Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] MemER: Scaling Up Memory for Rob...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 17, 2025
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] MemER: Scaling Up Memory for Robot Control via Experience Retrieval
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 17, 2025
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
61
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
73
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Featured
See All Featured
Side Projects
sachag
455
43k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
WENDY [Excerpt]
tessaabrams
11
38k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Odyssey Design
rkendrick25
PRO
2
730
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Evolving SEO for Evolving Search Engines
ryanjones
0
240
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
410
Marketing to machines
jonoalderson
1
5.6k
Transcript
M1 八島大地 MemER: Scaling Up Memory for Robot Control via
Experience Retrieval Sridhar, Ajay, et al. "MemER: Scaling Up Memory for Robot Control via Experience Retrieval." arXiv preprint arXiv:2510.20328 (2025). Ajay Sridhar*1, Jennifer Pan*1, Satvik Sharma1, Chelsea Finn1 1Stanford University
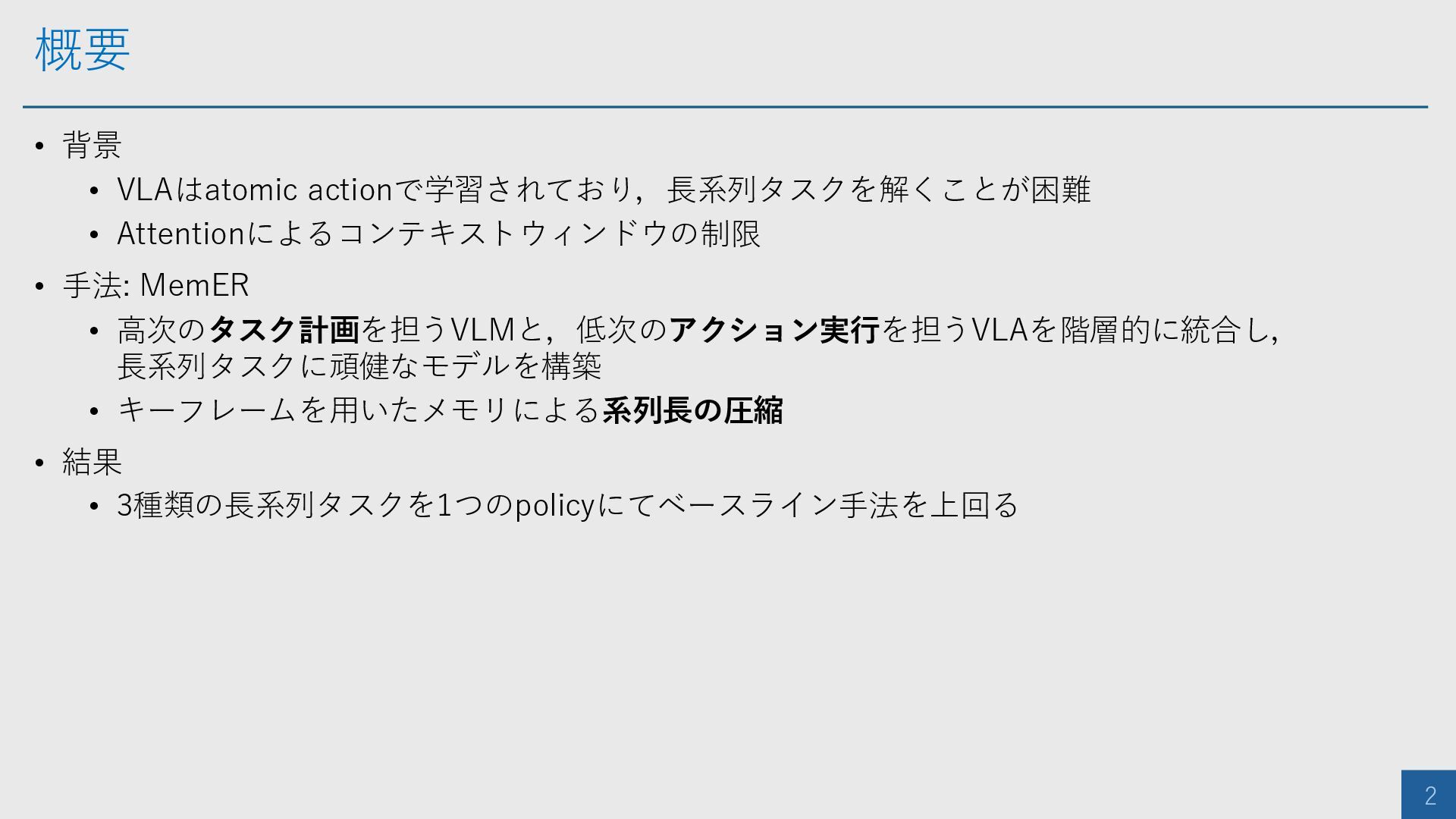
概要 2 • 背景 • VLAはatomic actionで学習されており,長系列タスクを解くことが困難 • Attentionによるコンテキストウィンドウの制限 •
手法: MemER • 高次のタスク計画を担うVLMと,低次のアクション実行を担うVLAを階層的に統合し, 長系列タスクに頑健なモデルを構築 • キーフレームを用いたメモリによる系列長の圧縮 • 結果 • 3種類の長系列タスクを1つのpolicyにてベースライン手法を上回る
関連研究: Memory-based VLA 3 手法 概要 SAM2Act [Fang+, ICML25] SAM2をbackboneにしたVLAを提案
メモリがないと解くのが難しいMemoryBench(simulation)を提案 [Torne+, CoRL25] Diffusion Policyに過去トークンを予測させた補助損失を組み込み,長系列タスク のimitation learningを可能に Mug replacement [Torne+, CoRL25] MemoryBench [Fang+, ICML25]
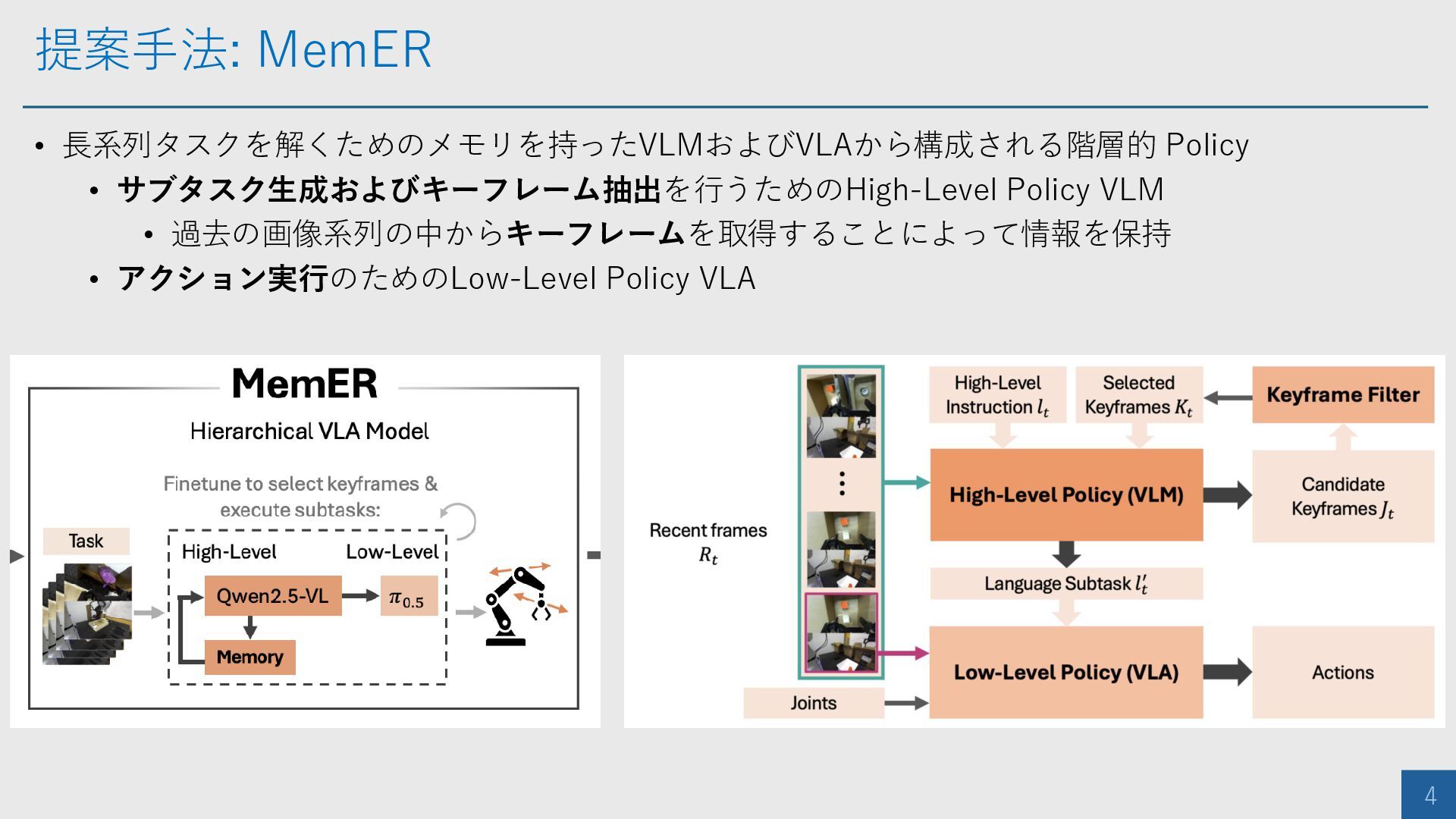
提案手法: MemER 4 • 長系列タスクを解くためのメモリを持ったVLMおよびVLAから構成される階層的 Policy • サブタスク生成およびキーフレーム抽出を行うためのHigh-Level Policy VLM
• 過去の画像系列の中からキーフレームを取得することによって情報を保持 • アクション実行のためのLow-Level Policy VLA
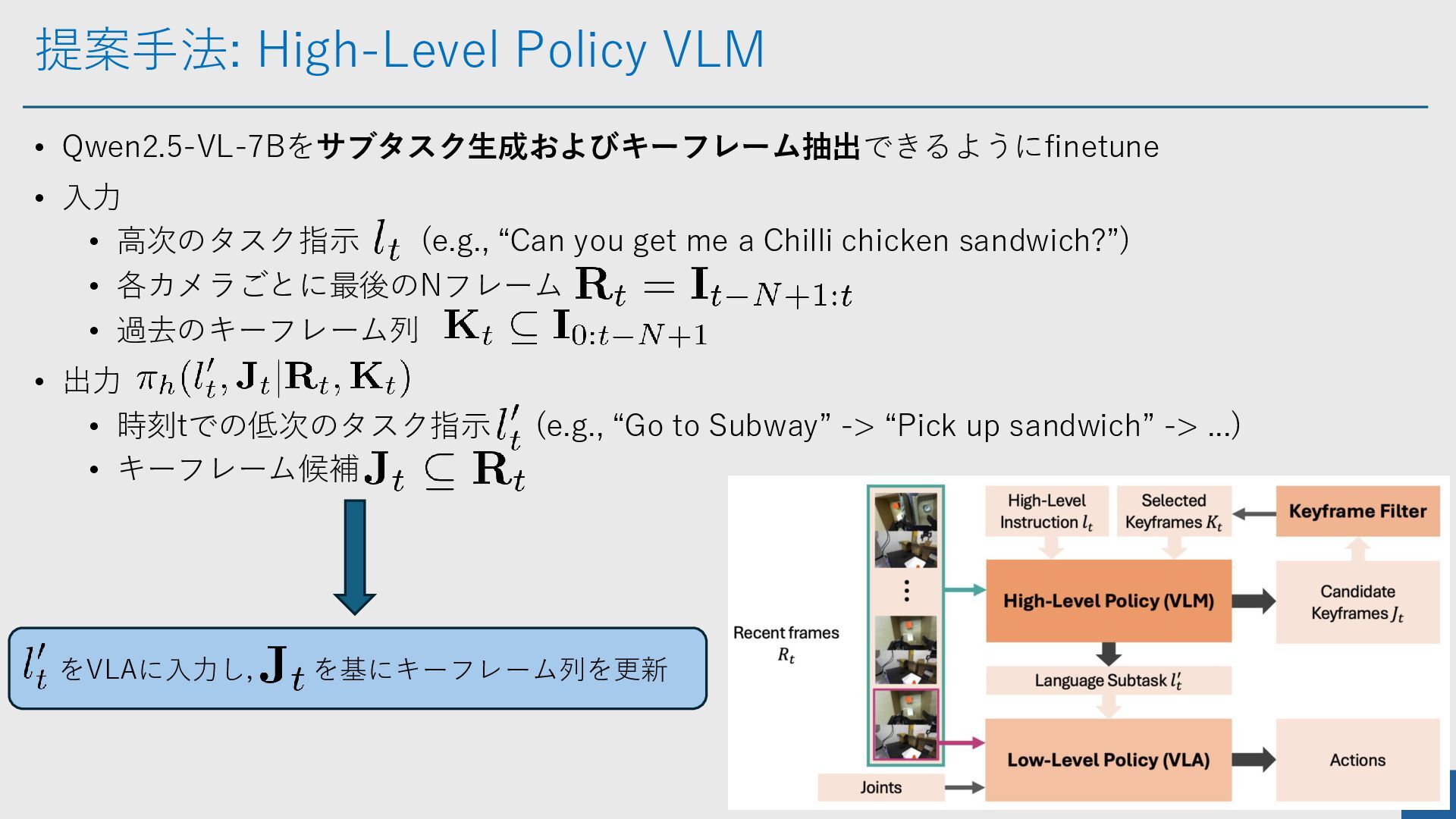
提案手法: High-Level Policy VLM 5 • Qwen2.5-VL-7Bをサブタスク生成およびキーフレーム抽出できるようにfinetune • 入力 •
高次のタスク指示 (e.g., “Can you get me a Chilli chicken sandwich?”) • 各カメラごとに最後のNフレーム • 過去のキーフレーム列 • 出力 • 時刻tでの低次のタスク指示 (e.g., “Go to Subway” -> “Pick up sandwich” -> ...) • キーフレーム候補 をVLAに入力し, を基にキーフレーム列を更新
提案手法: キーフレーム列の更新 6 • VLMが出力したキーフレーム候補列 はtemporal方向への冗長性を 排除できていない → 1D single-linkage
clustering • Merge distance = 5で中央値を代表キーフレームとして を取得
実験設定 7 • 環境: DROID [Khazatsky+, RSS24] • タスク: 記憶が必要な長系列タスク
• Object Search • Counting • Dust & Replace • 評価指標: task progress (e.g., Object Search: 1. 正しい物体を見つけて 物体把持できる(1点) 2. 最適なルート (1点)) Object Search
実験設定 8 • VLM: Qwen2.5-VL-7B • 各サブタスクの画像列からキーフレームを[first, last, no]でアノテーションを行いfinetune →
成否判定は最初と最後の画像から判断可能という発想 (i.e., [Goko+, CoRL24]) • 5000 stepほど学習するとサブタスク予測ができるようになるが,task recoveryなどに必要な generabilityが失われた → model merging • VLA: pi0.5 DROID finetuned [Black+, RSS25] • 3タスクから合計50軌道および10-15サンプル のinterventionデータでさらにfinetune pi*0.6 [Amin+, 25]
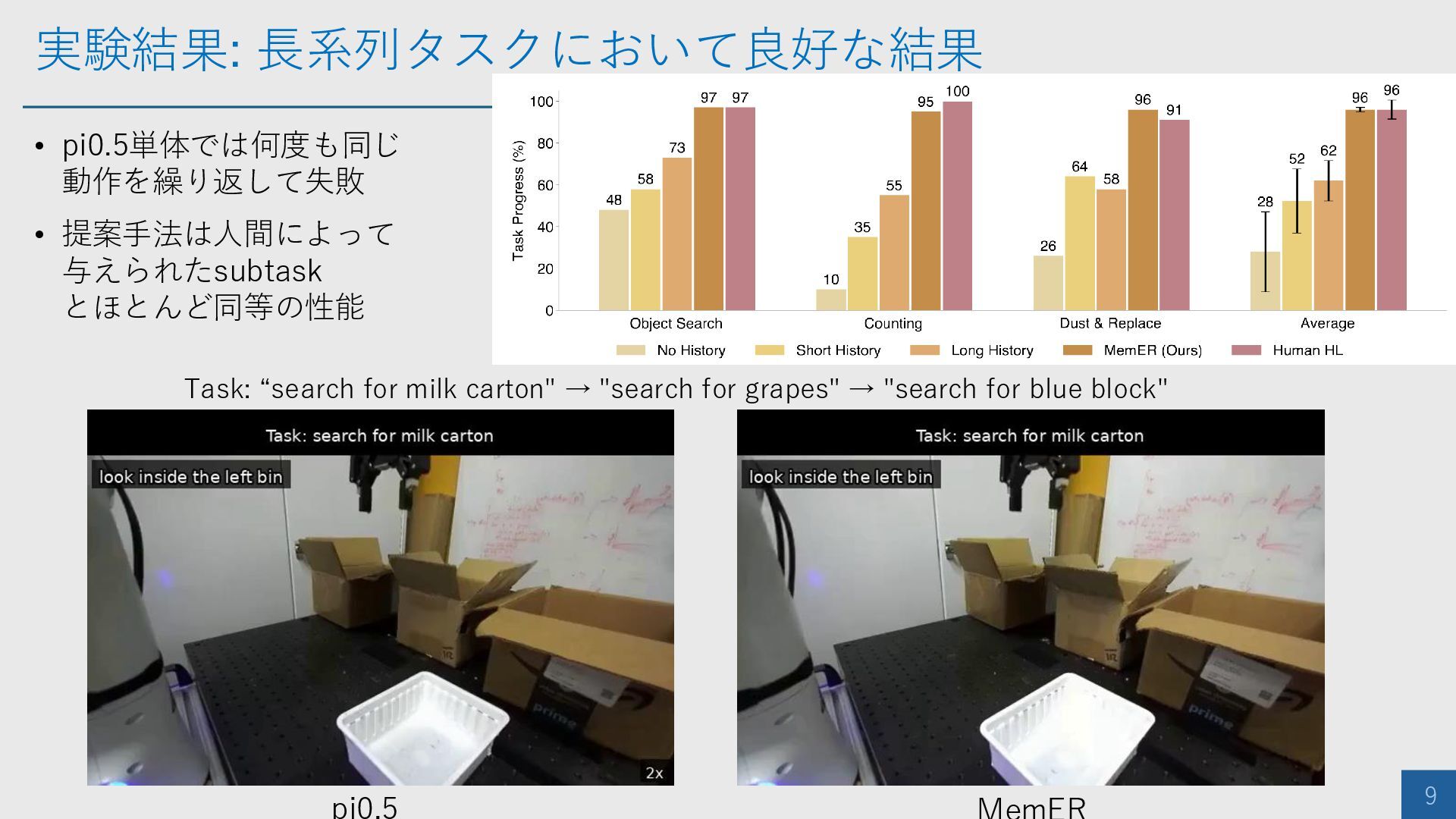
実験結果: 長系列タスクにおいて良好な結果 9 • pi0.5単体では何度も同じ 動作を繰り返して失敗 • 提案手法は人間によって 与えられたsubtask とほとんど同等の性能
Task: “search for milk carton" → "search for grapes" → "search for blue block"
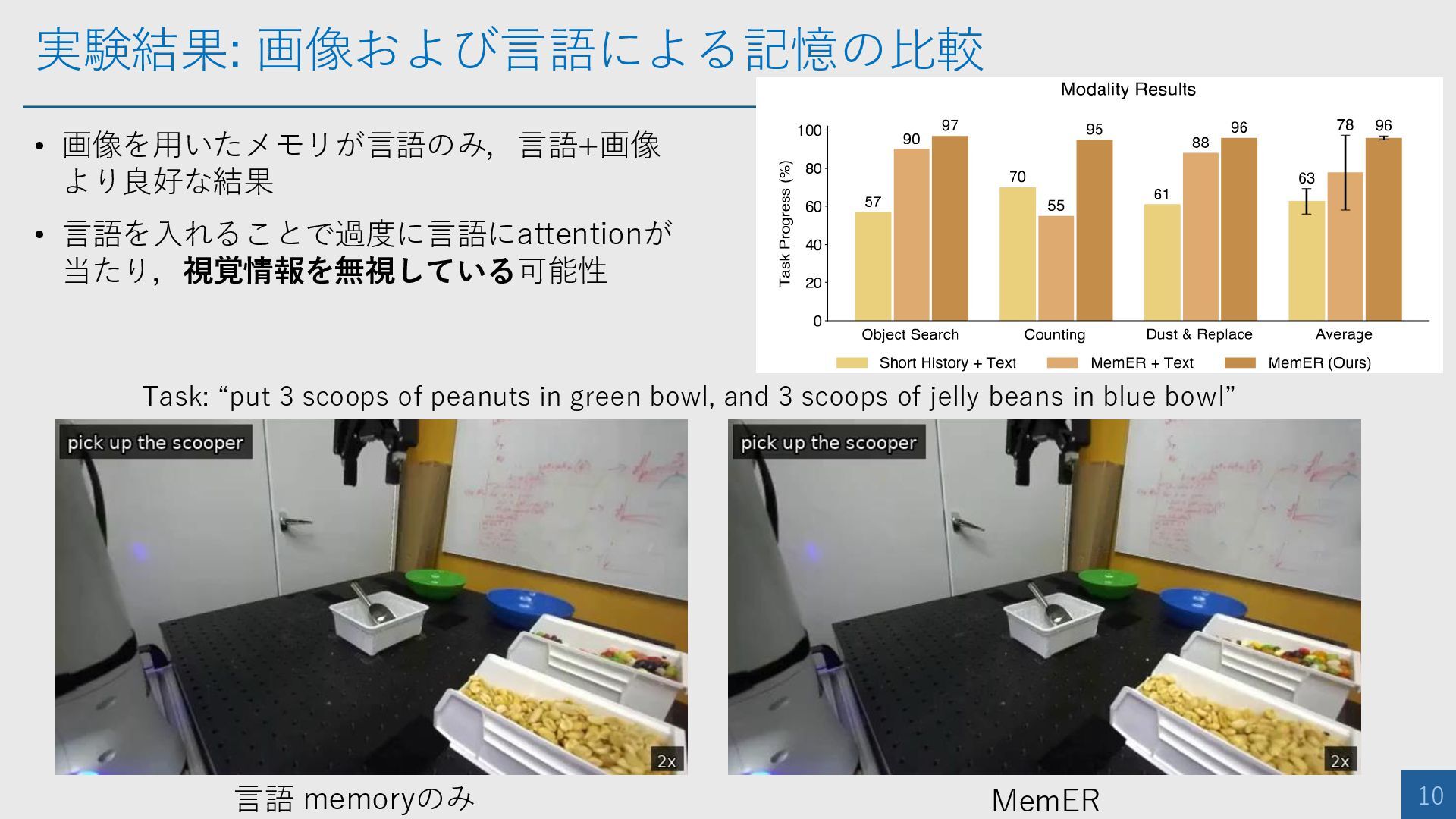
実験結果: 画像および言語による記憶の比較 10 • 画像を用いたメモリが言語のみ,言語+画像 より良好な結果 • 言語を入れることで過度に言語にattentionが 当たり,視覚情報を無視している可能性 MemER
言語 memoryのみ Task: “put 3 scoops of peanuts in green bowl, and 3 scoops of jelly beans in blue bowl”
実験結果: メモリによる頑健性 11 • VLMによるタスク成否判定により,何度もVLAがサブタスク実行を行い失敗からリカバリ を行っている トマトを落とす ホコリ落としとボールを落とす
まとめ 12 • 背景 • VLAはatomic actionで学習されており,長系列タスクを解くことが困難 • Attentionによるコンテキストウィンドウの制限 •
手法: MemER • 高次のタスク計画を担うVLMと,低次のアクション実行を担うVLAを階層的に統合し, 長系列タスクに頑健なモデルを構築 • キーフレームを用いたメモリによる系列長の圧縮 • 結果 • 3種類の長系列タスクを1つのpolicyにてベースライン手法を上回る
{kind=link}
{kind=link}
![関連研究: Memory-based VLA 3 手法 概要 SAM2Act [Fang+, ICML25] SAM2をbackboneにしたVLAを提案](https://files.speakerdeck.com/presentations/e0ffc5021dd64d0d9c3c98acca8f94cd/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定 7 • 環境: DROID [Khazatsky+, RSS24] • タスク: 記憶が必要な長系列タスク](https://files.speakerdeck.com/presentations/e0ffc5021dd64d0d9c3c98acca8f94cd/slide_6.jpg){kind=link}
![実験設定 8 • VLM: Qwen2.5-VL-7B • 各サブタスクの画像列からキーフレームを[first, last, no]でアノテーションを行いfinetune →](https://files.speakerdeck.com/presentations/e0ffc5021dd64d0d9c3c98acca8f94cd/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}