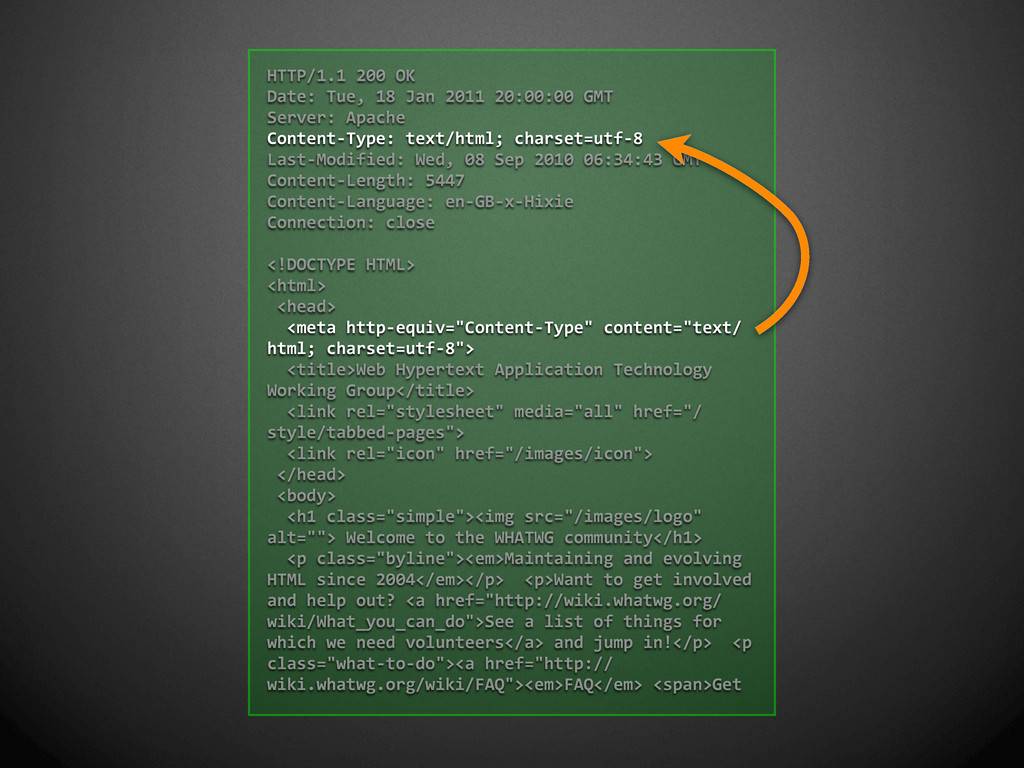
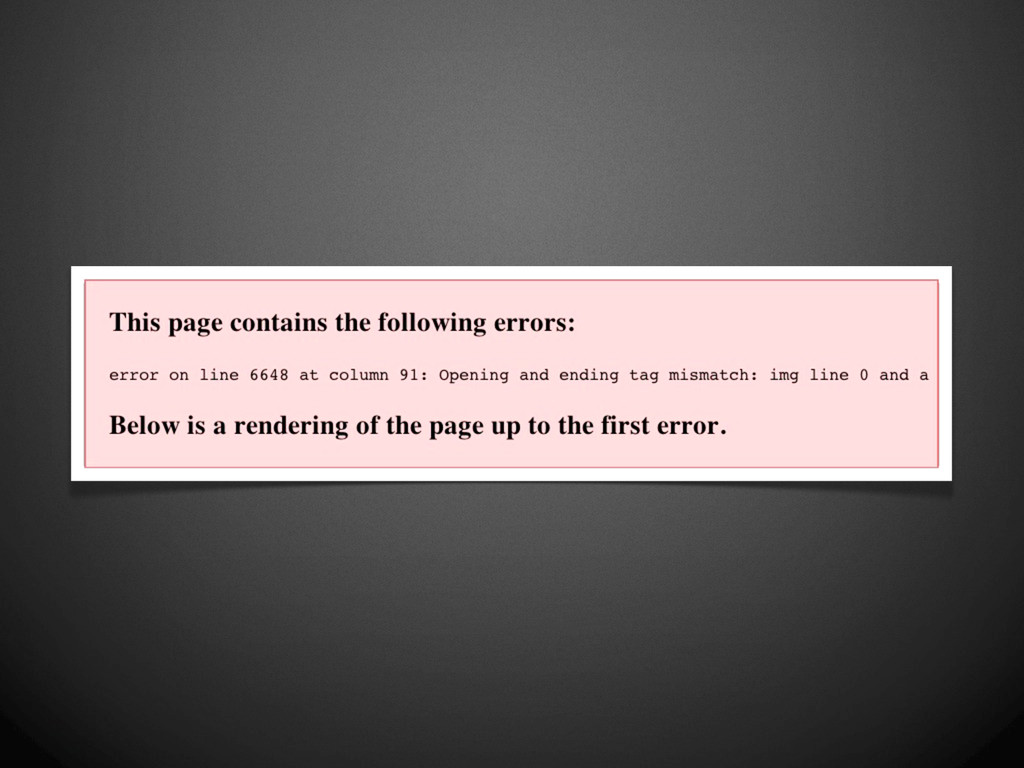
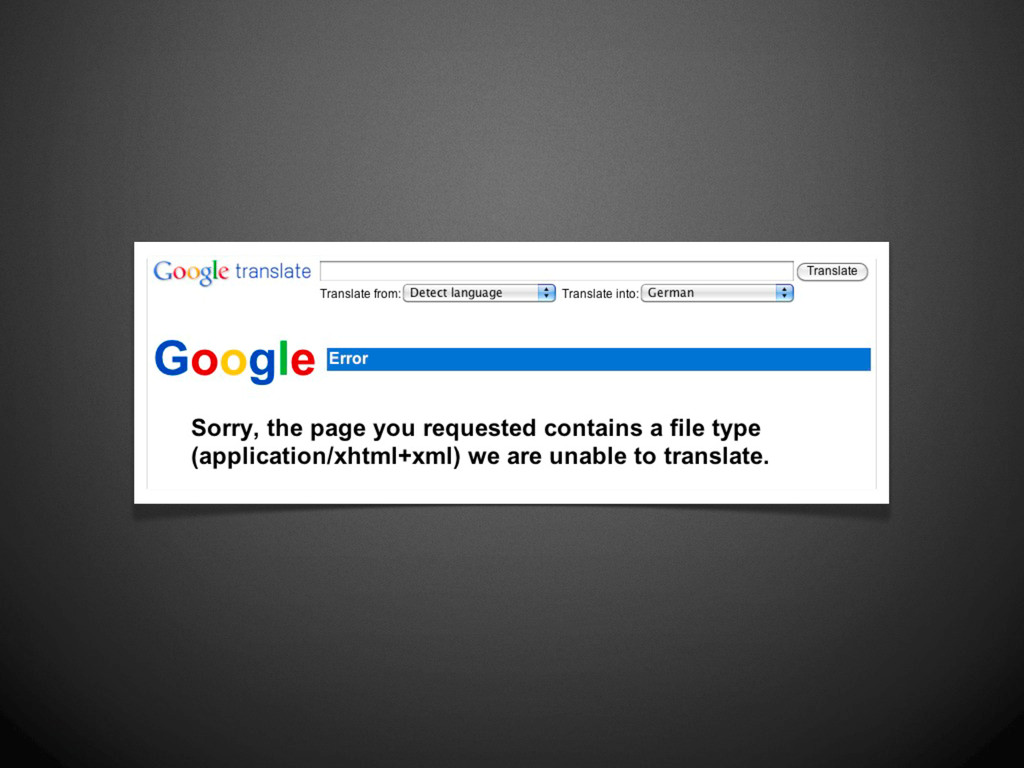
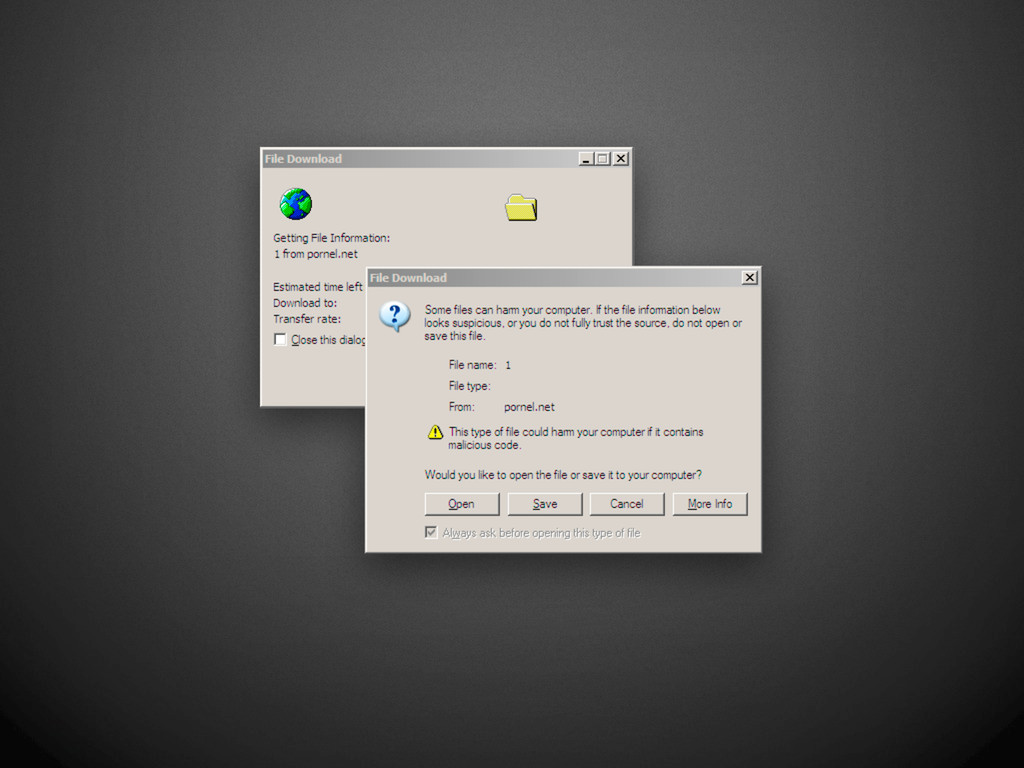
was to allow old (HTML-only) browsers to accept XHTML 1.0 documents by following the guidelines, and serving them as text/html. Therefore, documents served as text/html should be treated as HTML and not as XHTML. There should be no sniffing of text/html documents to see if they are really XHTML. Note that there are some semantic differences between HTML documents and XHTML documents: there are specific CSS rules that only apply to HTML (and not XHTML), and the DOM has different effects (for instance, the element names are returned in uppercase for HTML, and lower case for XHTML). Best wishes, Steven Pemberton Chair, W3C HTML WG ” “
{kind=link}
{kind=link}
{kind=link}
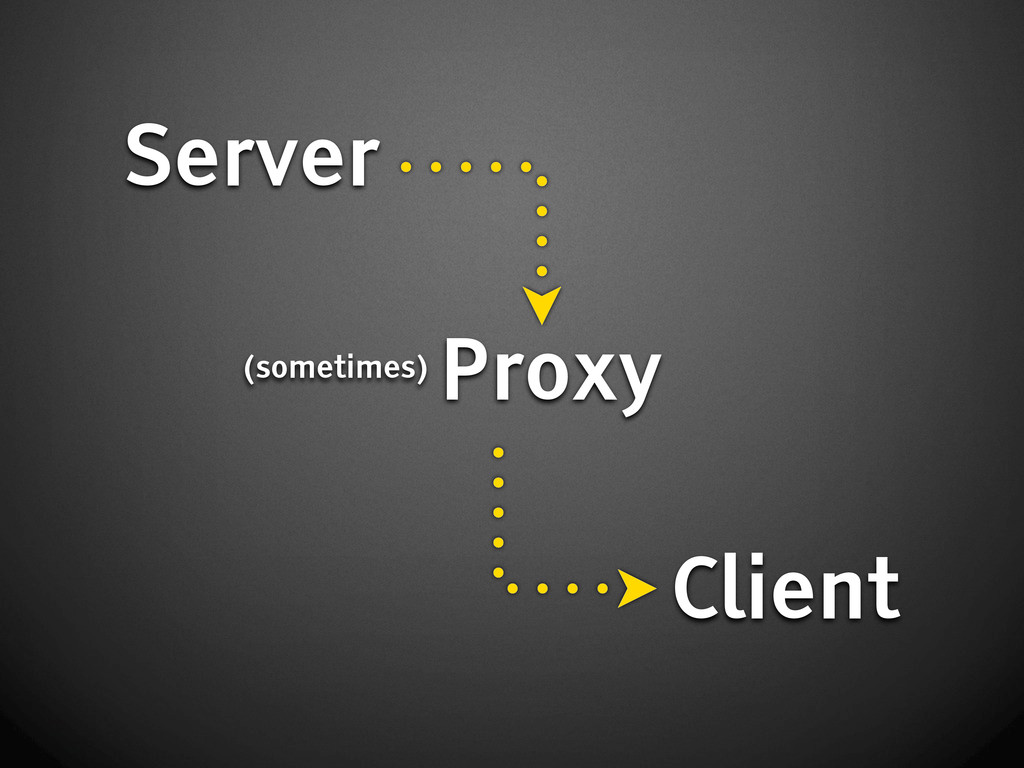{kind=link}
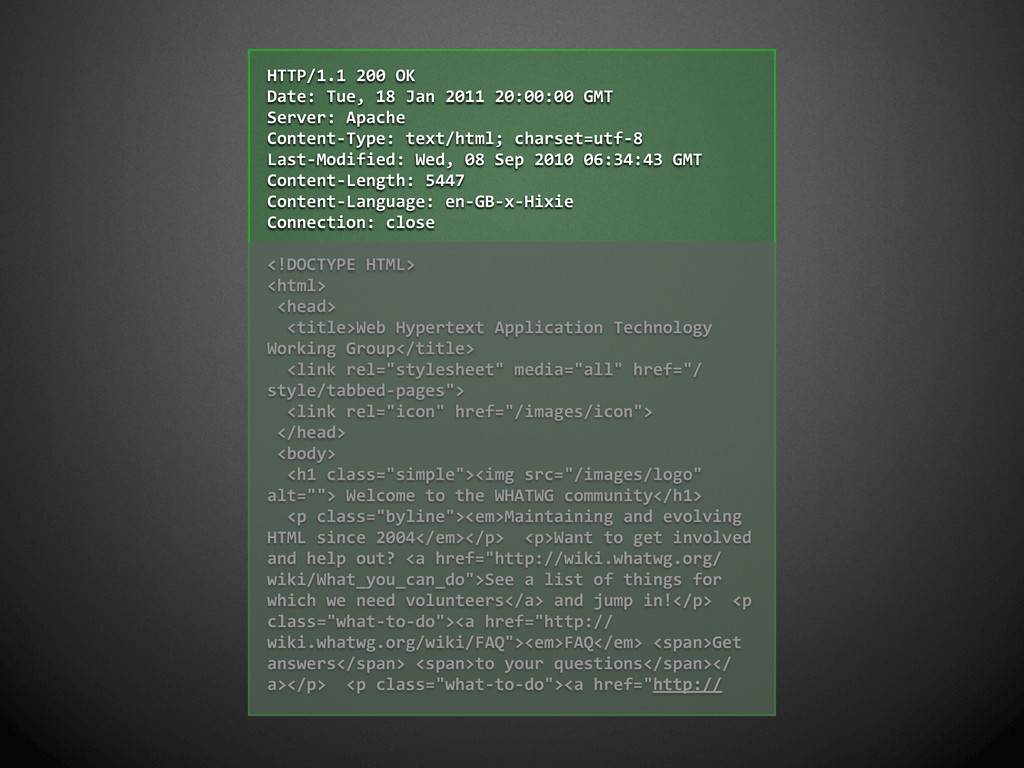{kind=link}
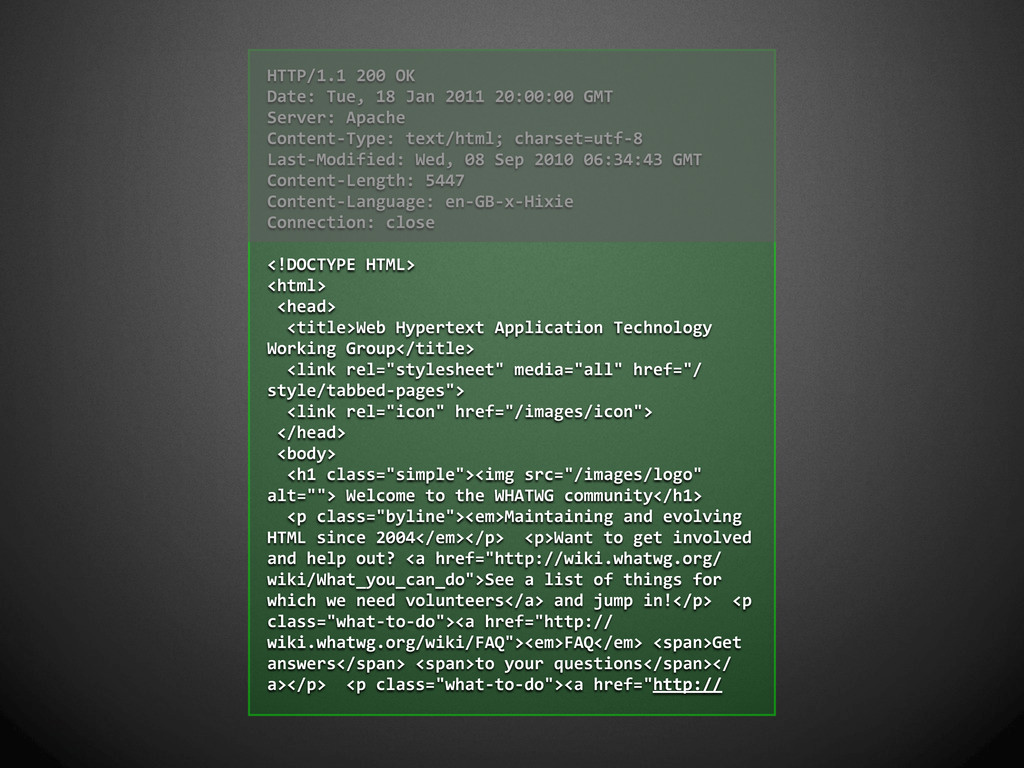{kind=link}
{kind=link}
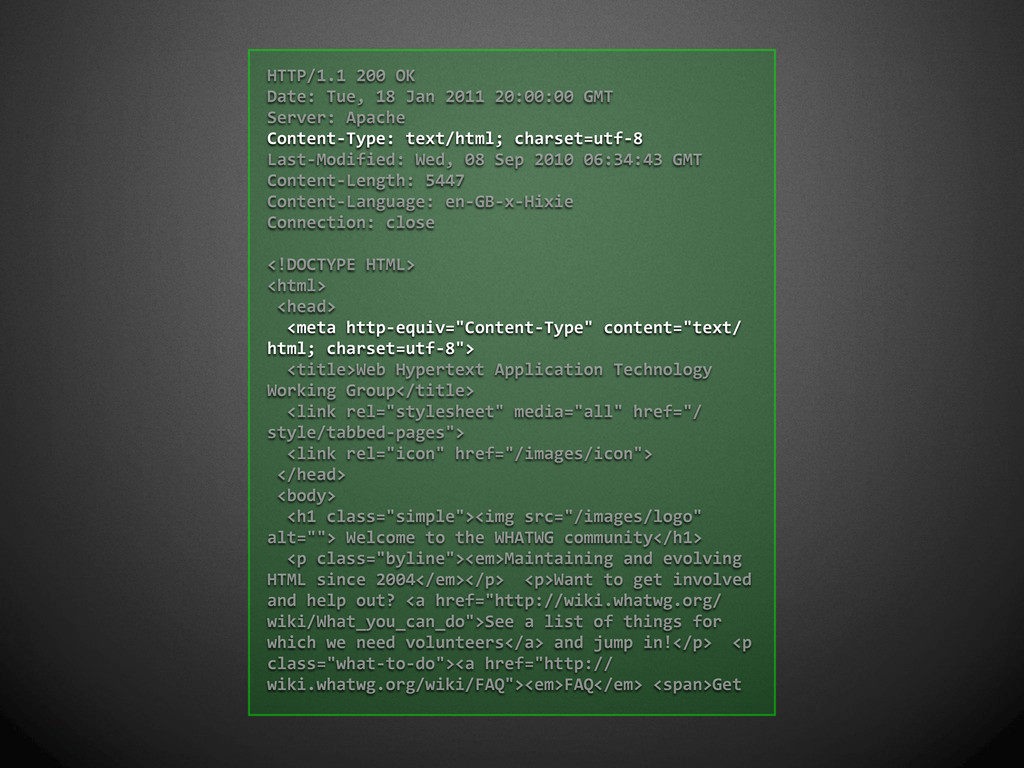{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}