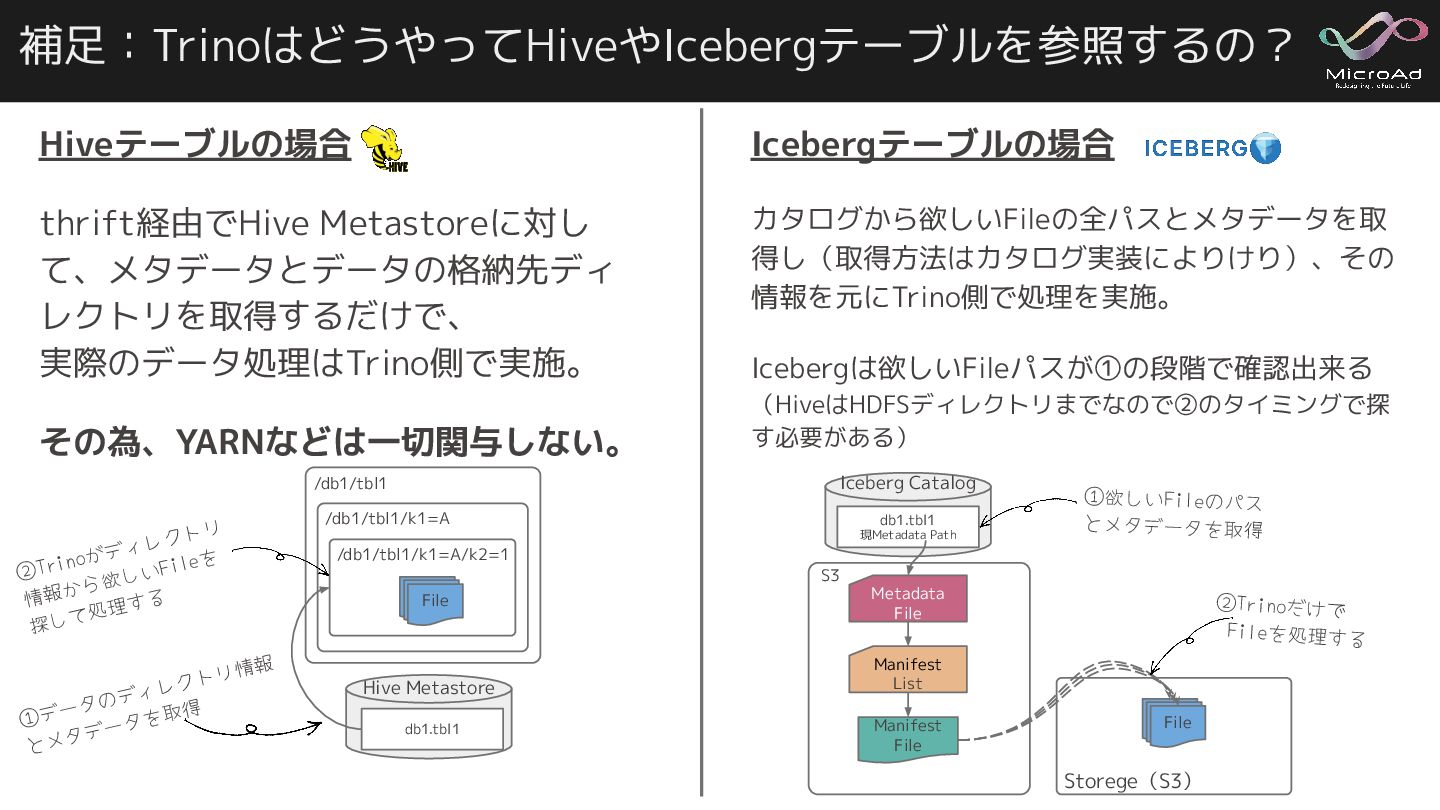
Iceberg connector · Issue #11744 · trinodb/trino 2. Icebergのadd_filesプロシージャを使ったテーブルにて、 参照元のHiveテーブルにtimestamp型があった場合、 そのままでは以下のエラーが出て参照出来ない ◦ エラー文:Query 20231002_061128_00067_tqdd2 failed: Unsupported Trino column type (timestamp(6) with time zone) for Parquet column ([update_time] optional int96 update_time = 8) ◦ Trino Iceberg not honoring existing timestamp column type name of the table created outside Trino (e.g. Spark) stored in HMS · Issue #11442 ◦ Hive/Impalaで利用しているTIMESTAMP型はINT96でParquetファイルで書き込みしている がTrinoで利用しているParquetライブラリは新しくINT96に対応していない事が影響
| Using Trino as a batch processing engine https://trino.io/blog/2022/06/24/trino-meetup-extract-trino-load.html ◦ Trino | Project Tardigrade delivers ETL at Trino speeds to early users https://trino.io/blog/2022/05/05/tardigrade-launch.html • TrinoのHAに関連する情報 ◦ Can you set up Trino in HA mode? - Trino - Starburst forum https://www.starburst.io/community/forum/t/can-you-set-up-trino-in-ha-mode/31 ◦ High Availability · Issue #391 · trinodb/trino https://github.com/trinodb/trino/issues/391 • Icebergについて深く知る事が出来る良い記事 ◦ Apache Iceberg: An Architectural Look Under the Covers | Dremio https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/
{kind=link}
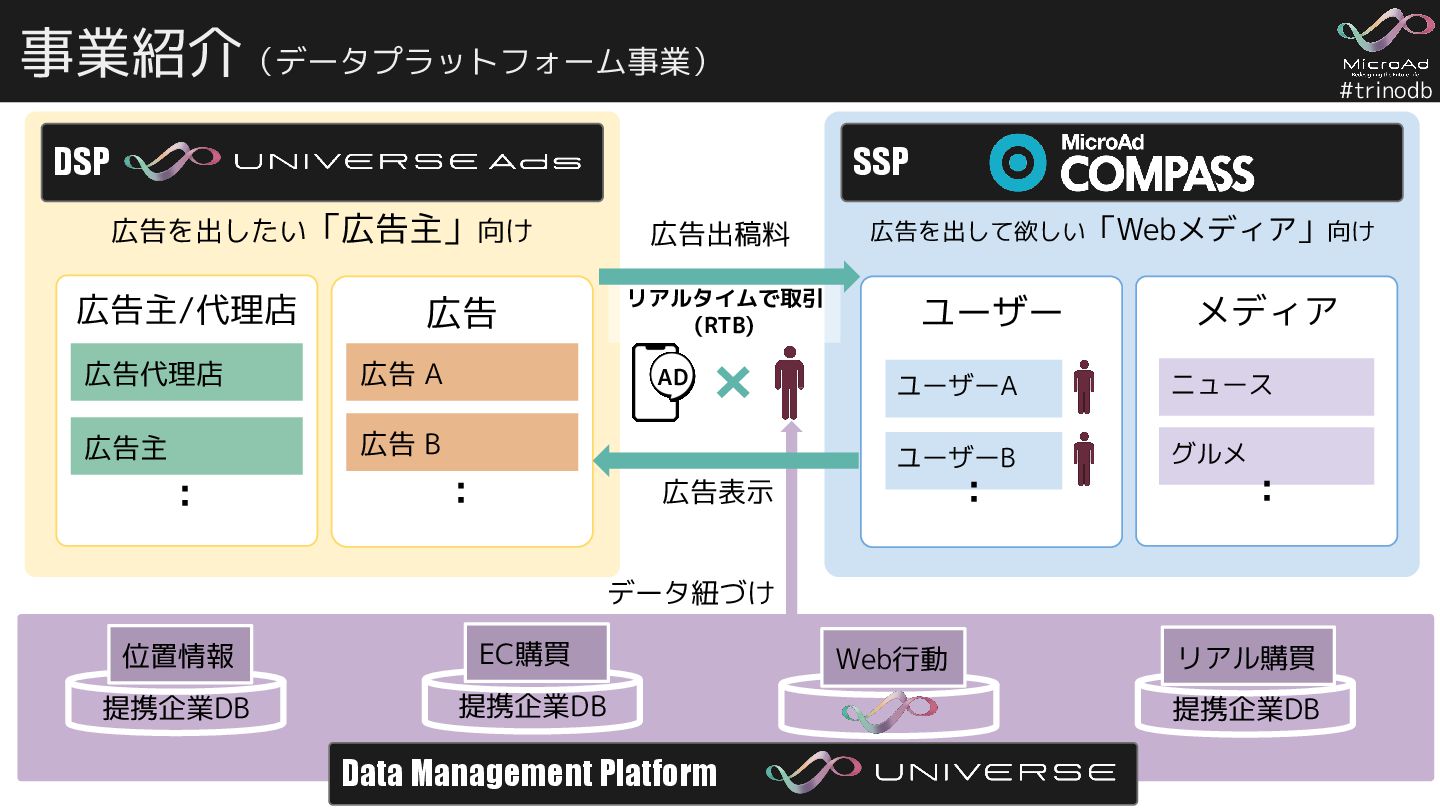{kind=link}
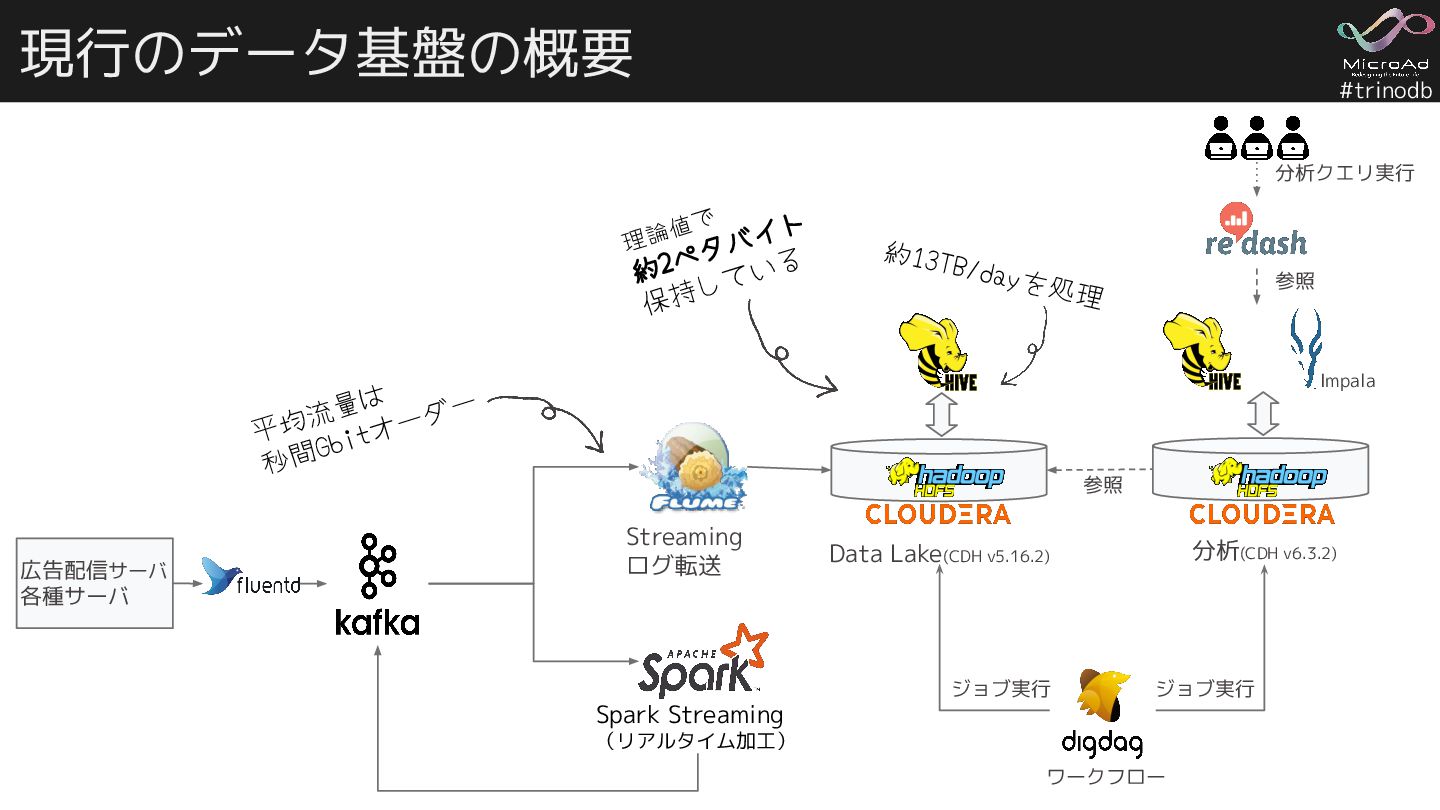{kind=link}
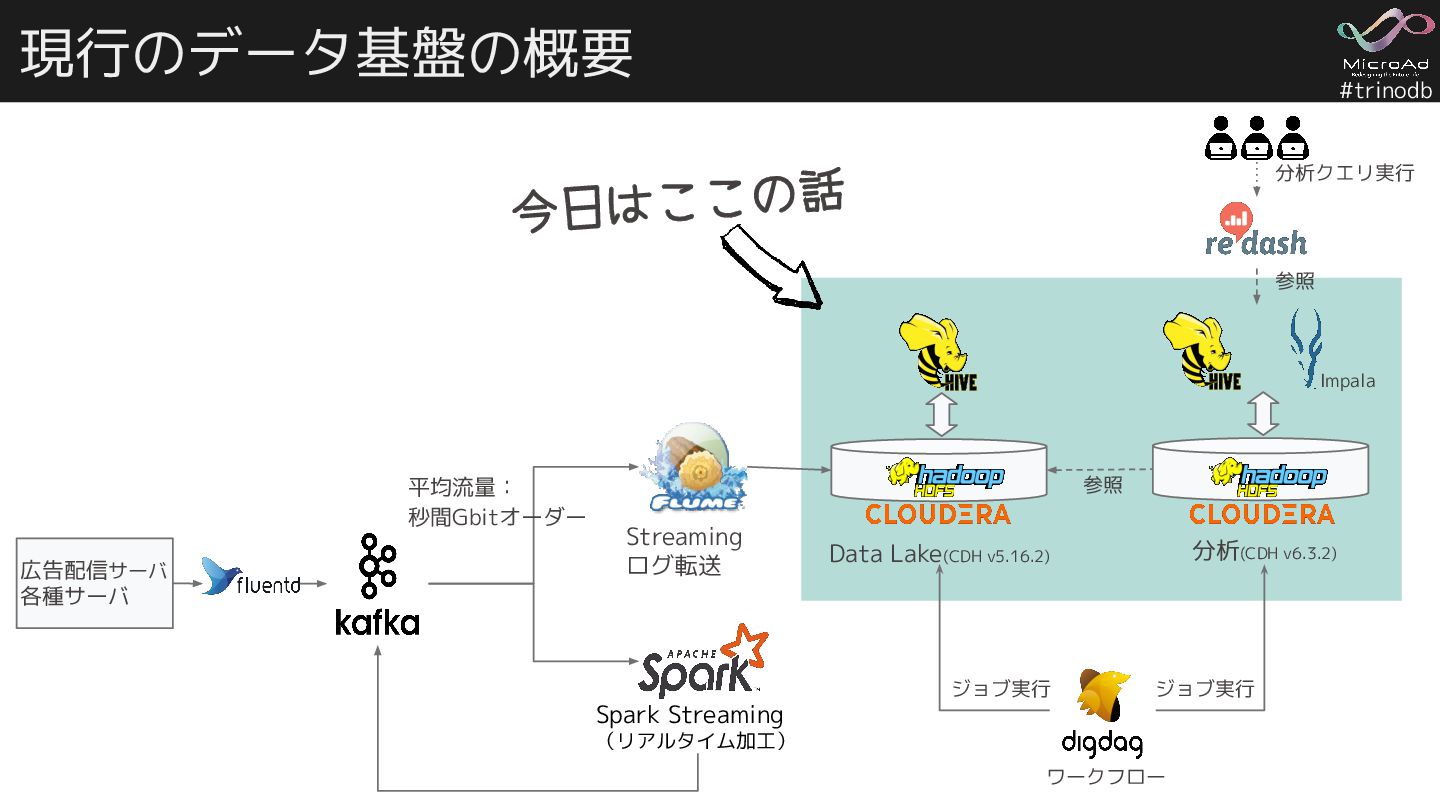{kind=link}
{kind=link}
{kind=link}
{kind=link}
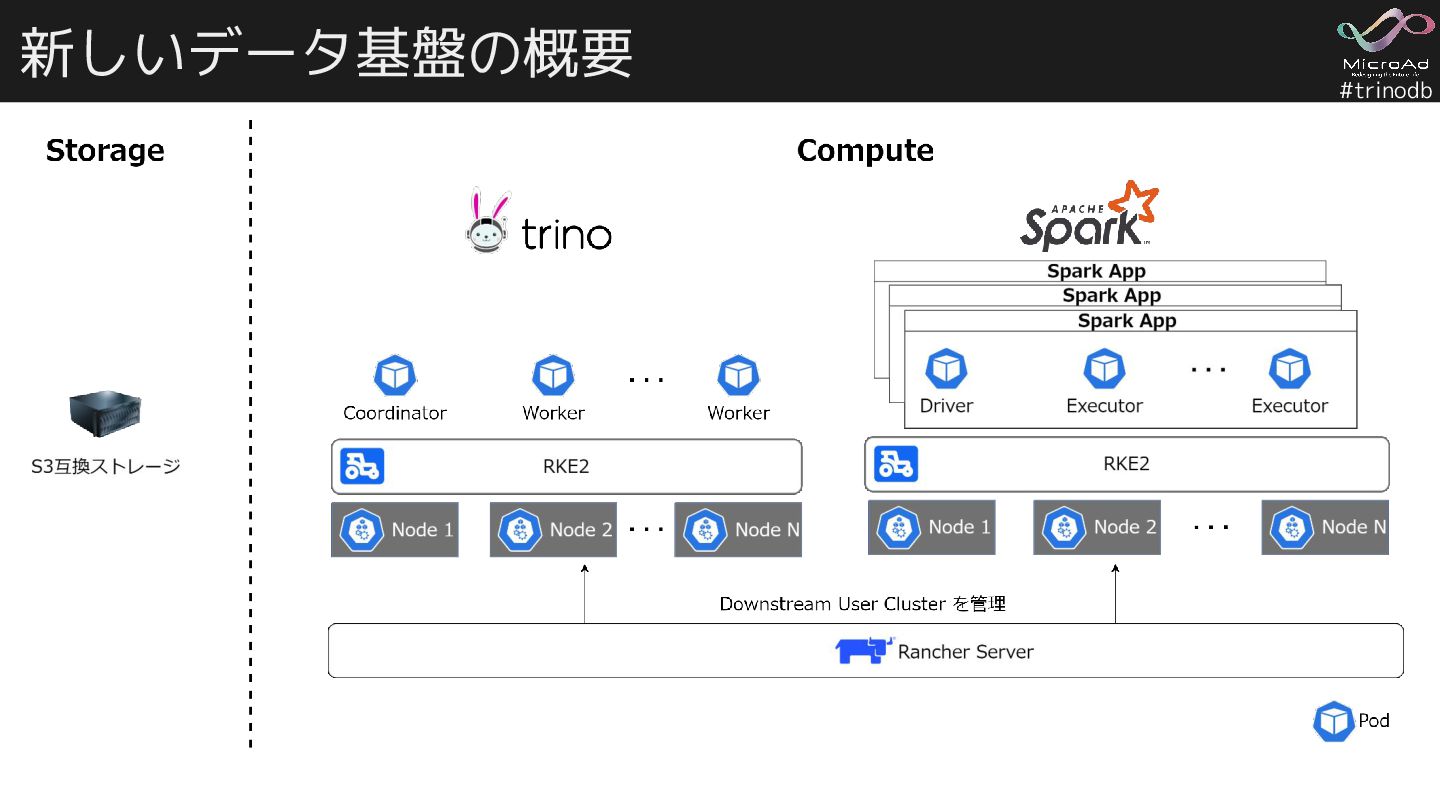{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}