Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigQueryを使った機械学習プロジェクトの分析とオフライン検証
Search
mahiguch
October 17, 2019
Programming
1.3k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigQueryを使った機械学習プロジェクトの分析とオフライン検証
「【増枠】酒とゲームとインフラとGCP 第11回」の発表資料です。
https://connpass.com/event/147801/
mahiguch
October 17, 2019
More Decks by mahiguch
See All by mahiguch
爆速で成長する おでかけ情報サービスの成長を支えるデザインと開発の取り組みについて
mahiguch
0
80
WebView認証連携
mahiguch
0
87
メディアアプリLIMIAにおけるプッシュ通知配信システム
mahiguch
0
120
公式部活動技術書典部の活動紹介
mahiguch
0
140
エンジニア以外の方が自らSQLを使ってセグメント分析を行うカルチャーをどのように作っていったか
mahiguch
1
1.1k
PHPからgoへの移行で分かったこと
mahiguch
2
4.4k
gRPCを使ったメディアサービス2
mahiguch
0
250
LIMIAでのBigQuery活用事例
mahiguch
0
230
機械学習輪講会資料
mahiguch
0
190
Other Decks in Programming
See All in Programming
AIエージェントで 変わるAndroid開発環境
takahirom
2
560
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.7k
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
110
Creating Composable Callables in Contemporary C++
rollbear
0
200
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
110
symfony/aiとlaravel/boost
77web
0
120
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
180
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
200
フィードバックで育てるAI開発
kotaminato
1
110
Mujeres en SEO Summit 2026 - Greatest Disaster Hits en Web Performance
guaca
0
240
霧の中の代数的エフェクト
funnyycat
1
350
1B+ /day規模のログを管理する技術
broadleaf
0
130
Featured
See All Featured
Six Lessons from altMBA
skipperchong
29
4.3k
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Facilitating Awesome Meetings
lara
57
7k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
Speed Design
sergeychernyshev
33
1.9k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Design in an AI World
tapps
1
260
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Transcript
Copyright © LIMIA, Inc. All Rights Reserved. BigQueryを使った機械学習 プロジェクトの分析とオフライン 検証
LIMIA推薦システム事例発表
Copyright © LIMIA, Inc. All Rights Reserved. • グリーグループのリミア株式会社で、LIMIA という住まい領域のメディア
を作っています。ゲーム会社ですが、最近はメディアに力を入れていま す。 • 機械学習(RecSys)のエンジニアですが、iOS, Android,JSなどもやってい る何でも屋です。5歳の娘のパパ。twitter: @mahiguch1 • 部活動でグリー技術書典部を作り技術書典7参加、8に参加予定。 • https://limia.jp/ • https://arine.jp/ • https://aumo.jp/ • https://www.mine-3m.com/mine/ Masahiro Higuchi/樋口雅拓 2
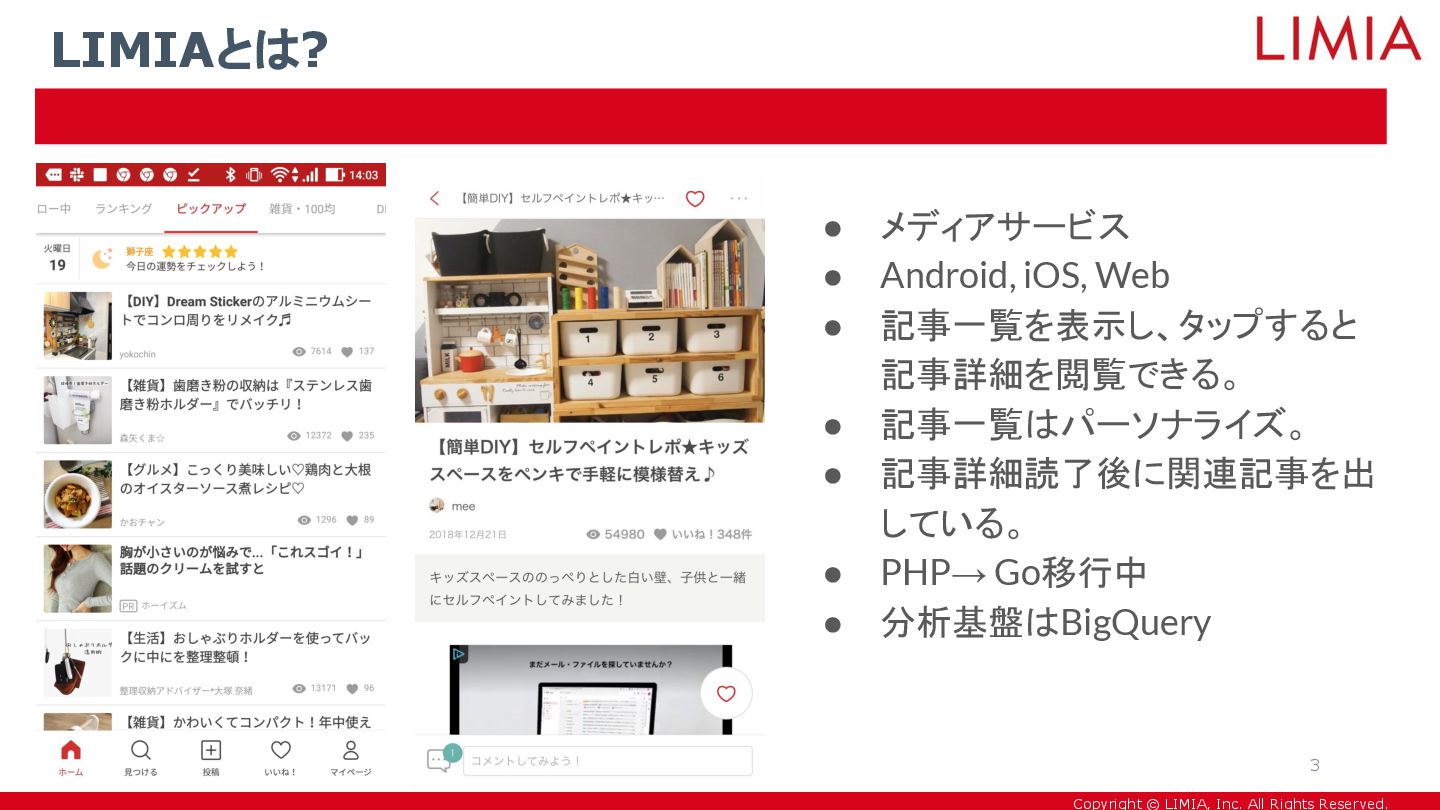
Copyright © LIMIA, Inc. All Rights Reserved. LIMIAとは? 3 •
メディアサービス • Android, iOS, Web • 記事一覧を表示し、タップすると 記事詳細を閲覧できる。 • 記事一覧はパーソナライズ。 • 記事詳細読了後に関連記事を出 している。 • PHP→ Go移行中 • 分析基盤はBigQuery
Copyright © LIMIA, Inc. All Rights Reserved. LIMIAでは、より良いユーザ体験を提供するため、ユーザ毎に最適な一覧表示 を行なっています。 【発表内容】
それを実現するため、1.分析、2.オフライン検証、3.配信、4.オンライン検証、 5.レポートのシステムを構築しました。 まず、0.推薦システムについて説明し、次に上記5システムについて説明しま す。最後に6.今後の課題について話します。 【発表のモチベーション】 知識を共有することで、機械学習基盤を効率的に構築したい! 発展途上の分野で定石がないので、お気付きの点があれば教えて欲しい。 概要 4
Copyright © LIMIA, Inc. All Rights Reserved. 0.推薦システムとは 概要説明
Copyright © LIMIA, Inc. All Rights Reserved. 推薦システムを作るのは難しい。 理想的には、以下の専門家が必要。 •
Analyst: データを分析して課題を発見 • Data Scientist: Model作成 • Algorithm Programer: 本番コード実装 • ML Ops: インフラを作る • Researcher: 使えそうな論文を見つけて共有 → この章では、それぞれの専門家がどんな環境で、何を目指して作業している か説明します。 プロジェクトの構成 6
Copyright © LIMIA, Inc. All Rights Reserved. 以下の目的のため、データを分析する。 • ユーザ体験向上
• 取引先企業の課題解決 課題を解決するため、施策立案と施策評価を行う。 昭和の言い方だと、上流工程? 機械学習が使えそうな課題があれば、DSに相談する。 → LIMIAではProductManager(PM)が担当。BigQueryとSpreadSheet を使って作業している。 Analyst 7
Copyright © LIMIA, Inc. All Rights Reserved. Analystから提案された課題の解決方法を提案する。 Researcherと相談して、使えそうな理論を選び、手元の開発環境でモデルを作 る。作ったモデルをAlgorithm
Programmerに渡してサービスに組み込んでも らう。Kagglerが多い。 推薦システムは、次の4つの要素から構成される。※1 • Item Modeling(Itemをvector化) • User Modeling(Userをvector化) • Scoring(それらを使ってscoreを作り) • Ranking(1つ以上のscoreを使って並べ替え) それぞれで使える手法を選んで実装し、オフライン検証を行う。良い結果が出た ら、Algorithm Programmerに渡す。 → LIMIAではAPが担当。Jupiter/Python/BigQueryを使う。 Data Scientist 8
Copyright © LIMIA, Inc. All Rights Reserved. Data Scientistが作ったモデルを使って、本番サービスで動くコードを書く。動 作速度が問題となることが多いので、競技プログラミング
(atcorder/topcorder)組が多い。 実装して本番反映し、オンライン(A/B)検証を行い、結果が良ければ全ユーザ へ適用する。 → LIMIAではAPとML Ops(発表者)が担当。golangで実装して本番デプロ イして、オンライン検証結果を確認する。 Algorithm Programmer 9
Copyright © LIMIA, Inc. All Rights Reserved. Algorithm Programmerと相談して、最適なインフラを作る。学習と言われ るバッチ処理は非常に重い。推論と言われるオンライン処理は、小さい
latencyが求められる。また、自動最適化を行うため、ログの収集が非常に重 要! → LIMIAではML Ops(発表者)が担当。各種ログをBigQueryに収集してい る。vscodeでCloudFormationテンプレートを書いている。 ML Ops 10
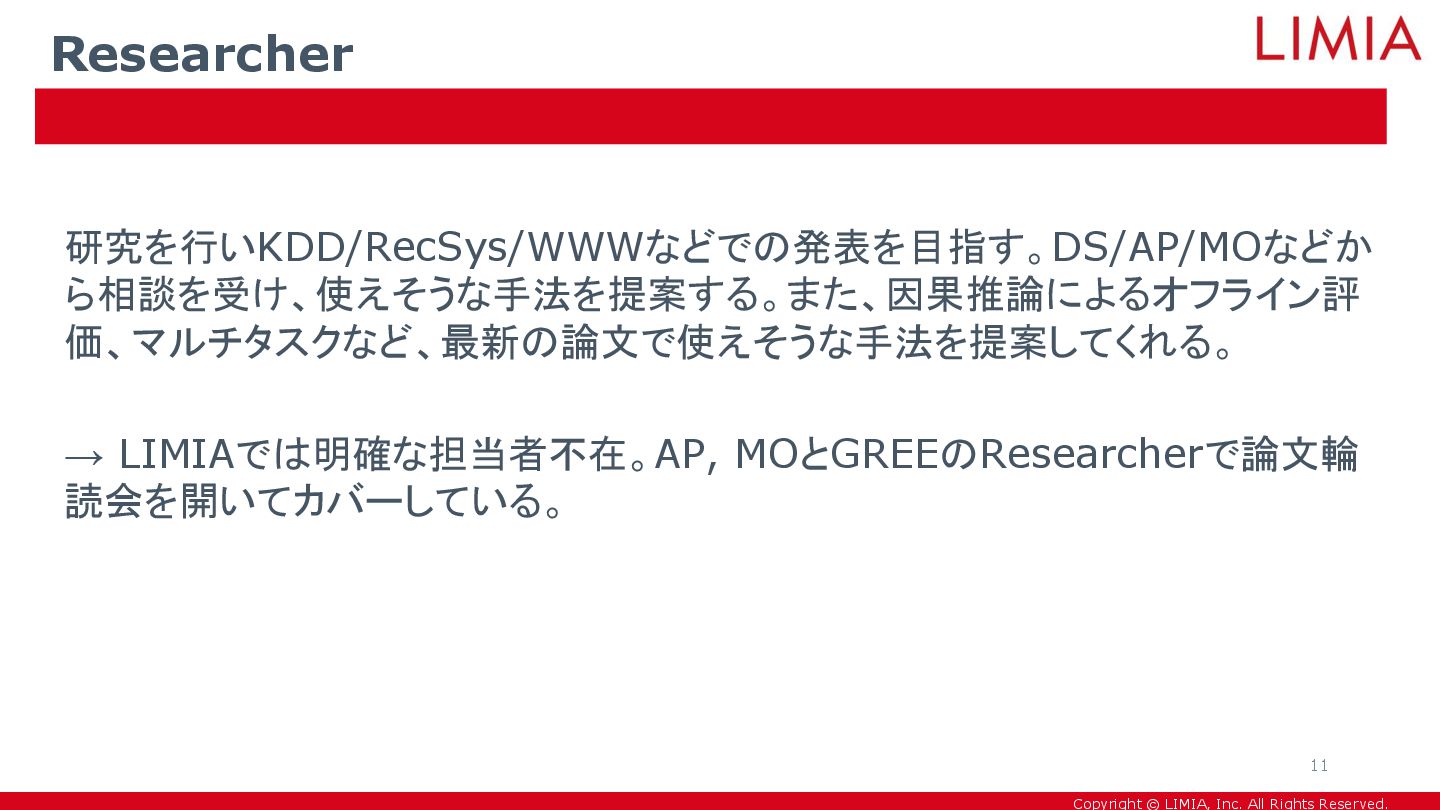
Copyright © LIMIA, Inc. All Rights Reserved. 研究を行いKDD/RecSys/WWWなどでの発表を目指す。DS/AP/MOなどか ら相談を受け、使えそうな手法を提案する。また、因果推論によるオフライン評 価、マルチタスクなど、最新の論文で使えそうな手法を提案してくれる。
→ LIMIAでは明確な担当者不在。AP, MOとGREEのResearcherで論文輪 読会を開いてカバーしている。 Researcher 11
Copyright © LIMIA, Inc. All Rights Reserved. 1.分析 Analystが使うシステム
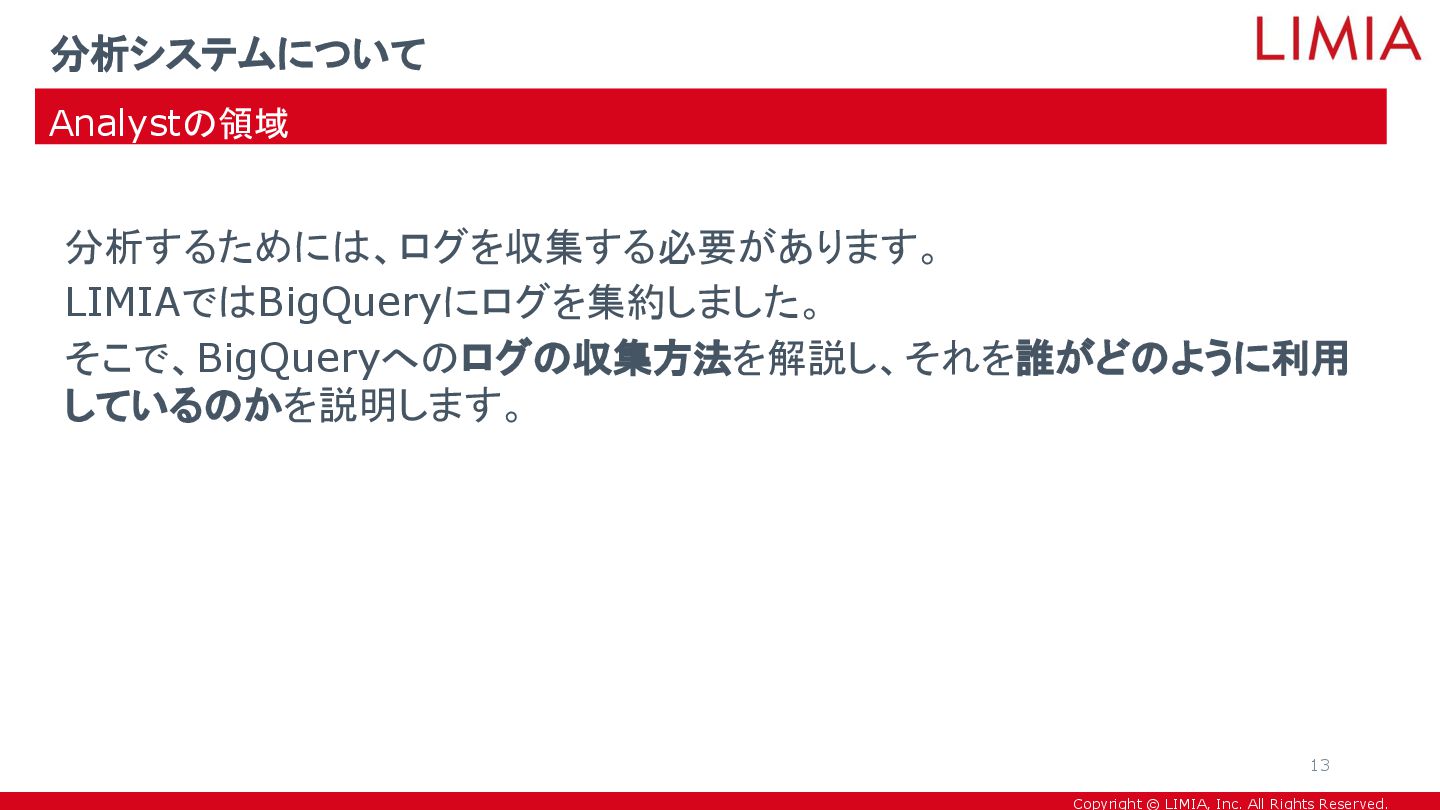
Copyright © LIMIA, Inc. All Rights Reserved. 分析するためには、ログを収集する必要があります。 LIMIAではBigQueryにログを集約しました。 そこで、BigQueryへのログの収集方法を解説し、それを誰がどのように利用
しているのかを説明します。 分析システムについて Analystの領域 13
Copyright © LIMIA, Inc. All Rights Reserved. Firebase管理画面でボタンを押すだけでBigQueryにデータが連携される。 連携されるデータは、次のもの。 •
Analytics: 送信した全てのイベント • Crashlytics: 発生した例外の情報 • Predictions: 予測結果 • FCM: プッシュ通知送受信ログ • Performance: 送信したトレース情報 Analytics以外のBigQueryデータは使いこなせていない。良い使い道があれ ば教えて欲しい。 イベントログ Firebase 14
Copyright © LIMIA, Inc. All Rights Reserved. Embulkを使ってBigQueryへ転送している。Embulkコンテナを作り、ECS Fargateで回している。以下に要点だけ示す。 •
ALB: daily table(xxlog_20190828)に前日分を転送 • CloudFront: ファイル名で前日分を特定できないので、手元に最終更新 日時指定でs3 syncしてから転送。 • RDS: 負荷を考慮して1テーブルずつ転送。daily tableを切らずに上書 きしていく。履歴は残らないが、MySQLと同じqueryが使える。 • Dynamo: 構造化データはjson文字列として格納。 GCP service accountは、EKSで暗号化したファイルをcontainerに含めて いる。embulkはfargateのExecRoleを見てくれないので、AWS IAM user を環境変数で渡している。 AWSのデータ ALBとCloudFrontのアクセスログ/RDSとDynamoのデータ 15
Copyright © LIMIA, Inc. All Rights Reserved. • Search Console:
golangバッチでAPIから取得し、BigQueryへ転送。 ECS fargate taskで毎晩実行。 • Google Analytics: 集計パターンをいくつか作り、それぞれをBigQuery の対象テーブルへ転送。実行環境はSCと同じ。 • Adjust: Cloud FunctionsにEndpointを作り、来たデータを全て BigQueryに格納。AdjustのGlobal Callbackに設定。 • Kintone: 一部業務の管理ツールとしてKintoneが使われていたため、 Kintone APIをGASで叩いてBigQueryへ。 その他のログ SearchConsole/GoogleAnalytics/Adjust 16
Copyright © LIMIA, Inc. All Rights Reserved. 原則データの確認はRDS/Dynamo等は使わず、BigQueryにある早朝に 取ったスナップショットに対して行う。BigQuery画面からが多く、DSは Jupiter+pandasから。
• Analyst: 施策立案のための状況把握。施策の想定効果見積もりと効果 測定。KPI変化の要因分析。 • Data Scientist: パーソナライズを行うため、ユーザやアイテムの特徴を 分析。オフライン検証。 • Algorithm Programmer: オンライン検証結果確認。 • ML Ops: エラーログ、動作速度、機能の利用状況などでシステムの健全 性を分析。 誰が何を分析しているのか 仮説を立てて定量的に検証する 17
Copyright © LIMIA, Inc. All Rights Reserved. LTVを上げるには回遊性向上が効果的。 アプリを起動してコンテンツを閲覧せずに離脱しているユーザが多数存在する ことが分かった。
そこで、起動直後に表示されるピックアップ面の一覧表示をパーソナライズする ことで回遊性を向上させられないか。 今回のプロジェクトでは Analyst分析結果 18
Copyright © LIMIA, Inc. All Rights Reserved. 2.オフライン検証 Data Scientistが使うシステム
Copyright © LIMIA, Inc. All Rights Reserved. Data Scientistが過去のデータを 使って、モデルの良し悪しを検証する。
良いモデルができたら、APにJupiter Notebookを渡す。 → LIMIAではgistにnotebookを貼 り付けて連携。 左図はGoogle Colaboratoryという インストールなしで使えるJupiter Notebookのようなもの。 https://colab.research.google.com/?hl=ja オフライン検証とは? Data Scientistの領域 20
Copyright © LIMIA, Inc. All Rights Reserved. 例えば、 • 14-8日前のデータを使って学習。ユーザ毎に推薦リストを作成。
• 7-1日前に閲覧されたItemが推薦リストの中に含まれている割合で評 価。 最近では因果推論を使った検証が流行中。 → LIMIAではMAPとnDCGで評価。 検証方法 21
Copyright © LIMIA, Inc. All Rights Reserved. オフライン検証のベースラインとして、人気のあるコンテンツを全員に配信した ときを想定する。 Cell/Itemを表示したらFirebase
Analyticsにimpression eventを送信 し、Clickしたらclick eventを送信してBigQueryに格納する。イベント数で割 り算したCTRを人気記事の定義とした。 → LIMIAではCTRがこれを上回ったら、オンライン検証に移行。 合格ラインは? Popular Model 22
Copyright © LIMIA, Inc. All Rights Reserved. • Item Modeling:
記事を形態素解析して名詞を取り出し、それをword embeddingしたvectorの平均を取った。 • User Modeling: ユーザが読んだ直近30件のItemのvectorの平均を 取った。 • Scoring: ItemとUserの距離。 • Ranking: Scoreの大きい順に並べた。 全Itemとの距離を計算すると重いので、10個に分類して中心点との距離を距 離を計算することにした。クラスタ内での並び順は、CTR順。 チャレンジし過ぎてRecSys2019のベストペーパーに指摘されるような事態は避けたい。 オフライン検証を通過したモデル 教科書に書いてある事を愚直に 23
Copyright © LIMIA, Inc. All Rights Reserved. RecSysは推薦分野の有名な国際学 会。 4つの有名な国際学会に発表された
深層学習を使った推薦のコードを確認 したら、ほとんど動かなかったらしい。 それを発表して最優秀論文に選ばれ ていた。 自分で出すときは、気を付けたい! こぼれ話 RecSys2019 Best Paper※2とは? 24
Copyright © LIMIA, Inc. All Rights Reserved. 3.配信 Algorithm Programmerが使うシステム
Copyright © LIMIA, Inc. All Rights Reserved. DSから受け取ったNotebookは、以下のようになっていました。 • 学習:
バッチでItemとUserをベクトル化しておきます。 • 推論: ユーザが一覧表示をリクエストすると、それらを使って一覧表示を作 ります。 これを受けて、次のようなシステムを構築しました。 • 学習: Item/Userの更新通知を既にKinesisに流していたため、これを受 け取って処理するLambdaを追加しました。 • 推論: APIをgolangで作っているため、そこに処理を追加しました。 システム概要 ここはAWSです! すいません。m(_ _)m 26
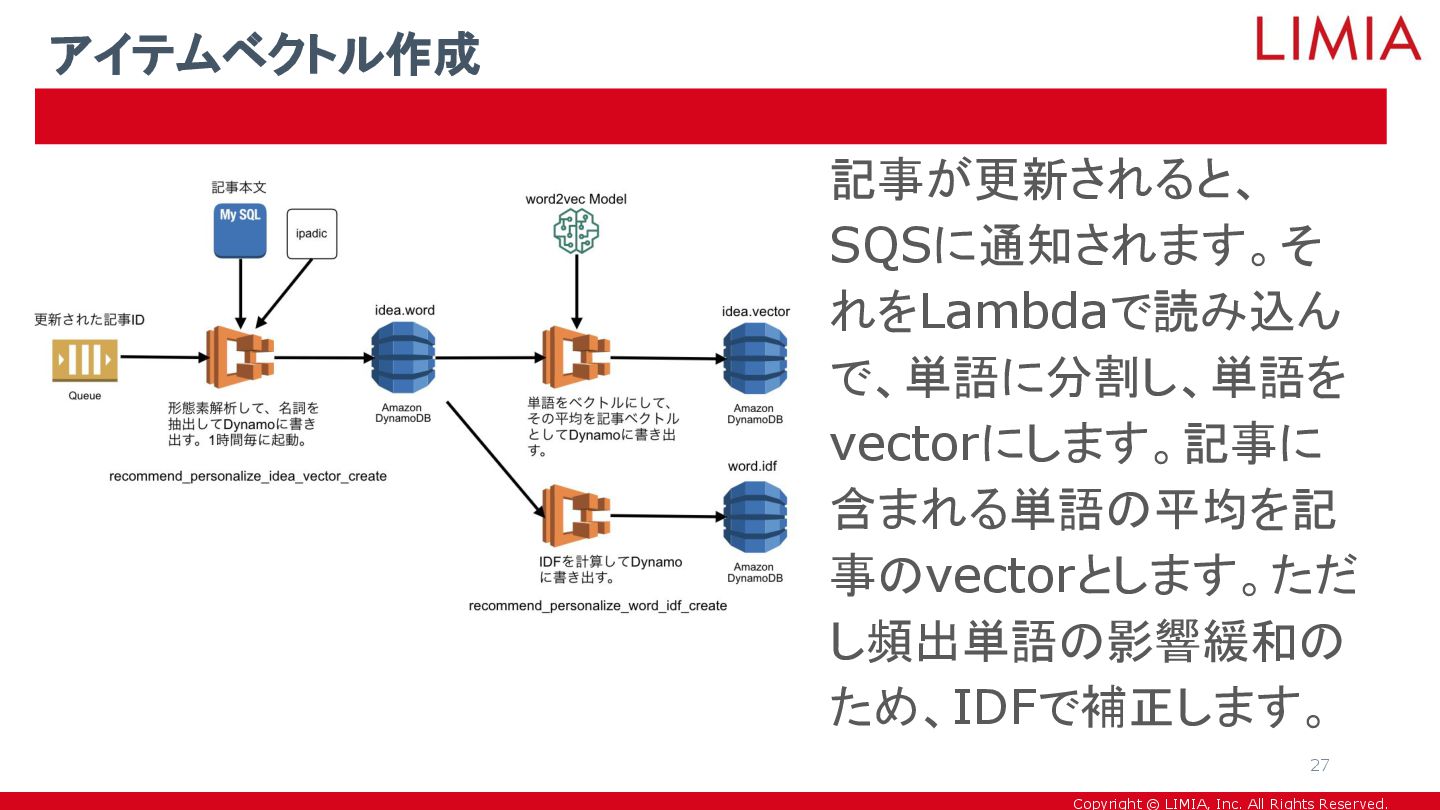
Copyright © LIMIA, Inc. All Rights Reserved. 記事が更新されると、 SQSに通知されます。そ れをLambdaで読み込ん
で、単語に分割し、単語を vectorにします。記事に 含まれる単語の平均を記 事のvectorとします。ただ し頻出単語の影響緩和の ため、IDFで補正します。 アイテムベクトル作成 27
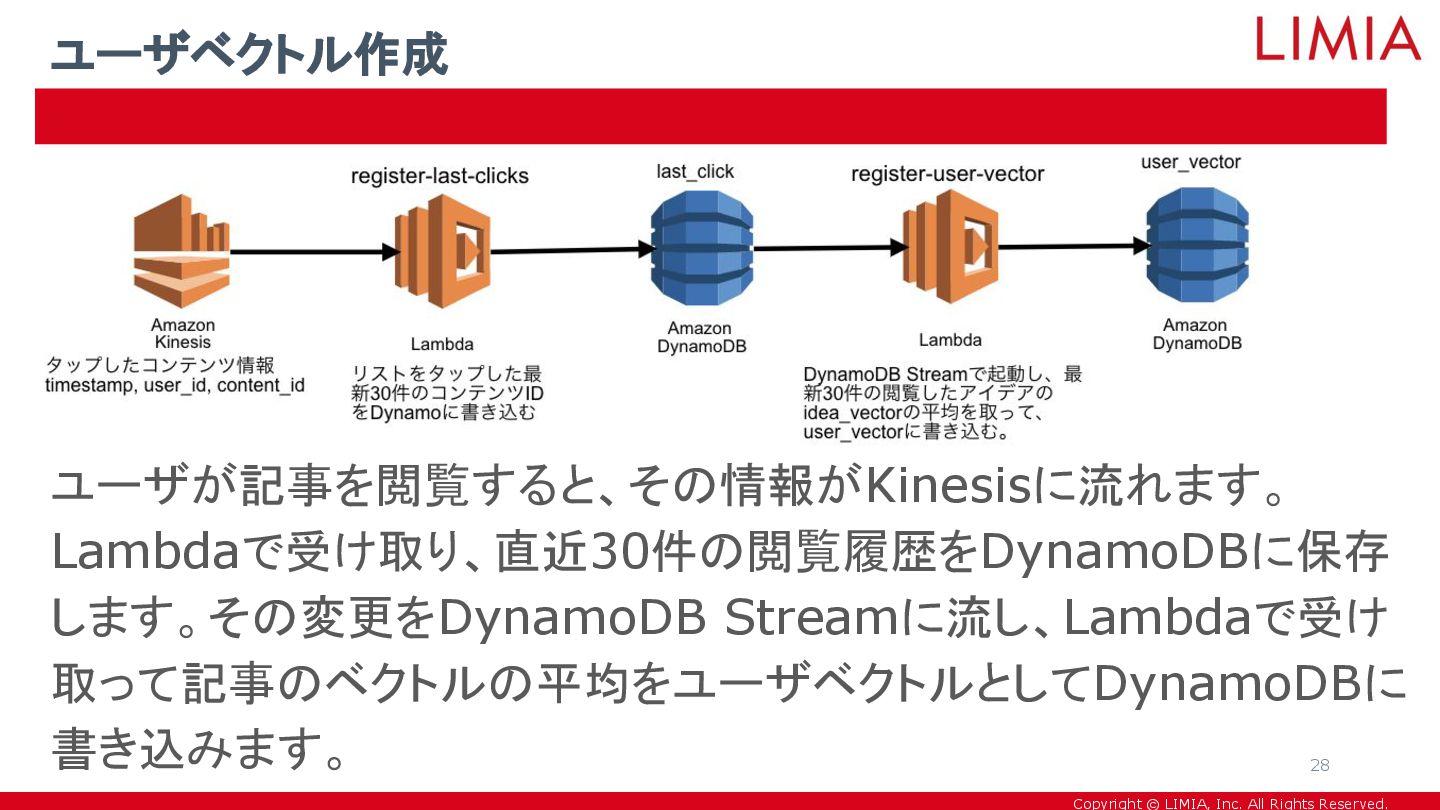
Copyright © LIMIA, Inc. All Rights Reserved. ユーザが記事を閲覧すると、その情報がKinesisに流れます。 Lambdaで受け取り、直近30件の閲覧履歴をDynamoDBに保存 します。その変更をDynamoDB
Streamに流し、Lambdaで受け 取って記事のベクトルの平均をユーザベクトルとしてDynamoDBに 書き込みます。 ユーザベクトル作成 28
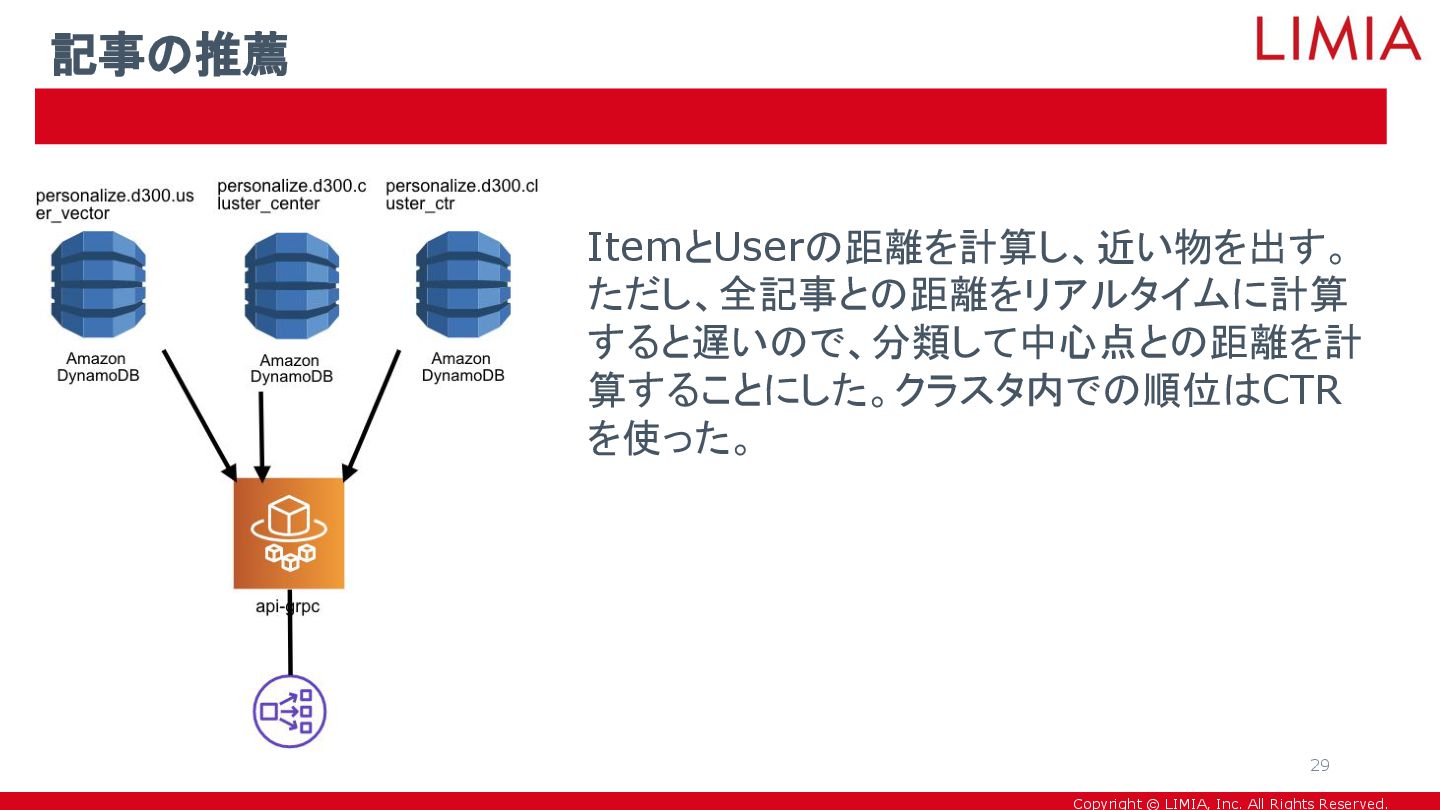
Copyright © LIMIA, Inc. All Rights Reserved. ItemとUserの距離を計算し、近い物を出す。 ただし、全記事との距離をリアルタイムに計算 すると遅いので、分類して中心点との距離を計
算することにした。クラスタ内での順位はCTR を使った。 記事の推薦 29
Copyright © LIMIA, Inc. All Rights Reserved. 4.オンライン検証
Copyright © LIMIA, Inc. All Rights Reserved. まず最初にFirebase A/B Testingを使ってオンライン検証を
行った。 この方法は楽だが厳密性に欠けるため、独自システムを開発し た。 → ここでは、両方について説明します。 オンライン検証方法 Firebase A/B Testingと独自システム 31
Copyright © LIMIA, Inc. All Rights Reserved. • RemoteConfigはKey-Valueスト ア。
• PCブラウザから設定できるので、企 画側で対応可能。 • Firebase A/B Testingでは、直接 的には指定したRemoteConfig key の値が変更される。 • そこでデータを取得するAPI毎に RemoteConfig keyを作成する。 Firebase A/B Testingを使った手法(1) Firebase RemoteConfig設定 32
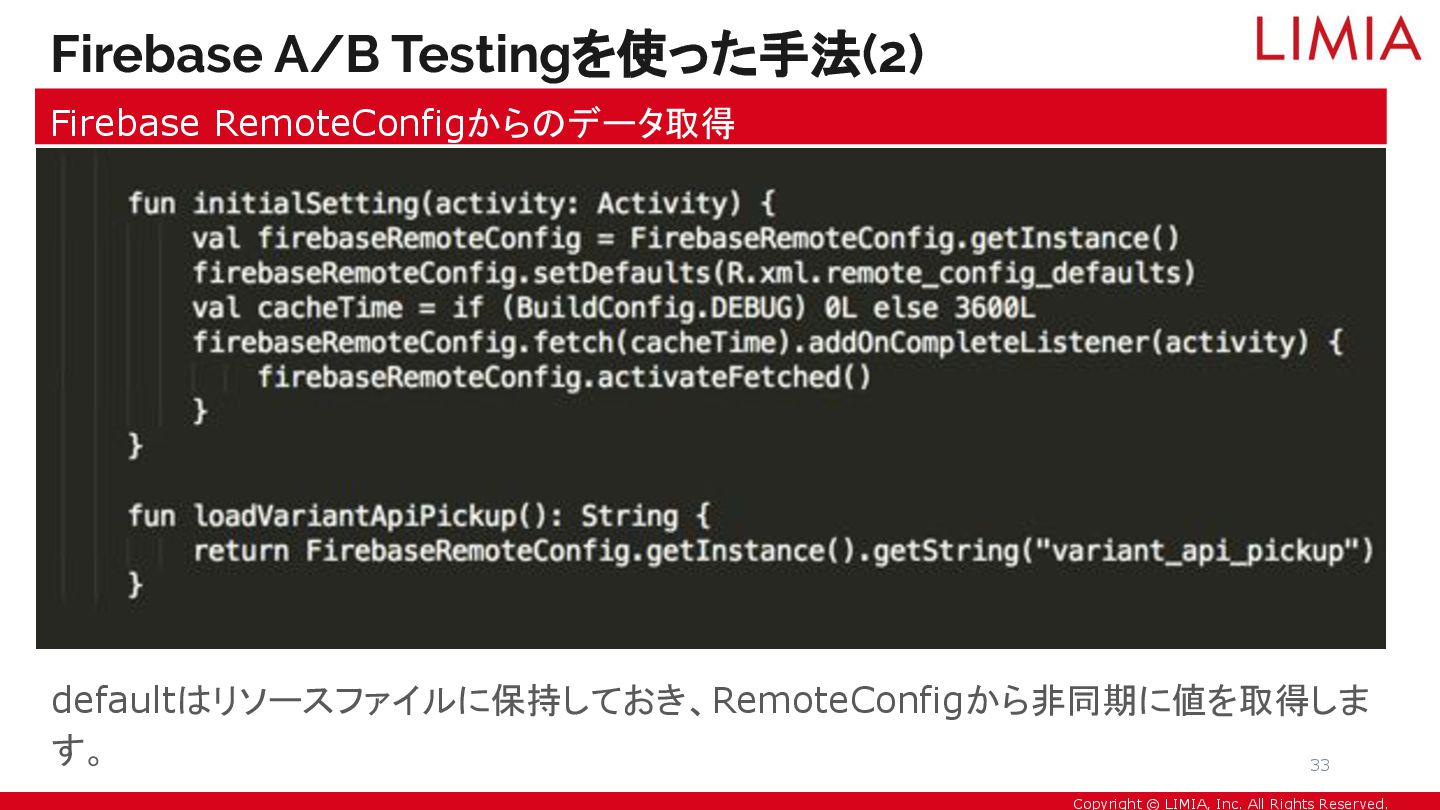
Copyright © LIMIA, Inc. All Rights Reserved. defaultはリソースファイルに保持しておき、RemoteConfigから非同期に値を取得しま す。 Firebase
A/B Testingを使った手法(2) Firebase RemoteConfigからのデータ取得 33
Copyright © LIMIA, Inc. All Rights Reserved. QueryStringにRemoteconfigから取得したパラメータを追加します。 サーバ側では、そのパラメータを使って処理を分けます。 Firebase
A/B Testingを使った手法(3) HTTPリクエストのQueryStringに追加 34
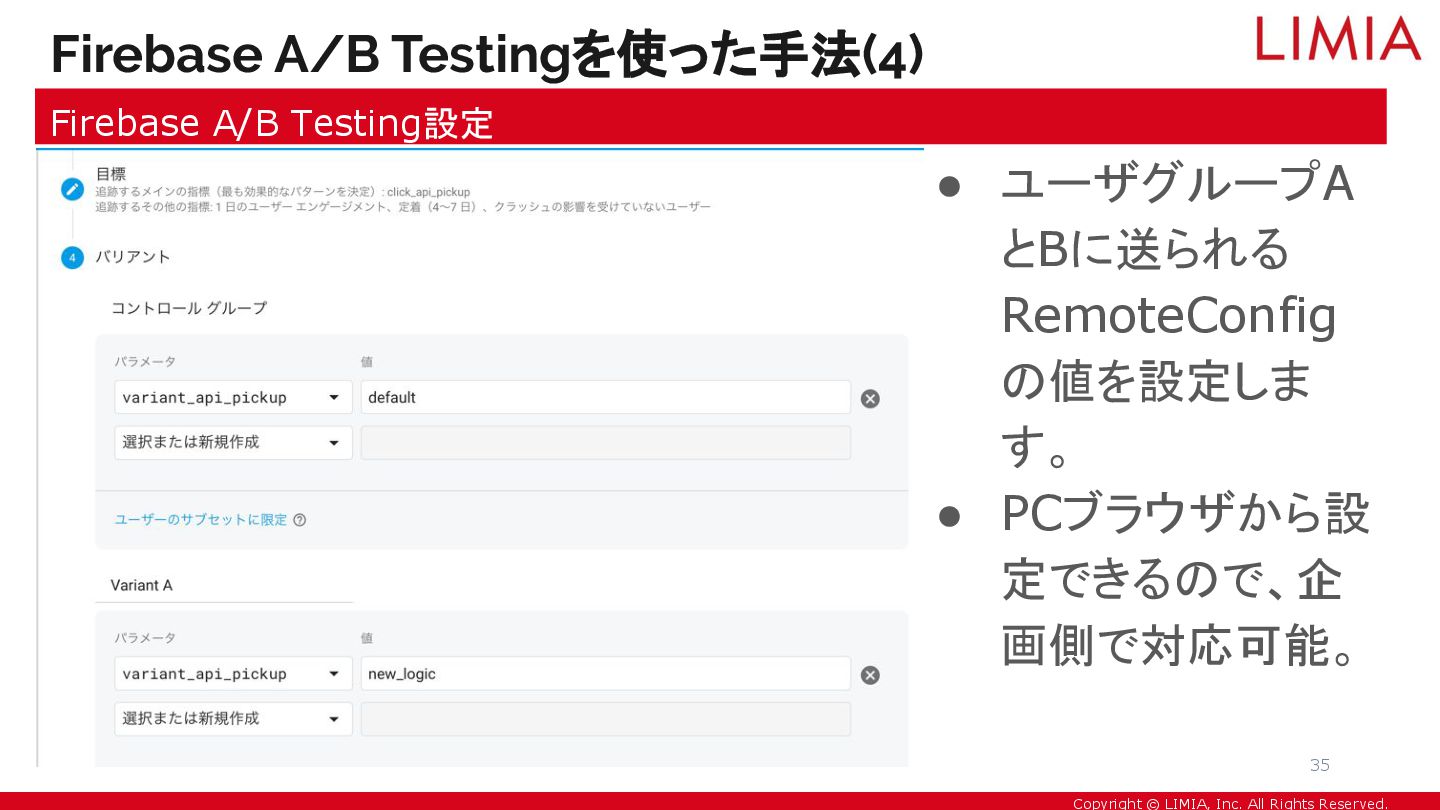
Copyright © LIMIA, Inc. All Rights Reserved. • ユーザグループA とBに送られる
RemoteConfig の値を設定しま す。 • PCブラウザから設 定できるので、企 画側で対応可能。 Firebase A/B Testingを使った手法(4) Firebase A/B Testing設定 35
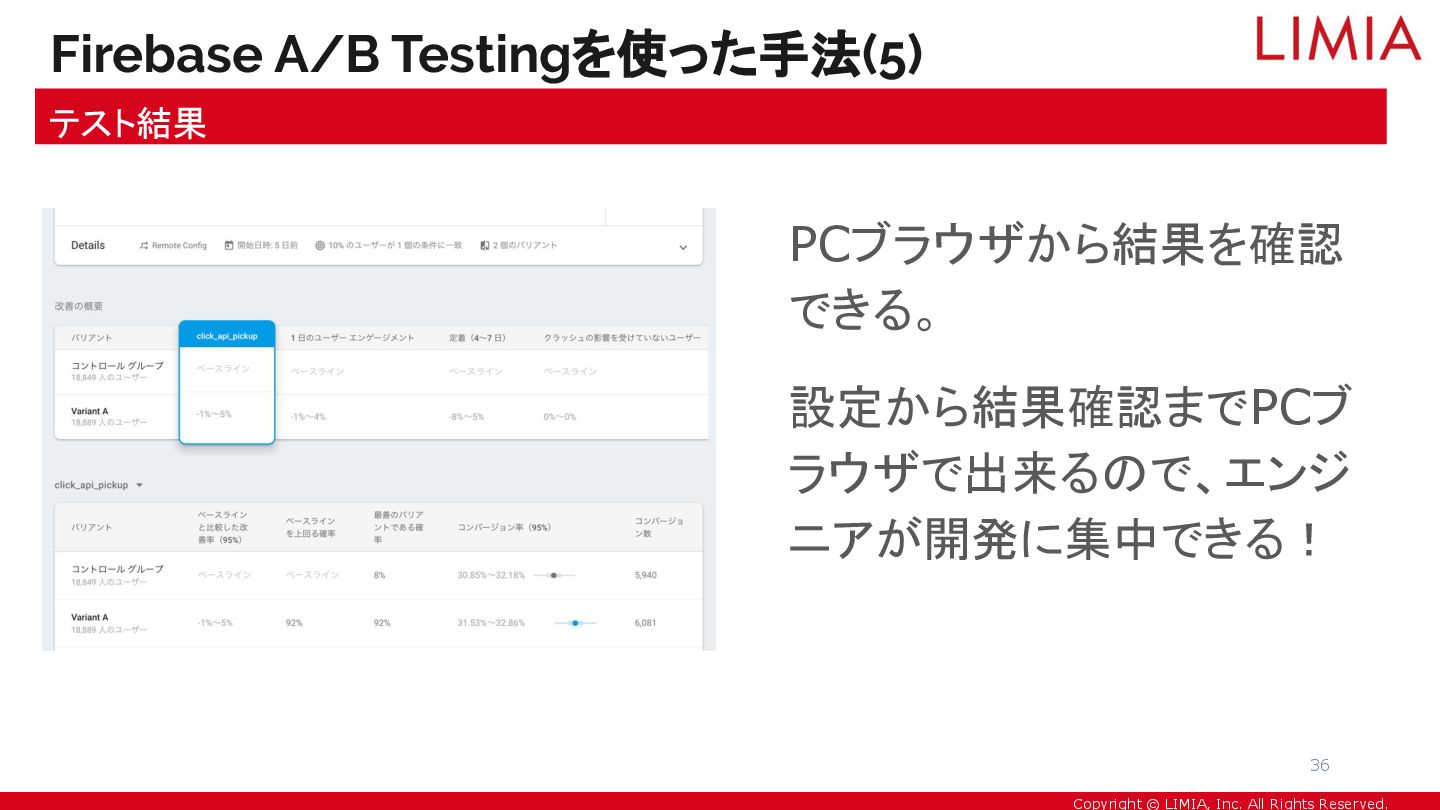
Copyright © LIMIA, Inc. All Rights Reserved. PCブラウザから結果を確認 できる。 設定から結果確認までPCブ
ラウザで出来るので、エンジ ニアが開発に集中できる! Firebase A/B Testingを使った手法(5) テスト結果 36
Copyright © LIMIA, Inc. All Rights Reserved. RemoteConfigは非同期で情報を取得する。そのため、初回アクセス時に は、A/B振り分けられた値が取得されていないケースが多い。 ここが厳密性に欠けるとの指摘を受けたため、独自実装のシステムを作った。
独自実装の方は、userIdの下二桁で分岐するやり方。 独自システムについて 37
Copyright © LIMIA, Inc. All Rights Reserved. 5.レポート
Copyright © LIMIA, Inc. All Rights Reserved. 【Firebase A/B Testing手法】
A/Bテストでどちらのセグメントに振り分 けられたか、UserPropertyに設定されま す。keyは次のようになります。 firebase_exp_<ABテスト番号> 【独自実装】 FAにsetUserId()という足が生えているの で、それで設定するとUserPropertyの user_idに設定されている。 パターン毎の集計方法 Firebase A/B Testingと独自実装 39
Copyright © LIMIA, Inc. All Rights Reserved. 6.今後の課題
Copyright © LIMIA, Inc. All Rights Reserved. • LTVと相関が強い指標を探す。特にRetentionを上げる方法。 •
ピックアップ以外でパーソナライズしたい場所があれば。他タブ、回遊導 線、プッシュ通知、検索結果など。 • BigQueryのqueryを実装するより早く分析する方法。GAのWeb+App の分析機能??? 今後の課題 Analyst領域 41
Copyright © LIMIA, Inc. All Rights Reserved. • ItemModel: word
embedding(学習データにLIMIAの記事を加える。 最新のWE手法を使う。 • ItemModel: 形態素解析の辞書をチューニング。user辞書にLIMIA記 事。neologd利用。 • UserModel: 平均 vs RNN(読んだ順序を考慮するか) • Scoring: 協調フィルタリングのScoreを作って既存に加える • Ranking: アドテクを参考にFrequency Capをかけて、興味のない記事 を掲載されずらくする • Kaggleを頑張る 今後の課題 Data Scientist領域 42
Copyright © LIMIA, Inc. All Rights Reserved. • UnitTestがほとんど無いので書く •
Data ScientistからPythonのコードが来るのに書き換えるべき? • atcorder頑張る 今後の課題 Algorithm Programmer領域 43
Copyright © LIMIA, Inc. All Rights Reserved. • エラーログ周りをなんとかする •
micro serviceとして切り出して他prjへ提供 • k8s(GKE)対応 今後の課題 ML Ops領域 44
Copyright © LIMIA, Inc. All Rights Reserved. • 論文輪読を繰り返して、最新に追いつく。 •
論文を書いて発表する。 今後の課題 Researcher領域 45
Copyright © LIMIA, Inc. All Rights Reserved. まとめ
Copyright © LIMIA, Inc. All Rights Reserved. • ユーザ体験向上のため、一覧表示のパーソナライズを行った。 •
この構成が良いと思っていないので、お気付きの点があれば指摘して欲し い。歴史が浅い分野なので、情報を共有して僕らで定石を作っていきた い。 • 機械学習prjは、様々な専門性を持つ人達を結集する必要がある。しかし 仲間が少なく、一人で複数の専門性を見ているので成長が遅い。 まとめ 47
Copyright © LIMIA, Inc. All Rights Reserved. 一緒に推薦システムを作ってくれる仲間を募集中です。 • Analyst
• Data Scientist • Algorithm Programmer • ML Ops • Researcher 興味がある方は声をかけてください! We are hiring! 48
Copyright © LIMIA, Inc. All Rights Reserved. Appendix
Copyright © LIMIA, Inc. All Rights Reserved. • 1: 書籍:推薦システム
https://www.kyoritsu-pub.co.jp/bookdetail/9784320124301 • 2: Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches https://arxiv.org/pdf/1907.06902.pdf • 参考資料 資料中の※は、以下の資料を表す。 50
Copyright © LIMIA, Inc. All Rights Reserved. 類似ユーザに人気の記事を配信することで、CTRが上がるという仮説を検証し た。 ユーザをいくつかのクラスタに分類する。
分類結果をBigQueryに送信し、クラスタ毎のCTRを集計する。 定期的に集計してストレージに格納しておき、ユーザは所属するクラスタ内で CTRが高い記事を一覧表示する。 これをPopular Modelとオフラインで比較して、既存手法とオンラインで比較し た。 失敗した手法 Segmentation Popular Model 51
Copyright © LIMIA, Inc. All Rights Reserved. LIMIAにはtwitterのようにユーザをフォローする機能がある。フォロー数が多 いほど来訪頻度が高いことが分かっている。興味のあるユーザを推薦すること でフォロー数が増えるという仮説を検証した。
BigQueryにあるフォロー情報を使ってUser x Userの行列を作る。 コサイン距離を計算するUDFを作り、類似ユーザを抽出した。自分がフォロー している人の類似ユーザや類似ユーザがフォローしていて自分がしていない人 を推薦した。 その他の推薦 UDFを使った協調フィルタリング 52
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}