• Multi-expert Prompting Improves Reliability, Safety and Usefulness of Large Language Models • Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization • MorphAgent: Empowering Agents through Self-Evolving Profiles and Decentralized Collaboration • AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios 計画 • ACPBench: Reasoning about Action, Change, and Planning 自己修正 • Reflection-Bench: probing AI intelligence with reflection 知覚 • IntentGPT: Few-shot Intent Discovery with Large Language Models • M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework • Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks?
of AI Self-Evolution • Adaptive Video Understanding Agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning 推論 • LLaVA-o1: Let Vision Language Models Reason Step-by-Step • Imagining and building wise machines: The centrality of AI metacognition ツール利用 • DynaSaur : Large Language Agents Beyond Predefined Actions 安全性 • Attacking Vision-Language Computer Agents via Pop-ups • World Models: The Safety Perspective • Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents • Breaking ReAct Agents: Foot-in-the-Door Attack Will Get You In 評価 • From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge 世界モデル • Evaluating World Models with LLM for Decision Making
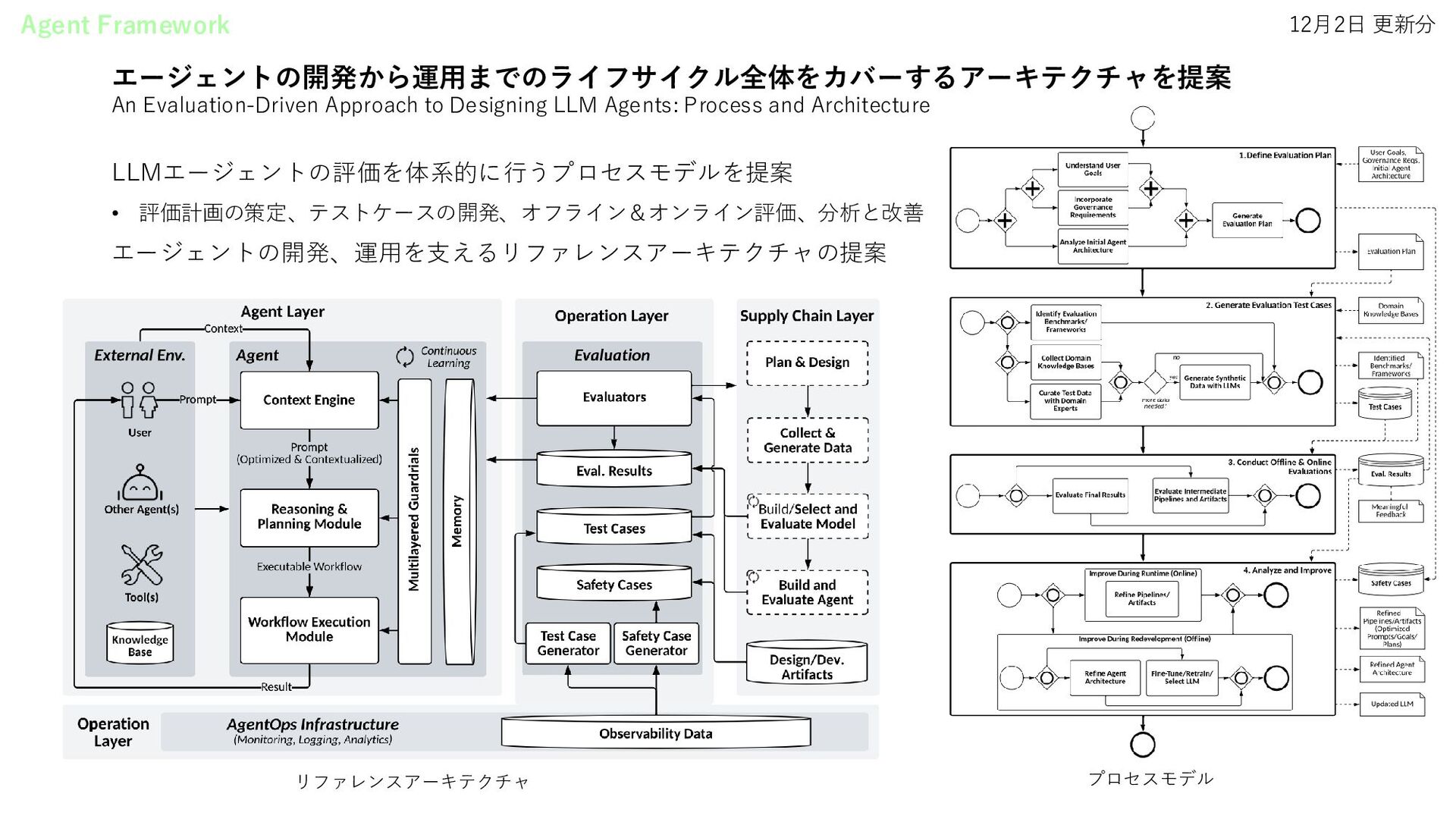
Environments (MUSE) • VipAct: Visual-Perception Enhancement via Specialized VLM Agent Collaboration and Tool-use • Aligning Generalisation Between Humans and Machines • An Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture • Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage • TapeAgents: a Holistic Framework for Agent Development and Optimization • PRACT: Optimizing Principled Reasoning and Acting of LLM Agent • Asynchronous Tool Usage for Real-Time Agents Agentic AI System • Enhancing LLMs for Power System Simulations: A Feedback-driven Multi-agent Framework • Towards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios • CRMArena: Understanding the Capacity of LLM Agents to Perform Professional CRM Tasks in Realistic Environments • Enhancing Cluster Resilience: LLM-agent Based Autonomous Intelligent Cluster Diagnosis System and Evaluation Framework • A Taxonomy of AgentOps for Enabling Observability of Foundation Model based Agents • Agents4PLC: Automating Closed-loop PLC Code Generation and Verification in Industrial Control Systems using LLM-based Agents • SceneGenAgent: Precise Industrial Scene Generation with Coding Agent • ControlAgent: Automating Control System Design via Novel Integration of LLM Agents and Domain Expertise • BENCHAGENTS: Automated Benchmark Creation with Agent Interaction
Agentic Framework with Large Language Models • Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving • WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models Research Agent • The Virtual Lab: AI Agents Design New SARS-CoV-2 Nanobodies with Experimental Validation • AAAR-1.0: Assessing AI's Potential to Assist Research Software Agent • An Empirical Study on LLM-based Agents for Automated Bug Fixing • Human-In-the-Loop Software Development Agents • A Comprehensive Survey of AI-Driven Advancements and Techniques in Automated Program Repair and Code Generation • Lingma SWE-GPT : An Open Development-Process-Centric Language Model for Automated Software Improvement Data Agent • GIS Copilot: Towards an Autonomous GIS Agent for Spatial Analysis • Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows • AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions • An LLM Agent for Automatic Geospatial Data Analysis • SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning
A Preliminary Case Study with Claude 3.5 Computer Use • ShowUI: One Vision-Language-Action Model for GUI Visual Agent • Large Language Model-Brained GUI Agents: A Survey • OS-ATLAS: A Foundation Action Model for Generalist GUI Agents • Foundations and Recent Trends in Multimodal Mobile Agents: A Survey • GUI Agents with Foundation Models: A Comprehensive Survey • Beyond Browsing: API-Based Web Agents • SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation • OSCAR: Operating System Control via State-Aware Reasoning and Re-Planning • OpenWebVoyager: Building Multimodal Web Agents via Iterative Real-World Exploration, Feedback and Optimization Embodied Agent • BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games • MindForge: Empowering Embodied Agents with Theory of Mind for Lifelong Collaborative Learning • CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation • Mr.Steve: Instruction-Following Agents in Minecraft with What-Where-When Memory
Interaction Simulations on One Million Agents • Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks • PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks • MARCO: Multi-Agent Real-time Chat Orchestration • Multi-Agent Large Language Models for Conversational Task-Solving • Project Sid: Many-agent simulations toward AI civilization • DARD: A Multi-Agent Approach for Task-Oriented Dialog Systems Agentic RAG • Boosting the Potential of Large Language Models with an Intelligent Information Assistant
System and Evaluation Framework LLMエージェントは障害を特定し、必要な修復ツールを実行し、結果から次のアクションを決定する ナレッジには250件の障害ログを問題、回答文、機能、結果の4フィールドで構造化し保存 ユースケース:GPUのクロック周波数低下により性能が1/3に低下するケース • 手動なら1時間、エージェントなら10分以内に特定し自動修復 Agentic AI Systems 11月18日 更新分
Model based Agents AgentOps: 開発、評価、運用、監視を含むDevOps/MLOpsに似 たプラットフォーム • エージェントは多様なタスクに対応可能だが、意思決定の計画 や挙動の複雑性が課題 • EUのAI法規制に対応するための観測性と追跡性の確保が必要 必要な機能(右図)ごとにドメインモデルもどきを紹介 Agentic AI Systems エージェント登録の例 11月18日 更新分
Control Systems using LLM-based Agents 自然言語による指示から産業用制御システムのPLCコード生成による制御自動化に向けたマルチエージェント Agents4PLCを提案 • コードの品質を高める役割のエージェントを特に重視 • Debugging Agent:コードのコンパイルエラーを検出し、修正のためのアドバイスを提供 • Validation Agent:構文的に正しいだけでなく、機能的にも正しいことを確認 応用例:エネルギー管理システム、製造業の生産ライン、輸送システム、プラント管理、HVAC(暖房・換気・空 調)システム、下水処理システム Agentic AI Systems 11月4日 更新分
Agents and Domain Expertise LLMと制御理論の専門知識を組み合わせた新しい制御シス テム設計フレームワークControlAgent を提案 10の制御タスクの500課題で、設計の安定性、セトリング タイム、位相余裕などの基準で評価 ControlAgentの現在は、LTIシステムに特化 Agentic AI Systems 11月4日 更新分
of Large Language Models Agentic Process Automation • 人間の指示に基づいて自律的にワークフローを生成・管理するプロセス自動化 • RPAは定型的なプロセスを自動化するが、ワークフローの設計には人間の手作業が必要で管理も大変 WorkflowLLM • 83アプリ、1,503 API、106,763サンプルを含むデータセット「WorkflowBench」を構築 • Llama-3.1-8BをWorkflowBenchで微調整し、ワークフローを生成する • 未知のAPIでも高い性能、アクション数、分岐・ループ、ネストの深さが増加しても高い性能を維持 API Agents 11月18日 更新分
Preliminary Case Study with Claude 3.5 Computer Use Claude 3.5 Computer Useは、APIベースのGUI自動化機能 Computer Useにはデスクトップ操作、ファイル編集、システム操作のツールが用意されている Web Search • 成功:Amazonで特定条件の製品を検索してカートに追加する • 失敗:認証プロセスが必要なタスクで、誤ったナビゲーションをする Workflow • 成功: GoogleスプレッドシートをエクスポートしExcelで開く、 Amazonの製品情報をExcelに記録する • 失敗:音楽アプリ内で特定の楽曲をプレイリストに追加で、スクロール操作が正確でなく、特定要素を見つけられなかった Office Productivity • 成功: Microsoft WordでレイアウトをA3サイズに変更、メールの転送とCC操作 • 失敗:履歴書テンプレートの名前と電話番号の更新で、テキスト選択が不完全で、部分的な変更のみ行われた Digital Agents 12月2日 更新分
• GUIグラウンディングとして、Set-of-Mark (SoM)を用いてスクショの該当箇所に赤枠をつけてGUI要素を特定する • タスク駆動型の再計画から失敗した特定のタスク部分のみを再計画し、再実行する • ユーザーの指示をPythonコードに変換し、OS操作を直接的に実行する 例)keyboard.write("This is a draft.") タスク成功率はGAIA:28.7% 、OSWorld:24.5% 、AndroidWorld:61.6% OSCAR Digital Agents 11月4日 更新分
Microsoft Researchから汎用的なマルチエージェントシステムMagentic-Oneを提案 • オーケストレーターが計画を立案、タスクを他の専門エージェントに割り振り、進捗を追跡 GAIA、AssistantBench、WebArenaの3つのベンチマークで競争力のある成果を達成 Multi Agent Systems 11月18日 更新分
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}