Zhengyuan Yang2, Feng Li4, Hao Zhang4, Shilong Liu5, Arul Aravinthan1, Yong Lee1, Lijuan Wang2, 1UW-Madison, 2Microsoft, 3UC Berkeley, 4HKUST, 5Tsinghua University Interfacing Foundation Models’ Embeddings Zou, Xueyan, et al. "Interfacing Foundation Models' Embeddings." arXiv preprint arXiv:2312.07532, 2023. 慶應義塾大学 飯岡雄偉
{kind=link}
![概要:視覚言語間の相互入力/出力を可能に ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_1.jpg){kind=link}
![背景:大規模基盤モデルの制限 ▪ 出力のモダリティが単一なものが多く,制限がある 3 BLIP-2 [Li+, ICML23] VQA → Text](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_2.jpg){kind=link}
![関連研究:基盤モデルをマルチモーダルに拡張 ▪ Prompt engineering:SoM [Yang+, 2023] ◦ ☺入出力のマルチモーダル化 ◦ 基盤モデルが扱うタスクそのものを拡張できて](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_3.jpg){kind=link}
![関連研究:X-Decoder, SEEMにおける基盤モデル ▪ X-Decoder [Zou+, CVPR23] ◦ マルチモーダル/タスクの基盤モデル ◦ 統一されたdecoderで複数タスクを扱う](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_4.jpg){kind=link}
{kind=link}
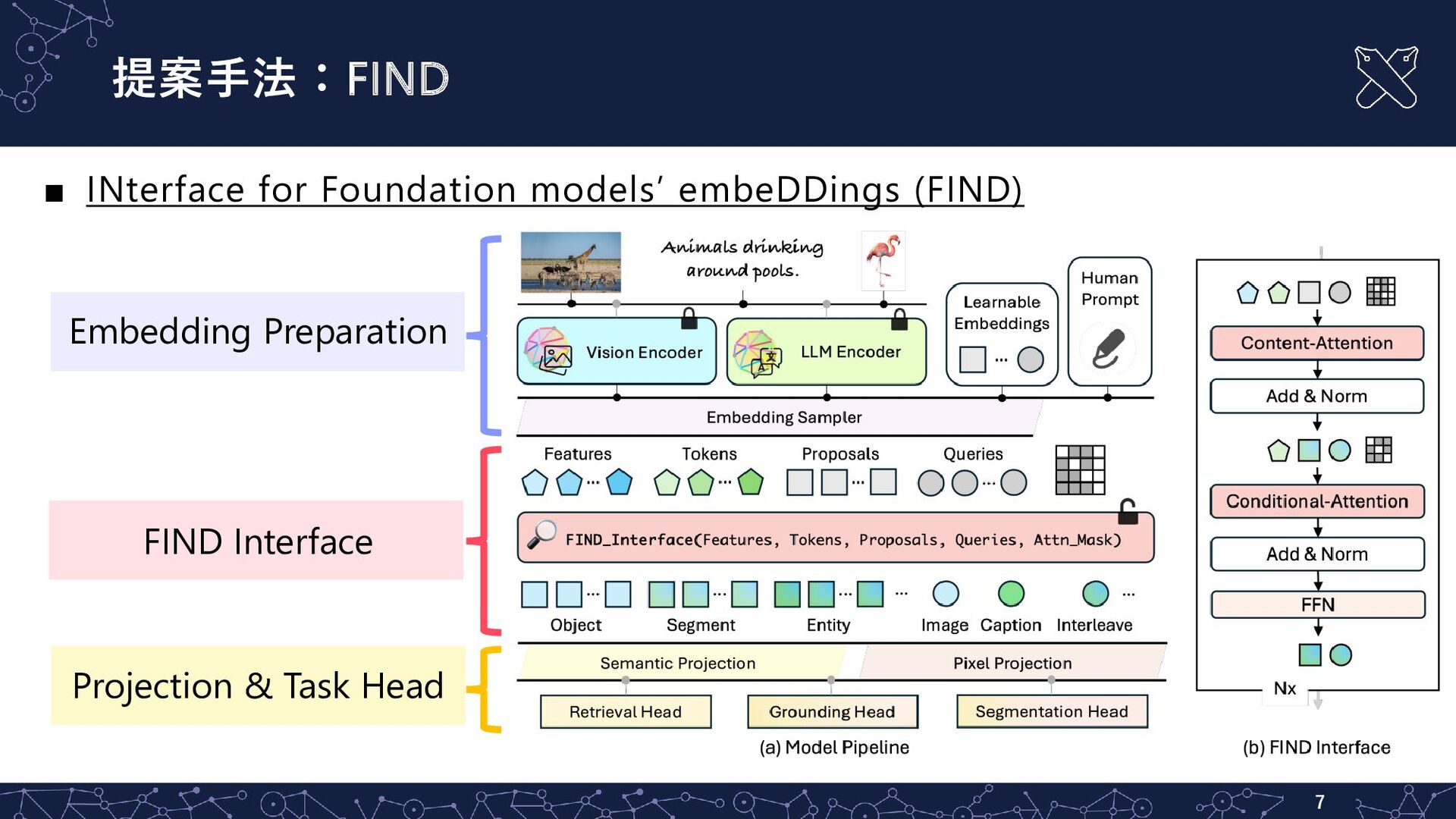{kind=link}
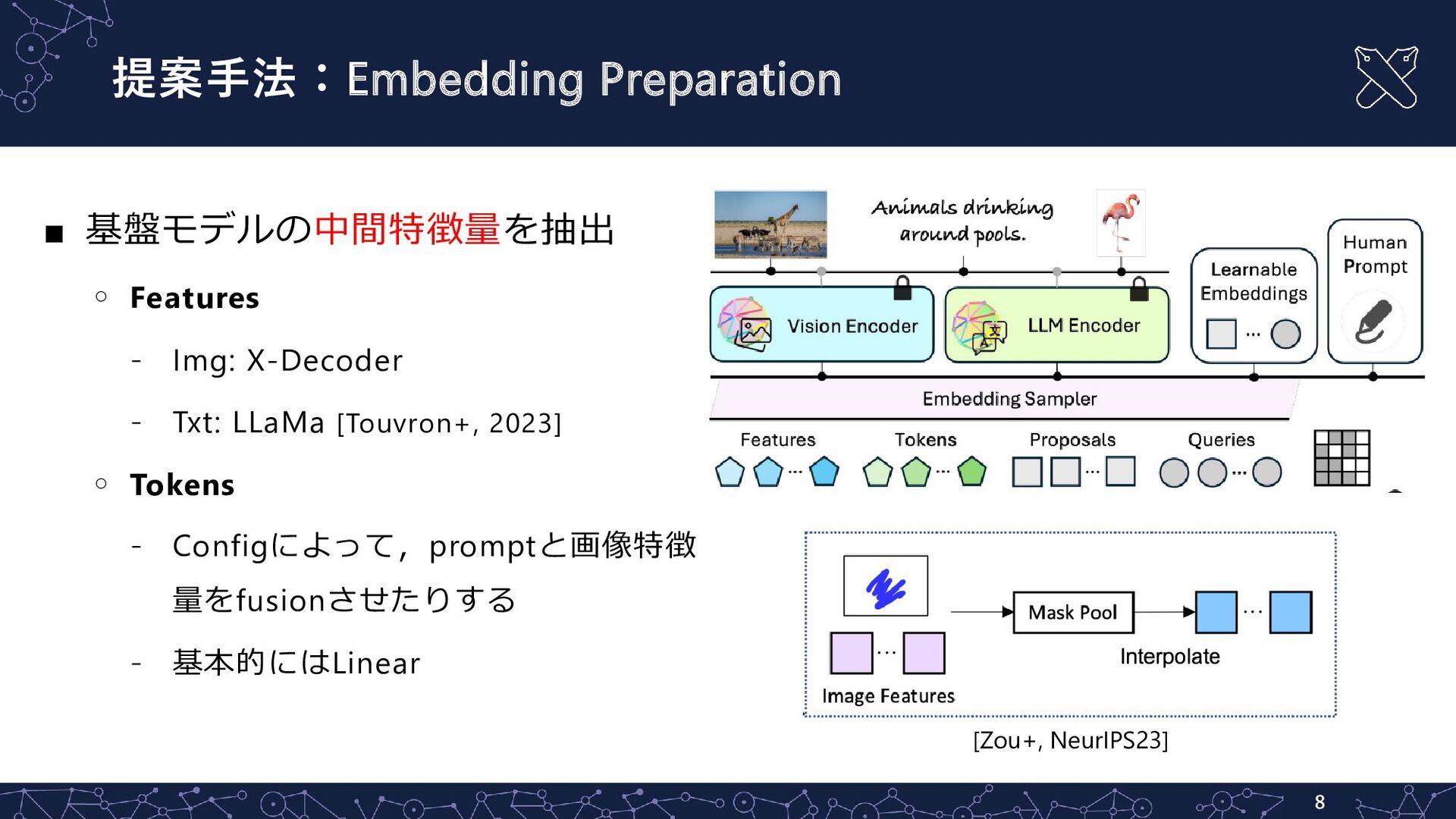{kind=link}
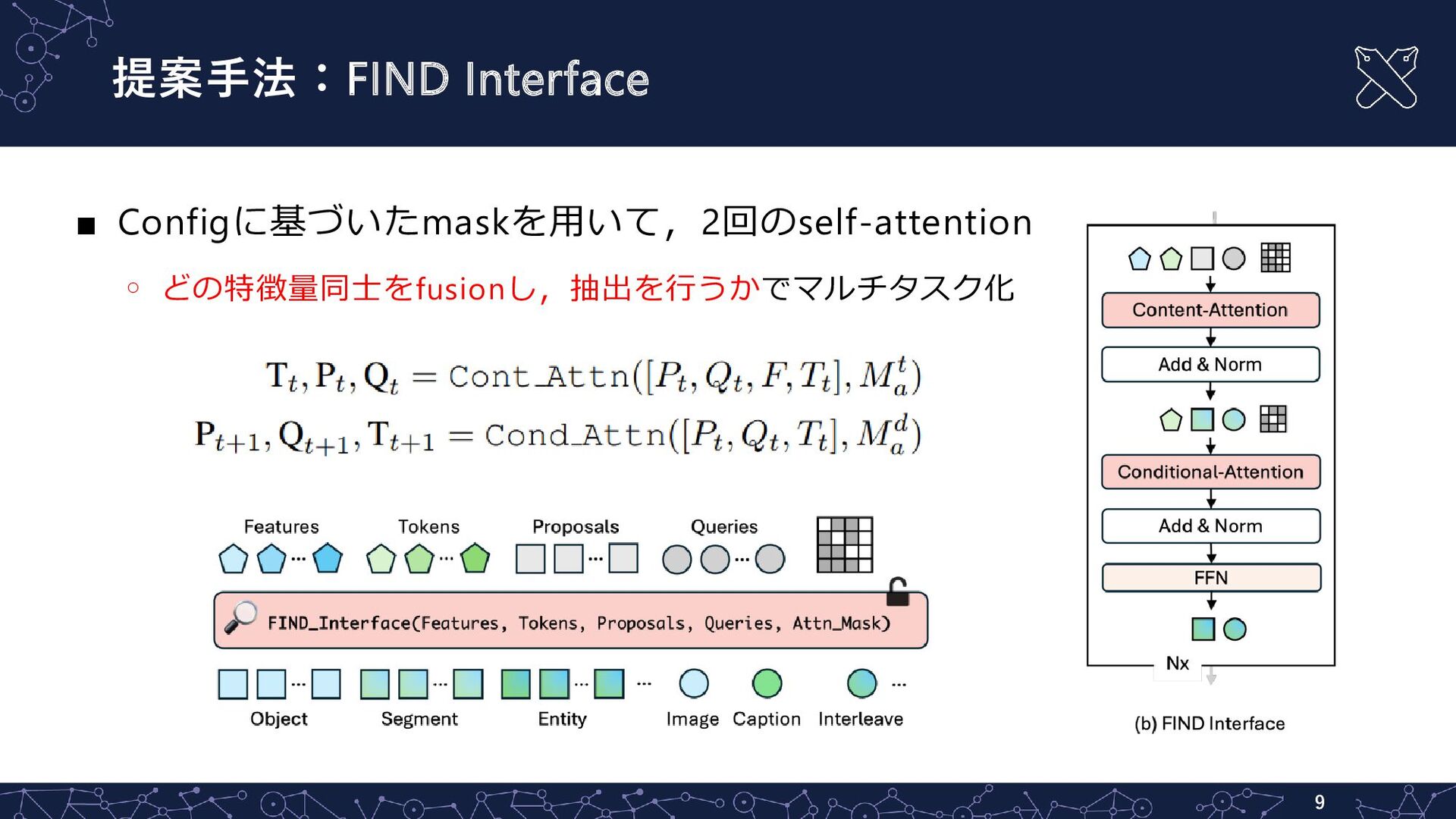{kind=link}
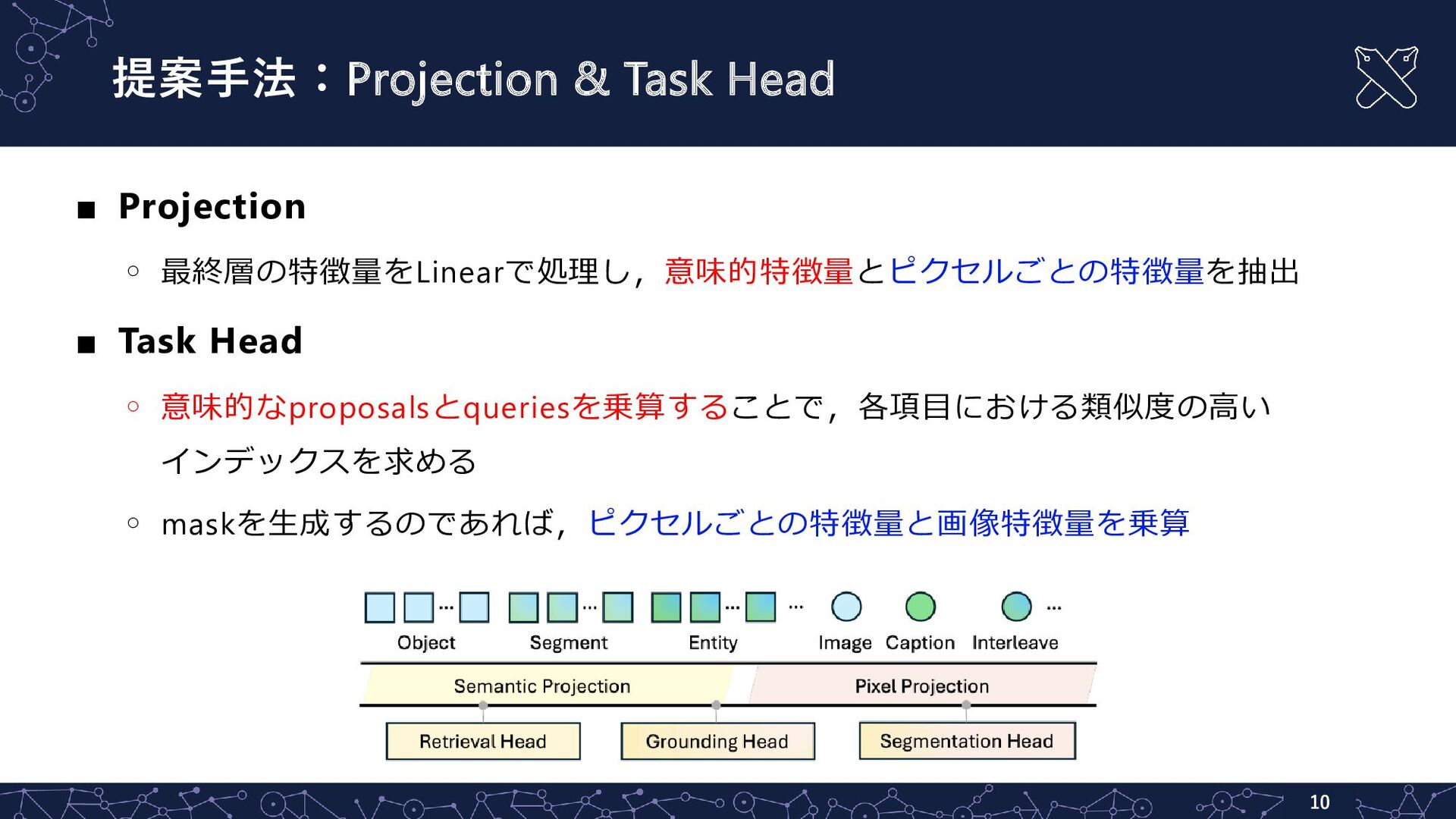{kind=link}
{kind=link}
{kind=link}
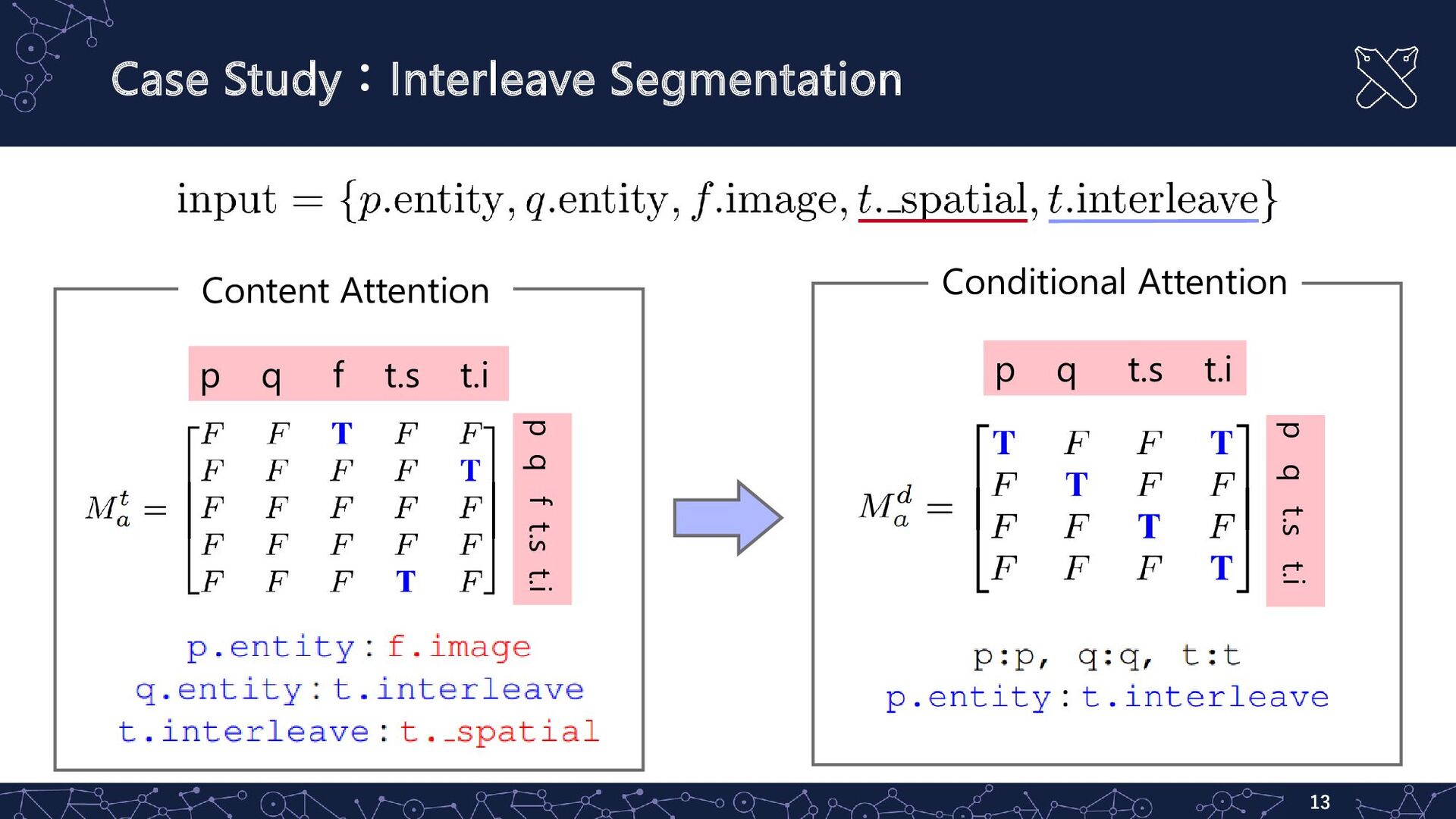{kind=link}
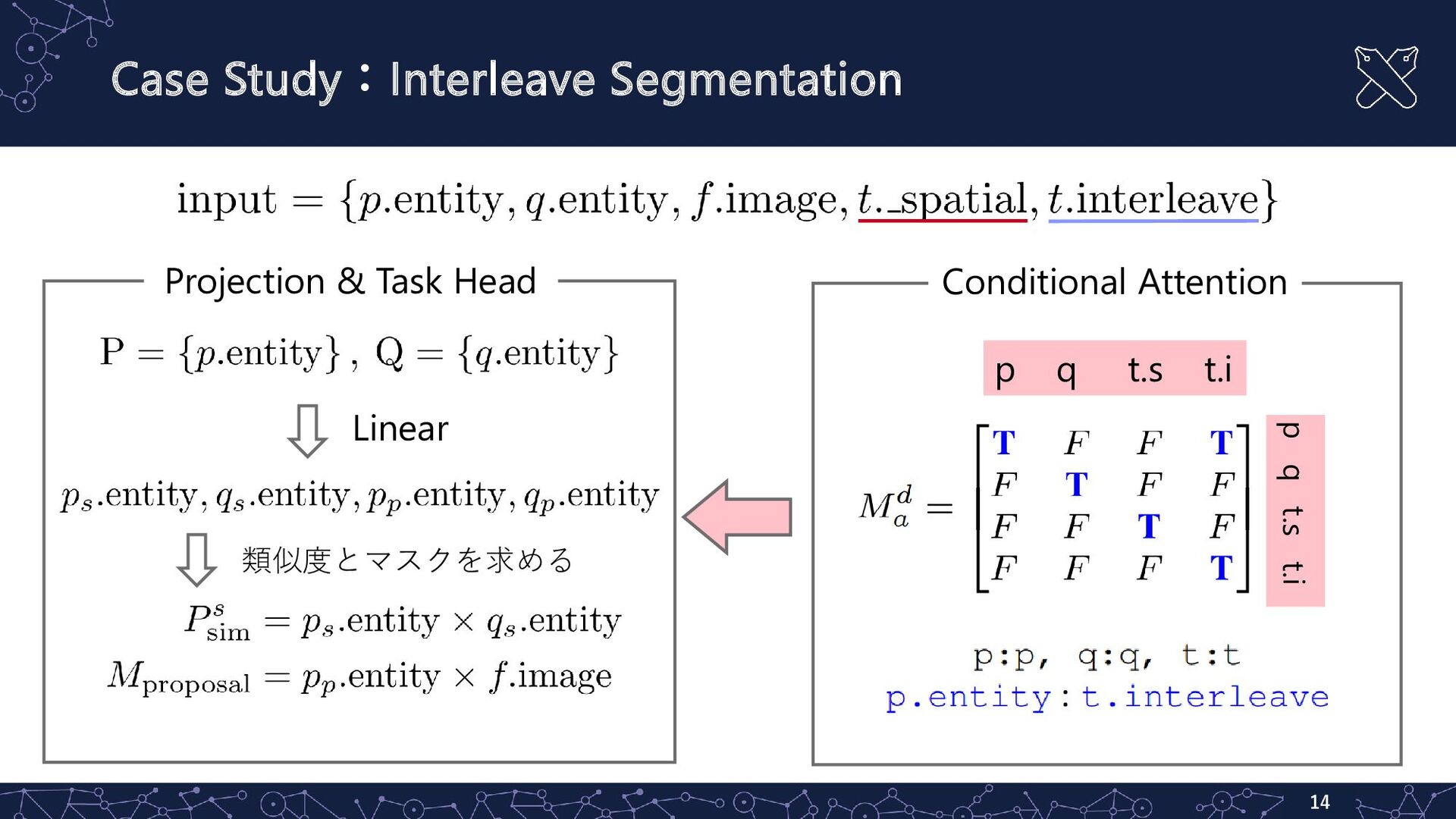{kind=link}
![実験設定:新たなベンチマークFIND-Bench ▪ データセット ◦ COCO系統のデータセットをGPT-4やLLaVa [Liu+, NeurIPS23]によるcaptionで拡張 15](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_14.jpg){kind=link}
{kind=link}
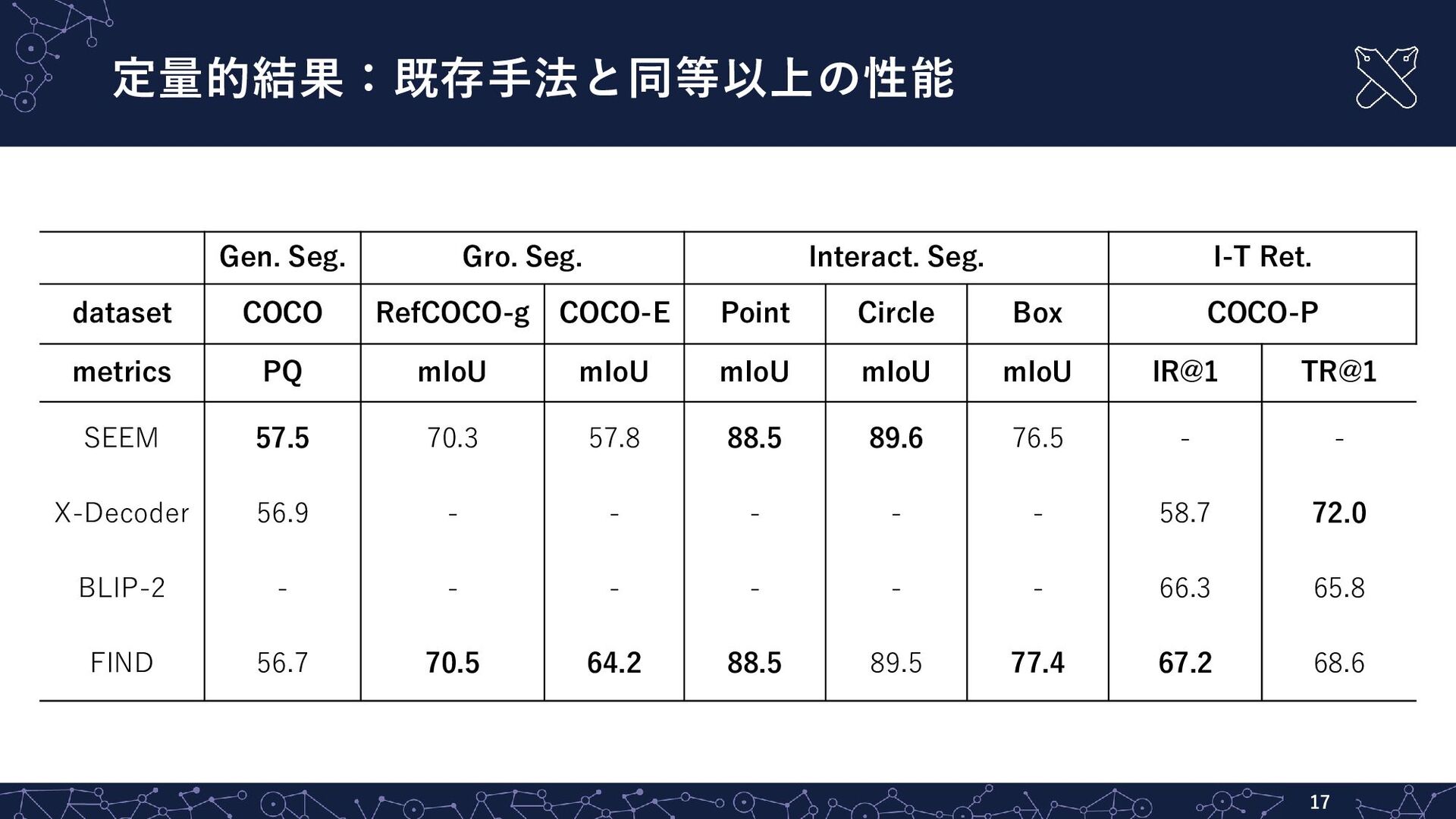{kind=link}
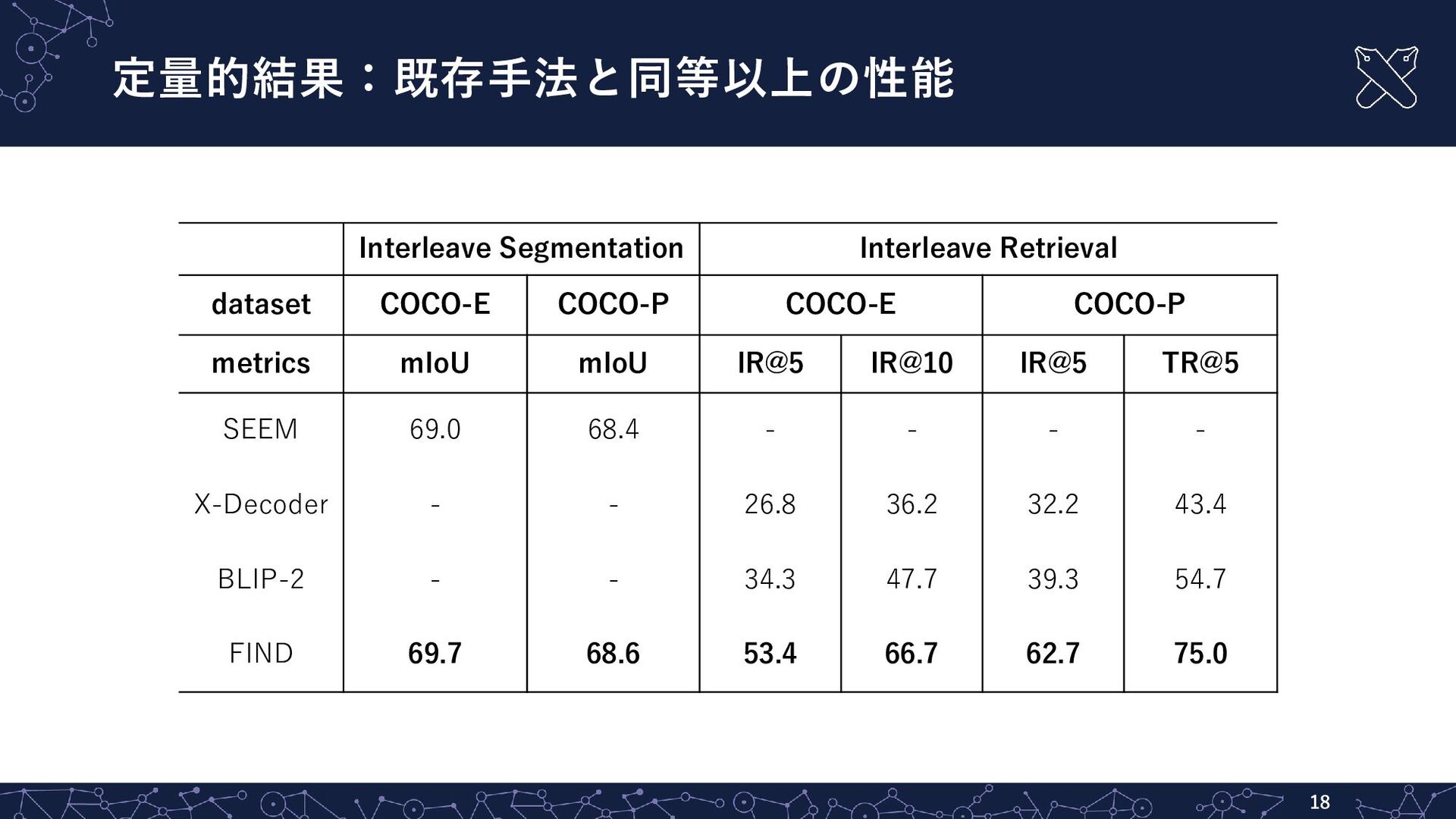{kind=link}
{kind=link}
![実際にやってみた ▪ Talk2Car [Deruyttere+, EMNLP19] 20](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_19.jpg){kind=link}
![まとめ:FIND ▪ X-Decoder [Zou+, CVPR23],SEEM [Zou+, NeurIPS23]の後続モデル ▪ 背景 ◦](https://files.speakerdeck.com/presentations/98f1597ce6664f77b33a14e7bd58bf45/slide_20.jpg){kind=link}
{kind=link}
{kind=link}