CoRL22] • Transporter Networks[Zeng+ CoRL20] を拡張してCLIP の言語/画像特徴量を導入 • 「どの位置にグリッパを移動させるか」を予測 KITE [Sundaresan+ CoRL23] 「物体のどの部分を掴むか(キーポイント)」を予測 物体検索 CLIP-Fields [Shafiullah+ RSS23] Detic, BERT, CLIPの組み合わせで物体の探索を行う OpenScene [Peng+ CVPR23] Open-vocabularyの3D Scene understanding
{kind=link}
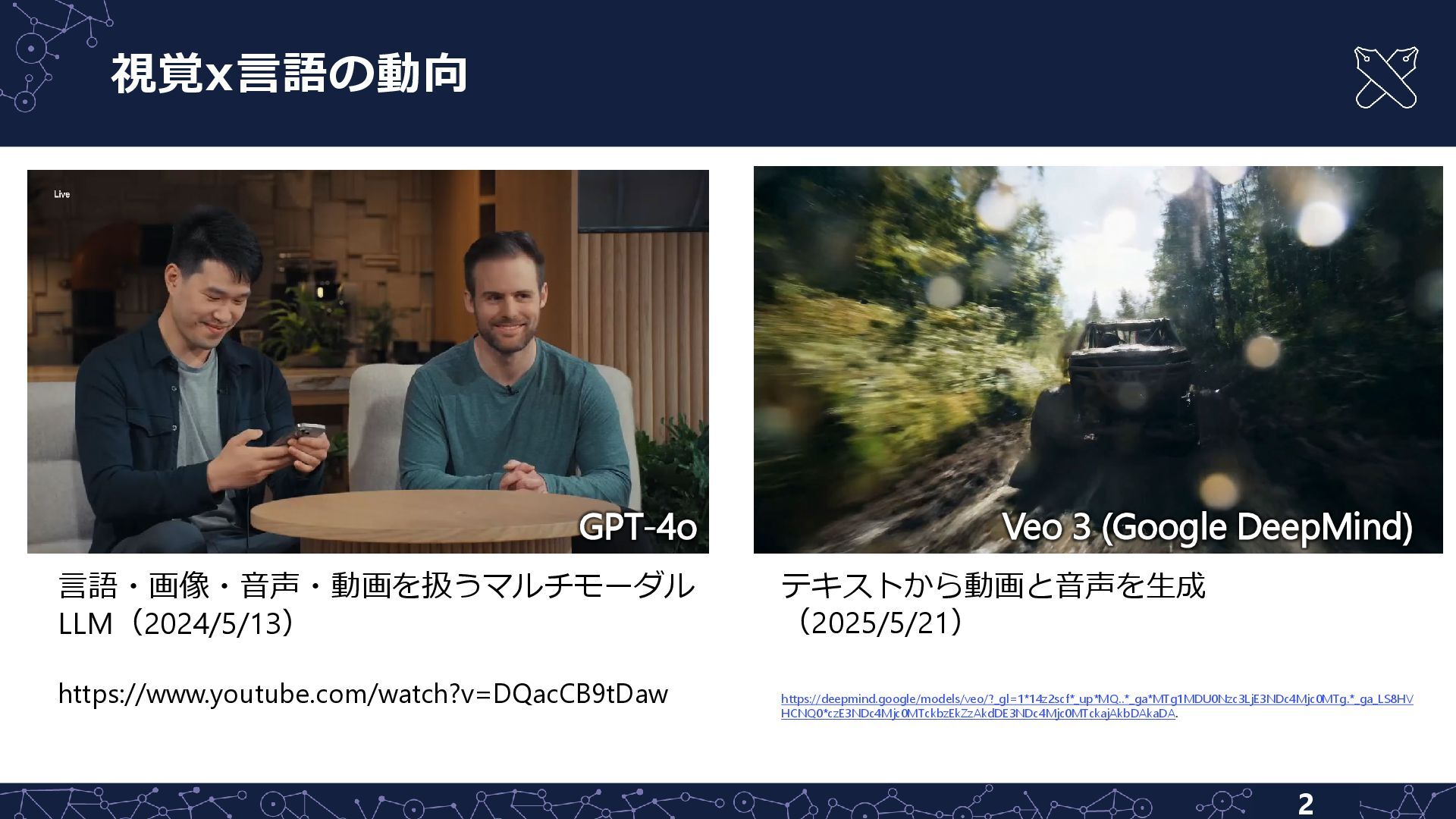{kind=link}
{kind=link}
{kind=link}
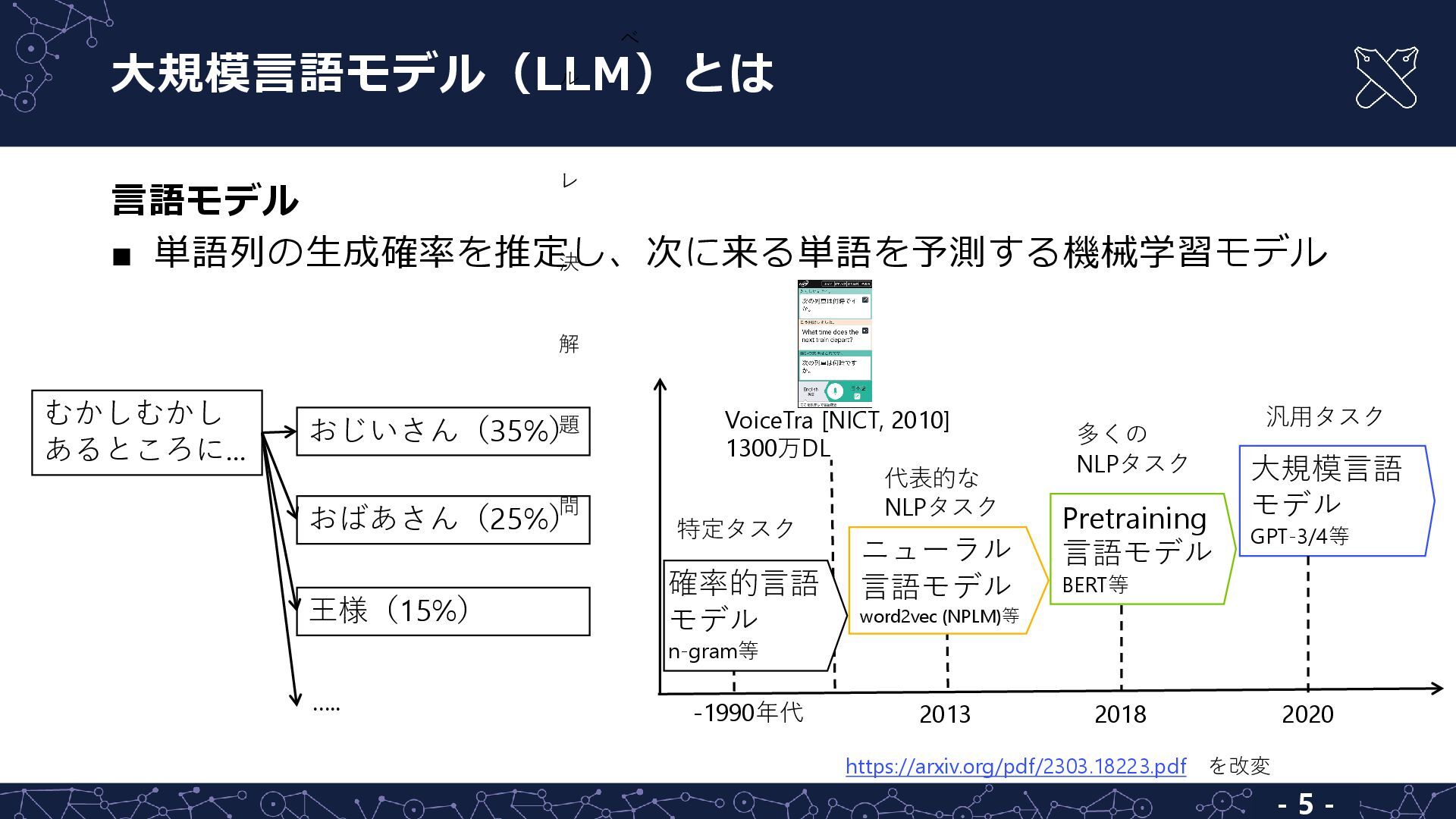{kind=link}
{kind=link}
![視覚言語基盤モデルの代表例:CLIP [Radford+ 2021] - - 7 ▪ 学習: 画像とテキストの組(4億組)の特徴量同士を近付ける ▪](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_6.jpg){kind=link}
![CLIPを物体操作・探索に利用 - - 8 物体操作 CLIPort [Shridhar+ CoRL21], PerAct [Shridhar+](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_7.jpg){kind=link}
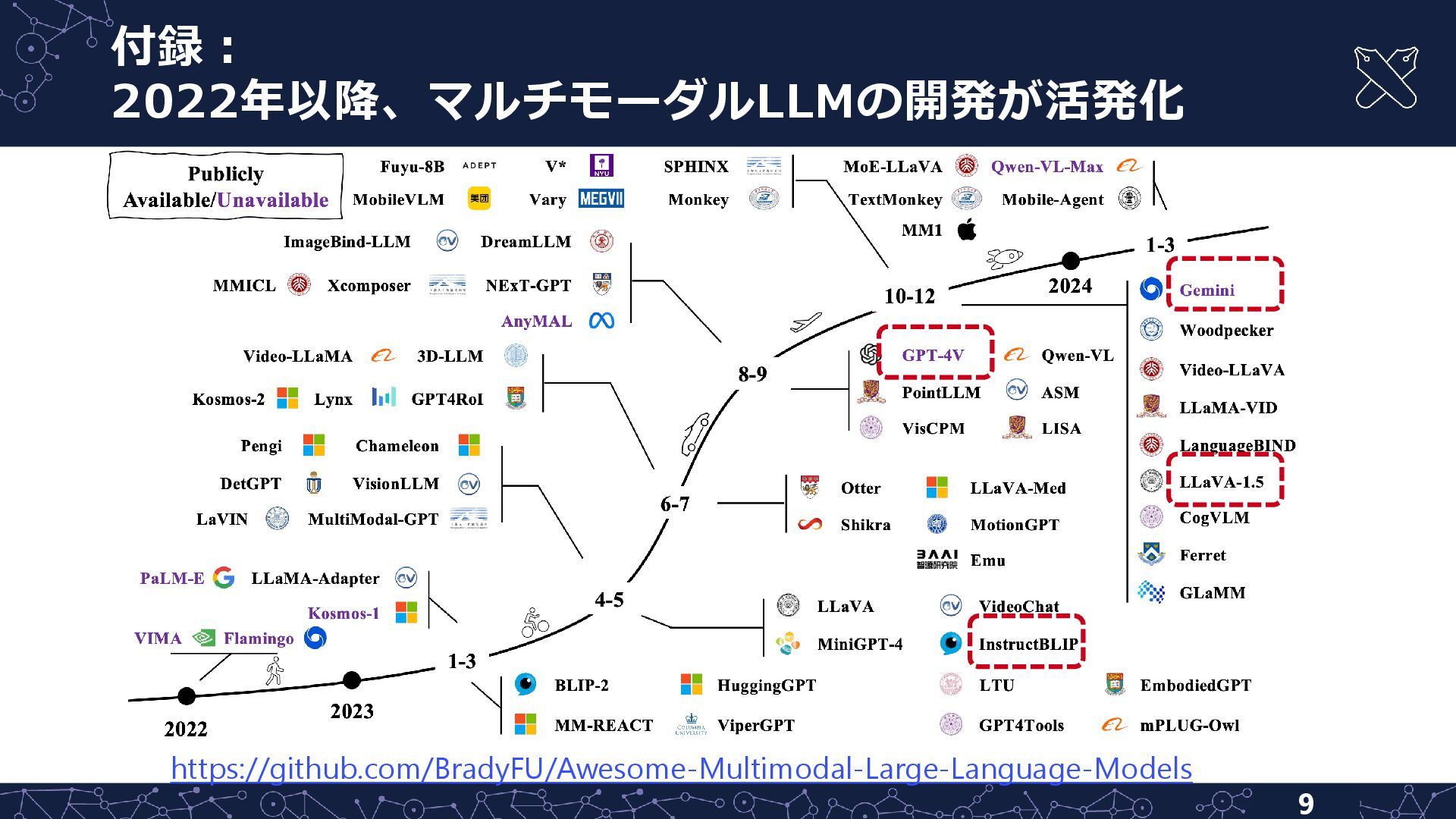{kind=link}
![マルチモーダルLLM(MLLM)の代表的構成 BLIP-2 [Li+ 2023], LLaVA[Liu+ NeurIPS23]等 10 ▪ 通常のLLM https://arxiv.org/abs/2306.13549](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_9.jpg){kind=link}
![マルチモーダルLLM(MLLM)の代表的構成 BLIP-2 [Li+ 2023], LLaVA[Liu+ NeurIPS23]等 11 ▪ Modality EncoderとGeneratorを設計すれば他モダリティに適用可](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![視覚言語行動モデル - - 15 手法 概要 PaLM SayCan [Ahn+ 2022]](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![語彙の制約がない物体操作の統合デモ [Yashima+ RAL25] [Kaneda+ RAL24] [Nishimura+ IROS24] [Korekata+ IROS23] 社会課題](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_18.jpg){kind=link}
![言語指示に基づく物体操作までの流れ - - 20 ① 探索位置・姿勢の最適化 ② 実世界検索 [Kaneda+ RAL24][Yashima+](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_19.jpg){kind=link}
![実世界検索エンジン [Kaneda+ IEEE RAL24] [Yashima+ IEEE RAL25] 21 背景 ▪](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_20.jpg){kind=link}
![マルチモーダルタスク成否判定[Goko+ CoRL24] 22 技術ポイント ▪ マルチモーダルLLMを含む多階層マルチモーダル表現 ▪ 状況間の差異と言語の関係をモデル化 結果 ▪](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_21.jpg){kind=link}
{kind=link}
![モビリティ向け移動指示理解 [Hosomi+ IEEE RAL24] [Hosomi+ IEEE RAL25] 【タスク】 「バイクが止まっている所の横に 停めて」等の移動指示言語理解](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_23.jpg){kind=link}
{kind=link}
![画像ベンチマーク:MMMU, MMMU-Pro Massive Multi-discipline Multimodal Understanding [Yue+ CVPR24][Yue+ 2024] 26](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![画像説明生成の評価[Wada+ CoNLL23][Wada+ CVPR24][Matsuda+ ACCV24] デモ→https://huggingface.co/spaces/yuwd/Polos-Demo 29 背景: 画像説明生成モデル開発の標準尺度は人手評価との相関が0.3しかない 技術ポイント: ▪](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_28.jpg){kind=link}
![エージェントベンチマーク: 移動指示・物体探索指示理解 実世界 ▪ R2R [Anderson+ CVPR18], REVERIE[Qi+ CVPR20] ▪](https://files.speakerdeck.com/presentations/2b532170f4cb4770872ec5c475d5641f/slide_29.jpg){kind=link}
{kind=link}
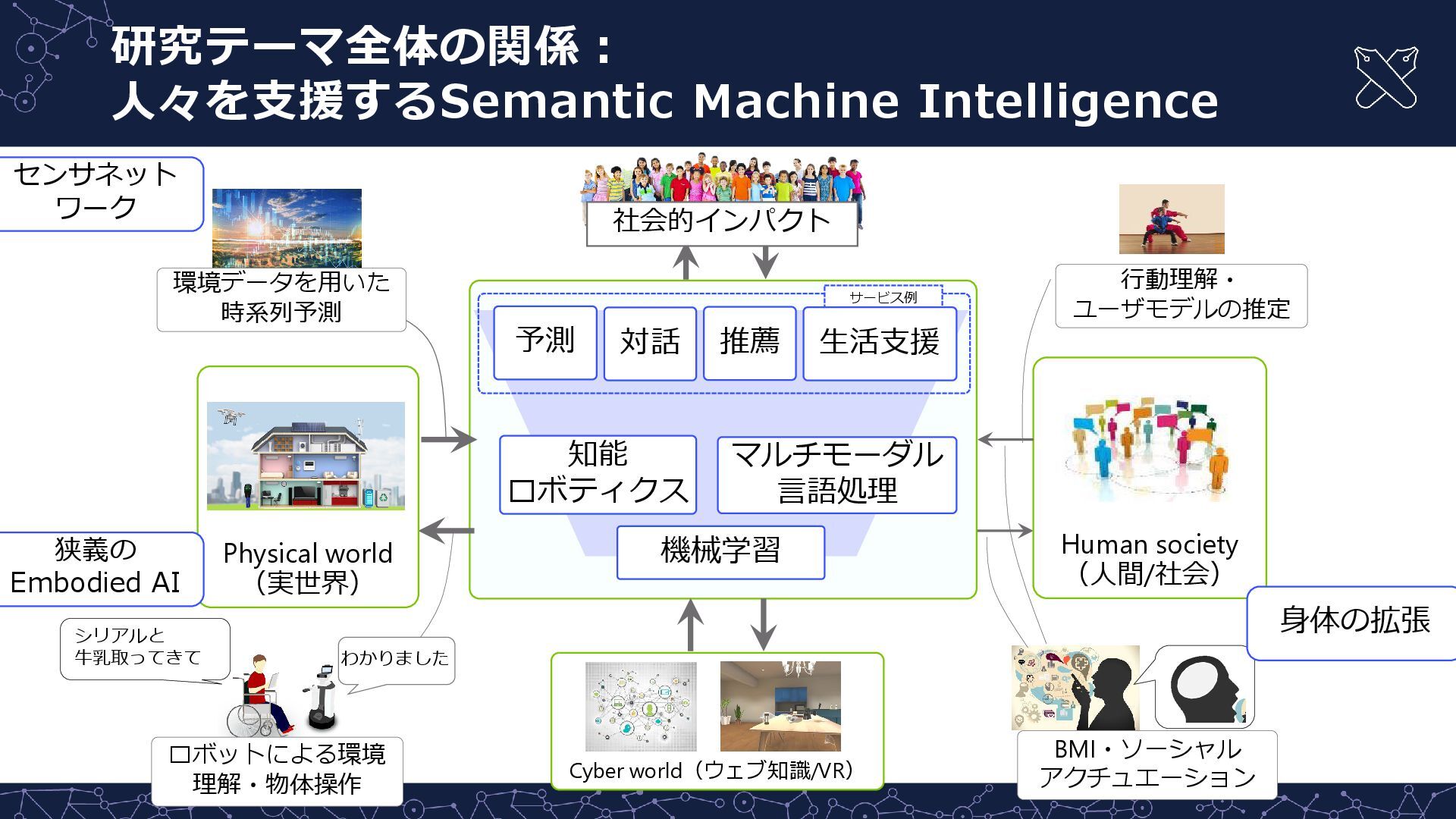{kind=link}
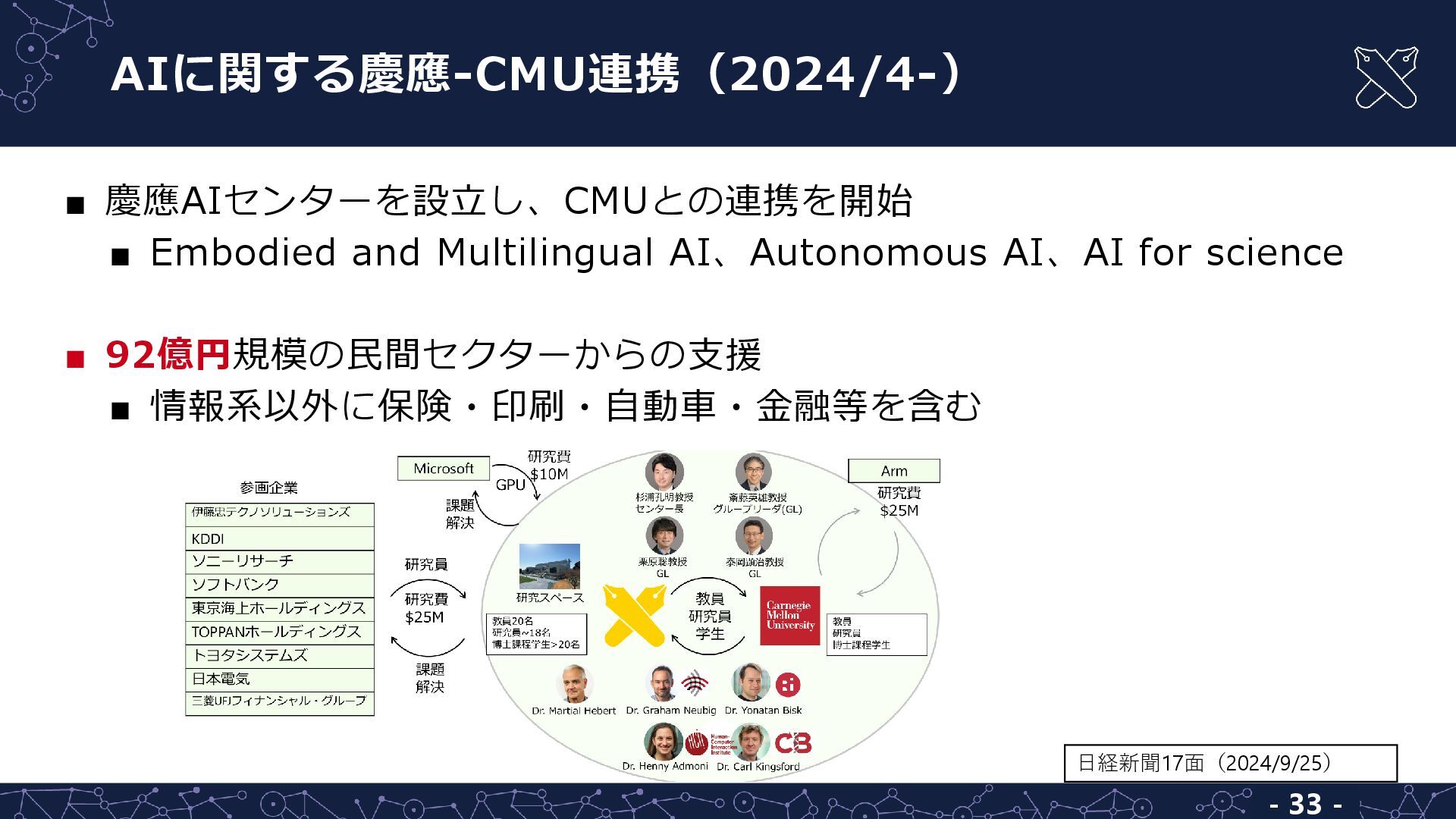{kind=link}
{kind=link}
{kind=link}