川中 真耶(株式会社ナレッジワーク / CTO)
東京大学大学院情報理工学系研究科コンピュータ科学専攻修士課程修了。日本IBM東京基礎研究所研究員やGoogleソフトウェアエンジニアなどを経て株式会社ナレッジワークを共同創業。CTO of the year 2022 ファイナリスト。「王様達のヴァイキング」(週刊ビッグコミックスピリッツ)技術監修。
<概要>
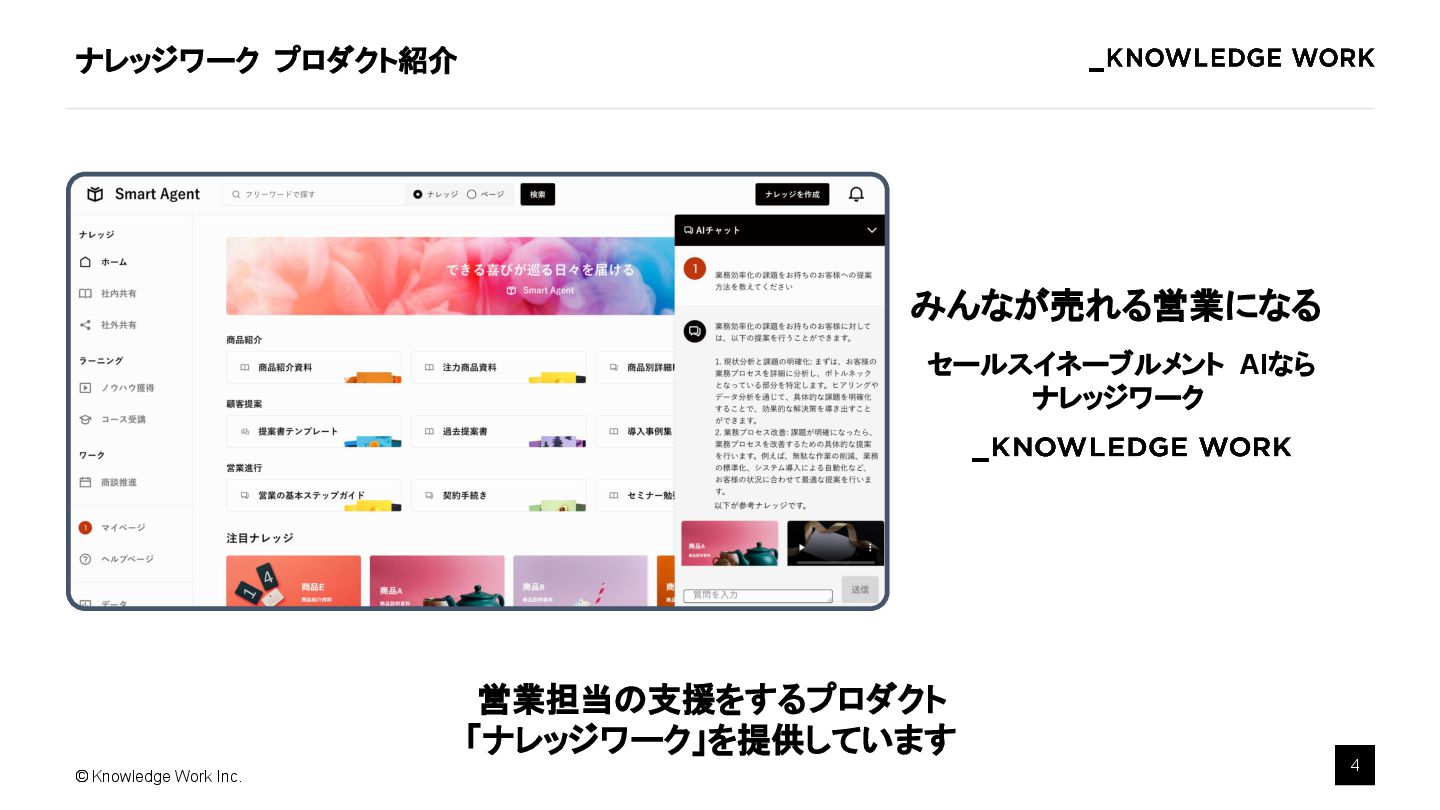
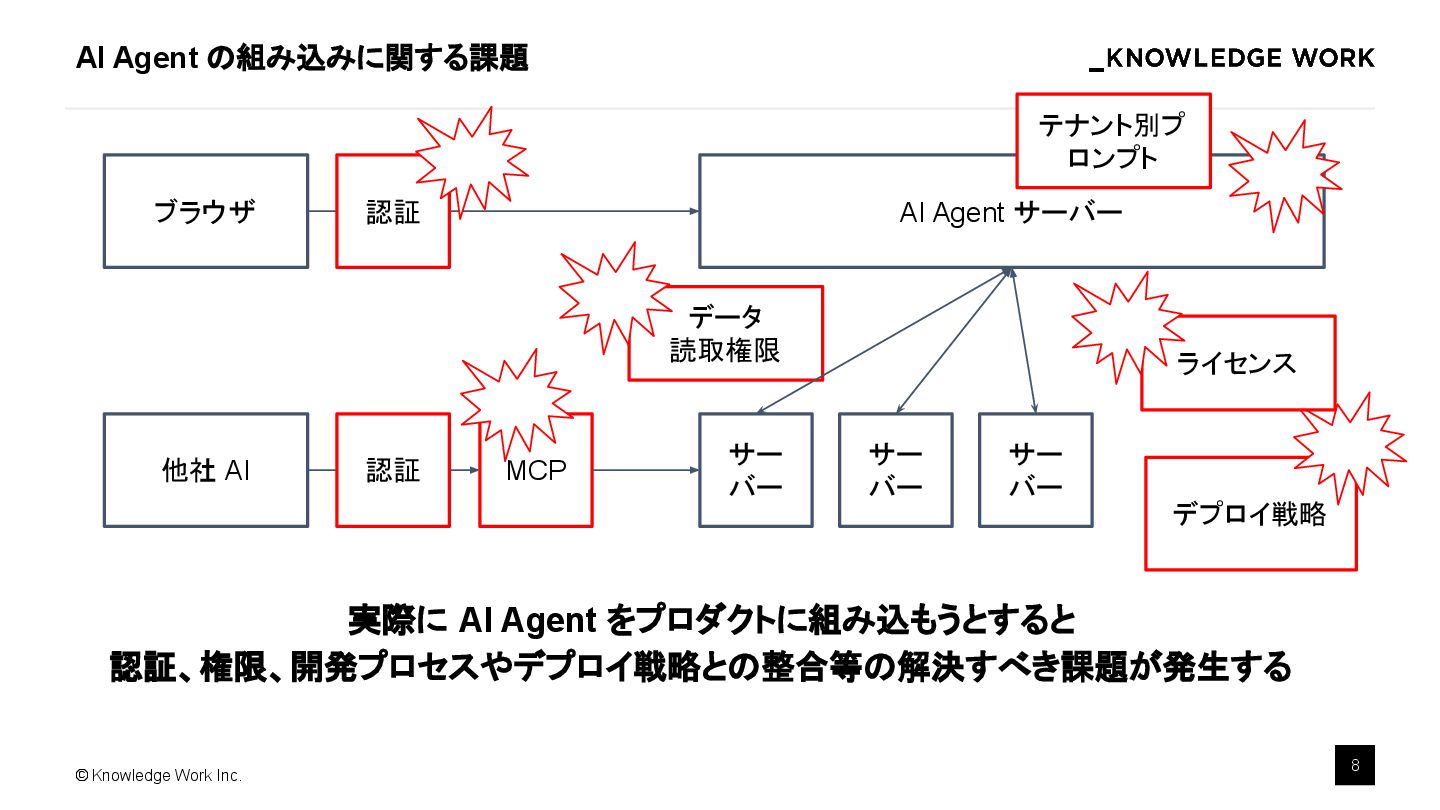
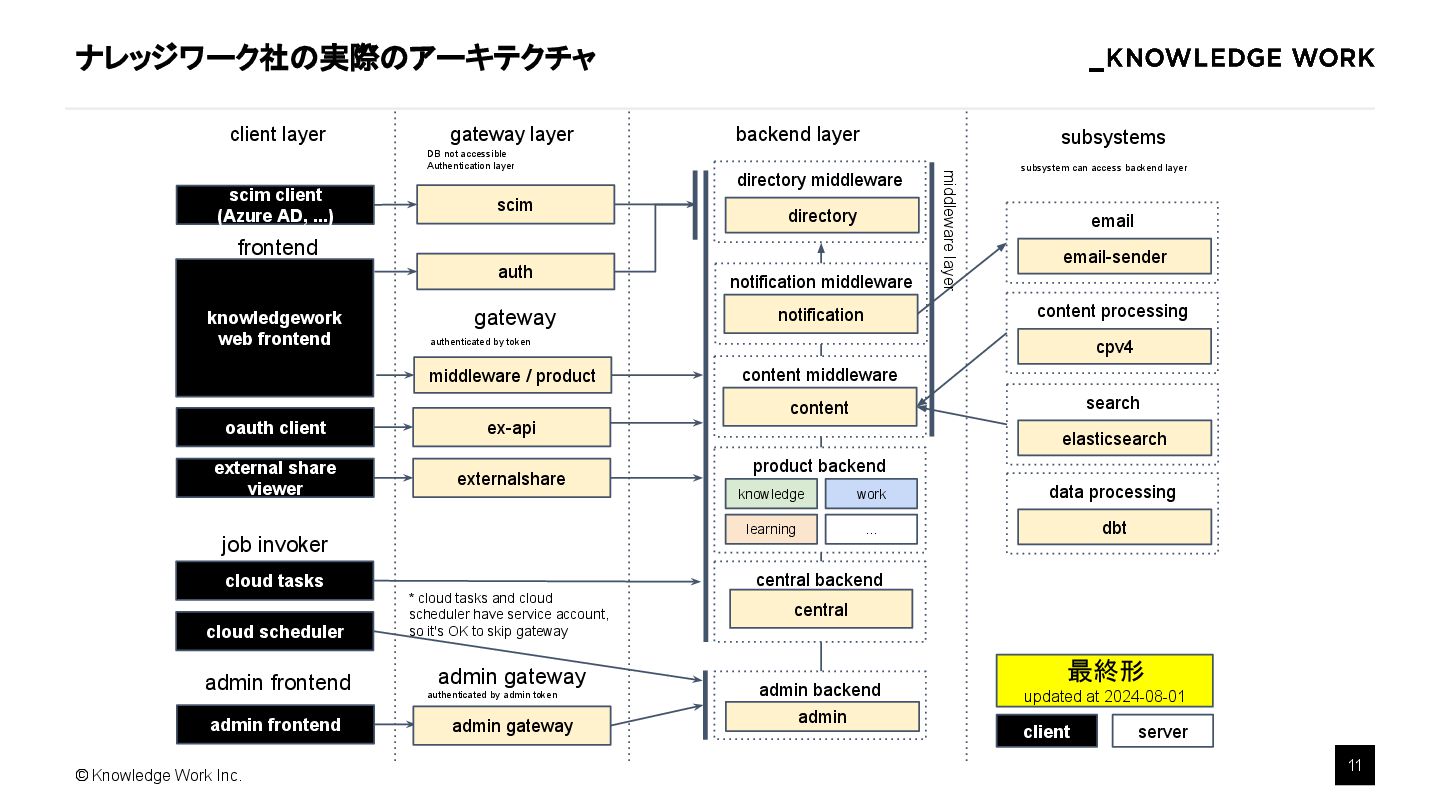
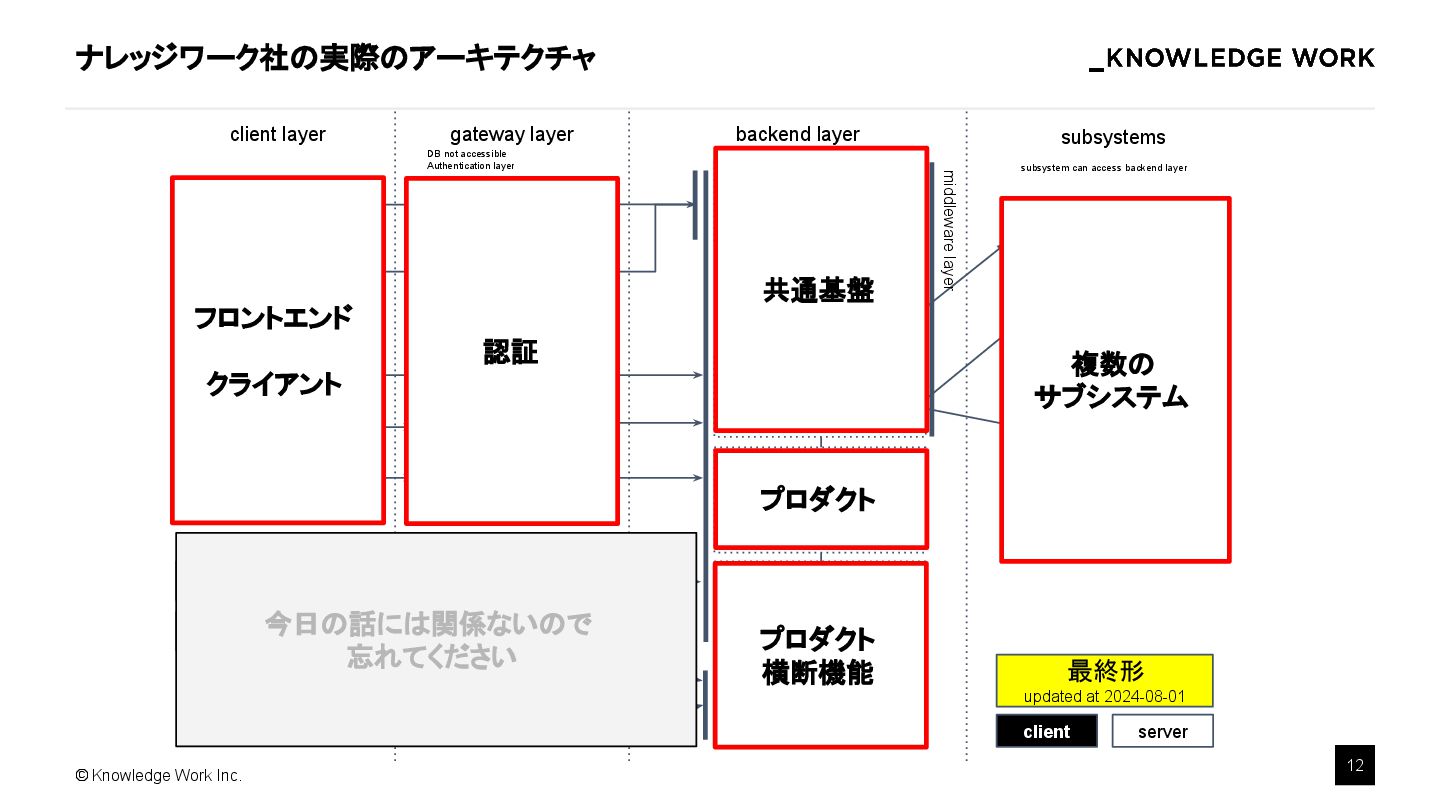
AI Agent を組み込んだプロダクトを開発することは一般的になってきましたが、マルチテナント SaaS への組み込み手法がまだ広く議論されているとはいえません。本講演では、マルチテナントSaaS環境において、AIエージェントを効果的に導入・運用するための実践的手法を解説します。最適なアーキテクチャ設計、テナント毎のデータ分離・セキュリティ確保、スケーラビリティ、テナント毎のカスタマイズ運用のポイントを具体例を交えて紹介します。
※AI Engineering Summit(2025/6/18開催)での登壇資料です
https://ai-engineering-summit.findy-tools.io/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
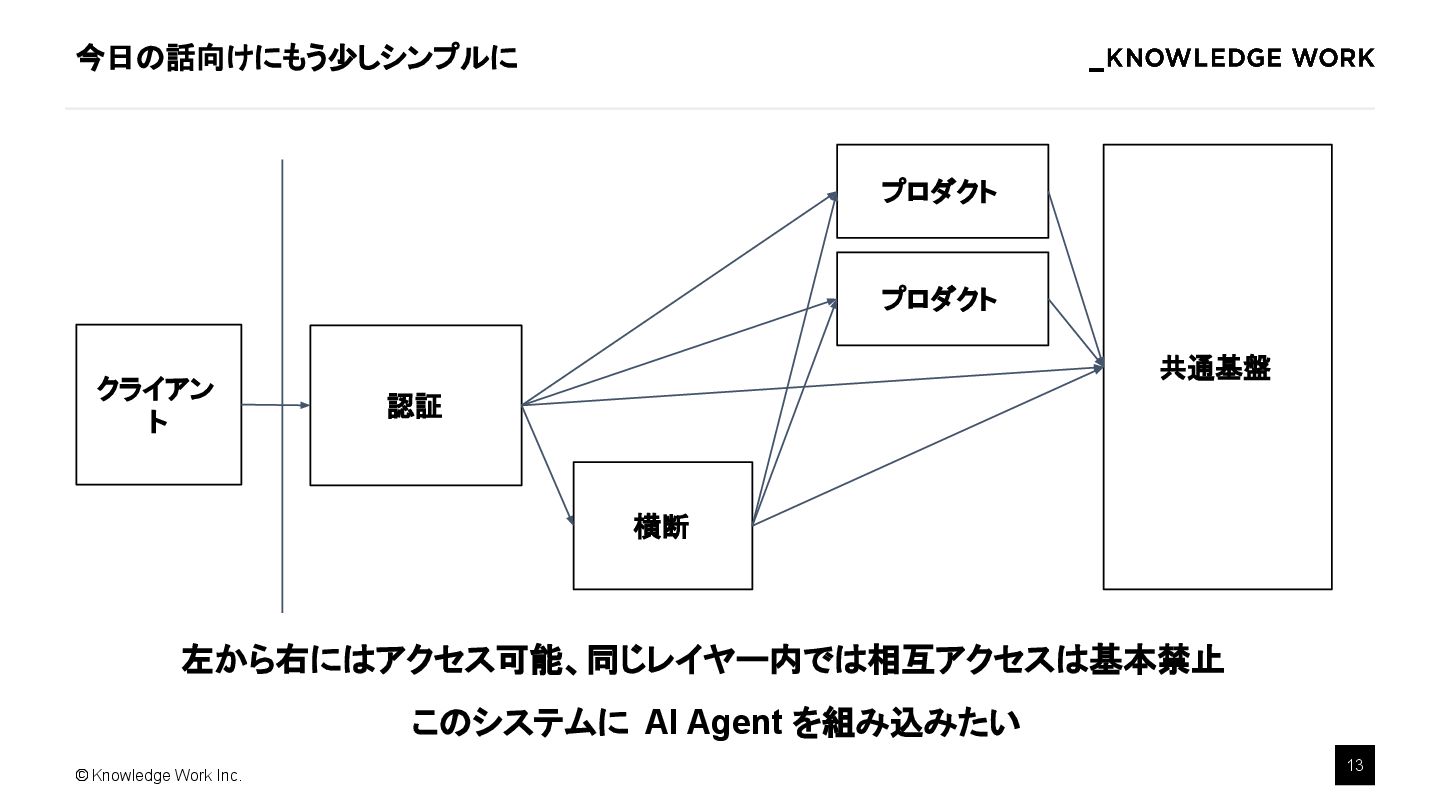{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
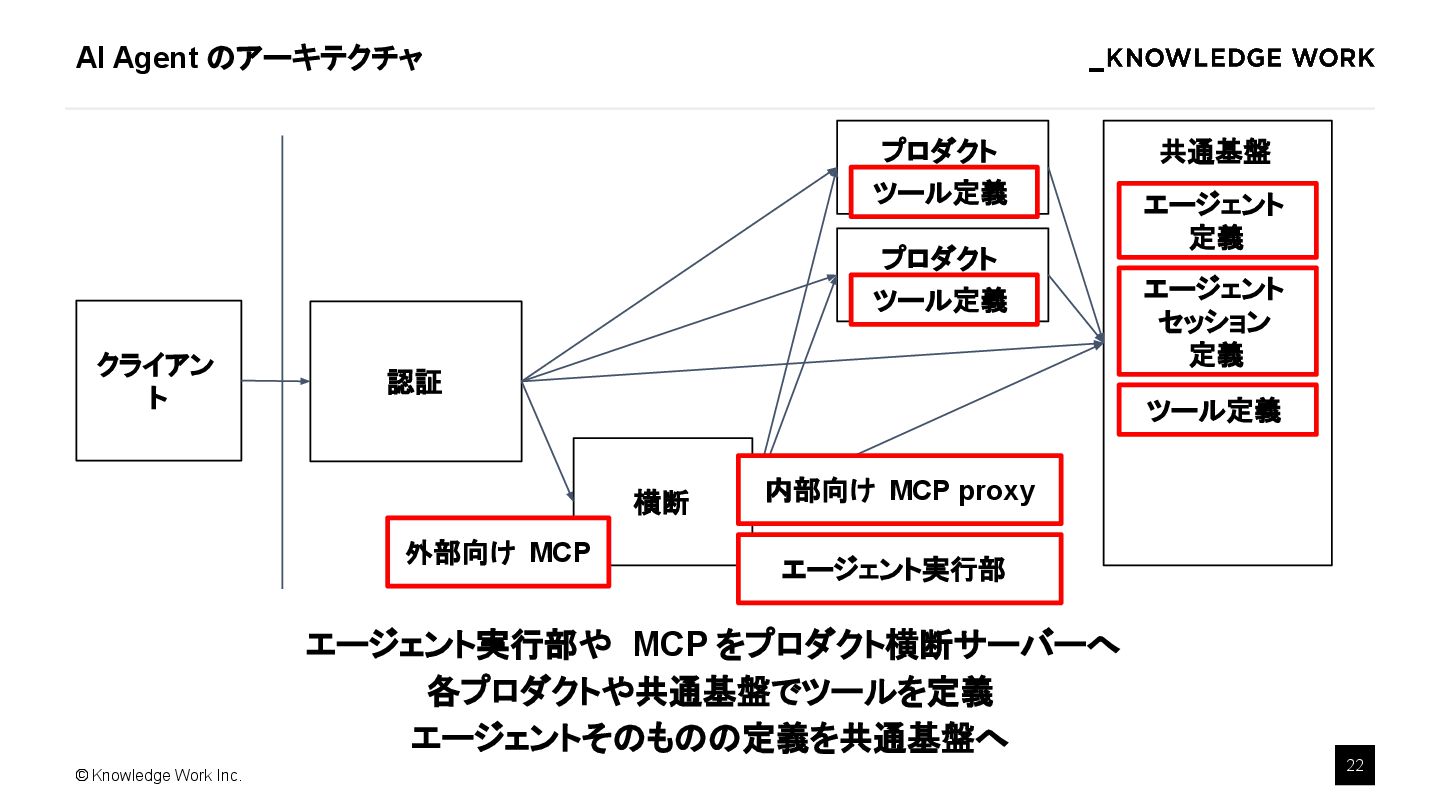{kind=link}
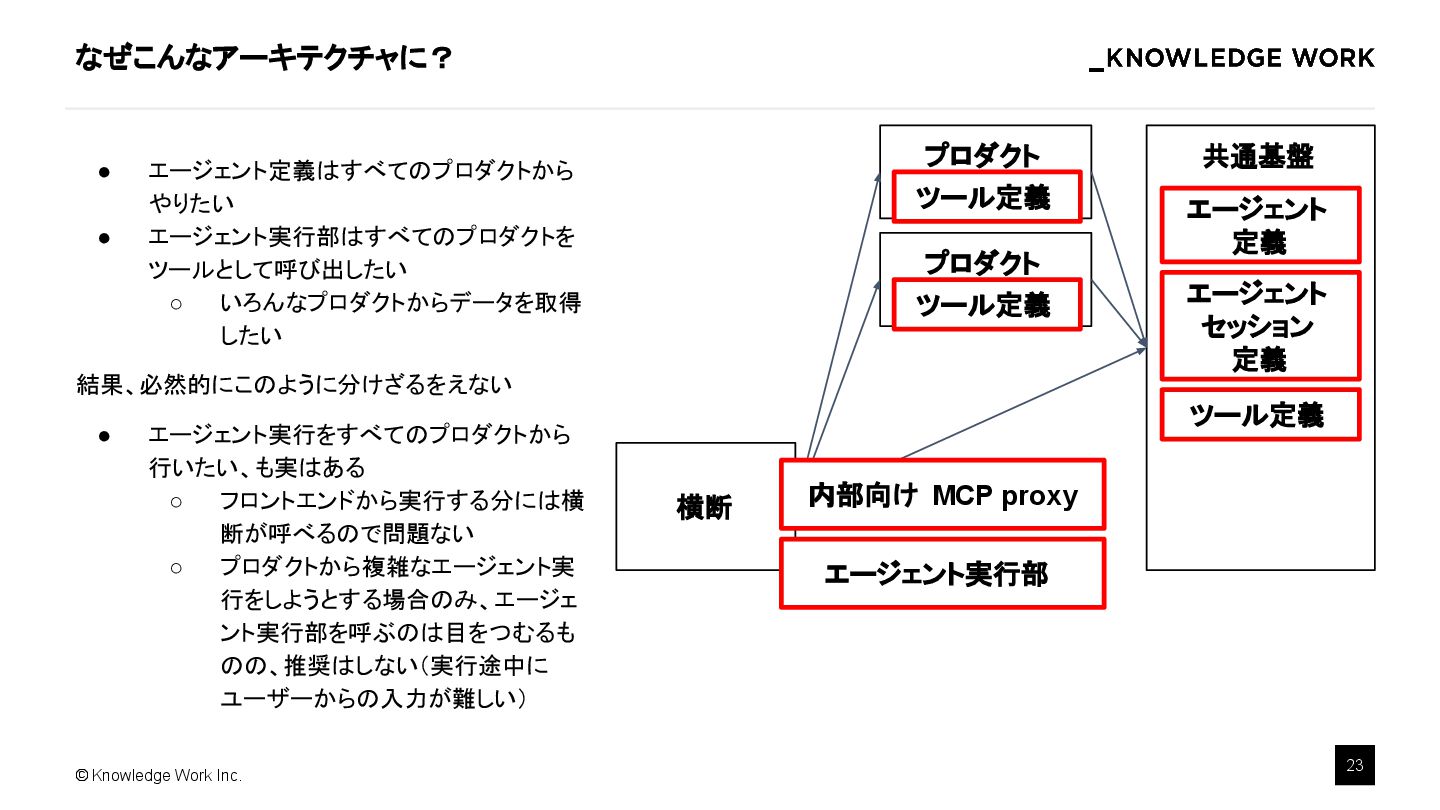{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
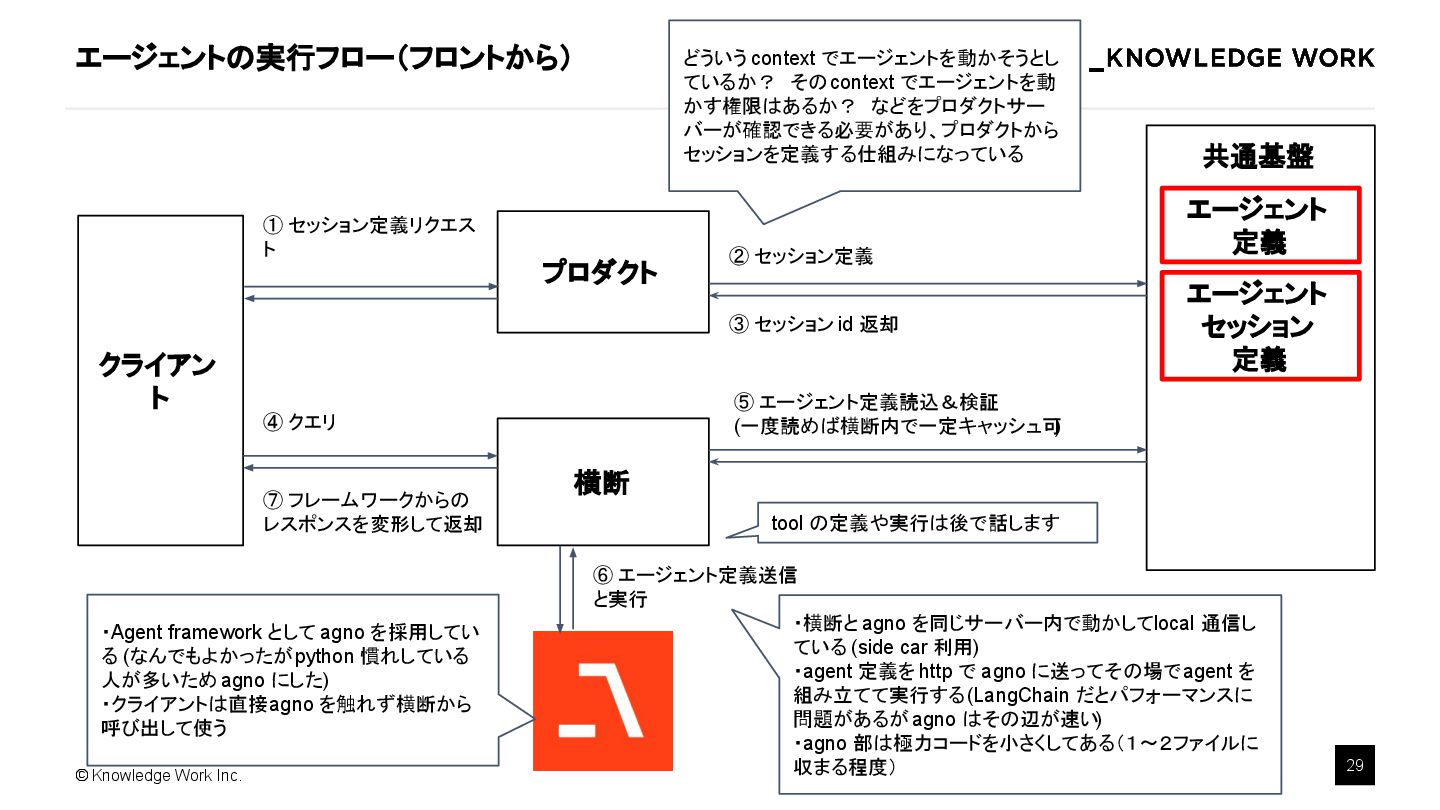{kind=link}
{kind=link}
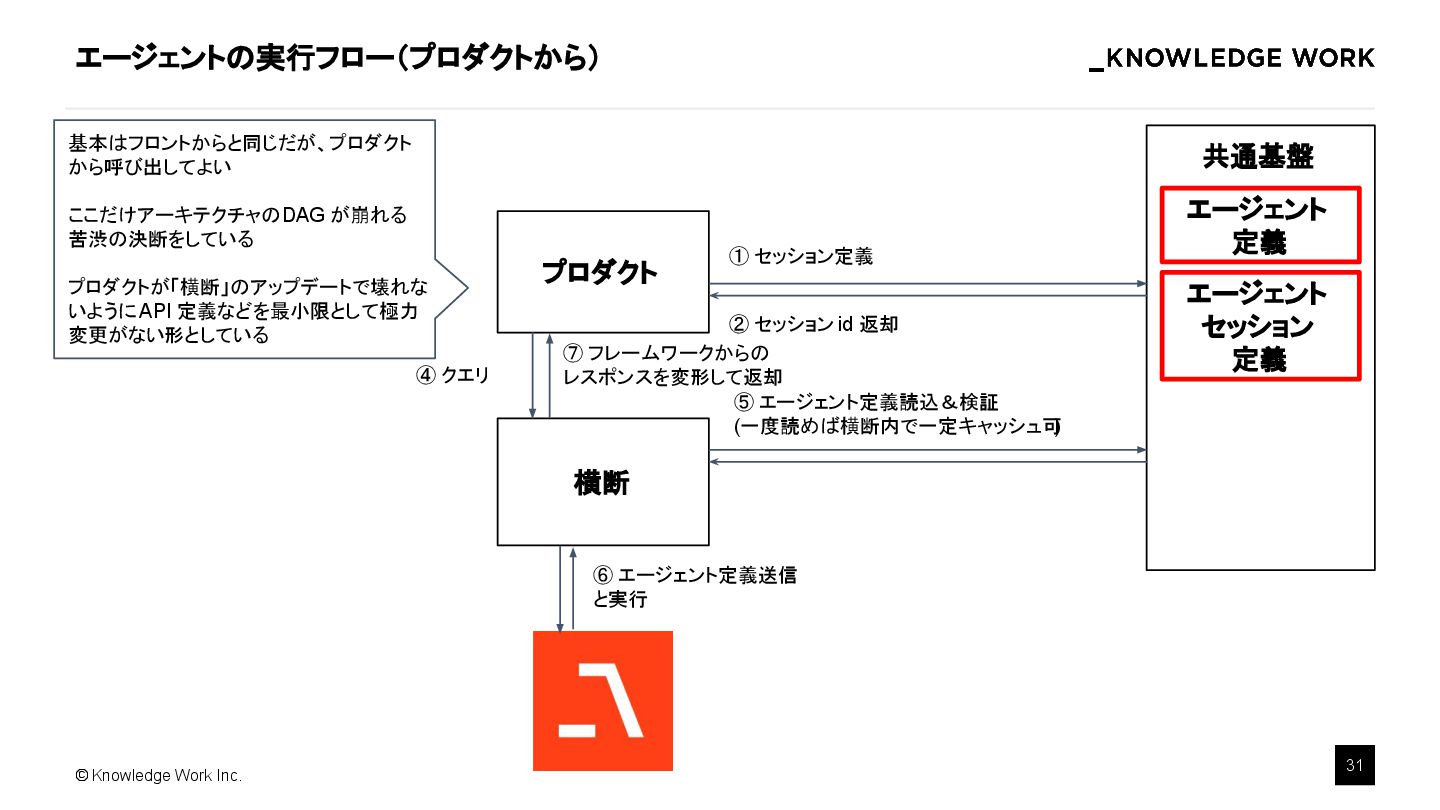{kind=link}
{kind=link}
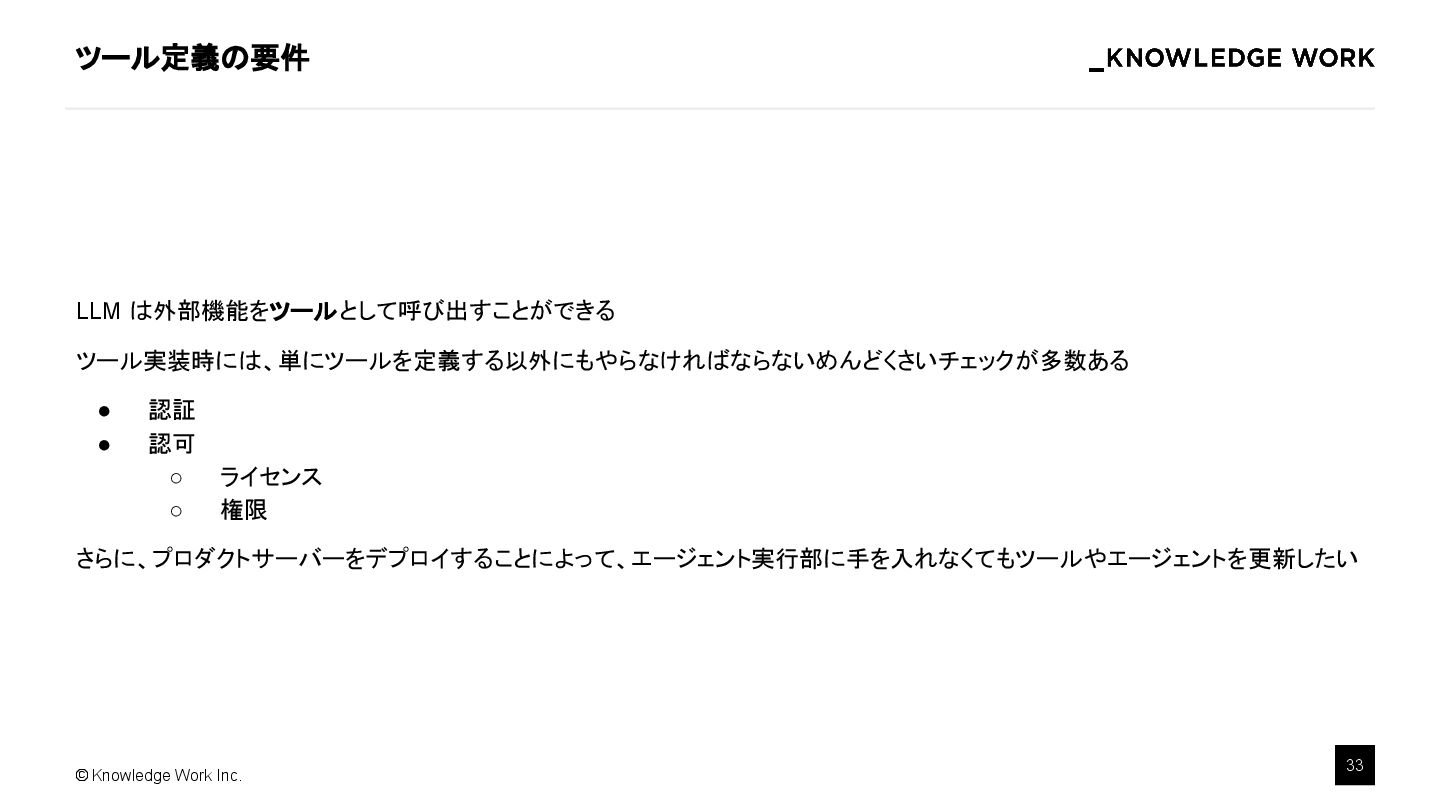{kind=link}
{kind=link}
{kind=link}
{kind=link}
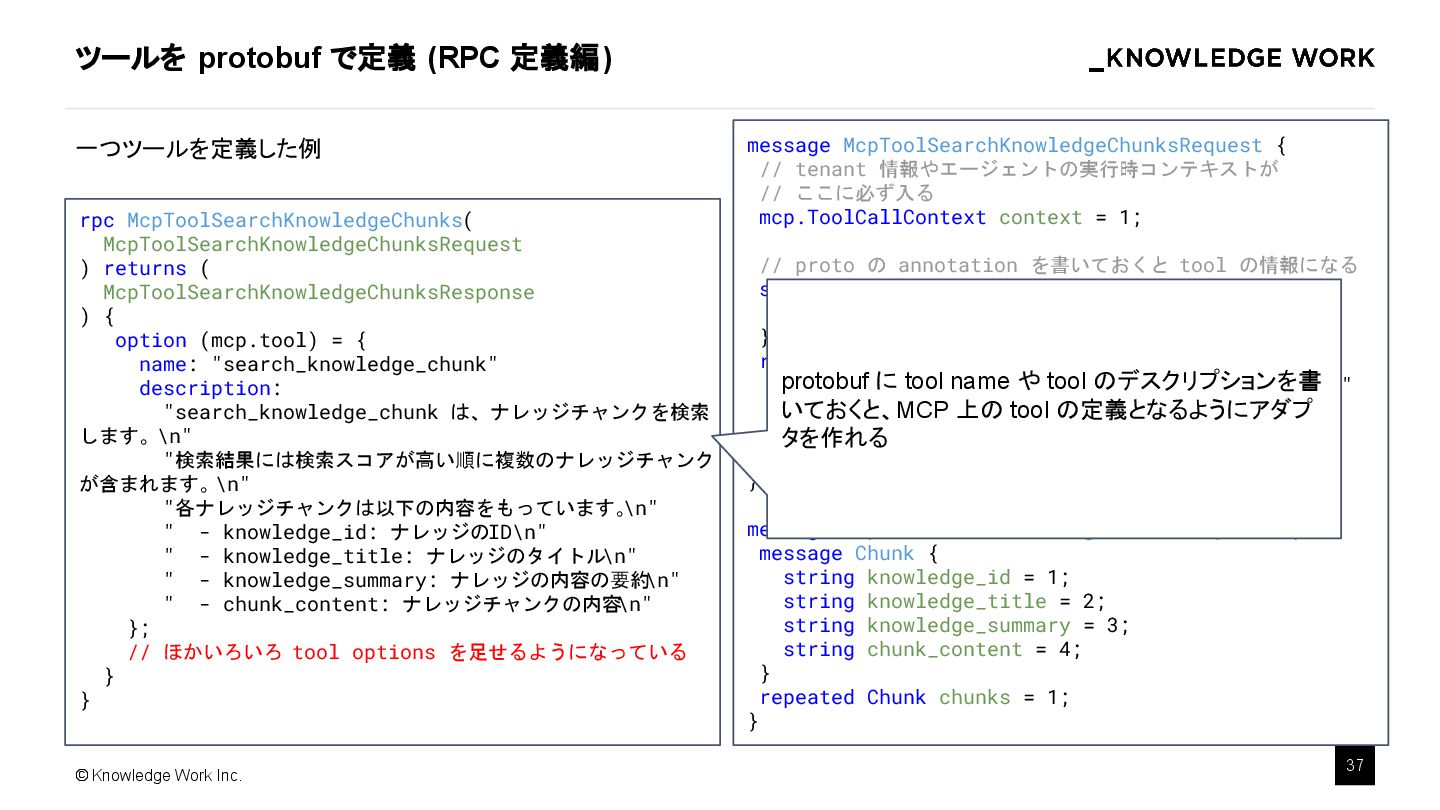{kind=link}
{kind=link}
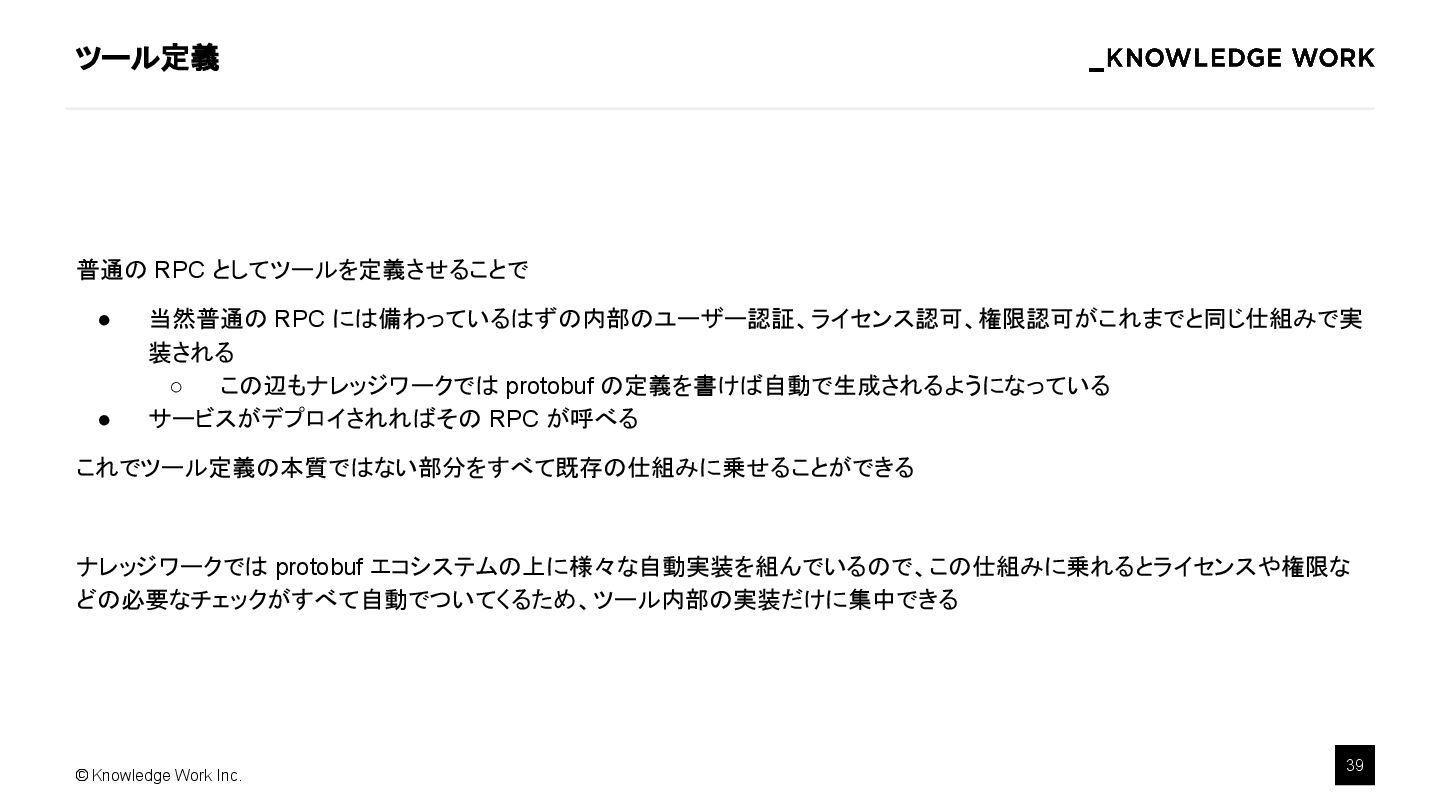{kind=link}
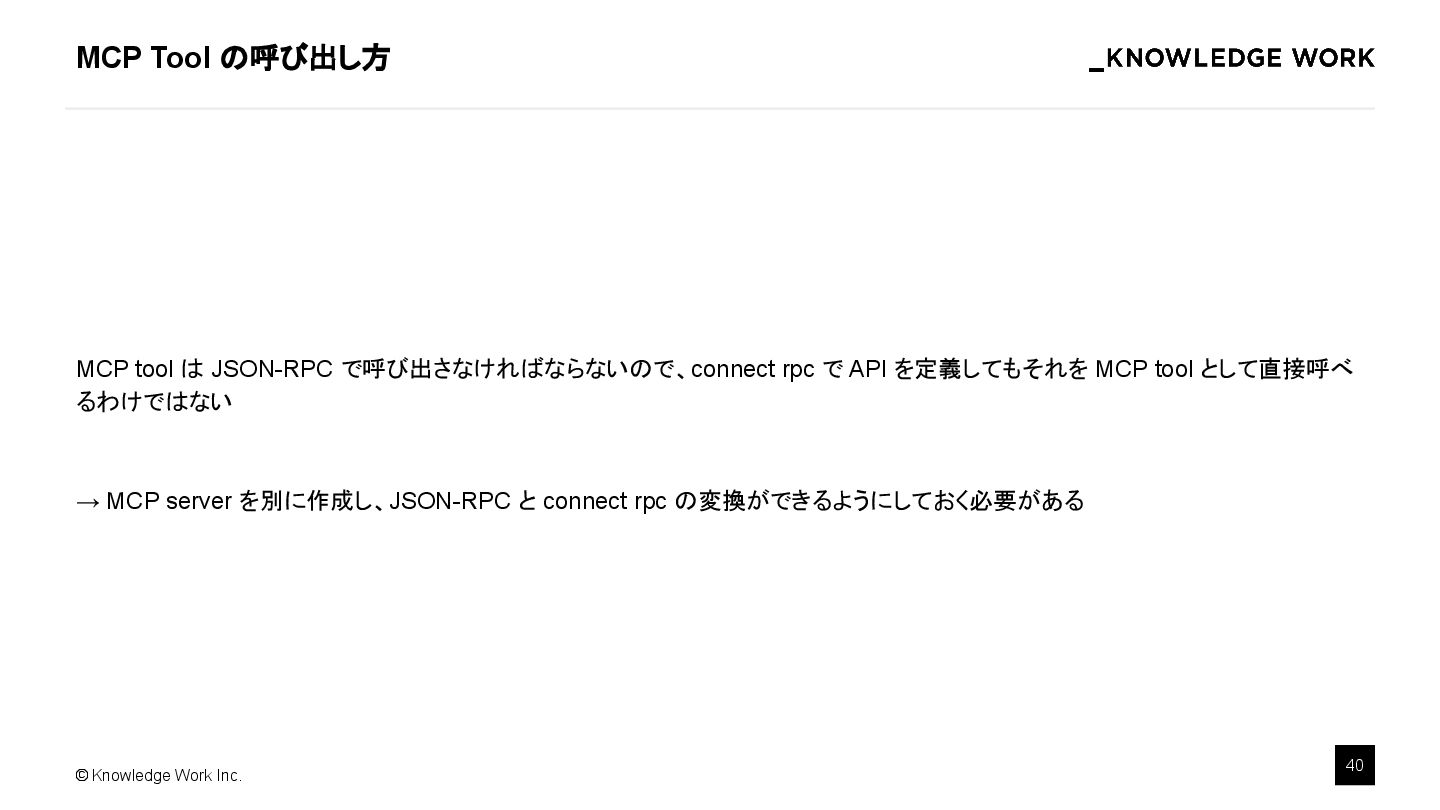{kind=link}
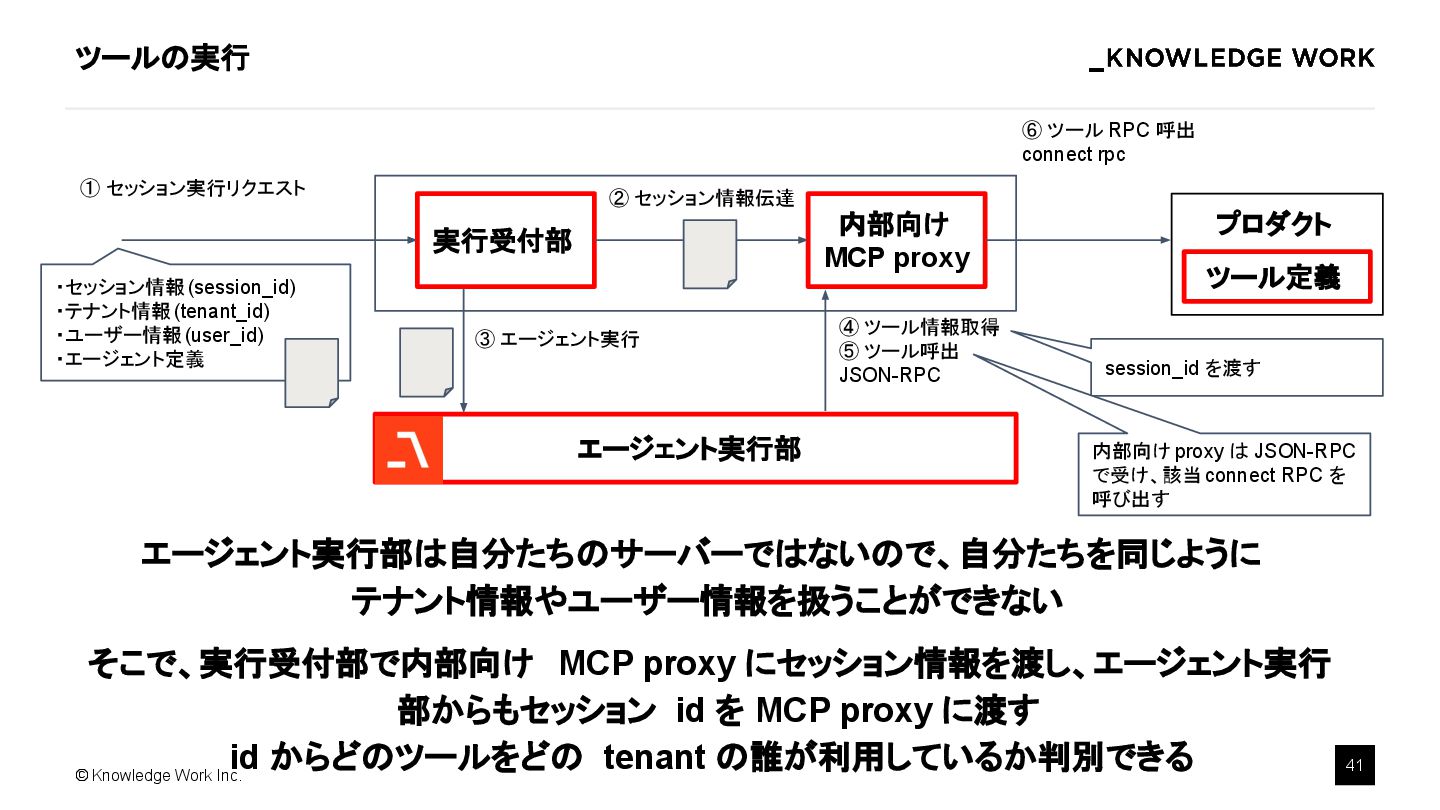{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}