Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Improved Mean Flows: On the Chal...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 24, 2025
Technology
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Improved Mean Flows: On the Challenges of Fastforward Generative Models
Semantic Machine Intelligence Lab., Keio Univ.
PRO
December 24, 2025
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
72
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
77
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
96
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Making sense of Google’s agentic dev tools
glaforge
1
280
マルチアカウント環境でSecurity Hubの運用、その後どうなった? / SRE NEXT 2026 miniLT会
genda
0
100
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
250
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
370
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
3
4.2k
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
270
見守りエージェントを作ってみた(ローカルLLM + Hermes Agent)
happysamurai294
0
110
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.9k
穢れた技術選定について
watany
17
5.5k
AI時代の闇と光
tatsuya1970
0
110
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
790
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
760
Featured
See All Featured
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
55k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Deep Space Network (abreviated)
tonyrice
0
230
Automating Front-end Workflow
addyosmani
1370
210k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Transcript
杉浦孔明研究室 妹尾幸樹 Improved Mean Flows: On the Challenges of Fastforward
Generative Models Zhengyang Geng1,2,3,* Yiyang Lu4,2,∗ Zongze Wu3 Eli Shechtman3 J. Zico Kolter1 Kaiming He2 1CMU 2MIT 3Adobe 4THU Geng, Z., Lu, Y., Wu, Z., Shechtman, E., Kolter, J. Z., & He, K. (2025). Improved Mean Flows: On the Challenges of Fastforward Generative Models. arXiv preprint arXiv:2512.02012, 2025
概要 2 ▪ 背景︓Mean Flows J 1-NFEで⾼品質な⽣成 L 数式に粗い近似が存在 ▪
提案︓Improved Mean Flows J Mean Flows における数式的な問題を改善 J 柔軟な Classifier Free Guidance J in-context conditioning による軽量化 ▪ 結果 J 1-NFE で多くの Multi-NFE モデルを上回る
背景︓Mean Flows の数式は不正確 3 ▪ 拡散モデルや Flow Matching は⾼性能だが計算コストが⾼い ▪
ODE を解く際に多くの NFE が必要 ▪ {1, few}-NFEのモデルが台頭 ▪ Mean Flows [Geng+, NeurIPS25] ▪ 瞬間速度ではなく平均速度を予測 J 1-NFE で⾼品質な⽣成が可能 L GTの計算が困難 ▪ 不正確な近似(後述) MoFlow [Fu+, CVPR25] Mean Flows [Geng+, NeurIPS25] Mean Flows [Geng+, NeurIPS25] 𝑧! ︓時刻 𝜏 におけるノイズ付きデータ, 𝑡, 𝑟︓時刻
関連研究︓Mean Flows の改善 4 ⼿法 特徴 AlphaFlow [Zhang+, 25] Flow
Matching から MeanFlow へ段階的に移⾏する カリキュラム学習⼿法 Decoupled MeanFlow [Lee+, 25] 事前学習済み Flow Matching モデルを fine-tuning して MeanFlow モデルへ変換 CMT [Hu+, 25] 事前学習と事後学習の間に⼀貫性損失を⽤いた中間学習を導⼊ 事後学習における MeanFlow モデルの性能が向上 Decoupled Meanflow [Lee+, 25] AlphaFlow [Zhang+, 25]
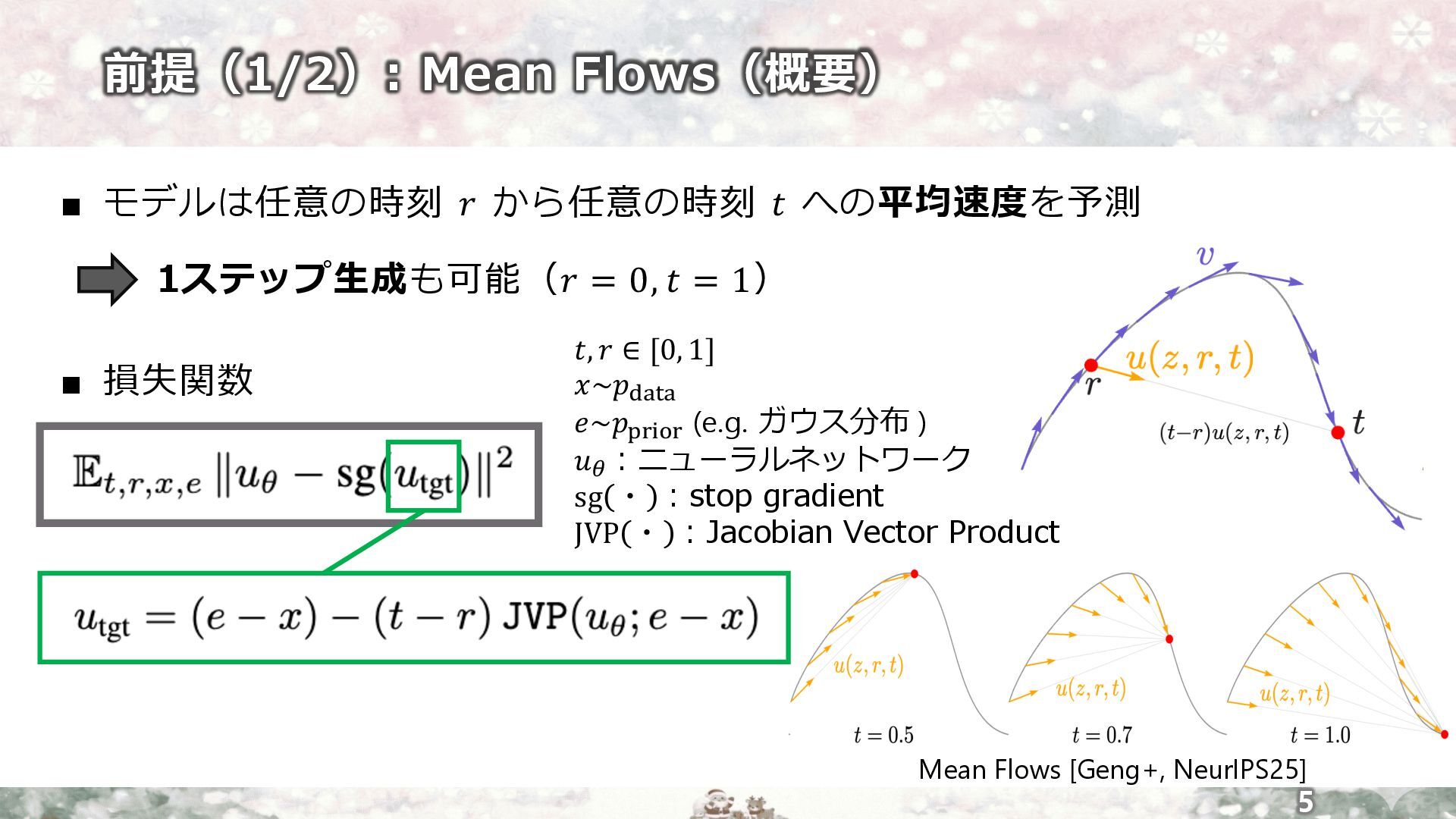
▪ モデルは任意の時刻 𝑟 から任意の時刻 𝑡 への平均速度を予測 1ステップ⽣成も可能(𝑟 = 0, 𝑡
= 1) ▪ 損失関数 前提(1/2): Mean Flows(概要) 5 𝑡, 𝑟 ∈ [0, 1] 𝑥~𝑝!"#" 𝑒~𝑝$%&'% (e.g. ガウス分布 ) 𝑢( ︓ニューラルネットワーク sg ・ ︓stop gradient JVP ・ ︓Jacobian Vector Product Mean Flows [Geng+, NeurIPS25]
前提(2/2): Mean Flows(導出・問題点) 6 𝑢 𝑧&, 𝑟, 𝑡 + 𝑡
− 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& 𝑑 𝑑𝑡 𝑡 − 𝑟 𝑢 𝑧&, 𝑟, 𝑡 = 𝑑 𝑑𝑡 - ' & 𝑣 𝑧( 𝑑𝜏 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& − 𝑡 − 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 , where 積の微分 ⟹ ⟹ ⟹ ∴ 𝑧" 𝑥 𝑒 𝑡 − 𝑟 を掛けた後,𝑡 で微分
前提(2/2): Mean Flows(導出・問題点) 7 𝑢 𝑧&, 𝑟, 𝑡 + 𝑡
− 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& 𝑑 𝑑𝑡 𝑡 − 𝑟 𝑢 𝑧&, 𝑟, 𝑡 = 𝑑 𝑑𝑡 - ' & 𝑣 𝑧( 𝑑𝜏 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& − 𝑡 − 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 , where 積の微分 = 𝑒 − 𝑥, 0, 1 / 𝜕# , 𝜕$ , 𝜕" 𝑢 = 𝑒 − 𝑥 / 𝜕# 𝑢 + 0 / 𝜕$ 𝑢 + 1 / 𝜕" 𝑢 J JVPを⽤いて計算可能 𝑑 𝑑𝑡 𝑢 𝑧" , 𝑟, 𝑡 = 𝑑𝑧" 𝑑𝑡 𝜕# 𝑢 + 𝑑𝑟 𝑑𝑡 𝜕$ 𝑢 + 𝑑𝑡 𝑑𝑡 𝜕" 𝑢 ⟹ ⟹ ⟹ ∴ 𝑧" 𝑥 𝑒 𝑡 − 𝑟 を掛けた後,𝑡 で微分
前提(2/2): Mean Flows(導出・問題点) 8 𝑢 𝑧&, 𝑟, 𝑡 + 𝑡
− 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& 𝑑 𝑑𝑡 𝑡 − 𝑟 𝑢 𝑧&, 𝑟, 𝑡 = 𝑑 𝑑𝑡 - ' & 𝑣 𝑧( 𝑑𝜏 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& − 𝑡 − 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 , where 積の微分 = 𝑒 − 𝑥, 0, 1 / 𝜕# , 𝜕$ , 𝜕" 𝑢 = 𝑒 − 𝑥 / 𝜕# 𝑢 + 0 / 𝜕$ 𝑢 + 1 / 𝜕" 𝑢 J JVPを⽤いて計算可能 𝑑 𝑑𝑡 𝑢 𝑧" , 𝑟, 𝑡 = 𝑑𝑧" 𝑑𝑡 𝜕# 𝑢 + 𝑑𝑟 𝑑𝑡 𝜕$ 𝑢 + 𝑑𝑡 𝑑𝑡 𝜕" 𝑢 ⟹ ⟹ ⟹ ∴ L 問題① 𝑧" 𝑥 𝑒 𝑡 − 𝑟 を掛けた後,𝑡 で微分 𝒗 𝒛𝒕 𝒆 − 𝒙 L 問題② L Marginal Velocity を Conditional Velocity で近似
提案⼿法 (1/4) : 𝒗-𝐥𝐨𝐬𝐬 (平均速度ではなく瞬間速度を回帰) 9 ▪ 𝒖-𝐥𝐨𝐬𝐬 ▪ 𝒗-𝐥𝐨𝐬𝐬
⇔ , where L GTの計算が困難 J 瞬間速度を回帰 𝑣 𝑧& = 𝑢 𝑧& , 𝑟, 𝑡 + 𝑡 − 𝑟 𝑑 𝑑𝑡 𝑢 𝑧& , 𝑟, 𝑡 𝑢 𝑧&, 𝑟, 𝑡 = 𝑣 𝑧& − 𝑡 − 𝑟 𝑑 𝑑𝑡 𝑢 𝑧&, 𝑟, 𝑡 ∴ 𝑢454
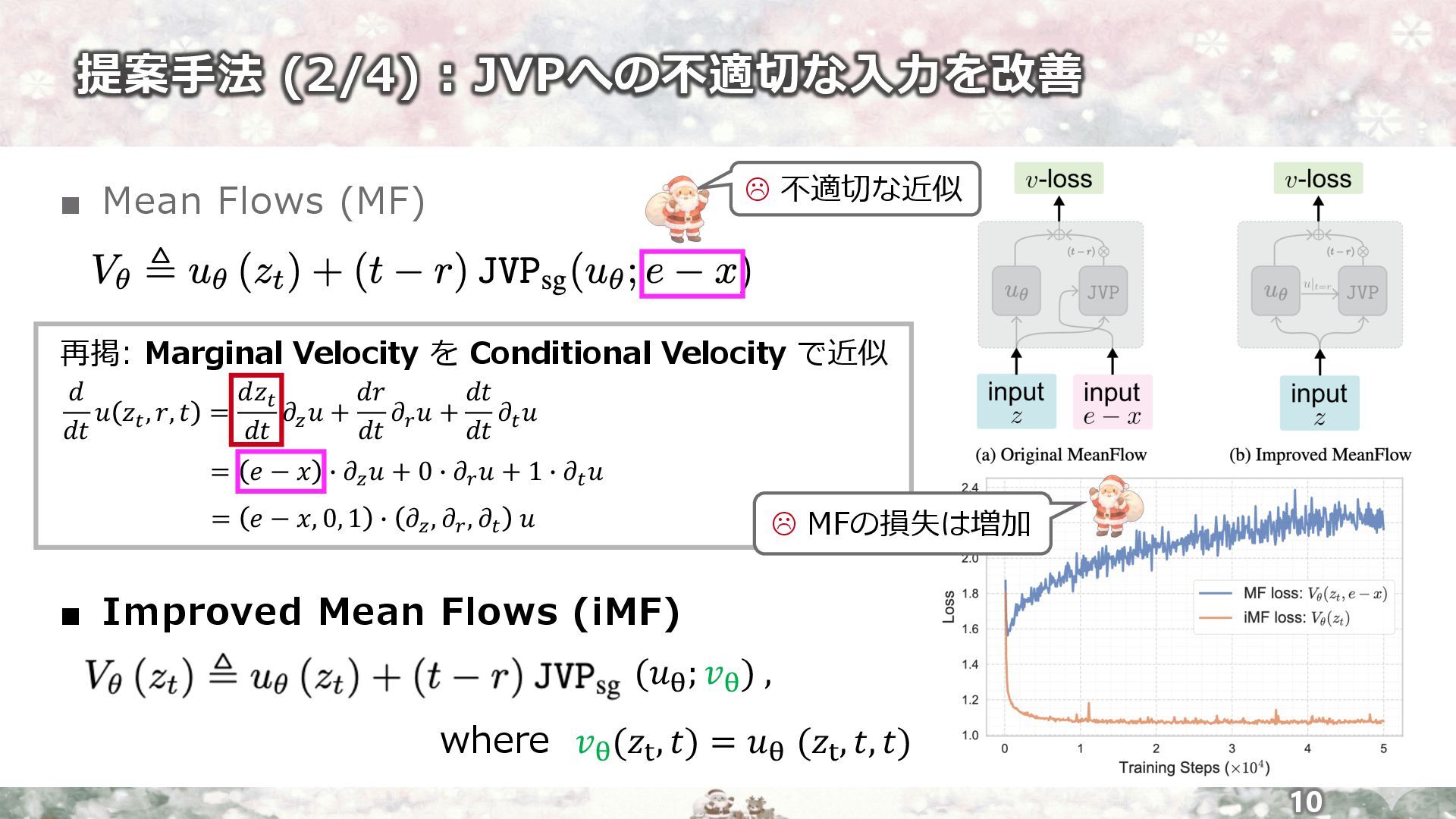
提案⼿法 (2/4) : JVPへの不適切な⼊⼒を改善 10 ▪ Mean Flows (MF) ▪
Improved Mean Flows (iMF) = 𝑒 − 𝑥, 0, 1 / 𝜕# , 𝜕$ , 𝜕" 𝑢 = 𝑒 − 𝑥 / 𝜕# 𝑢 + 0 / 𝜕$ 𝑢 + 1 / 𝜕" 𝑢 再掲: Marginal Velocity を Conditional Velocity で近似 𝑑 𝑑𝑡 𝑢 𝑧" , 𝑟, 𝑡 = 𝑑𝑧" 𝑑𝑡 𝜕# 𝑢 + 𝑑𝑟 𝑑𝑡 𝜕$ 𝑢 + 𝑑𝑡 𝑑𝑡 𝜕" 𝑢 L 不適切な近似 (𝑢6 ; 𝑣6 ) , where 𝑣6 (𝑧4 , 𝑡) = 𝑢6 (𝑧4 , 𝑡, 𝑡) L MFの損失は増加
提案⼿法 (3/4) : 推論時にパラメータを決定可能なCFG 11 ▪ 前提: Classifier Free Guidance
(CFG) J 推論時に条件⼊⼒{有, 無}のモデルの重みづけ和を⽤いて性能向上 ▪ Mean FlowsにおけるCFG ▪ Flexible Guidance (𝜔 を条件として⼊⼒) J 推論時に 𝜔 を決定可能な柔軟な設計 & 𝑣# 𝑧$ , 𝑡 𝑐) = 1 + 𝜔 𝑣% 𝑧$ , 𝑡| 𝑐 − 𝜔 𝑣% 𝑧$ , 𝑡 𝜙) & 𝑣$ = 𝜔 𝑒 − 𝑥 − 1 − 𝜔 𝑢 # &'( 𝑧, 𝑡, 𝑡 where 𝑢)() &'( = & 𝑣$ − 𝑡 − 𝑟 JVP(𝑢 # &'(; & 𝑣$ ) , − sg 𝑢!"! #$" , 𝑐︓条件 𝜙︓無条件 𝜔︓ガイダンススケール L 訓練時に 𝜔 を設定 < | 𝑐, ω 𝑧$ | 𝑐, ω
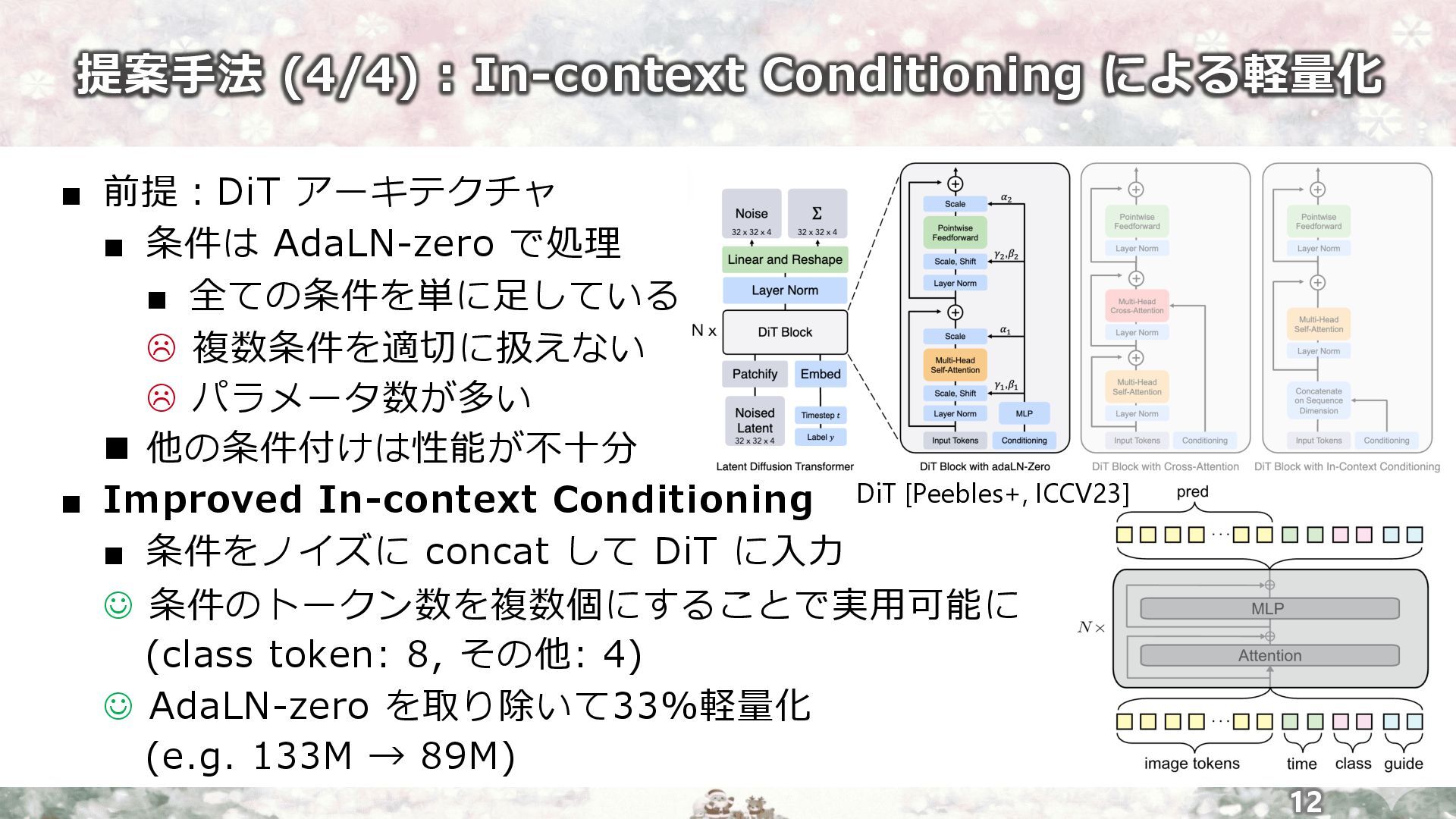
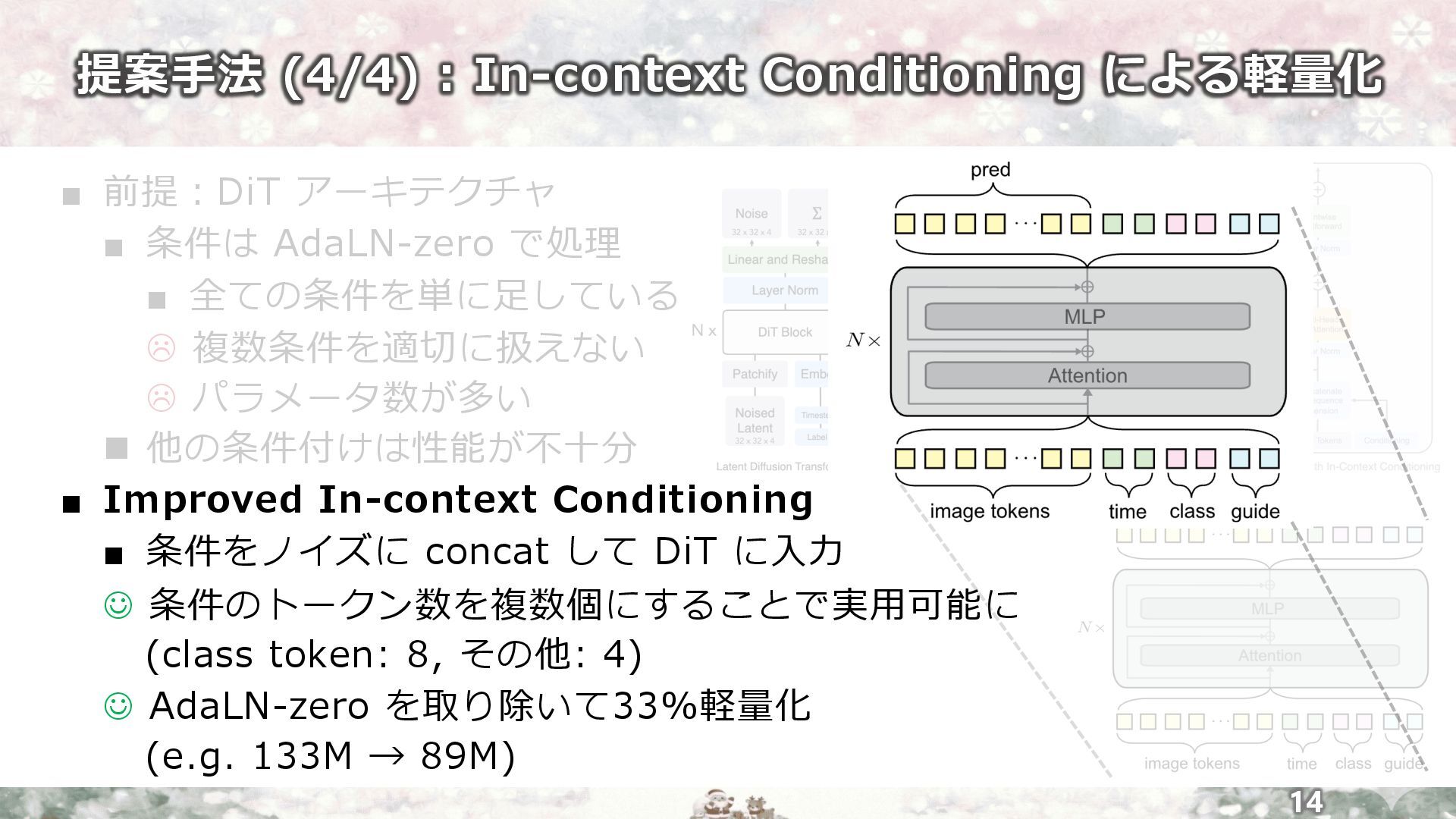
提案⼿法 (4/4) : In-context Conditioning による軽量化 12 ▪ 前提︓DiT アーキテクチャ
▪ 条件は AdaLN-zero で処理 ▪ 全ての条件を単に⾜している L 複数条件を適切に扱えない L パラメータ数が多い n 他の条件付けは性能が不⼗分 ▪ Improved In-context Conditioning ▪ 条件をノイズに concat して DiT に⼊⼒ J 条件のトークン数を複数個にすることで実⽤可能に (class token: 8, その他: 4) J AdaLN-zero を取り除いて33%軽量化 (e.g. 133M → 89M) DiT [Peebles+, ICCV23]
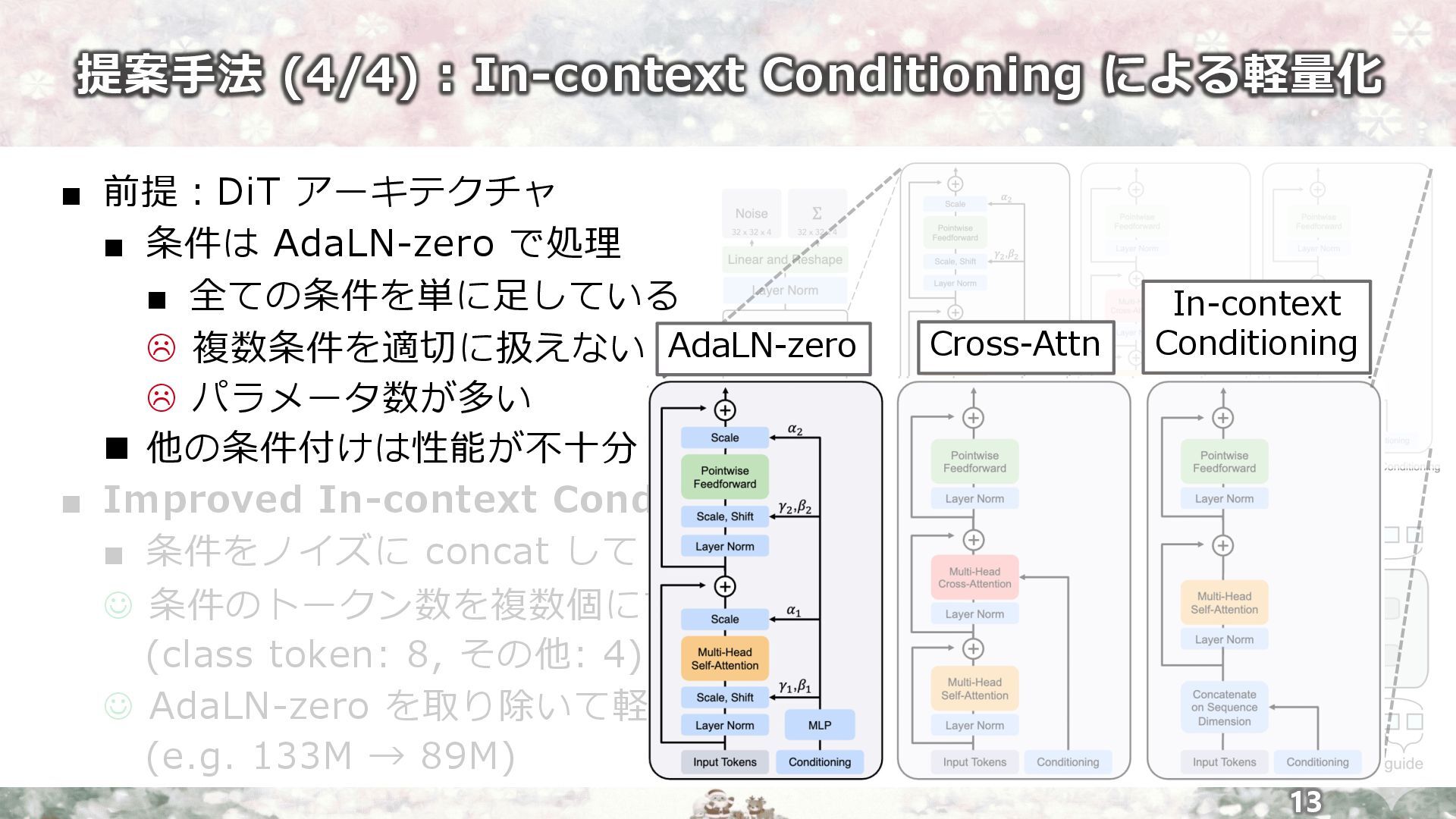
提案⼿法 (4/4) : In-context Conditioning による軽量化 13 ▪ 前提︓DiT アーキテクチャ
▪ 条件は AdaLN-zero で処理 ▪ 全ての条件を単に⾜している L 複数条件を適切に扱えない L パラメータ数が多い n 他の条件付けは性能が不⼗分 ▪ Improved In-context Conditioning ▪ 条件をノイズに concat して Transformer に⼊⼒ J 条件のトークン数を複数個にすることで実⽤可能に (class token: 8, その他: 4) J AdaLN-zero を取り除いて軽量化 (e.g. 133M → 89M) DiT [Peebles+, ICCV23] AdaLN-zero Cross-Attn In-context Conditioning
提案⼿法 (4/4) : In-context Conditioning による軽量化 14 ▪ 前提︓DiT アーキテクチャ
▪ 条件は AdaLN-zero で処理 ▪ 全ての条件を単に⾜している L 複数条件を適切に扱えない L パラメータ数が多い n 他の条件付けは性能が不⼗分 ▪ Improved In-context Conditioning ▪ 条件をノイズに concat して DiT に⼊⼒ J 条件のトークン数を複数個にすることで実⽤可能に (class token: 8, その他: 4) J AdaLN-zero を取り除いて33%軽量化 (e.g. 133M → 89M) DiT [Peebles+, ICCV23]
実験設定 15 ▪ タスク︓クラスラベルに基づく画像⽣成 ▪ データセット︓ImageNet(256x256) ▪ ⽣成⽅法 ▪ 潜在空間で⽣成
(4x32x32) ▪ 事前学習済みのVAEを使⽤ ▪ {1,2}-NFE ⽣成 ▪ 評価指標︓Fréchet Inception Distance (FID) ▪ ハードウェア構成︓記載なし ▪ 訓練時間︓記載なし
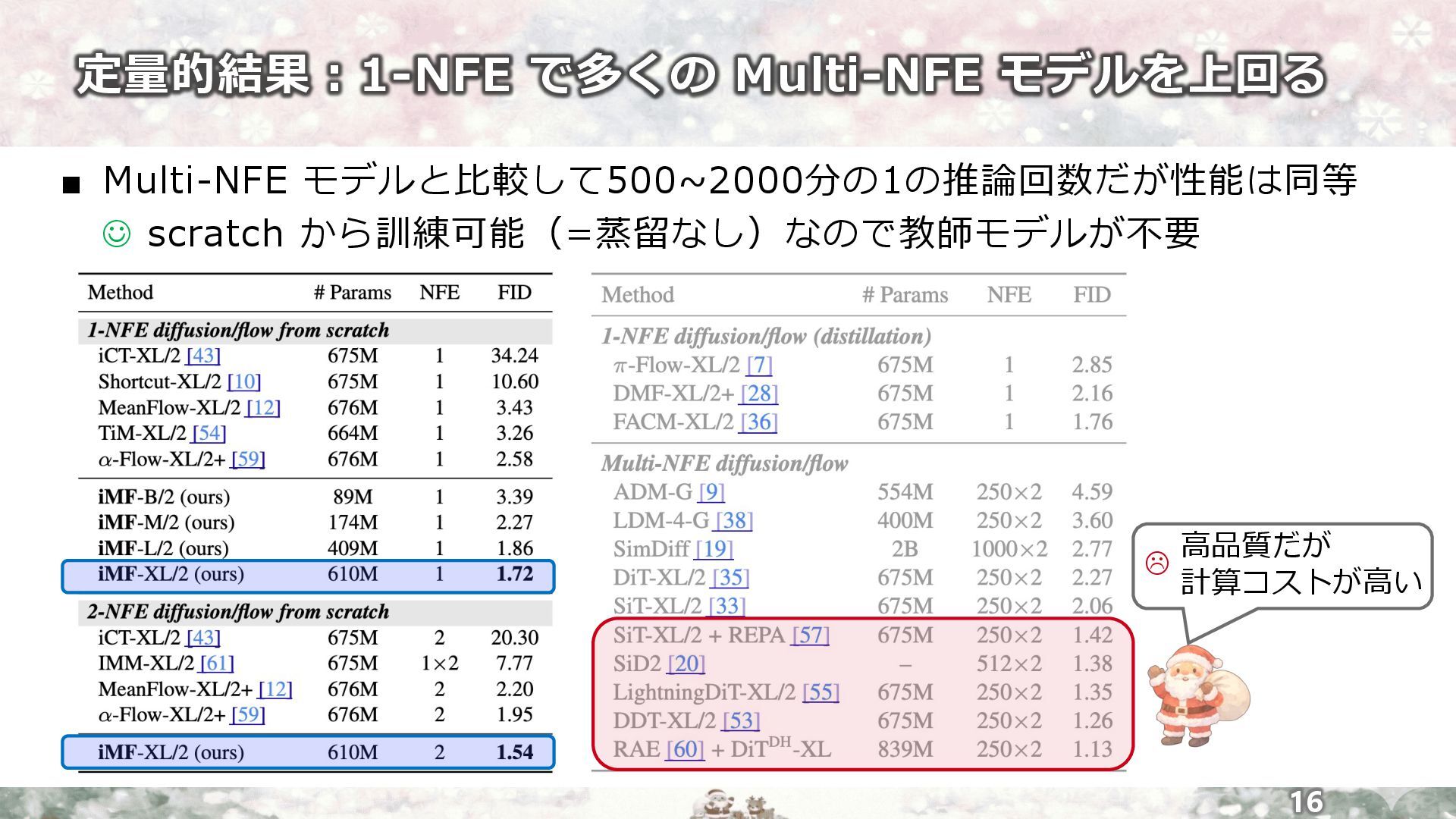
定量的結果︓1-NFE で多くの Multi-NFE モデルを上回る 16 ▪ Multi-NFE モデルと⽐較して500~2000分の1の推論回数だが性能は同等 J scratch
から訓練可能(=蒸留なし)なので教師モデルが不要 ⾼品質だが 計算コストが⾼い L
Ablation studies 17 J CFG (Flexible Guidance) を⽤いることで性能向上 J in-context
conditioning により軽量化かつ性能向上 ※ aux. head … 𝑣% ⽤の head を追加
定性的結果︓⾼品質な画像を⽣成 18
まとめ 19 ▪ 背景︓Mean Flows J 1-NFEで⾼品質な⽣成 L 数式に粗い近似が存在 ▪
提案︓Improved Mean Flows J Mean Flows における数式的な問題を改善 J 柔軟な Classifier Free Guidance J in-context conditioning による軽量化 ▪ 結果 J 1-NFE で多くの Multi-NFE モデルを上回る
{kind=link}
{kind=link}
{kind=link}
![関連研究︓Mean Flows の改善 4 ⼿法 特徴 AlphaFlow [Zhang+, 25] Flow](https://files.speakerdeck.com/presentations/a135e573c6df43df852246615805f4ef/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}