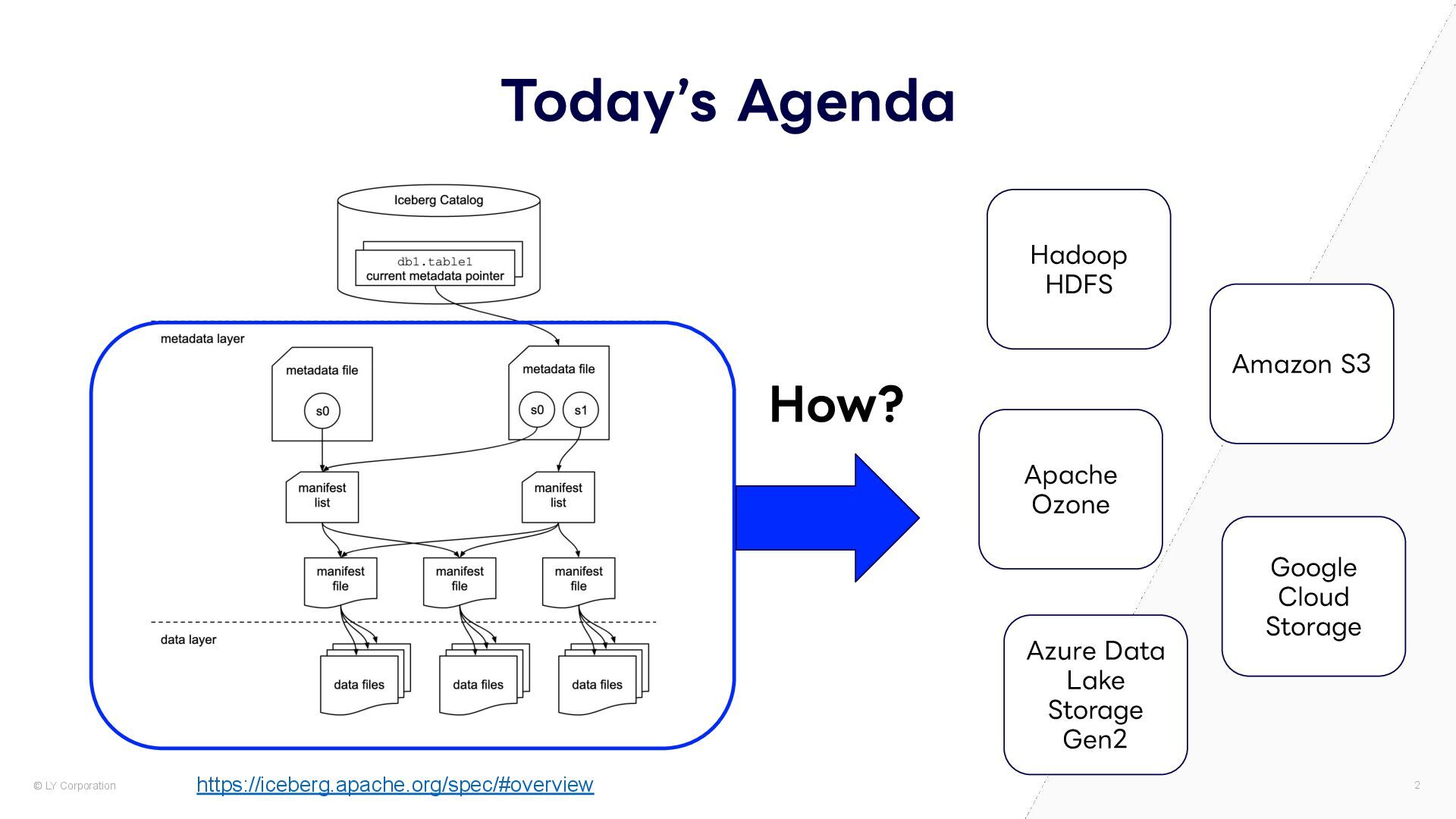
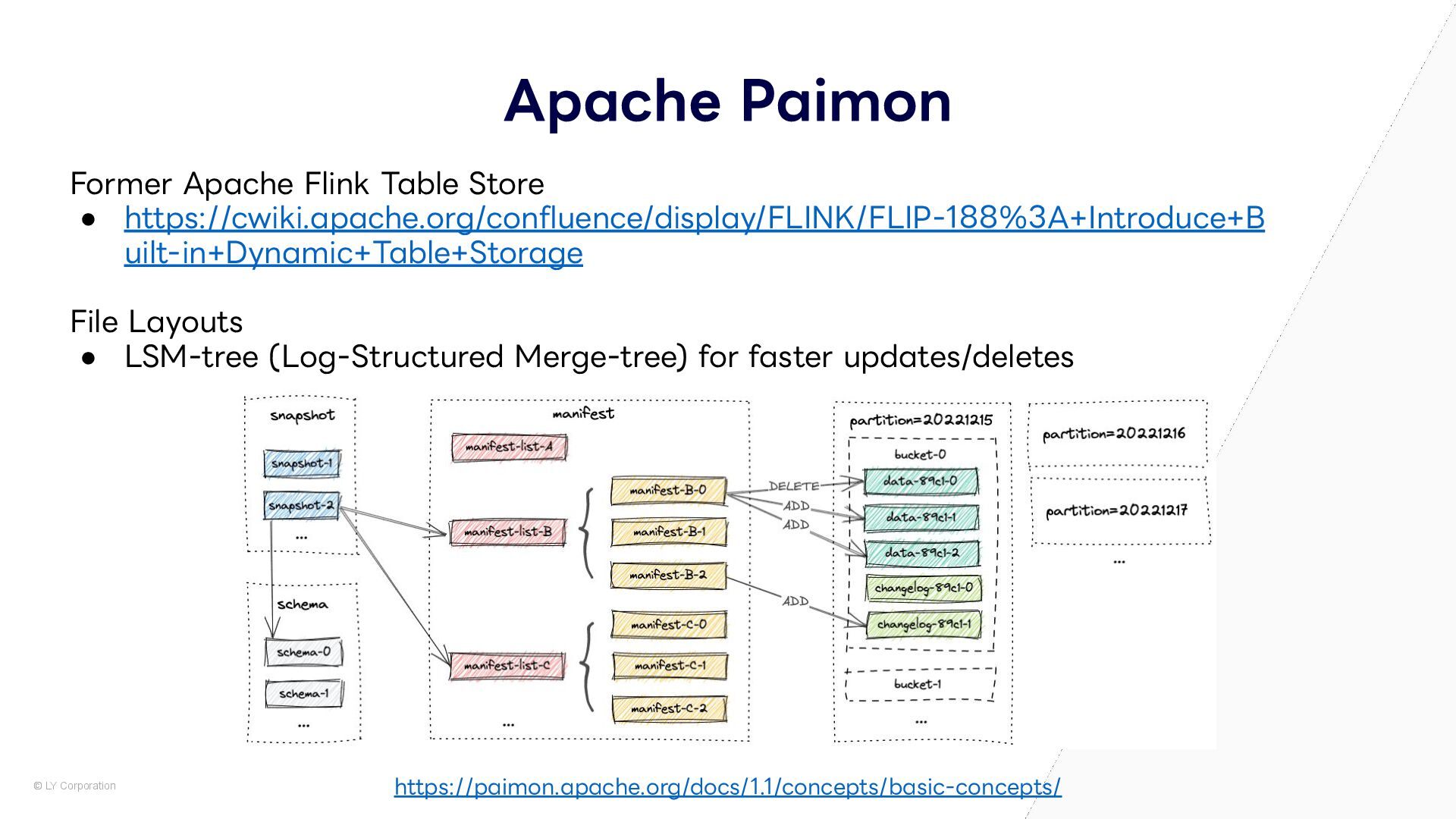
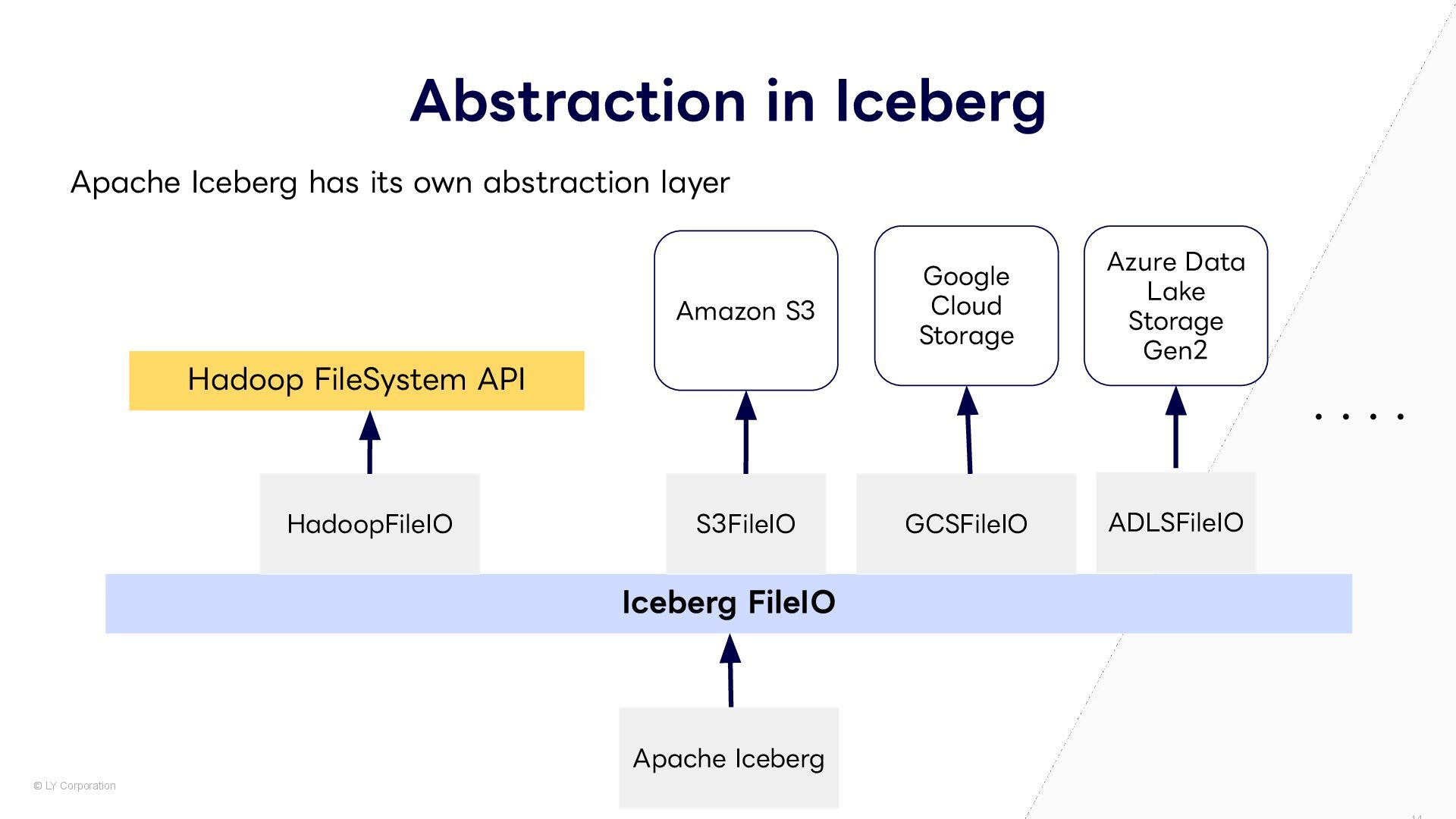
Open Table Format (OTF) は多種多様な分散ファイルシステムやオブジェクトストレージに対応しています。これらのストレージにはそれぞれ独自のAPIやSDKが用意されていますが、それらを最適な形で個別に使い分けるため、Apache Iceberg、Apache Hudi、Delta Lake、Apache Paimonはそれぞれどのようにストレージ層を抽象化しているか説明します。
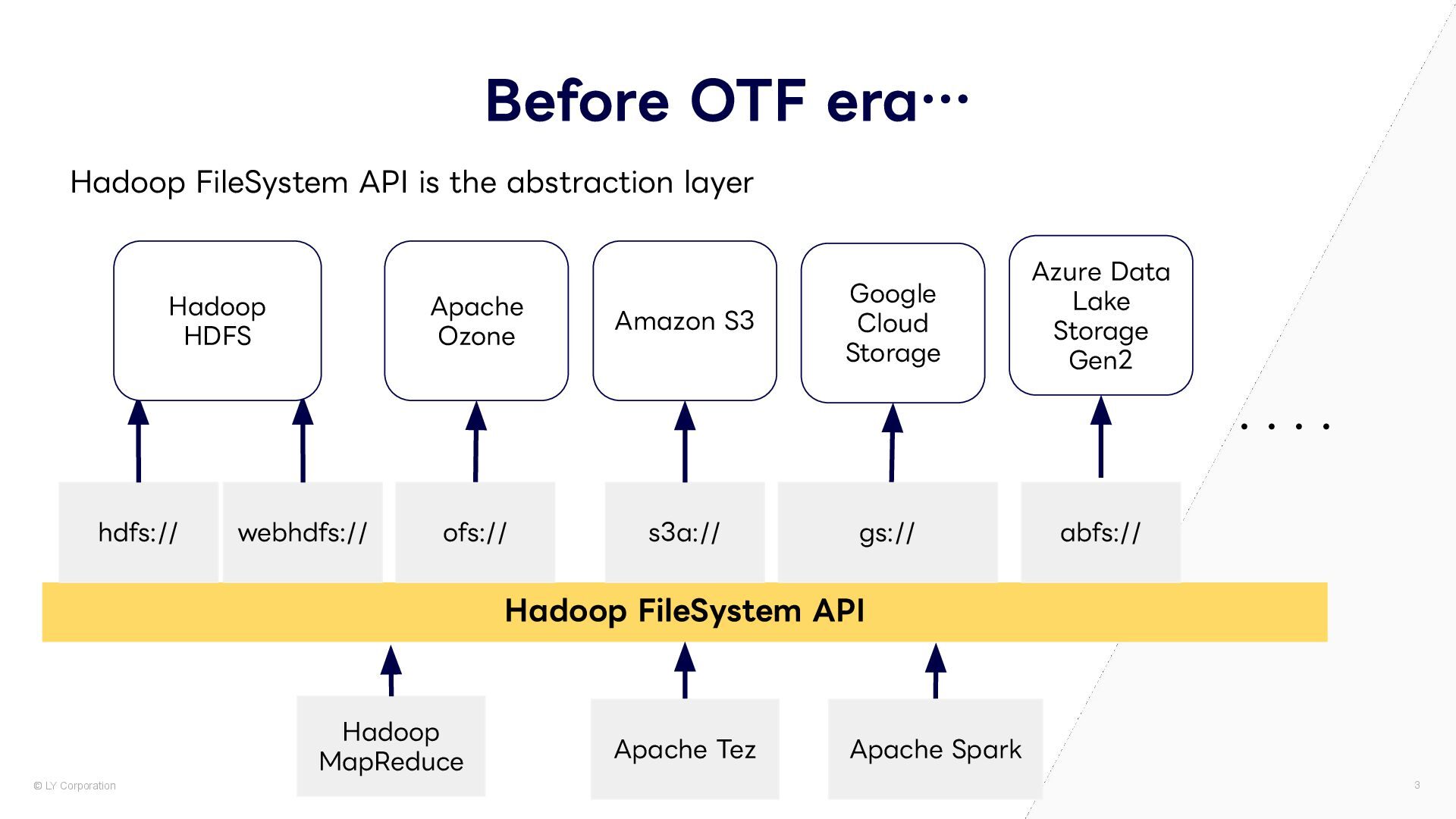
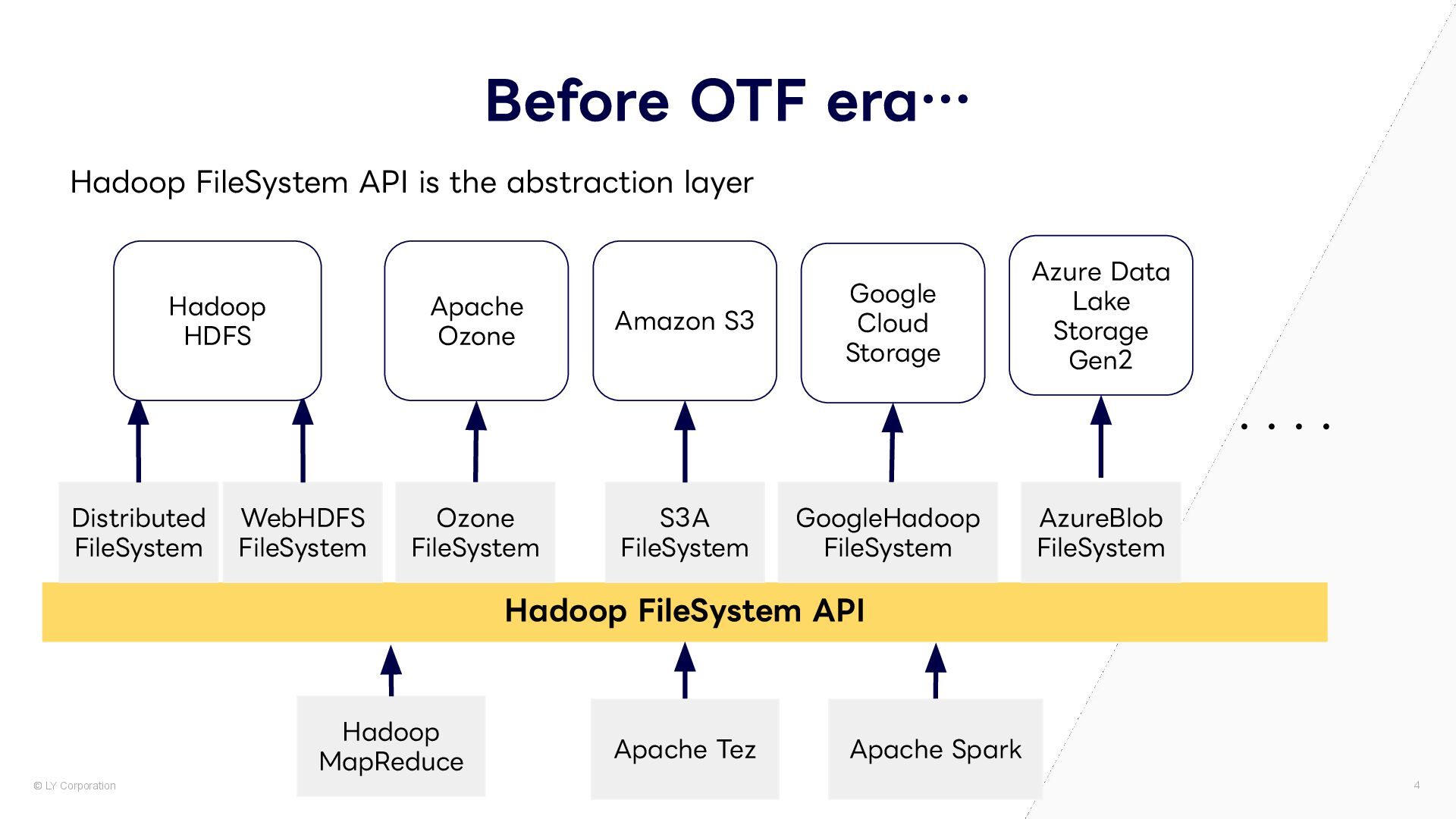
is the abstraction layer Hadoop FileSystem API Azure Data Lake Storage Gen2 ・・・・ hdfs:// webhdfs:// ofs:// s3a:// gs:// abfs:// Hadoop MapReduce Hadoop HDFS Apache Ozone Amazon S3 Google Cloud Storage Apache Tez Apache Spark
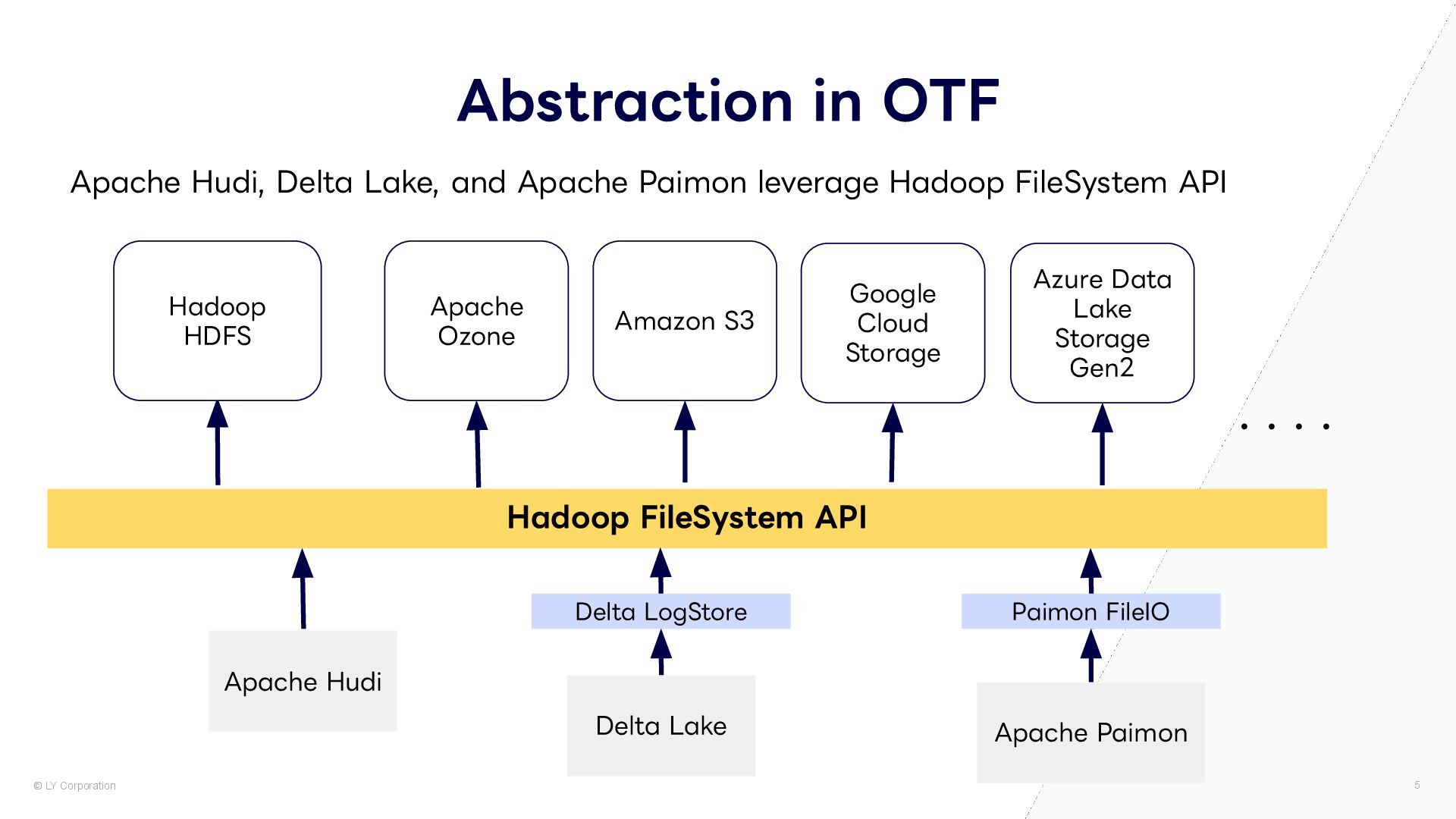
Lake, and Apache Paimon leverage Hadoop FileSystem API Hadoop FileSystem API Azure Data Lake Storage Gen2 ・・・・ Delta LogStore Paimon FileIO Apache Hudi Delta Lake Apache Paimon Hadoop HDFS Apache Ozone Amazon S3 Google Cloud Storage
isWriteTransactional • If true, skip block corrupt check Atomic writes • If supportAtomicCreation is true, FileSystemLockProvider can be used • If storageLockClass is true, StorageBasedLockProvider can be used • Otherwise, coordinator (such as ZooKeeper, DynamoDB) is required
rename is not atomic and external lock is required to commit snapshots newTwoPhaseOutputStream(Path, boolean) • Default: Create a temp file and rename it • S3, Alibaba Cloud Object Storage Service (OSS): Multipart upload and commit https://github.com/apache/paimon/pull/6287
FileIO S3FileIO GCSFileIO Azure Data Lake Storage Gen2 ・・・・ ADLSFileIO HadoopFileIO Apache Iceberg has its own abstraction layer Apache Iceberg Amazon S3 Google Cloud Storage
their differences among OTFs • Dive-deep into storage-specific implementations and optimizations ◦ This presentation does not cover all of them ◦ You can go further by reading source code or let AI to do ▪ Example: “Read the source code, please teach me FileIO in Paimon and its implementation, especially please teach me any specific implementation for a specific storage.” • Improvements in an OTF can be ported to other OTFs?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}