Vision Language Action Models Rokas Bendikas1, Daniel Dijkman2, Markus Peschl2, Sanjay Haresh2, Pietro Mazzaglia2 1Centre for Artificial Intelligence, UCL, 2Qualcomm AI Research Bendikas, R., Dijkman, D., Peschl, M., Haresh, S., & Mazzaglia, P. Focusing on What Matters: Object-Agent-centric Tokenization for Vision Language Action models. In 9th Annual Conference on Robot Learning. CoRL 2025
◼ out-of-distribution tasks ◼ 指示文の名詞を入れ替えるなどした 未知のタスク (全体)物体の向きや位置を軽微な変化を加える タスクの例 (a) Place the banana in green bowl (b) Place red cube in the brown bag ☺ 既知タスク・未知タスクともに OpenVLAより高い成功率
{kind=link}
{kind=link}
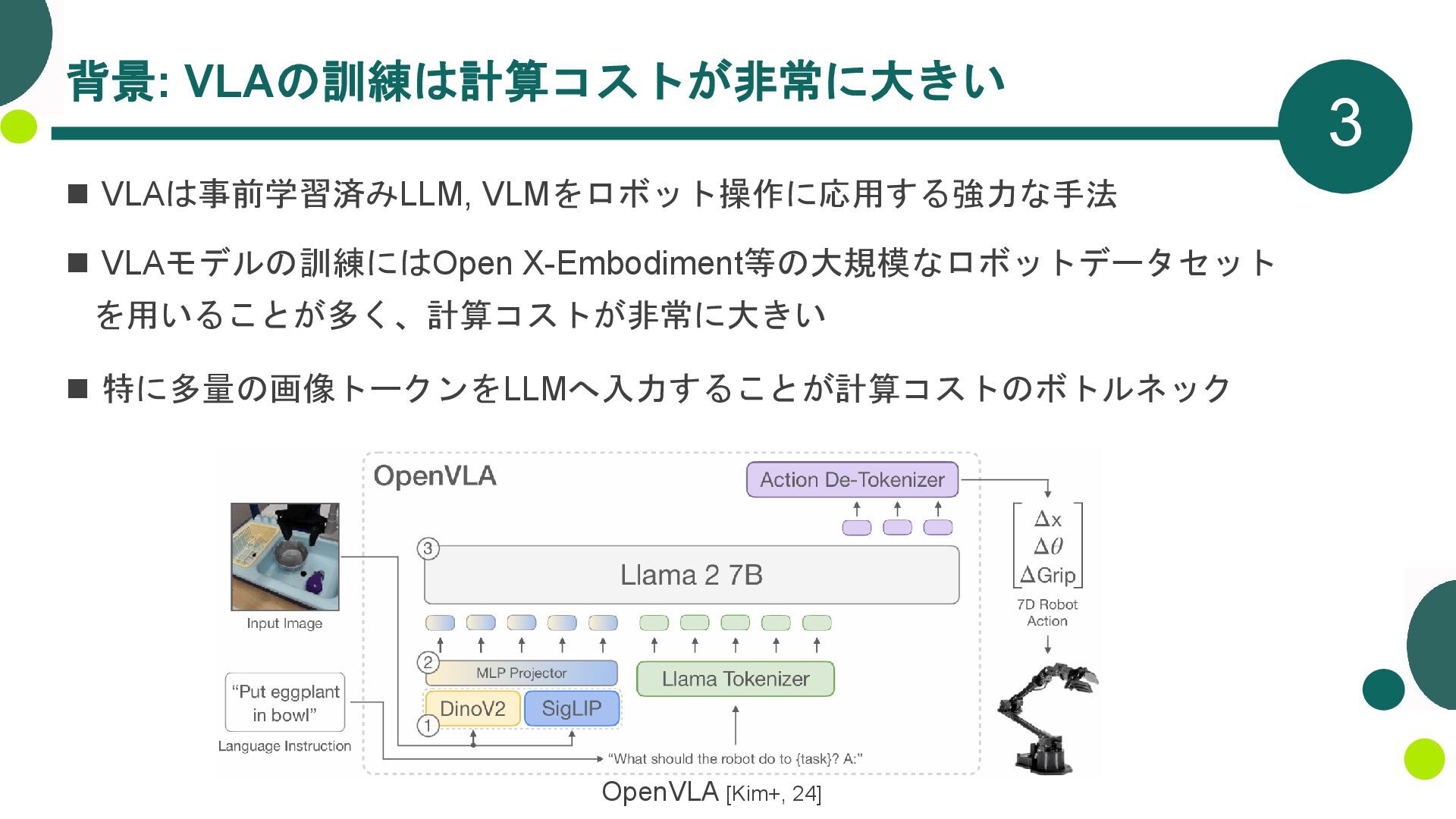{kind=link}
![4 関連研究: VLAを効率化する様々な手法が提案 ◼ 小さなモデルサイズやObject-centricの情報の入力をする研究 手法 詳細 TinyVLA [Wen+, RAL25]](https://files.speakerdeck.com/presentations/32e6c77f18ee4f2d8a22557358a006cb/slide_3.jpg){kind=link}
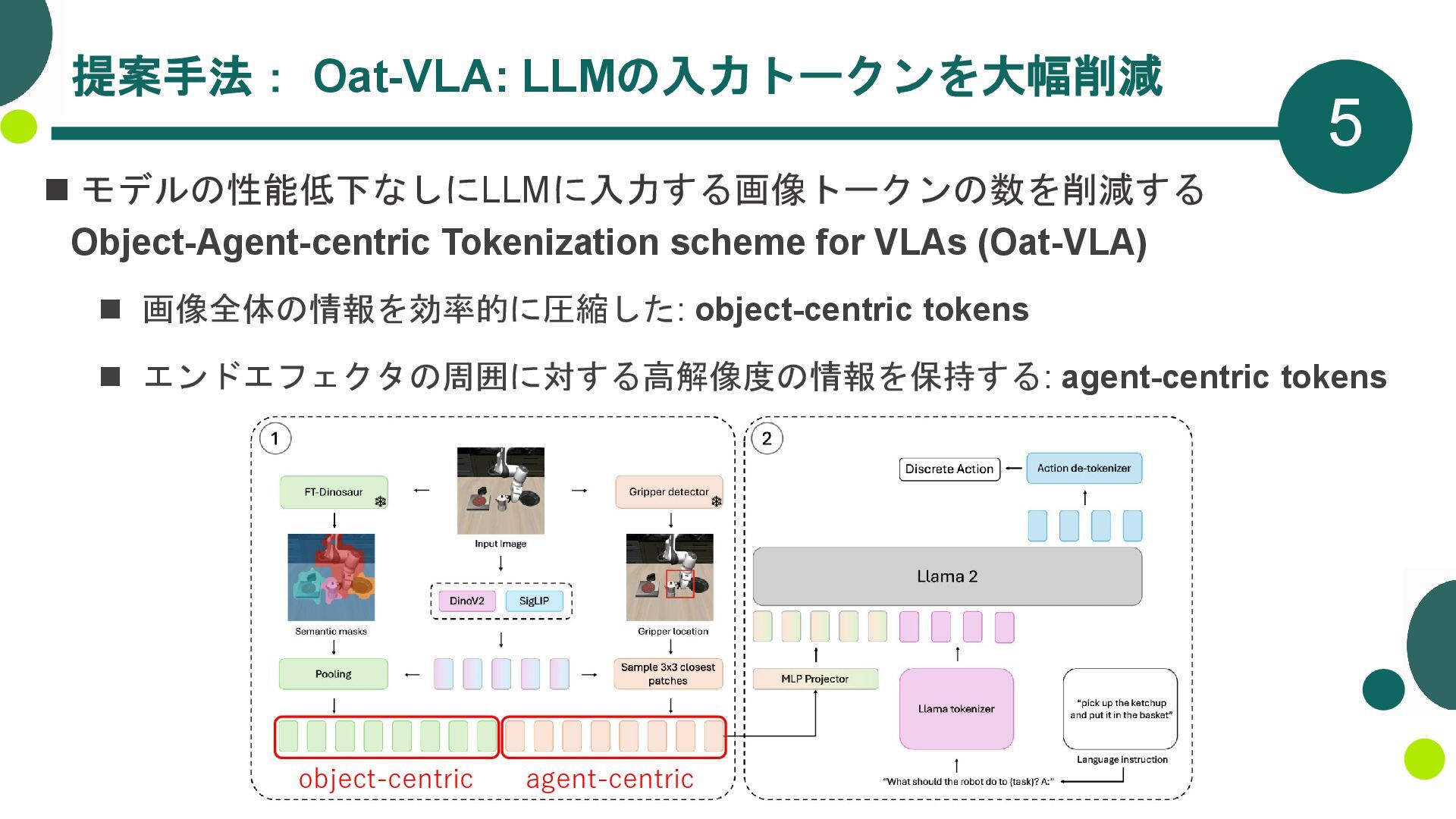{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
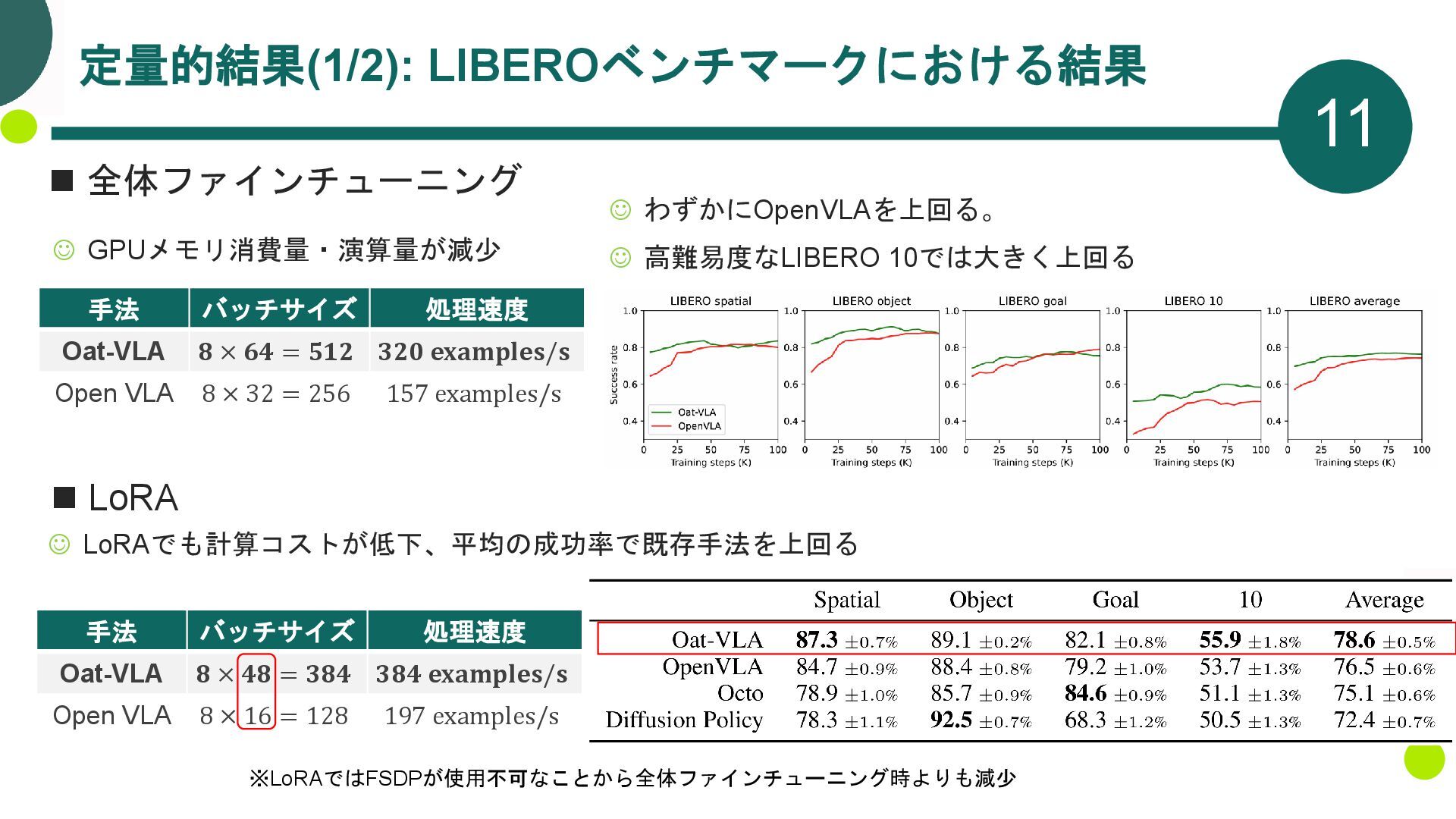{kind=link}
{kind=link}
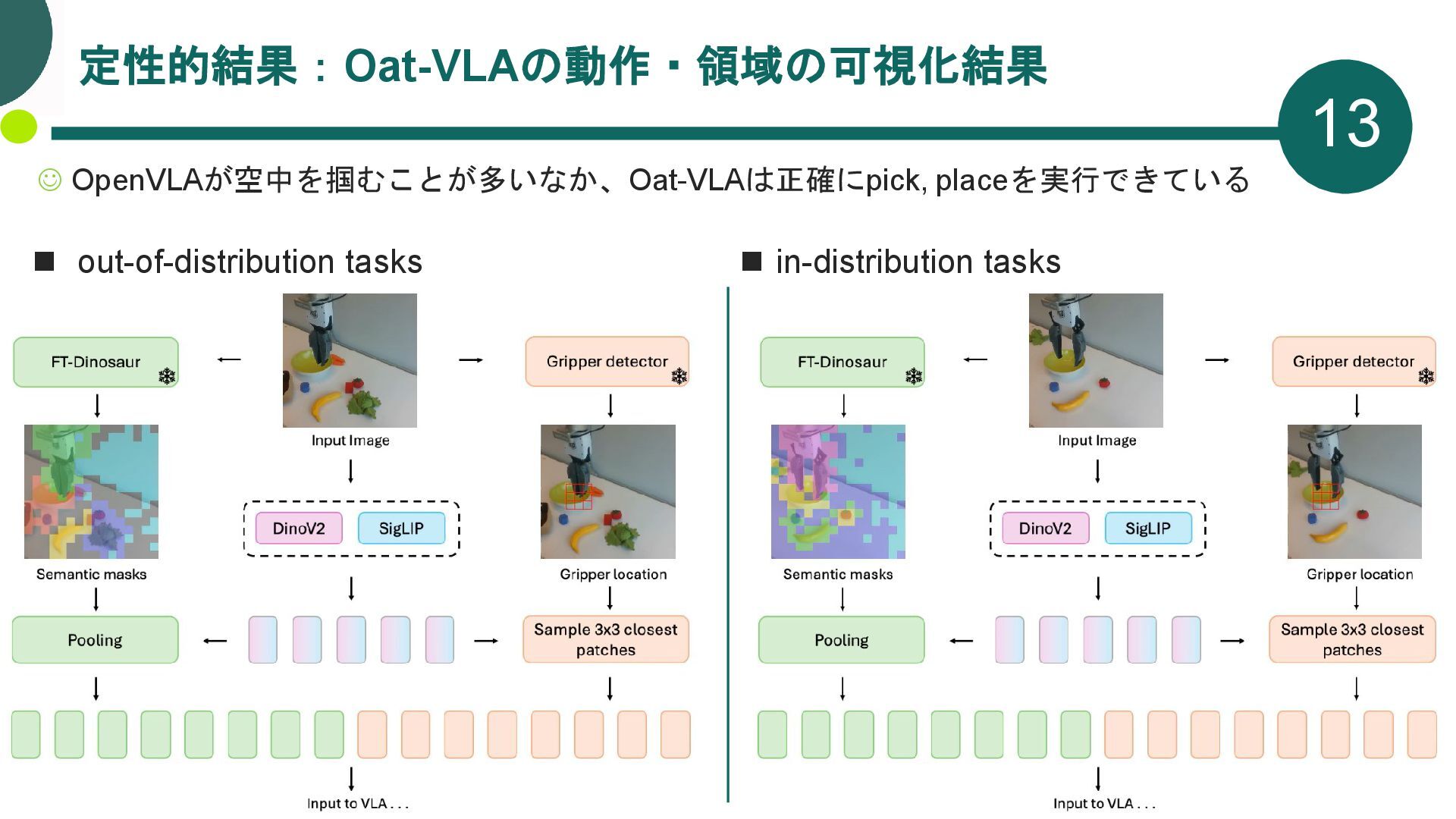{kind=link}
{kind=link}
{kind=link}
{kind=link}
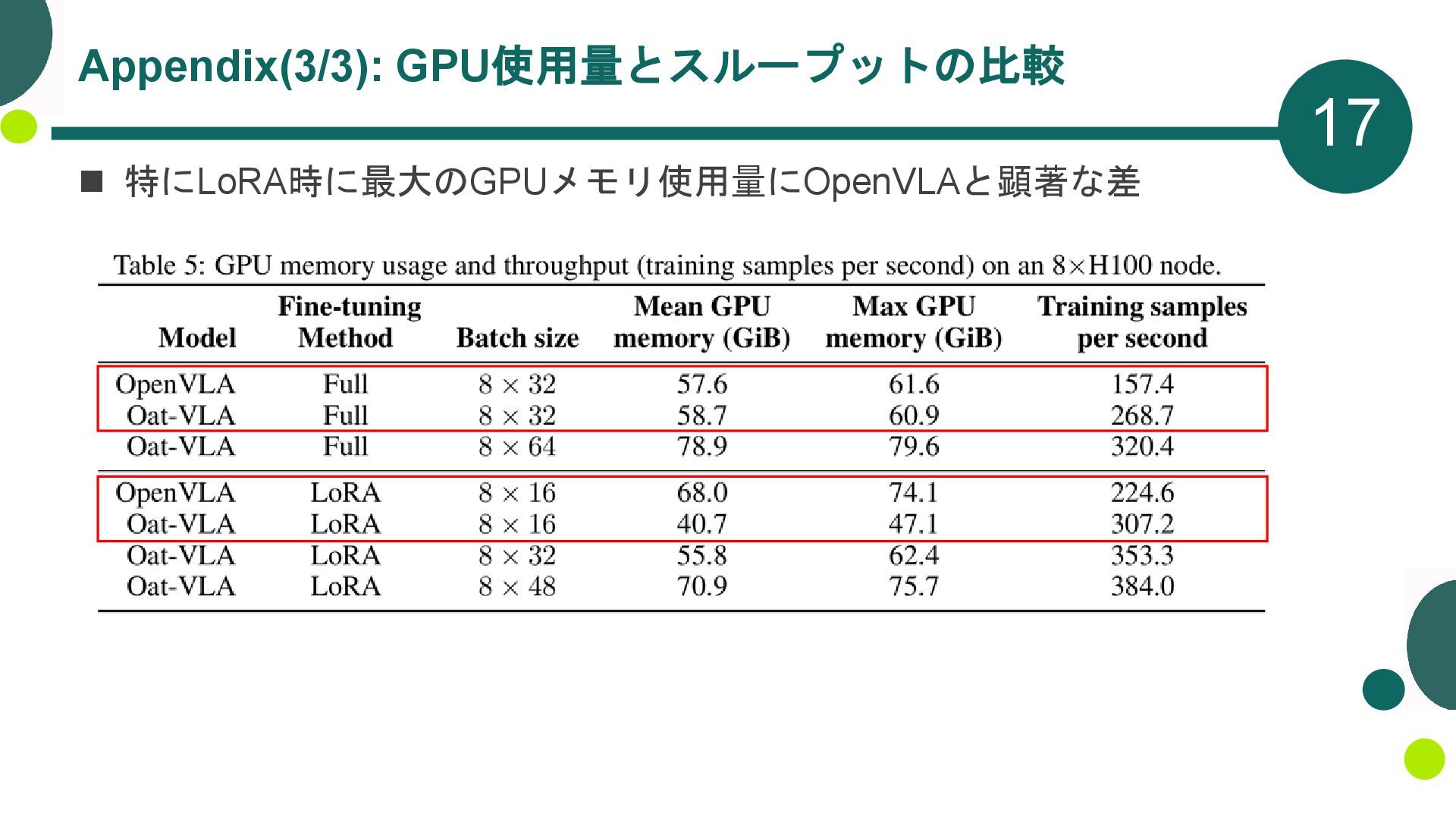{kind=link}