MODEL Yihao Wang1,2,4 ,Pengxiang Ding2,3,4 ,Lingxiao Li1,4,5, Can Cui2,4, Zirui Ge3,4, Xinyang Tong2,4, Wenxuan Song4,6, Han Zhao2,3,4, Wei Zhao2,4, Pengxu Hou6, Siteng Huang2, Yifan Tang1, WenhuiWang1, RuZhang1, Jianyi Liu1, Donglin Wang2 1Beijing University of Posts and Telecommunications, 2Westlake University, 3Zhejiang University, 4OpenHelix Team, 5State Key Laboratory of Networking and Switching Technology, 6The Hong Kong University of Science and Technology (Guangzhou) Wang, Yihao, et al. "Vla-Adapter: An Effective Paradigm for Tiny-scale Vision-Language-Action Model." arXiv preprint arXiv:2509.09372 (2025).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
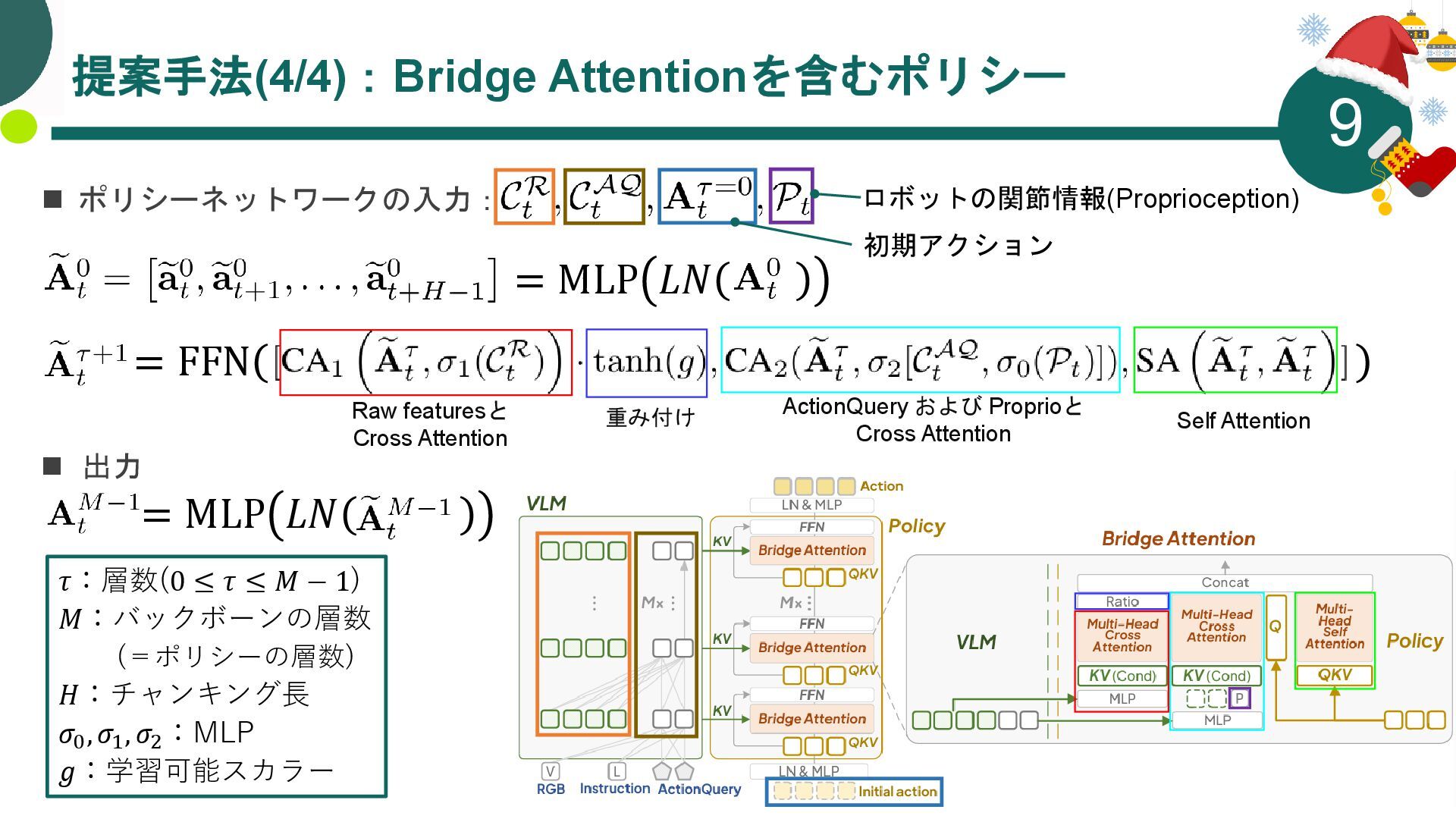{kind=link}
{kind=link}
{kind=link}
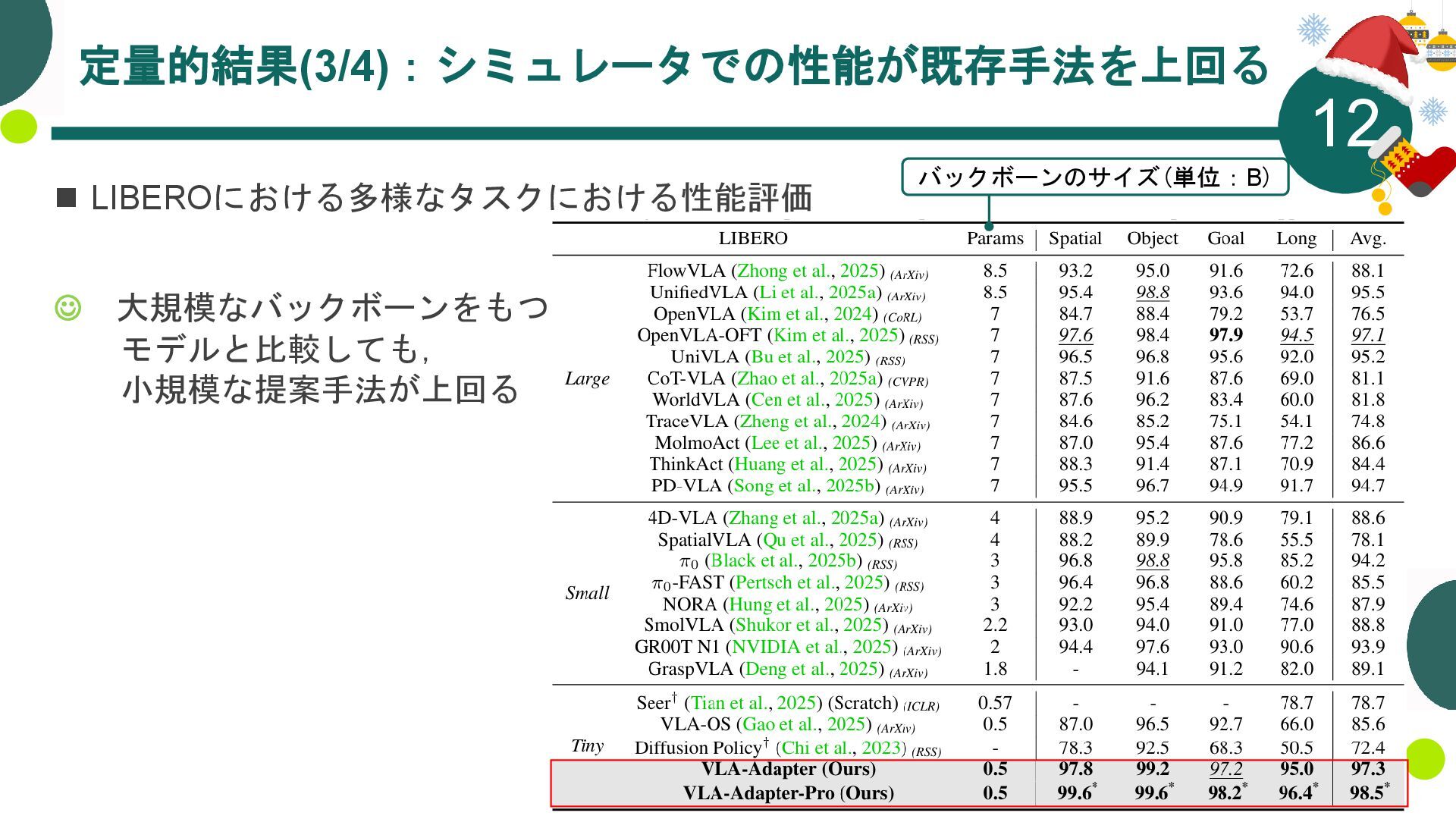{kind=link}
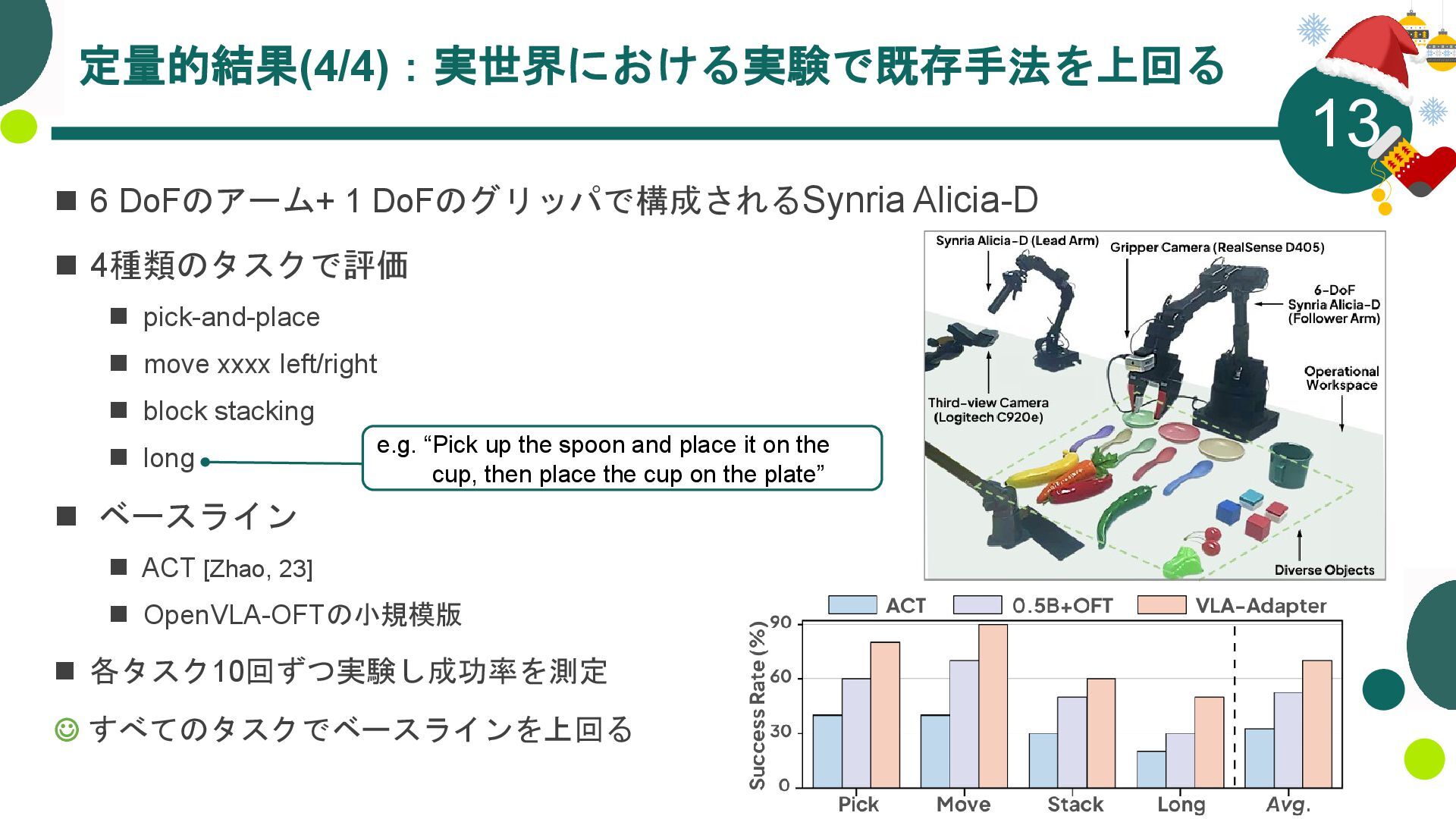{kind=link}
{kind=link}
{kind=link}