Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIで最適化を解けるか?
Search
MIKIO KUBO
March 31, 2026
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIで最適化を解けるか?
LLMや深層強化学習で組合せ最適化を解くためのアプローチと比較
MIKIO KUBO
March 31, 2026
More Decks by MIKIO KUBO
See All by MIKIO KUBO
人工知能の歴史: チューリングからエージェントスキルに至る道程}
mickey_kubo
0
78
AlgorithAlgorihms for Decision Making
mickey_kubo
0
97
エージェントスキル:自律型AIが変える最適化とサプライチェーンの未来
mickey_kubo
0
170
エージェントスキルによる最適化
mickey_kubo
2
200
Agent Skills 完全ガイド
mickey_kubo
0
160
Skill Creatorの技術設計と動作原理
mickey_kubo
0
130
AI+SCM
mickey_kubo
0
89
エージェンティック・サプライチェーン」の概念と、製造業におけるその革新的な役割について解説
mickey_kubo
0
98
MOAI Solutionの紹介 -電力最適化を中心として-
mickey_kubo
0
110
Other Decks in Research
See All in Research
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.6k
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
230
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
250
LLM Compute Infrastructure Overview
karakurist
2
1.5k
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
Claude Code × autoresearch 実践
mathbullet
0
210
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
270
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
380
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
120
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
420
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
210
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
560
Featured
See All Featured
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
380
Between Models and Reality
mayunak
4
380
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Building the Perfect Custom Keyboard
takai
2
820
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
730
The SEO identity crisis: Don't let AI make you average
varn
0
520
Building Adaptive Systems
keathley
44
3.1k
Google's AI Overviews - The New Search
badams
0
1.1k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
410
Balancing Empowerment & Direction
lara
6
1.2k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Transcript
AIで最適化を解けるか? MOAI Lab.
AIにおける古典最適化 • 制約プログラミング (CP) :数理最適化の対抗馬;パズルのよ うに離散的な問題に特化 • 使い分け:多くの連続変数を含む実務 => MIP,スケジューリ
ングや時間割 =>CP • メタヒューリスティクスをAI起源と称する場合もあり(所属す る研究分野が違うだけ) • 動的計画,強化学習,モデル予測制御などは,分野が違うだけ で本質は同じ
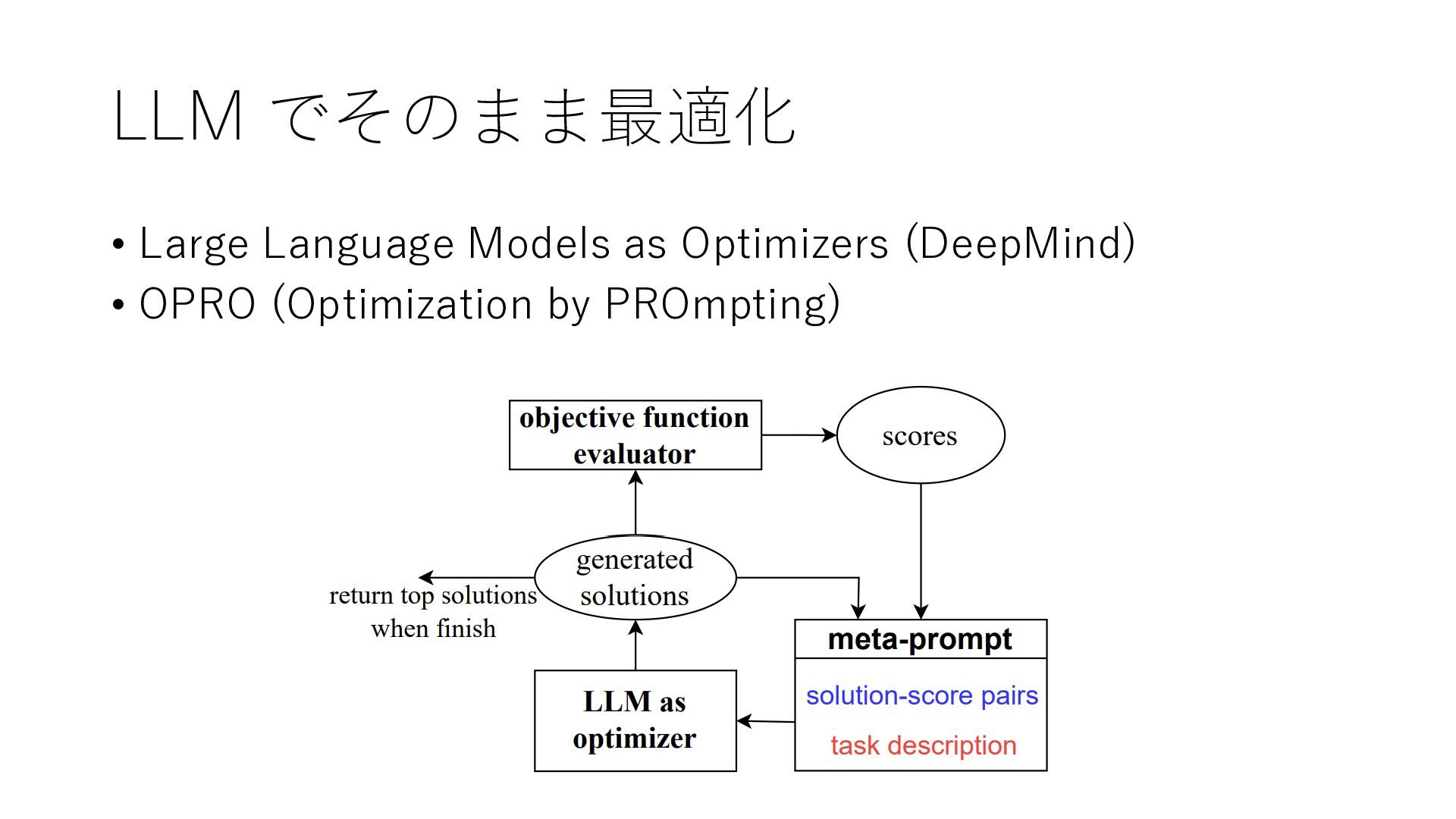
LLM でそのまま最適化 • Large Language Models as Optimizers (DeepMind) •
OPRO (Optimization by PROmpting)
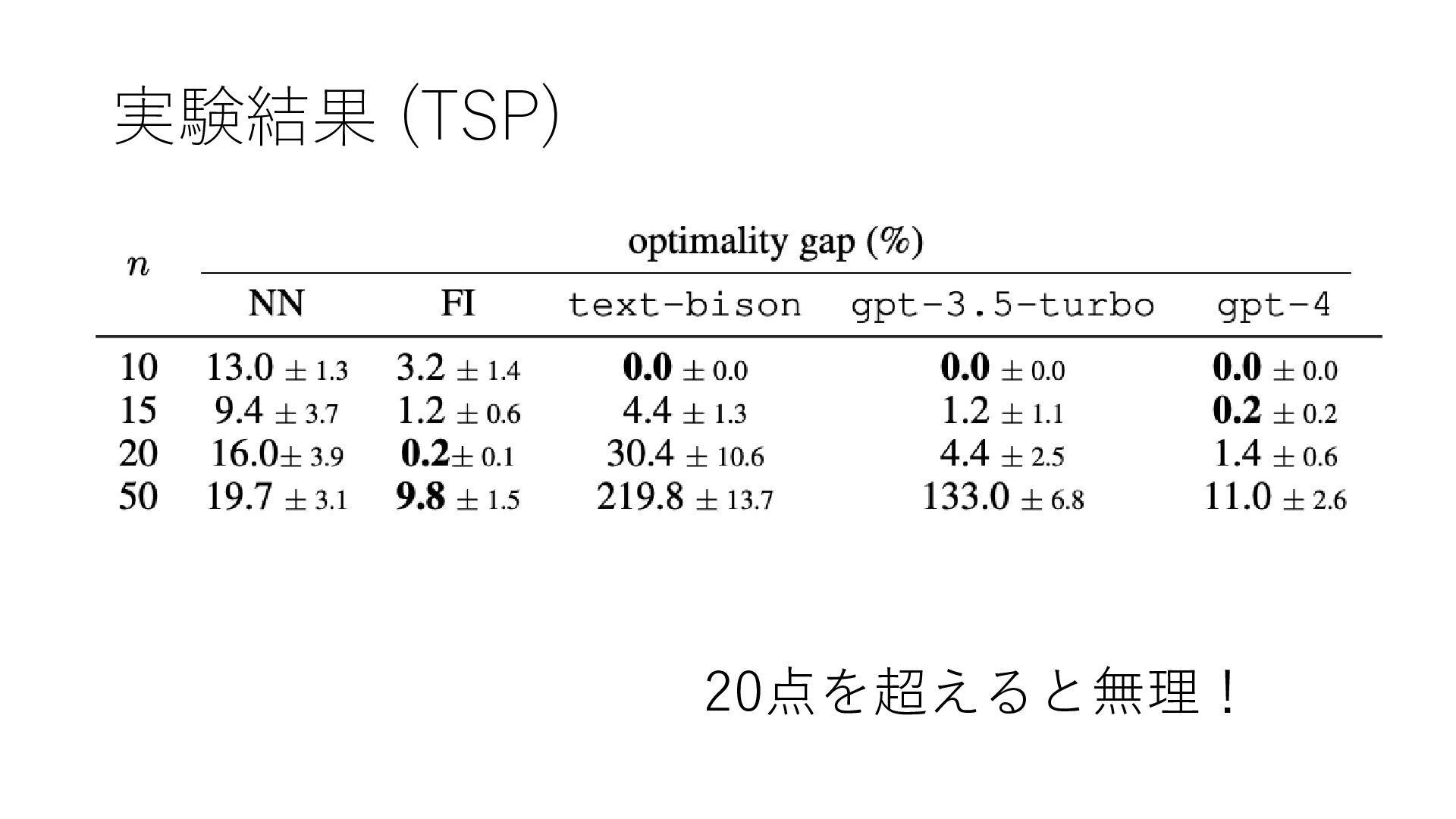
実験結果 (TSP) 20点を超えると無理!
深層強化学習 • AlphaZero (DeepMind) が有名 • Neural Combinatorial Optimizationという名前でたくさんある •
グラフをGNNやtransformerでエンコーディング,次の点への推移を当 てるデコーダーで近似解 • 一様ユークリッドのランダム問題例での実験が多い • 小さな問題例での実験が多い • 比較対象がLKHなどのSOTA解法でなく,NNやFIなどが多い • 提案手法はGPU,比較対象はCPUが多い • SOTA解法の計算時間がおかしい(提案手法の時間にあわせてある)
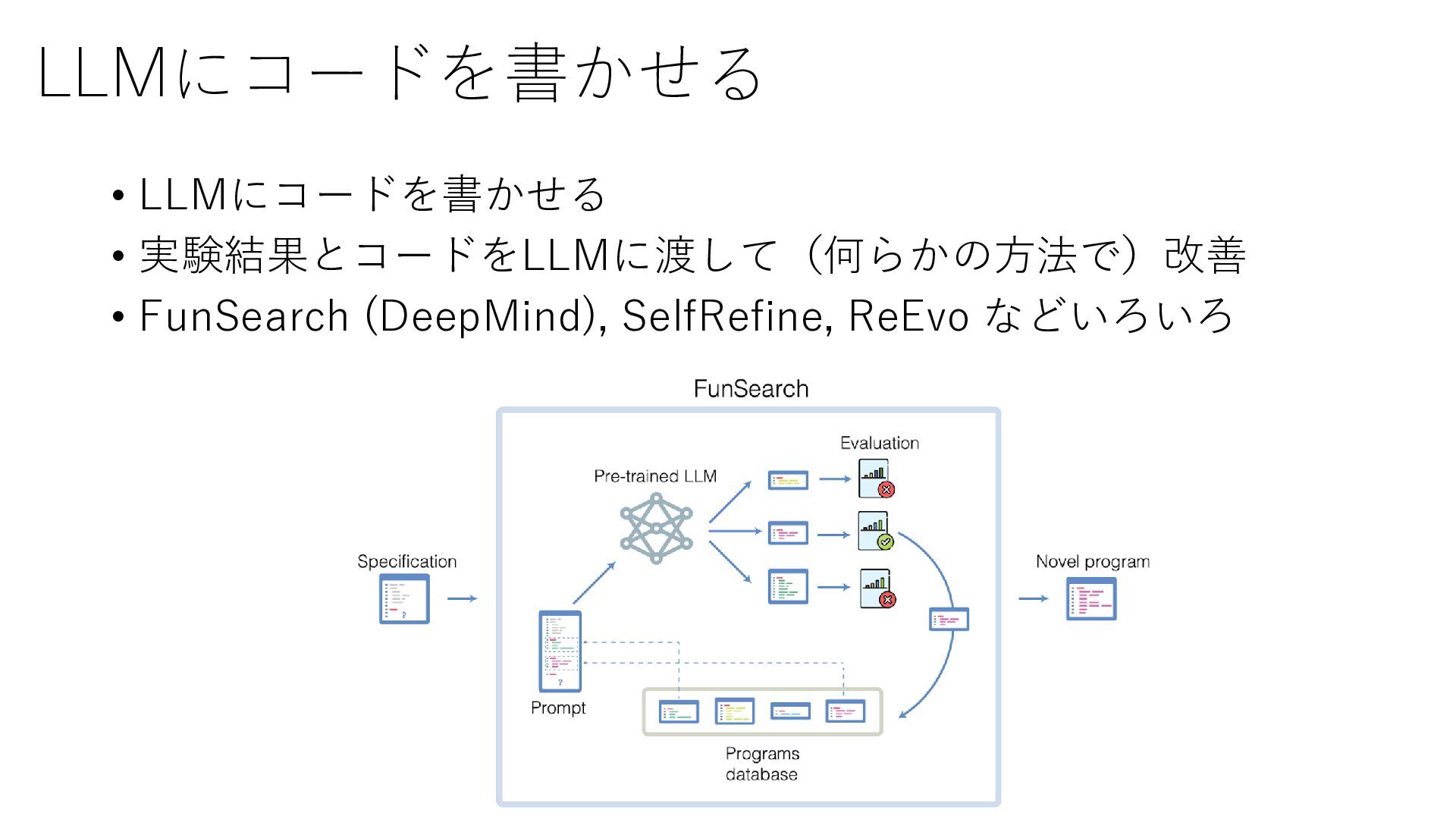
LLMにコードを書かせる • LLMにコードを書かせる • 実験結果とコードをLLMに渡して(何らかの方法で)改善 • FunSearch (DeepMind), SelfRefine, ReEvo
などいろいろ
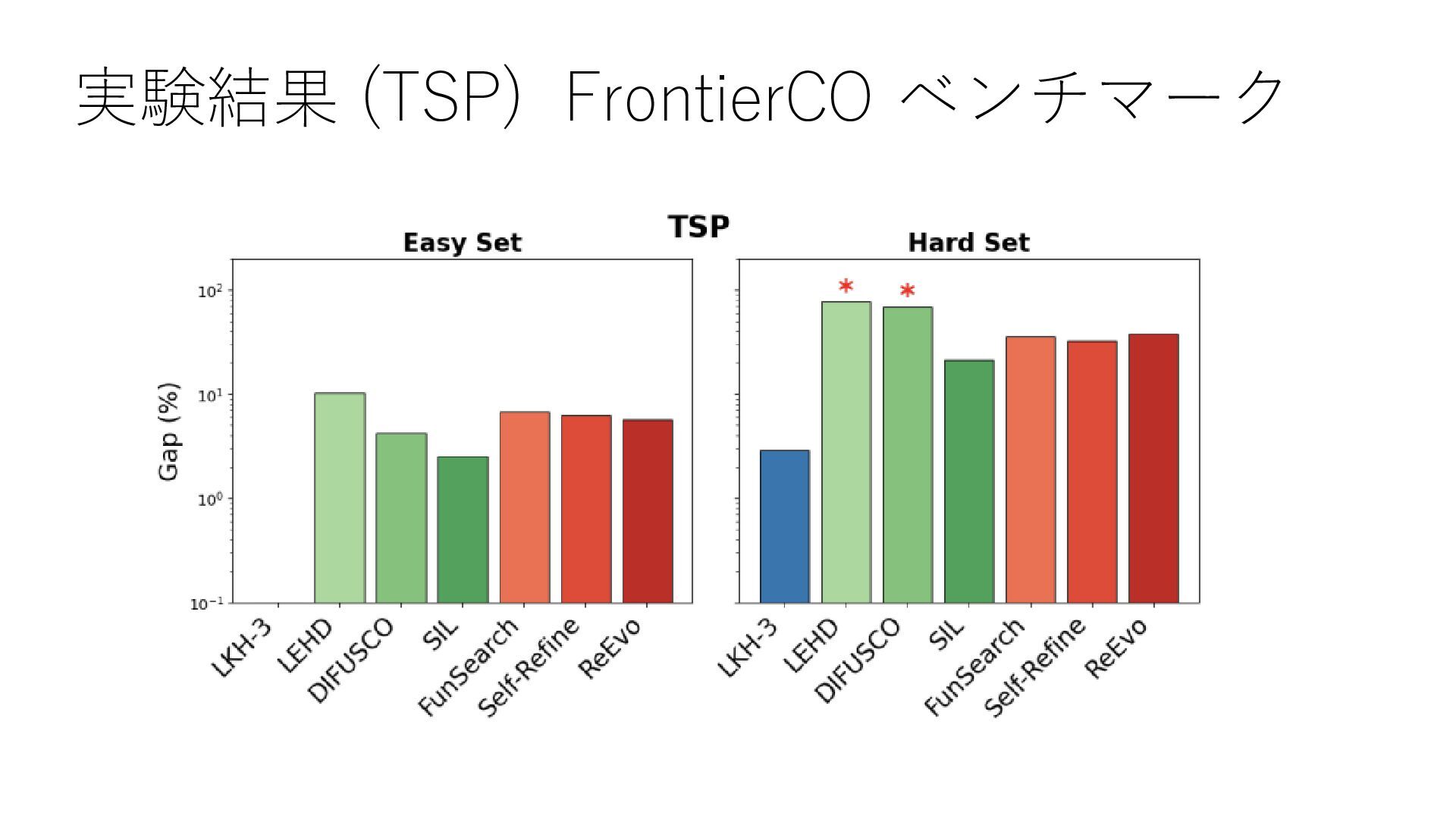
実験結果 (TSP) FrontierCO ベンチマーク
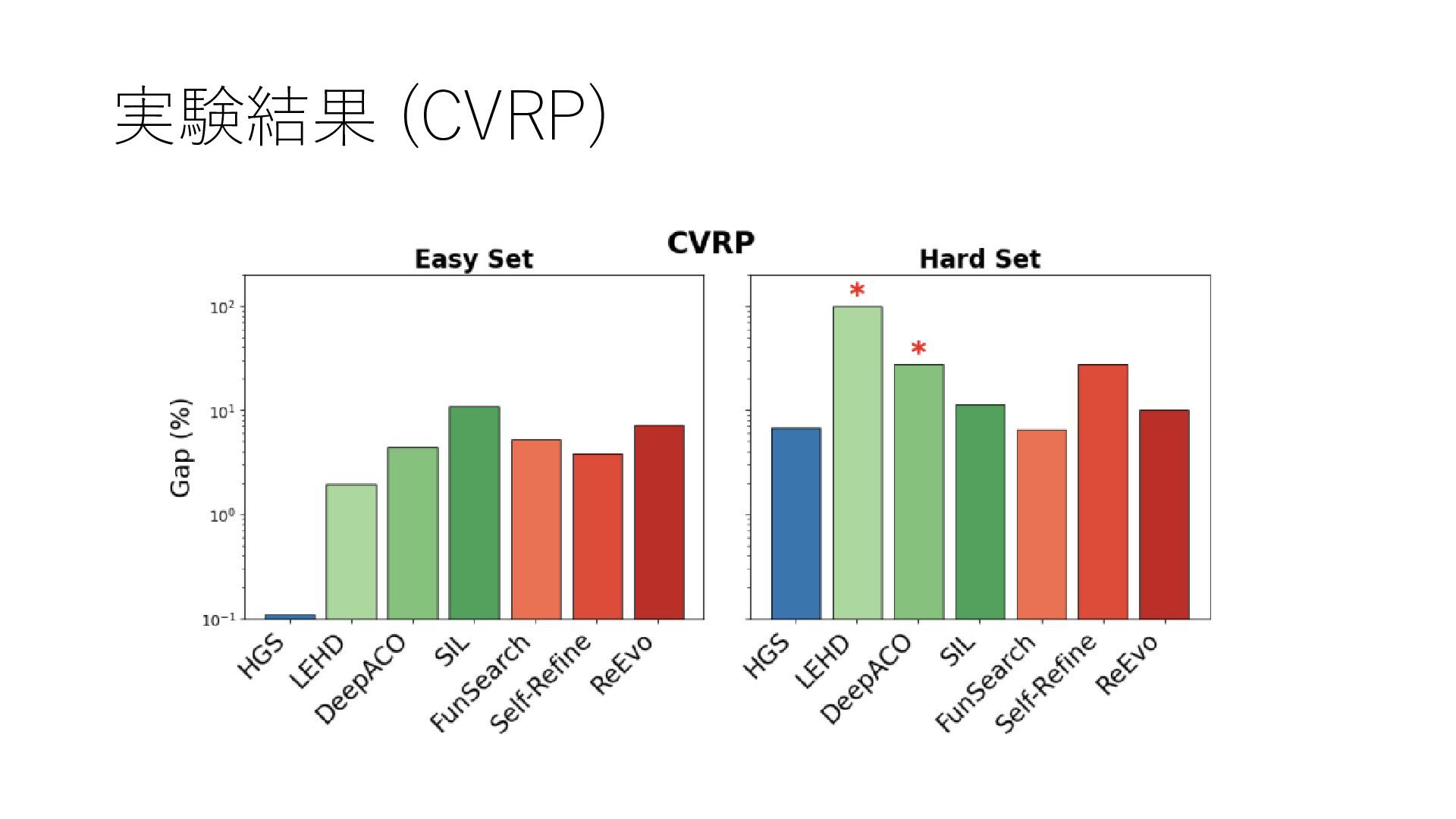
実験結果 (CVRP)
まとめ • AI は制約プログラミング (CP) だけではなくなってきている • 深層強化学習やLLMベースの研究は,実験が不十分 • 実験的解析の長い研究(1980-)を踏まえて再評価すべき
• 今のところ SOTA 解法にはかなわない • 自然言語からモデル抽出や,既存解法とLLMのハイブリッドが 正しい未来 • 過去の問題例が豊富にあれば,SOTA解法をさらに改善可能 (MOAIアプローチ)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}