Real-time Embodied Question Answering Saumya Saxena1*, Blake Buchanan2*, Chris Paxton3, Bingqing Chen4, Narunas Vaskevicius4, Luigi Palmieri4, Jonathan Francis1,4, Oliver Kroemer1 (1Carnegie Mellon University, 2Neya Systems, 3Hello Robot Inc., 4Bosch Center for AI) CoRL 2025 慶應義塾大学 杉浦孔明研究室 是方諒介 Saxena, S., Buchanan, B., Paxton, C., Chen, B., Vaskevicius, N., Palmieri, L., Francis, J., Kroemer, O. "GraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering." CoRL 2025.
{kind=link}
{kind=link}
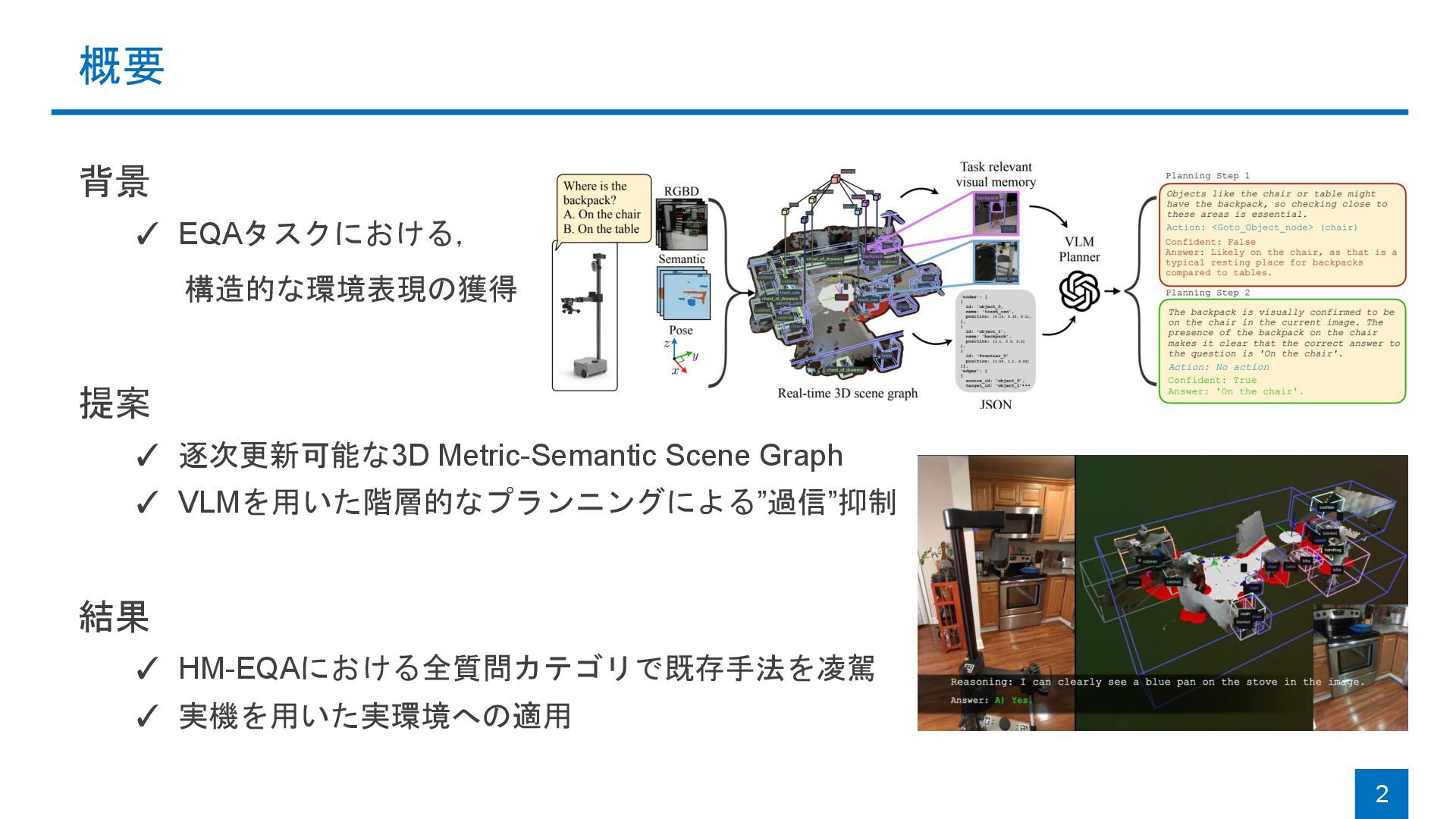
![背景:Embodied Question Answering (EQA [Das+, CVPR18]) ◼ 環境に関する質問が与えられ,ロボットが探索・理解・回答を一体で実施 ◼ 課題](https://files.speakerdeck.com/presentations/9c0012adbf59492fad62cf7dec127d72/slide_2.jpg){kind=link}
![関連研究:構造化されたグラフを逐次構築可能な手法は限定的 4 手法 概要 3DMem [Yang+, CVPR25] 過去に観測したsnapshotを集約し,VLMを用いて探索 部屋等の構造化された情報を持たない](https://files.speakerdeck.com/presentations/9c0012adbf59492fad62cf7dec127d72/slide_3.jpg){kind=link}
{kind=link}
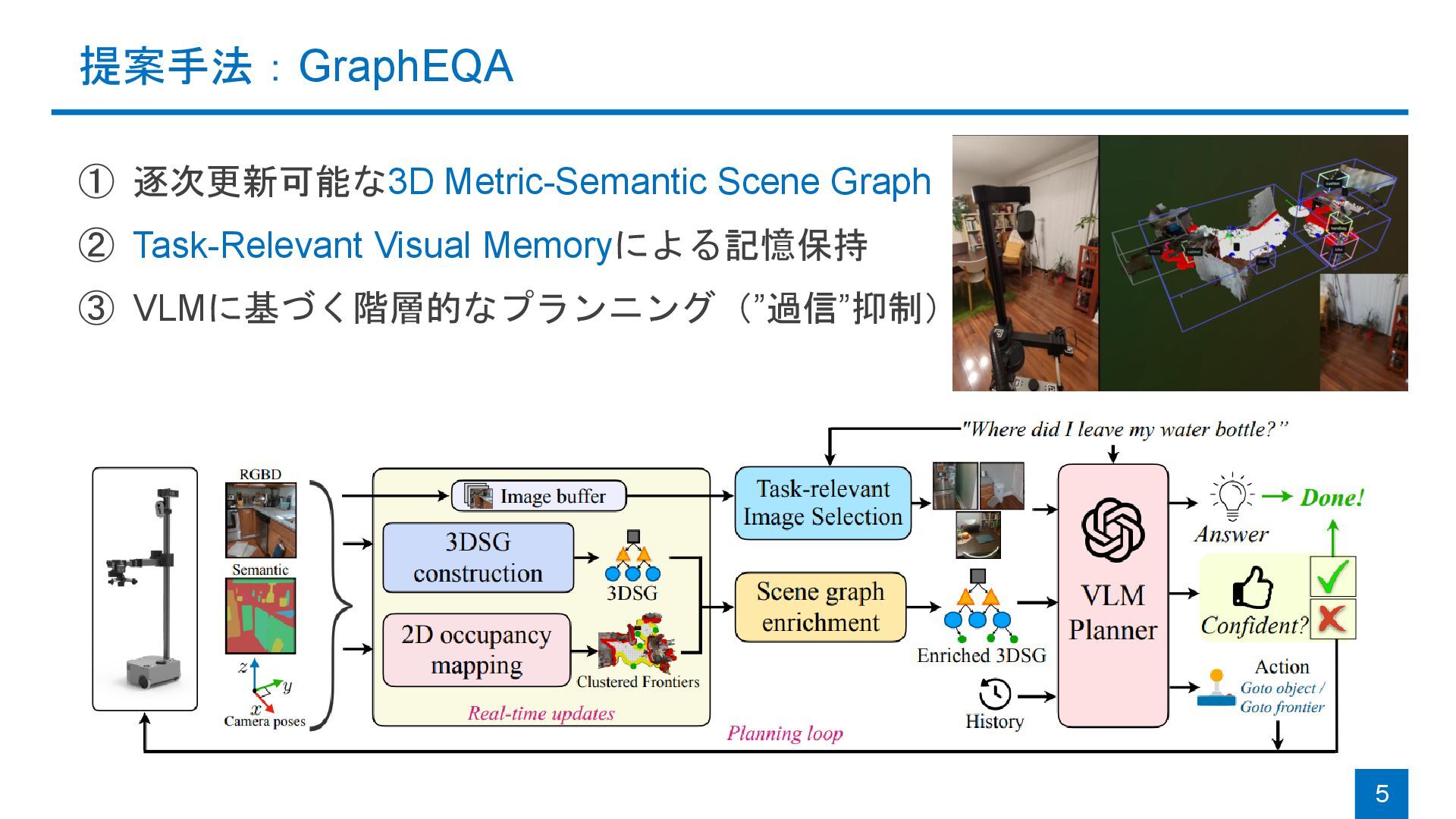
![3D Metric-Semantic Scene Graph (3DSG): Hydra [Hughes+, RSS22] + LLMに基づく,階層的な環境表現](https://files.speakerdeck.com/presentations/9c0012adbf59492fad62cf7dec127d72/slide_5.jpg){kind=link}
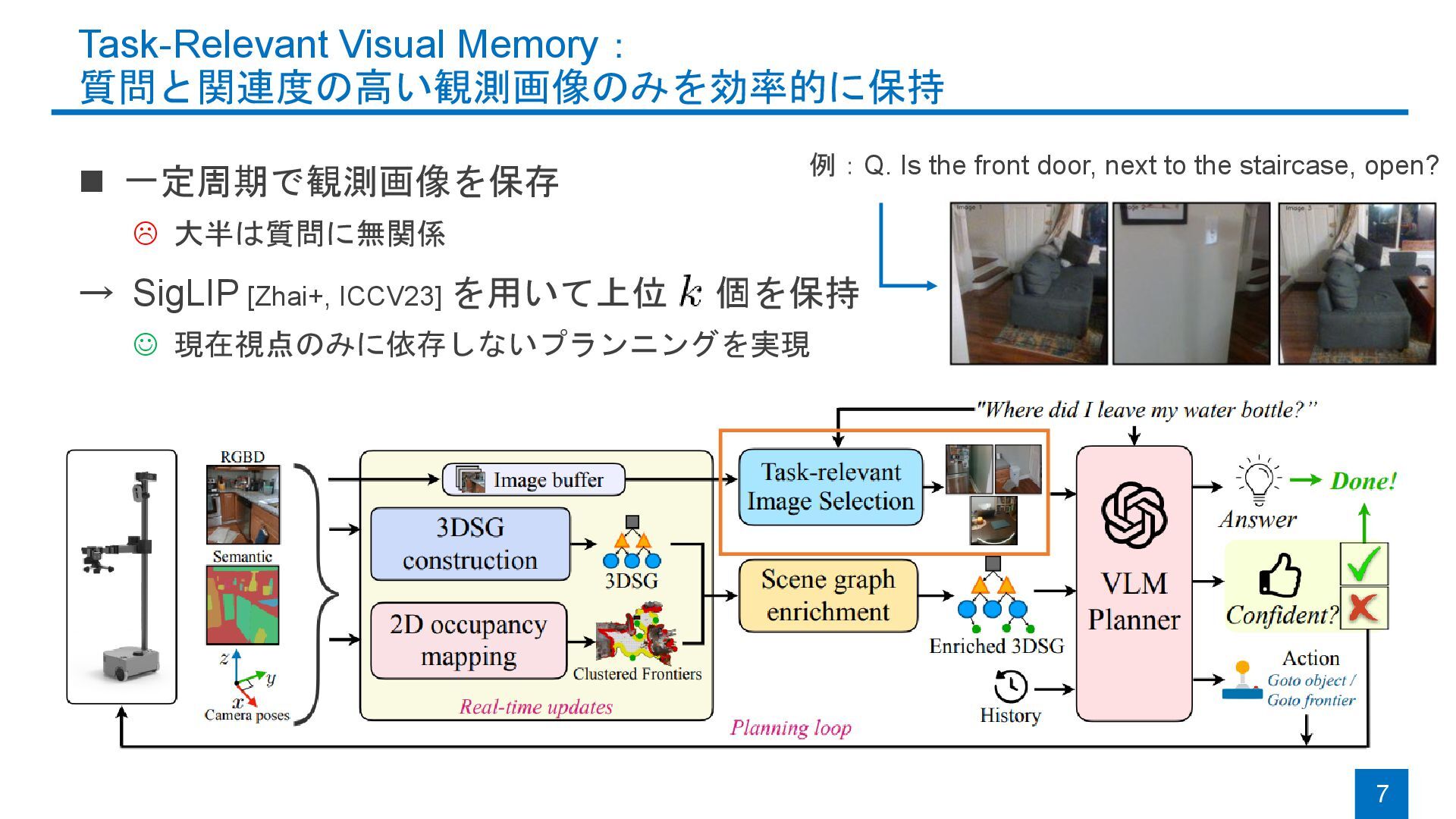{kind=link}
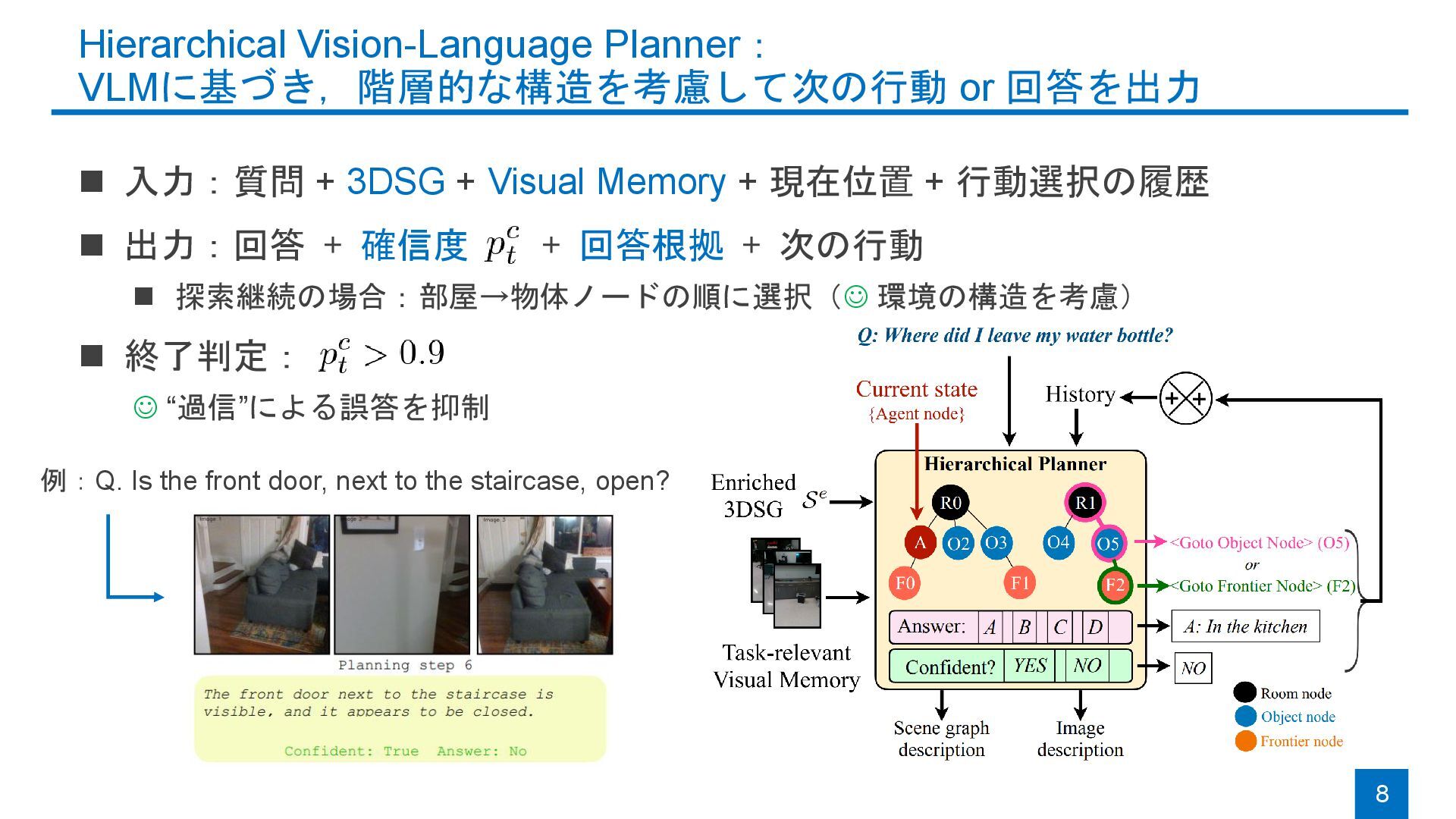{kind=link}
![実験設定:シミュレーション & 実機の両方で検証 シミュレーション:HM-EQA [Ren+, RSS24] ◼ 5カテゴリ,500サンプル(選択肢式) 評価指標 ◼](https://files.speakerdeck.com/presentations/9c0012adbf59492fad62cf7dec127d72/slide_8.jpg){kind=link}
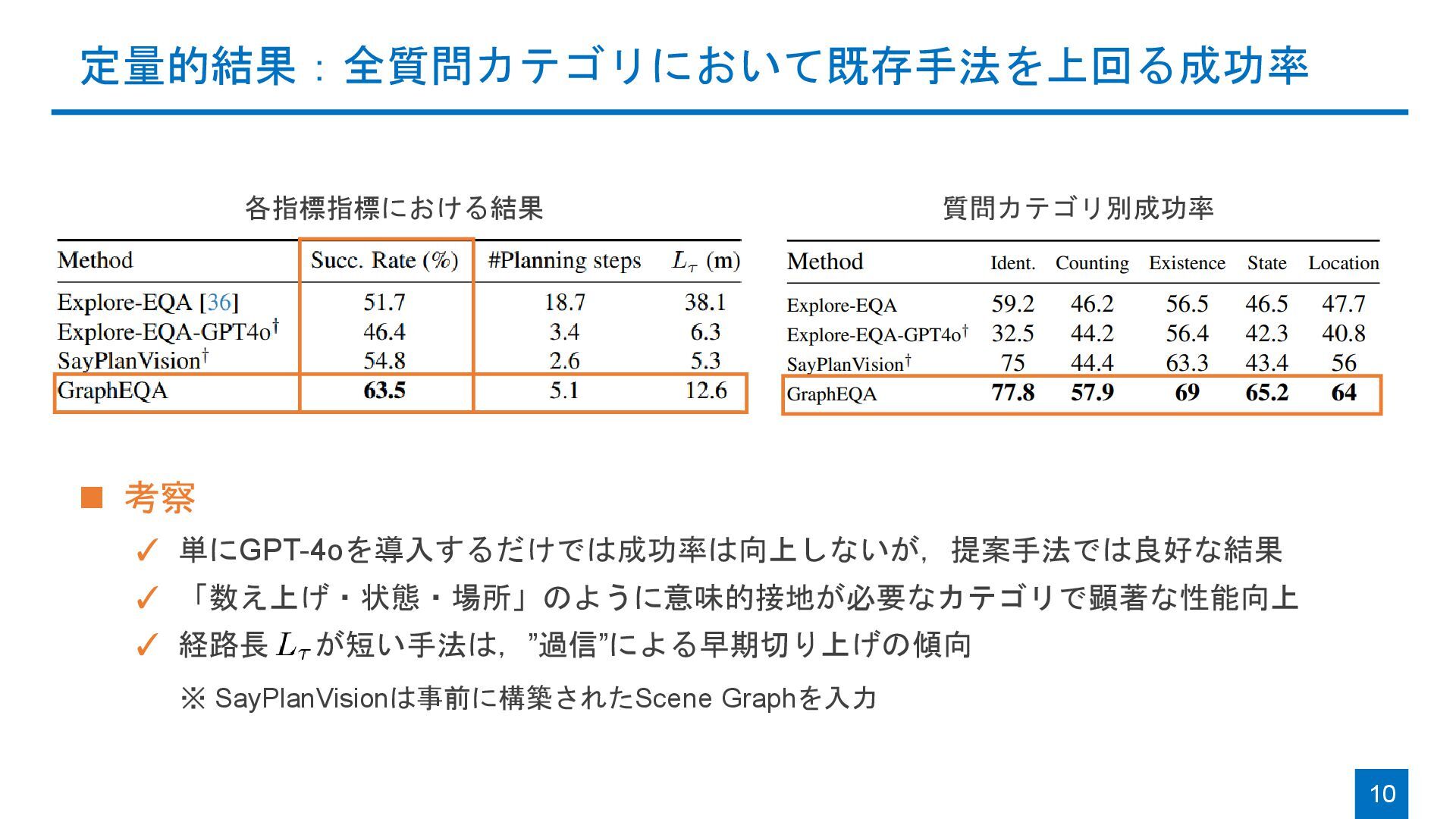{kind=link}
{kind=link}
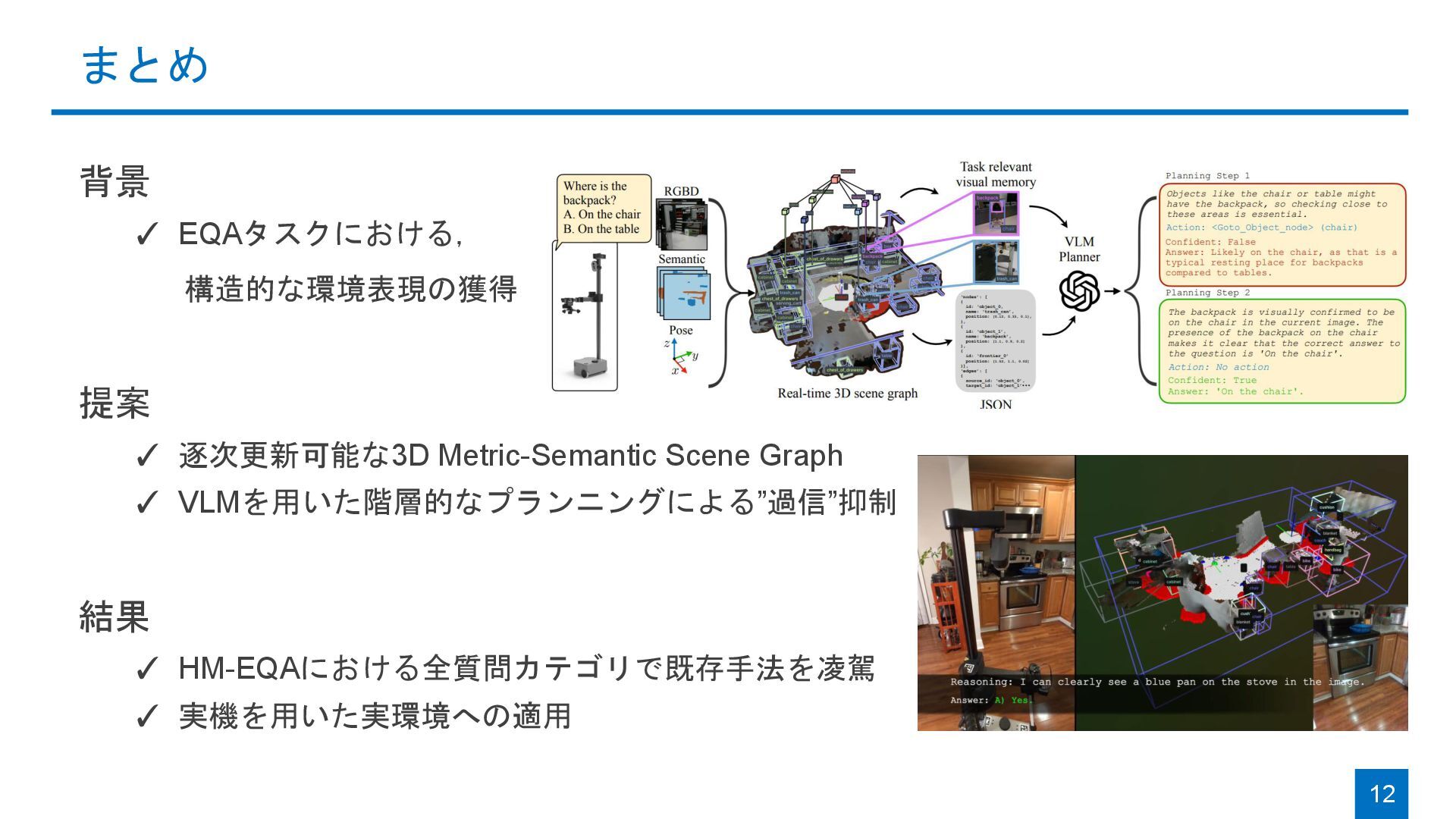{kind=link}
{kind=link}
{kind=link}
{kind=link}
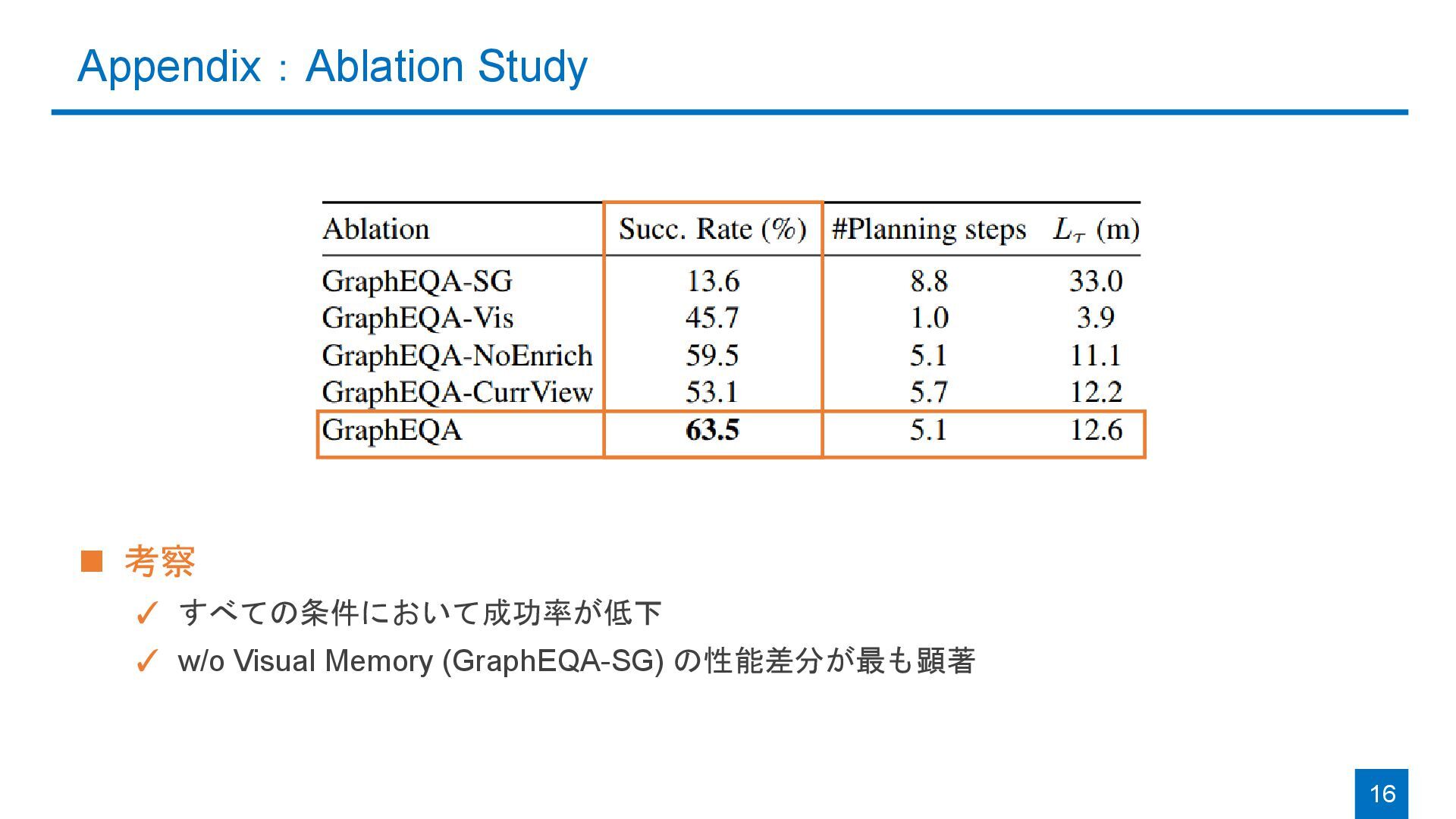{kind=link}
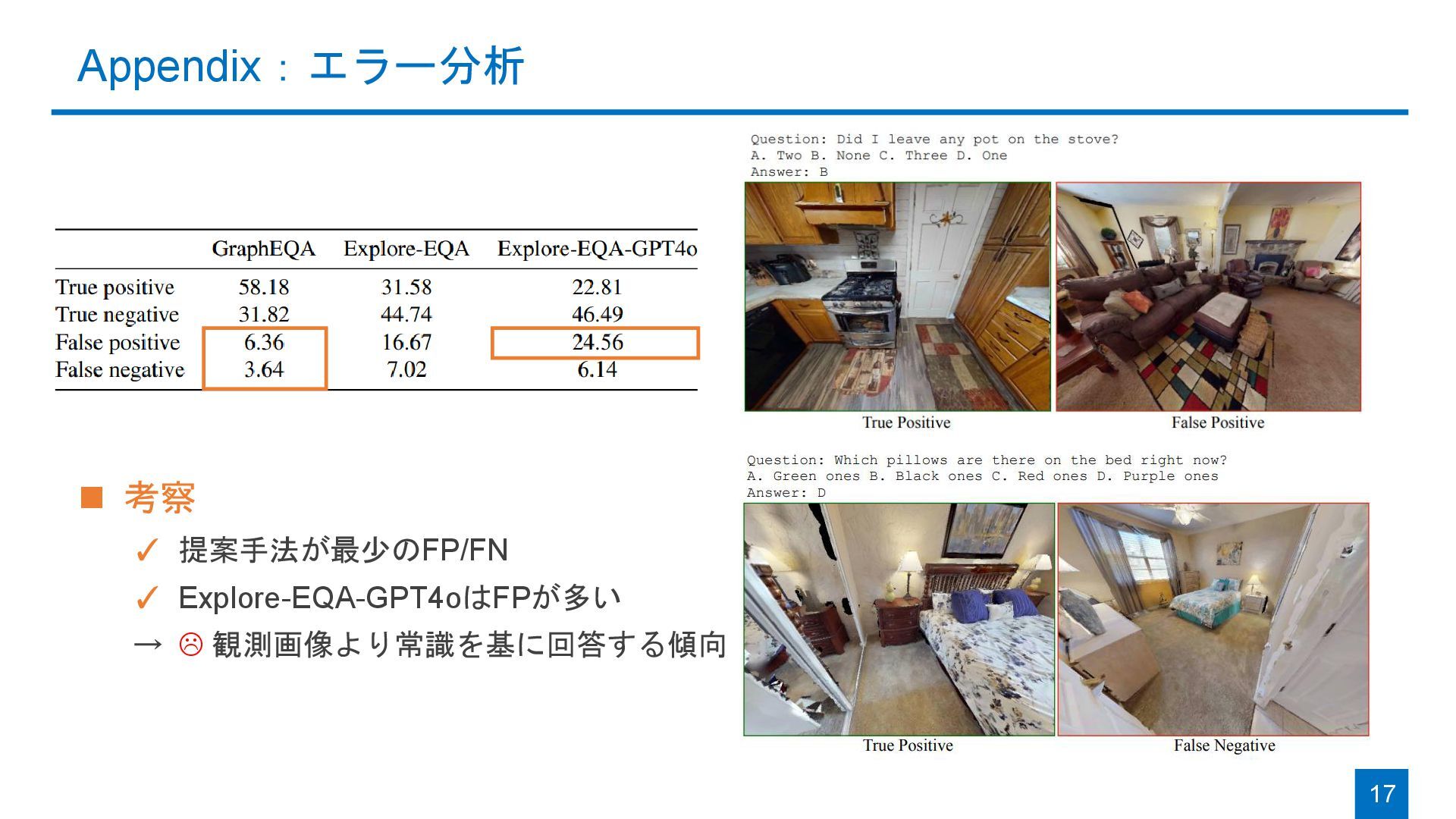{kind=link}