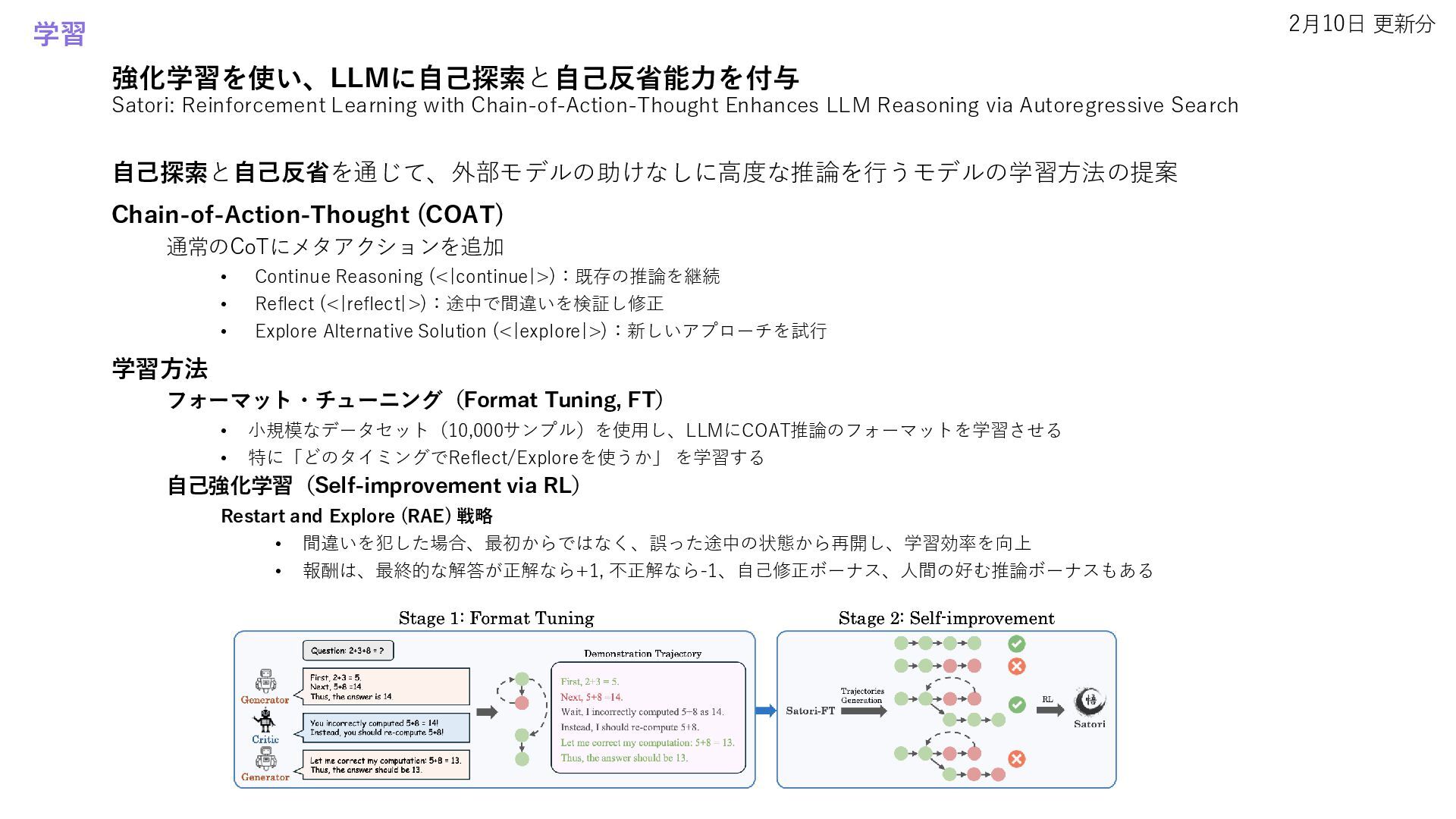
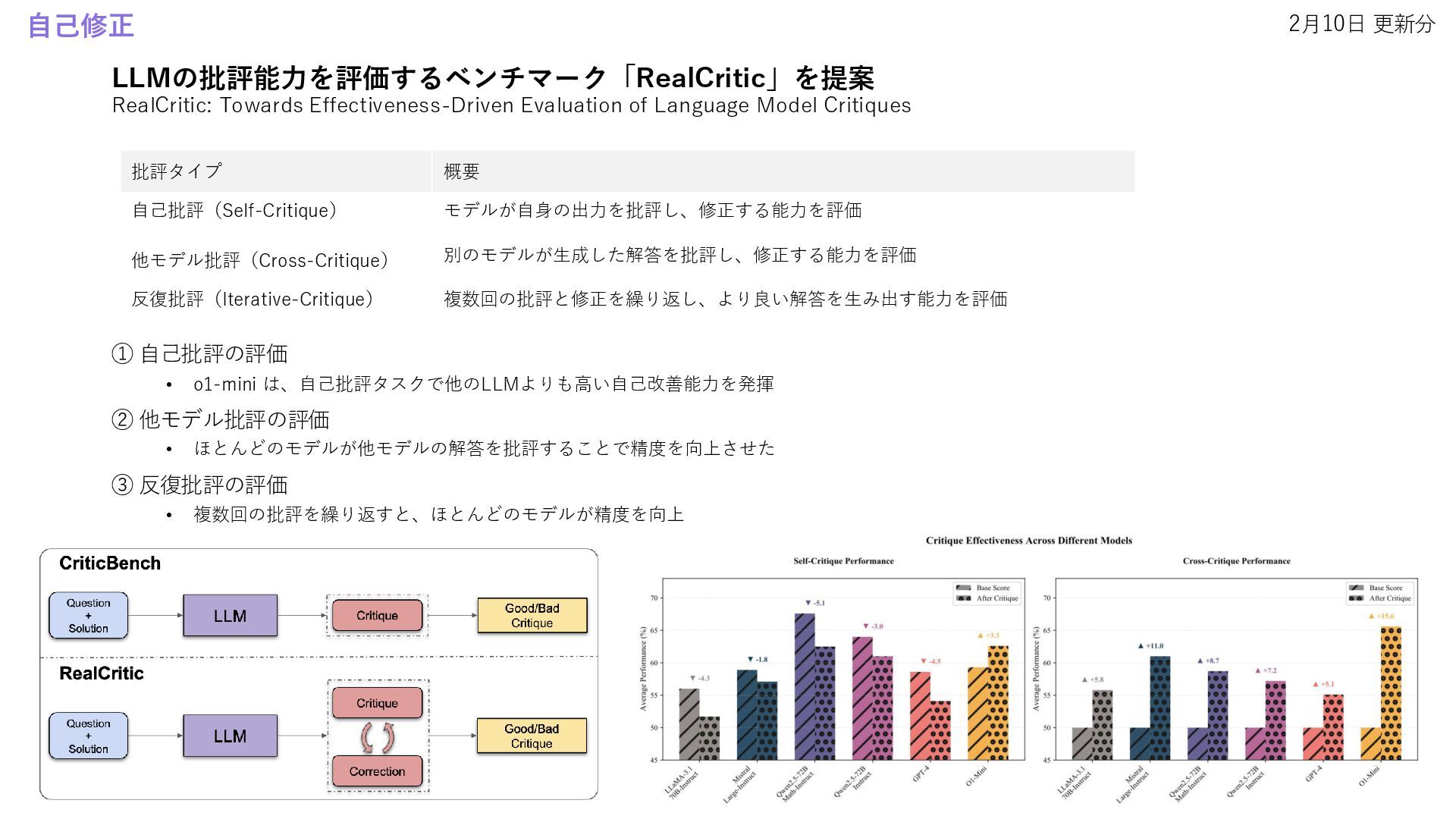
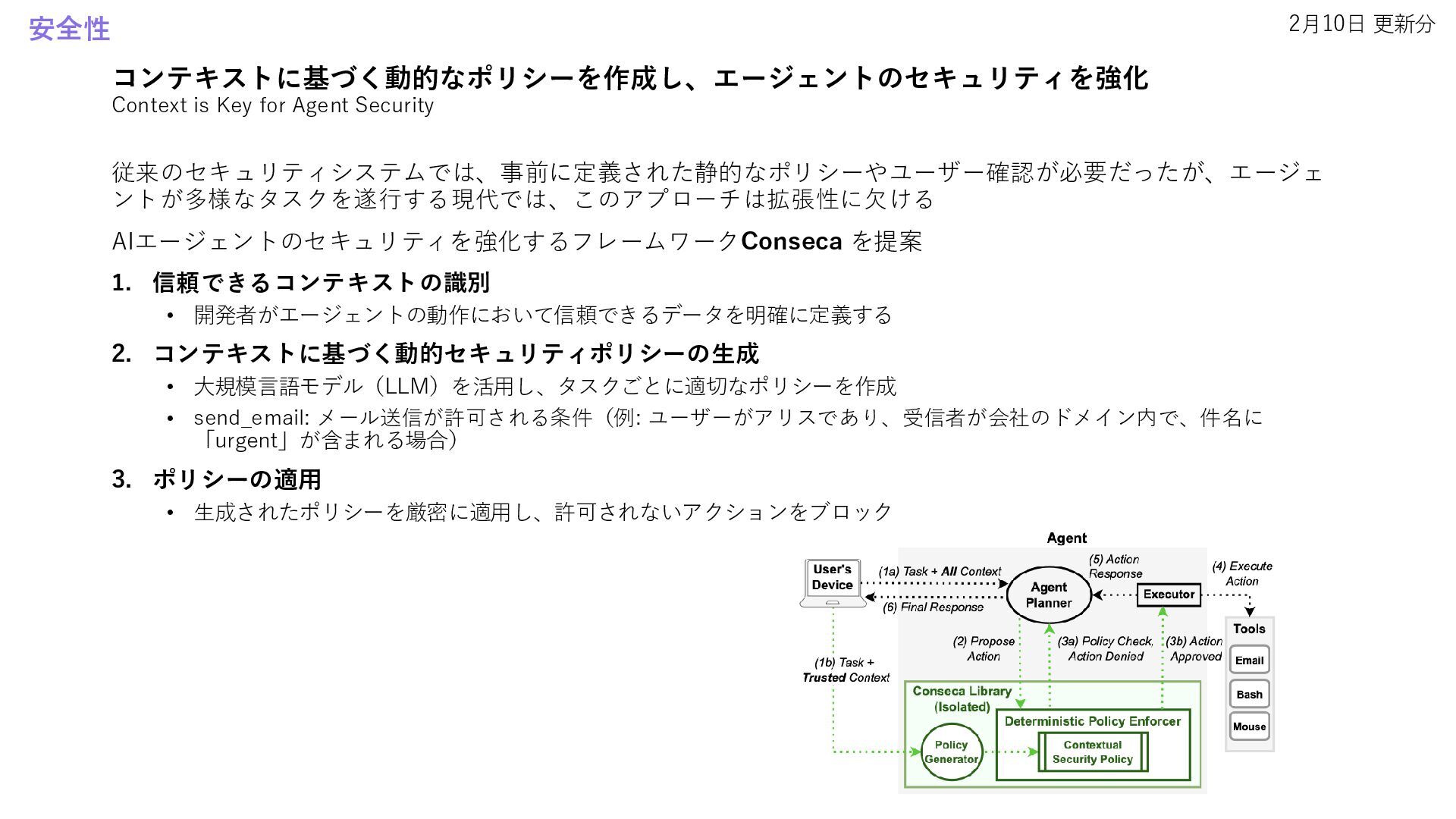
• Improving Vision-Language-Action Model with Online Reinforcement Learning • Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search 自己修正 • RealCritic: Towards Effectiveness-Driven Evaluation of Language Model Critiques • Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge 安全性 • Context is Key for Agent Security
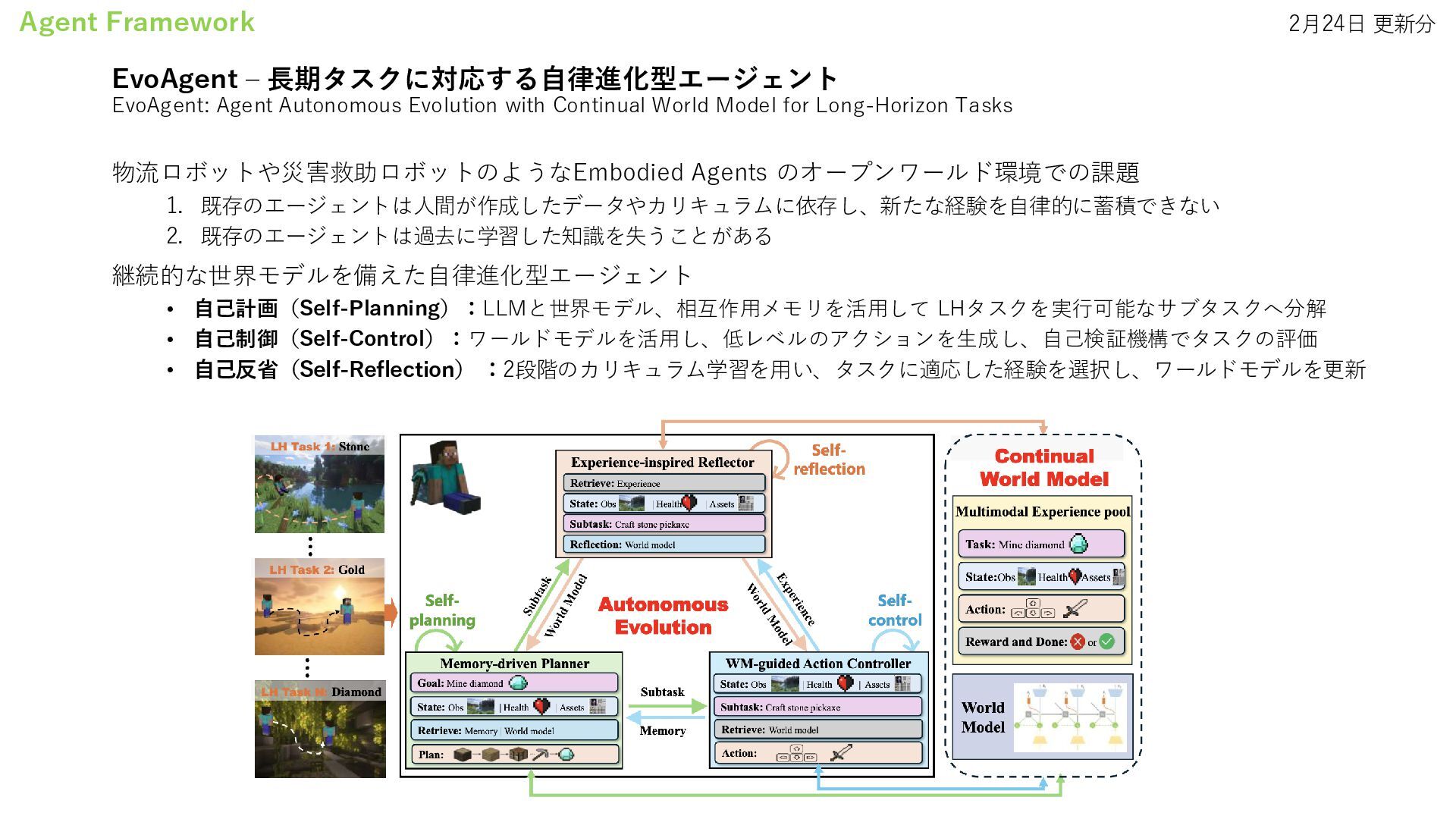
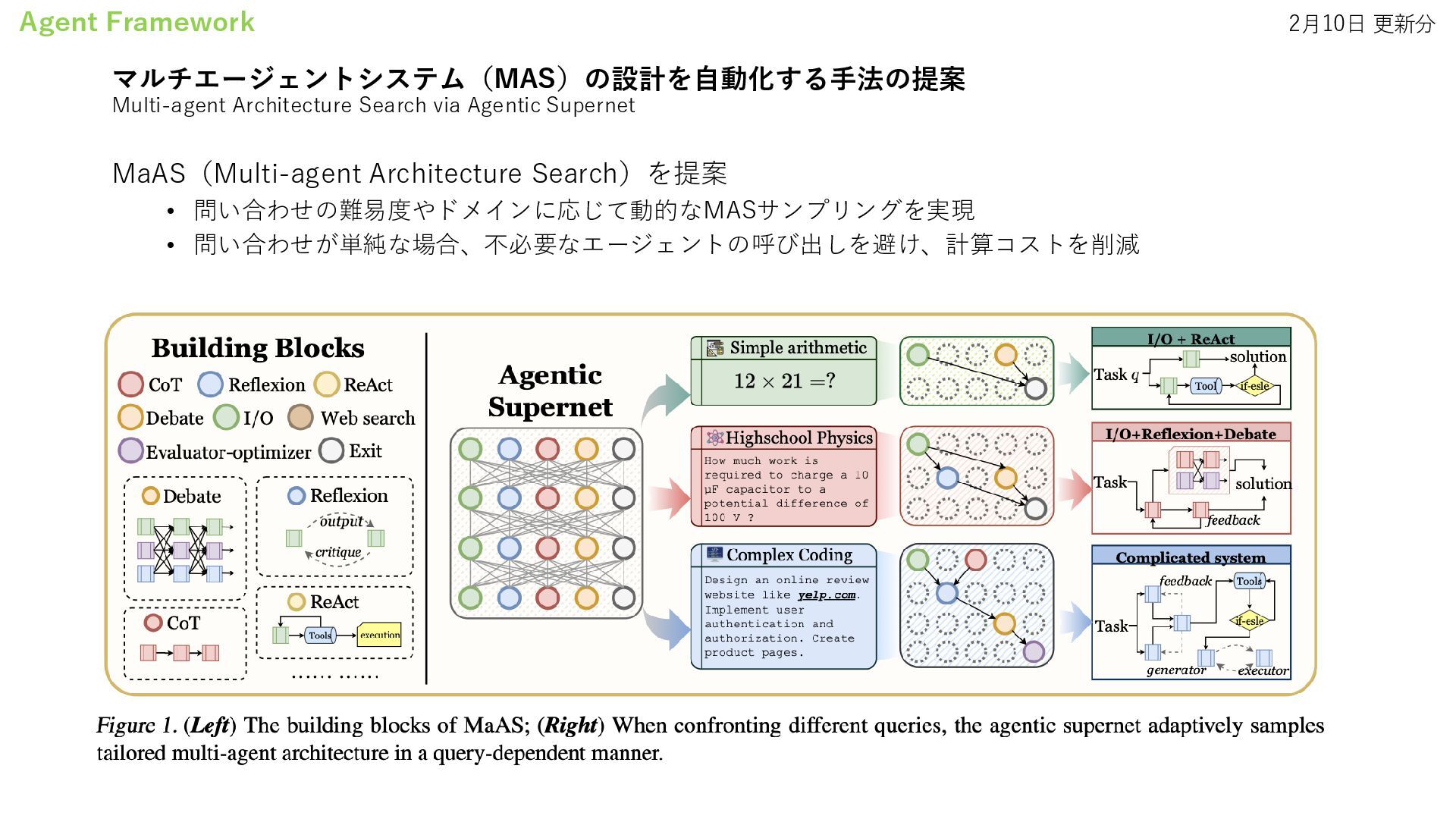
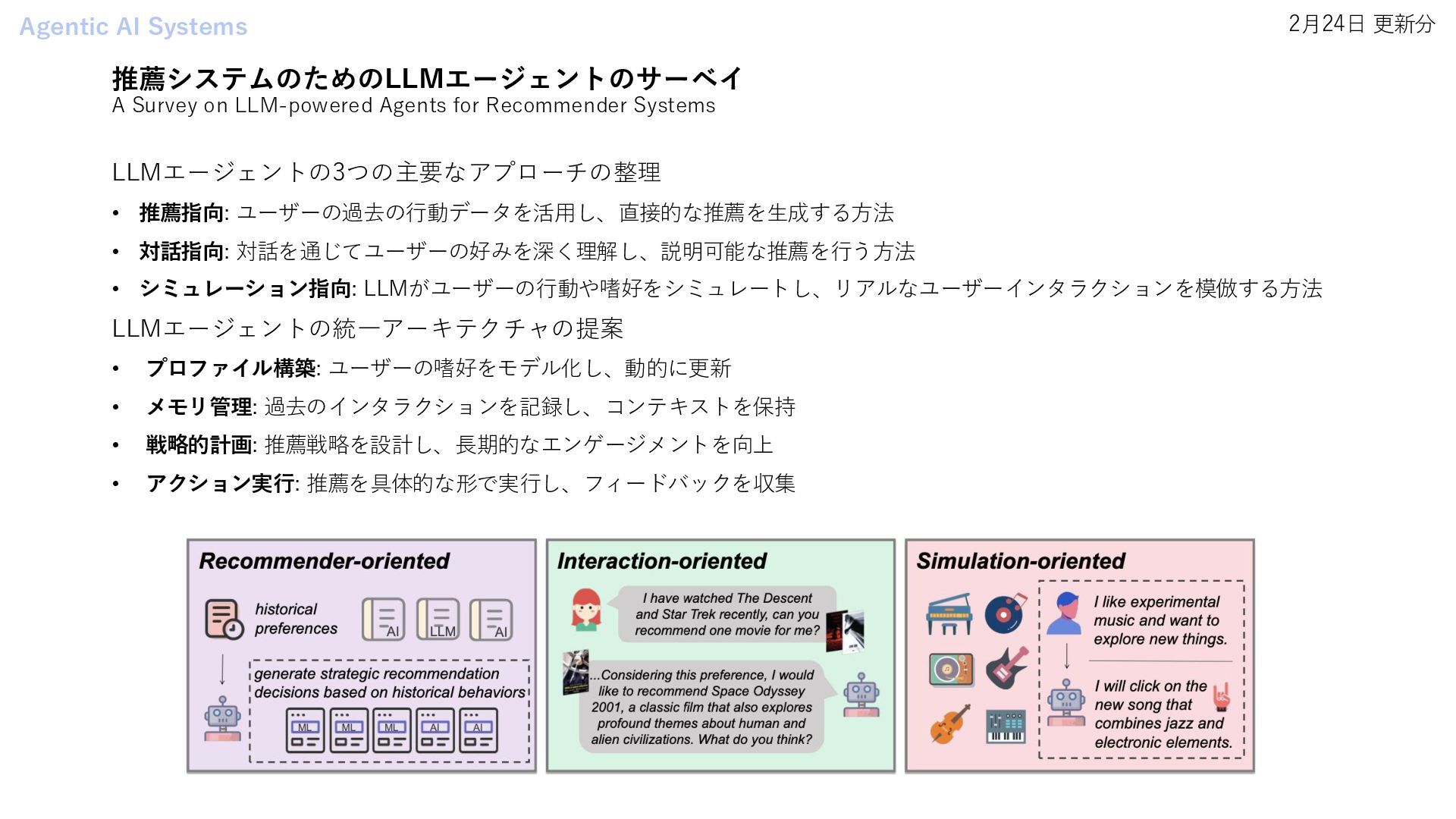
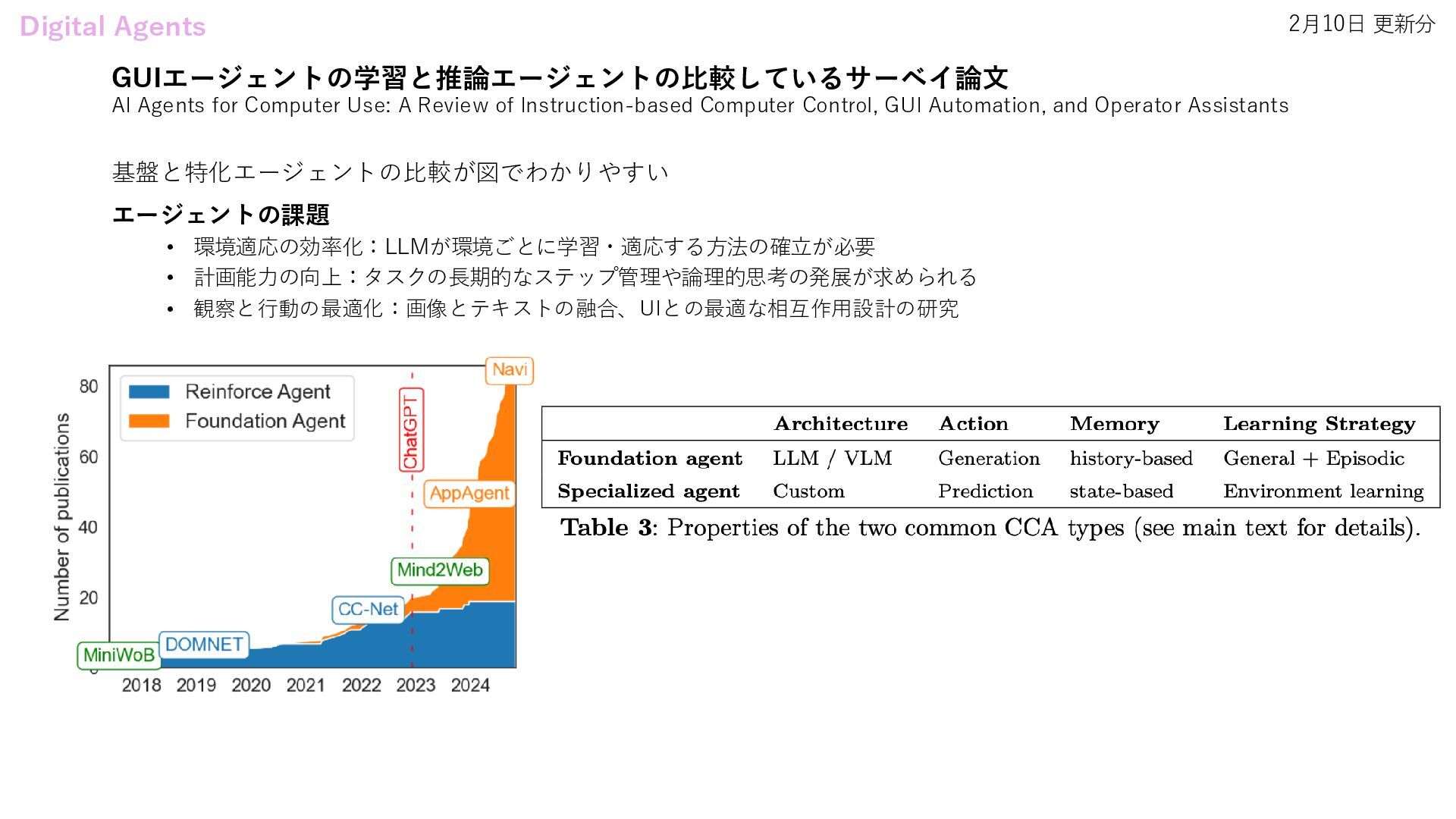
On The Fly • EvoAgent: Agent Autonomous Evolution with Continual World Model for Long-Horizon Tasks • Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research • Agency Is Frame-Dependent • Multi-agent Architecture Search via Agentic Supernet Agentic AI Systems • A Survey on LLM-powered Agents for Recommender Systems Research Agents • Towards an AI co-scientist Digital Agents • AI Agents for Computer Use: A Review of Instruction-based Computer Control, GUI Automation, and Operator Assistants Data Agents • Jupybara: Operationalizing a Design Space for Actionable Data Analysis and Storytelling with LLMs
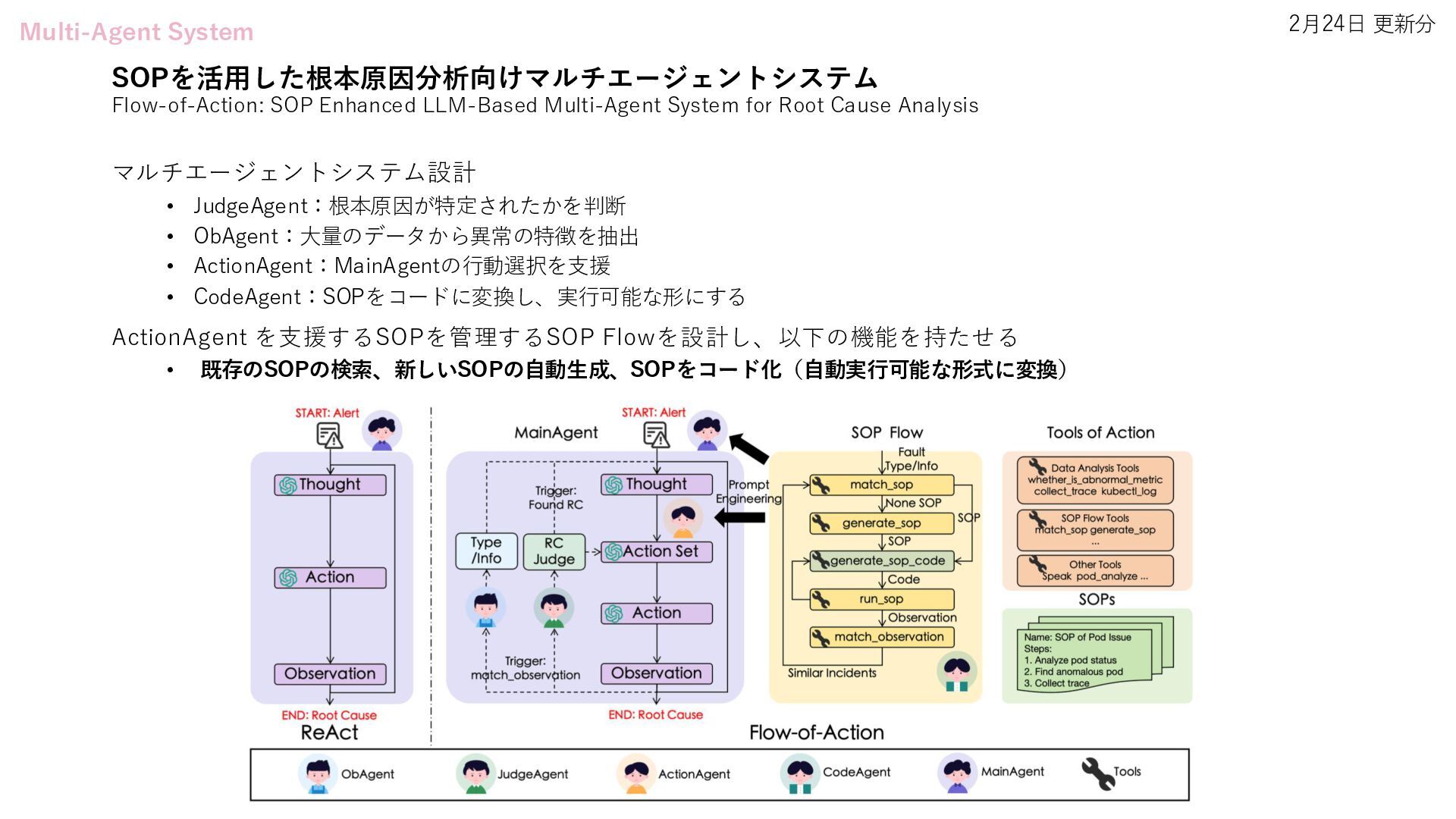
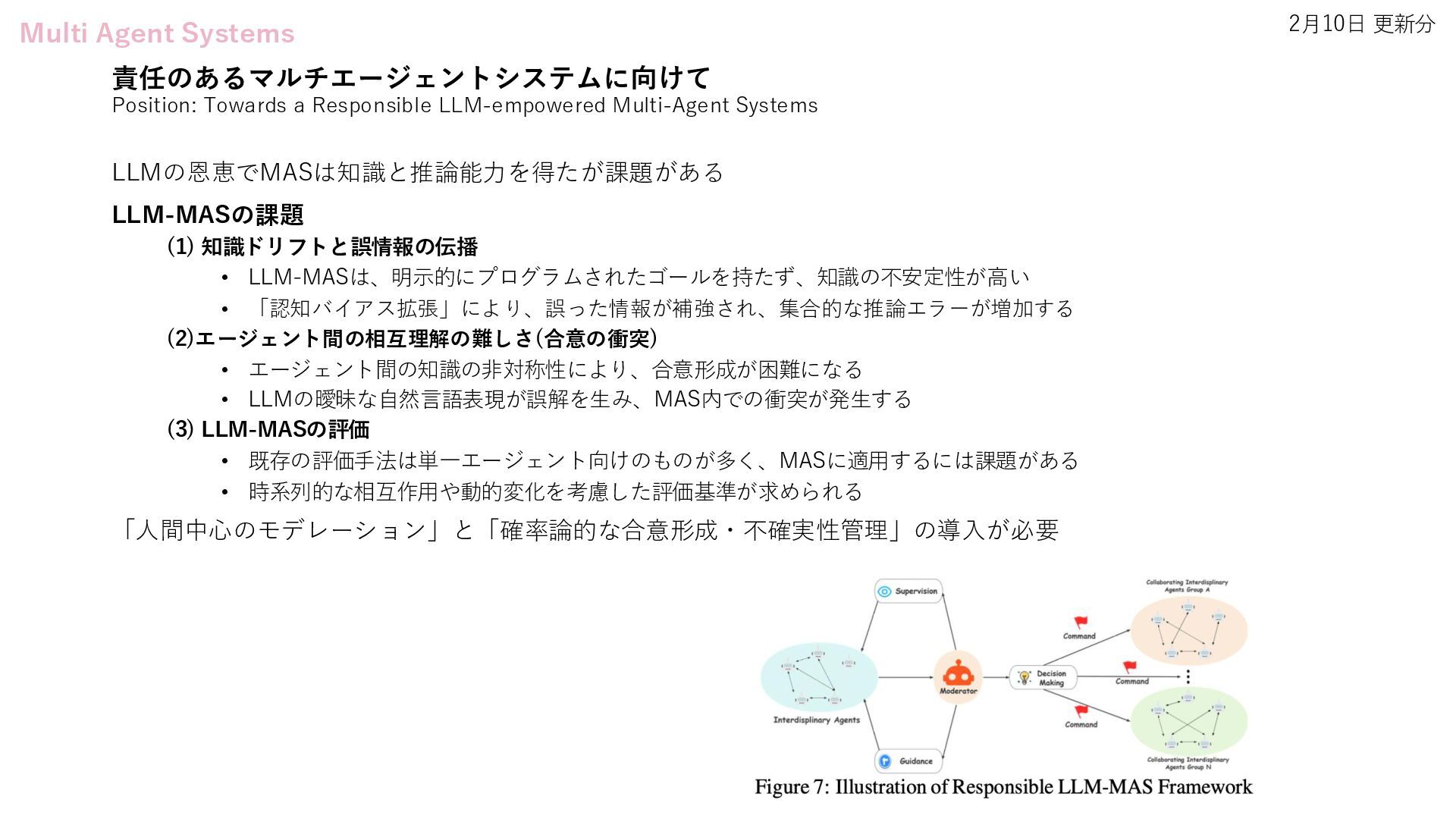
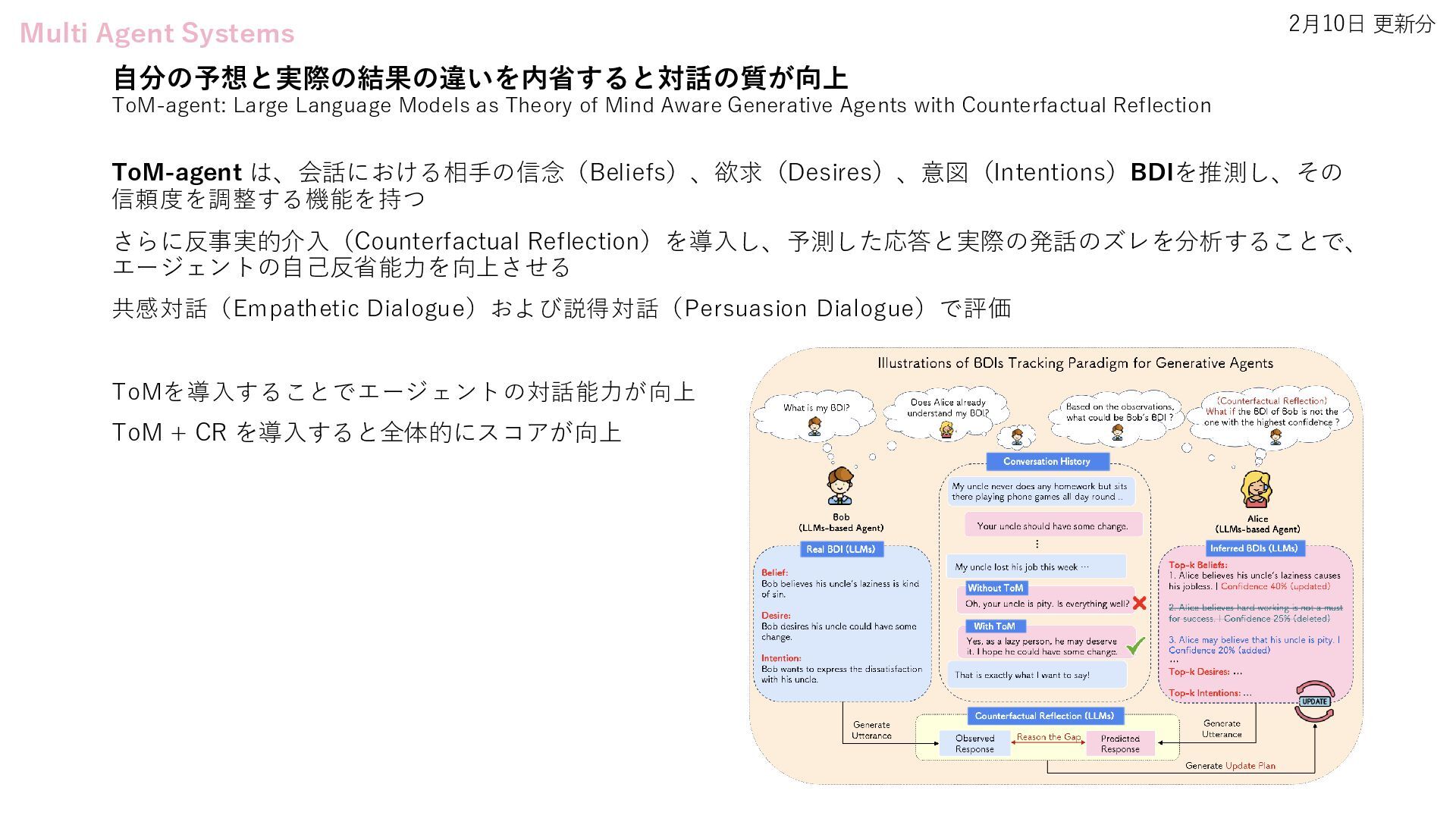
LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society • Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis • Position: Towards a Responsible LLM-empowered Multi-Agent Systems • ToM-agent: Large Language Models as Theory of Mind Aware Generative Agents with Counterfactual Reflection • Multi-Agent Geospatial Copilots for Remote Sensing Workflows
of Human Behaviors and Society シミュレーション用のLLMエージェントには認知、感情、欲求機能を持つ • 記憶、計画、意思決定機能を備え、状況に応じた社会的行動を行う 応用分野 • 日常行動、意見の極化、扇動的メッセージの拡散による炎上の再現 • ベーシックインカム(UBI)による消費増加、貧困層の精神的健康の向上、ハリケーンによる住民の移動変化 • 各種政策(税制改革、環境政策、社会福祉)の影響をシミュレーション • パンデミックや災害時の人間行動をシミュレーション • AIと人間の共存社会をシミュレーション 2月24日 更新分 Multi-Agent System
都市監視、森林保護、気候分析、農業研究などの多様なアプリケーションを統合できる 合計521のAPI関数が実装され、単一エージェントの約3倍の規模となった 都市計画、農業、エネルギー、環境、保険、防衛、不動産、物流、金融、通信 の業界で応用可能 2月10日 更新分 Multi Agent Systems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
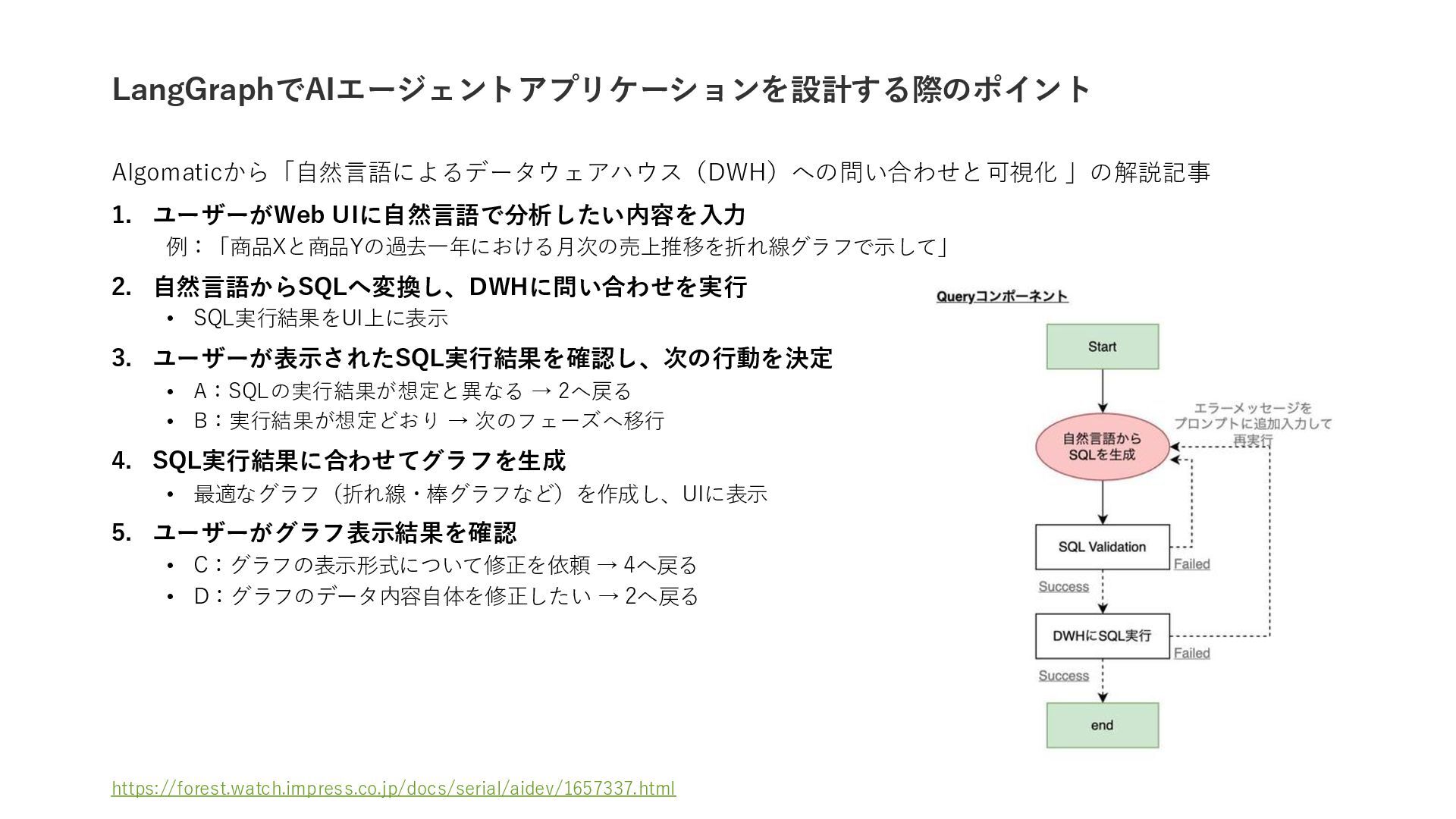{kind=link}
{kind=link}
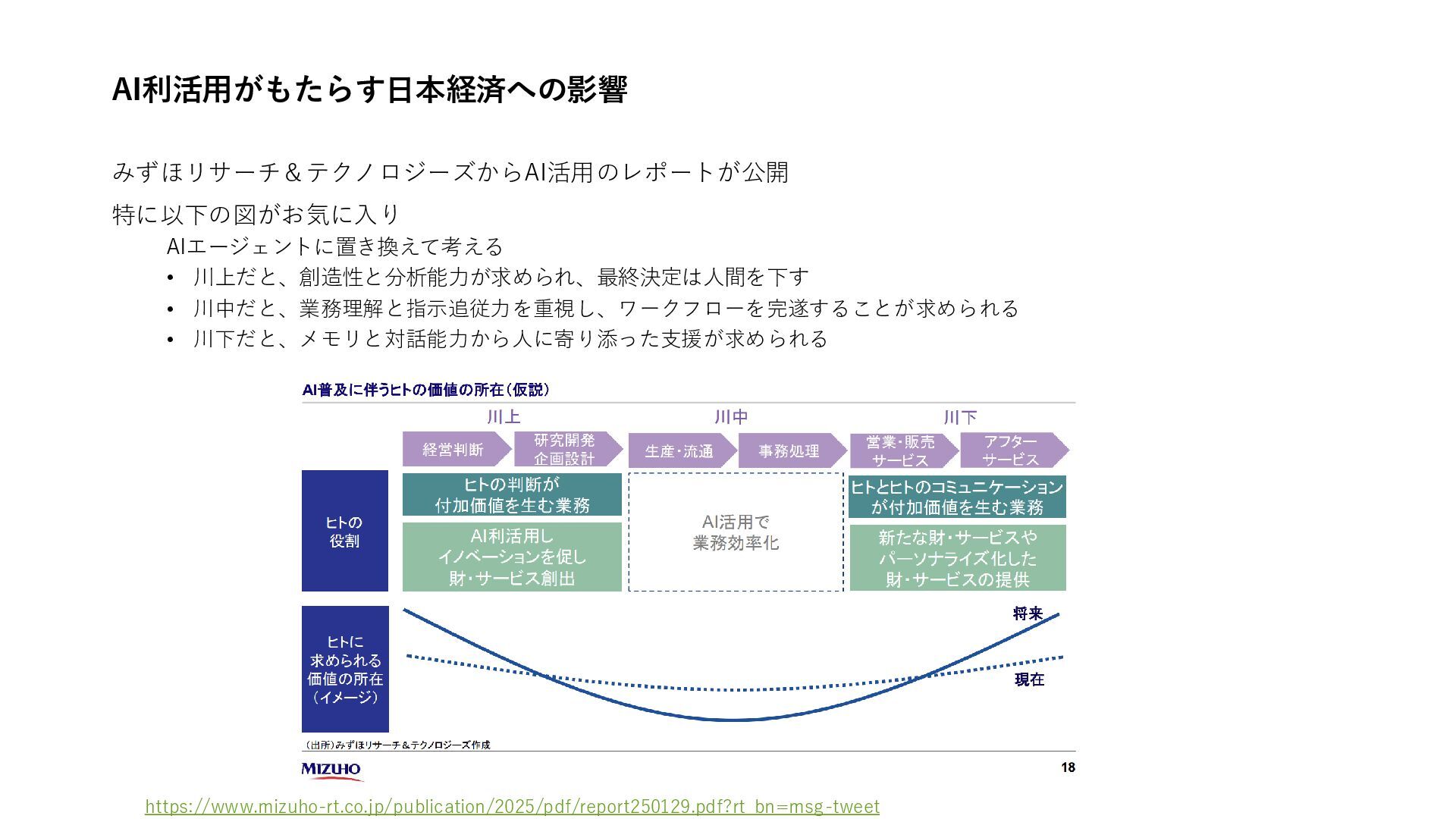{kind=link}
{kind=link}