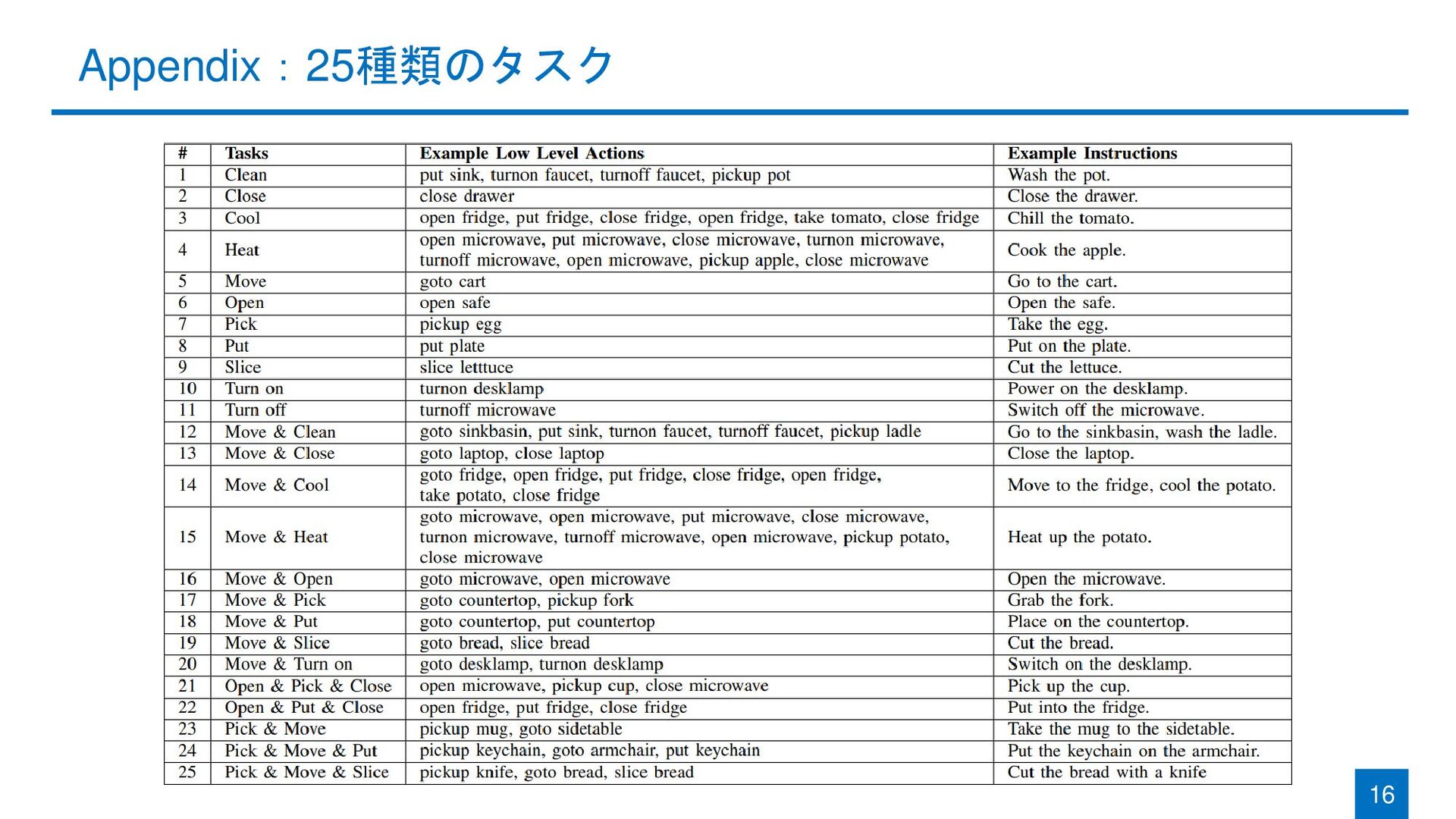{kind=link}