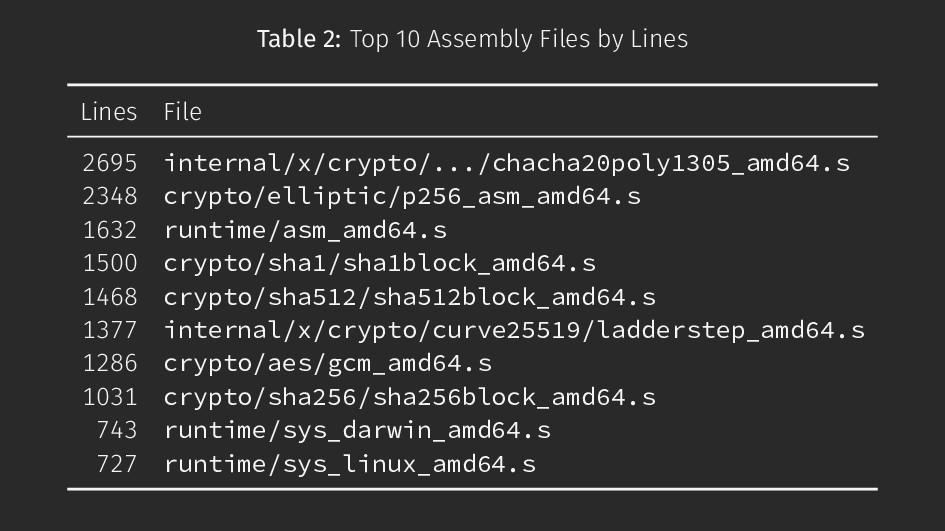
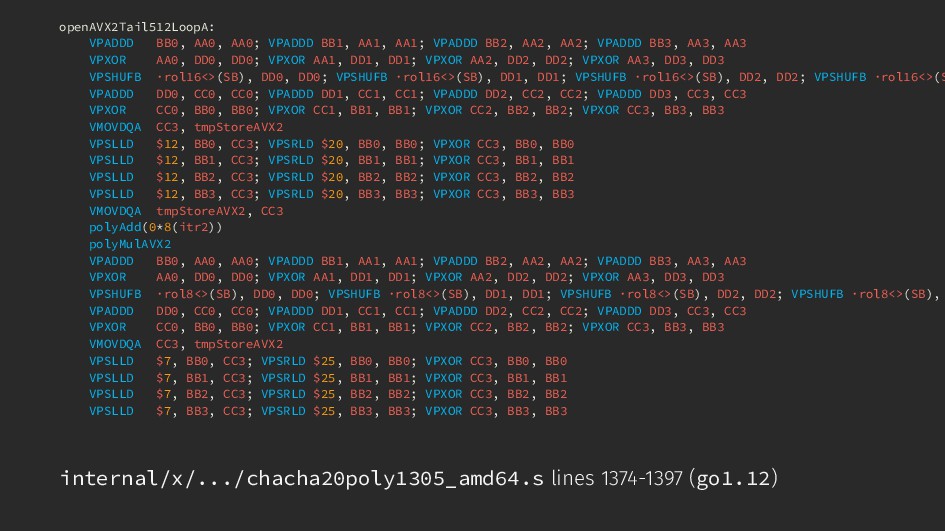
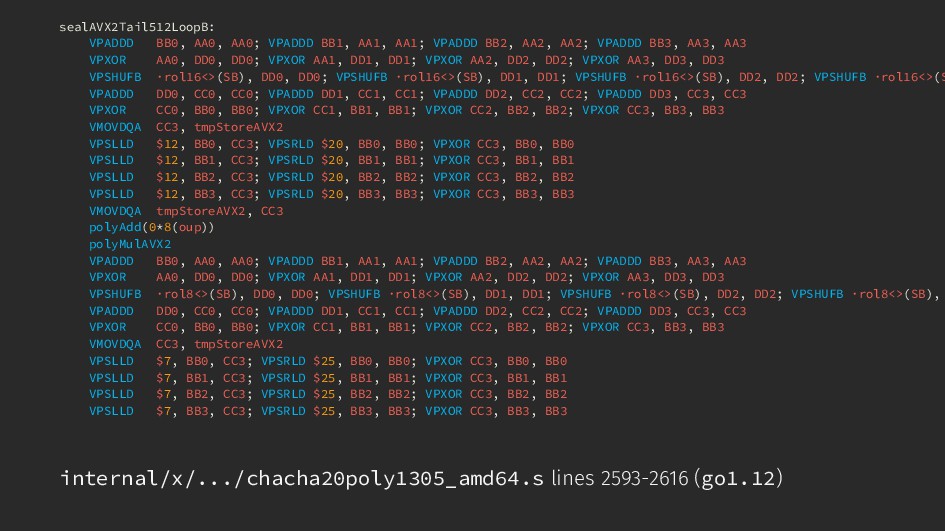
BB2, AA2, AA2; VPADDD BB3, AA3, AA3 VPXOR AA0, DD0, DD0; VPXOR AA1, DD1, DD1; VPXOR AA2, DD2, DD2; VPXOR AA3, DD3, DD3 VPSHUFB ·rol16<>(SB), DD0, DD0; VPSHUFB ·rol16<>(SB), DD1, DD1; VPSHUFB ·rol16<>(SB), DD2, DD2; VPSHUFB ·rol16<>(S VPADDD DD0, CC0, CC0; VPADDD DD1, CC1, CC1; VPADDD DD2, CC2, CC2; VPADDD DD3, CC3, CC3 VPXOR CC0, BB0, BB0; VPXOR CC1, BB1, BB1; VPXOR CC2, BB2, BB2; VPXOR CC3, BB3, BB3 VMOVDQA CC3, tmpStoreAVX2 VPSLLD $12, BB0, CC3; VPSRLD $20, BB0, BB0; VPXOR CC3, BB0, BB0 VPSLLD $12, BB1, CC3; VPSRLD $20, BB1, BB1; VPXOR CC3, BB1, BB1 VPSLLD $12, BB2, CC3; VPSRLD $20, BB2, BB2; VPXOR CC3, BB2, BB2 VPSLLD $12, BB3, CC3; VPSRLD $20, BB3, BB3; VPXOR CC3, BB3, BB3 VMOVDQA tmpStoreAVX2, CC3 polyAdd(0*8(itr2)) polyMulAVX2 VPADDD BB0, AA0, AA0; VPADDD BB1, AA1, AA1; VPADDD BB2, AA2, AA2; VPADDD BB3, AA3, AA3 VPXOR AA0, DD0, DD0; VPXOR AA1, DD1, DD1; VPXOR AA2, DD2, DD2; VPXOR AA3, DD3, DD3 VPSHUFB ·rol8<>(SB), DD0, DD0; VPSHUFB ·rol8<>(SB), DD1, DD1; VPSHUFB ·rol8<>(SB), DD2, DD2; VPSHUFB ·rol8<>(SB), VPADDD DD0, CC0, CC0; VPADDD DD1, CC1, CC1; VPADDD DD2, CC2, CC2; VPADDD DD3, CC3, CC3 VPXOR CC0, BB0, BB0; VPXOR CC1, BB1, BB1; VPXOR CC2, BB2, BB2; VPXOR CC3, BB3, BB3 VMOVDQA CC3, tmpStoreAVX2 VPSLLD $7, BB0, CC3; VPSRLD $25, BB0, BB0; VPXOR CC3, BB0, BB0 VPSLLD $7, BB1, CC3; VPSRLD $25, BB1, BB1; VPXOR CC3, BB1, BB1 VPSLLD $7, BB2, CC3; VPSRLD $25, BB2, BB2; VPXOR CC3, BB2, BB2 VPSLLD $7, BB3, CC3; VPSRLD $25, BB3, BB3; VPXOR CC3, BB3, BB3 internal/x/.../chacha20poly1305_amd64.s lines 1374-1397 (go1.12)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
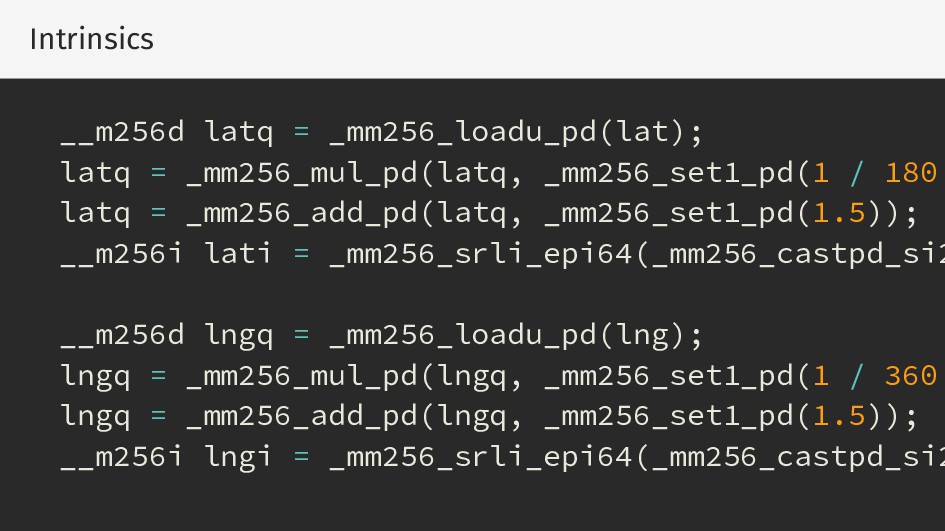{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
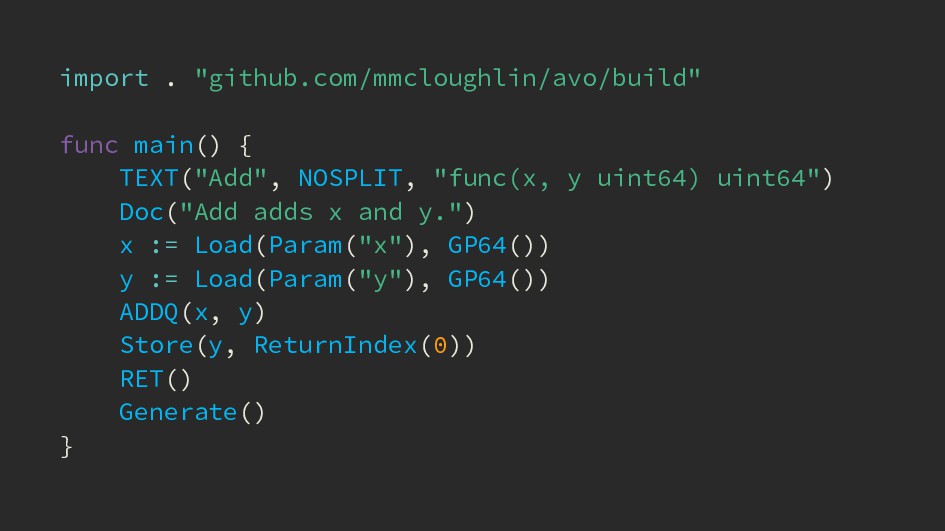{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
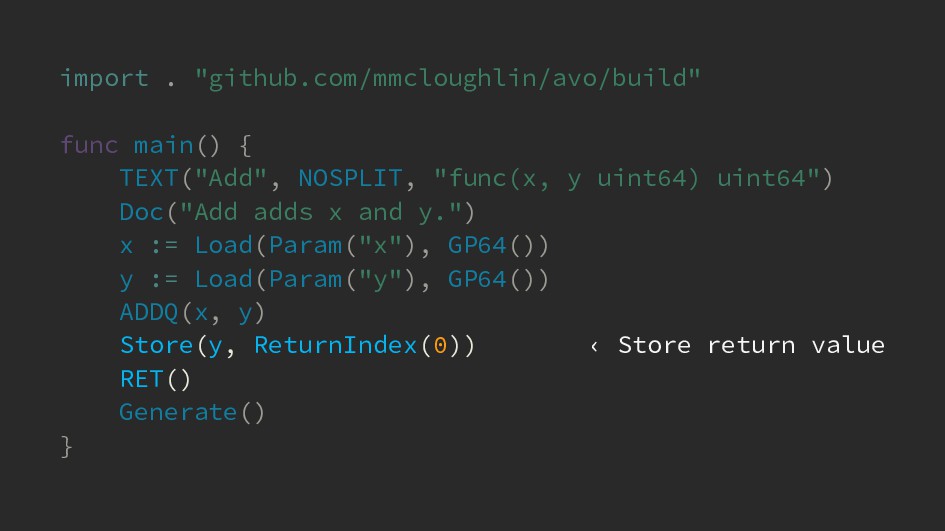{kind=link}
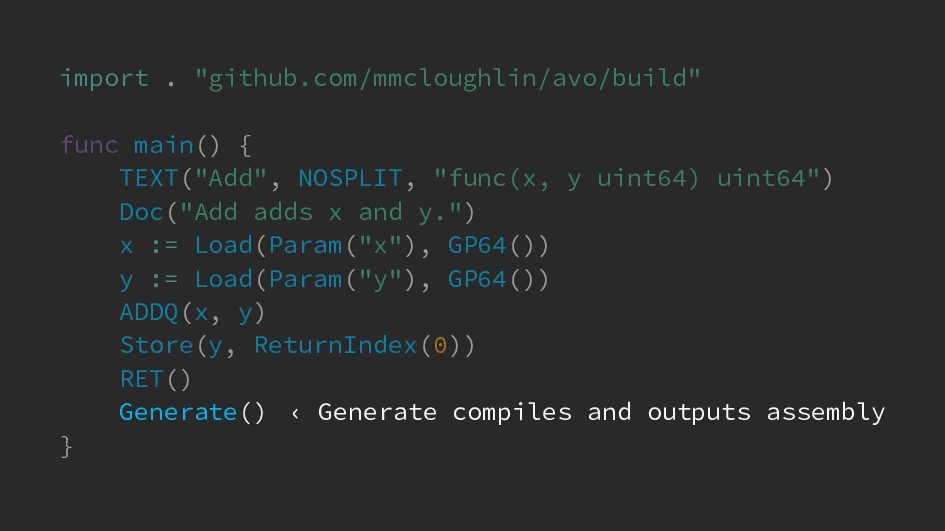{kind=link}
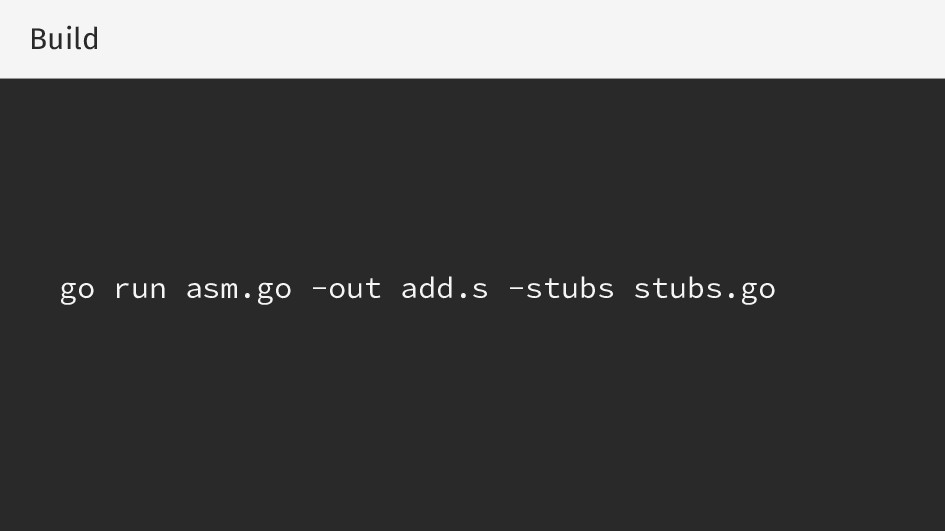{kind=link}
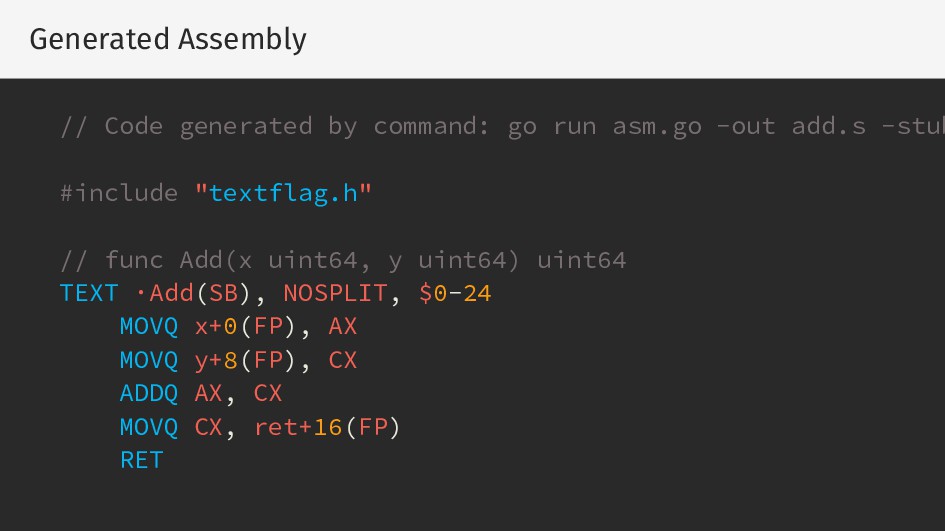{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
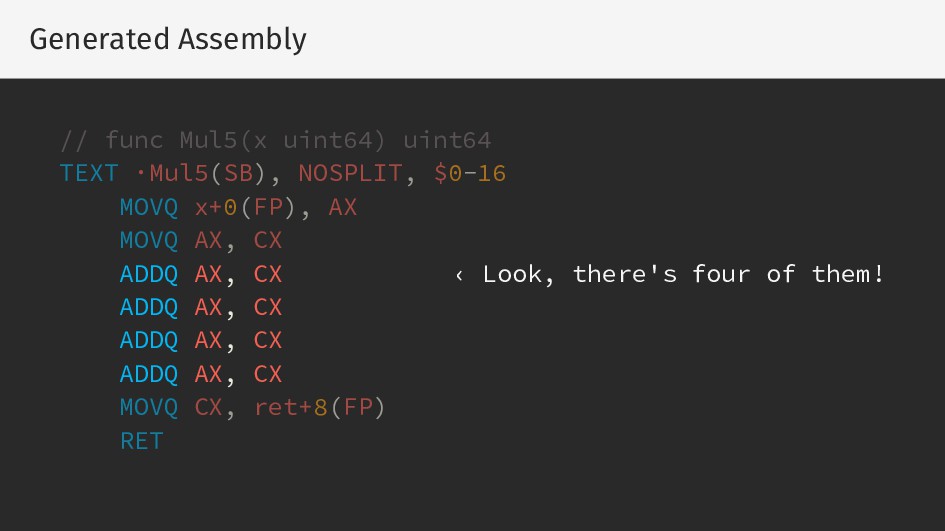{kind=link}
{kind=link}
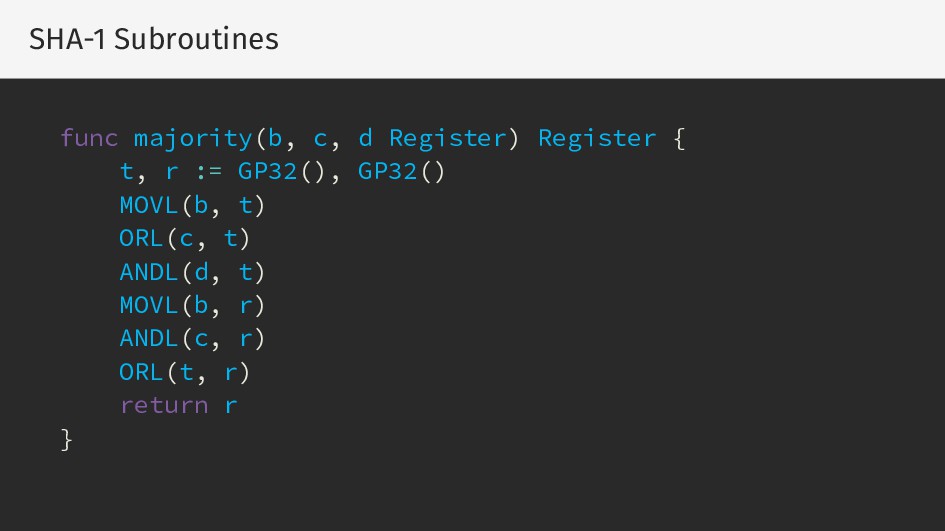{kind=link}
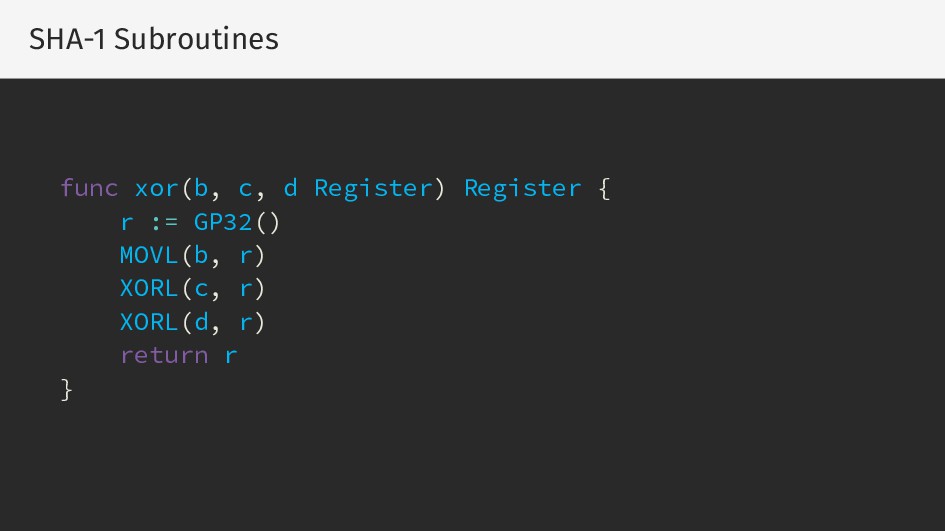{kind=link}
![SHA-1 Loops Comment("Load initial hash.") hash := [5]Register{GP32(), GP32(), GP32(),](https://files.speakerdeck.com/presentations/782158889fa14aa8960634c08574a217/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}