Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AutoGluon 時系列予測モデルの解説
Search
MIKIO KUBO
July 09, 2025
Programming
1
150
AutoGluon 時系列予測モデルの解説
# AutoGluon 時系列予測モデルの解説
## 初学者のためのモデル動物園ガイド
MIKIO KUBO
July 09, 2025
Tweet
Share
More Decks by MIKIO KUBO
See All by MIKIO KUBO
機械学習と数理最適化の融合 (MOAI) による革新
mickey_kubo
1
320
なぜ今最適化か?Agentic AI 時代に最適化 が必要な理由
mickey_kubo
1
36
Agentic AI Era におけるサプライチェーン最適化
mickey_kubo
0
42
最適化向けLLMベンチマークの潮流
mickey_kubo
2
380
Agentic AI による新時代の IBP (Intelligent Business Planning) (配布用)
mickey_kubo
0
100
Agentic AI による新時代の IBP (Intelligent Business Planning) 改訂版
mickey_kubo
2
35
Agentic AI による新時代の IBP (Intelligent Business Planning)
mickey_kubo
1
150
API、HTTP、Webhookの初学者向け完全ガイド
mickey_kubo
0
28
Connecting Theory and Practice V
mickey_kubo
0
21
Other Decks in Programming
See All in Programming
為你自己學 Python - 冷知識篇
eddie
1
350
モバイルアプリからWebへの横展開を加速した話_Claude_Code_実践術.pdf
kazuyasakamoto
0
330
testingを眺める
matumoto
1
140
時間軸から考えるTerraformを使う理由と留意点
fufuhu
16
4.8k
そのAPI、誰のため? Androidライブラリ設計における利用者目線の実践テクニック
mkeeda
2
310
Introducing ReActionView: A new ActionView-compatible ERB Engine @ Rails World 2025, Amsterdam
marcoroth
0
690
Android端末で実現するオンデバイスLLM 2025
masayukisuda
1
150
go test -json そして testing.T.Attr / Kyoto.go #63
utgwkk
3
310
AI時代のUIはどこへ行く?
yusukebe
18
8.9k
今だからこそ入門する Server-Sent Events (SSE)
nearme_tech
PRO
3
230
デザイナーが Androidエンジニアに 挑戦してみた
874wokiite
0
470
Navigating Dependency Injection with Metro
zacsweers
3
960
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
330
21k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
8
920
Context Engineering - Making Every Token Count
addyosmani
3
48
Build The Right Thing And Hit Your Dates
maggiecrowley
37
2.9k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
36
2.5k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.4k
How GitHub (no longer) Works
holman
315
140k
The World Runs on Bad Software
bkeepers
PRO
70
11k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
53
2.9k
The Power of CSS Pseudo Elements
geoffreycrofte
77
6k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
126
53k
RailsConf 2023
tenderlove
30
1.2k
Transcript
AutoGluon 時系列予測モデルの解説 初学者のためのモデル動物園ガイド 1
1. はじめに - AutoGluon Time Series とは? Amazon が開発したオープンソースのマルチモーダルAutoML ライブラリ
目的: 最小限のコードで、時系列予測を含む多様なタスクに対し、最先端モデルを自動で選択・訓練し、 最高のパフォーマンスを達成する。 利点: 複雑なモデル選択やハイパーパラメータチューニングから解放され、誰でも強力な予測モデルを構 築できる。 2
中心的なクラスとワークフロー TimeSeriesDataFrame : AutoGluon専用のデータ構造。 必須列: item_id , timestamp , target
。 パネル時系列として扱い、各時系列を個別に予測。 TimeSeriesPredictor : 予測モデルの訓練、選択、予測生成を担う。 prediction_length : 予測期間の長さを指定。 fit() : モデルの訓練。 predict() : 将来の値の予測。 3
AutoGluon の設計思想 「迅速なプロトタイピング」と「高度なカスタマイズ」の両立 自動化の恩恵: デフォルトで、内部検証で最高スコアのモデル(通常は WeightedEnsemble )を自動選択。 初心者でもすぐに高性能なモデルを利用可能。 詳細な制御: hyperparameters
引数で、訓練するモデルやそのパラメータを自由に指定・上書き可能。 モデルの内部が「ブラックボックス」ではなく、習熟度に応じて深いレベルでの制御が可能。 学習曲線に配慮した、初心者から専門家まで使える設計。 4
2. AutoGluon モデルの全体像 AutoGluonは、多様な時系列予測の要件に応えるため、幅広いモデルを提供しています。 モデルの主要カテゴリ ベースラインモデル (Baseline Models): 性能評価の基準。 統計モデル
(Statistical Models): 伝統的な時系列分析手法。 スパースデータ用統計モデル (Statistical Models for Sparse Data): ゼロが多い間欠需要データに特 化。 深層学習モデル (Deep Learning Models): 複雑なパターンを学習。 表形式モデル (Tabular Models): 時系列問題を表形式に変換。 事前学習済みモデル (Pretrained Models): ゼロショット予測やファインチューニングが可能。 5
3. 各モデルの詳細解説 6
【ベースラインモデル】 NaiveModel & SeasonalNaiveModel NaiveModel ( ナイーブモデル) コンセプト: 「明日も今日と同じ」。直前の観測値を予測値とする。 強み:
非常にシンプル、高速。安定したデータの短期予測や初期ベンチマークに。 弱み: トレンドや季節性を全く考慮しない。精度が低いことが多い。 SeasonalNaiveModel ( 季節ナイーブモデル) コンセプト: 「来年の1月も今年の1月と同じ」。同じ季節の最後の観測値を予測値とする。 強み: 明確な季節性を持つデータに有効。 弱み: 季節性以外のトレンドや不規則な変動は捉えられない。 7
【ベースラインモデル】 AverageModel , SeasonalAverageModel , ZeroModel AverageModel ( 平均モデル) コンセプト:
履歴データの平均値を予測値とする。 ユースケース: トレンドや季節性がなく、平均値の周りを変動するデータに。 SeasonalAverageModel ( 季節平均モデル) コンセプト: 同じ季節の履歴データの平均値を予測値とする。 ユースケース: 季節内の異常値の影響を緩和したい場合に有効。 ZeroModel ( ゼロモデル) コンセプト: 常に0を予測する。 ユースケース: ほぼ全ての値が0であるような、極端にスパースなデータの理論的ベースラインとし て。 8
【統計モデル】AutoETSModel ( 指数平滑化) コンセプト: 時系列を「Error(誤差)」「Trend(トレンド)」「Seasonality(季節性)」の3要素に分解して予 測。 AutoETS : 最適なETSモデルの構成(加法的/乗法的など)を自動で選択。 強み:
明確なトレンドと季節性を持つデータに非常に効果的。 モデルが直感的で解釈しやすい。 弱み: 複数の季節性や複雑な外部要因への対応は困難。 ユースケース: 季節変動が顕著な製品の需要予測、気象データの予測など。 9
【統計モデル】AutoARIMAModel ( 自己回帰和分移動平均) コンセプト: 過去の値(AR)、過去の誤差(MA)、差分(I)の3要素で将来を予測。差分により非定常データ (トレンド等を持つ)も扱える。 AutoARIMA : 最適なパラメータ(p,d,q)を自動で選択。 強み:
トレンドを持つ非定常データもモデル化可能。 短期予測で優れた性能を発揮。 弱み: 長期予測には不向き(誤差が蓄積)。 非線形なパターンや外部要因を直接扱えない。 ユースケース: 安定したトレンドを持つ短期的な経済指標や金融データの予測。 10
【スパースデータ用統計モデル】CrostonModel コンセプト: ゼロが多い「間欠需要」に特化。需要を2つに分解して予測。 i. 需要の発生間隔 (いつ発生するか) ii. 需要の量 (発生した場合の量はいくつか) 特徴:
SBA (Syntetos-Boylan Approximation) バリアントをデフォルト採用し、オリジナルのバイアスを補 正。 強み: 間欠需要データに対し、汎用モデルより高い精度を発揮。 弱み: 連続的な需要データには不向き。 ユースケース: スペアパーツ、修理部品、新製品など、需要が不定期に発生するアイテムの在庫管理。 11
【深層学習モデル】DeepARModel コンセプト: RNNベースの自己回帰モデル。複数の関連する時系列から共通パターンを学習し、個々の予 測精度を向上。 特徴: 確率的予測: 点予測だけでなく、予測の不確実性(分位数)を予測可能。 共変量サポート: 静的特徴や既知の共変量を活用できる。 強み:
高い予測精度。 多数の時系列から学習するため、データが少ない時系列にも有効。 弱み: 訓練に高い計算リソースと時間が必要。 比較的多くのデータ(または多くの時系列)が必要。 ユースケース: 大規模な製品需要予測(数千〜数万SKU)、リソース使用量予測など。 12
【深層学習モデル】TemporalFusionTransformerModel (TFT) コンセプト: LSTMとTransformerを組み合わせた、非常に強力なアーキテクチャ。 特徴: 高い精度: 多くのベンチマークで最高レベルの性能。 豊富な共変量サポート: 静的、既知、過去の全ての共変量を効果的に活用。 モデルの解釈性:
予測の根拠を理解しやすい。「なぜ」その予測になったかが分かる。 強み: 複雑な外部要因(休日、プロモーション等)を考慮した高精度な予測が可能。 弱み: 計算コストが高い。 訓練データにない極端なパターンへの対応は困難。 ユースケース: 小売の需要予測、金融市場予測など、精度と解釈性が共に重要なシナリオ。 13
【深層学習モデル】PatchTSTModel コンセプト: Transformerアーキテクチャを時系列予測に応用。 時系列を「パッチ」と呼ばれる小さなセグメントに分割し、Transformerで処理。 特徴: Transformerにより、シーケンス内の長期的な依存関係を効率的に捉える。 強み: 非常に長い時系列や、長期依存関係が重要なデータに有効。 弱み: 計算コストが高く、大量のデータが必要な場合がある。
ユースケース: 気候データ、大規模なセンサーネットワークデータなど、長期的なパターンが重要な予測。 14
【表形式モデル】DirectTabularModel コンセプト: 時系列予測の問題を「表形式の回帰問題」に変換。 ラグ特徴量(過去の値)、 時間特徴量(曜日、月など)、 共変量などを特徴量としてテーブルを作 成。 AutoGluon-Tabularの強力なモデル(LightGBMなど)で予測。 アプローチ: Direct:
全ての未来の時点を「同時に」予測。 強み: 豊富な補助情報(静的特徴、既知の共変量)を柔軟に活用できる。 高速なプロトタイピングが可能。 弱み: RNNやTransformerほど複雑な時系列パターンを捉えるのは苦手な場合がある。 ユースケース: 補助情報が豊富な時系列データや、時系列予測を一般的な機械学習タスクとして扱いたい場合。 15
【事前学習済みモデル】ChronosModel コンセプト: 大規模データで事前に訓練された言語モデルベースの予測モデル。 時系列データをトークンに変換し、言語モデルとして扱う。 特徴: ゼロショット予測: 追加の訓練なしで、未知のデータセットに対してすぐに予測を開始できる。 ファインチューニング: 特定のタスクに合わせて性能をさらに向上させることが可能。 強み:
データが非常に少ない、または存在しない新しいタスクでも予測が可能。 高い汎用性。 弱み: モデルが複雑で解釈が難しい場合がある。 ユースケース: 新製品・新サービスの需要予測、履歴データが限られている場合の迅速な予測。 16
4. モデル共通の重要概念 17
共有ハイパーパラメータ 多くのモデルで共通して利用できる、性能向上に役立つハイパーパラメータ。 target_scaler : 役割: 各時系列のターゲット値をスケーリング(標準化など)。 効果: 学習の安定化、精度向上、適合時間の短縮。特に深層学習モデルで重要。 covariate_scaler :
役割: 共変量や静的特徴をスケーリング。 効果: 正規化された入力を期待するモデルで、共変量を効果的に利用。 covariate_regressor : 役割: 共変量からターゲット値を予測する回帰モデル(GBMなど)を組み込む。 効果: 共変量の影響を明示的に分離し、メインの予測モデルが時系列自体のパターンに集中できるよ うにする。 18
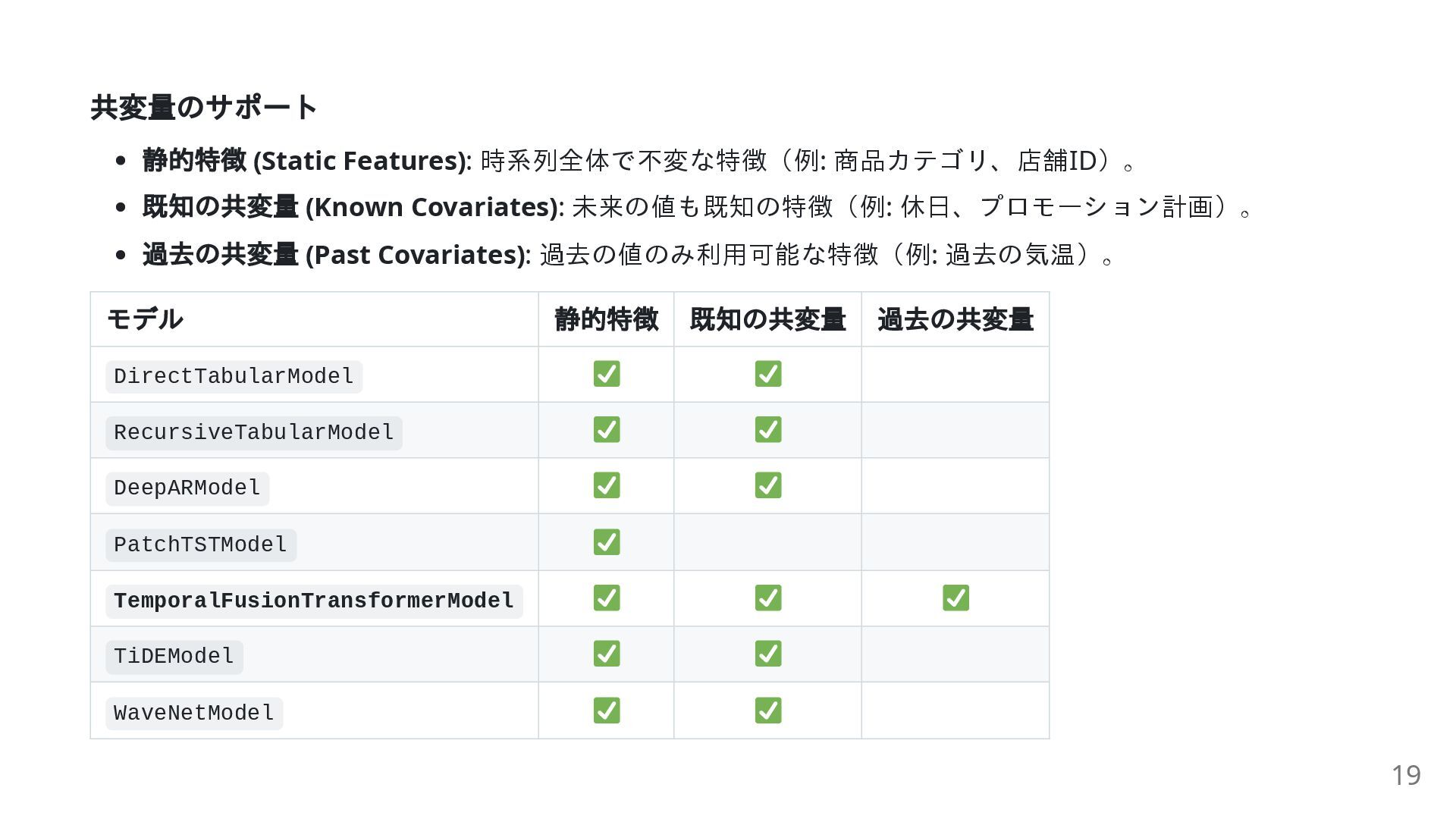
共変量のサポート 静的特徴 (Static Features): 時系列全体で不変な特徴(例: 商品カテゴリ、店舗ID)。 既知の共変量 (Known Covariates): 未来の値も既知の特徴(例:
休日、プロモーション計画)。 過去の共変量 (Past Covariates): 過去の値のみ利用可能な特徴(例: 過去の気温)。 モデル 静的特徴 既知の共変量 過去の共変量 DirectTabularModel RecursiveTabularModel DeepARModel PatchTSTModel TemporalFusionTransformerModel TiDEModel WaveNetModel 19
5. 結論 AutoGluon は強力なAutoML ツール: モデル選択とチューニングを自動化し、誰でも高性能な予測モデルを構築可能。 モデルの「適材適所」が重要: 自動化は万能ではない。各モデルの強みと弱みを理解することが不可欠。 Naiveモデルの限界、ARIMAの非線形性への弱さ、TFTの解釈性、Chronosのゼロショット能力な ど。
成功の鍵は「データの理解」: 自身のデータの特性(トレンド、季節性、スパース性、共変量の有無)を深く理解し、それに合っ たモデルを選択・検討することが、最も信頼性の高い予測システムを構築する近道。 AutoGluon の自動化の恩恵を受けつつ、モデルの本質を理解して賢く使いこなしましょう。 20
AutoGluon 時系列予測メトリクス解説 初学者向けガイド 21
1. はじめに:予測メトリクスとは? モデルの性能を客観的に数値化し、比較を可能にする不可欠な指標 なぜ必要か? グラフを眺めるだけでは、どのモデルが真に優れているか判断できない。 在庫管理や人員配置など、ビジネス上の重要な意思決定の羅針盤となる。 AutoGluon における役割 TimeSeriesPredictor の
eval_metric で指定。 ハイパーパラメータチューニング、モデルランキング、アンサンブル構築など、 自動化プロセス全 体の最適化目標として機能する。 22
AutoGluon の原則:「値が大きいほど良い」 AutoGluonの評価指標には、一つだけ重要なルールがあります。 すべてのメトリクスは「値が大きいほど良い」形式で報告される。 誤差メトリクス (MAE, MSE など) の場合: 通常は値が
小さいほど良い。 AutoGluonでは内部で -1 を乗算して報告。 結果は負の値となり、**0に近い(絶対値が小さい)**ほど良い予測。 例: モデルA: MASE = -0.5 モデルB: MASE = -1.0 -0.5 > -1.0 なので、AutoGluonは モデルAを優れた予測と判断する。 この統一ルールにより、ユーザーは常に「数値が高いものを選ぶ」だけで最適なモデルを選択できる。 23
予測メトリクスの表記法 メトリクスの計算式で使われる共通の記号を理解しましょう。 共通の記号: yi,t : 時刻 t の時系列 i の
実際の値 fi,t : 時刻 t の時系列 i の 予測値 N : データセット内の時系列の総数 (アイテム数) T : 過去データの長さ H : 予測期間の長さ ( prediction_length ) 確率的予測に固有の記号: fi,t,q : 時刻 t の時系列 i の予測された q 分位数 例: q=0.5 なら中央値、 q=0.9 なら90パーセンタイル予測 ρq(y,f) : 分位数損失(ピンボール損失) 24
2. メトリクスの種類:点予測と確率的予測 時系列予測の評価指標は、予測の目的によって大きく2つに分類されます。 点予測メトリクス (Point Forecast Metrics) 「来週の売上は100個」のような 単一の値の予測精度を評価。 予測値が実際の値にどれだけ近いかを示す。
例: MAE , MSE , RMSE , MAPE , MASE 確率的予測メトリクス (Probabilistic Forecast Metrics) 「来週の売上は90%の確率で80個~120個の範囲に収まる」のような予測の不確実性(範囲)の精 度を評価。 予測分布が実際の値をどれだけ正確に捉えているかを示す。 例: SQL , WQL 25
点予測 vs. 確率的予測:ビジネス上の意味 予測は、それに基づく 行動を決定するためのツールです。 点予測: 目的: 具体的な数値目標の設定(例: 売上目標100個)。 限界:
予測の不確実性やリスクを考慮できない。 確率的予測: 目的: リスク管理(例: 在庫管理)。 活用例: 品切れリスク回避: 需要が高くなる可能性(高分位数)に基づき、安全在庫量を決定。 過剰在庫リスク回避: 需要が低くなる可能性(低分位数)に基づき、発注量を調整。 確率的予測は、不確実な現実世界で、より堅牢でリスクを考慮した意思決定を可能にします。 26
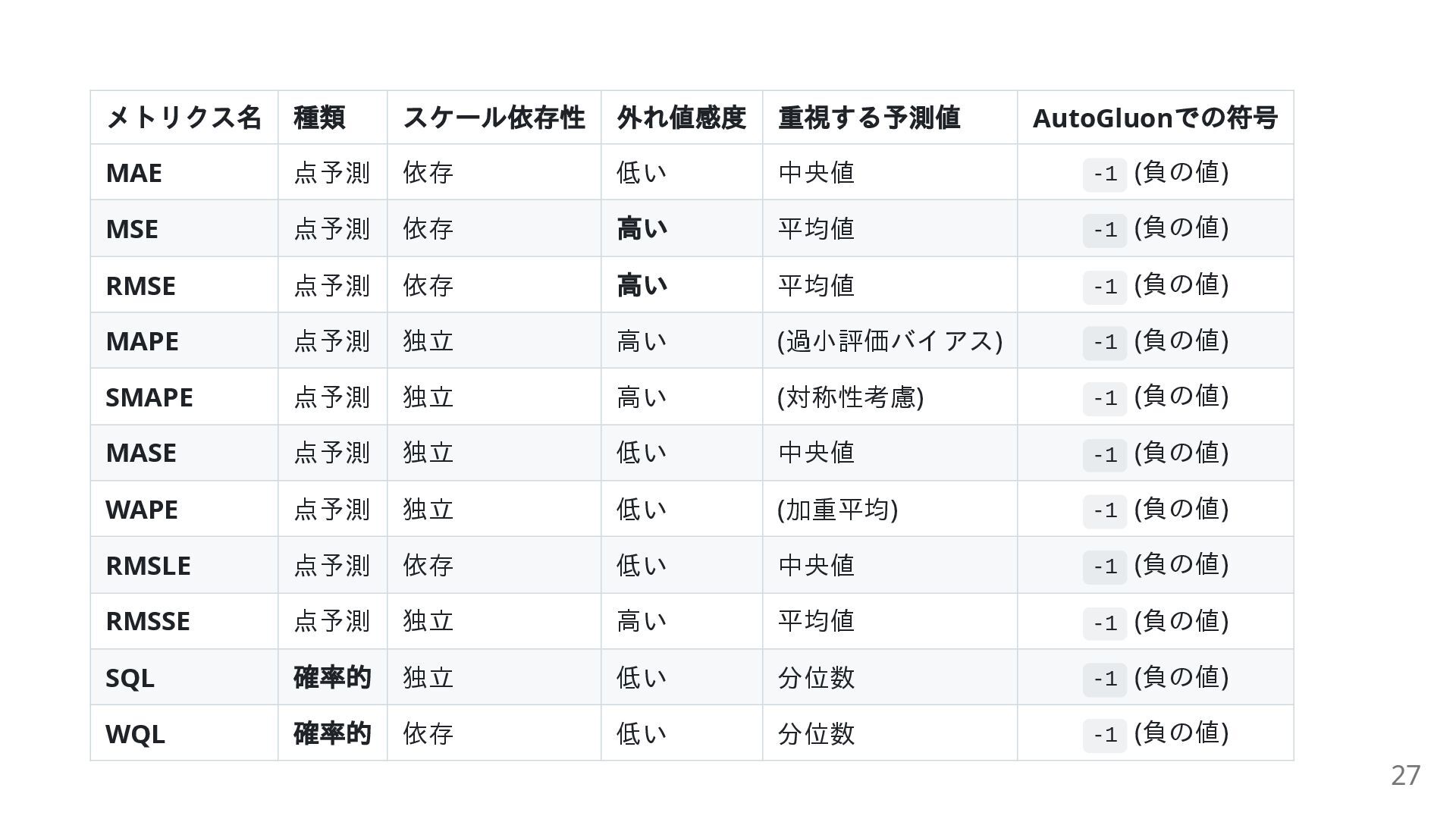
メトリクス名 種類 スケール依存性 外れ値感度 重視する予測値 AutoGluon での符号 MAE 点予測 依存
低い 中央値 -1 (負の値) MSE 点予測 依存 高い 平均値 -1 (負の値) RMSE 点予測 依存 高い 平均値 -1 (負の値) MAPE 点予測 独立 高い (過小評価バイアス) -1 (負の値) SMAPE 点予測 独立 高い (対称性考慮) -1 (負の値) MASE 点予測 独立 低い 中央値 -1 (負の値) WAPE 点予測 独立 低い (加重平均) -1 (負の値) RMSLE 点予測 依存 低い 中央値 -1 (負の値) RMSSE 点予測 独立 高い 平均値 -1 (負の値) SQL 確率的 独立 低い 分位数 -1 (負の値) WQL 確率的 依存 低い 分位数 -1 (負の値) 27
3. 主要な点予測メトリクス 28
MAE vs RMSE :誤差の捉え方の違い MAE (Mean Absolute Error - 平均絶対誤差)
コンセプト: 誤差の絶対値の平均。 特徴: シンプルで直感的。外れ値の影響を受けにくい。 重視: 中央値の予測。 ユースケース: 全ての誤差を均等に扱い、予測の 平均的なズレを把握したい場合。 RMSE (Root Mean Squared Error - 二乗平均平方根誤差) コンセプト: 誤差の二乗の平均の平方根。 特徴: 大きな誤差を強く罰する。外れ値に敏感。 重視: 平均値の予測。 ユースケース: 大きな予測ミスが致命的なコストに繋がる場合(例:在庫切れ)。 メトリクスの選択は、「頑健性 (MAE) 」と「大きな誤差の回避 (RMSE) 」のどちらを優先するかの戦略的判断 です。 29
MAPE vs SMAPE :パーセンテージ誤差 MAPE (Mean Absolute Percentage Error) コンセプト:
誤差をパーセンテージで評価。 強み: スケールが異なるデータ間の比較が容易。 弱み: ゼロ値問題: 実際の値が0だと計算不能。 バイアス: 過大予測に大きなペナルティを与え、モデルが過小予測する傾向を生む。 SMAPE (Symmetric Mean Absolute Percentage Error) コンセプト: MAPEの欠点を改善したバージョン。 特徴: 分母に予測値と実測値の平均を使うことで ゼロ値問題を緩和。 過大/過小予測のペナルティがより対称的。 30
MASE :最も推奨されるスケール独立メトリクス MASE (Mean Absolute Scaled Error) コンセプト: 予測誤差を、**ナイーブ予測の誤差で割り算(スケール)する。 解釈:
MASE < 1 : 予測モデルはナイーブ予測より 優れている。 MASE = 1 : ナイーブ予測と 同等。 MASE > 1 : ナイーブ予測より 劣っている(モデル導入価値なし)。 強み: スケール独立: 異なるデータ間で公平に比較可能。 ゼロ値問題なし: 間欠需要データに非常に有効。 直感的な基準: モデルの実用的な価値を判断しやすい。 MASE は、AutoML で試される多様なモデルを公平に比較するための「共通の物差し」として機能します。 31
WAPE & RMSLE :特定のビジネスニーズに対応 WAPE (Weighted Absolute Percentage Error) コンセプト:
誤差を 実際の値の合計で加重したパーセンテージ誤差。 特徴: MAPEのゼロ値問題を回避。売上が少ない商品の誤差を過大評価しない。 ユースケース: 低需要商品を含むポートフォリオ全体の誤差率を知りたい場合。 RMSLE (Root Mean Squared Logarithmic Error) コンセプト: 予測値と実測値の 対数を取ってからRMSEを計算。 特徴: 過小予測に大きなペナルティを与える。 ユースケース: 在庫切れなど、過小予測のコストが非常に高いビジネスシナリオ。 32
4. 主要な確率的予測メトリクス 33
SQL & WQL :不確実性の評価 SQL (Scaled Quantile Loss) コンセプト: 分位数損失(ピンボール損失)をナイーブ予測の誤差でスケール。
特徴: スケール独立で、異なるデータ間で予測区間の精度を比較可能。 中央値( q=0.5 )を予測する場合、MASE と等価。 WQL (Weighted Quantile Loss) コンセプト: 複数の分位数損失を 重み付けして合計。 特徴: AutoGluon のデフォルトメトリクス。 ビジネス上の重要度に応じて、特定の分位数(例:品切れリスクに関わる低分位数)を重視で きる。 ユースケース: 在庫切れと過剰在庫の両方のリスクをバランスさせたい場合。 AutoGluon がWQL をデフォルトとすることは、予測の「最先端」が不確実性の管理へとシフトしていること を示唆します。 34
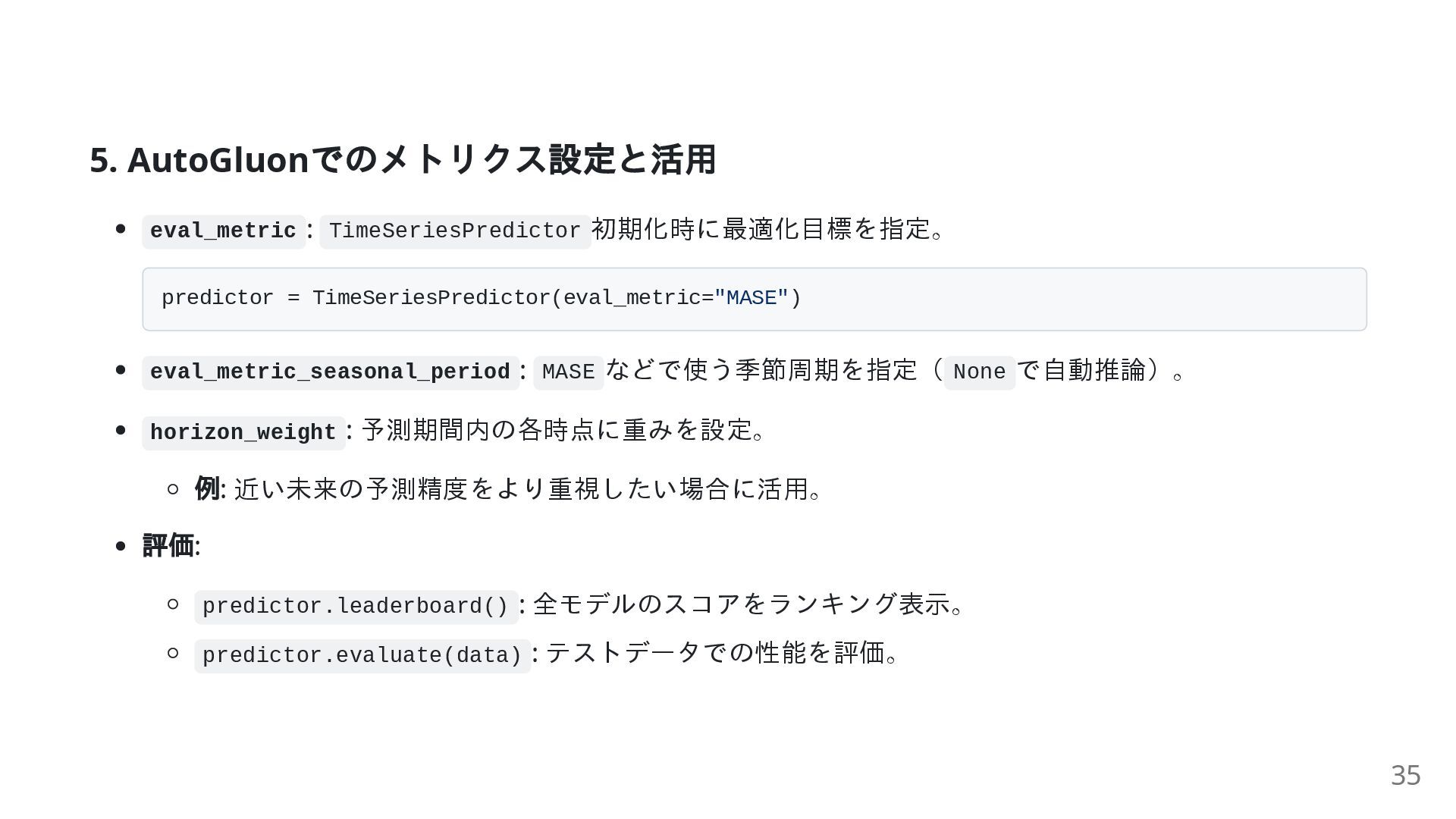
5. AutoGluon でのメトリクス設定と活用 eval_metric : TimeSeriesPredictor 初期化時に最適化目標を指定。 predictor = TimeSeriesPredictor(eval_metric="MASE")
eval_metric_seasonal_period : MASE などで使う季節周期を指定( None で自動推論)。 horizon_weight : 予測期間内の各時点に重みを設定。 例: 近い未来の予測精度をより重視したい場合に活用。 評価: predictor.leaderboard() : 全モデルのスコアをランキング表示。 predictor.evaluate(data) : テストデータでの性能を評価。 35
6. まとめと推奨事項 適切なメトリクス選択は、ビジネス目標とデータ特性を理解した上での戦略的判断です。 どう選ぶか? i. ビジネス目標を明確に: 何のための予測か?どの誤差が最もコスト高か? ii. データの特性を理解: ゼロ値、外れ値、スケールの違いは?
iii. 点予測 vs. 確率的予測: 不確実性の管理は必要か? 使い分けのヒント: 直感的な誤差: MAE 大きな誤差を罰したい: RMSE スケール比較(ゼロなし): MAPE ナイーブ予測との比較/ 間欠需要: MASE (推奨) 過小予測を罰したい: RMSLE 不確実性を評価したい: SQL , WQL (AutoGluonデフォルト) 各メトリクスの「意味」を理解し、AutoGluon の力を最大限に引き出しましょう。 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}