Finally you have managed to pack your application and are ready to deploy it onto your infrastructure. Ready to go!
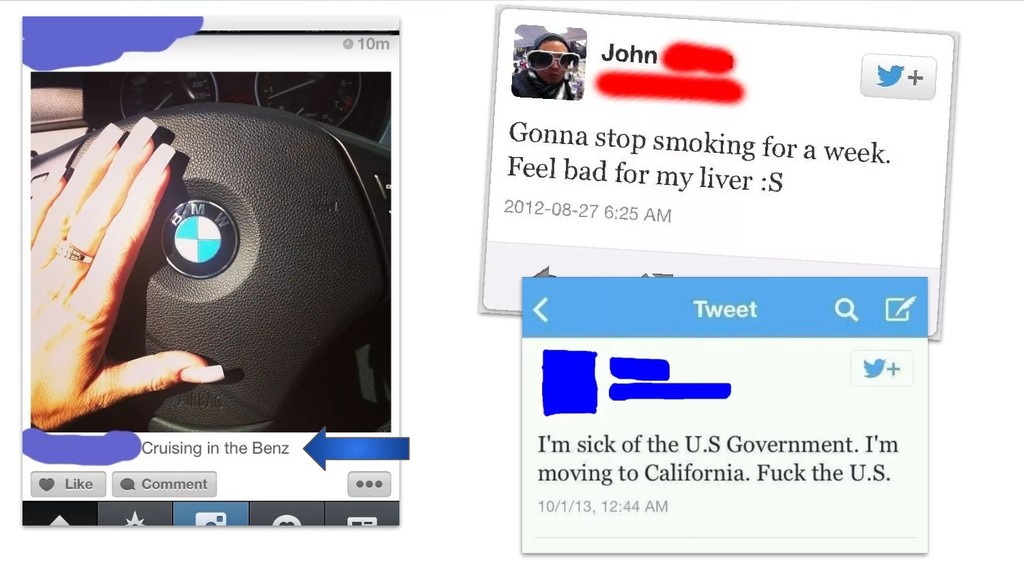
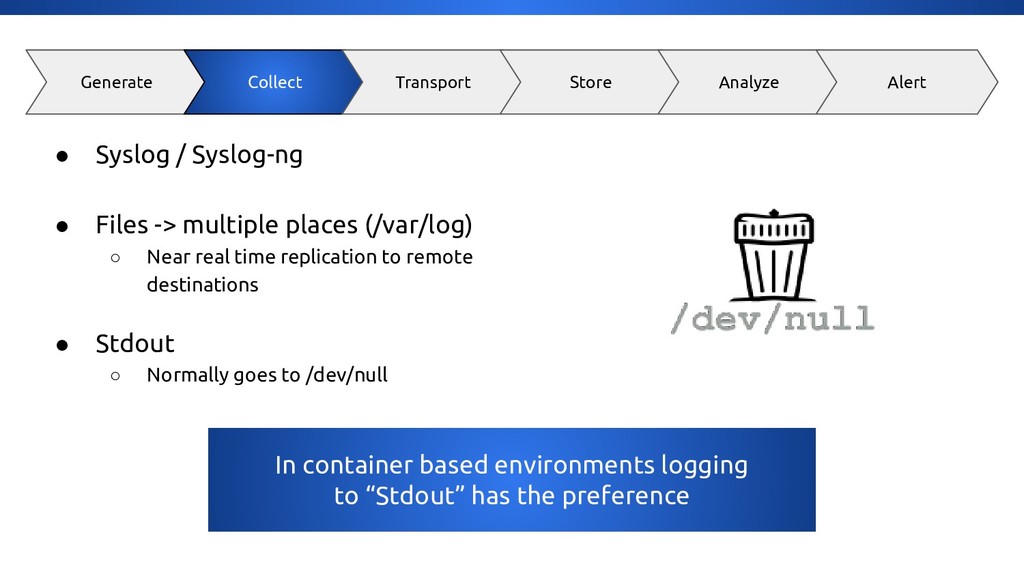
But wait, how do you deal with application logging & monitoring? No problem you will just send everything to a log file… think again! * how can you give that information to the operational department or even to your fellow engineers? * how to get monitoring metric data from your application and host operating system? * how to visualise visualise the information so it is easy to query? * how can you extract data from your logging data so its makes sense? * how do you alert on certain events that happened in your application?
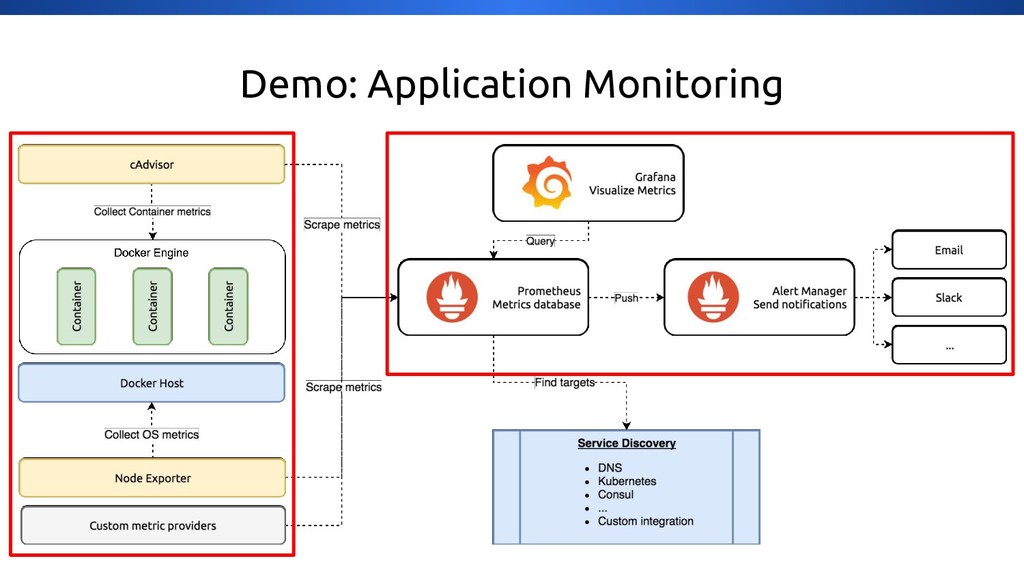
This hands on talk will give you an introduction on how easy it is to setup centralised logging & logging introducing Fluentd, Prometheus, ElasticSearch, Docker, Grafana. During the talk we will build an environment with the tools mentioned and deploy an application which you can monitor.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
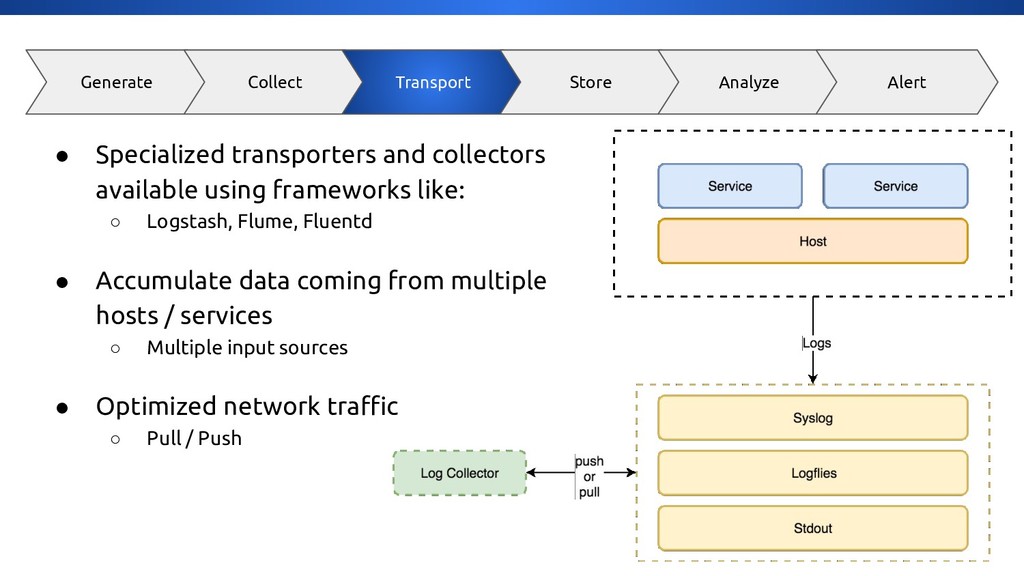{kind=link}
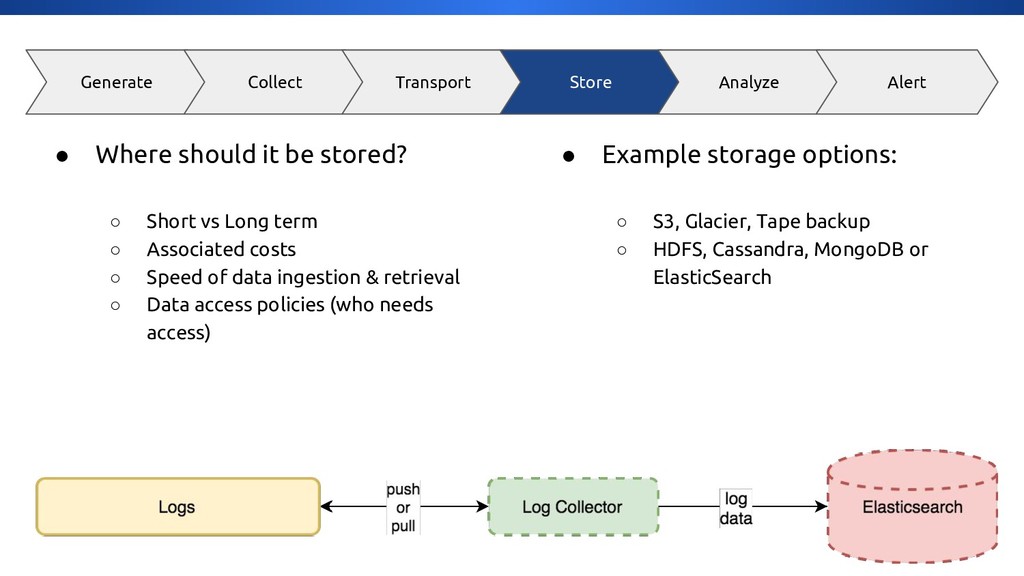{kind=link}
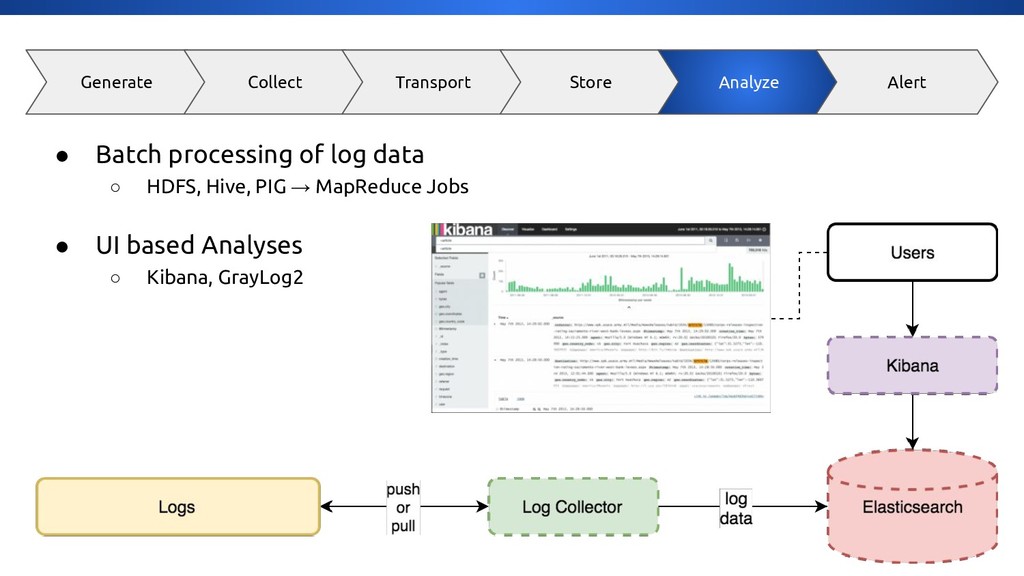{kind=link}
{kind=link}
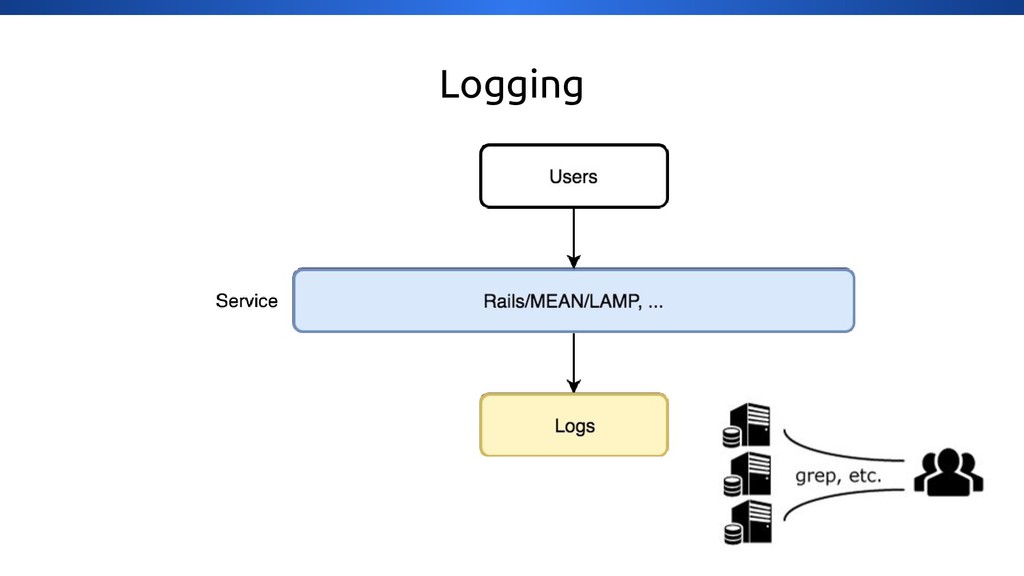{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
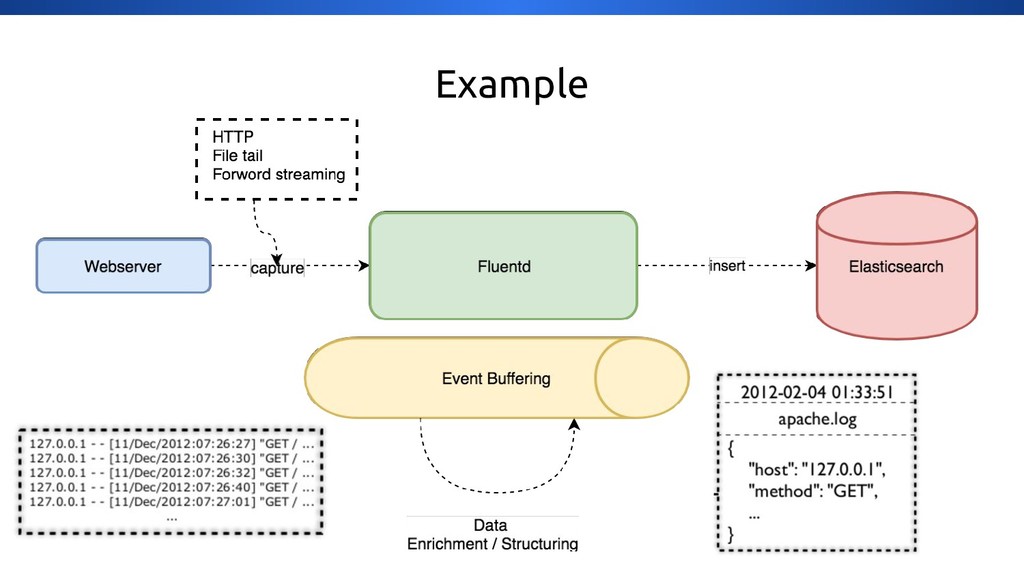{kind=link}
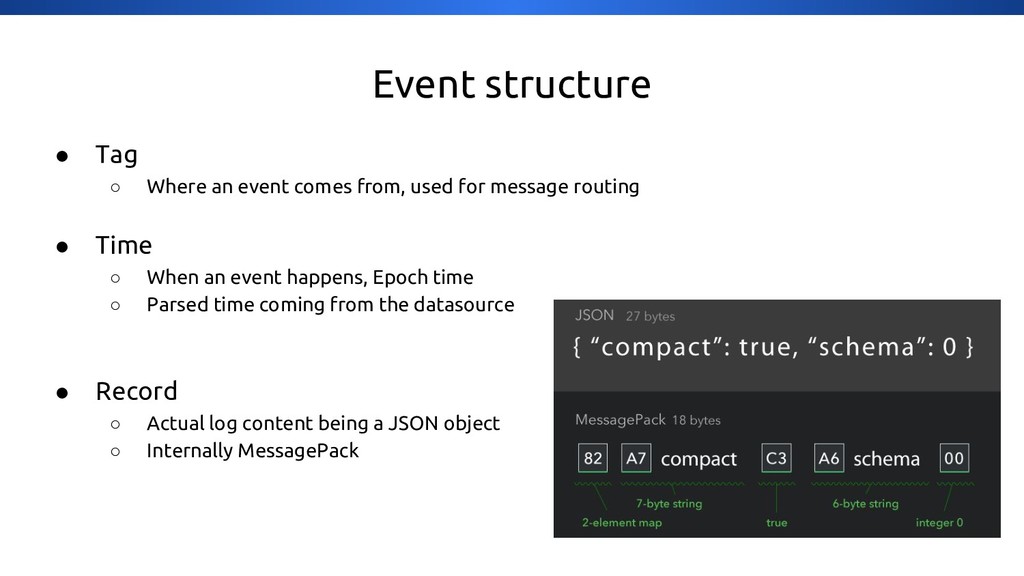{kind=link}
![Event example 192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1"](https://files.speakerdeck.com/presentations/a1579d540438458d8637ecc8b243e771/slide_24.jpg){kind=link}
{kind=link}
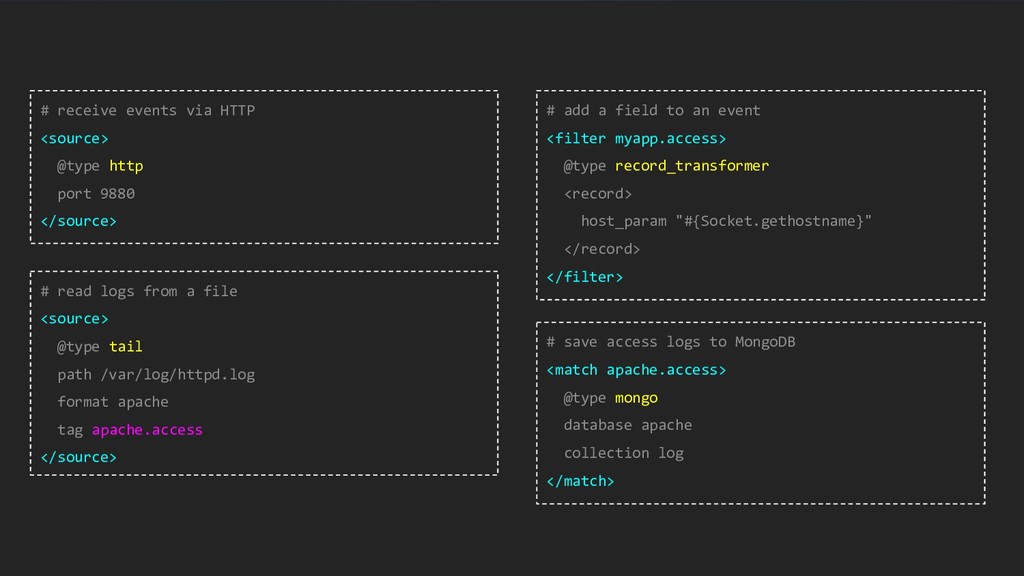{kind=link}
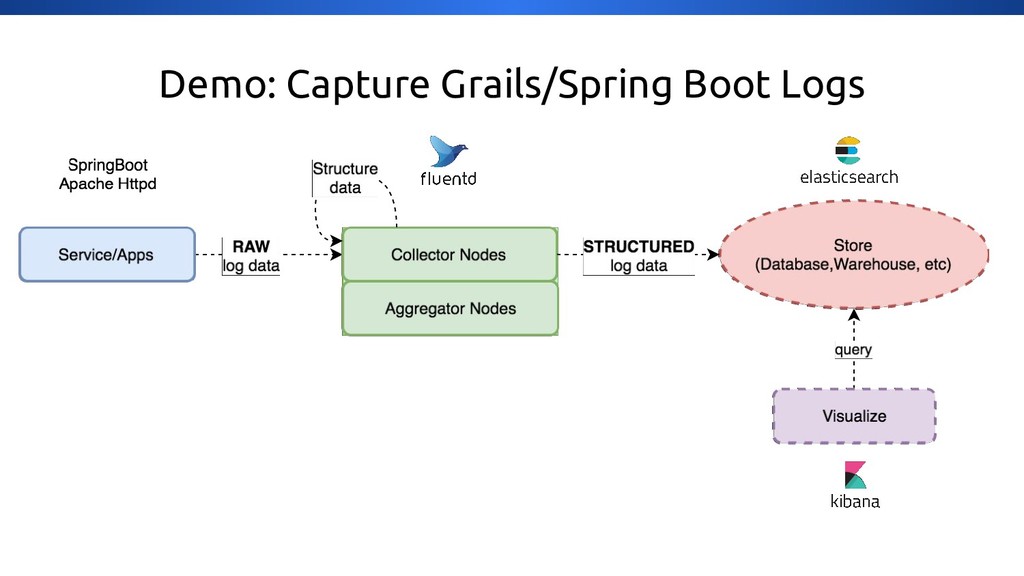{kind=link}
{kind=link}
{kind=link}
{kind=link}
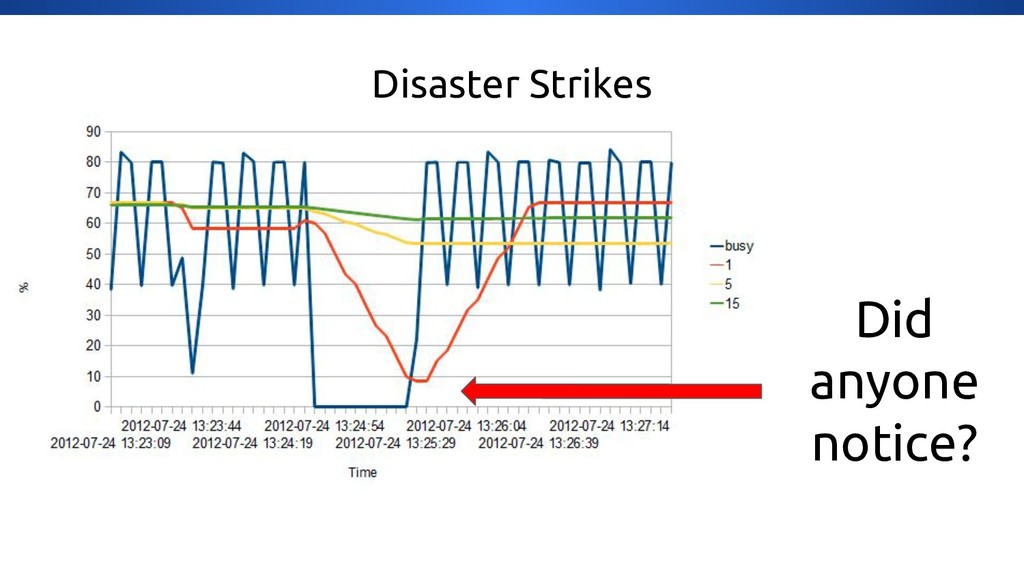{kind=link}
{kind=link}
{kind=link}
{kind=link}
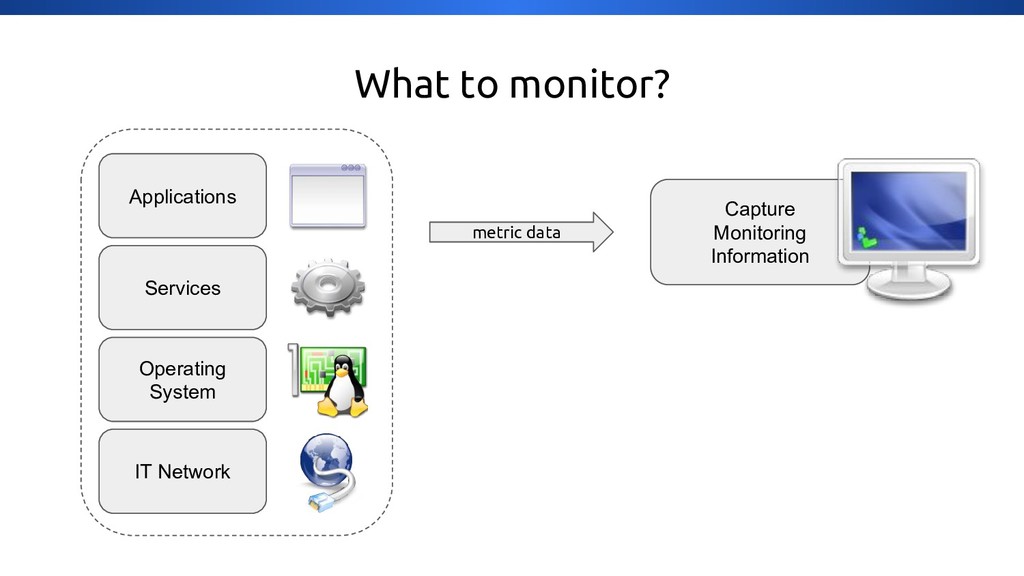{kind=link}
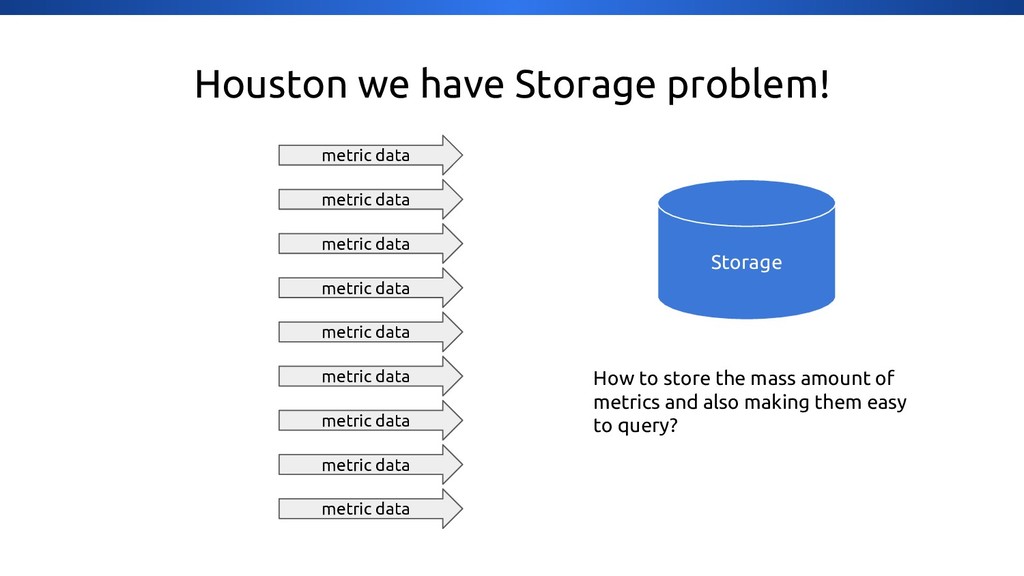{kind=link}
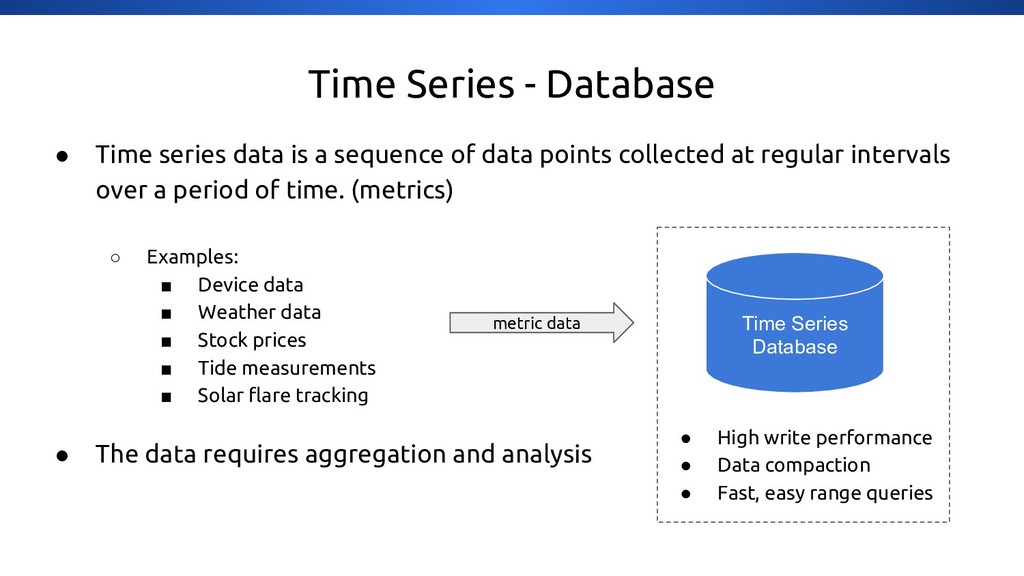{kind=link}
{kind=link}
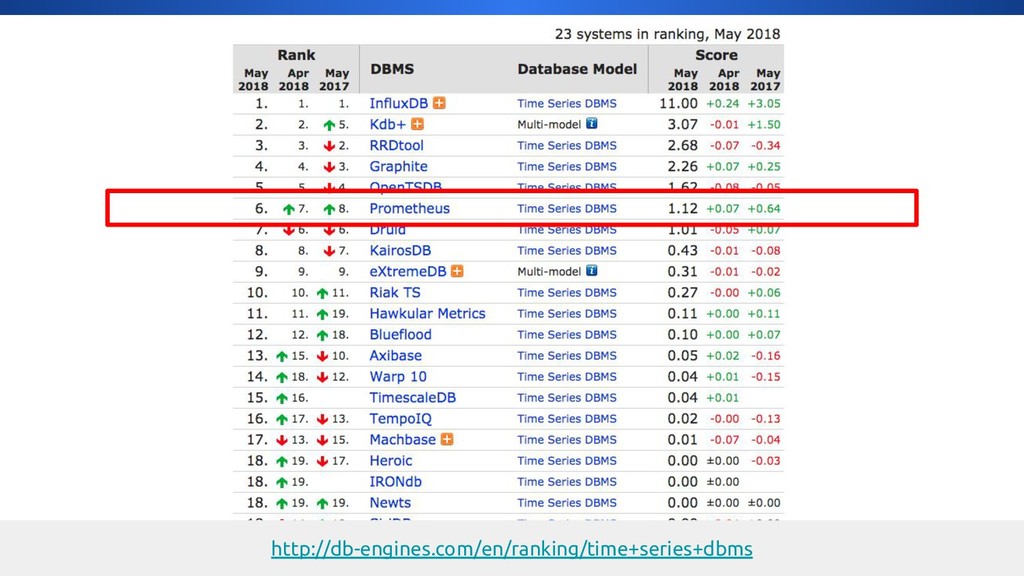{kind=link}
{kind=link}
{kind=link}
{kind=link}
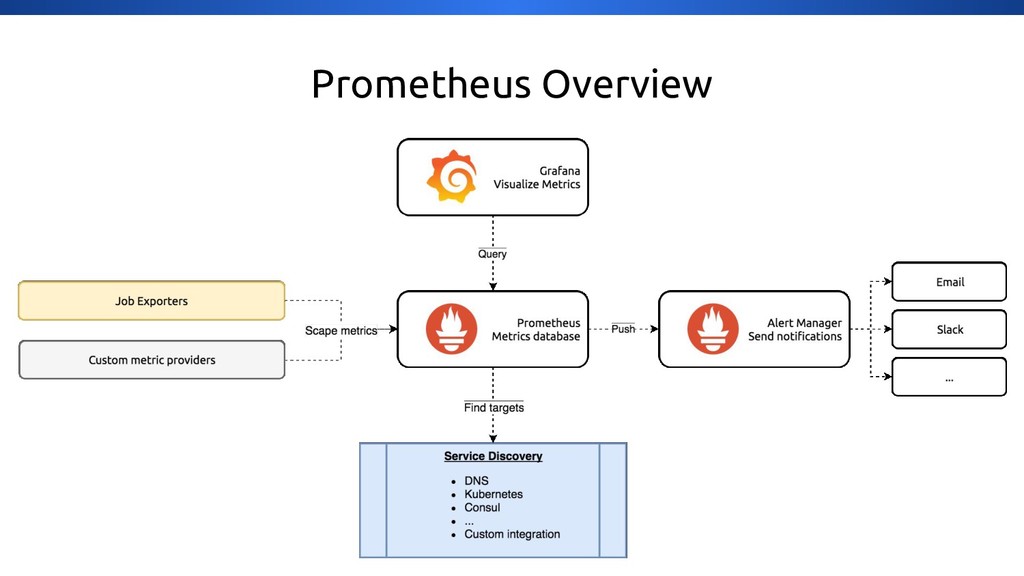{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}