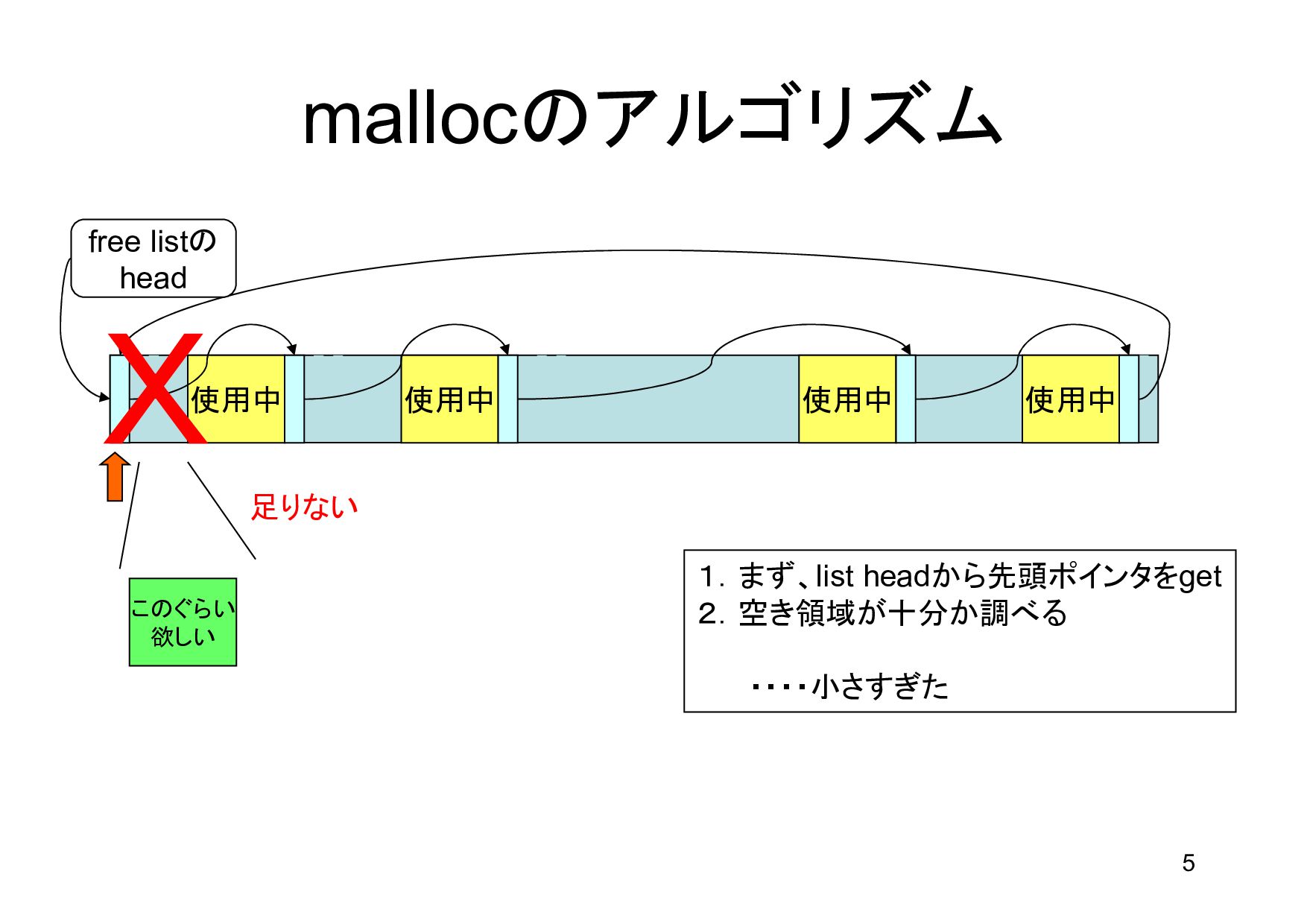
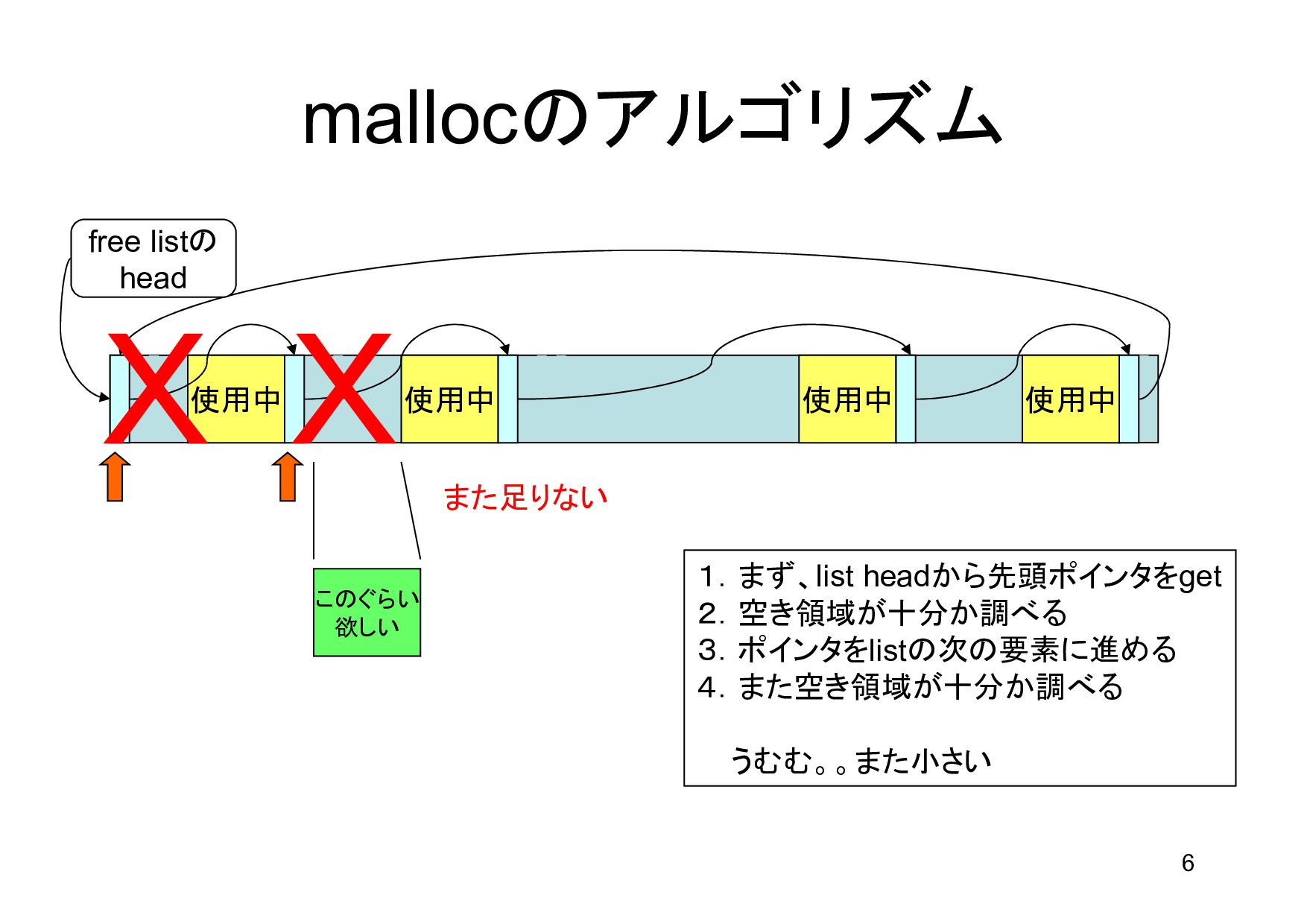
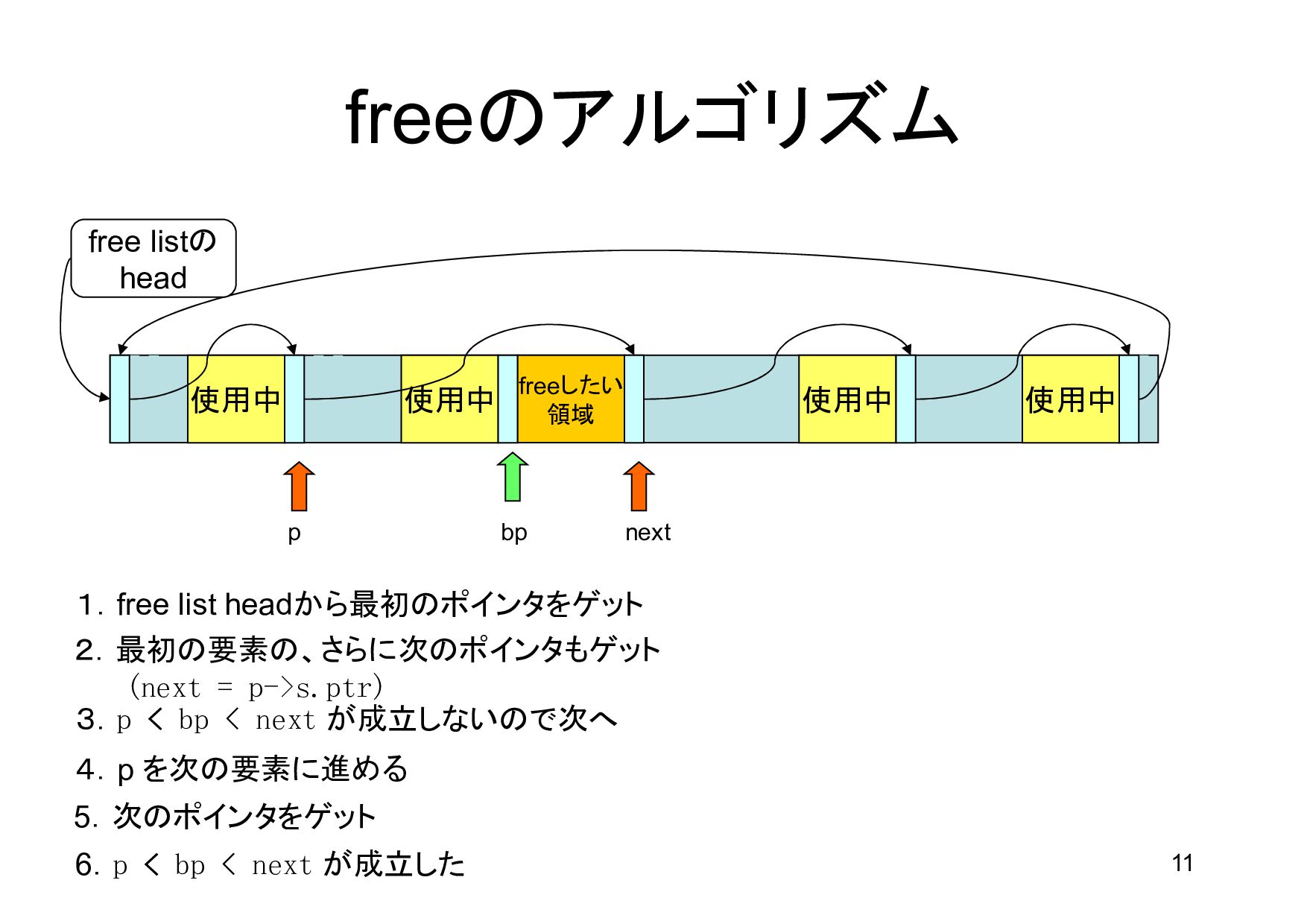
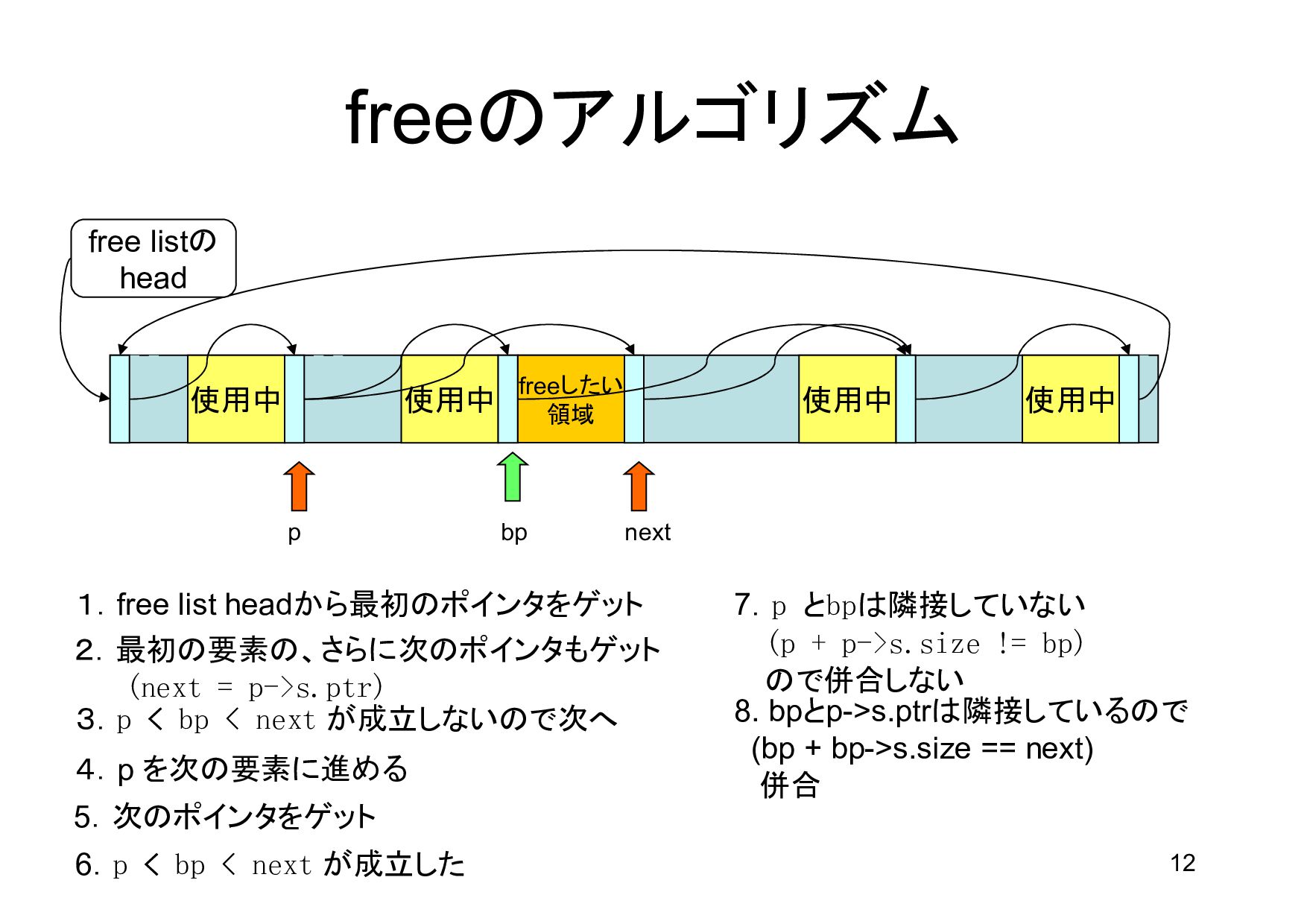
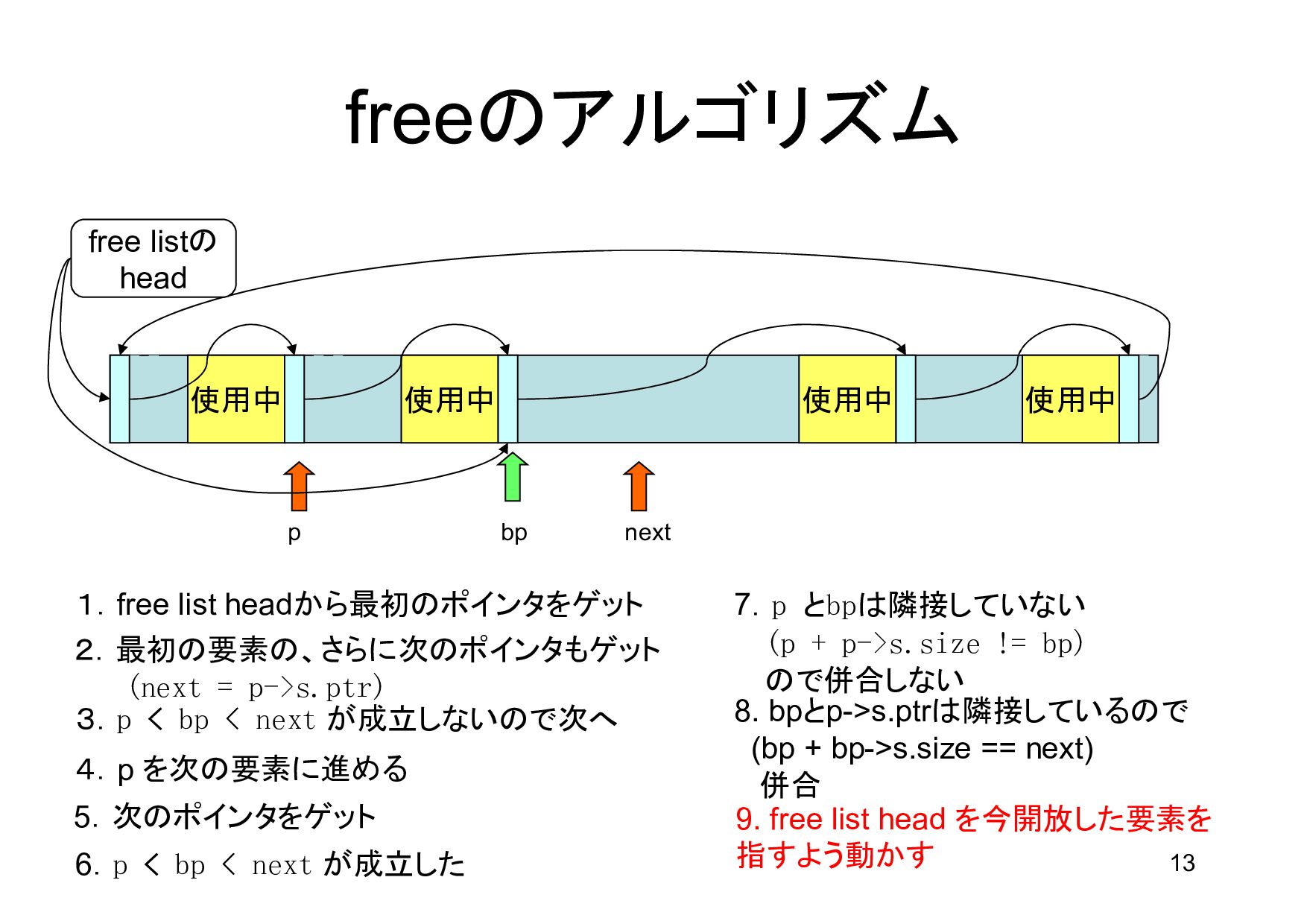
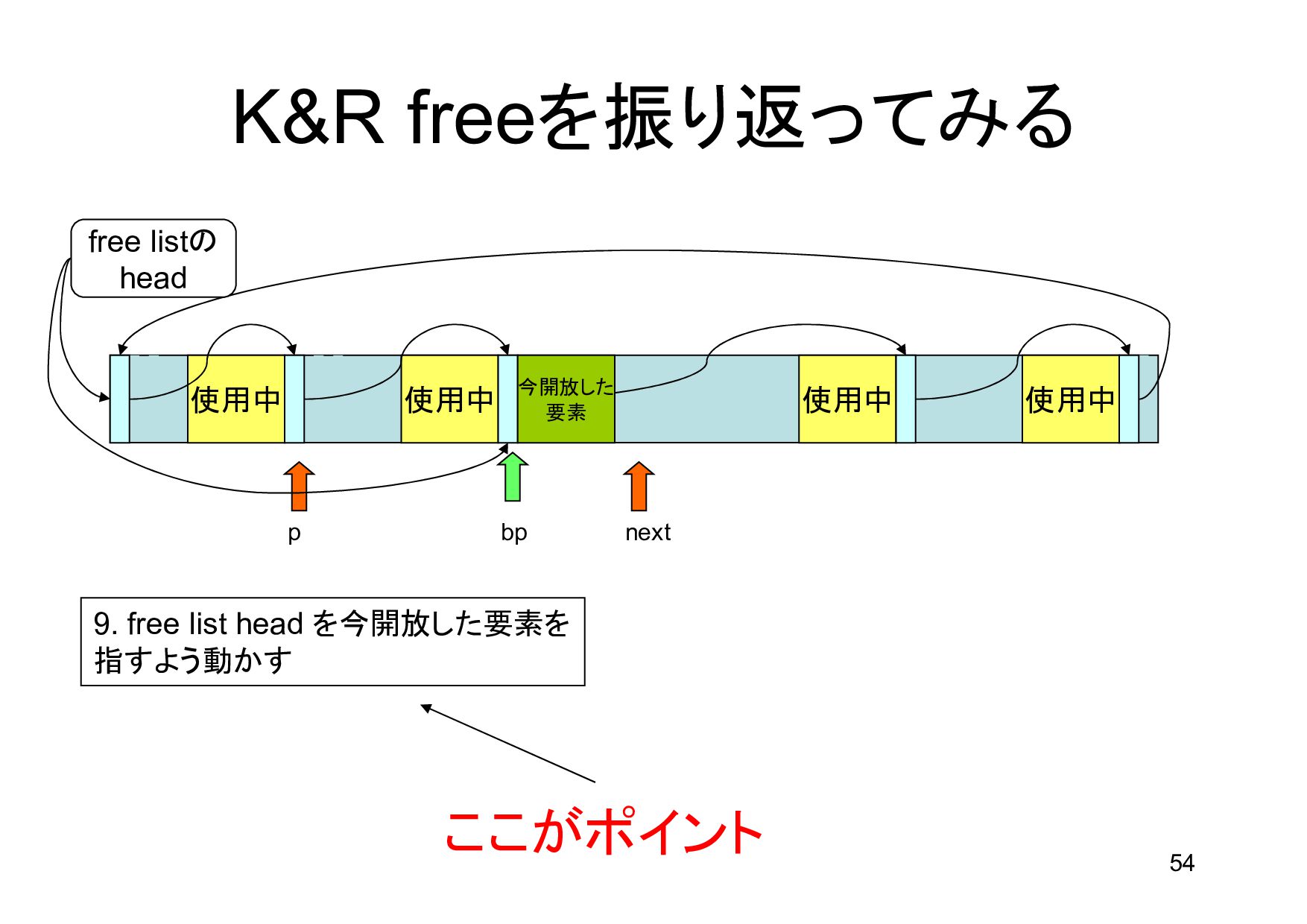
領域 bp p next 1.free list headから最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3.p < bp < next が成立しないので次へ 4.p を次の要素に進める 5.次のポインタをゲット 6.p < bp < next が成立した
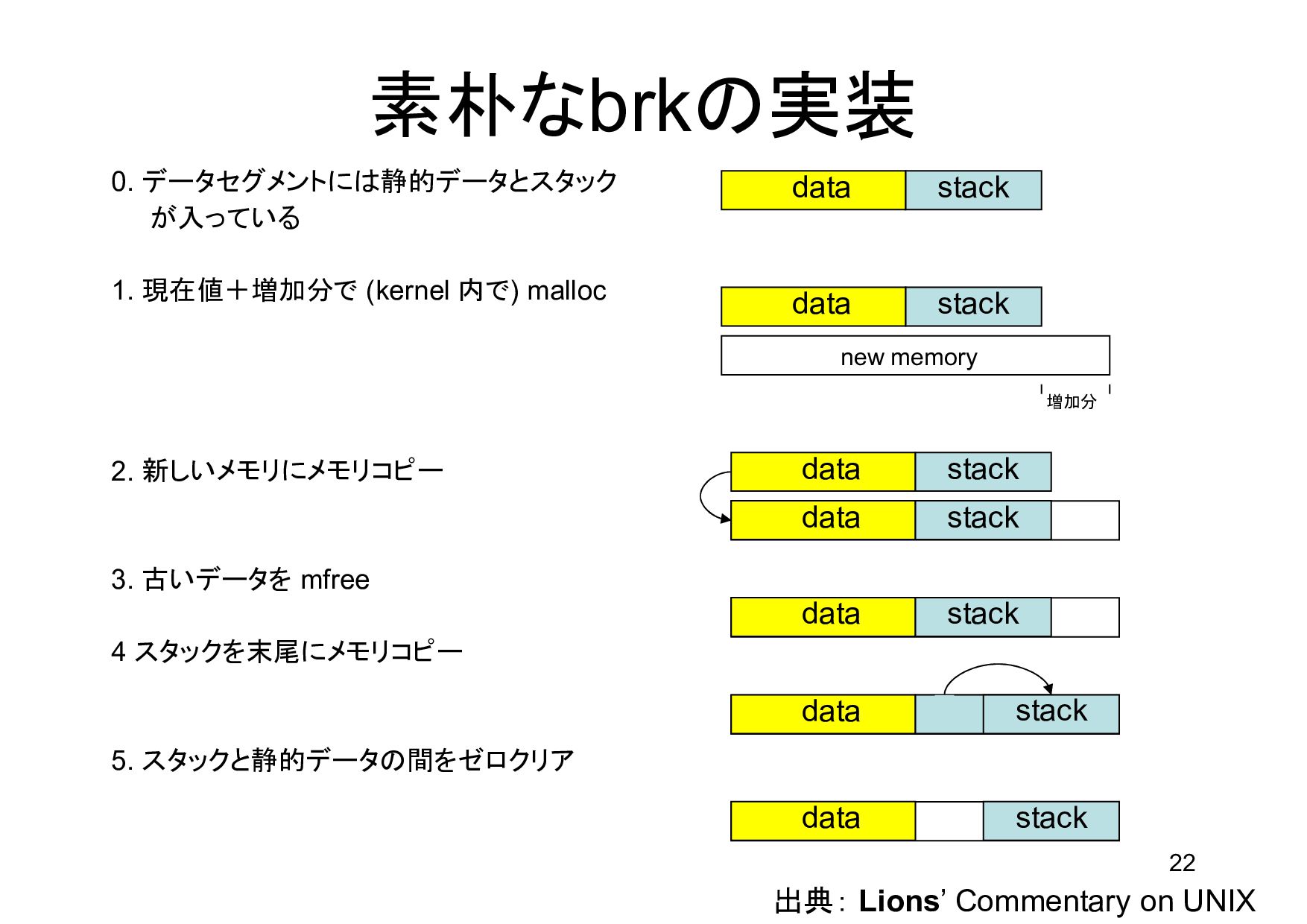
2. 新しいメモリにメモリコピー 3. 古いデータを mfree 4 スタックを末尾にメモリコピー 5. スタックと静的データの間をゼロクリア data stack data stack data stack new memory data stack data stack data data stack stack 出典: Lions’ Commentary on UNIX 増加分
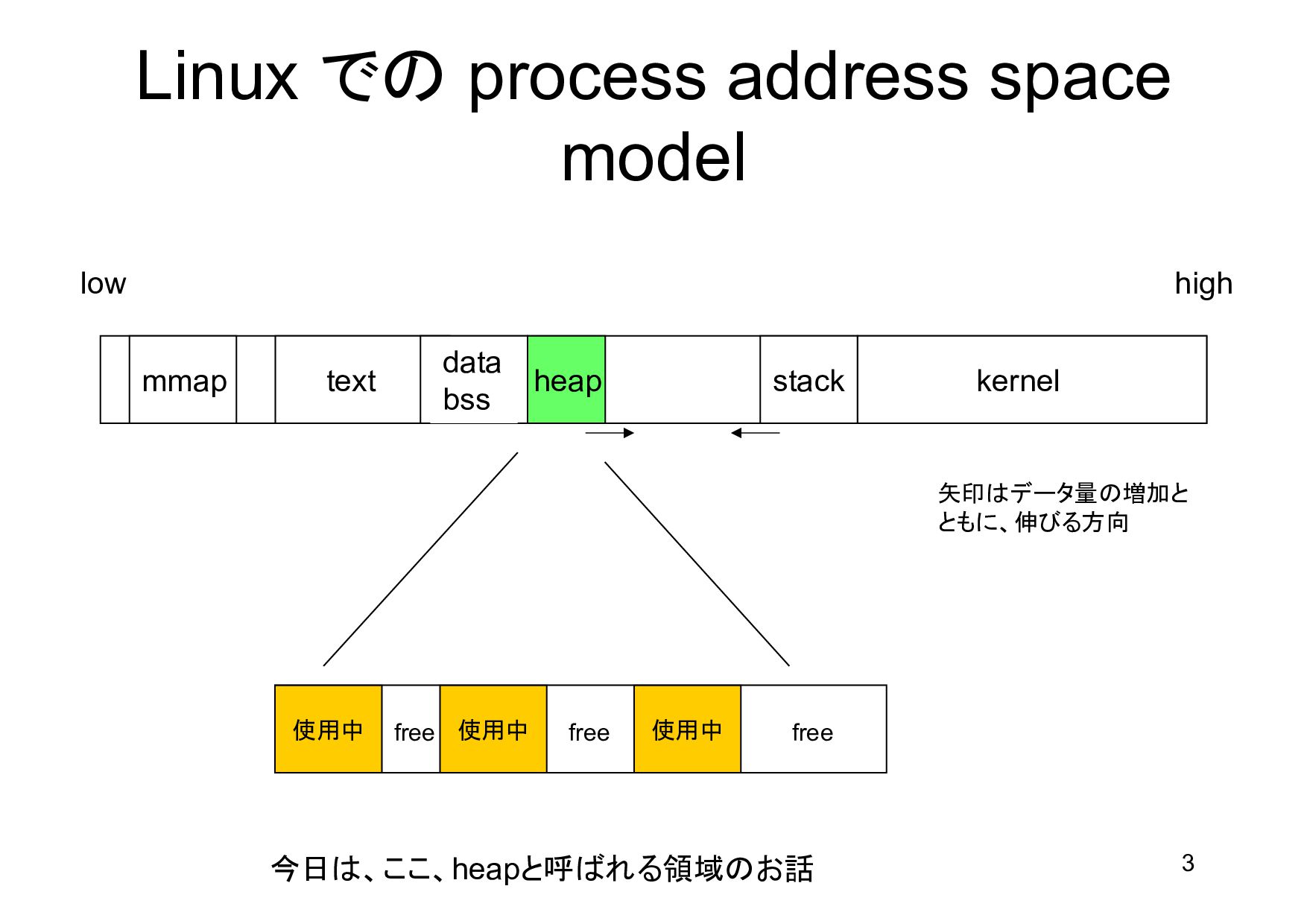
{kind=link}
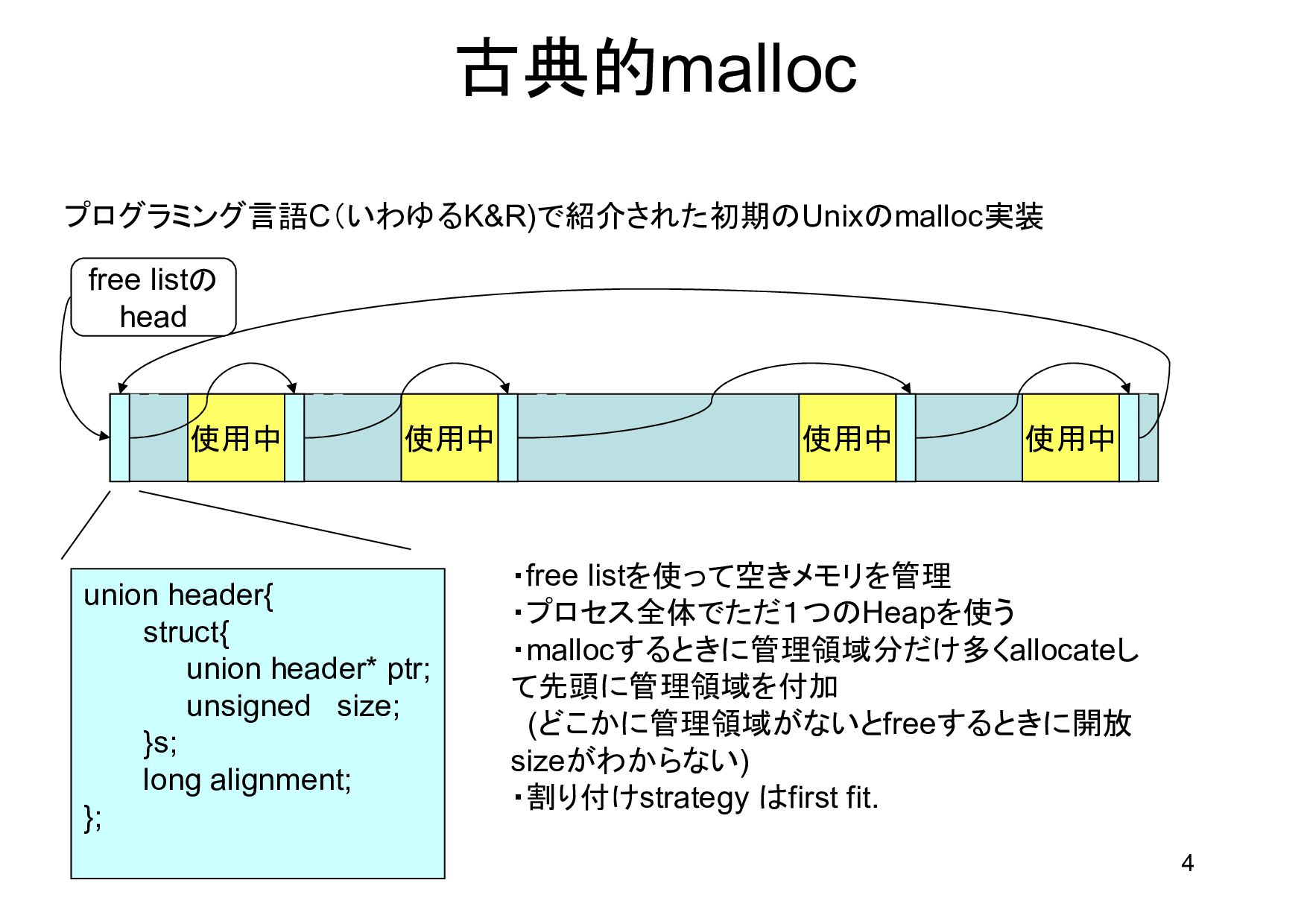
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
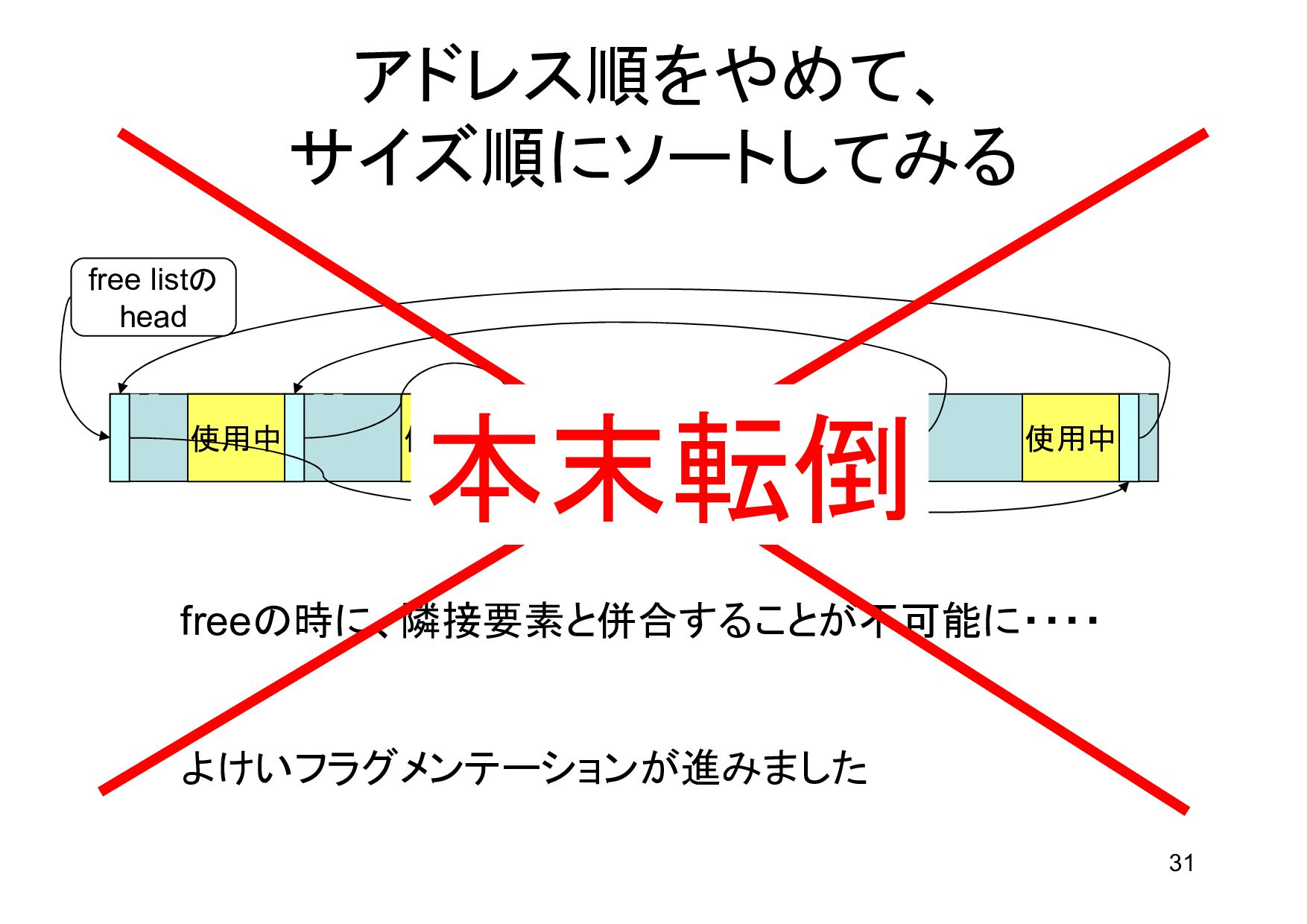{kind=link}
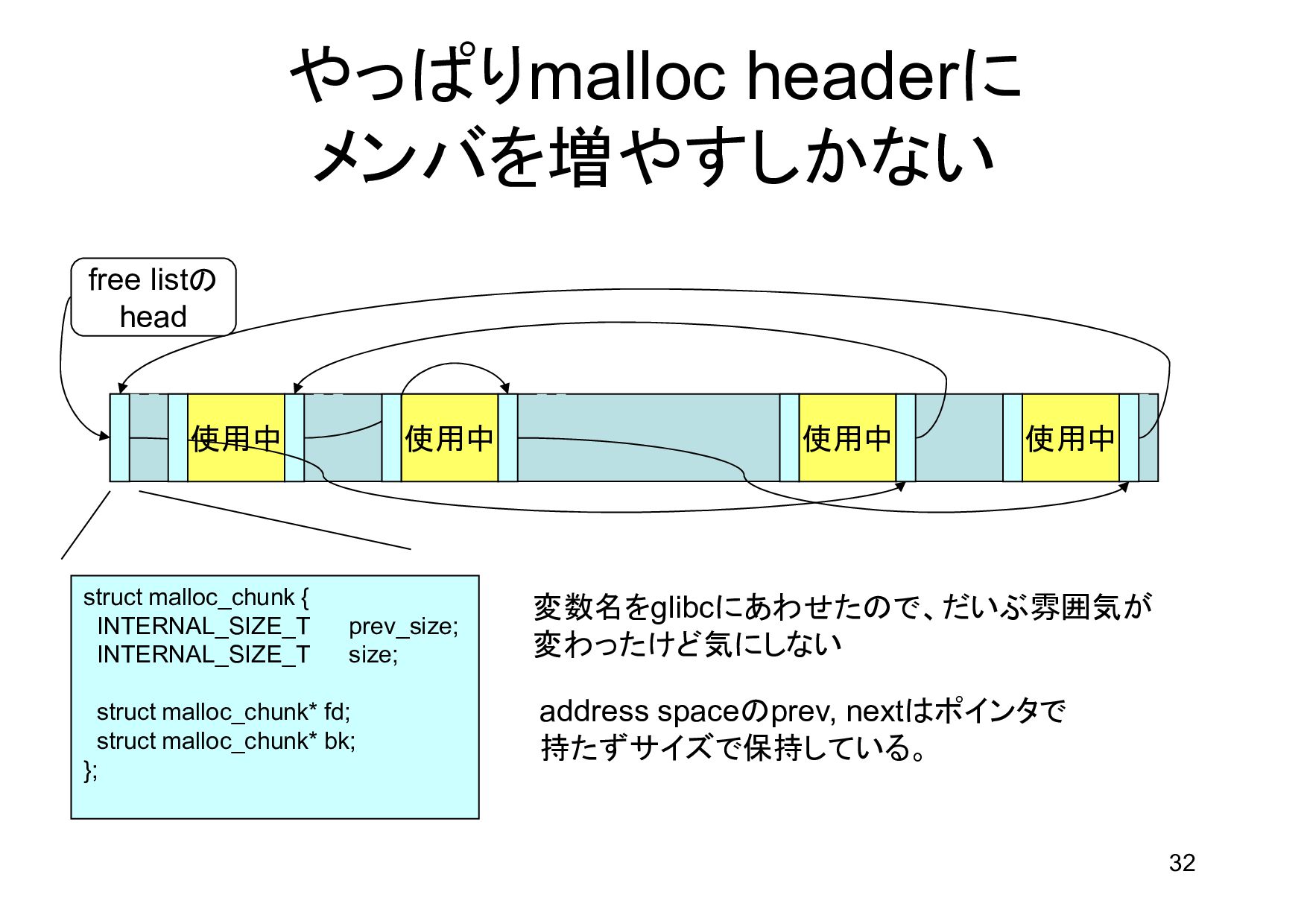{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
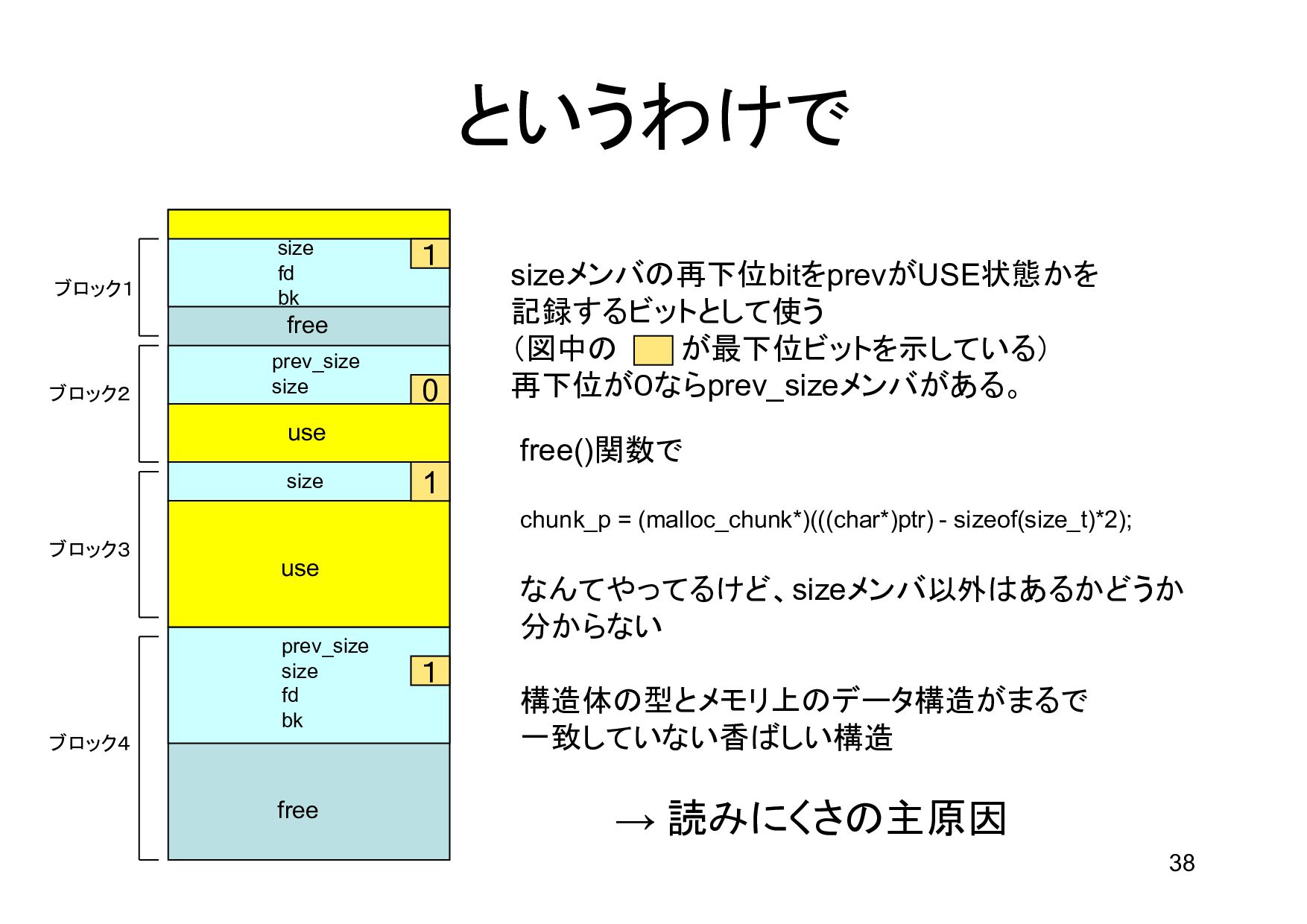{kind=link}
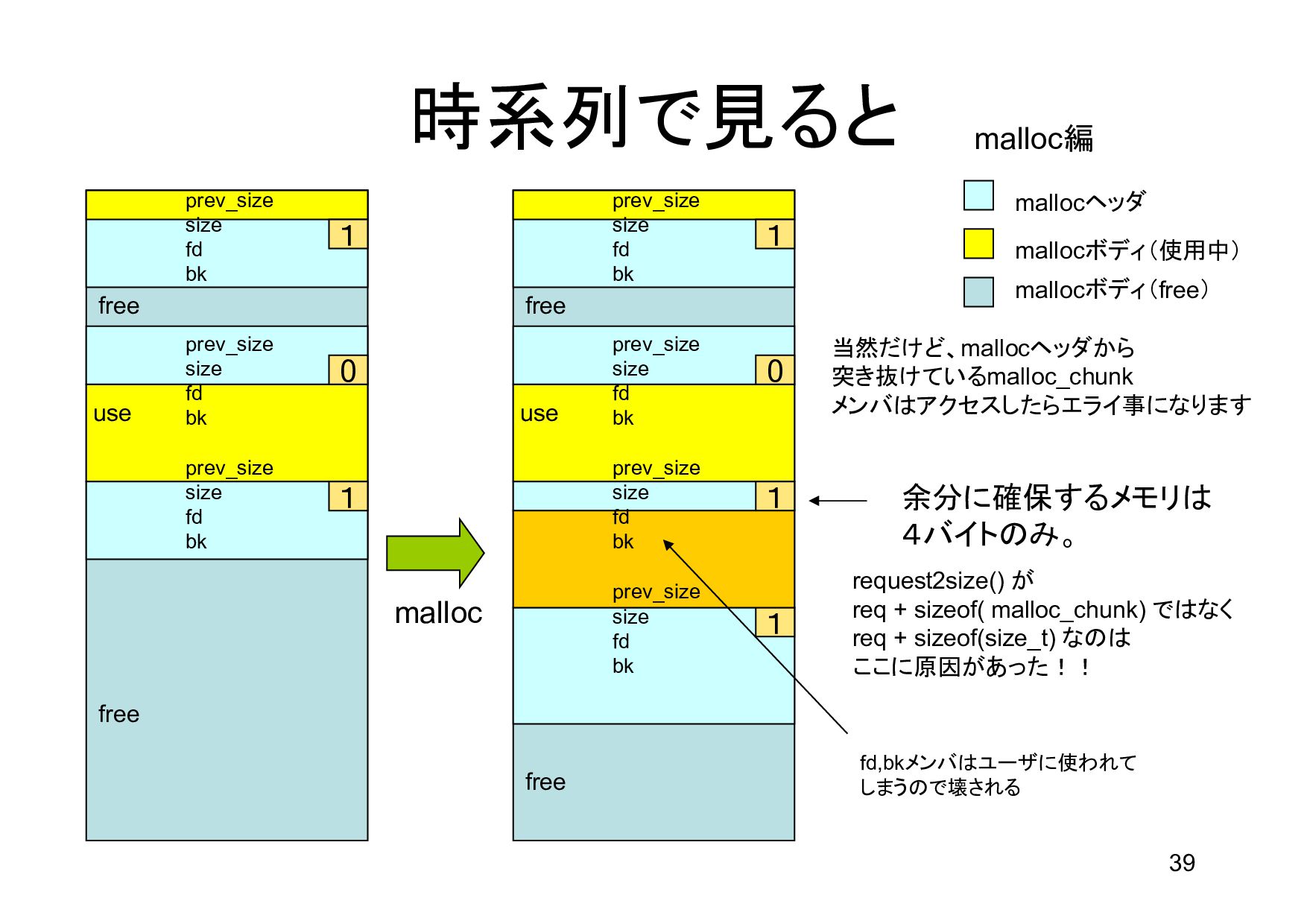{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![57 バッファの遅延合体 その2 • gligc mallocでは最低確保サイズが32なので bins[0]とbins[1]は使ってない • bins[1] をこの遅延されてるblockをつなげるリストの](https://files.speakerdeck.com/presentations/17b2822ba0564e6da002ff9fe14c59af/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
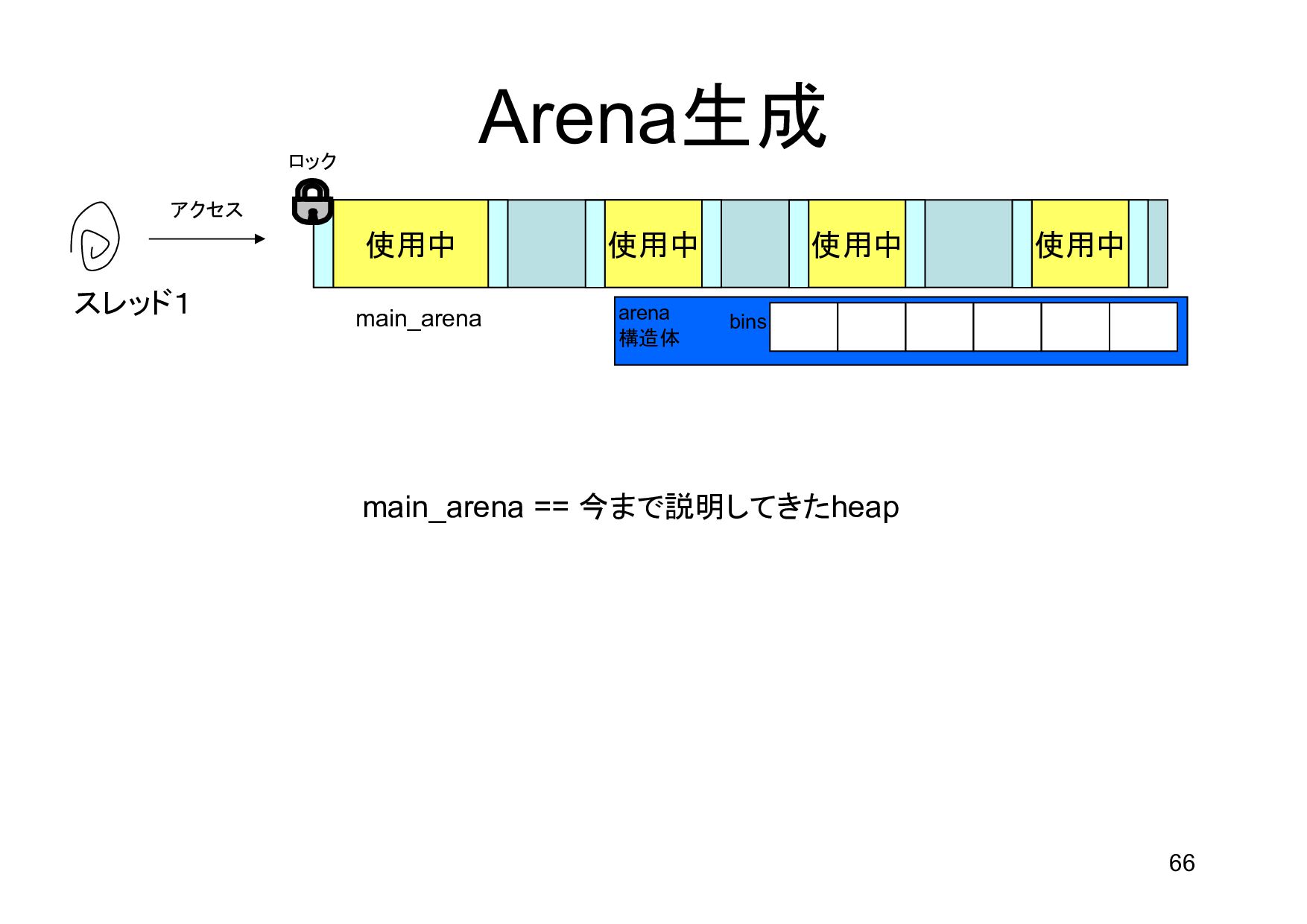{kind=link}
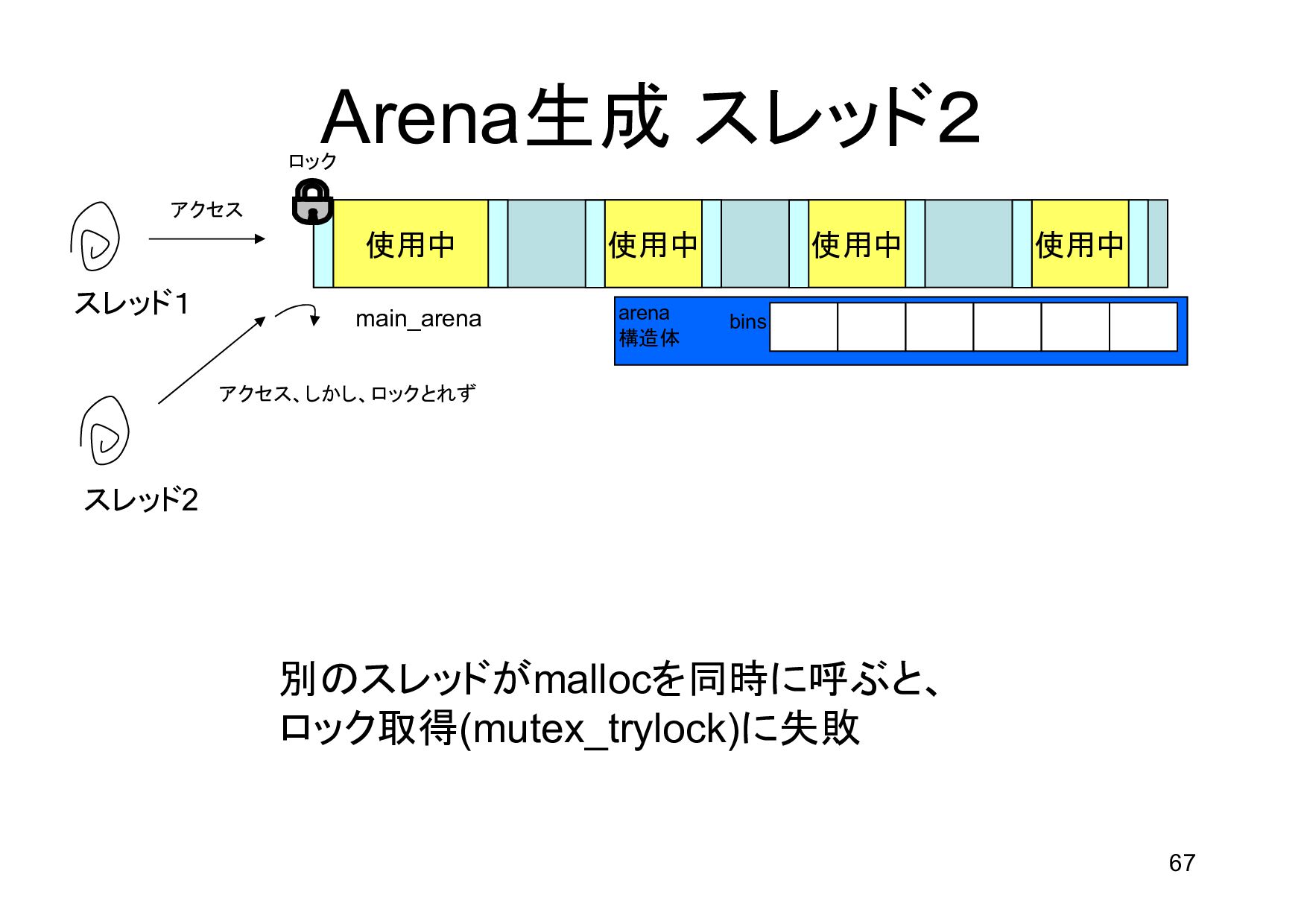{kind=link}
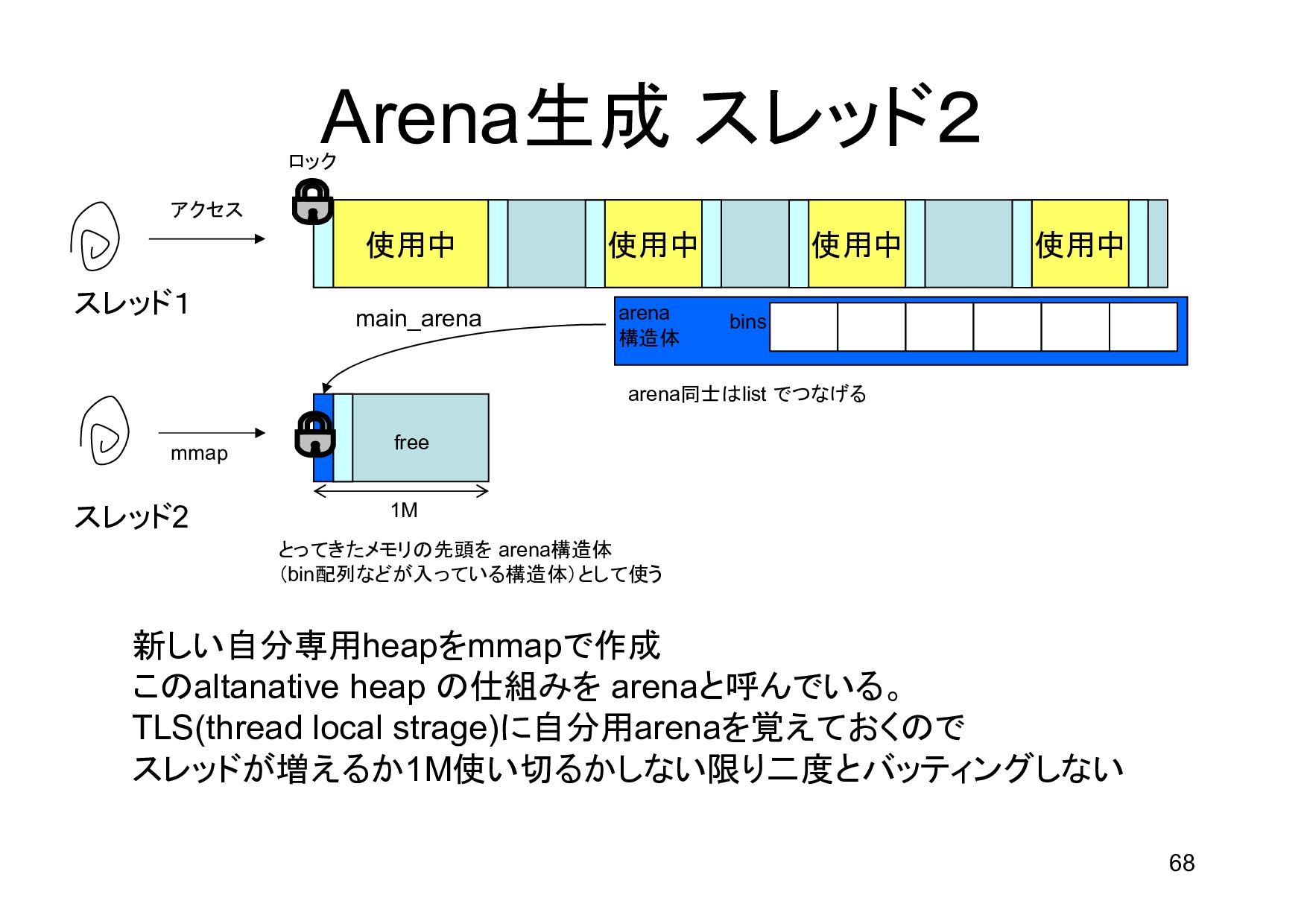{kind=link}
{kind=link}
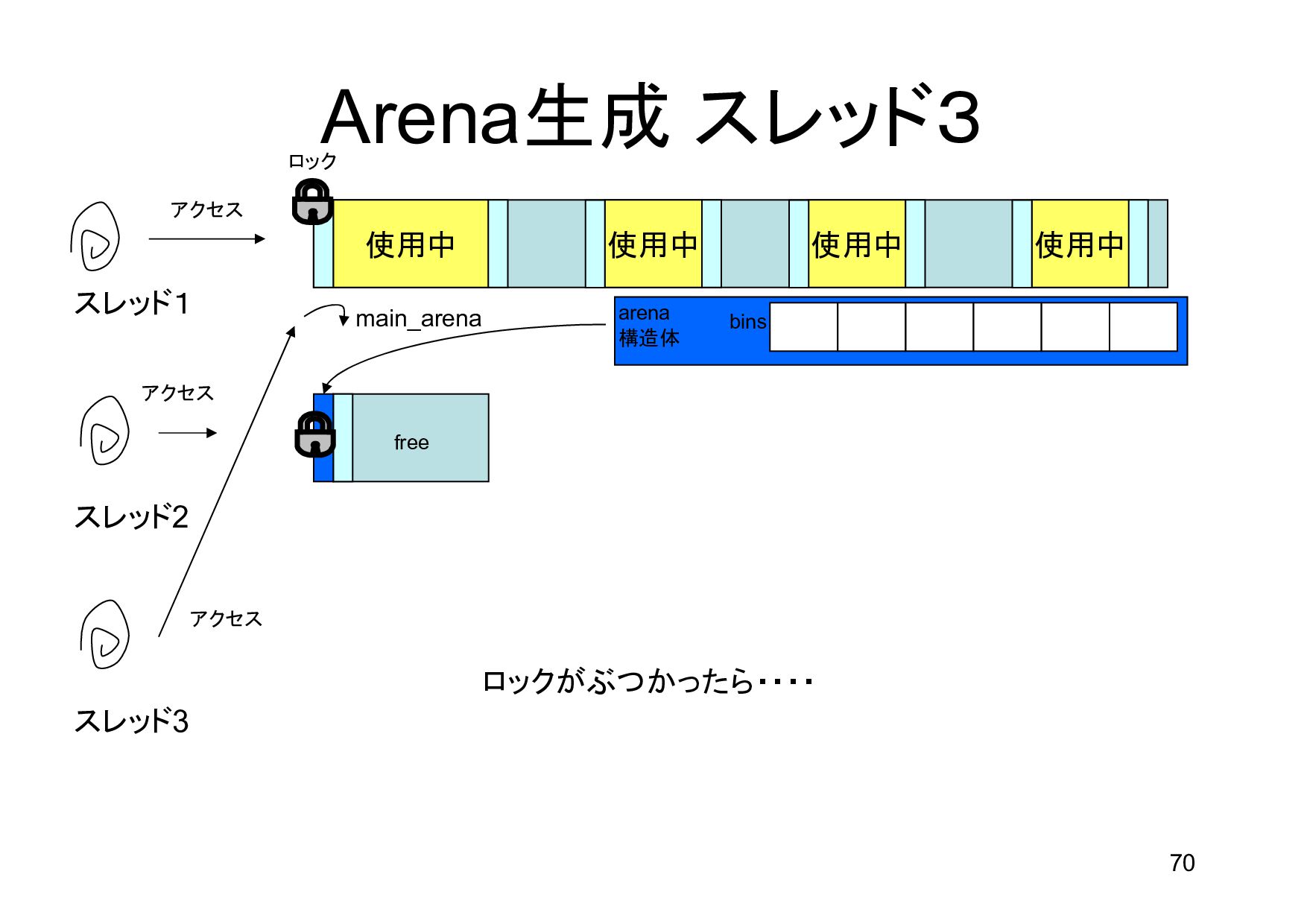{kind=link}
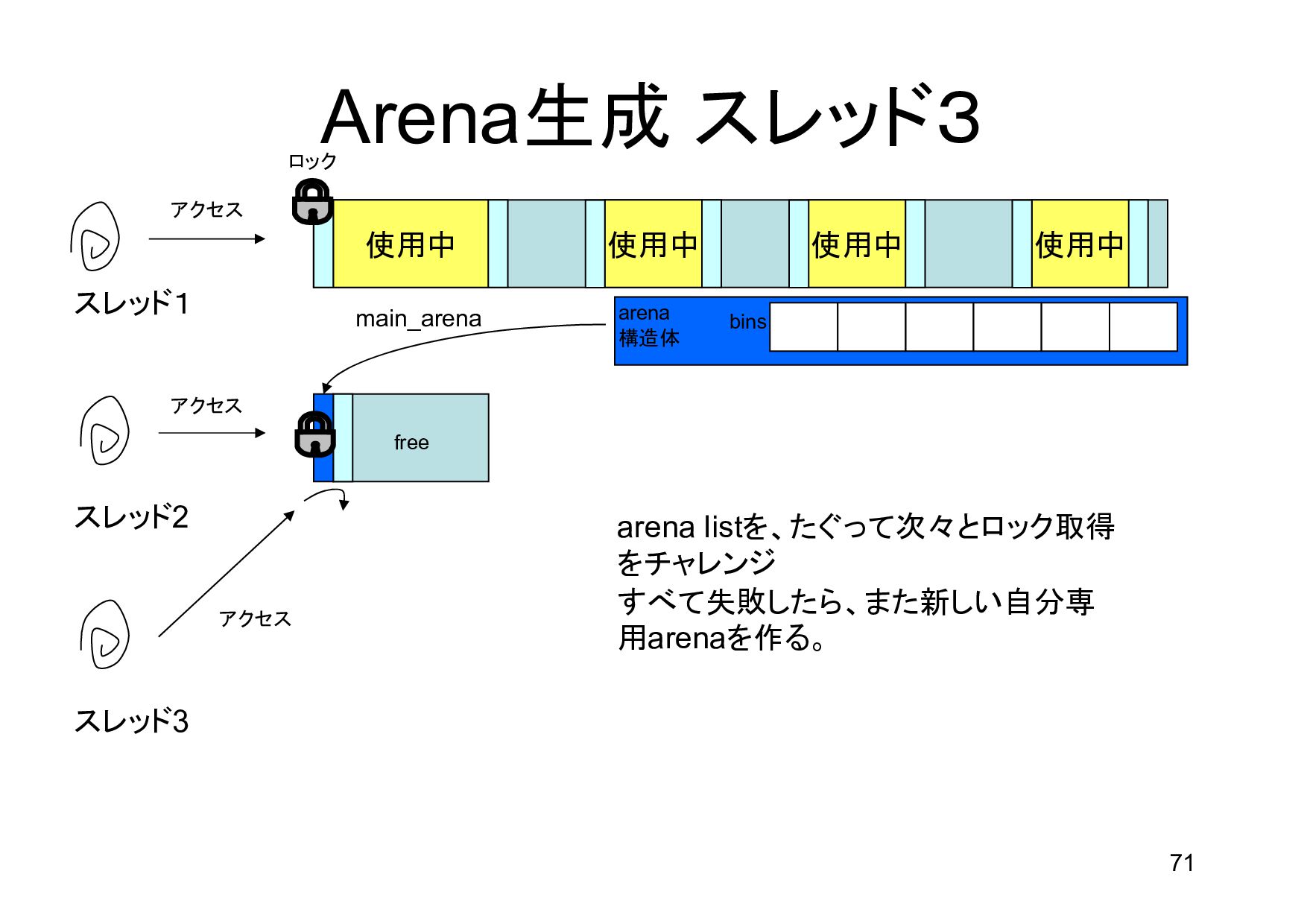{kind=link}
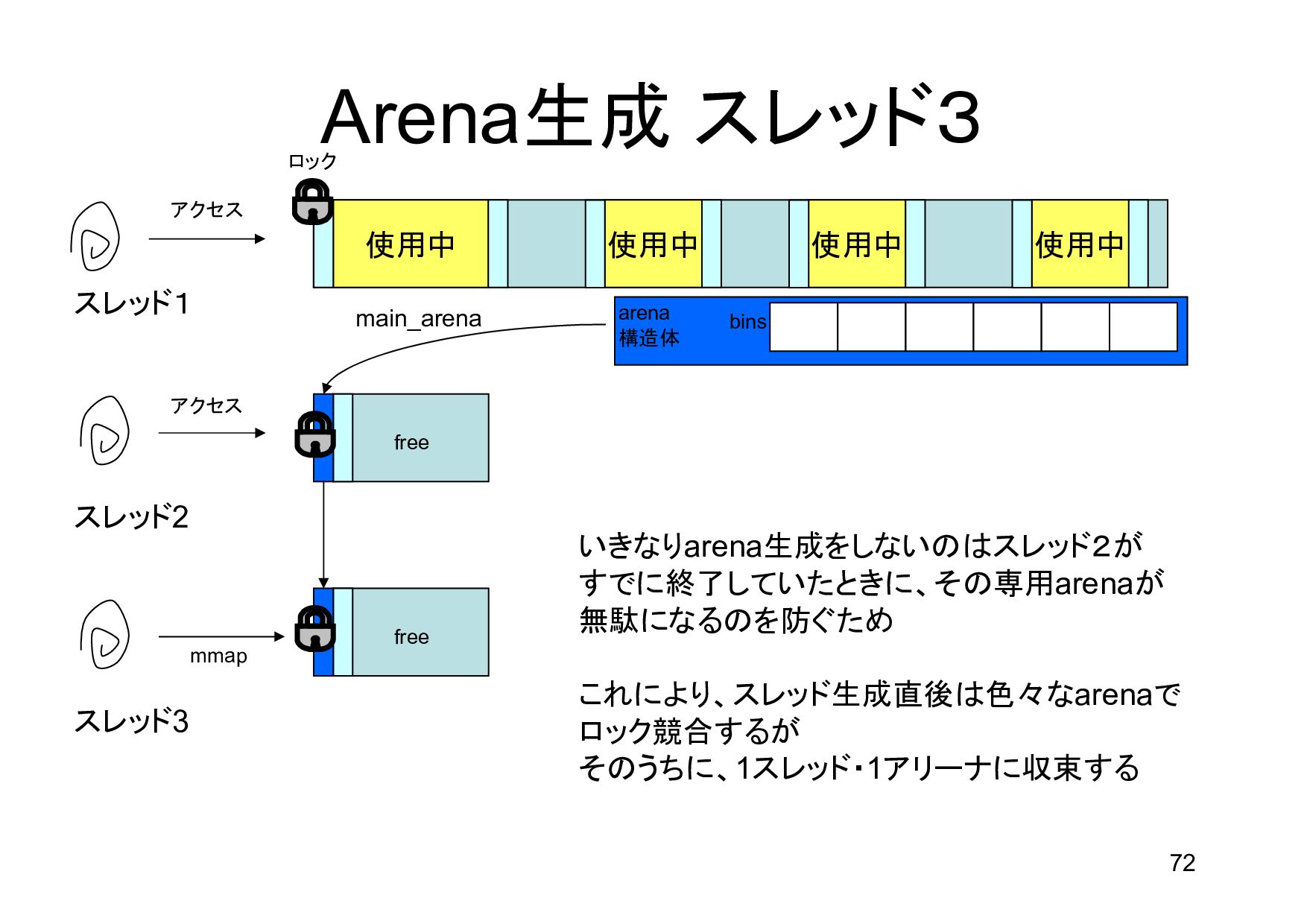{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
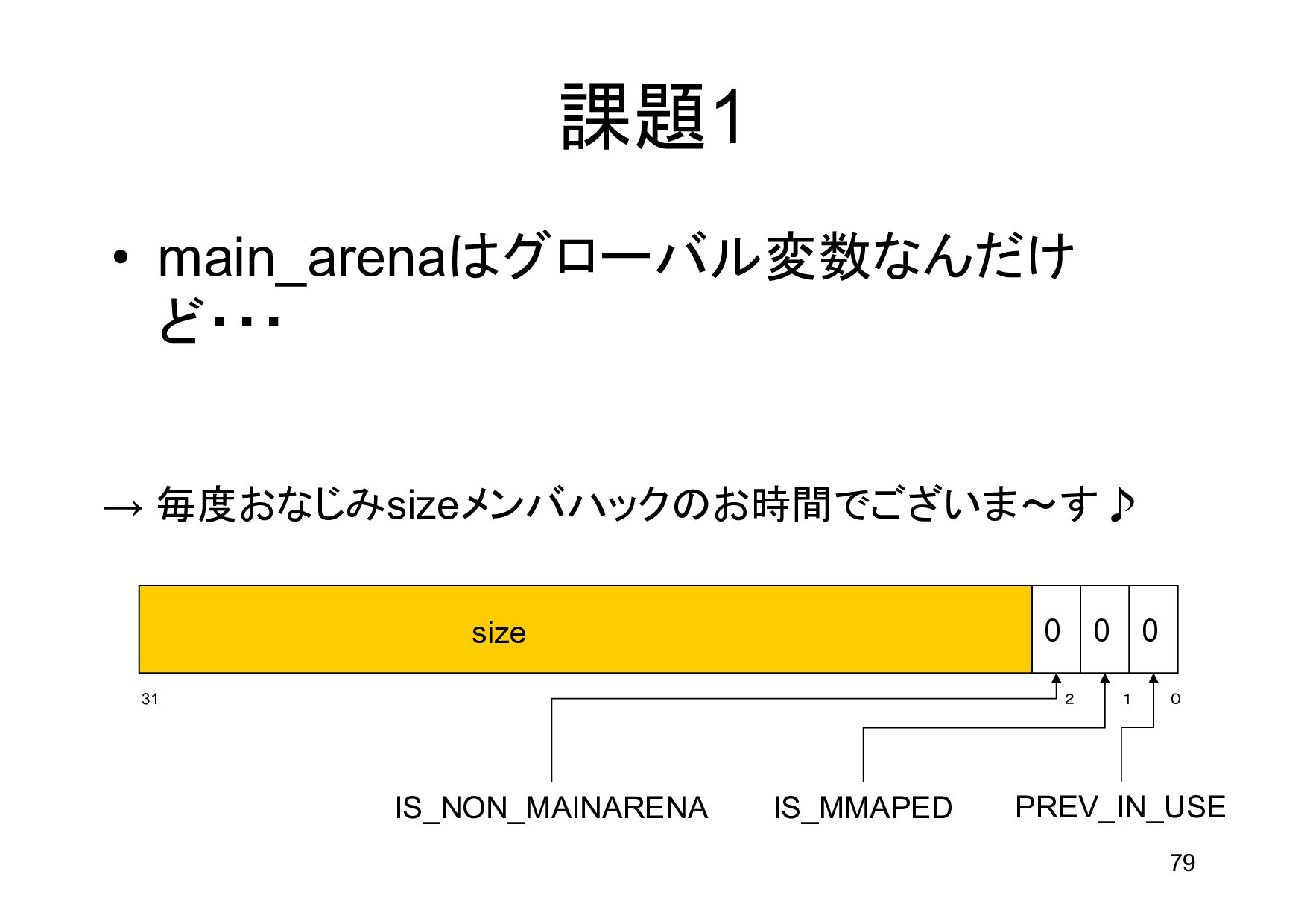
{kind=link}
{kind=link}
{kind=link}
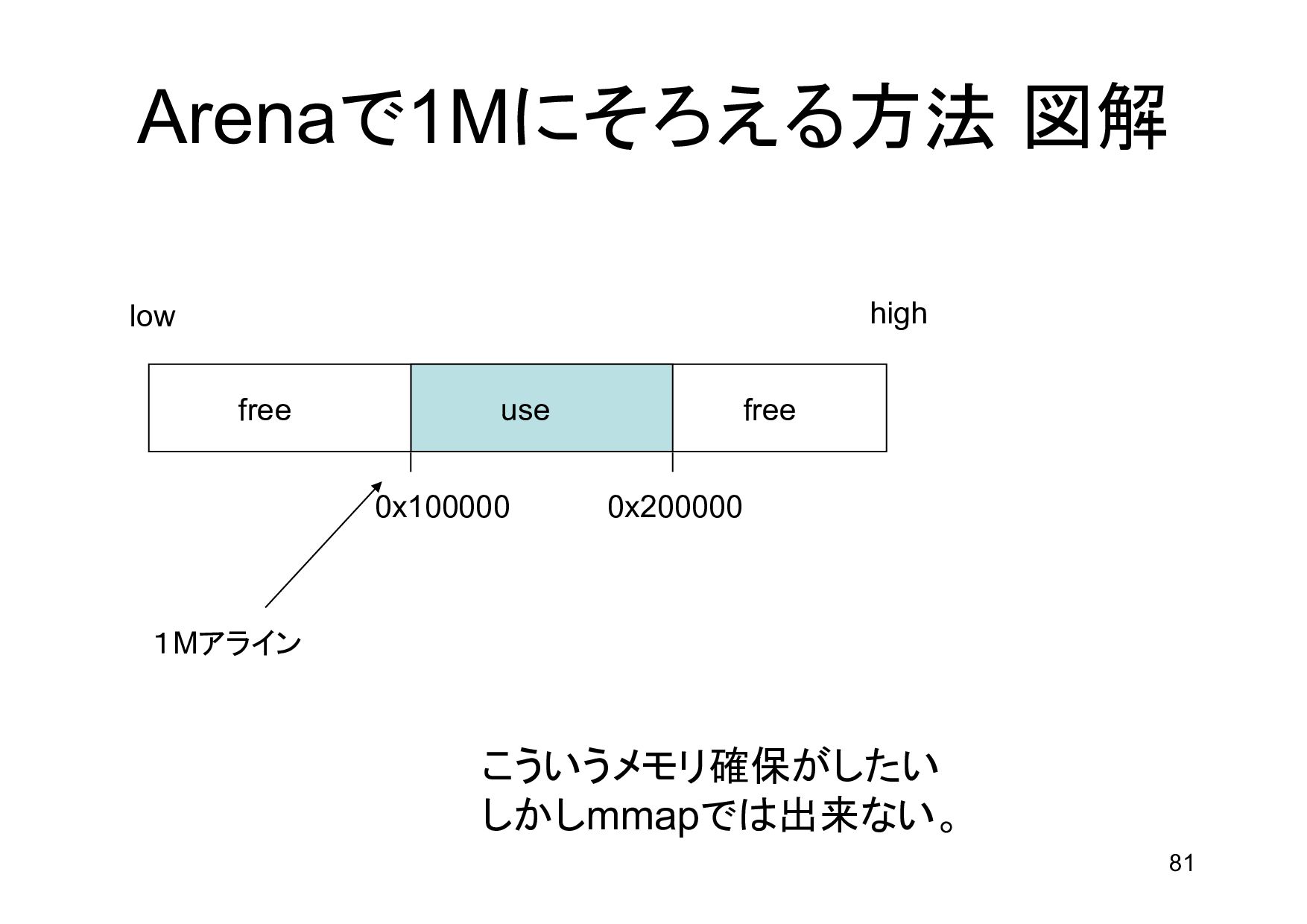{kind=link}
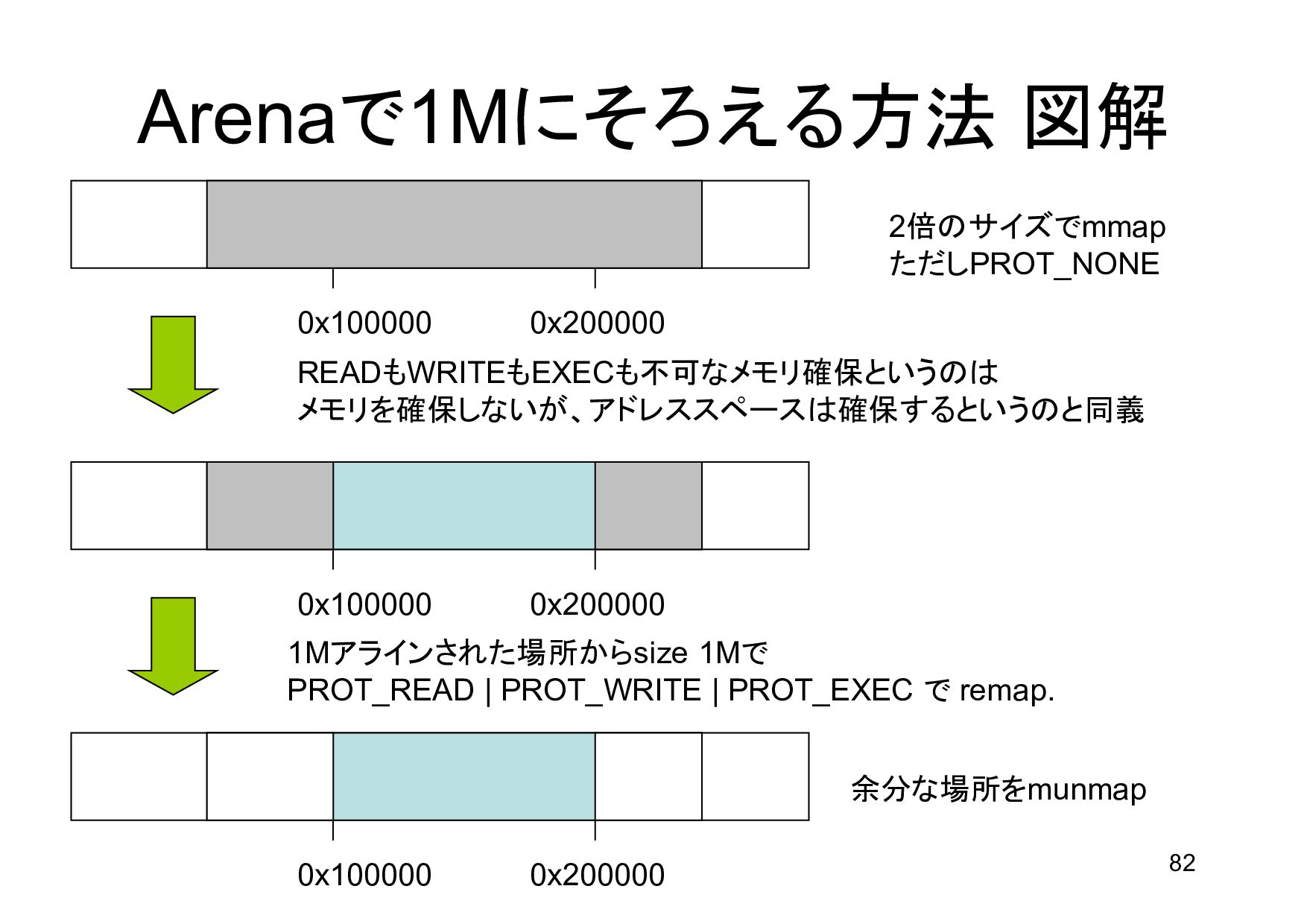{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}